はじめに
何番煎じかという感じですが、PytorchにおけるLSTMの扱いに習熟する為、コロナウイルス陽性者数の予測を行います。
初めに全国の過去の感染者数から、将来の全国の感染者数を予測します。
その後、各都道府県の過去の感染者数から、将来の全国の感染者数の予測を行います。
LSTM
LSTMの構造については以下のリンクが分かり易いかと思います。
Understanding LSTM Networks
LSTMネットワークの概要(上記リンクの翻訳)
ざっくり説明するとLSTMはRNN(Recurrent Neural Network)の進化系です。
RNNは通常の全結合型ニューラルネットワークと異なり、ニューラルネットワークの出力を別のネットワークの入力として利用することから、Recurrent(回帰性の)という言葉が当てられています。
LSTMは「忘却ゲート」「入力ゲート」「更新ゲート」というゲート層を導入することにより、従来のRNNが苦手としていた長期の時系列データを扱うことが可能になりました。
データセット
データセットとして厚生労働省が公表している「新規陽性者数の推移(日別)」を使用しました。
本データセットは2020/1/16から現在までの各都道府県(+全国)の陽性者数をcsvファイルとしてまとめたものです。以下のリンクの「新規陽性者数の推移(日別)」からダウンロードできます。
【厚生労働省】新型コロナウイルス感染症に関するオープンデータ
環境
- Google Colaboratory Pro
コード
モジュールのimport
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
import torch
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import torch.nn as nn
import torch.optim as optim
データの読み込み、前処理、学習用データと検証用データへの分割。
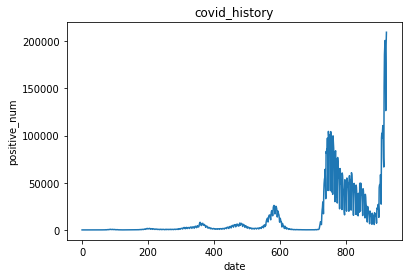
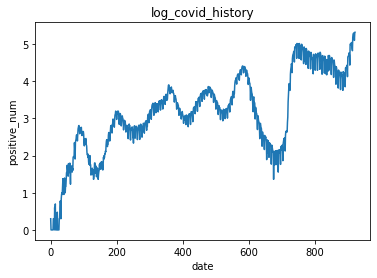
感染者数は指数関数的に増大する為、常用対数を取った値で以降の処理を行います。
(1⇒100と100⇒10000の増加を同程度に重要だと捉えます)
df = pd.read_csv("/content/drive/MyDrive/covid_prediction/newly_confirmed_cases_daily.csv")
all_df = df.loc[:,["Date","ALL"]]
all_df["log_ALL"] = np.log10(all_df["ALL"] + 1) #0の対数は取れないため1を足しています。
plt.figure()
plt.plot(all_df["ALL"])
plt.xlabel('date')
plt.ylabel('positive_num')
plt.title("covid_history")
plt.figure()
plt.plot(all_df["log_ALL"])
plt.xlabel('date')
plt.ylabel('positive_num')
plt.title("log_covid_history")
train_df = all_df[:800] #0~800日のデータを学習用に
val_df = all_df[800:] #800~日のデータを検証用に
常用対数を取らない場合の感染者数チャート
常用対数を取った場合の感染者数チャート
データローダーを作成します。lengthは過去何日分の値を使用して1日後の値を予測するかを示します。
length=25であれば、例として4/1~4/25のデータから4/26の感染者数を予測するという意味です。
class Dataset(Dataset):
def __init__(
self,
df,
length
):
self.data_num = len(df) - length
self.train_list = []
self.target_list = []
for i in range(self.data_num):
train_data = [[j] for j in all_df["log_ALL"][i:i + length]]
self.train_list.append(train_data) #length分のデータをリストとして格納
self.target_list.append([[all_df["log_ALL"][i + length]]]) #予測する1日後のデータをリストとして格納
def __getitem__(self, i):
train_data = torch.tensor(self.train_list[i]).float()
train_data = train_data/10 #値を0~1に収める為に10で割っています。
target_data = torch.tensor(self.target_list[i]).float()
target_data = target_data/10 #同上
data = {"train": train_data, "target": target_data}
return data
def __len__(self):
return self.data_num
例としてlength=25としてデータローダーを作成します。
BATCH_SIZE = 8
length = 25
train_dataset = Dataset(train_df, length)
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True)
val_dataset = Dataset(val_df, length)
val_loader = DataLoader(val_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True)
LSTMモデルを構築します。モデルはシンプルにLSTM1層⇒全結合1層としています。(全結合層にはDropoutあり)
nn.LSTMにhidden_sizeというパラメータがあり理解しにくいのですが、以下の図が最も分かり易いと思います。
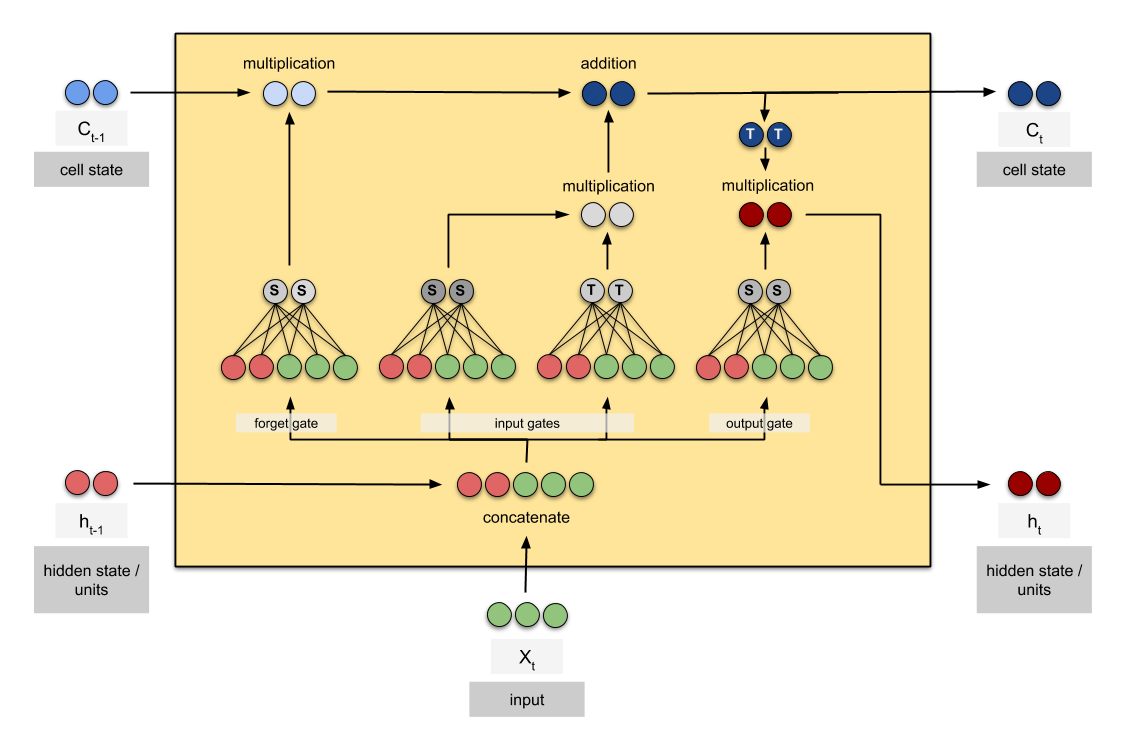
【引用】Counting No. of Parameters in Deep Learning Models by Hand
この図におけるCt、htの次元がhidden_sizeに該当します。
class Lstm_model(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.lstm = nn.LSTM(input_size = 1,
hidden_size = hidden_dim,
batch_first = True)
self.lr = nn.Linear(hidden_dim, 1)
self.drop = nn.Dropout(0.2)
def forward(self, x):
_, x = self.lstm(x)
x = x[0]
x = x.permute(1,0,2)
x = self.drop(x)
x = self.lr(x)
return x
モデルの定義、損失と最適化関数の設定を行います。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Lstm_model(hidden_dim = 100).to(device) #hidden_size=100に設定
criterion = nn.MSELoss() #回帰のタスクなので平均二乗誤差を損失に設定
optimizer = optim.Adam(model.parameters(), lr=0.001)
学習を行います。
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[400], gamma=0.1) #400epoch後に学習率を1/10に低下
weight_path = f"./train_drop_{length}.pth" #保存する重みのファイル名
epoch_num = 500
print_coef = 1
train_length = len(train_dataset)
val_length = len(val_dataset)
history = {"train_loss": [], "val_loss": []}
n = 0
m = 0
for epoch in range(epoch_num):
train_loss = 0
val_loss = 0
model.train()
for i, data in enumerate(train_loader):
inputs, labels = data["train"].to(device), data["target"].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
n += 1
history["train_loss"].append(loss.item())
if i % ((train_length//BATCH_SIZE)//print_coef) == (train_length//BATCH_SIZE)//print_coef - 1:
print(f"epoch:{epoch+1} index:{i+1} train_loss:{train_loss/n:.6f}")
n = 0
train_loss = 0
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
inputs, labels = data["train"].to(device), data["target"].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
m += 1
val_loss += loss.item()
history["val_loss"].append(loss.item())
print(f"epoch:{epoch+1} index:{i+1} val_loss:{val_loss/m:.6f}")
if epoch == 0:
temp_loss = val_loss
torch.save(model.state_dict(), weight_path)
elif val_loss < temp_loss: #最も検証用データの損失が低い重みを保存
temp_loss = val_loss
torch.save(model.state_dict(), weight_path)
m = 0
val_loss = 0
scheduler.step() #400epoch後に学習率を1/10に低下
print("low_valloss :",temp_loss/(val_length//BATCH_SIZE))
print("finish training")
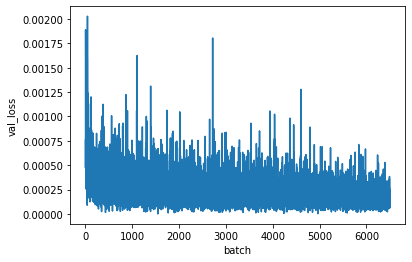
学習の履歴を表示します。
plt.figure()
plt.plot(history["train_loss"])
plt.xlabel('batch')
plt.ylabel('train_loss')
plt.figure()
plt.plot(history["val_loss"])
plt.xlabel('batch')
plt.ylabel('val_loss')
学習用データの損失チャート
検証用データの損失チャート
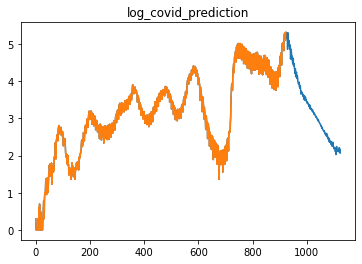
未来の感染者数の予測を行います。手法は以下の通りです。
まず現在から25日分前のデータを使用して1日後を予測します。
次に予測したデータと現在から24日分前のデータを使用して2日後を予測します。
上記の予測を連続して行い、数十~数百日後の感染者数を予測します。
model = Lstm_model(hidden_dim = 100)
model.load_state_dict(torch.load(weight_path)) #モデルの定義
predict_range = 200 #200日後まで予測します。
log_original_numpy = all_df["log_ALL"].to_numpy() #常用対数を取った現在までのチャート
original_numpy = all_df["ALL"].to_numpy() #常用対数を取っていない現在までのチャート
pred_numpy = all_df["log_ALL"].to_numpy()[:, np.newaxis]
for _ in range(predict_range):
data = pred_numpy[-1-length : -1]
data = torch.tensor([data]).float()
data = data/10
pred = model(data)
pred = pred * 10
pred = pred.to('cpu').detach().numpy().copy()
pred = pred.reshape(1,1)
pred_numpy = np.append(pred_numpy, pred, axis=0)
pred_numpy = pred_numpy.squeeze() #常用対数を取った予測結果
norm_pred_numpy = 10**pred_numpy #常用対数を取らない予測結果
plt.figure()
plt.plot(pred_numpy)
plt.plot(log_original_numpy)
plt.title("log_covid_prediction")
plt.figure()
plt.plot(norm_pred_numpy)
plt.plot(original_numpy)
plt.title("covid_prediction")
青が将来の感染者数を表します。
常用対数を取った感染者数チャート
常用対数を取っていない感染者数チャート
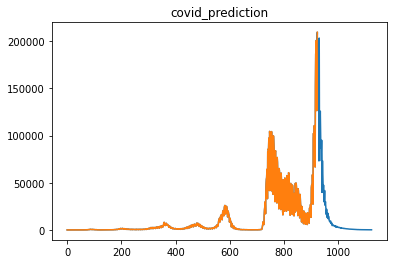
現在の20万人をピークとして急減すると予測していますね。
何日分のデータで学習するか(length)により精度が変わるのか
lengthの候補として25日、50日、100日を設定し、いずれのlengthで検証データにおける損失が最小になるのか調べました。
| length | 25days | 50days | 100days |
|---|---|---|---|
| MSE_Loss | 0.000175 | 0.000124 | 0.000132 |
結果、length=50daysで損失が最小になりました。以下が予測結果となり、感染者数が40万人に到達してから減少すると予測しています。
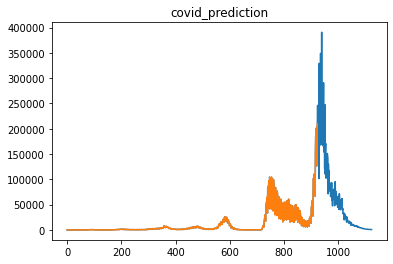
モデルによる比較
上記のシンプルなモデル以外にも、いくつかのモデルを用いて精度の比較を行いました。
- LSTMを2層重ねるモデル
- 47都道府県+全国のデータから全国の感染者数を予測するLSTM1層のモデル
- 2.に加えてLSTMを2層重ねるモデル
lengthの候補として25日、50日、100日を設定し、各組み合わせの中で検証データにおける損失が最小になるのか調べました。
(2.と3.は48系列に対して損失を計算しているため、1.と単純に比較ができません)
| length | 25days | 50days | 100days |
|---|---|---|---|
| 1. | 0.000101 | 0.000069 | 0.000114 |
| 2. | 0.000605 | 0.000597 | 0.000475 |
| 3. | 0.000676 | 0.000699 | 0.000530 |
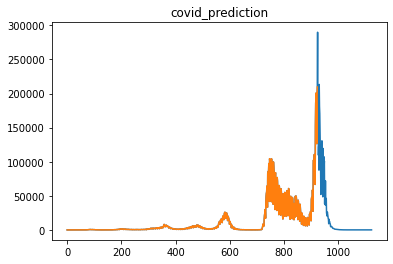
全国の感染者数のみ扱うモデルではlength=50daysで損失が最小になりました。一方、47都道府県+全国の感染者数を扱うモデルではlength=100daysで損失が最小になりました。
- + length=50daysの予測結果
- + length=100daysの予測結果
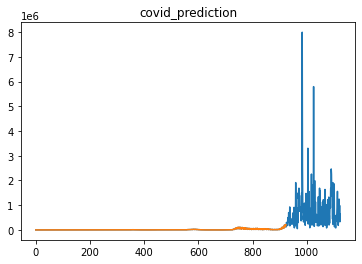
最大感染者数が800万人になっているのであり得ないと思います...
2.および3.におけるデータローダーのコード
class Dataset(Dataset):
def __init__(
self,
df,
length
):
self.data_num = len(df) - length
self.train_list = []
self.target_list = []
for i in range(self.data_num):
train_data = [j for j in df.loc[:,"log_ALL":][i:i + length].values]
self.train_list.append(train_data)
self.target_list.append([df.loc[:,"log_ALL":].values[i + length]])
def __getitem__(self, i):
train_data = torch.tensor(self.train_list[i]).float()
train_data = train_data/10
target_data = torch.tensor(self.target_list[i]).float()
target_data = target_data/10
data = {"train": train_data, "target": target_data}
return data
def __len__(self):
return self.data_num
1.におけるモデルのコード
class Lstm_model(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.lstm1 = nn.LSTM(input_size = 1,
hidden_size = hidden_dim,
batch_first = True)
self.lstm2 = nn.LSTM(input_size = hidden_dim,
hidden_size = hidden_dim,
batch_first = True)
self.lr = nn.Linear(hidden_dim, 1)
self.drop = nn.Dropout(0.2)
def forward(self, x):
x, _ = self.lstm1(x)
_, x = self.lstm2(x)
x = x[0]
x = x.permute(1,0,2)
x = self.drop(x)
x = self.lr(x)
return x
2.におけるモデルのコード
class Lstm_model(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.lstm = nn.LSTM(input_size = 48,
hidden_size = hidden_dim,
batch_first = True)
self.lr = nn.Linear(hidden_dim, 48)
self.drop = nn.Dropout(0.2)
def forward(self, x):
_, x = self.lstm(x)
x = x[0]
x = x.permute(1,0,2)
x = self.drop(x)
x = self.lr(x)
return x
3.におけるモデルのコード
class Lstm_model(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.lstm1 = nn.LSTM(input_size = 48,
hidden_size = hidden_dim,
batch_first = True)
self.lstm2 = nn.LSTM(input_size = hidden_dim,
hidden_size = hidden_dim,
batch_first = True)
self.lr = nn.Linear(hidden_dim, 48)
self.drop = nn.Dropout(0.2)
def forward(self, x):
x, _ = self.lstm1(x)
_, x = self.lstm2(x)
x = x[0]
x = x.permute(1,0,2)
x = self.drop(x)
x = self.lr(x)
return x
おまけ(LSTM+残差接続)
ResNetやDenseNetで使用される残差接続をLSTMに適用するモデルがあるとのことで作成しました。
結果的に精度が上がらなかったので(検証データにおける最小損失:0.000661)、モデル部のみコードを記載します。
class Lstm_model(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.lstm1 = nn.LSTM(input_size = 48,
hidden_size = hidden_dim,
batch_first = True)
self.lstm2 = nn.LSTM(input_size = hidden_dim + 48,
hidden_size = hidden_dim,
batch_first = True)
self.lstm3 = nn.LSTM(input_size = hidden_dim * 2 + 48,
hidden_size = hidden_dim,
batch_first = True)
self.lstm4 = nn.LSTM(input_size = hidden_dim * 3 + 48,
hidden_size = hidden_dim,
batch_first = True)
self.lstm5 = nn.LSTM(input_size = hidden_dim * 4 + 48,
hidden_size = hidden_dim,
batch_first = True)
self.lr = nn.Linear(hidden_dim, 48)
self.drop = nn.Dropout(0.2)
def forward(self, x):
x1 = x
x, _ = self.lstm1(x)
x = torch.cat([x1, x], dim = 2)
x1 = x
x, _ = self.lstm2(x)
x = torch.cat([x1, x], dim = 2)
x1 = x
x, _ = self.lstm3(x)
x = torch.cat([x1, x], dim = 2)
x1 = x
x, _ = self.lstm4(x)
x = torch.cat([x1, x], dim = 2)
_, x = self.lstm5(x)
x = x[0]
x = x.permute(1,0,2)
x = self.drop(x)
x = self.lr(x)
return x