はじめに
この記事はHamster Output Advent Calendar 2024の3日目の記事です!
タイトルが若干違うんですが、ほぼ2日目の続き見たいな内容になります。
今回はChatGPTのテキスト生成と共に利用した、AzureAIの音声サービスを利用した音声合成機能を実装しました。
正直に言うと、記事などの情報があまり見当たらなかったので、公式ドキュメントから引っ張ってきた内容を改良して利用しやすくした...という内容になります。全て理解しているかというと何とも言えませんが、そろそろアウトプットしたかったのでこの機会にやります。
作成したソースコード
参考にしたリンク
公式のドキュメントから持ってきた内容
このソースコードの内容は参考リンクで紹介した、音声合成の部分です。UniTaskなど一部処理が修正されています。全部の内容は正直分かっていません...
/// <summary>
/// 会話を再生する
/// </summary>
/// <param name="speakContext">会話内容</param>
/// <param name="ct">キャンセレーショントークン</param>
public async UniTask PlaySpeakAsync(string speakContext, CancellationToken ct)
{
// 入力内容が無ければ再生を中断する
if (string.IsNullOrEmpty(speakContext))
{
Debug.LogWarning("speakContextに何も入力されていないです");
return;
}
// 開始音声がある場合は再生
if (_startPlayer != null && _startPlayer.clip != null)
{
_startPlayer.Play();
// 開始音声の再生時間を取得
var startPlayerLength = Mathf.RoundToInt(_startPlayer.clip.length);
// 再生が終わるまで待機
await UniTask.Delay(startPlayerLength, cancellationToken: ct);
}
// 音声合成の開始
using (var result = _speechSynthesizer.StartSpeakingTextAsync(speakContext).Result)
{
var audioDataStream = AudioDataStream.FromResult(result);
var isFirstAudioChunk = true;
// 音声データを生成
var audioClip = AudioClip.Create(
"Speech",
_rate * 600, // 最大10分の音声を作成可能
1,
_rate,
true,
(float[] audioChunk) =>
{
var chunkSize = audioChunk.Length;
var audioChunkBytes = new byte[chunkSize * 2];
var readBytes = audioDataStream.ReadData(audioChunkBytes);
if (isFirstAudioChunk && readBytes > 0)
{
isFirstAudioChunk = false;
}
for (int i = 0; i < chunkSize; ++i)
{
if (i < readBytes / 2)
{
audioChunk[i] = (short)(audioChunkBytes[i * 2 + 1] << 8 | audioChunkBytes[i * 2]) / 32768.0F;
}
else
{
audioChunk[i] = 0.0f;
}
}
if (readBytes == 0)
{
// メインスレッドから呼び出せない処理
Thread.Sleep(200);
_isStoping = true;
}
});
// 音声プレイヤーにクリップをセット
_speakPlayer.clip = audioClip;
// 音声再生エフェクトを起動
PlaySpeakSoundEffect(true);
}
}
AzuerAIを利用した経緯
今回の音声合成の機能実装は、プランナーから頼まれた物でさらにいくつか要望もありました。
- ボイスロイドではなく人間の声が良い
- 音声を話す人は英語圏の年齢が高い渋めなおじさんの声が良い
という条件があり、ボイスロイドや自由にカスタマイズできない物は利用できなくなってしまいました。公開されているプラグインでは、カスタマイズできる物があまりなく、音声が固定の物だったり、4つのデフォルト音声しかない物が多いことから利用できる物が見当たりませんでした。
そして、最終的にAzureAIの音声合成の紹介記事を見つけたことからAzureを利用した...という経緯になります。
実装中に困ったこと
・SpeechSDKのダウロード
Azureの音声合成を利用する上で、必要なSDKで、プロジェクトにダウロードする必要があります。AzureAIのドキュメントではVisualStudio上からダウロードするという内容でしたが、自分の環境ではダウロードできなかったので下の記事の方法でダウロードしました。
・音声の変更方法
オンラインドキュメントを読みながら、音声リストの一覧を見つけたので、どこかで変更できるとは思っていましたが、少し探すのに手間がかかりました。
音声合成に関連するSpeechConfigとSpeechSynthesizerを元に検索を行い、翻訳して近い単語を探した結果、SpeechConfig.SpeechSynthesisVoiceNameというメソッドを発見しました。
最終的にはSpeechConfigで音声の名前を設定した後に、SpeechSynthesizerに初期化することで変更することができました。
/// <summary>
/// 読み上げ音声を変更する
/// </summary>
/// <param name="chageName">変更する音声の名前</param>
public void ChangeReadingVoice(ReadingVoiceNameList chageName)
{
// 指定された音声名を取得して設定
_speechConfig.SpeechSynthesisVoiceName = _readingVoiceNameGetter.GetConvertVoiceName(chageName);
// 新しい音声合成オブジェクトを生成
_speechSynthesizer = new SpeechSynthesizer(_speechConfig, null);
}
・音声名のサンプルボイスを総当たりで再生して条件にあった声を探す
虚無になりながら、1ずつ再生して音声を総当たりで探しました。理想としてはプランナーの方に探してもらう方が良かったかも知れませんが、企画の修正や練り直しで忙しそうな雰囲気だったので、自分がいくつか良さそうな音声をみつけてプランナーに提案するという方針で行いました。
・サウンドの追加
音声の雰囲気として、トランシーバーで会話を行っているという設定なので、AudioSourceで、ゴリ押しで実装しました。
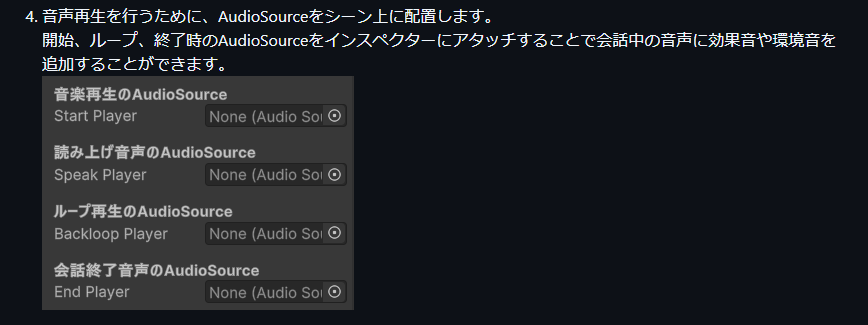
AudioSourceの値設定でわざと音割れに、近い雰囲気にしてトランシーバー風ぽく聞こえるように手探りで調整を行いました。音声に関しては昔からAudioSourceによるゴリ押しが多いので、CRIを使って管理してみたいですね。いつかやろうと思います。
まとめ
正直前回と、ほぼ一緒です。ただ、今回に関しては本当に情報が無かったので、今までのゲーム開発の中で一番厳しかったような気がします。今回の内容をまとめると、
・AIを利用した開発はかなり難しい
・AI関連の情報が少ない
・健康管理アプリを作るのが難しい
何より、ゲーム仕様の健康管理という部分が正直難しかったです...。食べた食事によってキャラクターが進化したり、データを日付ごとに管理したり、画像解析で撮った写真をどこかに保存...など、健康管理×ゲームという掛け合わせで実装する数が多く、自分の力不足もありますが...正直数ヵ月での実装は難しかったです。
今回の制作を振り返ると、中々難しい企画に挑戦したなとー...終わってから思いました。
ただ、開発が終わった後に、自分でも分かる実感できるくらい行動できるようになって...前よりも情報を調べれるようになったので良い一大イベントでした。