概要
この記事は Swendsen and Wang, "Nonuniversal critical dynamics in Monte Carlo simulations", 1987 のアルゴリズムでイジングモデルを数値的に解くことを目的とした記事です。
「いきなり複雑なアルゴリズムでイジングモデルを解くのはちょっと...」という方は、過去記事[理系大学生応援] シングルスピンフリップでイジングモデルを解くでイジングモデルの理解を深めてから、この記事を読んでいただければと思います。
実はもう先駆者様がおります。
私がここに記事にしなくても、実はもう先駆者様が記事を掲載してくれています。参考までにそのリンクを以下に貼ります。
原理の詳細に関しては先駆者様に譲るとして、ここではアルゴリズムを図解で紹介していきたいと思います。
アルゴリズム
ステップ0
適当に初期状態のスピン配置(ここでは例としてランダムとします)を用意します。

ステップ1
隣同士の2つのスピンをボンドで結ぶかどうか決定します。結ぶ基準は
(1) 2つのスピンが同じ向き
(2) $0<r<1$の乱数が確率$p = 1- e^{-2J/k_B T}$より小さい
この2つを満たすときにボンドを形成します(前のステップですでに結ばれたボンドがあればこれを削除しておきます)。
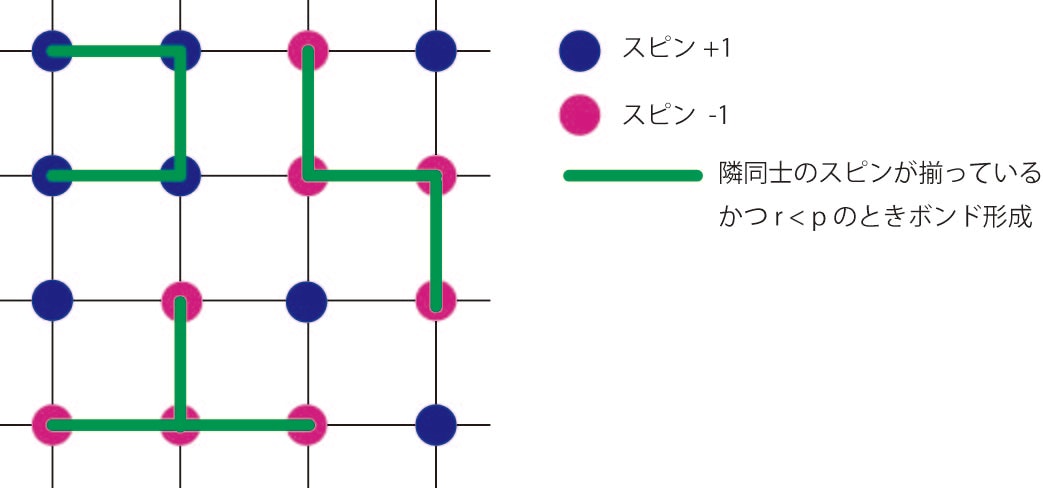
ステップ2
ステップ1でできた各クラスタごとに$0<r<1$の乱数を発生させ、それが0.5以下であれば、そのクラスタに属するスピンを反転させます。そうでなければそのクラスタは反転させず、そのままにします。

ステップ3
ステップ1に戻ります。
Union-Find木
座標$(i, j)$とその隣の座標$(i+1, j)$や$(i, j+1)$のスピン同士をつなぐ操作(Union)と、スピンがどのクラスタに属しているか調べる操作(Find)については、やはり先駆者様のUnion-Find木のサンプルコードを参照すると良いでしょう。
Pythonスクリプト
以下にPythonで書かれた実装スクリプトを示します。
# !/usr/bin/env python
import matplotlib.pyplot as plt
import numpy as np
class IsingSwendsenWang:
def __init__(self):
# set the number of spins in x-direrection, y-direction
self.IXMAX = 200
self.JYMAX = 200
# set J_ij (= J, uniform)
self.J = 1.0
# set initial condition (-1 or 1, random)
self.S = (np.random.rand(self.IXMAX, self.JYMAX)<0.5) * (-2) + 1
# set 1/(k_B T)
self.ONEOKBT = 1.0
# set the number of iteration
self.ITER = 1000000
# initialize Union-Find tree cluster rank
self.CLUSTER = np.zeros(self.IXMAX*self.JYMAX, dtype=np.int)
def Get_Cluster_Rank(self, i, j):
# set the rank of (i, j)
rank = i * self.JYMAX + j
# find the rank
while rank != self.CLUSTER[rank]:
rank = self.CLUSTER[rank]
return rank
def Connect_Bond(self, i1, j1, i2, j2, p):
# periodic boundary condition
if i2 == self.IXMAX:
i2 = 0
if j2 == self.JYMAX:
j2 = 0
# if two adjacent spins are anti-parallel, do nothing
if self.S[i1][j1] * self.S[i2][j2] < 0:
return
# if r < p, connect bond (Union procedure)
if np.random.rand() < p:
rank1 = self.Get_Cluster_Rank(i1, j1)
rank2 = self.Get_Cluster_Rank(i2, j2)
if rank1 < rank2:
self.CLUSTER[rank2] = rank1
else:
self.CLUSTER[rank1] = rank2
def Cluster_Flip(self):
# set rank of Union-Find cluster
for rank in range(self.IXMAX*self.JYMAX):
self.CLUSTER[rank] = rank
# compute probability of making bond
p = 1.0 - np.exp(-2.0*self.J*self.ONEOKBT)
# -1 or 1, random matrix
cluster_flip = (np.random.rand(self.IXMAX*self.JYMAX)<0.5) * (-2) + 1
# making bond
for i in range(self.IXMAX):
for j in range(self.JYMAX):
# bond between (i, j) & (i+1, j)
self.Connect_Bond(i, j, i+1, j, p)
# bond between (i, j) & (i, j+1)
self.Connect_Bond(i, j, i, j+1, p)
for i in range(self.IXMAX):
for j in range(self.JYMAX):
# get which cluster contains (i, j)
myrank = self.Get_Cluster_Rank(i, j)
# update spins
self.S[i][j] *= cluster_flip[myrank]
def Plot_Spin(self):
# remove previous figure
plt.clf()
# plot color map
plt.imshow(self.S, cmap='PuOr', vmin=-1, vmax=1)
# add colorbar
plt.colorbar(ticks=[-1, 1], orientation='vertical')
# set pause interval time
plt.pause(1e-6)
def run(self):
# main loop start
for n in range(self.ITER):
# plot
if n % 1 == 0:
self.Plot_Spin()
# cluster update with Swendsen-Wang algorithm
self.Cluster_Flip()
if __name__ == '__main__':
a = IsingSwendsenWang()
a.run()
スクリプト詳細
__init__
この関数内で初期条件等を設定しています。self.IXMAX, self.JYMAXはそれぞれ$x, y$方向のスピンの数です。self.Jは相互作用係数で、ここでは一様・一定を仮定しています。self.Sはスピンの$\pm 1$がランダムに並んだ2次元リストです。self.ONEOKBTは$1/k_B T$の大きさを指定しています。self.ITERはモンテカルロの試行回数を設定しています。self.CLUSTERはクラスタのランクナンバリングを初期化しています。
Get_Cluster_Rank
ここではFind, すなわち座標$(i, j)$がどのクラスターに属しているか、そのランクの取得を行なっています。
Connect_Bond
この関数は上述のアルゴリズムのステップ1、すなわちクラスタのボンド結合の判定を行なっています。
Cluster_Flip
この関数は上述のアルゴリズムのステップ2、すなわちクラスタごとのスピン反転を行なっています。
Plot_Spin
ここでmatplotlibを用いてself.S($\pm 1$のスピンの並び)を2次元カラーコントアとして描画しています。
run
この関数でSwendsen-Wangの方法によるスピン反転をself.ITERの回数だけ繰り返し行います。
結果
self.IXMAX = 200
self.JYMAX = 200
self.J = 1.0
self.S = (np.random.rand(self.IXMAX, self.JYMAX)<0.5) * (-2) + 1
self.ONEOKBT = 1.0
self.ITER = 1000000
上述のパラメータのときの計算結果を以下に示します。
初期状態

中間状態

終状態

$k_B T = 1.0$のときをシミュレーションしているので、綺麗にスピンが揃う結果が示せていることがわかります。
結言
シングルスピンフリップよりもかなり強力な方法です。アルゴリズムは複雑ではありますが、少ないモンテカルロのステップで状態が収束します。計算コストを減らすためにも、どんどん活用していきましょう。