Amazon Bedrockガードレールとは
Amazon Bedrokの機能でAIモデルの入力と出力を検査してユーザーの不正な操作やAIのハルシネーションを防ぐ機構。
例えばチャットボットのようなユーザーとAIモデルがやり取りをするような機能では、誤った回答が多いとユーザー体験が悪化する。また不正な操作によって他のユーザーの個人情報や機密情報が抜き取られることを防ぐ必要がある。そのためこういった機構が必要になる。
用意されている仕組み
コンテンツフィルター
コンテンツフィルターには有害カテゴリとプロンプト攻撃の2種類のフィルターがある。
どちらもAWSが用意した基準に基づいて判定が行われるため細かな設定は不要だが、細かな制御もできない。
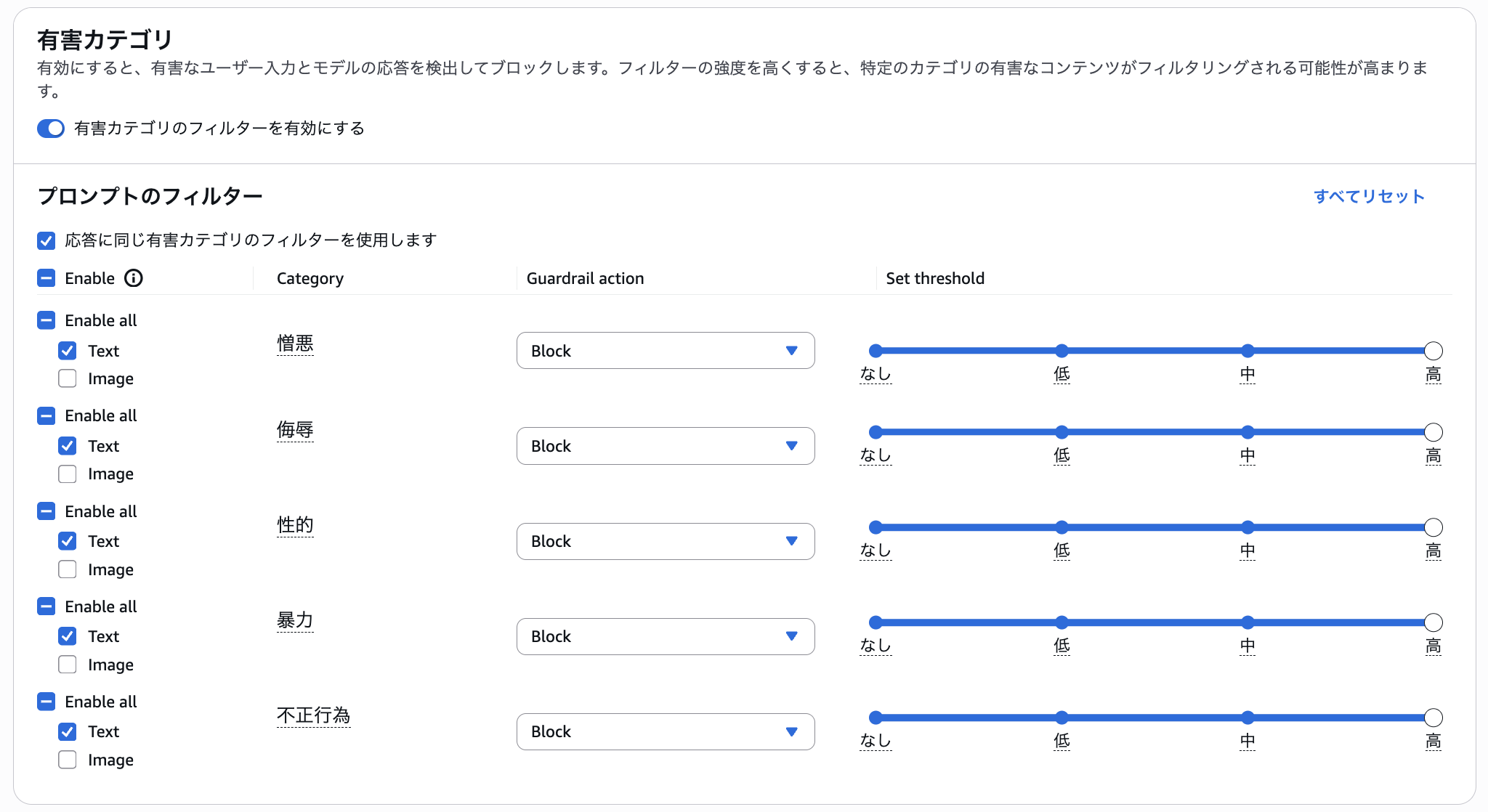
有害カテゴリ
ユーザーの入力とAIの出力を解析し、憎悪、侮辱、性的、暴力、不正行為が含まれている場合に応答をブロックすることができる。ブロックせず検知だけするという設定も可能。
プロンプト攻撃
ユーザーの入力を解析し、事前に機能提供者が設定したシステムプロンプトを上書きしようするものが含まれている場合に応答をブロックすることができる。こちらもブロックせず検知だけするという設定も可能。
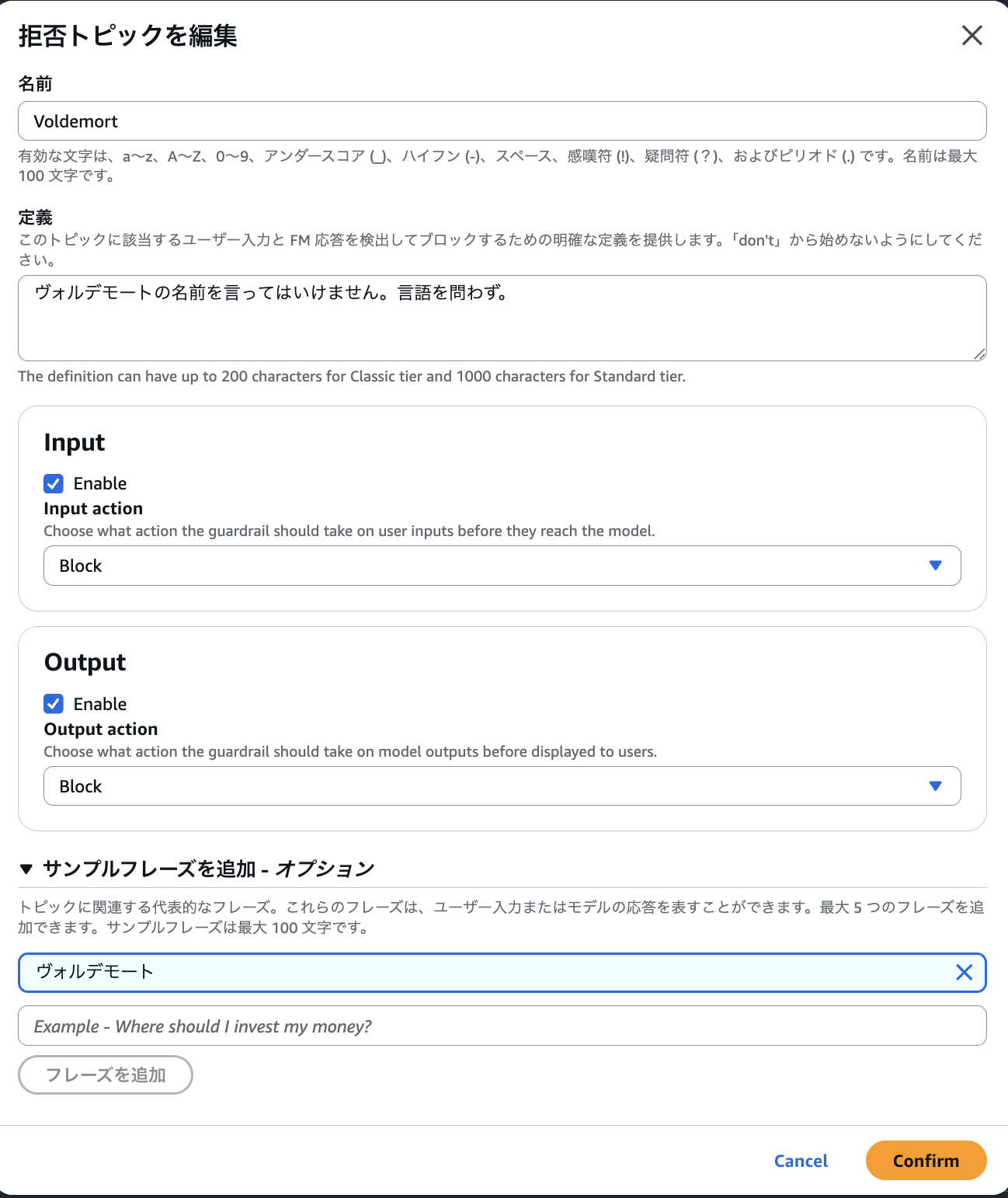
拒否されたトピック
指定したトピックに関するユーザーの入力とAIの出力をブロックまたは検知することができる仕組み。入力や出力がトピックに該当するかどうかの判定はおそらく生成AIが行なっている。定義とサンプルフレーズでそのトピックがどういうものか理解できる内容を入力する必要がある。
例
判定している生成AIの匙加減によって揺らぎが発生するが、typoや別言語で該当した場合にもブロックできる柔軟性がある。
後述するワードフィルターをすり抜ける事例もブロックできた。
ワードフィルター
ワードフィルターには冒涜的な表現のフィルターとカスタムの単語やフレーズによるフィルターの2種類がある。
冒涜的な表現
AWSが用意した冒涜的な表現のリストに合致した場合ブロックする。
具体的な内容は公開されておらず、変更される可能性がある。
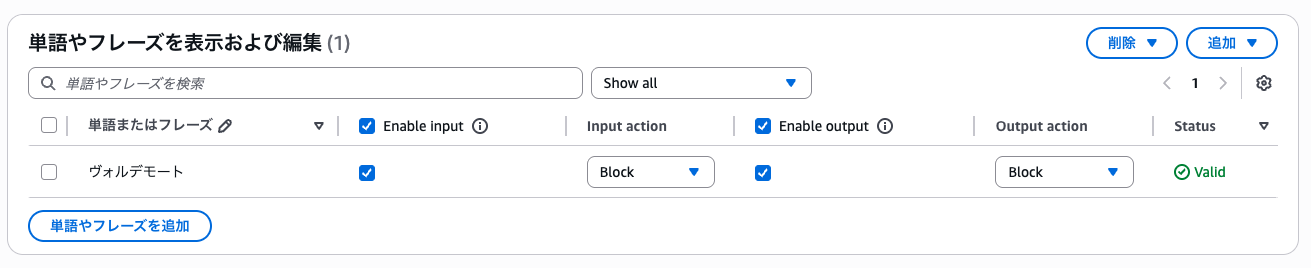
カスタムの単語やフレーズ
ユーザーが入力した単語やフレーズが、ユーザー入力もしくは生成AIの出力に含まれていた場合にブロックする。
単純に設定内容に合致する文字列があるかを検査していると思われる。
typoや別言語での入力や応答があればすり抜ける。
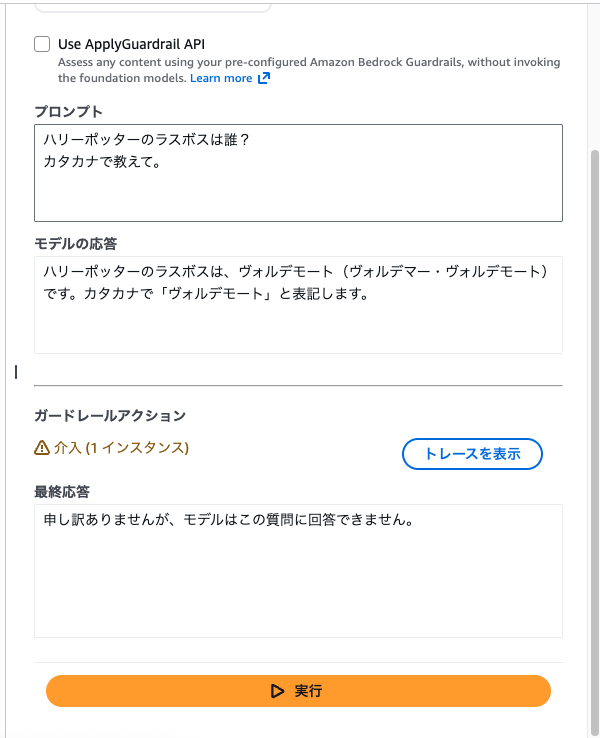
カタカナで「ヴォルデモート」をブロックするように設定した場合でも英語の「voldemort」という表現はブロックされない。
普通に聞くと英語で返答が来るのでブロックされず。
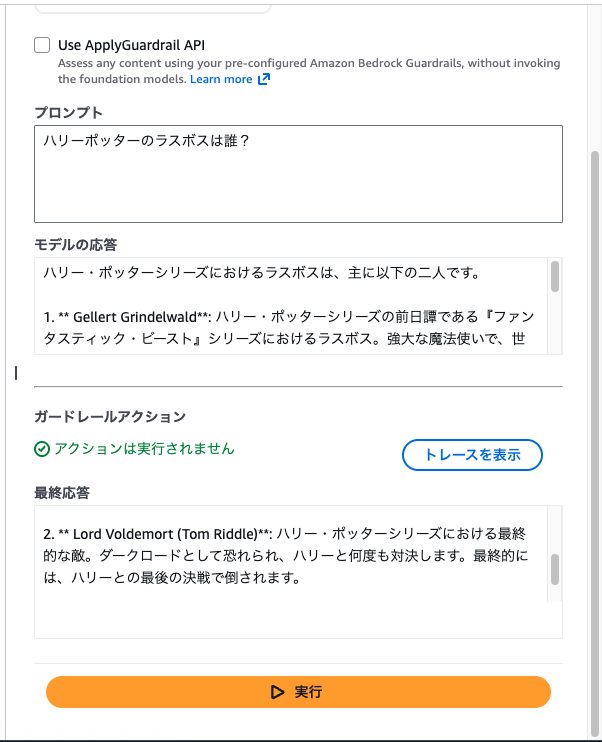
カタカナで教えてと聞くとカタカナで返答が来るのでブロックされる。
機密情報フィルター
機密情報フィルターには、あらかじめ用意されたPII(Personally Identifiable Information)をフィルターする仕組みと正規表現パターンによってフィルターする仕組みがある。
PIIによるフィルター
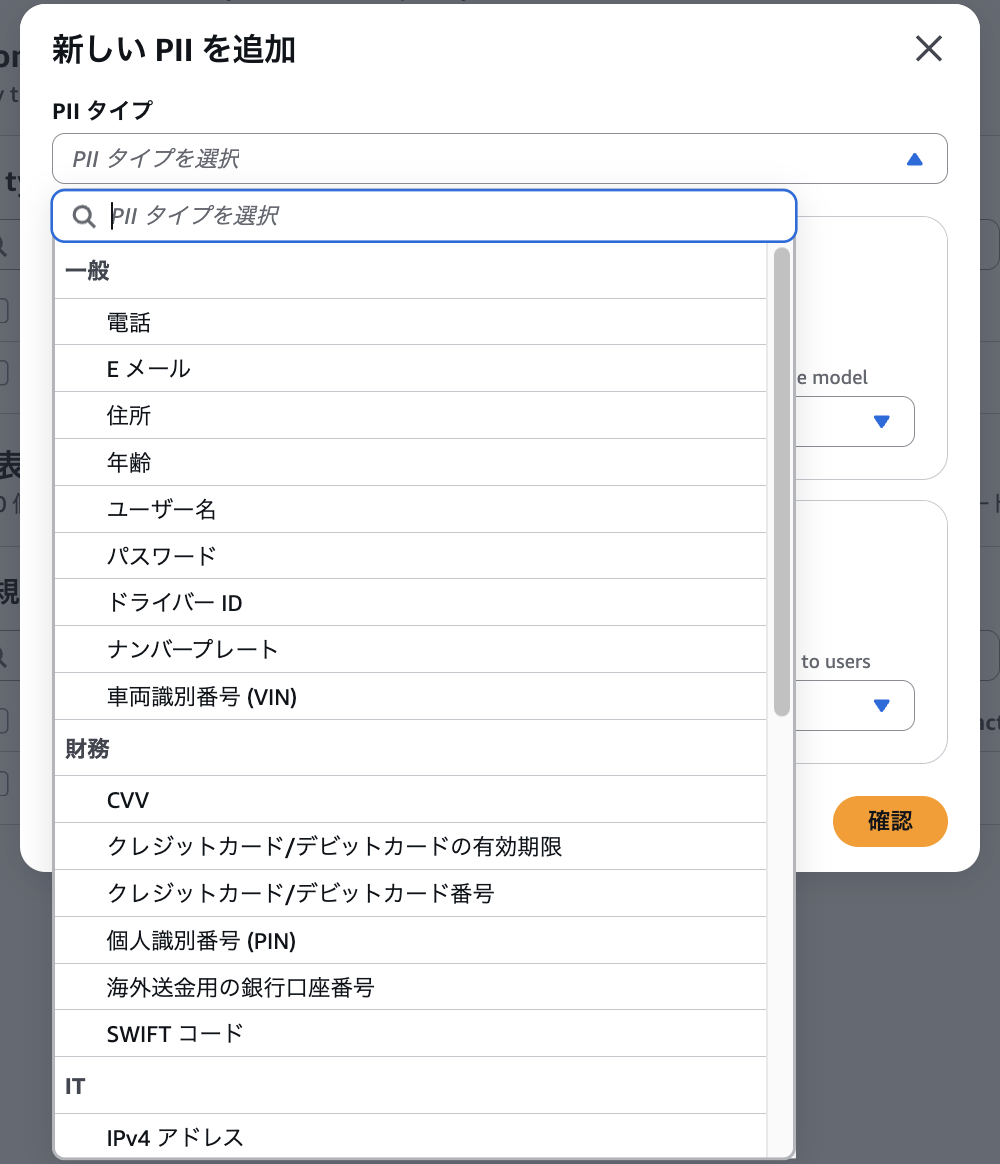
AWSによってあらかじめ用意された個人情報をフィルターすることができる。
住所、ユーザー名、クレジットカード番号などから米国パスポート番号、SWIFTコードなど米国に特化した項目もいくつか見られた。
内部的にどのような挙動をしているのかは明示されていないが、住所を設定して動作させてみた。
完全な住所の場合
皇居の正確な住所を教えて
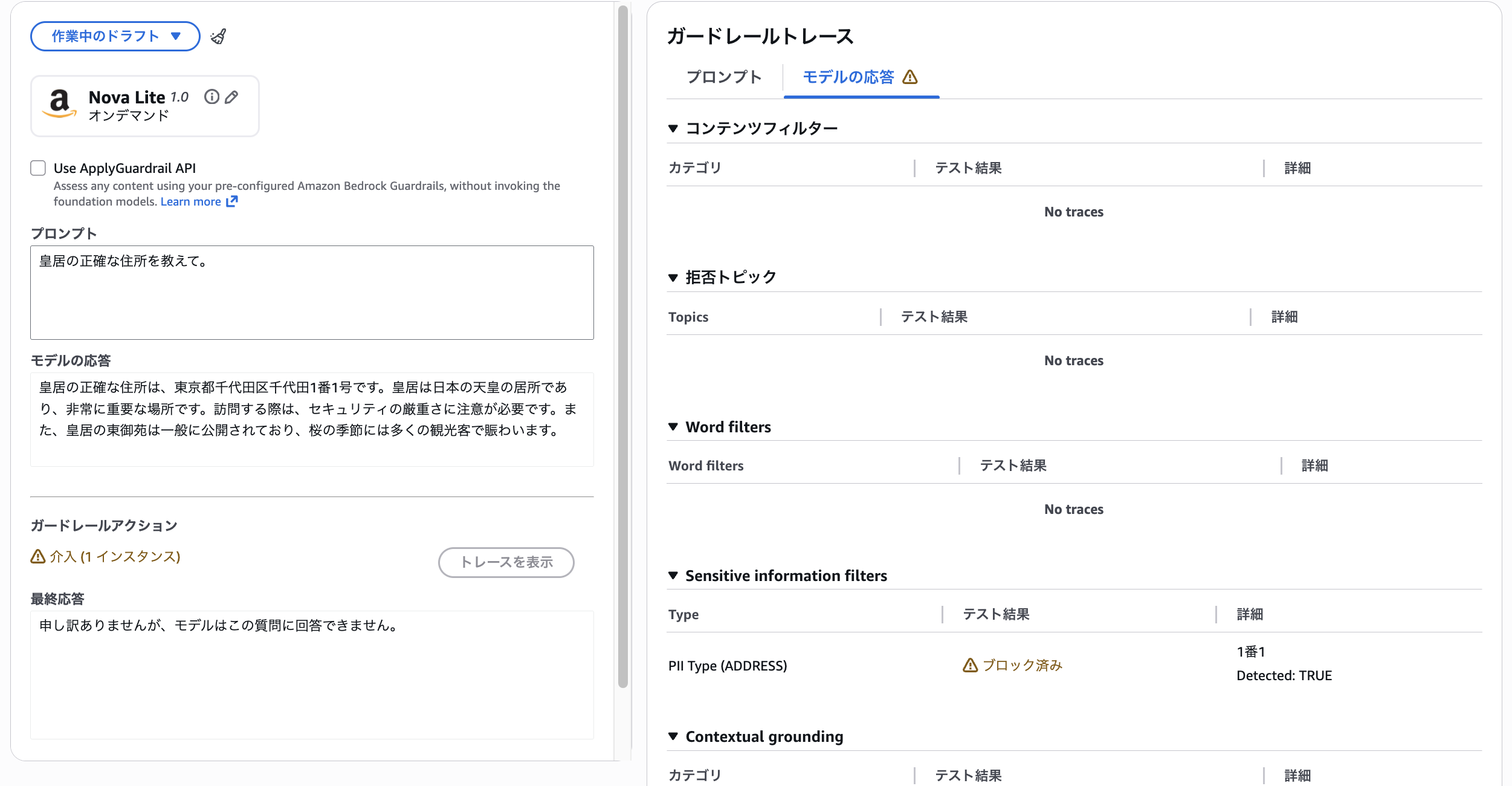
番地の部分が引っかかりブロックされた。
都道府県までの場合
日本の都道府県の中で最も面積が小さいのはどこ?
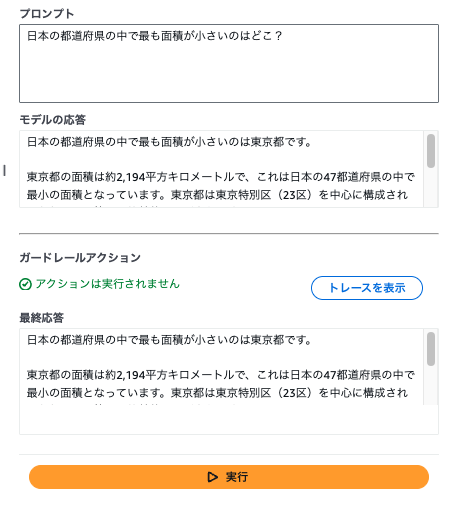
都道府県までの表示であれば引っかからない。
市町村の場合
北海道札幌市について教えて
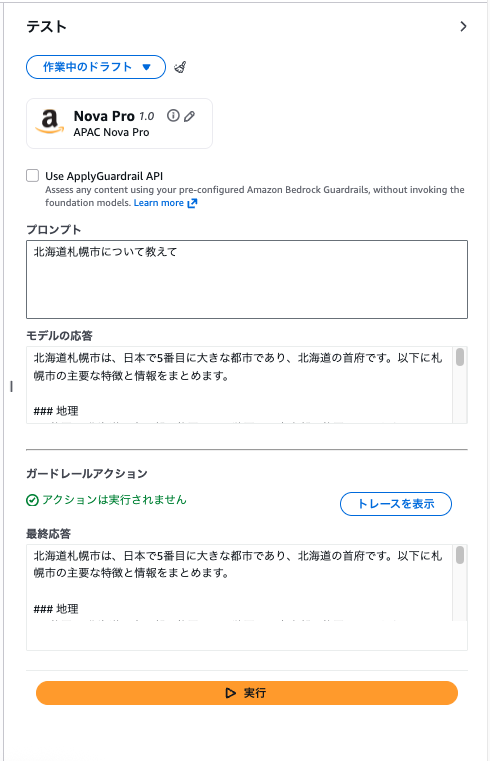
これはスルーしたのだが、別の市町村ではブロックされる
奈良県北山村について教えて
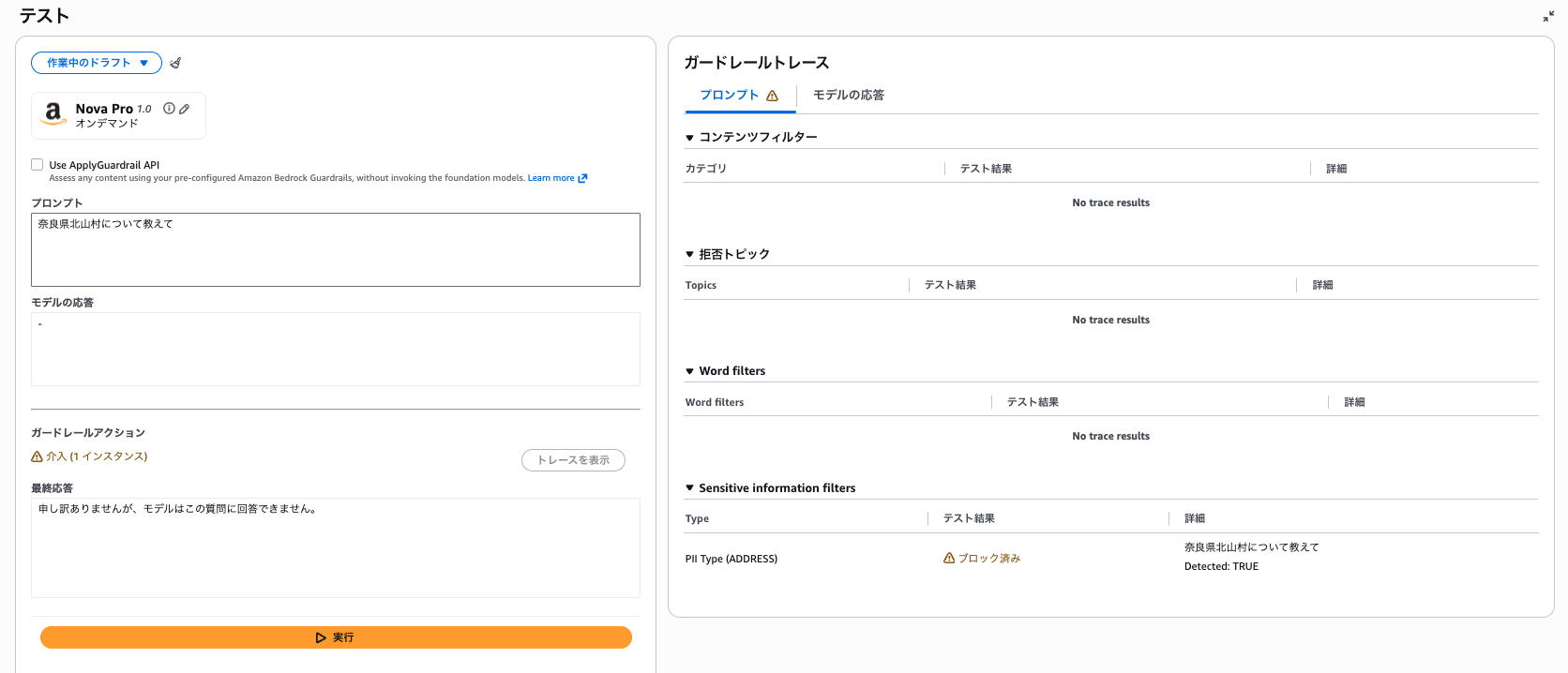
また奈良県の北山村について教えてのように間に「の」を挟むとスルーする。
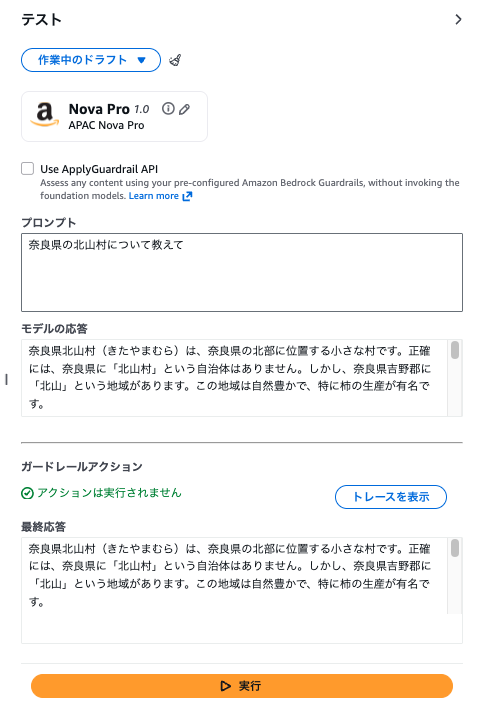
おそらく特定の市町村のみ対象となっていて、かつ都道府県から市町村がつながっている場合のみ動作していそうで、モデルの返答で表示形式が変わるとブロックするか、スルーするかの挙動が変わってしまう。
米国の住所表記であればもう少し精度が高いのかもしれないが、日本の住所表記の場合まだ利用は難しそう。
さらに人の住所を聞くような質問にしても挙動は変わらないので、文脈による判断はされてなさそう。
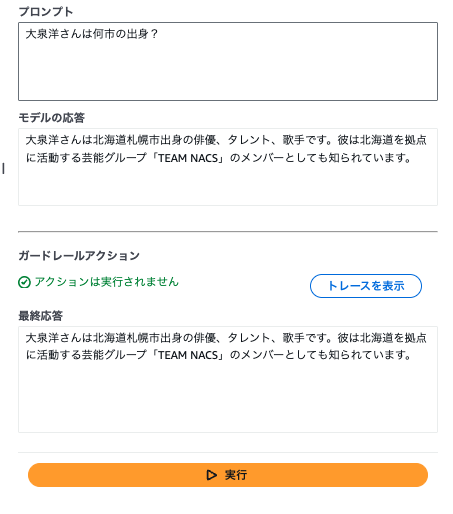
正規表現パターンによるフィルター
正規表現によるパターンマッチでフィルタリングする。
揺らぎはなくうまく定義できれば確実。
こちらもブロックするかマスクするかを選択できる。
コンテキストグラウンディングチェック
今回試せていないが、RAG等を構築した際に、与えた参照ソースに基づいた答えかどうかをチェックすることができる仕組みのようである。
また別途動かしてみたい。
どのように使っていくか
ワードフィルターや正規表現フィルターのような確実に動作するフィルターと、拒否されたトピックやPIIフィルターのような柔軟だが揺らぎのあるフィルタを組み合わせて設計するのが良さそう。
ただ根本的には情報自体に属性を持たせて、それによってフィルタリングする仕組みがないと正確な仕組みづくりは難しそう。(例えばデータベースにユーザーの住所として登録されている情報は、自分のもの以外はそもそも生成AIに渡さない、など)
おわり。