ランサーズ AdventCalendar 22日目担当の @odrum428 です。
10 ~ 11月にかけてSage Maker上に構築した機械学習モデルを本番導入までをやりました。
そこからいろいろ実運用でのつらさが見えてきたので問題点の共有と
その一部を解決するためにMLデータマートを考えてみたという記事です。
MLOps周りをやっている方や取り組もうとしている方、特徴量管理、データの知見管理に悩んでいる方向けの記事です!
9月ごろにAIチームの立ち上げを行いました🌅
今までも機械学習を使った機能開発はありましたが、会社としてやっていき💪な機運だったのでチームとしてが立ち上がる運びとなりました。
チームについての詳細は以下の記事に書いたので、読んでもらえると嬉しいです!
AIチームの立ち上げとこれから
既存の機械学習機能は僕がちょこちょこ作ったものや、数年前に作られていたものだったので
過去機械学習周りをやっていた人はすでにいなくなっており、実際に手を動かすのは僕一人という状況でした。
最初のうちは手探り状態で、何が失敗かわからず、見えている領域も狭いので、とりあえず小さく運用してみて感覚と知見を得ることを目的にしました。
めでたく施策も決定し(ここの詰めが中途半端で痛い目見るのはまた別の話...)、どうやって導入するかを考え始めました。
サービス導入ににあたってのアーキテクチャ要件は以下を設定しました。
- *既存環境がAWSに寄っていたので、AWS上に構築する
- 一人での開発なので、なるべく意識することを減らしたい
- Jupyter Notebookでいい感じにデータ分析&モデリングできる
- なるべく身軽なアーキテクチャで本番導入したい
- コストはちょっとかかってもしゃーなし
こんな感じのをつくりました
上記を満たすのがSage Maker+Lambda+API Gatewayの構成でした。
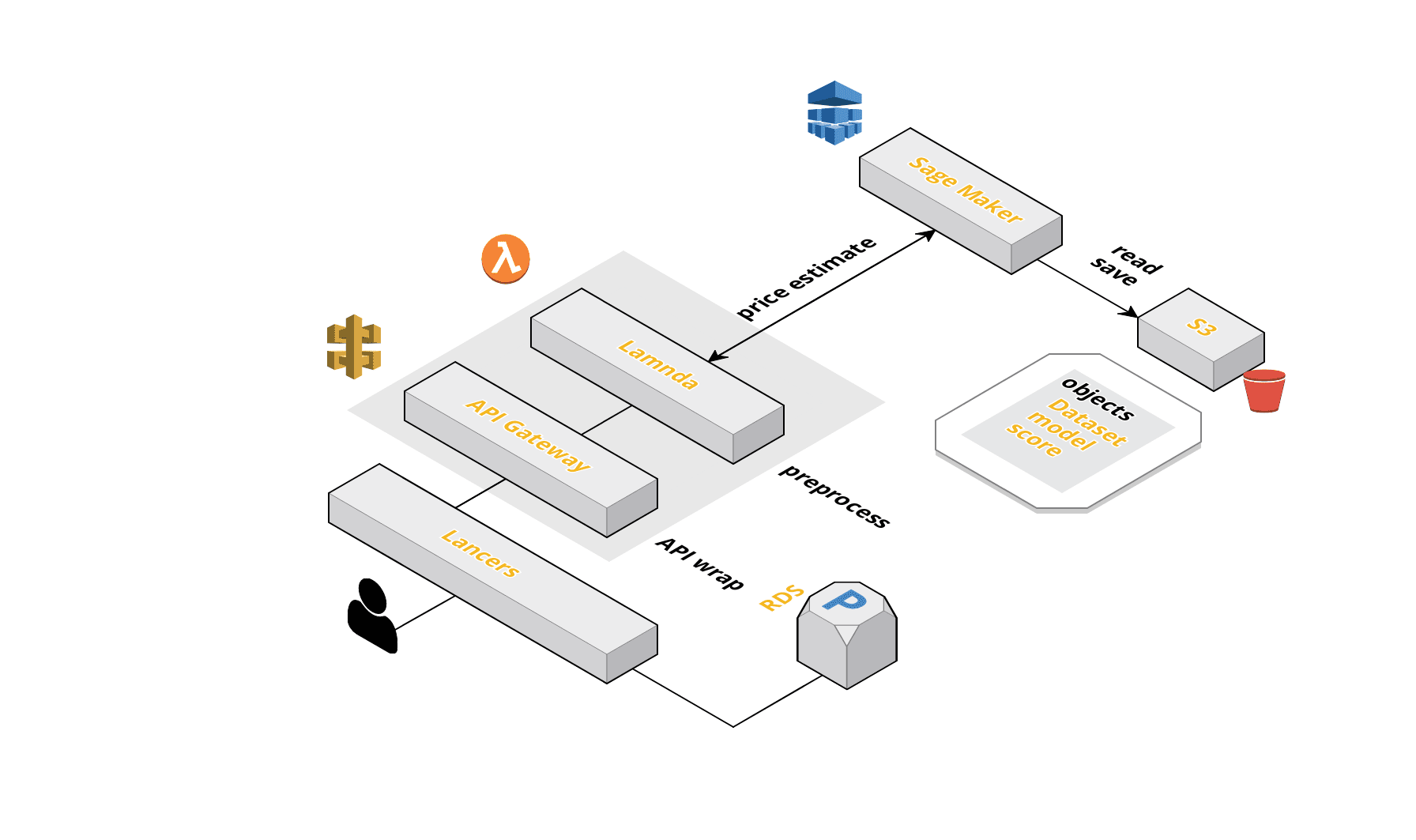
Sage MakerはAWSが提供するマネージドのML開発サービスです。
対応している範囲も広く、Juptyter Notebookを使ったデータ分析や、学習用コンテナの提供、作成したモデルのデプロイまでを一貫して行うことができるイカしたサービスです。
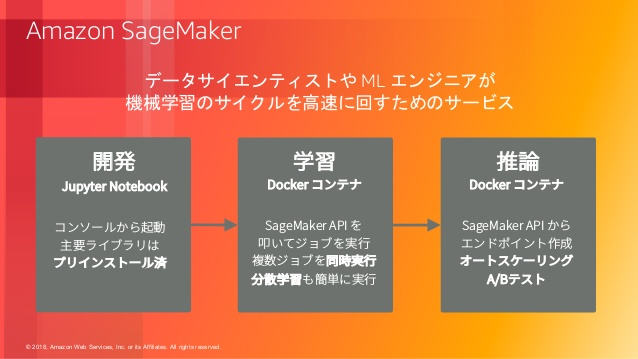
参考 : Amazon SageMaker を中心とした持続的な ML システム
このサービスは今回の要件にベストマッチしてました。ありがとうAmazonさん🎉。
Sage Makerを使うことでデータ分析や推論用エンドポイントの提供までを簡単に行うことができます。
あとは作成したエンドポイントを導入したいサービス側からSage Makerのエンドポイントを呼び出してやれば、推論を実行できます。
ただ、それだけではうまく動作せず、入力データをデータセット形式に加工する必要があります。
サービスと推論用エンドポイント間での依存関係を少なくしたかったので、Lambdaを使ってこれを実装しました。
エンドポイントがどこからでも叩けるのはちょっとまずいのでLambdaの前にAPI Gatewayを配置しました。
これによってエンドポイントのIP制限やデータ形式の制御などを行うことができます。
またこのような構成にしておくことでLambdaやSage Makerのエンドポイントを変更したい場合は、自由に置き換えることができます。
やってわかったツラみポイント
一ヶ月半ほどでサービスへの導入が完了したのですが、当初の目的どおりやってみないとわからないツラさがいろいろ出てきました。
データを手動で持ってこないといけない
弊社ではありがたいことにいい感じのDHWが以下のような構成で構築されていました。
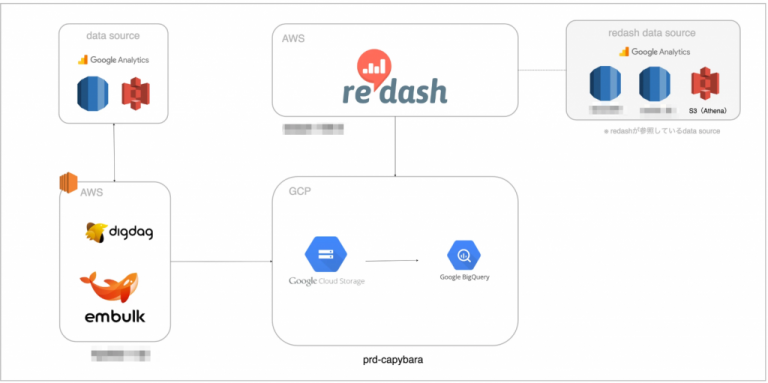
参考 : ランサーズの分析基盤(capybara)と運用について紹介
Sage MakerはS3に配置されたデータセットをデータソースとして参照することが出来ます。
Sage MakerのJuptyter Notebook上でモデル開発を行うには、Big Queryに構築されているDWHからS3に持ってくる必要がありました。
少し頑張れば、Big Queryのデータをいい感じに持ってこれるような機能を作ることは出来ます。
しかし、そもそも作るのが面倒なのとスピードを早くする目的から一旦手動でのデータ転送を選択しました。
目的のデータセットを抽出するクエリをRedashで書いて、CSVでダウンロードしてS3に配置するみたいなことをやってました。
データ分析や特徴量解析やっているときに、別のデータ要素が欲しくなったら、Redashのクエリを書き直して、手動でS3に配置する必要がありました。これが結構めんどくさかったです。
ここからちゃんと自動でデータセットが更新される仕組みと直接データにアクセスできる環境が必要だと思いました。
テストができない
Sage Makerはデータの前処理から学習、デプロイまでを行うことができて非常に便利です。
しかし、僕は単一のJupyter Notebookですべての処理を行っていました。
ただやはり、記述されているコードにテストがないのはすごく不安です。
pytest-ipynbなどをJupyter Notebookでテストを行うこともできましたが、一時しのぎにしかならず、本質的じゃないと思ったのでやめました。
ここから前処理部分などのテストをちゃんと行うようにしたいと思いました。
レビューしにくい
上記の通り、単一のJupyter Notebookに前処理からデプロイまでを書いていたので、かなりレビューがしにくかったと思います。
(レビューして頂いた各位ありがとうございました)
import部分でさえこんな感じです。
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"import math\n",
"import numpy as np\n",
"import boto3\n",
"import pandas as pd\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np \n",
"from io import StringIO\n",
"import seaborn as sns\n",
"import sagemaker\n",
"from pytz import timezone\n",
"from datetime import datetime\n",
"\n",
"sagemaker_session = sagemaker.Session()\n",
"\n",
"%matplotlib inline"
]
},
一応Python形式でもExportしていましたが、大きい単一ファイルだったので可読性は低かったです。
またSage Makerは以下のような複数のコンテナ環境でモデルのデプロイまでを行います。
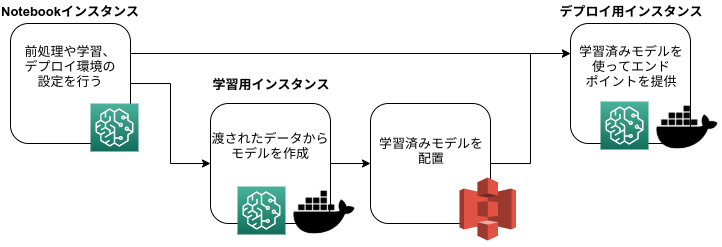
このような一連の流れから、学習用コンテナの設定部分やデプロイ周りの設定もNotebookで行いました。
これには使用するDocker Imageの指定やインスタンスタイプの設定、インスタンスに渡すハイパーパラメータの設定などが含まれます。
この部分の記述はSage Maker特有の知識が含まれ、レビューするのにも勉強する必要がありました。
ここから小さいスクリプトの集合で処理や設定を定義したいと思いました。
データや特徴量の知見が貯まらない
単一のJupyter Notebookではデータの知見がその中に閉じてしまい、なぜその特徴量を使ったのかを体系的に共有できないと感じました。
なんでそのデータを使ったのか、なぜそのような特徴量変換を行ったのか、その分析で使わなかったデータはどういう傾向があるのかなどが失われてしまっていました。
なるべくコメントを残すようにしましたが、それでもどうしてもわからなくなってしまいます。
きちんとドキュメントを書けばいいのではと思いましたが、そういうドキュメントは往々にして手が行き届かなくなっていくと思っています。
ここからなるべくコードに近いところでドキュメントを管理し、レビューを通すようにすればいいのではと思いました。
MLデータパイプラインを作ろう
上記の問題を解決するためにアーキテクチャの改善を行うことにしました。
まずは一番ツラさが存在するデータ取得部分と前処理部分の改善を行うことにします。
どういう風に直していくかを考えてみます。
データ取得部分の問題は、モデリングまでの環境(学習済みモデルを作成する部分まで)をGCPに変更することにします。
こうすることでDWHが構築されているBig Queryから直接データをとってこれるようにします。
GCPにはAI PlatformというML開発サービスが存在するので、これを使うことにしました。
前処理部分の問題は前処理ををスクリプトとして切り出し、それを使ってデータを特徴量に加工するデータパイプラインを構築することにしました。スクリプトとして切り出すことで、それぞれに対してちゃんとテストを書くことができるようになります。
また、それぞれに対してDoc Stringにデータの知見をきちんと書き、それをShpinxを使って静的ページとして公開することで知見が共有できるようになると思いました。
あとは個別に前処理したデータをBig Query上に戻し、MLデータマートとして扱うことで次回モデリング時にそこからデータ使うことができるので、無駄な計算を行う必要もなくなります。データパイプラインを使って定期的に処理を実行させるようにすることで、特徴量の更新を行うことができます。
まとめると、上記の問題を解決するためにはBig Query上にMLデータマートを作ってやればデータ取得から前処理までの問題は解決することができ、さらに大きなメリットが発生することがわかりました。
データマートなどの説明はゆずたそさんの記事が詳しいので以下に貼っておきます。
データ基盤の3分類と進化的データモデリング #DPCT / 20190213
MLデータマートの構築にあたって、アーキテクチャの構成には以下の要件を設定しました。
- ワークフローのDAGを柔軟にかけること
- モデルが増えても対応できるようにする
- アドホックな処理に耐えられるようにする
- コストをなるべくかけないようにしたい
- 社内に知見があるようなツール
- スケジュールリングを簡単に行うことができる
- エラーハンドリングを簡単に行うことができる
最終的にはこうなりました
様々なツールを検討・比較しましたが、最終的にはDigdag+Embulk+Fargateの構成 になりました。
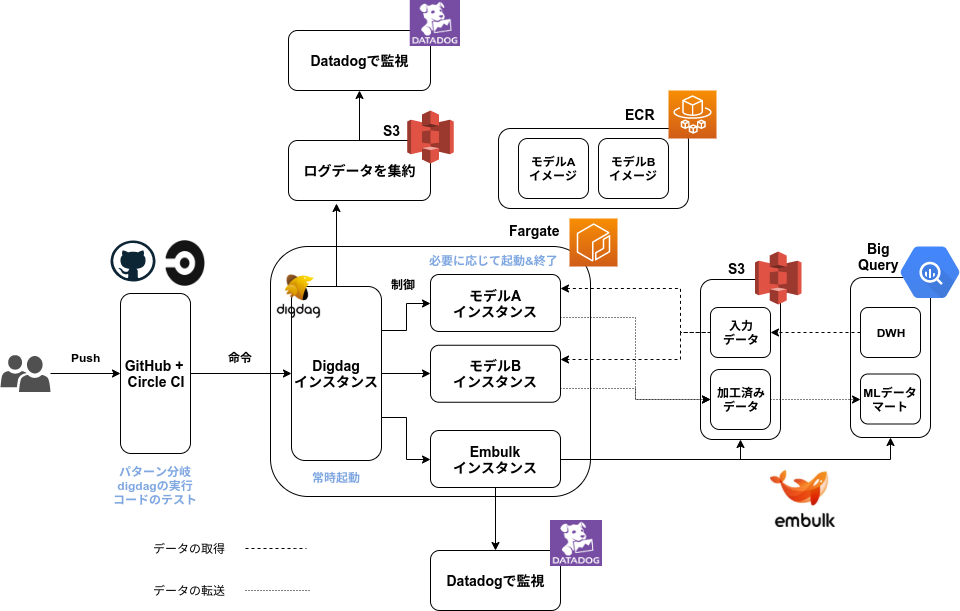
命令部分について
ワークフローやスクリプトの更新をCircle CIで監視し、更新内容によって実行するワークフローの分岐を行います。
その命令はFargate内で常時起動しているDigdagに渡されます。
このインスタンスはワークフローの実行だけを担うので、比較的サイズの小さいインスタンスで実行させることができます。
実行させる処理の制御やDAG構築、インスタンスの起動&終了、GUIからの再実行、エラー時のリトライ処理などをこのDigdagが担保します。
処理部分について
CircleCIからの命令を常時起動のDigdagが受けて、API経由でFargateインスタンスを立ち上げます。
これらはモデルごとにDockerイメージをECRに登録しておき、それをベースに構築されます。
データ加工を行うインスタンスは処理だけに役割を絞ることで、粗結合な仕組みにすることができます。
行う処理内容から比較的大きなサイズのインスタンスを指定してやります。
データ転送部分について
今回の構成ではBig Query ~ S3間のデータ転送部分をEmbulkコンテナに切り出しています。データ
こうすることで各モデルのワーカーインスタンスは処理だけに特化させることができるようになり、コンテナ内部での依存関係とイメージサイズをなるべく小さくすることができます。
各モデルのワーカーコンテナについてはS3のデータを用いて処理を行い、加工が終わったものをS3に戻すようなフローを組んでいます。すべてのデータ加工が完了したら、S3の加工済みデータをEmbulkコンテナがBig Queryに格納することでデータマートにデータが溜まっていきます。
監視部分について
監視はDatadogを使って行います。
Datadogにデータの加工処理で発生する負荷のモニタリングや、エラー検知、ログの可視化などを任せます。
Fargateから直接参照させることできないので、Digdagの実行ログをS3に吐き出し、それをS3に参照させます。
各モデルのワーカーインスタンスはCPUやメモリの負荷についてもDatadogを使って監視することにします。
コスト部分について
この構成だと、比較的重い処理も必要最低限のコストで実行することができます。
常時起動なのは比較的サイズの小さいDigdagだけで、必要に応じて各モデルのワーカーインスタンスを適切なサイズで起動させます。処理が終わればdigdagインスタンスが終了命令を出してくれるので大きなサイズのインスタンスを使用しても、コストがかからないような設計になっています。
この仕組みだと機械学習モデルごとにDocker imageを定義してやればいくらでも拡張することができます。
まだまだ見えてない部分は多いですが、上記の問題は解消されるようなアーキテクチャになっています。
MLデータマートの使用ワークフロー
上記を使用したモデリングのワークフローを示します。
- DWHからデータを持ってきてGCP上でデータ分析やモデリングを行う
MLデータマート部分
2. 必要な変換や処理が決まったら、それを個別のスクリプトに分解する
3. スクリプトをDigdagのタスクに落とし込む
4. スクリプトのテストと解説を書く
5. GitHubにPush
6. CircleCIで実行するワークフローを指定
7. Digdagがデータ変換処理を行なってMLデータマートに格納
MLデータマート部分終了
- モデリング部分のコードはデータとMLデータマートから呼び出すように修正
- モデル作成 & デプロイ
- サービスとMLエンドポイントの前処理は定義したタスクを使ってストリーム処理
- Doc StringをSphinxを使って静的なページにする+どこかでホスティング
- Digdagが定期的にデータマートを最新の状態に更新
- MLデータマートの特徴量を使って次のモデルを開発
Q&A (&Q)
Q. なんでデータパイプラインをAWS上に構築したの?無駄じゃない?
A. 既存との繋げ込みと運用実績からAWS上に構築しました
最初はCGPのCloud Composer+Dataflowを使って構築しようとしていました。
GCP Composer&Dataflowの構成やData Fusionを使った構成、GCP上にDigdag+embulkでパイプラインを作るなどいろいろな構成を考えました。どの構成も運用経験がなく、問題の発生予想が不透明だったのとそれなりに複雑なので覚えないといけないこと一杯で会社的にちょっときつかったです。
どれも採用には一歩足りず、既存でDHWへのデータ転送をdigdag+embulkでやっていたり、チームにAWS運用の知見が溜まっていたのでAWS上での構築を選択しました。
Q. なんでEmbulkコンテナ切り出したの?
A. 機械学習モデルをなるべくシンプルにしたかったから。
このイメージは学習環境やデプロイ環境にも使うので、余計な部分が増えてボリュームが大きくなるのが嫌でした。
またdigdagのアップデートやプラグインを追加したいときに、個別に分散していると移行作業が面倒になると予想しました。
まとめて置くことでバージョンアップ等が楽になり、プラグインも一括管理できます。
Q. 前処理部もデータパイプラインで定義したスクリプト使いたい。
この記事を読んでいるみなさんへの質問です。
サービス ~ エンドポイント間に存在する前処理部分(Sage Maker時代の運用例だとLambda)って今回作ったMLデータマートと全く同じ処理をするんですよ。同じこと二度かくのは面倒だし、ダサいのでこれも同じスクリプトを使っていい感じに処理できるようにしたいと思っています。
バッチ処理は上記の構成で満たしているので、ストリーム処理をいい感じにできるようにしたいです。
僕が考えているのは、Lambdaを使って実現する方法です。
Digdagで定義されているスクリプトをいい感じにPythonパッケージにして(どうやればいいのかはよくわからん)、Zip形式で固めたものをLambda Layerに定義してやります。
このパッケージをLambdaで呼び出して、前処理を定義してやればよいのではと思っています。
が、ベストではないので、もしよければ、アドバイスもらえると嬉しいです。
まとめ
以上、見えている範囲で僕が考えた最強のMLデータマートの話でした。
今回改善できた部分はデータ取得 ~ 前処理部分だけなので、次はモデルのデプロイ周りやA/Bテスト環境を整えようと思います。Sage Makerは個人的にとても良いツールだと思っているので、そこからエッセンスを学びつつ、開発できたらと思います。
※ヴァイオレット・エヴァーガーデン見ながらこの記事を書いたのですが、良すぎて全く手が進みませんでした😢。今年見た中で一番良かった作品でした。みなさんも見てみてください。