この投稿は、 Go アドベントカレンダーの 6日目のものになります。
はじめに
GoでYAMLを扱う際にデファクトになっているのは、おそらく github.com/go-yaml/yaml でしょう。
実装はC言語で実装された libyaml を Go に移植しつつ、 Go ならではの機能を足す作りになっているのですが、 cgo を使わずに pure Go で移植されており、開発者の気合を感じます。
枯れている libyaml を利用していることからも、 YAML の仕様を忠実に実装していることが期待できます。
ですが、このライブラリにはいくつか使いにくい点もあり、例えば以下のようなことはできませんでした
- 構造体を埋め込む場合に、埋め込む型をポインタで定義できない ( ※ ポインタなしは大丈夫 )
-
encoding/jsonとコンパチの インターフェース (MarshalYAML() ([]byte, error)/UnmarshalYAML([]byte) error) が使えない -
YAMLの アンカー・エイリアス を書き出し時に利用できない
加えて、個人的にはライブラリの中で panic , recover なコードが書かれていたり、よくも悪くもC言語の書き方を忠実に移植していることから Go っぽい書き方になっていないところが気になります。
そこで他に有名なライブラリを探してみると、 github.com/ghodss/yaml に辿り着くことでしょう。
このライブラリは YAML ライブラリという立場ながらも JSON フレンドリーに設計されており、 中でも YAML の エンコード・デコードのために encoding/json の エンコード・デコード処理を経由している ところが面白いところで、これによって裏で利用している go-yaml/yaml の埋め込みまわりの挙動を改善することができていたりするわけなのですが、まあ正直本来しなくて良い処理な感はあるのに加え、結局のところ go-yaml/yaml を利用しているんだなという感想を持ちました。
Go では現在、上で挙げた 2つのライブラリがほとんどのプロジェクトで採用されており、 ghodss/yaml も中で go-yaml/yaml を使っていることから、実質 YAML の解釈部分にはすべて go-yaml/yaml の実装が使われているという現状があります。
というわけで、何か YAML まわりで不満があった場合は go-yaml/yaml に PR を投げるのが正攻法になるのですが
- 自分が感じた アンカー・エイリアスまわりの改修や
MarshalYAML/UnmarshalYAMLのインターフェースを変えて欲しいなどの要求がすんなり通ることもないだろうこと - 個人的に
YAMLを扱うライブラリに期待したいことが他にもいくつかあったこと
-
YAMLファイルに syntax error があったときに、該当のエラー箇所をソースコード付きでココだよ!って教えて欲しい -
YAMLの内容をデコードする際、アプリケーションが期待する値と異なる値だったら、バリデーションエラーと同時にここが違う!ってソースコード付きで教えて欲しい -
YAMLライブラリ内部で利用しているLexerやParserの API を外から触れると便利そう -
YAMLには他のYAMLファイルを読み込む仕様がないので、定義を複数のファイルに分割して書いたりすると、 アンカーを使い回せないのをなんとかして欲しい
- 過去に Perl5 を含めいくつかプログラミング言語のパーサーを書いたことがあり、パーサー実装の知見がある程度あったこと
もあり、自作してみることにしました。
やるからには go-yaml/yaml を超えるものを作るぞ!と意気込み、パーサーを開発するときは yacc , bison なパーサージェネレータを使わずに書きたい変なポリシーがあるので、 YAML の仕様を見ながらガリガリとスクラッチから書き始め (特に他の YAML パーサーの実装を読むようなこともしていないので、完全に独自のやり方になっています )、仕事の合間をぬって大体 1 ~ 2週間ほどで大枠を作りました。その後もう2週間ほどかけてバグ修正や機能改修を行って完成度を上げて今に至ります。
開発したライブラリは github.com/goccy/go-yaml で公開しています。ぜひ利用してみてください。
この記事では、開発した上記の YAML ライブラリの紹介をしつつ、他ではなかなか見る機会の少ない YAML パーサをスクラッチから設計・実装した上で気づいた話を余力のある限りでしていこうと思います。
ライブラリの紹介

1. go-yaml/yaml とコンパチのインターフェース
自分では go-yaml/yaml を超えるものを作ったと思っていても、すでに go-yaml/yaml で動作しているプロジェクトで自分のライブラリを使ってもらえるようにするのは簡単ではないと思っています。
そこで、 go-yaml/yaml から goccy/go-yaml へ移行するためのコストが最小限になるよう設計しました。
具体的には、 go-yaml/yaml (※v2 まで) とコンパチのインターフェースを実装しているので、移行にあたって障壁となりそうな MarshalYAML() (interface{}, error) や UnmarshalYAML(unmarshal func(interface{})error) error を実装した箇所を修正することなく、 import 先を gopkg.in/yaml.v2 から github.com/goccy/go-yaml に切り替えるだけで利用できる ようにしています。
( ※ go-yaml/yaml で順序指定マッピングを実現するために必要な yaml.MapItem や yaml.MapSlice も実装しているので、 MarshalYAML や UnmarshalYAML の中身も修正する必要がないようになっています )
いやいや、自分のプロジェクトでは github.com/go-yaml/yaml じゃなくて github.com/ghodss/yaml を使っているから、構造体のタグは yaml じゃなくて json を期待しているんだよーといった場合も安心してください。
開発したライブラリでは yaml タグの他に json タグもサポートしているので、タグを置き換えることなく移行することができます。 ( ※ yaml タグと json タグの両方が定義されている場合は yaml タグを優先して解釈するようになっています )
2. encoding/json とコンパチのインターフェース
開発に協力してくださった @lestrrat さんが https://medium.com/@lestrrat/3-reasons-to-use-github-com-goccy54-go-yaml-to-handle-yaml-in-go-5ccfd662191f で言及してくれているのですが、おそらく go-yaml/yaml で MarshalYAML / UnmarshalYAML を実装しようとしたことがある方は、一度はそのインターフェースに面食らうのではないでしょうか。
encoding/json のインターフェース
MarshalJSON() ([]byte, error)
UnmarshalJSON([]byte) error
に慣れていた自分は最初に
MarshalYAML() (interface{}, error)
UnmarshalYAML(func(interface{})error) error
を見たとき、どうやってデコードするんだ!?と思った記憶があります。
( どうして go-yaml/yaml がこのようなインターフェースになっているかは、自分でライブラリを実装してみてなるほどと気づいたわけなのですが、それは後ほど紹介したいと思います )
理由があるとはいえ、インターフェースが異なることによる不都合もあり、参照先の記事で触れられていますが JSON や YAML を設定ファイルとして同列に扱うライブラリを開発する際、これらのインターフェースを下記のように透過的に扱いたいケースに対応できなくなってしまいます。
var marshaler func() ([]byte, error)
switch ext {
case ".json":
marshaler = json.MarshalJSON
case ".yaml":
marshaler = yaml.MarshalYAML
}
実を言うと、実装前は encoding/json とコンパチのインターフェースで作るつもりだったのですが、実装中に go-yaml/yaml の設計意図に気づき、やっぱり go-yaml/yaml と同じでいくかと思い直してそちらで実装したのですが、 @lestrrat さんに上記のようなことができないがために go-yaml/yaml を YAML ライブラリとして選定できていないというようなことを教えていただき、急遽 encoding/json とコンパチの
MarshalYAML() ([]byte, error)
UnmarshalYAML([]byte) error
も追加で実装したという経緯があります。
もうひとつ encoding/json と同じインターフェースで実装するメリットだと自分が思うのは
UnmarshalYAML([]byte) error の引数の部分で、このインターフェースにすることによって 「 YAML ドキュメント中のどの部分を対象にデコードしようとしているか」というスコープが明確になるので、ライブラリを利用する側にとってデバッグしやすくなると考えています。
3. ソースコード付きのエラー出力
例えば以下のような YAML として不正な文字列をライブラリに渡すと
---
- a
b: c
go-yaml/yaml では以下のようなエラーが出ます
yaml: line 3: mapping values are not allowed in this context
これに対して、 開発したライブラリでは 以下のようなエラー出力をカスタマイズする機能を提供しており
func FormatError(e error, colored, inclSource bool) string
下記のように エラー個所とその理由とともに、該当箇所のソースコードを色付き表示できる機能を追加しました。
fmt.Println(yaml.FormatError(err, true, true))

( まだ go-yaml/yaml に比べてエラーメッセージが親切でなかったりするケースがあるとは思うのですが、
気になった場合は Issue を挙げていただければ随時対応させていただこうと思っています )
ただ実際には上記のように YAML として不正な文字列を与えられるケースはそう多くはなく、
ほとんどが YAML で書かれた設定値を受け取ったライブラリ側で、値をバリデーションした際に生じたエラーをイイ感じに出力したいというケースだと思います。 そこで開発したライブラリでは、以下に示すような書き方をすることでバリデーションエラーを綺麗に出力する機能を持っています。
package main
import (
"fmt"
"strings"
"github.com/goccy/go-yaml"
"gopkg.in/go-playground/validator.v9"
)
type Person struct {
Name string `validate:"required"`
Age int `validate:"gte=0,lt=120"`
}
func main() {
yml := `---
- name: john
age: 20
- name: tom
age: -1
- name: ken
age: 10
`
validate := validator.New()
dec := yaml.NewDecoder(
strings.NewReader(yml),
yaml.Validator(validate),
)
var v []*Person
err := dec.Decode(&v)
fmt.Println(yaml.FormatError(err, true, true))
}
gopkg.in/go-playground/validator.v9 を使ってバリデーション処理を記述した後、
yaml.Decoder を初期化する際に validate インスタンスを yaml.Validator(validate) で
YAML ライブラリ側へ渡しています。
この状態でデコードをおこなうと、以下のようなエラー出力が得られます。

gopkg.in/go-playground/validator.v9 で出力されたエラーに加えて、どの値でエラーが起こったのかをソースコードと共に出力してくれます。これは読み込み対象の YAML ドキュメントの構造が複雑だったり量が多いほど効いてくると思っています。
ただ、この方法だと gopkg.in/go-playground/validator.v9 で出力されているエラーの部分 ( Key: 'Person.Age' Error:Field validation for 'Age' failed on the 'gte' tag のところ ) をカスタマイズすることができないため、これをどのように変更可能にするのが良いか考えているところです。
もしこの機能を利用して頂いている方で上記の点を含め使いにくい箇所があれば、遠慮なく報告していただければと思います。
4. アンカー・エイリアスを利用した YAML の書き出し
YAML には アンカーとエイリアスという変数定義とその参照を行えるような機能がありますが、
go-yaml/yaml では YAML 読み込み時にはこれらを解釈して読み込んでくれるものの、書き出しには対応していません。
せっかく YAML は仕様として DRY に書く方法を提供してくれているのに、ライブラリ側がそれを利用せずに書き出してしまうのです。これは同じ設定値を多数再利用するような YAML ファイルを作成したいと思ったときに困り、自分は今までこれを text/template を使ってテンプレート経由で生成することで対処していました。
ただこれは明らかに悪手なので、できれば YAML ライブラリ側で アンカー・エイリアス を残した状態で書き出して欲しいところです。( これができないと例えば、ある YAML ファイルを読み込んでプログラム側で何か値を書き換えた後、もとのファイルを上書きするようなことを実現したいときに、書き出す際には YAML ライブラリ経由で出力した結果ではなく text/template などを利用して出力した結果を使わなければいけないことになります )
そこで開発したライブラリでは、新しく anchor と alias というタグを設定できるようにすることでこれを解決しています。
例えば以下のように指定すると、 v.A を &x として、 v.B を *x として書き出します。
package main
import (
"bytes"
"fmt"
"github.com/goccy/go-yaml"
)
func main() {
type T struct {
A int
B string
}
var v struct {
A *T `yaml:"a,anchor=x"` // a というキーに対応する値に x というアンカー名を設定する
B *T `yaml:"b,alias=x"` // b というキーに対応する値は x のエイリアスとして提供する
}
v.A = &T{A: 1, B: "hello"}
v.B = v.A
var buf bytes.Buffer
yaml.NewEncoder(&buf).Encode(v)
fmt.Println(buf.String())
}
出力結果は以下のようになります
a: &x
a: 1
b: hello
b: *x
anchor と alias に設定する名前は省略可能で、省略すると anchor の場合はその構造体のフィールド名の lower_case が使われ、 alias の名前は参照しているポインタのアドレスを見て決定されます。
例えば以下のようなケースでは
package main
import (
"bytes"
"fmt"
"github.com/goccy/go-yaml"
)
func main() {
type T struct {
I int
S string
}
var v struct {
A *T `yaml:"a,anchor"`
B *T `yaml:"b,anchor"`
C *T `yaml:"c,alias"`
D *T `yaml:"d,alias"`
}
v.A = &T{I: 1, S: "hello"}
v.B = &T{I: 2, S: "world"}
v.C = v.A
v.D = v.B
var buf bytes.Buffer
yaml.NewEncoder(&buf).Encode(v)
fmt.Println(buf.String())
}
v.A と v.B に anchor タグが設定されていますが、名前を指定していないので、それぞれキー名と同じ a と b が使われます。
また、 v.C と v.D には alias タグが設定されていますが、名前を指定していないので v.C と v.D に代入されているポインタのアドレスを見て決定されます。
この場合は v.C に v.A のアドレスが入っているので、 v.A の参照だと判断し、 c: *a を書き出します。同様に v.D には v.B のアドレスが入っているので、 d: *b を書き出します。
つまり出力結果は以下のようになります。
a: &a
i: 1
s: hello
b: &b
i: 2
s: world
c: *a
d: *b
名前を指定しない上記のような書き方は、一見すると使いどころがわからなかったかもしれませんが、
都度参照する対象のアンカー名が変わるような YAML を生成したい場合は、 alias 名を省略することによって自動的に最適な構造で書き出してくれるメリットがあります。
加えて、 YAML には << で定義される MergeKey という特殊なキーがあり、
このキーに対応する値をインライン展開しつつ、そこに定義されてある値と適宜マージしてくれる機能があります。
a: &a
hello: 1
b:
<<: *a
world: 2
上記の b に対応する値は
b:
hello: 1
world: 2
と書いているのと同じ状態です。
開発したライブラリでは、この MergeKey を用いた出力にも対応しており、
より DRY な YAML を出力することが可能になっています。
package main
import (
"bytes"
"fmt"
"github.com/goccy/go-yaml"
)
func main() {
type Person struct {
*Person `yaml:",omitempty,inline,alias"`
Name string `yaml:",omitempty"`
Age int `yaml:",omitempty"`
}
defaultPerson := &Person{
Name: "John Smith",
Age: 20,
}
people := []*Person{
{
Person: defaultPerson,
Name: "Ken",
Age: 10,
},
{
Person: defaultPerson,
},
}
var doc struct {
Default *Person `yaml:"default,anchor"`
People []*Person `yaml:"people"`
}
doc.Default = defaultPerson
doc.People = people
var buf bytes.Buffer
yaml.NewEncoder(&buf).Encode(doc)
fmt.Println(buf.String())
}
MergeKey を利用した書き出し機能は、構造体埋め込みによって実現しています。
type Person struct {
*Person `yaml:",omitempty,inline,alias"`
Name string `yaml:",omitempty"`
Age int `yaml:",omitempty"`
}
Person 構造体の中で、 *Person と埋め込みを利用しているのは、この部分を <<: *alias に置き換えたいためです。
もしマージしたい対象がある場合は、 *Person に対応する値を入れることになります。
ですが、値によってはマージしたくないケースもあると思います。
そのためタグには yaml:",omitempty,inline" を指定しており、値が存在しない場合は YAML の書き出し対象にしない旨を明示しています。
最後の alias タグでは名前を指定していません。ここで先述した、参照値から動的にエイリアス名を決定する手法を利用しています。
上記のサンプルを書き出すと以下のような出力が得られます
default: &default
name: John Smith
age: 20
people:
- <<: *default
name: Ken
age: 10
- <<: *default
ぜひこれらの機能を利用して、人間が読んでも気持ちの良い YAML ファイルを生成してみてください。
5. 異なる YAML ファイルで定義されたアンカーの再利用
YAML には他の YAML ファイルを読み込むような仕様は存在しません。
...しませんが、何かの設定値や定義を記述する際にひとつの YAML ファイルですべて記述するのではなく、適宜分割して記述したい場合もあるかと思います。
実際自分が社内で開発していたツールでは、複数の YAML ファイルから設定値を読み込んで処理したいものがありました。それだけならばまだ良いのですが、この設定値のうちいくつかを、また別の YAML ファイルから参照したいというようなケースも存在しました。
当然、 ある YAML ファイルで定義されたアンカーを他の YAML ファイルから参照する方法はないので、
力技でやろうとするとすべての YAML ファイルを結合する方法が思いつくのですが、 YAML のエイリアス機能はエイリアスを利用するより手前に定義されているアンカーしか利用することができないため、結合順序がかなりシビアになってきます。
エイリアスの使い方によっては、(循環参照していたりすると)そもそも結合順序だけでは解決できないケースもあると思います。
そこでこういった場合に対応できるよう、開発したライブラリでは YAML をデコードする前にアンカー定義だけを作るフェーズを設けられる機能を提供しています。
package main
import (
"bytes"
"fmt"
"github.com/goccy/go-yaml"
)
func main() {
buf := bytes.NewBufferString("a: *a\n")
dec := yaml.NewDecoder(
buf,
yaml.RecursiveDir(true),
yaml.ReferenceDirs("testdata"),
)
var v struct {
A struct {
B int
C string
}
}
dec.Decode(&v)
fmt.Printf("%+v\n", v)
}
例えば上記のように、 yaml.Decoder を作る際に yaml.RecursiveDir(true) と yaml.ReferenceDirs("testdata") と指定すると、 あらかじめ指定されたディレクトリ配下にある YAML ファイルを再帰的に読み込んでアンカー定義を構築してからデコードするようになります。
そのため testdata 配下に
a: &a
b: 1
c: hello
のような YAML ファイルを作っておくと、
デコード対象の YAML ドキュメントに a の定義がなかったとしても正しく参照してくれるようになります。
( ※ 複数のファイルに同じ名前のアンカー定義がある場合は、後に読み込んだもので上書きする挙動になっているため、読み込み順序に依存します )
6. Lexer / Parser API の提供
実装している Lexer や Parser を public な API として提供しています。
これによって、 シンタックスハイライトを行うツールを作ったり、 YAML の linter を作ったり、
YAML 用の jq 的なツールを作ったりしたい場合に再利用することができます。
実装例として、 ycat という YAML ファイルをカラーで出力するだけのツールを作ってみました。
https://github.com/goccy/go-yaml#ycat
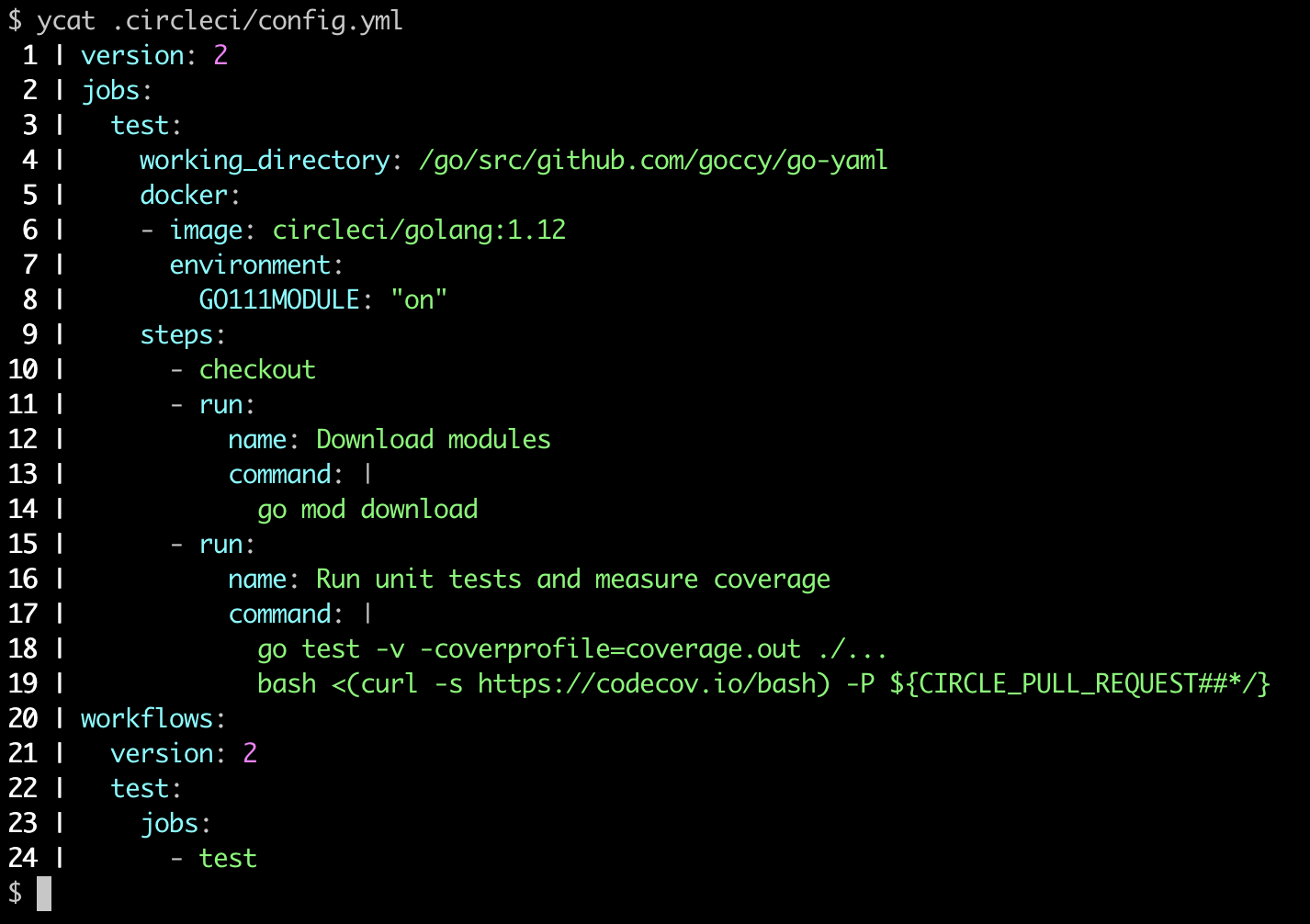
7. 機能紹介まとめ
思ったよりも長くなってしまいましたが、以上が開発したライブラリの紹介になります。
以降では、ライブラリ開発をする過程で得た実装よりの知見を共有していきたいと思います。
設計・実装
YAML パーサーを書く際に利用したのは以下の2つのページです。
ビックリしたのは、 仕様書に仕様だと思っていたものが書かれていない ことで、実は仕様は上記の PDF だけでは足りず、https://yaml.org/type にあるものを見なければいけなかったりします。
( 例えば MergeKey の仕様は PDF のどこにもなく、 https://yaml.org/type/merge.pdf にあったりします )
これがなかなか実装する上で大変で、いろいろなプログラミング言語の YAML ライブラリのオンラインドキュメントを読み漁っては https://yaml-online-parser.appspot.com のページで挙動を確かめて、仕様として考えて良さそうなものを実装してくといった流れで進めました。
1. パーサーの設計方針
プログラミング言語のパーサーの実装は様々ありますが、
ここでは 字句解析器 と 構文解析器 の二つから構成されていることとします。
字句解析器 は Tokenizer や Lexer と呼ばれ、 入力された文字列からプログラミング言語処理系が解釈できる最小単位( トークン )に分割する役割を担っています。
構文解析器 は、これがいわゆる Parser と書かれるやつで、 字句解析器 で分割された トークン 列を入力に、 構文木 ( AST または Abstract Syntax Tree ) と呼ばれる木構造を構築します。
木構造にすることで、トークン列がグルーピングされることになるため、ある処理を行いたいときはこの木構造の配下だけ見れば良いといった具合に考慮しなければいけない単位が明確になり、機械的に処理しやすくなります。
今回 YAML パーサーを開発する場合も上記の構成で開発しました。
処理系によっては字句解析器と構文解析器がくっついていて、トークン分割したそばから木構造を構築していくような実装があるのですが、この方針だと実装が複雑になりやすいのと、字句解析器や構文解析器を個別にライブラリとして提供したいという意図からも外れてしまうため採用していません。 ( ただ、高速なパーサーを開発したい場合は、ひとつにまとめる実装もアリなのかもしれません )
パッケージ構成は Go の構成に習ったほうが把握しやすいだろうということで
-
lexer: 字句解析器本体 ( 中でscannerを利用して文字列をトークン列にする。ストリームで処理する場合はここで文字列の読み込み管理をする ) -
scanner: ある文字列からトークン列を作成する -
token: トークンの定義 -
parser: 構文解析器本体 ( トークン列からastパッケージで定義された 木構造 を作る ) -
ast: 木構造の定義
のようにしました。
次項では、 YAML パーサー開発においてもっとも難易度が高かった字句解析器の実装について説明していきたいと思います。
2. 字句解析器の実装方針
パーサーを開発する上で特に大変だったのが、 scanner ( 字句解析 ) の部分でした。
開発するにあたって大事にした方針は大きく分けて以下の3点です。
- 字句解析器が状態を保持する期間を可能な限り短くすること
- 特殊な場合を除いて文字の先読みをしないこと
- すでに分割し終わったトークンを参照するような実装はしないこと
いずれも、トークン分割の判断のために参照しなければならない変数の数を少なくするための方針です。
参照しなければいけない変数の数が多ければ多いほど複雑になっていくので、できるだけ変数の生存期間が短くなるよう実装する必要があります ( プログラミング全般に言える話ですね )。
Perl の話にはなりますが、 http://gihyo.jp/dev/serial/01/perl-hackers-hub/002801 で Perl のパーサー開発について上記のようなこともふまえて詳しく解説しているので、このあたりに興味がある方は読んでみていただけると嬉しいです。
3. トークン分割をおこなうタイミング
字句解析を行う場合、どのタイミングでトークンに切り出すのかをまず考えるわけなのですが、
YAML の場合はどのタイミングで行うべきでしょうか。
a: b
c: d
などを考えると、 : といった特殊文字の他に \n ( 説明を簡単にするために改行文字を LF 前提で書きます ) を処理するタイミングかな?と考えたりします。
しかし実はそうではなく
a: b
c
のような YAML は
a: b c
と等価なので、 b の直後の \n を処理しているタイミングではトークンに分割できるかはわかりません ( c のインデントの位置がわかるまで b に続く文字がある可能性があります )
同様に、以下のような例もあります
- a
- b
- c
- d
- e
- f
こちらの YAML は
- a
- b
- c - d - e
- f
と書いたものと等価になります。つまり - のような特殊文字のあとに スペースがきていたとしても、
そこで分割してはいけないケースもあります。
ただ似たような構成で
- a:
- b
- c
- d
と書かれている場合は
- a:
- b
- c
- d
のまま解釈できるので、同じ - とスペースの組み合わせでも、そのときのコンテキストによって挙動が変わっていることがわかります。
これらは何によって決まるでしょうか。開発したライブラリでは
インデントの大小を判定するために必要な文字の位置(列番号) を記憶しつつ字句解析を続け、
\n が現れたら トークンを作り始めた時の文字の位置(列番号) があればそれを覚えつつ、
改行後に初めて現れたスペース以外の文字の位置(列番号) と記憶していた位置との大小を比較して、トークン分割をするか決めています。
例えば一つ目の例をもとにすると
a: b
c: d
では最初の : の文字を解釈する際、次の文字がスペースだったらマップのキーとして判断できるので、
一つ前の文字位置 ( a の位置 ) を記憶して先に進みます。 そのまま読み進めて \n まできたら、
b の位置を覚えて次の行に進み、 c の文字が現れた際にその文字位置と記憶していた a の文字位置を比較します。
文字位置が同じであればマップのキーであるとみなしてそこでトークンを分割し、もし c の方が列番号が大きければ b の続き文字だと判断するといった流れです。
これで
a: b
c
との区別は可能になりました。同じ発想で
- a
- b
- c
- d
- e
- f
の場合は、 - を解釈する際に次の文字がスペースであれば区切り文字と判断し、その位置を記憶しておきます。
改行後、再び - が現れた際に、記憶していた文字位置と比べて列番号が大きければ分割せず、同じかまたは小さい場合は分割するといった判定で正しく分割できるようになります。
ここまでで YAML の字句解析がやっかいそうだなというイメージを持ってもらえれば、ひとまず伝えたいことは伝わったかなと思います(笑)
4. UnmarshalYAML のインターフェースの由来を知る
パーサーの説明はこのあたりにして、今度は作った AST を読み取って Go の構造体にマッピングする話をしたいと思います。
思い出していただきたいのは、 go-yaml/yaml が 提供していた
UnmarshalYAML(func(interface{}) error) error
というインターフェースです。どうして引数に []byte をとるようなインターフェースではなく、
func(interface{})error という形をとっているのでしょうか。
ひとつは、ライブラリ内部の実装効率に関係していると考えています。パーサーが AST を作成してからデコーダがそれを使って処理するような場合、すでにもとの YAML ドキュメントを文字列で保持するようなことはしていないことになります。このため
UnmarshalYAML([]byte) error
のようなインターフェースを提供しようとした場合、引数として このインターフェースを実装している構造体に対応するバイト列を渡さないといけないのですが、それを AST から再作成しないといけないことになります。
せっかく文字列から AST を作ったのに、また AST ( 一部 ) からバイト列に戻すことが必要になるわけです。これは効率が悪いよねということで、 go-yaml/yaml は UnmarshalYAML(func(interface{}) error) error でライブラリ側にデコード作業を移譲するような方法をとることで、 AST のまま扱えるようにしているのではないかと思っています。
AST を作ってからデコードするといったステップをふまなければ ( 直接入力文字列を操作しながらマッピングしていくようなやり方 )問題はないのですが、それだと処理が複雑になりすぎてしまうので、開発したライブラリでは一見無駄に思える処理をインターフェースのために許容して実装する形をとっています ( YAML ライブラリにそこまで高速な処理を求めていないのではという意図もあります )。
5. MarshalYAML のインターフェースの由来を知る
同様に、 go-yaml/yaml がなぜ
MarshalYAML() (interface{}, error)
のようなインターフェースを用いているかも考えたいと思います。
Go の構造体から YAML ドキュメントを作る過程では、デコーダーと逆のことを行います。
つまり、 Go の構造体の内容を用いて AST を作成して、それを使って文字列を生成する流れです。
ここで
MarshalYAML() ([]byte, error)
のインターフェースを利用しようとすると、 JSON では気にしなくてよく、 YAML では重要な要素が気になってきます。
そう、インデントです。
MarshalYAML() ([]byte, error) で返されるバイト列は、言ってみればライブラリの利用者が好きに作った文字列です。
実際には、何段にも入れ子になった箇所に利用する文字列だったりすることもあるので、そのままライブラリ側で保持している文字列に結合しようとすると、インデントの数が合わずに意図したドキュメントになりません ( JSON では気にせず追記でうまくいく点が違います )
そこで開発したライブラリでは、 MarshalYAML() を呼び出したタイミングのインデントを利用しつつ、
もらったバイト列を一度 AST に変換し、それを内部でもっている AST に結合するような方法をとっています。
本当は []byte で渡されたらそれをそのままドキュメント書き出しに利用したいところですが、
一度それを AST に変換する手間がある点が実装効率が悪い部分です。
この二度手間を嫌って、おそらく go-yaml/yaml では MarshalYAML() (interface{}, error) で Go の値を直接ライブラリ側に渡す設計になっているのかなと思いました。
6. 実装解説まとめ
実際に自分で作ってみると、 YAML パーサのどこが難しいのかが分かってきて、
自分で YAML を書くときもパーサーの気持ちになって書くことができるようになりました ( Quote で囲わずにいろんな記号を使って value を書いたりするとドキドキします... )
また、どうしてこんなインターフェースにしたんだろうという疑問にも自分なりの答えが見つかったことは良かった点です。再実装してみるのも悪くないですね!
おわりに
かなり長くなってしまいましたが、ここまでお付き合いいただきありがとうございます...!
手前味噌ですが、自分が使う上で欲しかった機能をつめこんだ使いやすいライブラリになったと思っているので、ぜひこの投稿で興味をもっていただけたら利用していただきたいなと思います ( そのときに、 Star をポチッと押していただけると、すごく今後の開発にやる気が出ます! )。
何か使いにくいとか、こういった機能が欲しいといった要望があれば、遠慮なく https://github.com/goccy/go-yaml/issues に投げていただければと思います。 ( 日本語で構いません )
おそらく使う上で一番不安になるとしたら、パーサーまわりの不備だろうと思います。
一応 https://github.com/go-yaml/yaml/blob/v2/decode_test.go に記載されてあるテストケースはほとんど動作することを確認しているので大丈夫だとは思っているのですが、何か動作しない不具合を見つけた際は、そのバグをこちらで認識していない可能性が高いので、ぜひ「 これが動かない! 」と YAML の内容だけでもよいので Issue にはりつけて投稿していただければ嬉しいです。よほど忙しくなければ、2・3日で修正したいと思っています。