犬・猫画像識別アプリ作成
はじめに
初めまして!python初心者のgenkiです。
学習内容のアウトプットを目的としてブログ制作しました。
https://dog-cat1234.herokuapp.com/
アドバイス等あればご指導頂ければ幸いです。
開発環境
・PC
Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz 2.40 GHz
メモリ8GB
・Google Colaborabory
・Visual Studio Code ver1.61.0
・Python ver 3.8.8
目次
- 学習データの準備
- モデルの定義
- モデルの学習
- モデルの評価
- アプリの実装
- 動作確認
- 考察
- 今後
- 追記
1.学習データの準備
学習に使用する画像は下記から引用しています。
https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
こちらの画像は犬、猫が混同していた為手動で振り分けました。
2.モデルの定義
KerasのSequentialモデルによるモデルの定義を以下に示します。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# お使いの仮想環境のディレクトリ構造等によってファイルパスは異なります。
path_dog = os.listdir('/content/drive/MyDrive/Colab Notebooks/dog1')
path_cat = os.listdir('/content/drive/MyDrive/Colab Notebooks/cat1')
img_dog = []
img_cat = []
# 画像を読み込みます。
for i in range(len(path_dog)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/dog1/' + path_dog[i])
img = cv2.resize(img, (100,100))
img_dog.append(img)
for i in range(len(path_cat)):
print(i)
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/cat1/' + path_cat[i])
img = cv2.resize(img, (100,100))
img_cat.append(img)
X = np.array(img_dog + img_cat)
y = np.array([0]*len(img_dog) + [1]*len(img_cat))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルにvggを使います
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義します
# その際中間層を下のようにいくつか入れると精度が上がります
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vggと、top_modelを連結します
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
3.モデルの学習
model.fit(X_train, y_train, batch_size=100, epochs=20, validation_data=(X_test, y_test))
Epoch 1/20
39/39 [==============================] - 10s 240ms/step - loss: 0.0358 - accuracy: 0.9864 - val_loss: 0.6239 - val_accuracy: 0.9101
Epoch 2/20
39/39 [==============================] - 9s 232ms/step - loss: 0.0357 - accuracy: 0.9867 - val_loss: 0.6229 - val_accuracy: 0.9080
Epoch 3/20
39/39 [==============================] - 9s 234ms/step - loss: 0.0272 - accuracy: 0.9898 - val_loss: 0.6163 - val_accuracy: 0.9112
Epoch 4/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0385 - accuracy: 0.9893 - val_loss: 0.6185 - val_accuracy: 0.9101
Epoch 5/20
39/39 [==============================] - 9s 237ms/step - loss: 0.0355 - accuracy: 0.9885 - val_loss: 0.6210 - val_accuracy: 0.9070
Epoch 6/20
39/39 [==============================] - 9s 237ms/step - loss: 0.0373 - accuracy: 0.9867 - val_loss: 0.6331 - val_accuracy: 0.9028
Epoch 7/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0341 - accuracy: 0.9901 - val_loss: 0.6181 - val_accuracy: 0.9101
Epoch 8/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0242 - accuracy: 0.9916 - val_loss: 0.6116 - val_accuracy: 0.9101
Epoch 9/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0397 - accuracy: 0.9880 - val_loss: 0.6126 - val_accuracy: 0.9122
Epoch 10/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0281 - accuracy: 0.9903 - val_loss: 0.6207 - val_accuracy: 0.9164
Epoch 11/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0398 - accuracy: 0.9864 - val_loss: 0.6173 - val_accuracy: 0.9070
Epoch 12/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0345 - accuracy: 0.9896 - val_loss: 0.6073 - val_accuracy: 0.9070
Epoch 13/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0283 - accuracy: 0.9903 - val_loss: 0.6058 - val_accuracy: 0.9039
Epoch 14/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0236 - accuracy: 0.9906 - val_loss: 0.6064 - val_accuracy: 0.9080
Epoch 15/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0275 - accuracy: 0.9911 - val_loss: 0.6068 - val_accuracy: 0.9101
Epoch 16/20
39/39 [==============================] - 9s 236ms/step - loss: 0.0259 - accuracy: 0.9909 - val_loss: 0.6082 - val_accuracy: 0.9091
Epoch 17/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0202 - accuracy: 0.9948 - val_loss: 0.6124 - val_accuracy: 0.9091
Epoch 18/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0340 - accuracy: 0.9877 - val_loss: 0.6078 - val_accuracy: 0.9060
Epoch 19/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0185 - accuracy: 0.9932 - val_loss: 0.6095 - val_accuracy: 0.9080
Epoch 20/20
39/39 [==============================] - 9s 235ms/step - loss: 0.0234 - accuracy: 0.9919 - val_loss: 0.6120 - val_accuracy: 0.91120.9744 - val_loss: 0.3308 - val_accuracy: 0.9402
上記の通り「loss: 0.0234:損失」は減少し、「accuracy: 0.9919:正解率」は上昇している事がわかります。
4.モデルの評価
# 画像を一枚受け取り、犬か猫かを判定する関数
def pred_gender(img):
img = cv2.resize(img, (100, 100))
print(np.array([img]).shape)
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'dog'
else:
return 'cat'
# pred_gender関数に画像を渡して犬か猫を予測します
for i in range(10):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/dog1/' + path_dog[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_gender(img))

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
cat

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
cat

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
dog

(1, 100, 100, 3)
dog
10回行った結果、上記の通り8回正解となりました。
5.アプリの実装
HTML
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>Dog Cat Classifier</title>
<link rel='stylesheet' href="./static/stylesheet.css">
</head>
<body>
<header>
<img class='header_img' src="./static/img/1.jpg" alt="Aidemy">
<a class='header-logo' href="#">Dog Cat Classifier</a>
</header>
<div class='main'>
<h2> AIが送信された画像から犬か猫を識別します</h2>
<p>画像を送信してください</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="submit!" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
<footer>
<img class='footer_img' src="./static/img/1.jpg" alt="Aidemy">
<small>© watari</small>
</footer>
</body>
</html>
CSS
header {
background-color: #b55b5b;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
6.動作確認
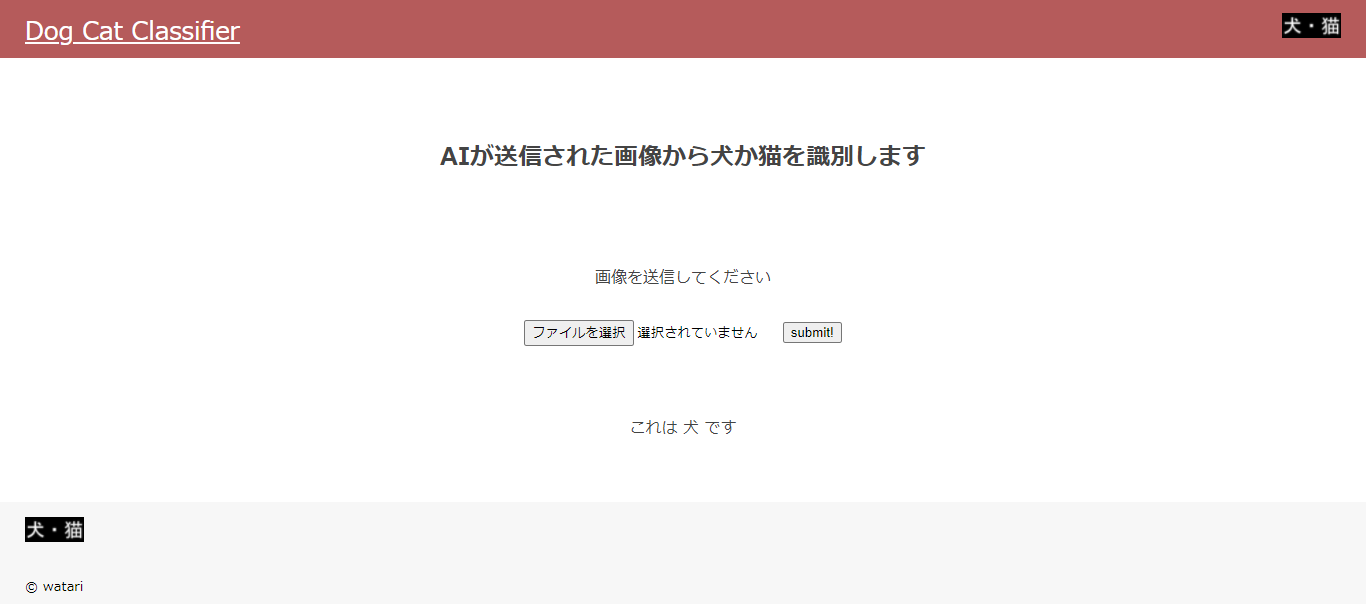
下記の通り問題なく動作しました。
下記画像を識別

結果
7.考察
損失、正解率ともに悪くない数値となっていますが、まだ伸びしろはありそう?かと思います。
その心は、データにもっと工夫をの余地があるという事です。
一見精度が良いように思いますが、今回使用したデータは犬、猫の顔がはっきり写っているものが多く、この結果を維持するためには画像の見やすさが重要になってきます。
単純にテーマのデータを集めるのではなく、いかに実用的な(例外無く正解率を維持できる)学習をさせる事、データを集める事が重要かという事に気が付くことができました。
8.今後
今回学んだ「高い正解率を維持する」モデルを作るという事を踏まえ、学習させる事は少しの工夫次第で大きく結果に影響するという事を念頭に需要のあるアプリ開発したいと思います。
9.追記
精度を上げる為に「img = cv2.resize(img, (50,50))」→「img = cv2.resize(img, (100,100))」に変更しました。
結果「loss: 0.6070」→「loss: 0.0234」、「accuracy: 0.7283」→「accuracy: 0.9919」となりモデルの評価でも正解率" 7/10 → 8/10 "と大きく精度向上しました。