はじめに
先日、Open Hack U 2025 KANAZAWAというLINEヤフーさんが開催している学生ハッカソンへ参加してきました。
詳細は以下のWebサイトに掲載されていますので詳細はこちらをご覧ください。
そこで発表した作品について、今回は作品の概要とその具体的な仕組みを、細かく紐解きながら説明していきたいと思います。
今回、短期間で作る必要があったため、かなりの部分をAIに頼って書きました。そのため、コードの詳細理解をするためにこの記事を書くこととしました。
Chromeウェブストアにて拡張機能が公開されました!
是非ご活用の上、ご指摘等していただけますと幸いです。
https://chromewebstore.google.com/detail/invert-pdf-viewer/klndmcomjnjmcappeiibgklmlhdcihhe?hl=ja
今回使用したコードについては以下のGitHubにまとめてありますのでそちらもぜひご覧ください。
https://github.com/Sekainokanata/PDFDARK
この記事では、順に
- システムの発想
- ファイル構造
- viewerフォルダ外のコード
- viewerフォルダ内のコード
という流れで解説していこうと思います。
使った言語や技術等+著作権表示
HTML,CSS,JavaScript,PDF.js,OpenCV.js
=== PDF.js ===
Copyright © Mozilla Foundation and contributors.
Licensed under the Apache License, Version 2.0.
See http://www.apache.org/licenses/LICENSE-2.0 for the full license text.
=== OpenCV.js ===
Copyright © 2000–2025 OpenCV team.
Licensed under the Apache License, Version 2.0.
See http://www.apache.org/licenses/LICENSE-2.0 and https://opencv.org/license/ for details.
作成したアプリケーションについて
今回作成したアプリケーションは、PDFの完全ダークモード化を実現しようとするChrome拡張機能です。現状、今までのPDFリーダーはダークモード設定にしても画像の色まで反転してしまっていました。
そこで、新たに写真が反転しないようにした、新たなPDFリーダーを作成しようと考えました。
しかし、PDFのままではどこに画像があって、どこにテキストがあるかを判別するのが難しいというのが現状です。
そこで、PDF→SVGへ変換することによってテキストと画像の位置が割り出せるのではないかと考えました。つまり、今回作ったのは正確に言うと SVGビュワーということになります。SVGであれば、PDFのベクター情報を落とすことなく表示できるため、PDFビュワー「もどき」としては最適であると考えました。
SVGにするとテキストと画像の位置が分かるとは?
まず、こちらをご覧ください。
以下に用いてる画像はUI改善前(ハッカソンで出した際のもの)です。
後述するui.jsではより洗練されたUIになっています。
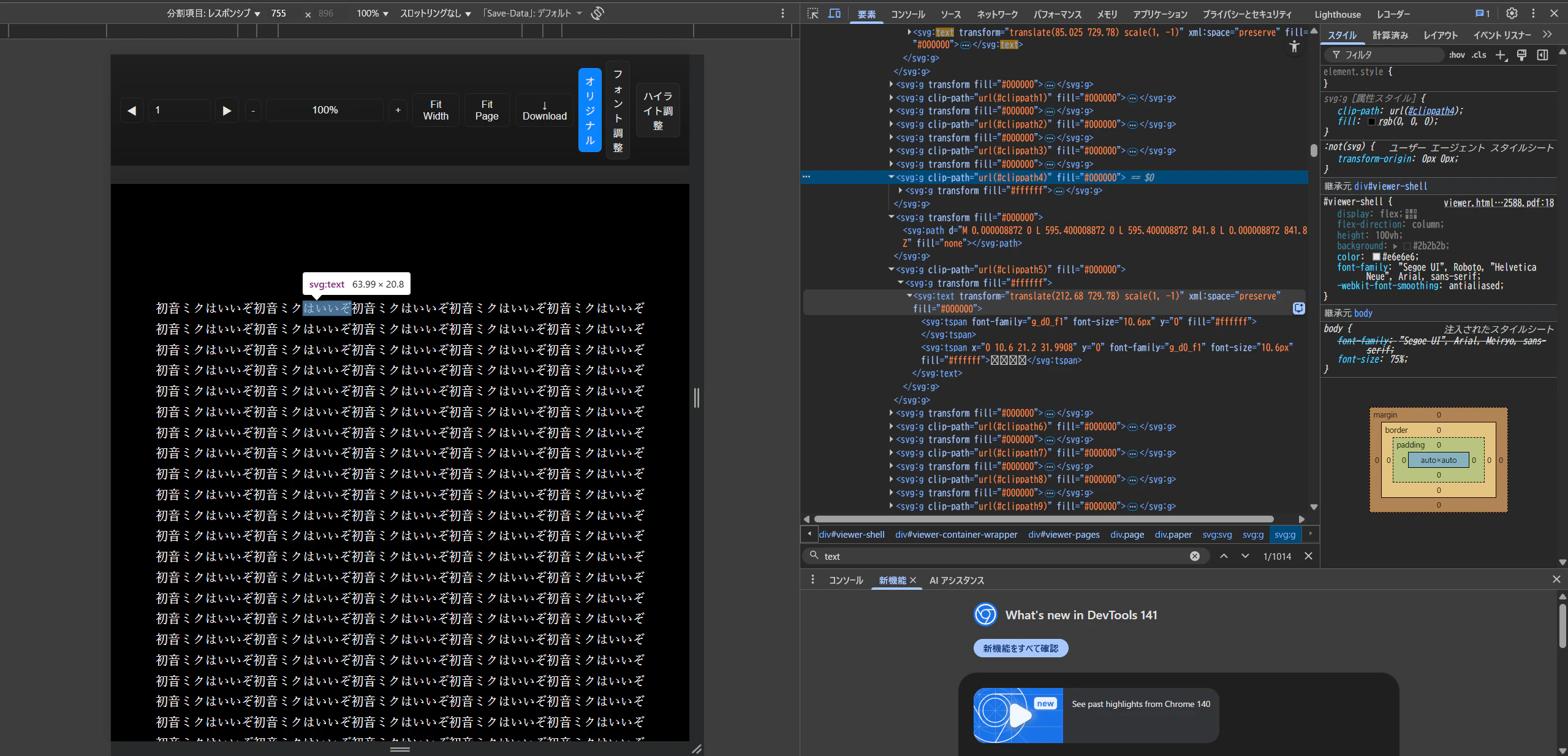
この画像は、拡張機能を有効にした状態で要素を覗いてみたものです(つまり、SVGの中身を覗いているものに相当します)。このように、テキスト部分に「svg:text」タグが付いており...
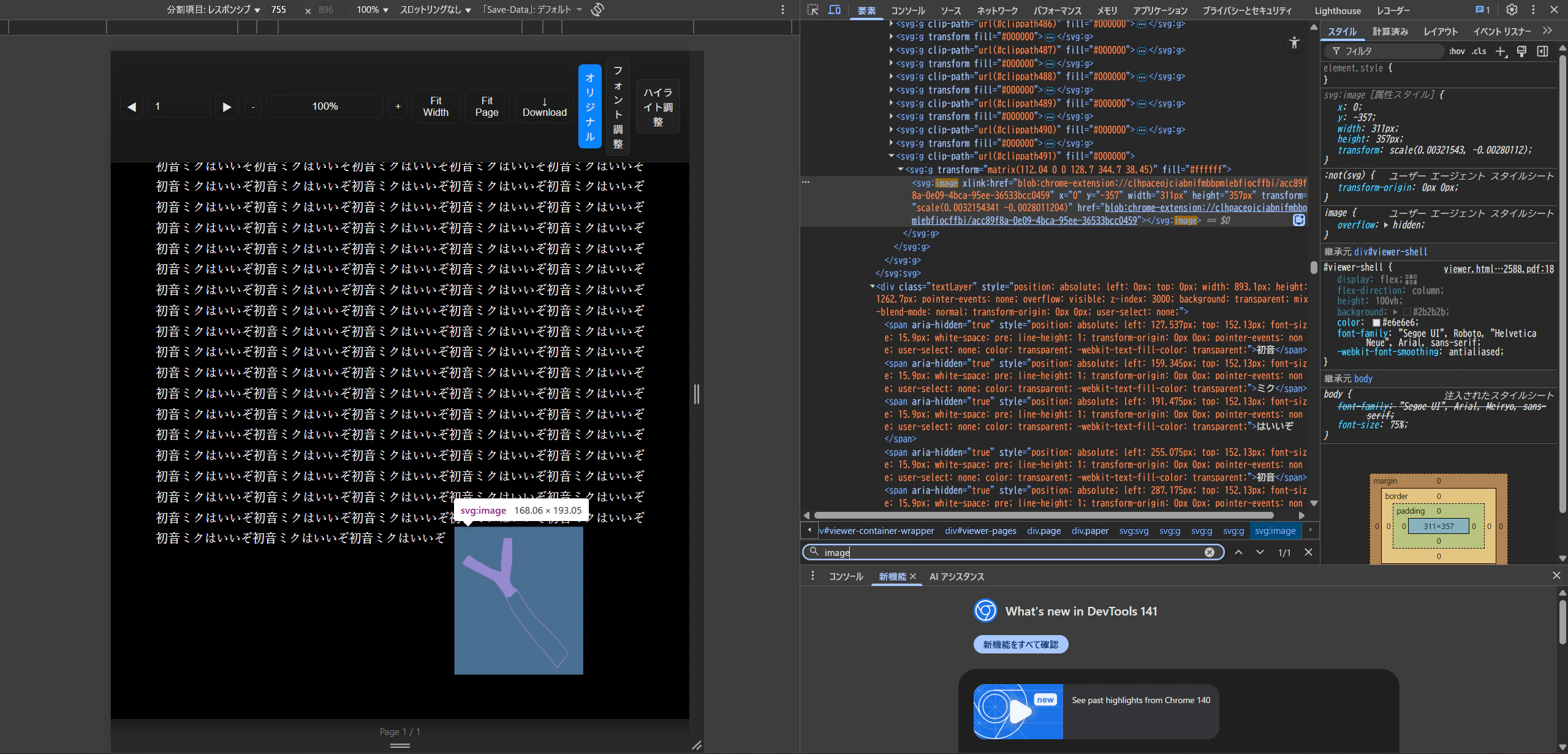
画像部分には「svg:image」タグが付いています。
これによってテキストと画像の位置の取得が簡単にできます。
ダーク化システムの構造
この拡張機能は、以下のような仕組みとなっています。
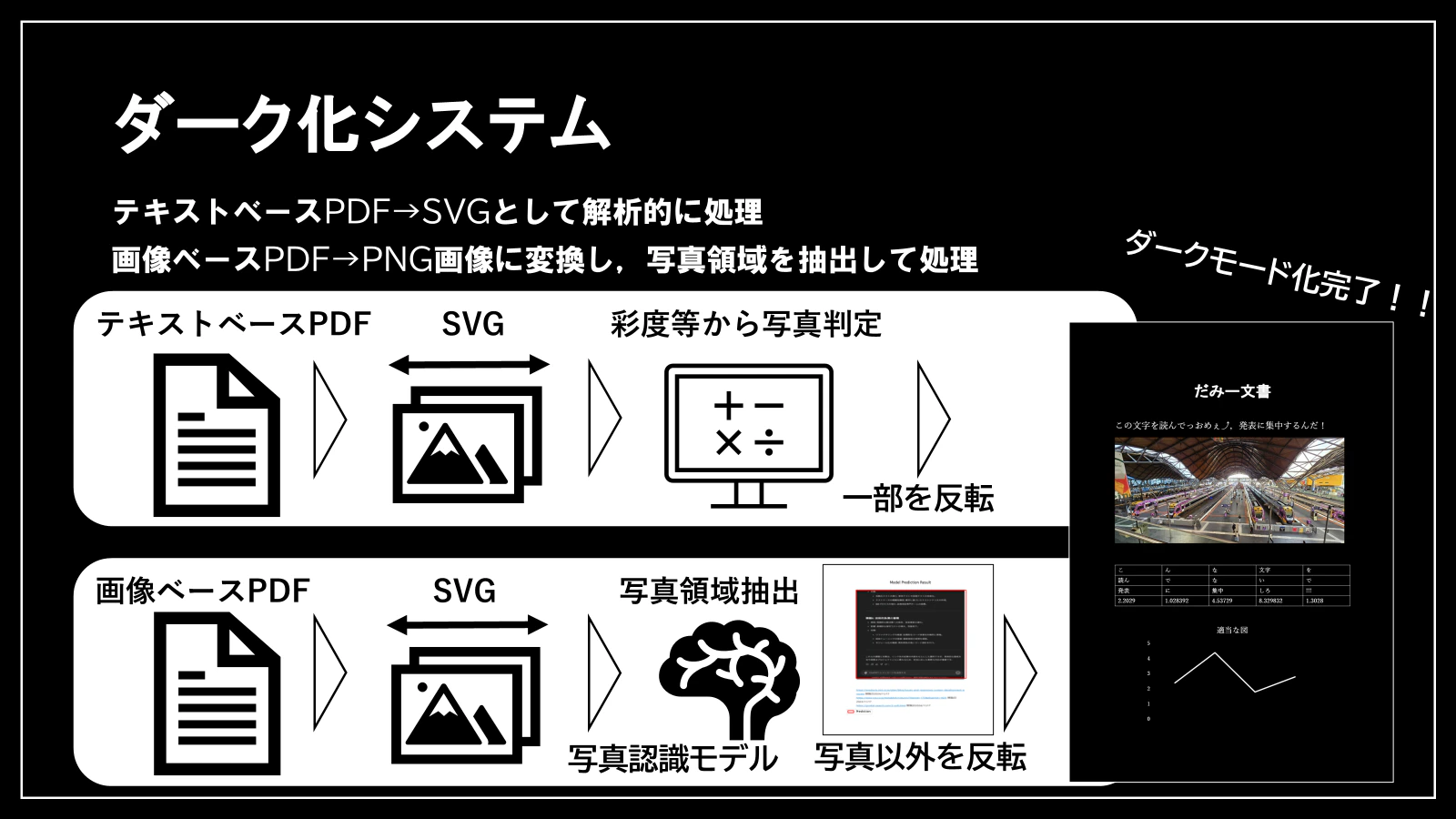
テキストベースPDF(普通にWord等からPDFへ変換したタイプのPDF)の場合、SVGへ変換します。すると、上記の通り「image」タグと「text」タグを抽出することが出来ます。背景色と「text」を反転させたうえで、「image」は彩度等から判断して、グラフであれば反転せず、写真であれば反転するという処理を行っています。
また、ハッカソンの際にだした作品では、画像ベースPDF(ページ丸ごと画像一枚で構成されているPDF)の場合、SVGをPNG変換して、それを写真領域の抽出ができる機械学習モデルに入力して、その出力として得られる座標の内側(写真があると推測された領域)のみを反転させないという仕組みにしていました。
ただし、結局推測にかなり時間がかかるのと、精度を向上させるのが難しかった為、別の手法を取ることにしました。
具体的にはOpenCVをもちいて画像の中から写真を見つけ出すという手法です。詳しくは後述します。これによって、きわめて精度が高くかつ素早く写真領域を特定することが可能になりました。
システム解説~ファイルを読み解こう~
まず、全体のファイル構成を以下に示します。
PDFDARK/
├ pdfjs/
│ └ pdf.js
│ └ pdf.worker.js
│ └ cmaps/
│ └ *.bcmap(多数のファイル)
├ sandbox/
│ └ opencv.html
│ └ opencv.js
├ vender/
│ └ opencv/
│ └ opencv.js
│ └ opencv_js.wasm
├ viewer/
│ └ copy-control.js
│ └ darkmode.js
│ └ download.js
│ └ highlight.js
│ └ image-process.js
│ └ main.js
│ └ page-render.js
│ └ scroll.js
│ └ shell.js
│ └ svg-invert.js
│ └ text-layer.js
│ └ text-mode.js
│ └ toolbar.js
│ └ zoom.js
├ background.js
├ icon48.png
├ manifest.json
├ viewer-run.js
├ viewer.html
├ popup.html
├ popup.js
├ popup.css
└ style.css
では、まず外側の各ファイルの働きから見ていきましょう。
ただし、css及びmanifest.jsonについては解説を省きます。時間があればのちに別の記事で詳しく解説をしようと考えております。
1.プロジェクトルート直下のファイル
viewer.html
プログラムは以下の通りになっています。
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<!-- モバイル等でのページズームを抑止し、内部ズームに一本化 -->
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no" />
<title>シロクロクローバ</title>
<!--<link rel="stylesheet" href="viewer.css">-->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<div id="container">Loading PDF…</div>
<!-- 1) pdf.js 本体 -->
<script src="pdfjs/pdf.js"></script>
<!-- 2) 分割した viewer スクリプト群 -->
<script src="viewer/scroll.js"></script>
<script src="viewer/ui.js"></script>
<script src="viewer/renderer.js"></script>
<script src="viewer/toolbar.js"></script>
<script src="viewer/main.js"></script>
<script src="viewer-run.js"></script>
</body>
</html>
head部では、そのまま「文字セット」の指定、タイトルの設定、処理中の際の表示、そしてCSSファイルの読み込みを行っています。
次に、body部では各種JSを読み込んでいます。
ここで大事なのが、「OpenCV.jsはここで読み込んではいけない」ということです。
これはChrome拡張機能に課されたManifest V3によるものです。具体的な理由は不明ですが、おそらくOpenCV.jsによる動的コード生成が悪さをしているような気がします。どちらにせよ、OpenCVに関しての処理はsandbox側で行う必要があります。
viewer-run.js
以下のようなコードになっています。
// viewer-run.js
// worker のパスを拡張内のファイルに合わせる
pdfjsLib.GlobalWorkerOptions.workerSrc = chrome.runtime.getURL('pdfjs/pdf.worker.js');
// 拡張機能の有効/無効状態をチェック
async function checkExtensionEnabled() {
try {
const result = await chrome.storage.local.get(['pdfViewerEnabled']);
return result.pdfViewerEnabled !== false; // デフォルトはON
} catch (e) {
console.warn('Could not check extension state:', e);
return true; // エラー時はデフォルトON
}
}
document.addEventListener('DOMContentLoaded', async () => {
// 拡張機能が無効の場合、元のPDF URLにリダイレクト
const enabled = await checkExtensionEnabled();
if (!enabled) {
const params = new URLSearchParams(location.search);
const originalPdfUrl = params.get('file');
if (originalPdfUrl) {
console.log('PDF Dark Viewer is disabled. Redirecting to original PDF:', originalPdfUrl);
// 元のPDF URLにリダイレクト
location.replace(originalPdfUrl);
return; // startViewer を実行しない
}
}
if (typeof startViewer === 'function') {
startViewer().catch(e => {
console.error('startViewer error', e);
document.getElementById('container').textContent = 'Error: ' + e.message;
});
} else {
console.error('startViewer is not defined (viewer.js が読み込まれていない可能性あり)');
}
});
拡張機能自体をクリックするとポップアップ(下図)によって拡張機能のON/OFFを切り替えられるようにする為、有効か無効かの状態チェックを行っています。
ページ再読み込み時、有効状態であれば自動的に拡張機能が提供するビュワーに切り替わりますが、無効状態の場合はそうなりません。
ですので、無効状態の場合はもとのPDFファイルのURLへリダイレクトし直し、後述するmain.jsのstartViewerを実行しないようにすることで拡張機能のON/OFFを切り替えられるようにしています。
DOM要素へすべてアクセス出来るようになってから、JS等依存ファイルがきちんと読み込まれているか確認しています。ここで、startViewerは非同期関数なので.catch()でエラーの補足を行っています。
popup.html
拡張機能をクリックした際に出てくる、先ほど貼った画像のようなポップアップを表示する為のものです。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="/popup.css">
</head>
<body>
<div class="header">
<img src="images/darkmode.png" alt="Icon">
<h1>PDF Dark Viewer</h1>
</div>
<div class="toggle-section">
<div class="toggle-container" id="toggleBtn">
<span class="toggle-label">自動PDF変換</span>
<div class="toggle-switch" id="toggleSwitch"></div>
</div>
<div class="status-text" id="statusText">読み込み中...</div>
</div>
<div class="info">
<strong>ON:</strong> PDFを自動的にダークモードビューアーで開きます<br>
<strong>OFF:</strong> 通常のPDFビューアーで開きます
</div>
<script src="popup.js"></script>
</body>
</html>
"toggle-section"で、トグルボタンの実装を行っています。
また、ON/OFFの際の説明も追記しています。
popup.js
コードは以下のようになっています。
// popup.js - ポップアップメニューのロジック
// 現在の有効/無効状態を取得
async function getExtensionState() {
const result = await chrome.storage.local.get(['pdfViewerEnabled']);
// デフォルトはON
return result.pdfViewerEnabled !== false;
}
// 状態を保存
async function setExtensionState(enabled) {
await chrome.storage.local.set({ pdfViewerEnabled: enabled });
}
// UI更新
function updateUI(enabled) {
const toggleSwitch = document.getElementById('toggleSwitch');
const statusText = document.getElementById('statusText');
if (enabled) {
toggleSwitch.classList.add('active');
statusText.textContent = '有効 - PDFを自動変換します';
statusText.className = 'status-text enabled';
} else {
toggleSwitch.classList.remove('active');
statusText.textContent = '無効 - 通常のPDFビューアーを使用します';
statusText.className = 'status-text disabled';
}
}
// トグル処理
async function toggleExtension() {
const currentState = await getExtensionState();
const newState = !currentState;
await setExtensionState(newState);
updateUI(newState);
// バックグラウンドスクリプトに通知(アイコン更新用)
chrome.runtime.sendMessage({
action: 'stateChanged',
enabled: newState
});
}
// 初期化
document.addEventListener('DOMContentLoaded', async () => {
const enabled = await getExtensionState();
updateUI(enabled);
// クリックイベント
document.getElementById('toggleBtn').addEventListener('click', toggleExtension);
});
いろいろとはありますが、主にトグルボタンを切り替えた際に、UIを更新したり、background.js等へ情報をわたすような役割をしています。
background.js
ここでは、つねにバックグラウンドで行うべき処理を書いています。
// 拡張機能の有効/無効状態を取得
async function isExtensionEnabled() {
const result = await chrome.storage.local.get(['pdfViewerEnabled']);
return result.pdfViewerEnabled !== false; // デフォルトはON
}
// アイコンの状態を更新
async function updateIcon() {
const enabled = await isExtensionEnabled();
const iconPath = enabled ? "images/darkmode.png" : "images/darkmode.png"; // 必要に応じてOFF用アイコンを別途作成可能
const title = enabled ? "PDF Dark Viewer (有効)" : "PDF Dark Viewer (無効)";
chrome.action.setIcon({ path: iconPath });
chrome.action.setTitle({ title: title });
}
chrome.runtime.onInstalled.addListener(async () => {
// 初期状態を設定(デフォルトON)
const result = await chrome.storage.local.get(['pdfViewerEnabled']);
if (result.pdfViewerEnabled === undefined) {
await chrome.storage.local.set({ pdfViewerEnabled: true });
}
await updateIcon();
});
// ポップアップからの状態変更メッセージを受信
chrome.runtime.onMessage.addListener((message, sender, sendResponse) => {
if (message.action === 'stateChanged') {
updateIcon();
}
});
// タブの情報(URLなど)が更新されたときに発火するイベントリスナー
chrome.tabs.onUpdated.addListener(async (tabId, changeInfo, tab) => {
if (changeInfo.status !== 'complete') return; // complete 以外は無視
const url = tab.url;
if (!url) return; // url が undefined の場合は何もしない
if (!url.match(/\.pdf(\?|$)/i)) {
return; // PDFじゃなければ無視
}
// 拡張機能が有効な場合のみビューアーで開く
const enabled = await isExtensionEnabled();
if (!enabled) {
console.log('PDF Dark Viewer is disabled. Skipping auto-conversion.');
return;
}
const viewerUrl = chrome.runtime.getURL("viewer.html") + "?file=" + encodeURIComponent(url);
chrome.tabs.update(tabId, { url: viewerUrl });
});
機能はコードのコメントに書いてあることが全てなのですが、ここでなにか疑問に思った方もいらっしゃるのではないでしょうか?
そう。viewer-run.jsと処理内容被っとるやん、と。
確かに、拡張機能が有効状態かどうか(ポップアップウインドウで切り替えられる奴)をチェックする構造が重複しています。
...君のような勘のいいガキは嫌いだよ
※Qiita執筆時にこの矛盾があることを気づき、現在ではURLパラメータで有効or無効状態を渡すようにしています。
2.viewerフォルダ内のJSファイル
さて、ここからはコード自体がとっても長くなるため、ものによっては少しずつコードを分けながら解説していきます。
copy-control.js
ここでは、コピーガード等の処理を行っています。
もとのPDFにコピーガードがされている場合、それを拡張機能側でも引き継ぐ機能を持っています。
主に二つの関数から成り立っています。
一つ目の関数、「detectCopyPermission」(非同期処理関数)のコードは以下のようになっています。
// コピー権限の検出とコピー操作のブロック
window.detectCopyPermission = async function detectCopyPermission(pdfDoc) {
//明確に COPY 権限が検出できた場合のみ true、それ以外は false 。
try {
const perms = await pdfDoc.getPermissions();
const Flag = (typeof pdfjsLib !== 'undefined' && pdfjsLib.PermissionFlag) ? pdfjsLib.PermissionFlag : {};
const COPY_FLAG = (Flag && typeof Flag.COPY === 'number') ? Flag.COPY : 16; // PDF.js 既定値のフォールバック
if (Array.isArray(perms)) {
// 数値フラグの配列を想定
const nums = perms.filter(v => typeof v === 'number');
if (nums.length > 0) {
const canCopy = nums.includes(COPY_FLAG);
return { canCopy, rawPerms: perms };
}
// 文字列等のフォーマットは非対応 → false
return { canCopy: false, rawPerms: perms };
}
// perms === null(非暗号 or 取得不能)でも false。
return { canCopy: false, rawPerms: perms };
} catch (e) {
console.warn('detectCopyPermission failed; returning canCopy=false', e);
return { canCopy: false, rawPerms: null, error: e?.message };
}
};
上記のpdfDocはmain.jsにある
const permInfo = await window.detectCopyPermission(pdf);
から呼ばれています。なお、ここにある変数pdfは以下のコードから来ています。
const loadingTask = pdfjsLib.getDocument({ data: arrayBuffer, cMapUrl: cMapUrlForExtension, cMapPacked: true, useWorkerFetch: true });
const pdf = await loadingTask.promise;
pdfjsLib.getDocumentが返す「PDFDocumentLoadingTask」はPDFの読み込み状態を管理しており、「.promise」をつけて待つと、正しくPDFが読み込まれた際にはPDFDocumentProxyを返します。
そして、
const perms = await pdfDoc.getPermissions();
によって、権限制御に関する配列を取得します。
PDFにコピー禁止が付いていない場合、配列に16(number型で、PDF.jsが規定値で返す値)が入っている筈です。
もし入っていない場合(number型以外であったり、配列がnullだった場合も)、コピー禁止であると判断しています。
次に、実際にコピー禁止にするためのロジックが2つ目の関数、「installCopyBlockers」 になります。
window.installCopyBlockers = function installCopyBlockers(rootEl) {
rootEl.style.userSelect = 'none';
rootEl.style.webkitUserSelect = 'none';
rootEl.style.MozUserSelect = 'none';
function onCopy(e) {
e.preventDefault();
try {
e.clipboardData.setData('text/plain', '');
}
catch (_) {}
return false;
}
document.addEventListener('copy', onCopy);
document.addEventListener('cut', onCopy);
const onContext = (e) => e.preventDefault();
rootEl.addEventListener('contextmenu', onContext);
return () => {
document.removeEventListener('copy', onCopy);
document.removeEventListener('cut', onCopy);
rootEl.removeEventListener('contextmenu', onContext);
rootEl.style.userSelect = '';
rootEl.style.webkitUserSelect = '';
rootEl.style.MozUserSelect = '';
};
};
rootElは、関数の呼び出し元が
removeCopyBlockers = window.installCopyBlockers(container);
となっており、このcontainerが
const container = ui.pagesHolder;
で定義されています。
uiはDOMコンテナ要素で、uiの初期化をしたものです。具体的な処理はshell.jsにあるため、ここでは省略します。
また、copyやcutのイベントリスナーを捕まえたうえで、removeすることによって、コピーまたはカットができないようになっています。
darkmode.js
ここでは、変換されたSVGを「ダークモード化」するためのロジックを書いています。
大きく分けると、ダークモードの有効化・無効化の状態を保存する為の処理と、関数ensureDarkModeToggleと非同期関数__viewer_applyDarkModeの3要素となります。
まず、一つ目のダークモードの有効化・無効化の状態を保存する為の処理が以下のようになっています。
if (typeof window.__viewer_darkModeEnabled === 'undefined') {
// localStorageから読み込み(初回起動時はON)
try {
const saved = localStorage.getItem('viewerDarkMode');
if (saved !== null) {
window.__viewer_darkModeEnabled = saved === 'true';
} else {
// 初回起動時はデフォルトON
window.__viewer_darkModeEnabled = true;
}
} catch(_) {
window.__viewer_darkModeEnabled = true; // localStorageが使えない場合もON
}
}
ようはlocalStorageに状態を保存しており、localStorageにデータがない、あるいは使えない場合は立ち上げ直後にダークモードがONになるように設定しています。
次に、ボタンを押したときの挙動に関する関数です。
window.ensureDarkModeToggle = function ensureDarkModeToggle(ui){
ui = ui || window.__viewer_ui;
if (!ui || !ui.btnDarkmode)
return;
const btn = ui.btnDarkmode;
if (btn.__dm_wired)
return;
const updateUi = () => {
btn.title = window.__viewer_darkModeEnabled ? 'ダークモード: ON' : 'ダークモード: OFF';
// ON のとき他のトグル同様に青く表示
btn.style.background = window.__viewer_darkModeEnabled ? '#0a84ff' : '';
};
btn.addEventListener('click', () => {
// 状態を反転しlocalStorageに保存
window.__viewer_darkModeEnabled = !window.__viewer_darkModeEnabled;
try {
localStorage.setItem('viewerDarkMode', window.__viewer_darkModeEnabled);
} catch(_) {}
// ダークモードを適用
try {
if (typeof window.__viewer_applyDarkMode === 'function') {
window.__viewer_applyDarkMode(window.__viewer_darkModeEnabled);
}
}
catch(_) {}
updateUi();
});
updateUi();
btn.__dm_wired = true;
};
基本的には、ボタンが押されたらbackgroundを青色(選択状態又は有効化状態)に設定し、そのあとの__viewer_applyDarkMode関数につなげています。
この関数については、詳しい説明等特段書くことはないのですが、一点だけ見慣れない書き方があったので紹介します。以下の部分です。
ui = ui || window.__viewer_ui;
どうやらこれは、関数の引数「ui」の中身がなかった(渡されていない)場合に、代わりにwindow.__viewer_uiを代わりに用いる、という処理らしいです。その次でuiのなかみがない、又はbtnDarkmodeプロパティがなければreturnするという流れになっています。
そして、次に説明するのが実際にダークモード化を行う非同期関数 __viewer_applyDarkMode なのですが、非常に長い関数の為、少しづつわけて掲載&説明をしていこうと思います。
window.__viewer_applyDarkMode = async function __viewer_applyDarkMode(enabled){
try {
const holder = (window.__viewer_ui && window.__viewer_ui.pagesHolder) || document.getElementById('viewer-pages');
if (!holder) return;
const pages = holder.querySelectorAll('.page');
// 現在のモード(overlay/svg)を取得
let currentMode = 'svg';
try {
currentMode = localStorage.getItem('viewerTextMode') || 'svg';
}
catch(_) {}
pages.forEach(pageDiv => {
const paper = pageDiv.querySelector('.paper');
if (!paper) return;
const svg = paper.querySelector('svg');
const canvases = paper.querySelectorAll('canvas');
const textLayer = pageDiv.querySelector('.textLayer');
const hasShadingError = pageDiv.hasAttribute('data-shading-error');
// オーバーレイモードまたはShadingエラーページの場合、テキストレイヤーの色を更新
if ((currentMode === 'overlay' || hasShadingError) && textLayer) {
const overlayColor = enabled ? '#e0e0e0' : '#222222';
textLayer.querySelectorAll('span').forEach(s => {
s.style.setProperty('color', overlayColor, 'important');
s.style.setProperty('-webkit-text-fill-color', overlayColor, 'important');
}
});
}
まず、ここら辺ではPDFのページ取得や正規順への並び替えなどを行っています。
const pages = holder.querySelectorAll('.page');
で、.pageクラスを持つ要素(PDFの実際のページ)がpagesに入れられ、その後のforEachにて一ページずつ処理されています。
下の方にあるif文以降では、シェーディングエラーかオーバーレイモードにした際、強制的に背景を黒、文字を白色にするためのものです。
シェーディングエラーはかなりの頻度で発生します。通常のフォント等であれば問題ないのですが、Word等の飾り文字は大半シェーディングエラーとなります。
シェーディングエラーが起こると、最悪ページごとなくなってしまうので、このように代替処置を行うこととしました。
さて、ここからはこの拡張機能のコアである、反転処理です。
これに関してはとても長くなってしまうため、別記事へ分割します。
(出来次第記事のURLをここにはります)
そのほか
制作中...
3.sandboxフォルダ内のJSファイル
opencv.html
制作中...
opencv.js
制作中...
特に苦労した点/良かった点
1.写真領域の判定方法
ハッカソンまでは、写真領域の判定に機械学習モデルを用いようとしていました。
しかし、そもそも学習が大変だし、Windows環境だとなかなか難しく...正直ハッカソンまでには何とか動きはしたものの、実用的な精度までは結局間に合いませんでした。
2.Manifest V3の制限
Manifest V3の制限がかなりきつく、sandbox回避を使ったり、manifest.jsonでの権限設定でなにがダメかを一つずつ試したりなどしました。
例えば、以下のpermissionsとhost_permissionsですが、
{
"permissions": ["activeTab", "storage"],
"host_permissions": ["<all_urls>"],
}
このように設定することで、ようやく意図通りに動きました。
拡張機能の公開にはかなりここの部分がチェックされるようで、アプリケーションの動作以上にここの許可権限を増やすと却下されてしまいます。
3.拡大縮小ロジック(パフォーマンス改善)
ハッカソンの際には最低限動くものでしかなかったのですが、拡大縮小時にすこしカクカクしたような動きとなっていました。
デフォルトのChromePDFReaderのような「吸いつくような操作性」を目指すため、拡張機能を公開する為の最終修正として、パフォーマンス改善に取り組みました。
そこで、実際にChromePDFReaderがどのような手法を用いて良いパフォーマンスを生み出しているかを解析しました。そこで一番大きい要因だと思われる仕組みが
拡大縮小の操作時、ベクター表示ではなく、ラスター表示にする
というものです。
実際に、限界まで縮小してから拡大すると文字が完全につぶれて読めない状態になりますが、拡大縮小動作をやめた数秒後にはレンダリングがしなおされ、綺麗な表示となります。
これを実現しようとしたのですが、拡張機能で行うには極めて難しい可能性があるということが分かりました。
あくまでさらっとコードを読んで適当に調べた結果ではありますが、拡大縮小時の動きとしては以下のような流れになっているようです。
ベクター化されたPDFを拡大or縮小する
↓
ユーザの拡大縮小操作が終わる
↓
現在の拡大率(縮小率)に合わせてもとファイルのPDFだとどうなるかを参照してレンダリングしなおす
そしてこの「元ファイルをベクターでレンダリングしなおす」という動作をC言語系統で作成されたプログラム(Chromeに内蔵?)が行っているようです。
拡張機能から呼び出せるようなものでもないですし、拡張機能にC言語を含めることは出来ないはずなので、別の手法を考える必要がありました。
そこで、我々はどういう場合において、自分たちが作った拡張機能でファイルを拡大縮小した時のパフォーマンスが下がるかを検証しました。その結果、一ページ内にある文字数が多く、全体ページ数がおおいPDFファイル
であることが分かりました。
よって、
拡大縮小時、現在表示しているページの前後のみ(合わせて3ページ)をレンダリングする
という手法を取ることにしました。
これによって、パフォーマンスが劇的に改善され、デフォルトのChromePDFReaderに劣らない操作性を実現することが出来ました。
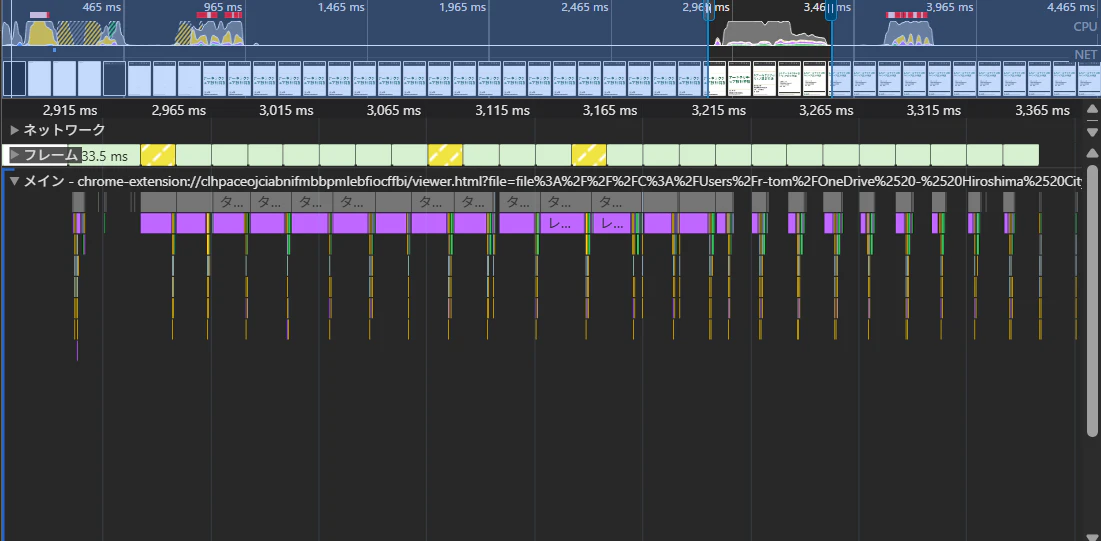
画像はノートパソコンのトラックパッドで一回拡大した際のパフォーマンスログ。
3500msあたりにある、上に赤い表示が出ているところでは拡大縮小の操作が終了した時点で、全ページを読み込んでいる処理です。ですので、「拡大縮小の滑らかさ」に寄与するのが、メインタブに表示されている時間で複数回発生しているそれぞれの処理時間の短さとなっています。
平均的に一番長いレンダリングタスクでも15ms程度で、基本的に0~15ms程度に収まっている為、かなり滑らかに動いているのがこのグラフからもわかるかと思います。
最後に
本ソフトウェアは、PDF.jsおよびOpenCV.jsのオープンソースライブラリを利用しています。これらのライブラリの開発者に深く感謝いたします。
また、友人のsatoyaa氏には、このアプリケーションの開発において多大な助言とサポートをいただきました。心より感謝申し上げます。
そして最後に、ハッカソンを開催してくださったLINEヤフー社様、サポートしてくださった社員の方々や審査員の方々にも厚くお礼申し上げます。