背景_アプリ製作の動機
・スプレッドシートで ImportXML を主に使っていた
・Qiitaのまとまった情報がほしいと思った
・技術系のサイトであればAPIがあるんじゃないか
と思い 調べるとやはりあった
・QiitaAPI があり
それを使えば リクエスト数 を1/10くらいに減らせそう
ということを知った
・GAS で fetch を使ったら通常とは違うタイプの警告が出た
・自分は通信周りがあまり詳しくないので
通信周りの処理は下手に触りたくない
・通信周りを学習するか既存の知識でどうにかするか悩む
・既存の知識としては そこそこなじみ深い C# を使い
ブラウザ上でリクエスト済みのファイルに対して
クローム拡張 を作ってどうにか出来ないか考えた
・クローム拡張は未だ1個しか作ったことが無い
・結局 既存の知識でどうにかすることにした
・とりあえず動くものが出来たので投稿することにした
背景_記事を投稿しようと思った動機
・Qiitaはよく使っていたので自分も何か投稿したいと思っていた
・ブログに書く という選択肢もあったが
PGの話はその界隈で出力した方が良いと思った
・Qiitaのアカウントを作ると他人をミュート出来る機能が使えるようになるらしいので
最悪それに任せれば良いのでは と思った
想定読者 または 希望読者
・C# と 簡単なweb制作 にそこそこ馴れている
・通信周りに詳しくない が 自分のクロームは信用している
・コードをちゃんと読んで理解してから実行できる
・記事の内容に関して自己責任を負える
・情報の非対称性 に関する理解がある
アプリで出来ること
アプリがちゃんと機能すると 以下のようなものが出来る
クエリの条件は 確か tag:WPF と 投稿日時でソート という条件だったと思う
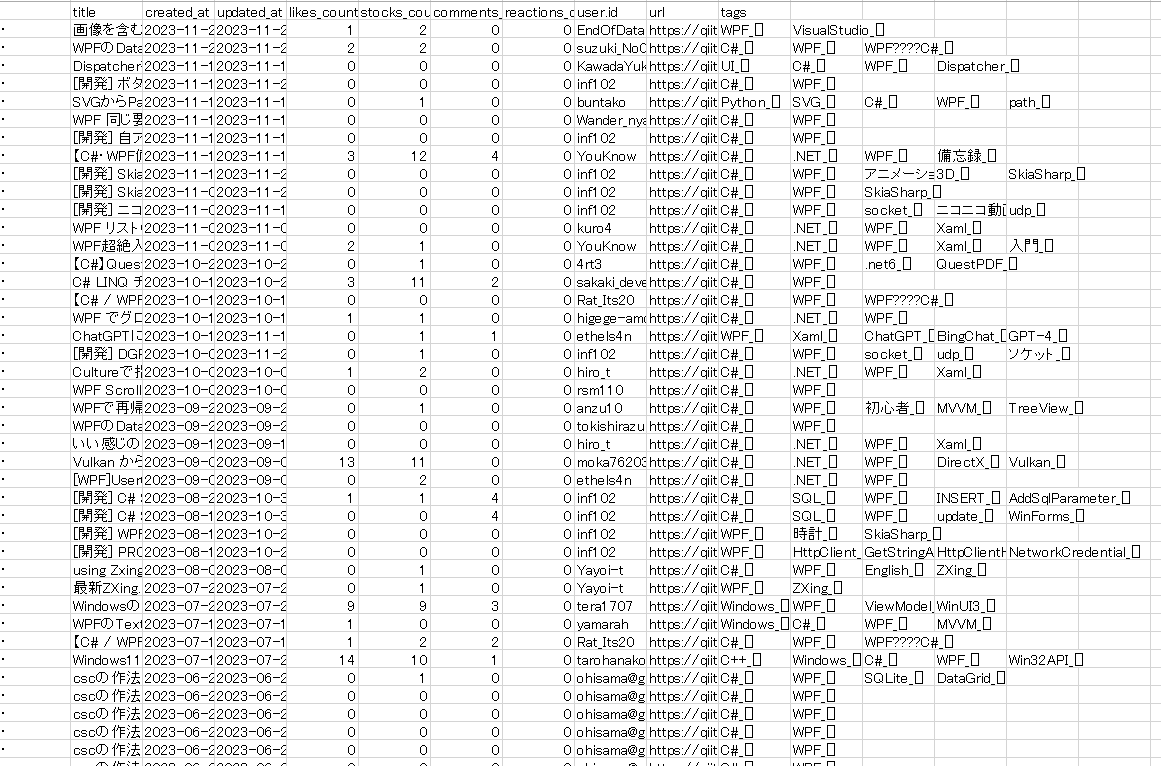
実際にはアプリでは csvファイル が出来るんだが
上記はそれを エクセルに張り付けて カンマ区切り したもの
WPF は Python とかと比べるとだいぶ記事数が少ないので ほとんど全部 すぐに取得できる
記事数が多いものを取得する場合は サーバーへの負荷などに注意して 自己責任 で
コード_概要
・フォームアプリ上で入力
・URL:必須
・ページ数:任意
(ページ数が適当だと 不要なファイルが一つ生成される)
↓
・Downloadボタンをクリック
↓
・既定のブラウザで URL を1個ずつ開いていく処理が始まる
↓
・URL が QiitaAPI の場合にクローム拡張が実行され以下の処理を実行:
・自身以外の QiitaAPI のページを開いているタブを削除
・リクエストの結果であるhtmlからjson文 を読み取り
jsonファイルとしてダウンロードする
・フォームアプリはダウンロードフォルダを監視し
アプリ実行後にjsonファイルが生成されたのを検知すると
次のURLを開く
↓
・最初に設定したページ数だけ 繰り返し
・停止条件:
・指定したページ数分の処理が終わる
・指定したページが存在しない
・ページ数が100を超える
・その他 例外が発生する
コード_本体
クローム拡張
-manifest.json
{
"name": "Jsonをダウンロード",
"manifest_version": 3,
"version": "1.0",
"background": {
"service_worker": "background.js"
},
"content_scripts": [{
"matches": ["https://qiita.com/api/v2/items?*"],
"js": ["script.js"]
}],
"permissions": [
"tabs"
]
}
-script.js
function DownloadText(text , title) {
let blob = new Blob([text], { type: "text/plain" });
let link = document.createElement('a');
link.href = URL.createObjectURL(blob);
link.download = title + '.json';
link.click();
}
DownloadText(
document.querySelector('html > body > pre').innerText ,
new Date().toISOString().replace(":","_")
);
-backgroung.js
chrome.tabs.onCreated.addListener(
tab_current =>
{
const str_url = "https://qiita.com/api/v2/items?";
if(tab_current.url.includes(str_url))
{
chrome.tabs.query({}, tabs =>
{
var tabs_target =
tabs.filter(
(tab) => tab.url.includes(str_url) && (tab.id !== tab_current.id)
).map(
(tab) => tab.id
);
while(tabs_target.length > 0){
chrome.tabs.remove(tabs_target.pop());
}
});
console.log("Done");
}
});
フォームアプリ
-Form1.cs
using MyLibrary;
using MyLibrary.Json;
using System.Text.RegularExpressions;
namespace Json_Converter
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
this.InitializeField();
}
protected MyLibrary.Json.Type ArrayType { get; set; }
protected HashSet<string> Hash_Name { get; set; }
protected string path_download { get; set; }
// Hard Coding
protected void InitializeField()
{
this.textBox1.Text = "https://qiita.com/api/v2/items?per_page=100&page=????&query=tag:QiitaAPI";
this.textBox2.Text = "101";
this.ArrayType = MyLibrary.Json.Type.Qiita;
this.path_download = @"";
this.Hash_Name =
new HashSet<string>()
{
"title",
"created_at",
"updated_at",
"likes_count",
"stocks_count",
"comments_count",
"reactions_count",
"user.id",
"url",
"tags"
};
}
private void Button_Download_Click(object sender, EventArgs e)
{
var str_url = this.textBox1.Text;
if (!str_url.Contains("????")) { MessageBox.Show("check ????"); return; }
var count_page = int.Parse(this.textBox2.Text);
var br = new Browsing(str_url, count_page, path_download);
this.ReadAndWrite(
br.HashSet_File_Downloaded_Main,
path_download +
$"{Regex.Replace(DateTime.Now.ToString(), "[/,:, ]", "_")}" +
".csv"
);
this.BringToFront();
MessageBox.Show("Finished");
}
private void Button_Convert_Click(object sender, EventArgs e)
{
var str_fullpath_read = @"";
var str_fullpath_write = @"";
this.ReadAndWrite(
new DirectoryInfo(str_fullpath_read).EnumerateFiles(),
str_fullpath_write
);
}
public void ReadAndWrite(
IEnumerable<FileInfo> files,
string str_fullpath_write
)
{
var writer = new StreamWriter(str_fullpath_write);
writer.WriteLine("," + string.Join(',', Hash_Name));
files.ForEach_Mine(
file =>
JsonToCSV.Create(
file.FullName ,
this.Hash_Name ,
this.ArrayType
).List_Value.ForEach_Mine(
text => writer.WriteLine(text)
)
);
writer.Flush();
writer.Close();
}
}
}
-Browsing.cs
using System.Diagnostics;
namespace MyLibrary.Json
{
internal class Browsing
{
public HashSet<FileInfo> HashSet_File_Downloaded { get; protected set; }
protected int Time_Sleep { get; set; } = 5000;
protected int FileSize_FailedRequest { get; set; } = 200;
public Browsing(
string str_url,
int count_page,
string path
)
{
var count = 0;
var time_start = DateTime.Now;
for (int i = 1; i <= count_page; i++)
{
Process.Start(
new ProcessStartInfo()
{
FileName = str_url.Replace("????", "" + i),
UseShellExecute = true
}
);
while (count < i)
{
Thread.Sleep(this.Time_Sleep);
this.HashSet_File_Downloaded =
new DirectoryInfo(path).EnumerateFiles().Where(
file => file.CreationTime > time_start
).Where(
file => file.Extension == ".json"
).ToHashSet();
count = this.HashSet_File_Downloaded.Count;
{
var count_badrequest =
this.HashSet_File_Downloaded.Where(
file => file.Length < this.FileSize_FailedRequest
).Count();
if (count_badrequest != 0)
{
return;
}
}
}
}
}
public HashSet<FileInfo> HashSet_File_Downloaded_Main =>
this.HashSet_File_Downloaded.Where(
file => file.Length >= this.FileSize_FailedRequest
).ToHashSet();
}
}
-JsonToCSV.cs
using System.Text.Json;
namespace MyLibrary.Json
{
public class JsonToCSV
{
public JsonElement Root { get; protected set; }
public HashSet<string> Hash_Name { get; protected set; }
public IEnumerable<string> List_Value { get; protected set; }
protected JsonToCSV(string str_fullpath , HashSet<string> hash_name)
{
var str_json = new FileInfo(str_fullpath).OpenText().ReadToEnd();
this.Root = JsonDocument.Parse(str_json).RootElement;
this.Hash_Name = hash_name;
this.Set_List();
}
protected void Set_List()
{
this.List_Value =
this.Root.EnumerateArray().Select(
obj =>
"・," +
string.Join(
',',
this.Hash_Name.Select(
str =>
this.Get_Prop(obj, str)
)
)
);
}
protected string Get_Prop(JsonElement target, string str_name)
{
var prop = this._Get_Prop(target, str_name);
return
(prop.ValueKind == JsonValueKind.Array) ?
this.Get_Prop_Array(prop) :
prop.ToString().ReplaceAll(",", "????");
}
protected JsonElement _Get_Prop(JsonElement target, string str_name)
{
var list_str = str_name.Split('.');
var prop = target.GetProperty(list_str.First());
for (int i = 1; i < list_str.Length; i++)
{
prop = prop.GetProperty(list_str[i]);
}
return prop;
}
protected virtual string Get_Prop_Array(JsonElement prop)
{
return
string.Join(
"_&_",
prop.EnumerateArray()
);
}
public static JsonToCSV Create(string str_fullpath, HashSet<string> hash_name , Type type)
{
switch (type)
{
case Type.Default:
return new JsonToCSV(str_fullpath, hash_name);
case Type.Qiita:
return new Qiita_00(str_fullpath , hash_name);
case Type.Other:
break;
default:
break;
}
return null;
}
}
static class Extension
{
public static string ReplaceAll(this string str_target, string str_before, string str_after)
{
var str_result = str_target;
while (str_result.Contains(str_before))
{
str_result = str_result.Replace(str_before, str_after);
}
return str_result;
}
}
public enum Type
{
Default , Qiita , Other
}
class Qiita_00 : JsonToCSV
{
public Qiita_00(string str_fullpath, HashSet<string> hash_name) : base(str_fullpath, hash_name) { }
protected override string Get_Prop_Array(JsonElement target)
{
return
string.Join(
",",
target.EnumerateArray().Select(
obj =>
{
var name = obj.GetProperty("name").ToString().ReplaceAll(",", "????");
var version = obj.GetProperty("versions");
return
$"{name}_{version}";
}
)
);
}
}
}
・独自拡張メソッド:
・ForEach_Mine
例外
| 内容 | 処理 | |
|---|---|---|
| ・ | page=???? の ???? が付いていない | メッセージ:"check ????" |
| ・ | ページ数 が 超過している | return |
| ・ | URL が間違っている | 未 |
| ・ | サイト名が違う | 未 クローム拡張が反応しない |
| ・ | jsonのプロパティが存在しない | MS例外 |
| ・ | アプリの処理中に新しいjsonファイルまたはtxtファイルを別にダウンロードする | 未 |
| ・ | アプリの処理中にアプリがダウンロードしたファイルを消す | 未 アプリがファイルを使用中なので たぶん消せない と思う |
| etc |
ハマったところ または 注意したところ
・クローム拡張のエラー画面を開きっぱなしにした状態で
更新ボタンを押すと 更新前のエラー画面が残り続ける
ので 手動でクリア してから更新するか
一度画面を離れるなどして確かめる必要がある
・querySelector() は
popup.html がある場合
popup.html の方を取得する
・QiitaAPI は # がついていると若干動作が変わる
・QiitaAPI は
pageが100未満でページが存在しない場合は
空のjsonを返すが
pageが100以上の場合は
Bad request を返す
・Qiita では タグに対して versions を指定できるらしい
しかし versions は一般ユーザーが見ることも出来ない
そして json においては Array として表現されている
・Windows では ファイルをダウンロードするときに一時ファイルを作る
ので ダウンロードフォルダを監視するときは
一時ファイルを読み込まないようにする必要がある
・array に対する pop()メソッド は
配列自体を変更して戻り値を返す
ので 若干 注意が必要
etc
つぶやき
・「このケースでは fetch を使えばどうにかなる」
「fetch は使っても問題が無い」
この二点さえわかればどうにかなるのだろうけども
素人はこれがわからないから歯がゆい思いをする
・n:=count(少し調べればわかること) を
n→∞ にすると人間は死ぬ
・知らなくても対処できることはあるが
知らないで自作し続けることと調べて新しい世界に行く場合の
分岐点の分析 が難しい
・コード自体は割とすぐに出来たけど
Qiitaに投稿するための時間の方が長かった気がする
割合としては 3:7 くらい????
etc
引用について
・Qiita公式 では 引用についてはやったほうが良いとあるんだが
例えば document.querySelector() みたいな汎用性の高い文に関していちいち調べたソースを示していたら 投稿者にとってはかなりの負担になる
それに対して ある大きなライブラリを使っている場合はたしかにソースを示した方が良いとは思う
中間にあるものとして ある一つのメソッド などはどうすれば良いのか悩みどころな気がする
スクレイピングについて
・Qiita は スクレイピング を禁止しているらしい
・スクレイピング とは webページから 情報を抽出する行為 と認識している
・ブラウザ上でAPIファイルをレンダリングすることも webページからの情報抽出と同じようなものな気がする
・Qiita はAPIを提供している
・スクレイピングがダメとされる一般的な理由の一つにサーバーの負荷というのをよく聞く
・なので APIリクエストを短期間に大量に送ることも問題となりs
etc
・これで良かったのか?感が拭え切れない
Qiita_Tag_Detail
{
"App" : ["フォームアプリ" , "クローム拡張"],
"Lang" : ["C#","CSharp","VisualC#","Javascript","HTML","JSON"],
"Format" : ["json","csv","html","js","cs"],
"All" :
[
"フォームアプリ" , "クローム拡張",
"C#","CSharp","VisualC#","Javascript","HTML","JSON",
"json","csv","html","js","cs",
"Windows",
"Visual Studio",
".NET Framework",
"System.Windows.Forms",
"System.Diagnostics",
"System.Text.RegularExpressions",
".NET",
"System.Text.Json",
"chrome API",
"chrome-extension",
"DOM","Web API"
]
}