はじめに
HTMLテーブルはpandasのpd.read_html()を使えば数行でスクレイピングすることができますが、今回はあえてread_html()を使わずにスクレイピングする方法をご紹介したいと思います。
準備
BeautifulSoupをインストールしましょう。(今回はデータフレーム作成のためにpandasも使いますので適宜インストールしておきましょう。)
$ pip install beautifulsoup4 # or conda install
方針
今回は例としてこちらのwikipediaページから下記のCPUの一覧表を取得してみましょう。

参考
ここで、参考までに超簡単メソッドであるpd.read_html()を利用する場合の方法を以下にお示ししたいと思います。
import pandas as pd
url = 'https://en.wikipedia.org/wiki/Transistor_count' # 対象のwebページのurl
dfs = pd.read_html(url) # webページに複数のテーブルがある場合、リスト形式でdfsに格納されます
今回はdfsの1番目のインデックスに目的のテーブルが格納されているようですのでdfs[1]を出力してみましょう(dfs[0]は別のクラスのテーブルが格納されます)。
出力結果は下記画像のようになり、確かにスクレイピングすることができていますね。

概観
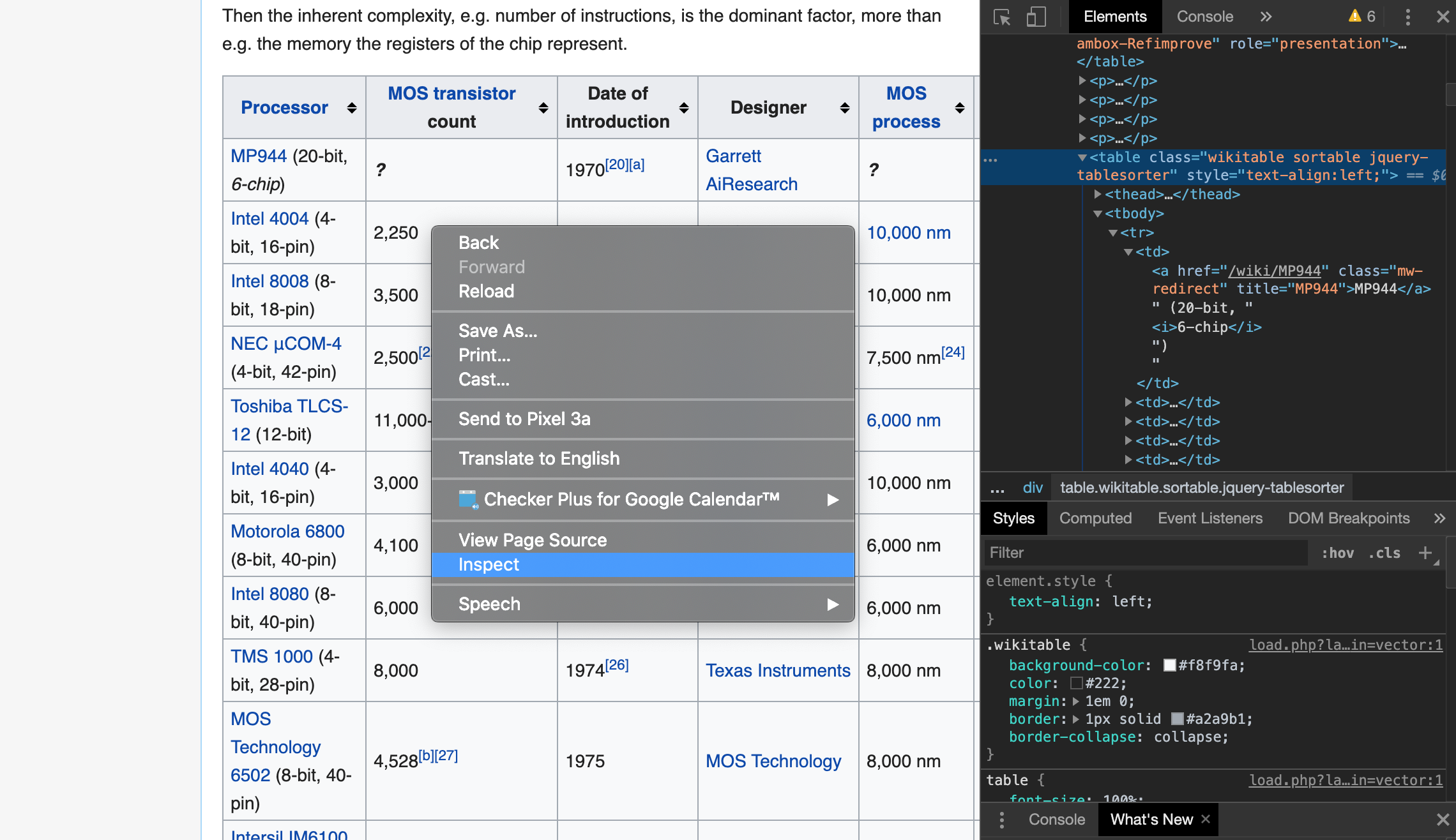
BeautifulSoupでテーブルのスクレイピングを行う前に、ここでひとまずスクレイピング先のwebページを見ておきましょう。
先程示したリンク先からwikipediaのページにとび、ディベロッパーツールを開いてみましょう(chromeの場合は表の上で右クリック⇒inspectで表示することができます。option + command + I でも可)。ディベロッパーツールでページのhtmlソースをみてみると、対象のテーブルは<table>タグ以下、<tbody>(テーブルボディ) ⇒ <tr>(テーブル列成分) ⇒<td>(テーブルセルデータ)という階層構造になっていることがわかります(下記の画像では見えていないですが\<tbody>タグと同レベルの階層にある<thead>以下の階層には<th>タグがあり、テーブルのカラム名(Processor~MOS process)の部分に相当します)。
コード
上記の概観を念頭にコードを書いていきましょう。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = "https://en.wikipedia.org/wiki/Transistor_count"
# webページデータを取得
page = requests.get(url)
# htmlをパース
soup = BeautifulSoup(page.text, 'html.parser')
ここで一旦、パースしたデータを見てみましょう。
以下のように先程ディベロッパーツールで見たような階層構造が延々と見えてきます。
output
<!DOCTYPE html>
<html class="client-nojs" dir="ltr" lang="en">
<head>
<meta charset="utf-8"/>
<title>
Transistor count - Wikipedia
</title>
<script>
・・・
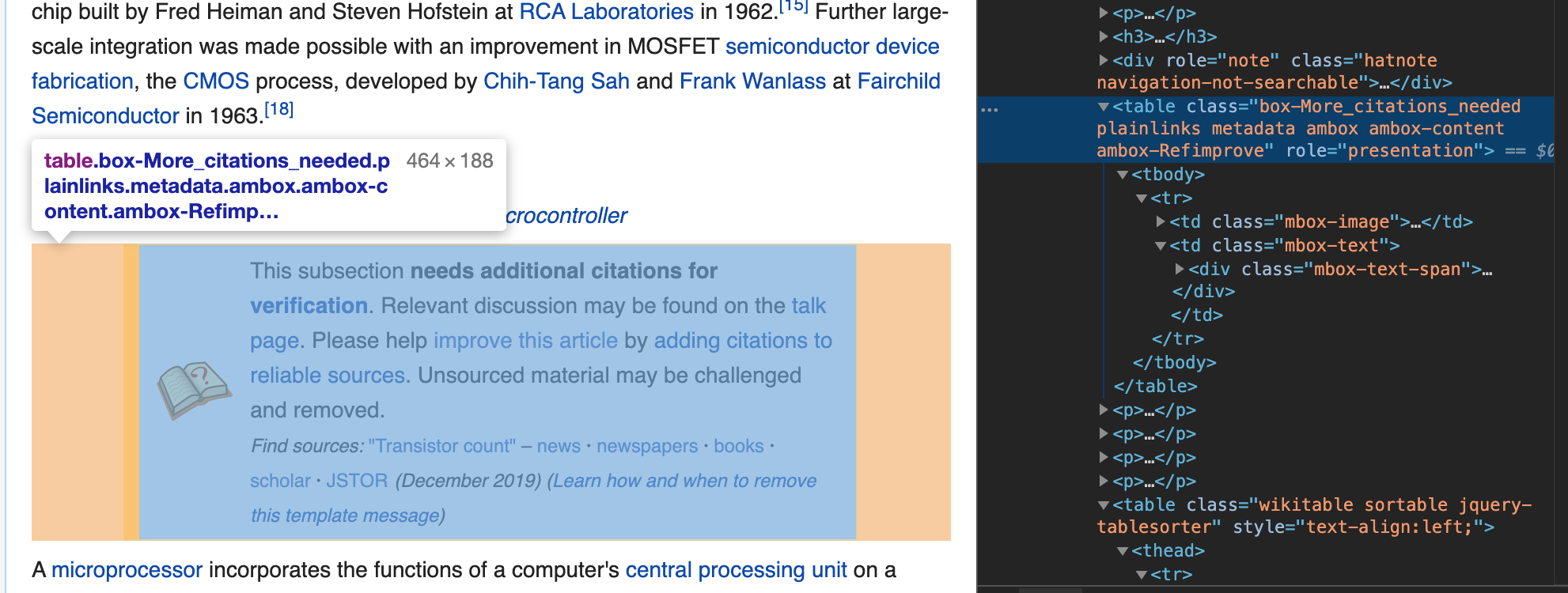
このうちテーブルに該当する部分を抽出しましょう。find()メソッドで
タグのうち、
タグ、及びwikitableクラスを指定して該当する部分を抽出します。
table = soup.find('table', {'class':'wikitable'}).tbody
テーブルのクラス指定は必ずしも必要はないと思われるかもしれませんが、他のクラスのテーブルが存在する場合は指定する必要があります。今回は下記画像のようにbox-Moreという別クラス名で存在しているため、wikitableクラスを明示的に指定しています。
続いて抽出したテーブルボディのうち、
タグ部分(テーブルの行成分)を取得します。
以下のfind_all('tr')では各行成分がリスト形式で格納されます。
rows = table.find_all('tr')
取得した行成分の0番目の要素を見てみましょう。
以下のように、<tr>タグ内にさらに<th>タグの階層が存在し、これらはテーブルのヘッダー部分に相当することがわかりますね。
output
<tr>
<th><a href="/wiki/Microprocessor" title="Microprocessor">Processor</a>
</th>
<th data-sort-type="number"><a class="mw-redirect" href="/wiki/MOS_transistor" title="MOS transistor">MOS transistor</a> count
</th>
<th>Date of<br/>introduction
</th>
<th>Designer
</th>
<th data-sort-type="number"><a href="/wiki/MOSFET" title="MOSFET">MOS</a><br/><a href="/wiki/Semiconductor_device_fabrication" title="Semiconductor device fabrication">process</a>
</th>
<th data-sort-type="number">Area
</th></tr>
一方、取得した行成分のうち、0番目の次の要素を見てみましょう。
以下のように、<tr>タグ内にさらに<td>タグの階層が存在し、これらはテーブルの1行目の各セルのデータ成分に相当することがわかりますね。
output
<tr>
<td><a class="mw-redirect" href="/wiki/MP944" title="MP944">MP944</a> (20-bit, <i>6-chip</i>)
</td>
<td><i><b>?</b></i>
</td>
<td>1970<sup class="reference" id="cite_ref-F-14_20-1"><a href="#cite_note-F-14-20">[20]</a></sup><sup class="reference" id="cite_ref-22"><a href="#cite_note-22">[a]</a></sup>
</td>
<td><a href="/wiki/Garrett_AiResearch" title="Garrett AiResearch">Garrett AiResearch</a>
</td>
<td><i><b>?</b></i>
</td>
<td><i><b>?</b></i>
</td></tr>
データフレームの作成
続いて、抽出したデータからデータフレームを作成します。まずはデータフレームのカラム名からとりかかりましょう。テーブルの0番目の行からヘッダー成分である<th>タグをすべて取得し、そのうちテキスト成分のみ抜き出します(v.text)。
columns = [v.text for v in rows[0].find_all('th')]
print(columns)
結果は以下のようになりますが、改行を示す\nが邪魔ですね。
output
['Processor\n', 'MOS transistor count\n', 'Date ofintroduction\n', 'Designer\n', 'MOSprocess\n', 'Area\n']
ですので、上記のコードを以下のように修正しましょう。
columns = [v.text.replace('\n', '') for v in rows[0].find_all('th')]
print(columns)
結果は以下のようになります。きれいにカラム名だけが抽出できましたね。
output
['Processor', 'MOS transistor count', 'Date ofintroduction', 'Designer', 'MOSprocess', 'Area']
さて、ここで上記のカラム名を指定して空のデータフレームを用意しておきましょう。
df = pd.DataFrame(columns=columns)
df
結果は以下のようになります。カラム名だけがヘッダー部分に表示され、空のデータフレームが確認できますね。

さて、カラムの抽出はできたので、次にテーブルの各データ成分を抽出していきましょう。
# 全行のうちのある行成分について
for i in range(len(rows)):
# 全ての<td>タグ(セルデータ)を取得しtdsに格納、リスト化
tds = rows[i].find_all('td')
# tdsのデータ数がカラム数に一致しない場合(ブランク)などは排除し、
if len(tds) == len(columns):
# (ある行成分の)全セルデータをテキスト成分としてvaluesに格納、リスト化
values = [ td.text.replace('\n', '').replace('\xa0', ' ') for td in tds ]
# valuesをpd.seriesデータに変換、データフレームに結合
df = df.append(pd.Series(values, index=columns), ignore_index= True)
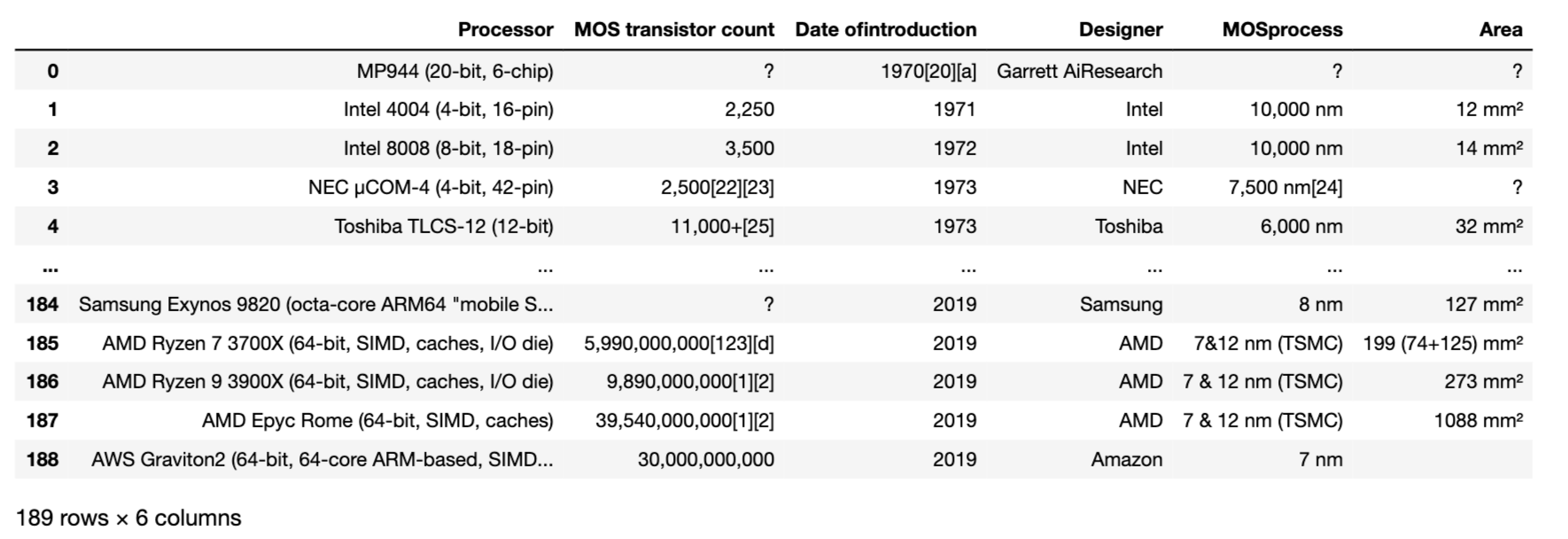
作成されたデータフレームを出力してみましょう。
結果は以下の画像のようになります。BeautifulSoupできれいに表のスクレイピングを行うことができました。
ちなみに上記のtd.text.replace('\n', '').replace('\xa0', ' ')を単にtd.textとして実行してしまうとvaluesは下記の様な結果になってしまいます(valuesのうちある成分を例として表示しています)。
output
['Intel 4004 (4-bit, 16-pin)\n', '2,250\n', '1971\n', 'Intel\n', '10,000\xa0nm\n', '12\xa0mm²\n']
ヘッダーの時と同様に改行コード\nが、そしてスペースを示すコードである\xa0がそれぞれ含まれてしまっていますね。このためそれぞれreplace()メソッドで置き換えを行う必要があります。
作成したデータフレームはcsv形式で適宜保存しておきましょう。
# ヘッダー抜き、デリミッターはタブ指定
df.to_csv('processor.csv', index=False, sep='\t' )
コードまとめ
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://en.wikipedia.org/wiki/Transistor_count'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
table = soup.find('table', {'class':'wikitable'}).tbody
rows = table.find_all('tr')
columns = [v.text.replace('\n', '') for v in rows[0].find_all('th')]
df = pd.DataFrame(columns=columns)
for i in range(len(rows)):
tds = rows[i].find_all('td')
if len(tds) == len(columns):
values = [ td.text.replace('\n', '').replace('\xa0', ' ') for td in tds ]
df = df.append(pd.Series(values, index=columns), ignore_index= True)
df.to_csv('processor.csv', index=False, sep='\t' )