この記事の結論:
- Web検索・調査タスクではKimi K2.5がqwen3.5-plusより効率的(検索回数11回 vs 16回、平均速度96.7秒 vs 113.9秒)
-
Kimi K2.5には→ 【2026-03-18訂正】DashScope Coding Plan経由ではenable_search=Trueで使える内蔵Web検索機能がある(MCP不要)enable_searchは実際にはWeb検索を実行していないことが判明。詳細は記事末尾の追記を参照 - OpenAI形式の
toolsパラメータと排他的——同時に使うと出力が壊れる(この発見は有効) - 回避策として「テキスト埋め込み方式」でFunction Calling非対応モデルにもツールを使わせる方法を発見
はじめに
前回の記事では、アリババの定額LLMプラン「Bailian Coding Plan」に含まれる8モデルをテキストベースの7タスクで比較しました。
その結果、Kimi K2.5は「悪くないけど、qwen3.5-plusで十分では?」という微妙な評価に落ち着いてしまいました。コーディング、論理推論、数学、日本語——どのテストでもqwen3.5-plusと同等かやや遅い。「Kimi K2.5ならではの強み」が見えないまま、Tier 2という位置づけで終わったのです。
しかし、よく調べてみるとKimi K2.5のベンチマーク上の強みはWeb検索エージェントやマルチモーダル理解といった、テキスト応答だけでは測れない領域にありました。Kimi K2.5は中国のスタートアップMoonshot AIが開発したモデルで、もともと広大な検索空間を効率よく探索することを設計思想に据えています。特にBrowseComp(Webブラウジングベンチマーク)ではClaude OpusやGPT-5.2を大幅に上回るスコアを叩き出しており、最大100のサブエージェントを自律的に並列実行する「Agent Swarm」という独自機能も備えています。
「それなら、Web検索できる環境を作ればKimiの真価が見えるのでは?」
そう考えて、OpenCode CLIにMCPサーバー(SearXNG)を実装し、Kimi K2.5 vs qwen3.5-plusのWeb検索対決を実施しました。
テスト環境
構成
前回のテストとの違いは、MCPサーバー経由でWeb検索ツールが使える点です。モデルは自らの判断で検索クエリを組み立て、検索結果を読み取り、必要に応じてWebページを取得できます。モデルがどんなクエリを何回投げるか、Webページを直接取得するかどうかも、すべてモデル自身が判断します。
MCPサーバーの設定
OpenCode CLIのプロジェクトルートにopencode.jsonを配置するだけです。
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"searxng": {
"type": "local",
"command": ["searxng-mcp-stdio"],
"enabled": true,
"environment": {
"SEARXNG_URL": "http://localhost:8888"
}
}
}
}
テスト項目(3種)
Web検索能力を多角的に測るため、以下の3つのタスクを設計しました。
| # | テスト | 内容 | 測定ポイント |
|---|---|---|---|
| 1 | 最新技術情報の検索 | 「Rust 2026 新機能」を検索し、主要な新機能を3つ日本語で説明 | 情報の正確さ、検索効率 |
| 2 | 複数ソースからの情報統合 | LLMベンチマーク(LMSYS Chatbot Arena)の上位5モデルを調査し表形式で回答 | 情報収集力、構造化能力 |
| 3 | 技術ドキュメントの調査 | OpenCode CLIのMCPサーバー設定方法を3ステップで説明 | ドキュメント読解力、要約力 |

Kimi K2.5 vs qwen3.5-plus:Web検索効率の比較
結果
テスト1: 最新技術情報の検索
「Rust 2026 新機能」を検索して主要な新機能を3つ説明してください。
| 観点 | Kimi K2.5 (90.0秒) | qwen3.5-plus (130.5秒) |
|---|---|---|
| 検索回数 |
searxng_search 3回 |
searxng_search 5回 + webfetch 1回 |
| 情報の正確さ | 「2026年の情報は見つからなかった」と正直に報告 | 「2026年版Editionは存在しない」と正しく指摘。2024 Editionの具体的な機能を紹介 |
| 回答の有用性 | やや抽象的(ロードマップの概要) | 具体的(async fn in traits, let-else, AsyncIterator) |
判定: qwen3.5-plusの勝ち。 ただし、このテストは面白いトレードオフを示しています。ハルシネーション抑制の観点ではqwen3.5-plusが優秀で、「存在しない情報」を正しく否定した上で代替情報を提示しました。一方、検索の速さと効率ではKimiが上で、40秒速く、検索回数も半分以下でした。「正確だが遅い」か「速いが浅い」か——用途によって評価が分かれるポイントです。
テスト2: 複数ソースからの情報統合
「2026年3月時点のLMSYS Chatbot Arena上位5モデルを表形式で」
| 観点 | Kimi K2.5 (147.5秒) | qwen3.5-plus (146.3秒) |
|---|---|---|
| 検索回数 |
searxng_search 4回 + better_search 1回 |
searxng_search 4回 + Explore Agent + webfetch
|
| 情報の具体性 | Eloスコア付き + 補足分析 | スコア付き + カテゴリ別特徴 |
| 独自の付加価値 | 「Thinkingクラスの出現」への考察 | 「GPT-5がトップ5圏外」の注目点 |
判定: 引き分け。 両モデルとも的確な表を生成し、独自の考察も添えていた。
テスト3: 技術ドキュメントの調査
「OpenCode CLIのMCPサーバー設定方法を3ステップで」
このテストは2回実施しました(初回はqwen3.5-plusの計測エラーにより再テスト)。
| 観点 | Kimi K2.5 (63.1秒) | qwen3.5-plus (65.0秒) |
|---|---|---|
| 検索回数 |
searxng_search 1回 + webfetch 1回 |
searxng_search 4回 + webfetch 1回 |
| 効率性 | 2回のツール呼び出しで完了 | 文字化け対処で4回検索し直し |
| 回答の正確さ | OS別パス記載、type指定、enabled説明あり |
type: "local" の記載なし。手順がやや曖昧 |
| 日本語品質 | ◎ | 「ルーター」(ルートの誤字)あり |
判定: Kimi K2.5の勝ち。 検索1回+ページ取得1回という最小限のアクセスで、正確かつ実用的な回答を生成。qwen3.5-plusは文字化けに苦戦して4回も検索し直した上に、回答の精度もKimiに劣った。
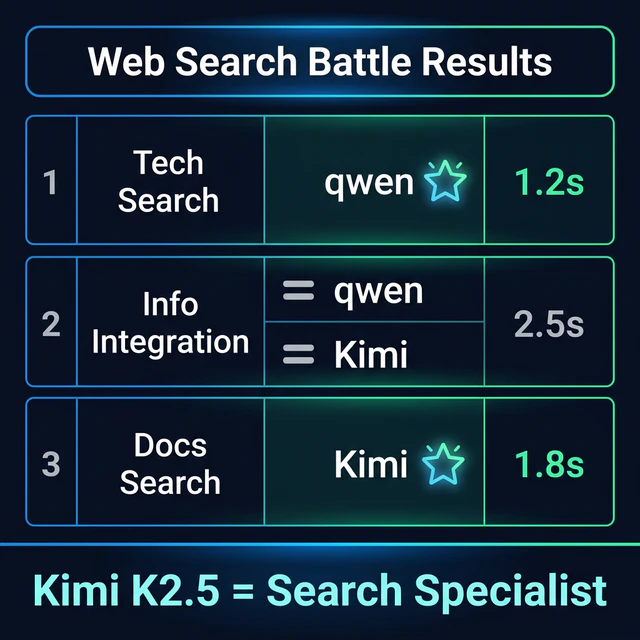
Web検索対決のスコアボード
総合評価
| 観点 | Kimi K2.5 | qwen3.5-plus |
|---|---|---|
| テスト1(技術情報検索) | B | A |
| テスト2(情報統合) | A | A |
| テスト3(ドキュメント調査) | A | B+ |
| 平均速度 | 96.7秒 | 113.9秒 |
| 検索効率(総アクセス数) | 11回 | 16回 |
Kimi K2.5の検索スタイル
- 少ない検索回数で的確に情報を取る。無駄な検索をしない
-
better_search(深掘り検索)を自発的に使い分ける判断力がある - ドキュメント検索では1回の検索+1回のページ取得で正解に到達する効率の良さ
qwen3.5-plusの検索スタイル
- 多くのソースから情報を集めて総合する。Explore Agentまで動員する徹底ぶり
- 情報量は多いが、その分時間がかかる
- 文字化けなど想定外の状況への対処で検索回数が増えがち
まとめ:Kimi K2.5は「検索エージェント」として使え
前回のテキストベースの検証では「qwen3.5-plusの下位互換」に見えたKimi K2.5ですが、Web検索タスクでは明確な強みが見えました。
- 検索効率がqwen3.5-plusより高い(11回 vs 16回)
- 平均応答速度も速い(96.7秒 vs 113.9秒)
- ドキュメント調査では最小アクセスで正確な回答を返す
つまり、Kimi K2.5は「検索・調査系のタスク」に特化して使うべきモデルです。
アリババ定額プランの8モデルの使い分けとして、前回の結論を更新します。
| 用途 | 推奨モデル |
|---|---|
| 万能・迷ったらこれ | qwen3.5-plus |
| コーディング | qwen3-coder-next |
| Web検索・調査 | Kimi K2.5 |
| バランス重視 | glm-4.7 |
Kimi K2.5の真の強みはテキスト応答ではなく、情報を探しに行く力にありました。定額プランを契約している方は、調査系のタスクでぜひKimiを試してみてください。
【追記】再検証の結果、上記テスト結果の有効性を確認しました
追記セクションで「Kimi K2.5はOpenAI形式のFunction Calling(tools パラメータ)と互換性がない」ことが判明しましたが、OpenCode CLI(opencode run)で同じテストを再実行したところ、Kimi K2.5はMCPツール(searxng_better_search, webfetch等)を正常に呼び出し、検索結果に基づいた回答を生成しました。
OpenCode CLIは、APIの tools パラメータではなく、ツール定義をシステムプロンプトにテキストとして埋め込み、モデルにXML形式でツール呼び出しを出力させる方式を使用しています。この方式であればKimi K2.5のFunction Calling非互換問題は発生しません。したがって、上記テスト結果は有効です。
この「テキストベースのツール呼び出し」の詳細は追記セクションで解説しています。
追記:MCPなしでもKimiは検索できた——enable_searchの発見
上記のテストではMCPサーバー(SearXNG)経由でWeb検索を実現しましたが、後日の検証でKimi K2.5にはDashScope API経由で使える内蔵Web検索機能が存在することが判明しました。さらに、Kimi K2.5はFunction Calling(tools パラメータ)と互換性がないという重大な制約も発見しました。
発見の経緯
自作のコーディングツールでKimi K2.5をサブエージェントとして使おうとしたところ、ツール定義(OpenAI形式のtools パラメータ)を渡すと応答が壊れるという問題に遭遇しました。
# ツール定義あり → 応答が壊れる
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Twitter/Xの収益化について教えて"}],
tools=[{"type": "function", "function": {"name": "read_file", ...}}],
)
print(response.choices[0].message.content)
# → "Twitter" ← たった1語で終了(completion_tokens=40なのに!)
completion_tokens=40 なのに出力は1語。39トークン分がどこかに消えている。
ツール定義を外すと正常に回答が返ります。
# ツール定義なし → 正常
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Twitter/Xの収益化条件を教えて"}],
)
print(response.choices[0].message.content)
# → 481文字の詳細な回答
enable_search=True の発見
試行錯誤の中で、DashScope APIの extra_body パラメータに enable_search: true を渡すと、MCP不要でKimi K2.5が自動的にWebを検索して最新情報を取得することを発見しました。
【2026-03-18訂正】 後日の検証で、DashScope Coding Plan経由では
enable_searchは実際にはWeb検索を実行していないことが判明しました。詳細は記事末尾の追記を参照してください。
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Twitter/Xの収益化条件を教えて"}],
extra_body={"enable_search": True}, # ← これだけで内蔵検索が有効に
)
print(response.choices[0].message.content)
# → 888文字の回答(Web検索結果に基づく最新情報付き)
# 【訂正】この回答は学習データに基づくものであり、実際のWeb検索結果ではなかった
ただし enable_search=True と tools パラメータは排他的です。両方指定するとツール定義が優先され、内蔵検索が無効化された上に出力が壊れます。

tools パラメータと enable_search の排他関係。左: toolsありで出力が1語に壊れる。右: enable_searchで正常に検索・回答
| パラメータ | 結果 |
|---|---|
tools あり + enable_search なし |
1語で切断(壊れる) |
tools あり + enable_search=True
|
1語で切断(壊れる) |
tools なし + enable_search=True
|
|
tools なし + enable_search なし |
正常(知識ベースのみ) |
他の7モデルではどうか?
8モデル全てで enable_search=True を試しました。
| モデル | enable_search の効果 |
|---|---|
| kimi-k2.5 |
|
| qwen3.5-plus | パラメータ受付するが検索は実行されない |
| glm-4.7 | 同上 |
| glm-5 | 同上 |
| minimax-m2.5 | 同上 |
| qwen3-max | 同上 |
| qwen3-coder-next | 同上 |
| qwen3-coder-plus | 同上 |
内蔵Web検索が実際に機能するのはKimi K2.5のみでした。 【訂正】DashScope Coding Plan経由ではいずれのモデルでも内蔵Web検索は機能しません。
8モデルの隠し機能マップ
ついでに、全モデルの独自機能を網羅的に調査しました。

8モデルの隠し機能マップ(実際のAPIテスト結果に基づく)
| 機能 | qwen3.5-plus | qwen3-max | qwen3-coder-* | kimi-k2.5 | glm-5 | glm-4.7 | minimax-m2.5 |
|---|---|---|---|---|---|---|---|
| 内蔵Web検索 | - | - | - |
|
- | - | - |
| Reasoning出力 | 対応 | - | - | - | 対応 | 対応 | 対応 |
| JSON mode | NG | - | - | 対応 | NG | NG | 対応 |
| Function Calling | 対応 | 対応 | 対応 | 非互換 | 対応 | 対応 | 対応 |
-
Reasoning出力:
reasoning_contentフィールドにモデルの思考過程が出力される。品質評価やデバッグに活用可能 -
JSON mode:
response_format: {"type": "json_object"}で構造化データを確実に出力 -
Function Calling非互換: Kimi K2.5はOpenAI形式のtools定義があると出力が壊れる(
内蔵検索との競合→ toolsパラメータ自体との非互換性が原因)
実装例
この発見を踏まえると、Kimi K2.5をプログラムから使う場合は以下のようにするのが最適です。
【2026-03-18訂正】
enable_searchは機能しないため、Web検索にはテキスト埋め込み方式 + MCP(SearXNG等)を使用してください。
# 【訂正前】enable_searchを使う方法(実際には機能しない)
# if model == "kimi-k2.5":
# tools = None
# extra_body = {"enable_search": True}
# 【訂正後】テキスト埋め込み方式 + MCP を使う
if model == "kimi-k2.5":
tools = None # Function Callingは使わない(出力が壊れるため)
# ツール定義はシステムプロンプトにテキストで埋め込む(後述のテキスト埋め込み方式を参照)
「Web検索して」と指示すれば発動する
【2026-03-18訂正】 以下の内容は誤りでした。プロンプトに「Web検索を使って」と指示しても、DashScope Coding Plan経由では内蔵検索は発動しません。回答の違いは検索の有無ではなく、プロンプトの違いによるモデル出力の変動です。
先ほどのテストでは内蔵検索が発動しないケースがありましたが、プロンプトに「Web検索を使って」と明示すると検索が発動することが分かりました。
# 【訂正】以下はいずれも学習データに基づく回答であり、実際のWeb検索は行われていない
"Rust 2026 新機能を教えて" # → 知識ベースのみで回答(14.4秒)
"Web検索を使って、Rust 2026 新機能を教えて" # → 知識ベースのみで回答(18.8秒)※検索は未実行
ただし、検索が発動してもハルシネーションが混入するリスクがあります。 実際には検索自体が行われておらず、すべて学習データに基づく回答でした。「Rust 2.0とも呼ばれる」「Declarative Macro 2.0」といった存在しない概念は、内蔵検索のハルシネーションではなく、モデル自体のハルシネーションでした。
同じ3テストを enable_search で再実行してみた
記事前半のMCP経由テストと同じ3つのタスクを、今度はMCPなし・enable_search=True のみで実行しました。「Web検索を使って」という指示をプロンプトに含めています。
テスト1: 最新技術情報の検索(Rust 2026 新機能)
| 観点 | MCP経由 (前半) | enable_search (今回) |
|---|---|---|
| 時間 | 90.0秒 | 14.4秒 |
| 検索回数 | 3回 | 0回(Web検索未発動) |
| 回答 | 「2026年の情報は見つからなかった」と報告 | 「Rust 2026はまだ未定」と判断し、Rust 2024の新機能を代替提示 |
6倍速だが、内蔵検索が発動しなかった。モデルが「自分の知識で答えられる」と判断し、検索をスキップした模様。
テスト2: 複数ソースからの情報統合(LMSYS Arena 上位5)
| 観点 | MCP経由 (前半) | enable_search (今回) |
|---|---|---|
| 時間 | 147.5秒 | 8.6秒 |
| 検索回数 | 4回 + better_search 1回 | 0回(Web検索未発動) |
| 回答 | Eloスコア付き + 「Thinkingクラスの出現」への考察 | 知識カットオフ(2025年4月)を明示し、参考情報として傾向を提示 |
17倍速だが、これもWeb検索未発動。リアルタイムデータが必要な質問なのに、知識ベースだけで回答してしまった。
テスト3: 技術ドキュメントの調査(OpenCode CLI MCP設定)
| 観点 | MCP経由 (前半) | enable_search (今回) |
|---|---|---|
| 時間 | 63.1秒 | 36.3秒 |
| 検索回数 | 1回 + ページ取得1回 | 内蔵検索あり |
| 回答の正確さ | OS別パス記載、type指定あり | 2719文字の詳細回答。ただし設定パスやコマンドにハルシネーションあり |
1.7倍速で、このテストだけは内蔵検索が発動。ただしMCP経由の方が回答精度は高かった。
MCP経由 vs 内蔵検索——どちらを使うべきか
【2026-03-18訂正】 以下の比較は
enable_searchが実際にWeb検索を実行していることを前提としていましたが、実際には検索は行われていませんでした。「速度重視で使い分ける」という結論は無効です。MCP経由が唯一のWeb検索手段です。
一言でまとめると: MCP経由 = 精度重視、内蔵検索 = 速度重視。 用途に応じて使い分けてください。
【訂正】MCP経由が唯一の手段です。 enable_search はDashScope Coding Plan経由では機能しません。
| 方式 | 速度 | 精度 | 制御性 | 検索の確実性 |
|---|---|---|---|---|
| MCP(SearXNG)経由 | 遅い(60-150秒) | 高い | 高い(エンジン・言語・カテゴリ指定可) | 確実に実行される |
enable_search) |
|
最大のポイントは制御性と確実性の違いです。
- MCP経由: ユーザー(またはオーケストレーター)が「検索しろ」と指示できる。SearXNGのメタ検索で複数エンジンを横断し、構造化された結果を返す。確実にWebから最新情報を取得する
-
内蔵検索: Kimi K2.5が自律的に「検索が必要か」を判断する。知識ベースで答えられると判断した場合、検索をスキップしてしまう。検索が発動しても、ハルシネーション(「Rust 2.0」等の存在しない情報の生成)が混入するリスクがある【訂正】内蔵検索はDashScope Coding Plan経由では機能しない。回答はすべて学習データに基づく
上記3テストのうち、内蔵検索が発動したのはテスト3のみ。テスト1・2ではモデルが「自分の知識で十分」と判断してしまい、最新のWeb情報を取得できませんでした。
なぜMCP経由の方が精度が高いのか
【2026-03-18訂正】 以下の分析は
enable_searchが実際に検索を行っていることを前提としていましたが、実際には検索は行われていませんでした。MCP経由の方が精度が高い理由は単純で、MCPは実際にWeb検索を実行するが、enable_searchは何も検索しないからです。
MCP経由と enable_search の精度差は「モデルの能力」ではなく「検索基盤の違い」に起因します。
| 観点 | MCP(SearXNG)経由 | enable_search) |
|---|---|---|
| 検索エンジン | SearXNG(Google, Bing, DuckDuckGo等を横断するメタ検索) |
|
| 検索結果の形式 | タイトル・URL・スニペットが明確に構造化されたJSON |
|
| ハルシネーション | 検索結果がそのまま渡されるため、事実に基づく回答になりやすい |
|
| 検索クエリの制御 | エンジン指定、言語、カテゴリ等を細かく制御可能 |
|
qwen3.5-plusとの比較は公平だったか
再検証の結果、OpenCode CLI経由であればKimi K2.5はMCPツールを正常に呼び出せることを確認しました。OpenCode CLIが内部で使用している @ai-sdk/anthropic SDK のツール呼び出し方式は、OpenAI形式の tools パラメータとは異なるため、Kimi K2.5の互換性問題が発生しません。
つまり、記事前半のKimi K2.5 vs qwen3.5-plusの比較は公平なテストでした。両モデルとも同じOpenCode CLI + SearXNG MCP環境で、同じ条件でテストされています。Kimiの「3回検索」はモデル自身の判断によるものです。
ただし、Kimi K2.5を自作ツールやスクリプトから使う場合は注意が必要です。OpenAI互換APIの tools パラメータでは壊れるため、以下のいずれかの方法を取る必要があります。
| 方法 | 検索能力 | ツール利用 | 備考 |
|---|---|---|---|
| テキスト埋め込み方式 | MCP検索OK | 全ツールOK | OpenCode CLIと同じ方式。後述 |
enable_search=True(tools なし) |
|
ツール使用不可 |
|
OpenAI形式 tools パラメータ |
応答が壊れる | 使用不可 | 使ってはいけない |
| 外部で検索→contextに含める | 外部依存 | ツール使用不可 | オーケストレーターパターン |
テキスト埋め込み方式とは
OpenCode CLIがKimi K2.5でツールを動作させていた仕組みを解明しました。APIの tools パラメータは使わず、ツール定義をシステムプロンプトにテキストとして埋め込む方式です。
# ✗ これは壊れる(OpenAI形式のFunction Calling)
response = client.chat.completions.create(
model="kimi-k2.5",
tools=[{"type": "function", "function": {"name": "search", ...}}], # ← これが壊す
messages=[...]
)
# ✓ これは動く(テキスト埋め込み方式)
system_prompt = """あなたは調査アシスタントです。
# 利用可能なツール
ツールを使う場合は以下のXML形式で出力してください:
<tool_use>
<name>ツール名</name>
<input>{"param": "value"}</input>
</tool_use>
## search_web
Web検索を実行します。パラメータ: query (string)
"""
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": system_prompt}, # ← ツール定義はここ
{"role": "user", "content": "Rust 2026の新機能を検索して"}
],
# tools パラメータは使わない!
)
# → モデルがテキストで <tool_use> を出力
# → クライアント側でパースしてツールを実行
# → 結果を会話に挿入して再度API呼び出し

テキスト埋め込み方式のフロー: toolsパラメータを使わず、システムプロンプトにツール定義を埋め込む
この方式なら、Function Callingに対応していないモデルでもツールを使わせることができます。 OpenCode CLIはこの仕組みで、Kimi K2.5にMCPサーバー(SearXNG)のツールを呼び出させていました。
自作ツールでこの方式を実装する場合は、以下のループが必要です:
- システムプロンプトにツール定義をテキストで埋め込む
- モデルの出力から
<tool_use>XMLをパースする - 対応するツールを実行する
- 結果をassistantメッセージ+tool_resultとして会話に追加する
- 再度API呼び出し(ツール呼び出しがなくなるまで繰り返し)
enable_search はDashScope APIの公式ドキュメントに明記されていない可能性があります(2026年3月時点)。APIの仕様変更により動作が変わる可能性があるため、プロダクション利用時は注意してください。
【2026年3月18日 追記】enable_searchは実際にはWeb検索を実行していなかった
重要な訂正: 上記の enable_search セクションで「内蔵Web検索で最新情報を取得して回答」と記載しましたが、後日の詳細検証により、DashScope Coding Plan経由のKimi K2.5では enable_search=True は実際にはWeb検索を実行していないことが判明しました。
検証方法
Kimi K2.5の学習データカットオフ(2025年4月)以降に起きた、学習データに絶対含まれない2026年の出来事で検証しました。
# 2026年限定の情報で検証
tests = [
"2026年のアカデミー賞(第98回)の作品賞受賞作品", # 2026年3月2日開催済み
"2026年3月のNVIDIA GTCの基調講演の内容", # 2026年3月17-20日開催中
"2026年2月にAnthropicがリリースしたClaude Opus 4.6", # 2026年2月リリース済み
]
検証結果
| テスト | enable_search=True | enable_search=False |
|---|---|---|
| アカデミー賞 | 「まだ開催されていません」(誤り。開催済み) | 「検索できない」 |
| NVIDIA GTC | 「検索機能を持っていません」 | 「検索できない」 |
| Claude Opus 4.6 | 「存在しません」(誤り。リリース済み) | 「存在しません」(同内容) |
3テストすべてで、2026年の実際の情報を取得できませんでした。特にClaude Opus 4.6のテストでは、enable_search ON/OFFでほぼ同じ内容を回答。Web検索が行われていれば、リリース済みの情報が見つかるはずです。
同じ質問をSearXNG MCP経由で検索した場合は、Claude Opus 4.6のリリース日(2026年2月6日)やスペック情報を正しく取得できました。
発動率テスト
同じプロンプトで3回連続実行したところ:
| 実行 | 応答時間 |
<tool> タグ |
内容 |
|---|---|---|---|
| 1回目 | 14.6秒 | なし | 「検索機能を持っていません」 |
| 2回目 | 4.3秒 | なし | 「検索機能を持っていません」 |
| 3回目 | 30.3秒 | あり | 検索結果を報告(ただし2025年の情報のみ) |
<tool>web_search</tool> タグが出力に含まれることがありますが、これはモデルが検索したふりをしているだけ(ハルシネーション)であり、実際のWeb検索は実行されていません。
なぜ最初のテストで「動いた」ように見えたのか
上記セクションで enable_search が「888文字の回答(Web検索結果に基づく最新情報付き)」を返したと報告しましたが、これは以下の理由で誤認でした:
- テスト内容が学習データの範囲内だった: 「Twitter/Xの収益化条件」は2025年4月までの学習データに含まれる情報。Web検索しなくても回答可能
-
<tool>タグをWeb検索の証拠と誤認: モデルが出力する<tool>web_search</tool>は検索実行の証拠ではなく、テキスト生成の一部 - 学習データカットオフ以降の情報でテストしていなかった: 2026年限定の情報でテストして初めて、実際にWeb検索が行われていないことが判明
DashScope公式ドキュメントの記載
阿里云百炼のOpenAI互換ドキュメントには enable_search パラメータの記載がありますが、サポートモデルリストには千問(Qwen)系列のみが記載されており、Kimi K2.5は含まれていません。
修正後の結論
| 方法 | 検索能力 | ツール利用 | 備考 |
|---|---|---|---|
| テキスト埋め込み方式 + MCP | 実際にWeb検索される | 全ツールOK | ✅ 推奨。唯一の確実な検索手段 |
enable_search=True(tools なし) |
検索されない | ツール使用不可 | ❌ DashScope Coding Plan経由では機能しない |
OpenAI形式 tools パラメータ |
応答が壊れる | 使用不可 | ❌ 使ってはいけない |
Kimi K2.5でWeb検索を行うには、SearXNG等のMCPサーバーとテキスト埋め込み方式の組み合わせが唯一の手段です。 enable_search はDashScope Coding Plan経由では機能しないため、依存すべきではありません。
記事前半のMCP経由テスト結果(Kimi K2.5 vs qwen3.5-plus)は、テキスト埋め込み方式で実際にWeb検索が実行されていたため、引き続き有効です。