この記事は ランサーズ Advent Calendar 2019 25日目(最終日)の記事です。
こんにちは。ランサーズでEMぽいことをしている @godgarden です。
普段は、データ基盤や認証認可などのプラットフォーム基盤の開発、エンジニア組織(特に採用周り)グループ会社とのシステム連携を見ています。
まえおき
2008年、当時は 「時間と場所にとらわれない新しい働き方を創る」 というビジョンのもと クラウドソーシング「Lancers」をリリースしました。このときは単一事業・サービスとして運営をしていました。
2017年、「テクノロジーで誰もが自分らしく働ける社会をつくる。」 というビジョンにアップデートし、働くをより包括的にサポートするため事業領域を拡大し、グループ企業も増えてきています。(詳細は、ランサーズ サービス概要から)

プロジェクトは突然に。
ある朝、Slackに経営企画メンバーから一通のメッセージが突然届きました。

KPIを自動で吸い上げるシステムとは、、と思いながらも会話してみると、データ基盤を整備している話を聞き、以下のような課題を解決できないかという相談でした。
- より詳細にさまざまな角度からKPI分析したい
- 定期的にかつ自動でモニタリング
- グループ会社を含めた全事業のサマリ、ドリルダウン分析したい
- 一部人力作業も絡んでおり、オペレーション工数が増大
- ... などなど。
ワンチームで解決。
無事、プロジェクトは遂行できましたが、数々のアンチパターンを歩みそうになったり、先行して構築していたデータ・モニタリング基盤が整っていたからやりきれた、など運もありました。
急成長企業や、IPO前後の企業では似たような課題が起きがちです。
ランサーズで歩んできた事例を課題ベースで振り返りながら紹介し、少しでも同じステージを辿る誰かの1mmでも参考になればと幸いです。
そして、プロダクトを裏から支える BI・SREなど玄人エンジニアの武勇伝を讃えるというクリスマスプレゼント(いいね)をお願いします。きっと皆の励みになります🎅
データドリブンへの道のり。
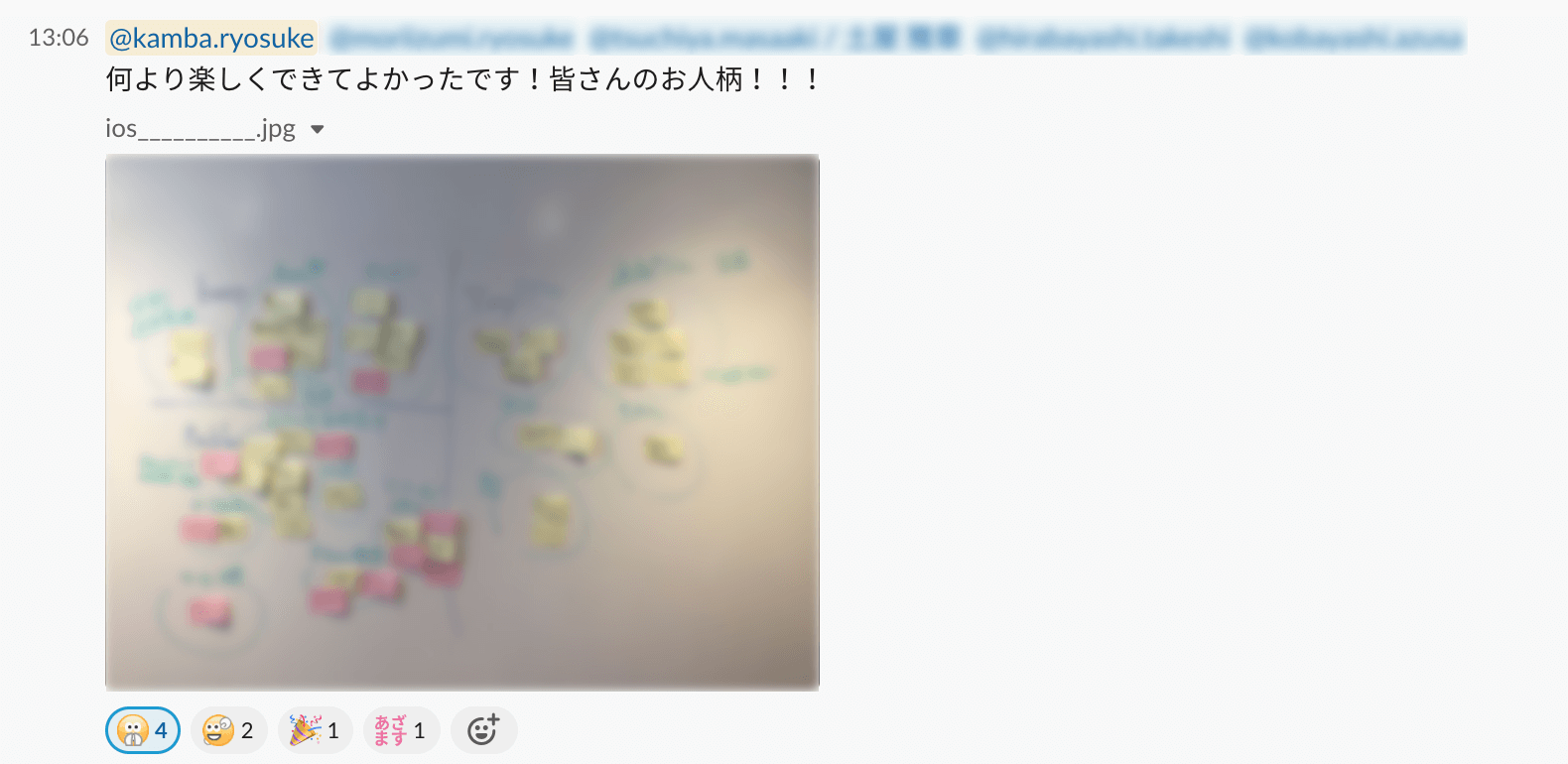
#1.データが一箇所に管理されていない
データが各サービスのDBにあったり、顧客管理システムにあったり、ローカルファイルにあったり、データが散らばった状態ではオンデマンドにデータを見ることができません。
事業スピードの低下や運用コストの増加に繋がります。
何より、確認するためのコストが高いと、担当者はデータを見なくなります。
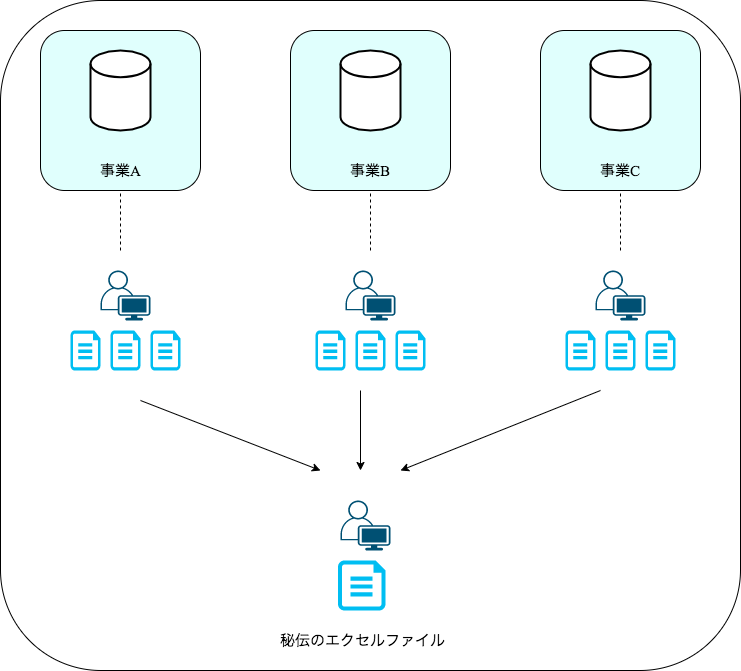
アンチパターンから学ぶ処方箋
データを一箇所に集約するためのデータ基盤を整える。
早い段階で、データを集約するためのデータ基盤の構築にリソースを投下します。
弊社の場合は、分析基盤としてBigQueryを利用しています(CRMとしてSalesforceも利用)
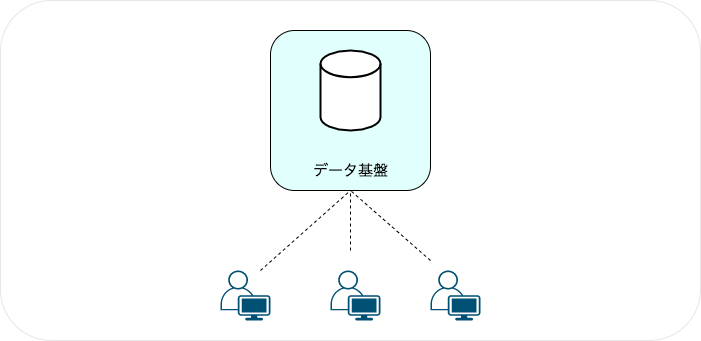
必要なデータを紐解き、機密情報を除外したうえでデータ基盤に集約をしています。
データをどのような構造で保持をするかが、カオスを未然に防ぐうえで重要となります。三層構造に役割を分けて、データを蓄積・加工・集計する形にしています。
このあたりは 「データ基盤の3分類と進化的データモデリング」 の記事がとても参考になります。
- Data Lake(元データ層)
- Data Warehouse(集約層)
- Data Mart(集計層)
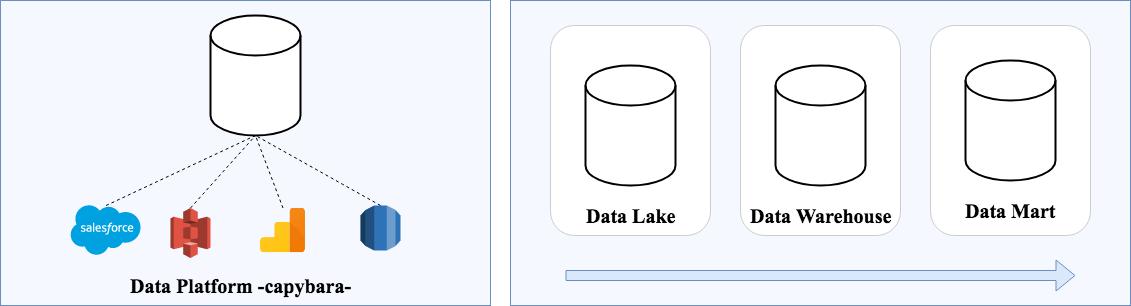
当初、分析ニーズが強かった基盤ですが、AIチーム立ち上げもあって、現在はML基盤としての役割も多くなりアーキテクチャを発展させています。
関連のありそうな記事
- ランサーズの分析基盤(capybara)と運用について紹介
- 実際に本番導入してみて分かった!ツラさから考える最強のMLデータパイプライン
- AIチームの立ち上げとこれから
- Google Analytics(GA)のデータをembulkを使ってBigQueryに転送させる方法
#2.同じユーザーがわからない。名寄せ問題
組織の成長とともに事業・サービス・人が増加してきます。
不確実性の高い新規事業はスピードが命なので、垂直に事業立ち上げをします。
はじめは、問題にはなりませんが一定のフェーズで次のような会話がよく起きます。
- A事業とB事業の両方を利用している企業を知りたい
- 全事業横断していろいろな指標で分析をしたい
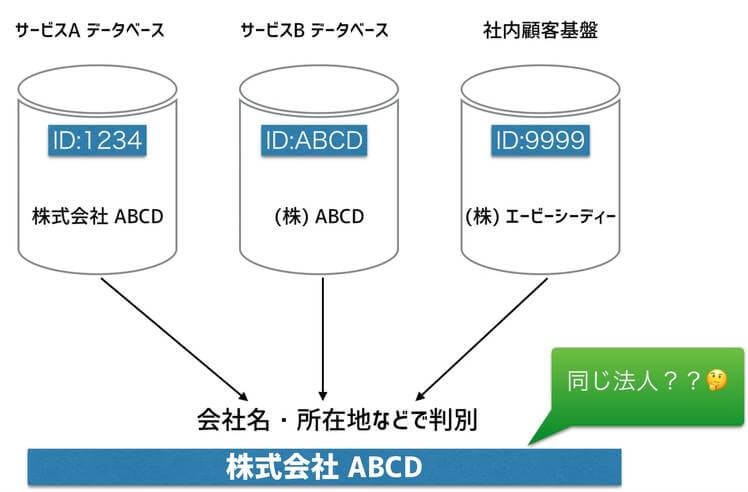
この時に問題になるのが異なるシステムで管理されている企業データの名寄せの問題です。システム単位に独自のIDでユーザーを管理されていることが多いと思います。
横断で確認したい場合は、例えばエクセルに集めて「社名」や「住所」などで名寄せを試みたりしますが、恐ろしくカロリーが高く精度も低いです。
Before*名寄せできていない世界*
アンチパターンから学ぶ処方箋
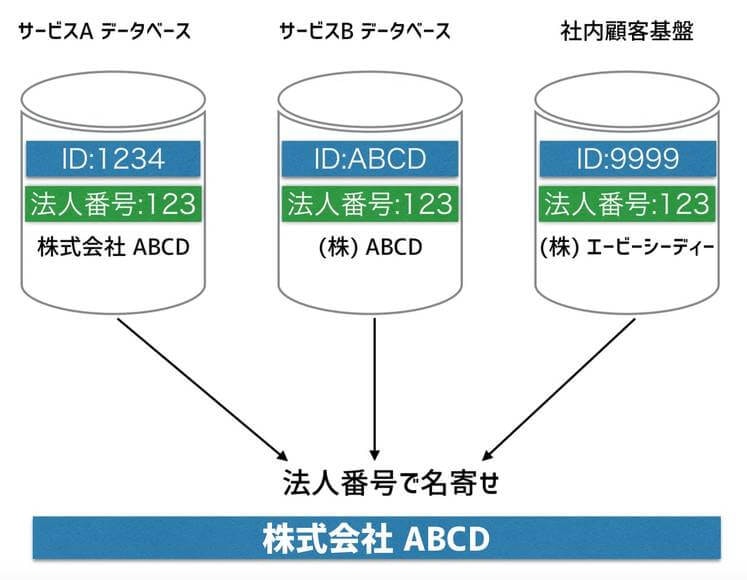
各データソースに対し、国税庁が管理する 「法人番号」 を付与しました。
国税庁が公開するAPIなどもあり、統一された番号を付与しておくことで、集計時の名寄せの精度向上やスケールが期待できます。
あらかじめ、オペレーションであったり、UIで「法人番号」の入力を促すことが出来ていると幸せになれそうです。
After*名寄せされた世界*
関連のありそうな記事
#3.LancersID連携
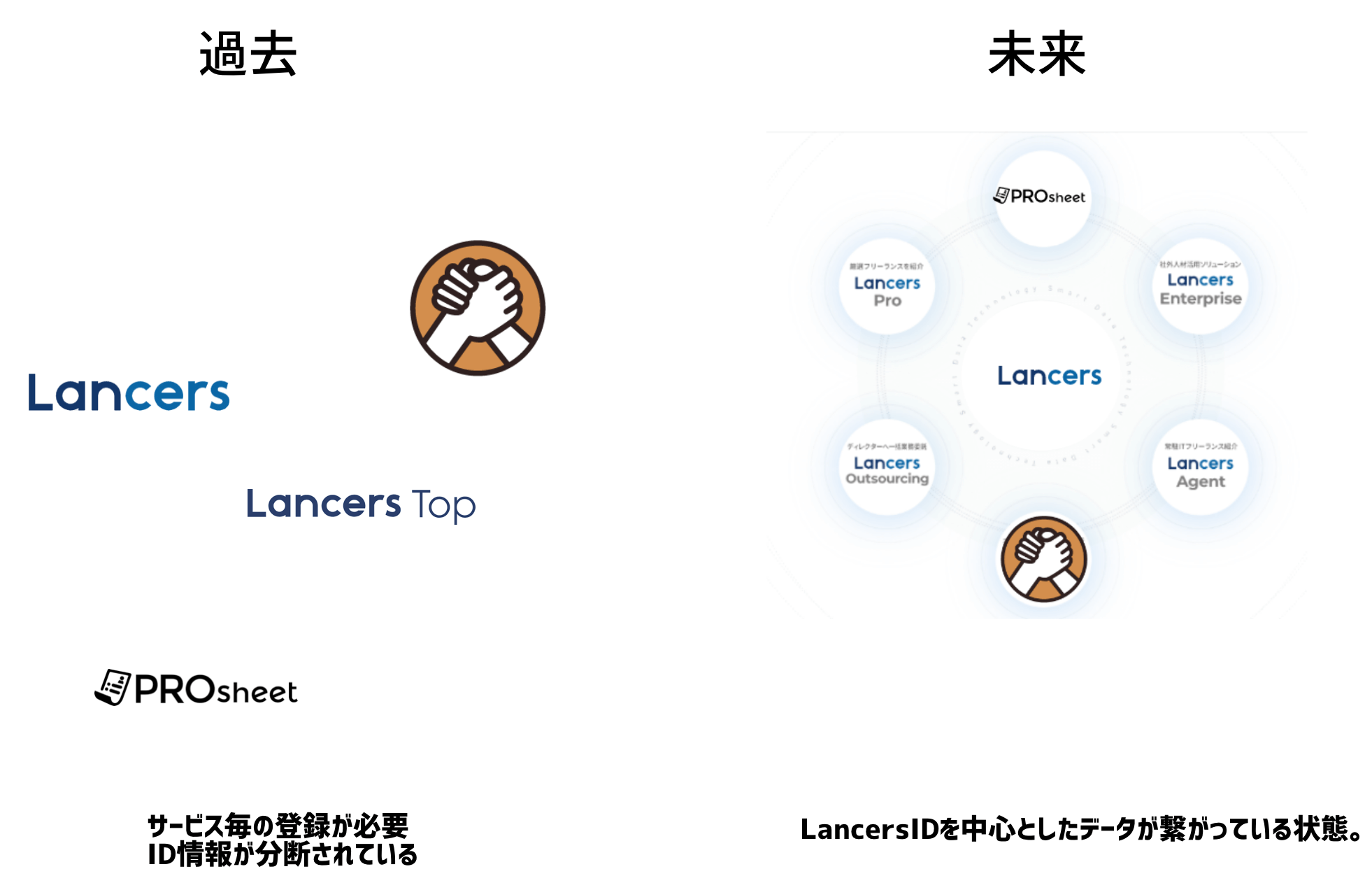
もともと、ランサーズは単体事業で1つのプロダクトでしたが、組織が成長していくにつれ複数プロダクトが立ち上がり、それぞれのデータが独立し分断された状態でした。
アンチパターンから学ぶ処方箋
まだ、一部プロダクトに限定し提供していますが LancersID を中心とした未来を目指しています。
OAuth 2.0 による認可の機能を提供することで、IDを紐づけ名寄せを実現しています。
#4.KPI定義難すぎる問題
例えば、売上を出したいと思っても、事業モデルが違えば集計方法は異なります。
また、リピート、チャーンなどといった定義も、もしかしたら事業ごとに基点とする項目が違い、異なるかもしれません。定義を確認し必要であれば整える必要があります。
そのためには、まず事業モデルを理解しデータを紐解き、様々な角度でKPIを分解し可視化していく必要があります。
エンジニアだけで行おうとすると、間違いなく未来は暗くなります。
* 流通金額、売上、チャーンレート...
* 日時、月次、四半期、年次...
* 方式別、カテゴリ別、クライアント別、事業別...
* 過去イレギュラー措置で作られたデータ達...
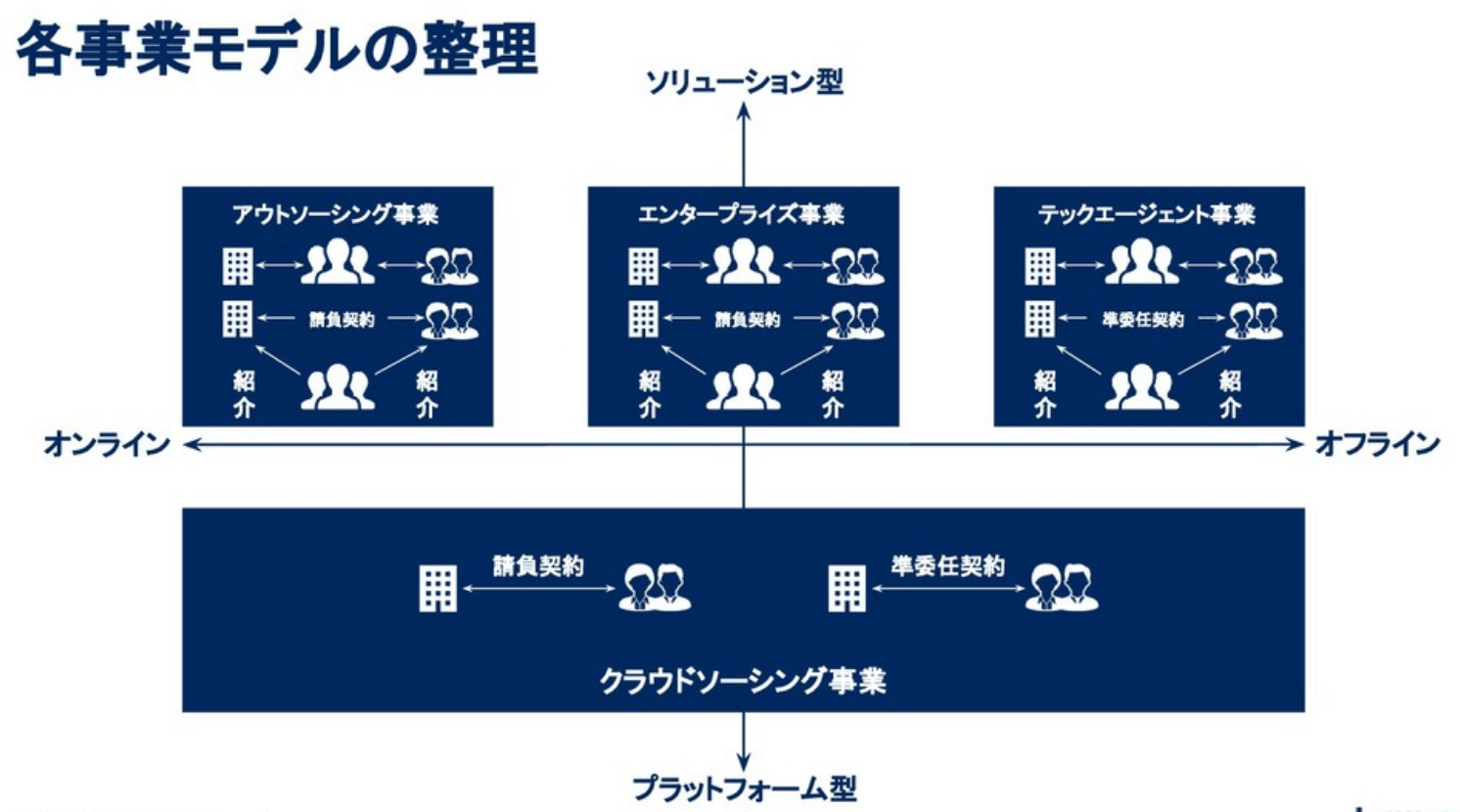
#4.アンチパターンから学ぶ処方箋
ステークホルダーを整理し巻き込む
横断プロジェクトでは、特にプロジェクトの初期段階で、ステークホルダーと事業構造を整理し、早い段階で周りを巻き込んで役割を整理することが重要です。
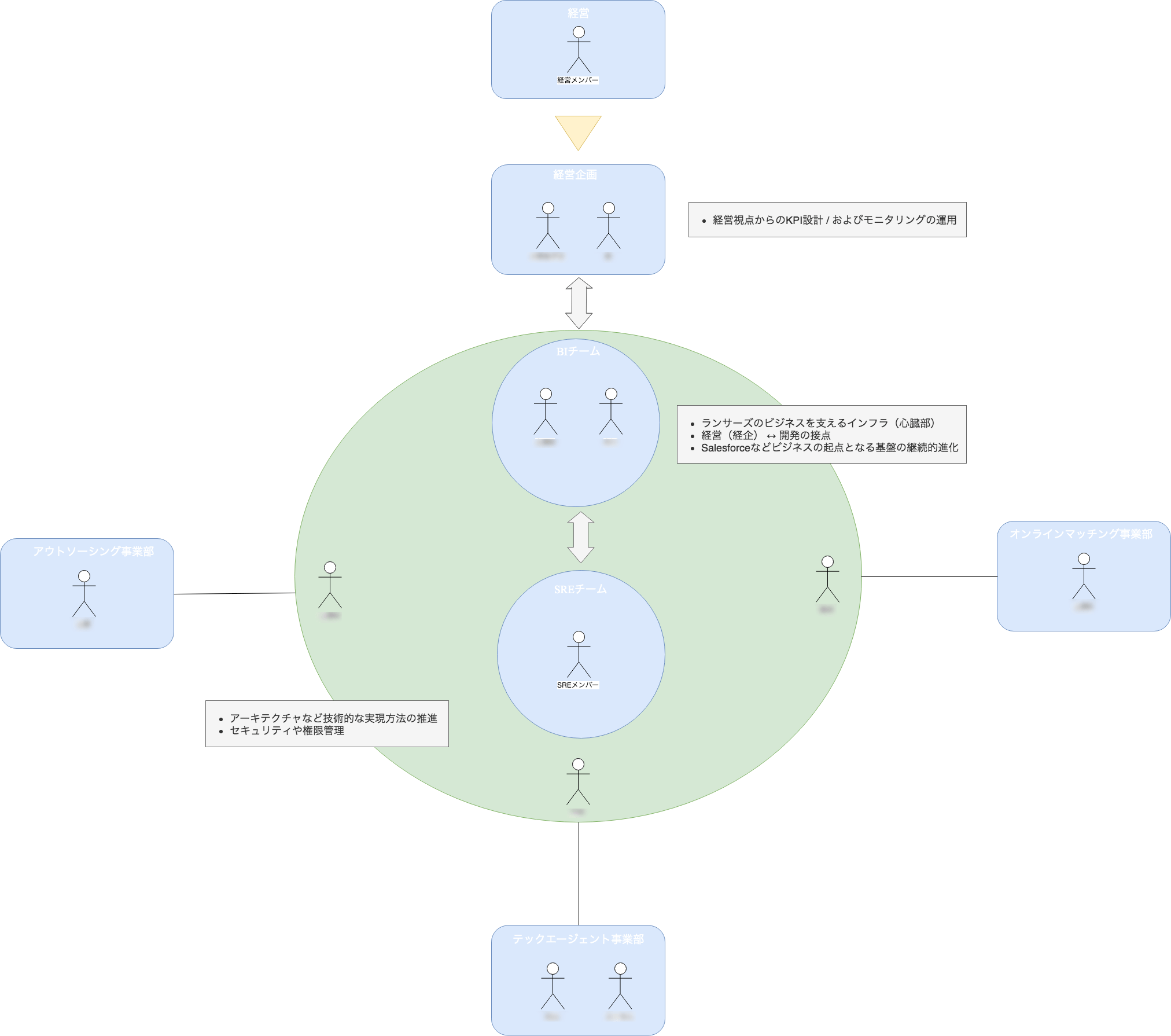
会社のフェーズや、組織によって最適解は異なりますが弊社の場合は以下のように役割整理しプロジェクトを進めました。
共通の目的を持ったワンチームで、それぞれの得意領域で役割分担できたことが最大の勝因と思っています。
実際にプロジェクトのキックオフで使用した資料
| 担当 | 役割 |
|---|---|
| 経営企画 | 会社としてモニタリングしたいKPIの要件定義 |
| BIチーム | 経営企画とエンジニアの窓口。全体のクエリの取りまとめ |
| SREチーム | データ基盤の運用、データのパイプラインの構築 |
| 事業エンジニア | 所属事業の事業構造を理解し必要なクエリを作る |
やりたかったけど、できなかったこと
エンジニア以外もGithubイシューで議論をする
バックオフィスメンバーとの議論をGithub Issue 利用を試みましたが、プロジェクト中盤からの導入はコストが高く断念しました。
次回は、初期にコミュニケーションラインを設計し改めてトライしてみようと思ってます。
まとめ
組織の成長にはデータドリブンな開発サイクルがとても大切です。
組織が成長してくると、横断しての依頼事項が突然増えてきます。早い段階で手を打ちましょう。
データの3種の神器、「データ基盤」「KPI定義」「意思決定・開発サイクル」を皆さんも手に入れてみてください。銀の弾丸はありませんがやれば確実に前進します。
最後までお読みいただき、ありがとうございました。
ランサーズでは 「個のエンパワーメント」 をミッションに、「テクノロジーによって誰もが自分らしく働ける社会をつくるため」 日本の働き方を本気で変えようとしています。
記事でもご紹介したように、まだまだレガシーな部分やあるべき姿に向けて解決したい課題が多くあります。課題を解決するのが好きな仲間とともに、我々も一歩ずつ歩んで行きたいと思います。
メリークリスマス🎅