はじめに
S3Vectorsなるベクトルデータベースがプレビューリリースされたので,簡単なRAGを作ってみました。KendraやOpenSearchを使うと固定費が発生して結構なお値段になる(個人で遊ぶには厳しいお値段)ベクトルデータベースが,S3で安価に作れるようになりました。S3selectのようにS3をデータベースと見立ててデータ操作を行う機能と私は理解しています。
ちなみにこれがRAGデビューなので,知識不足であさってなことを書いていたらすいません。2025/8/3時点での情報です。
やったこと
手元にWeb+DBpress総集編があったので,適当に選択した7冊分のPDFをRAGに入れて,そのデータを使ってLLMで会話してみました。30分ぐらいで作れます。
リージョンはus-east-1です。
ざっくり作業の流れ
- 手順1:RAGに入れる元データ用のS3バケットを作成する
- 手順2:Bedrockナレッジベースからベクトルインデックスを作成する
- 手順3:ベクトルインデックスにS3バケットの情報を同期する(インデックスを作成する)
- 手順4:ナレッジベースをテストする
手順1:RAGに入れる元データ用のS3バケットを作成する
- RAGで扱いたい元データを入れるS3バケットを作成します。バケットの設定はデフォルトで構いません。
- バケットに,元データのPDFをアップロードしておきます。
手順2:Bedrockナレッジベースからベクトルインデックスを作成する
-
「Bedorock」→「ナレッジベース」→「作成」→「ベクトルストアを含むナレッジベース」をクリックする。
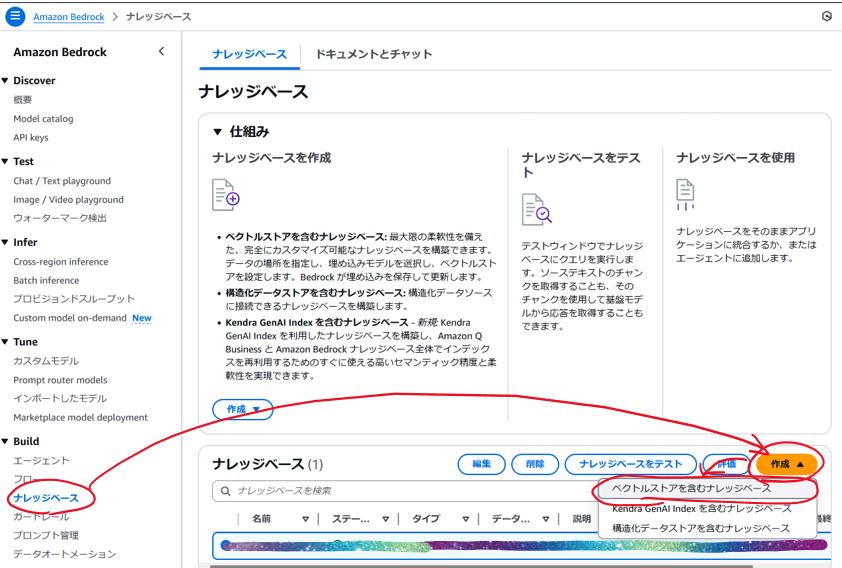
-
データソースで「Amazon S3」を選択し「次へ」をクリック。(パラメータはデフォルトでOK)
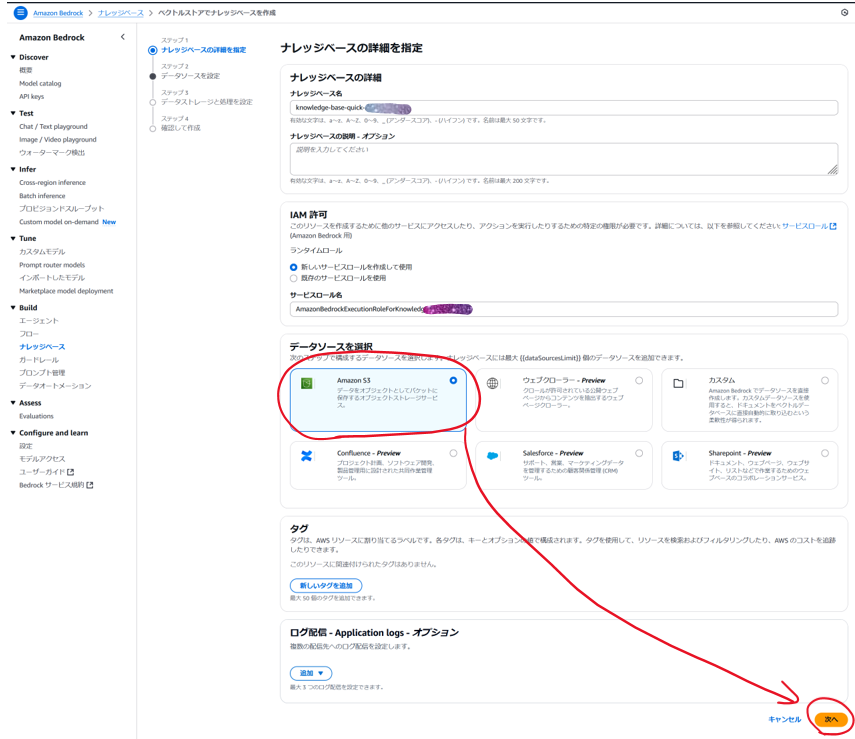
-
データソースのS3として手順1で作成したバケットを指し,「次へ」
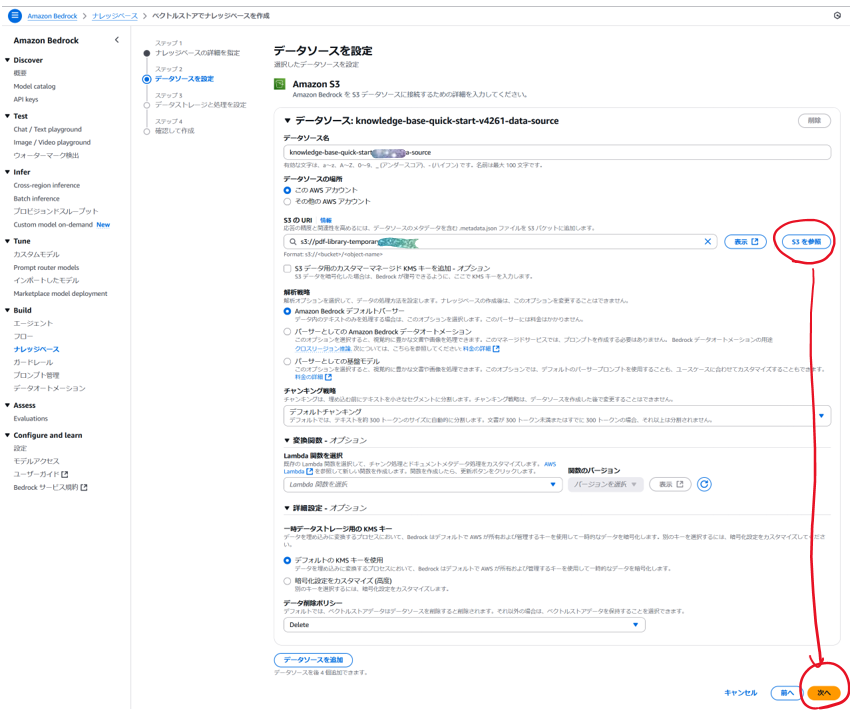
-
埋め込みモデルを適当に選択し,ベクトルストアに「Amazon S3vectorsプレビュー」を選択する。埋め込みモデルはAmazon TitanかCohereが使えます。あらかじめモデルカタログから有効化しておかないといけません。
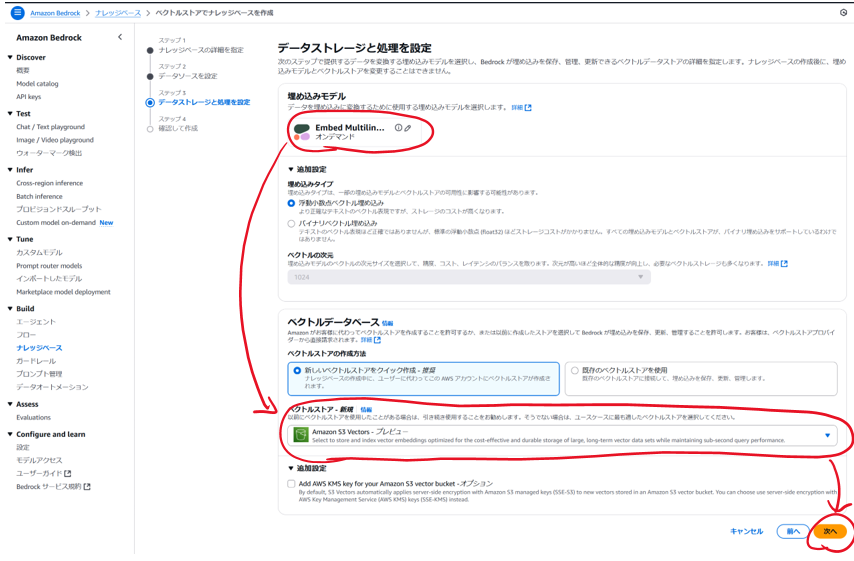
-
設定内容を確認し「ナレッジベースを作成」
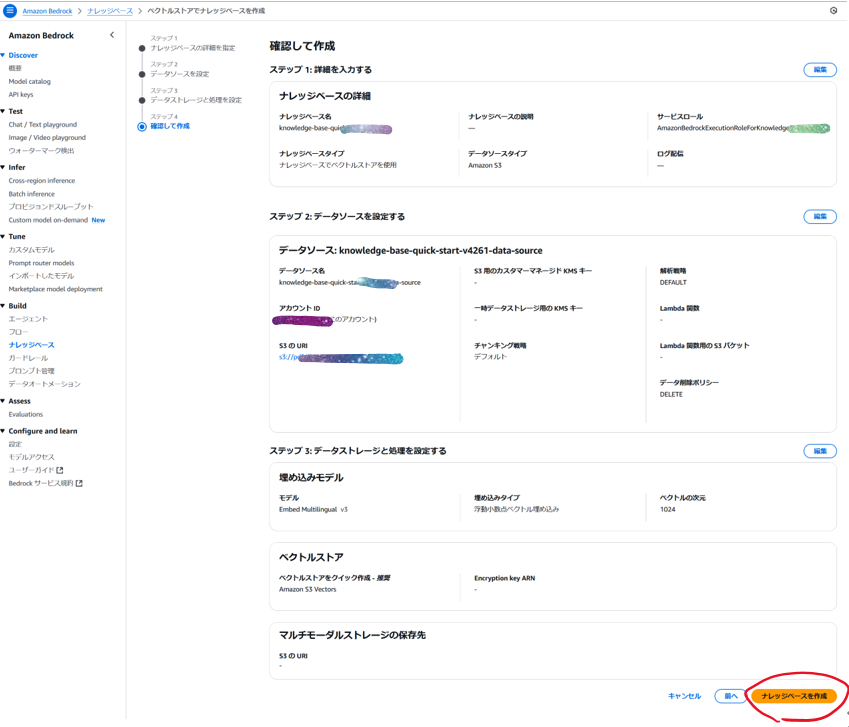
この作業が完了すると,S3にベクトルバケットと,その中にデフォルトのベクトルインデックス(この時点では中身は空)ができあがります。
手順3:ベクトルインデックスにS3バケットの情報を同期する(インデックスを作成する)
-
「Bedorock」→「ナレッジベース」→ナレッジベースの名前をクリック
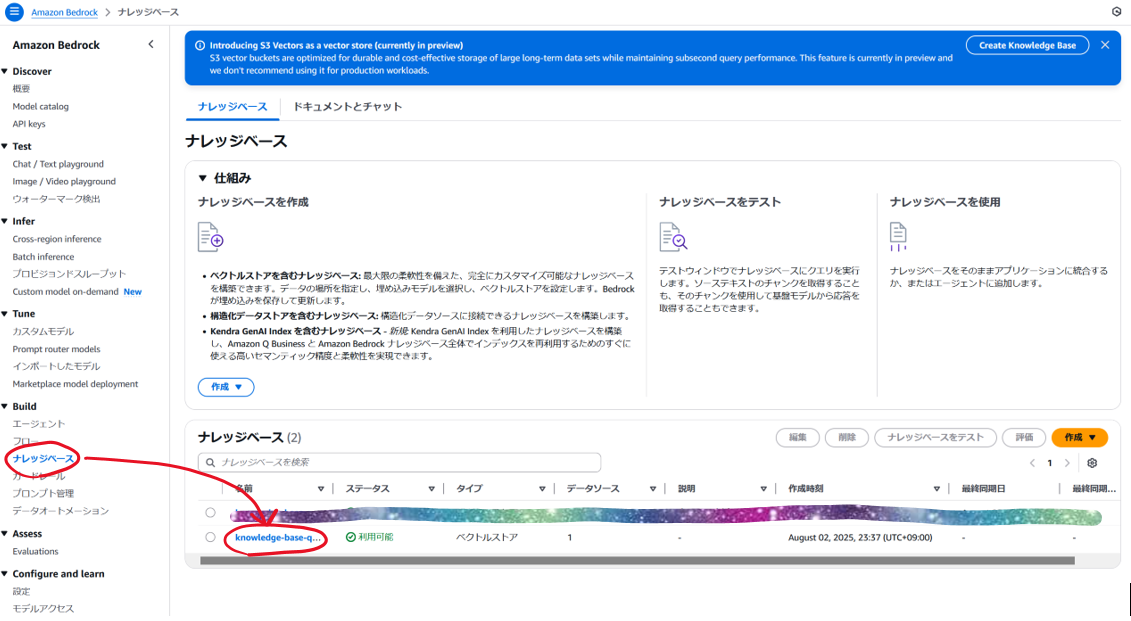
-
データソース名をクリック
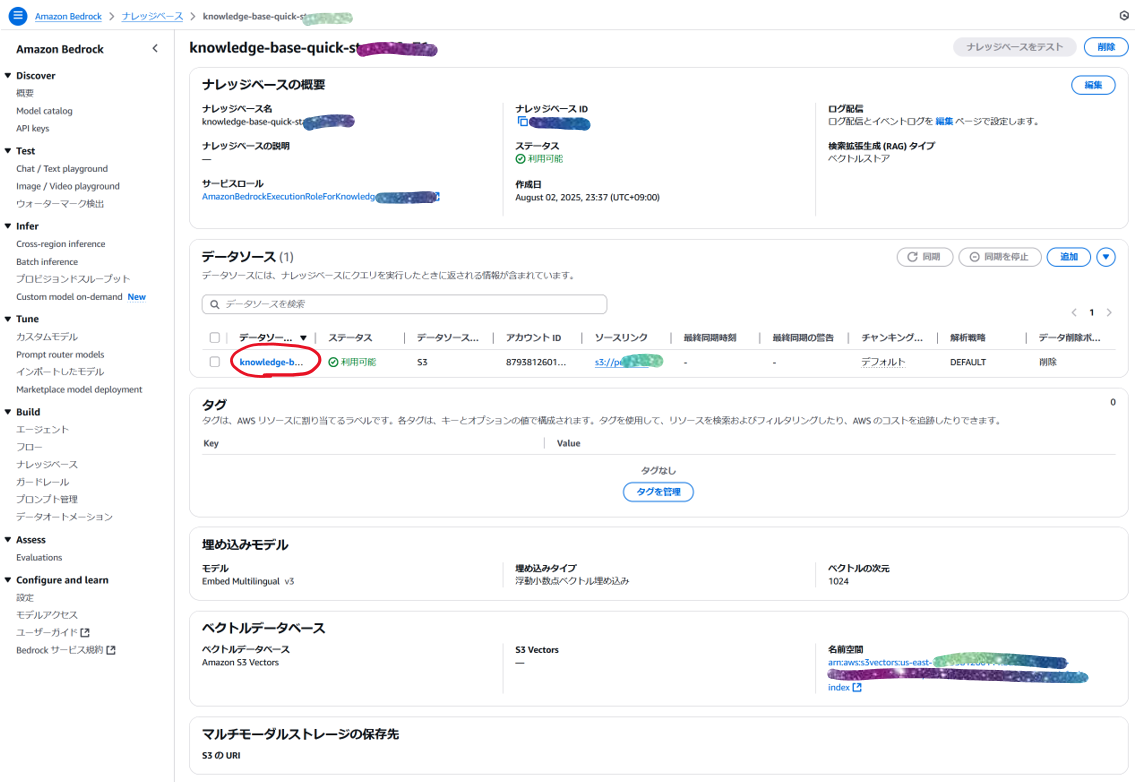
-
「同期」をクリック
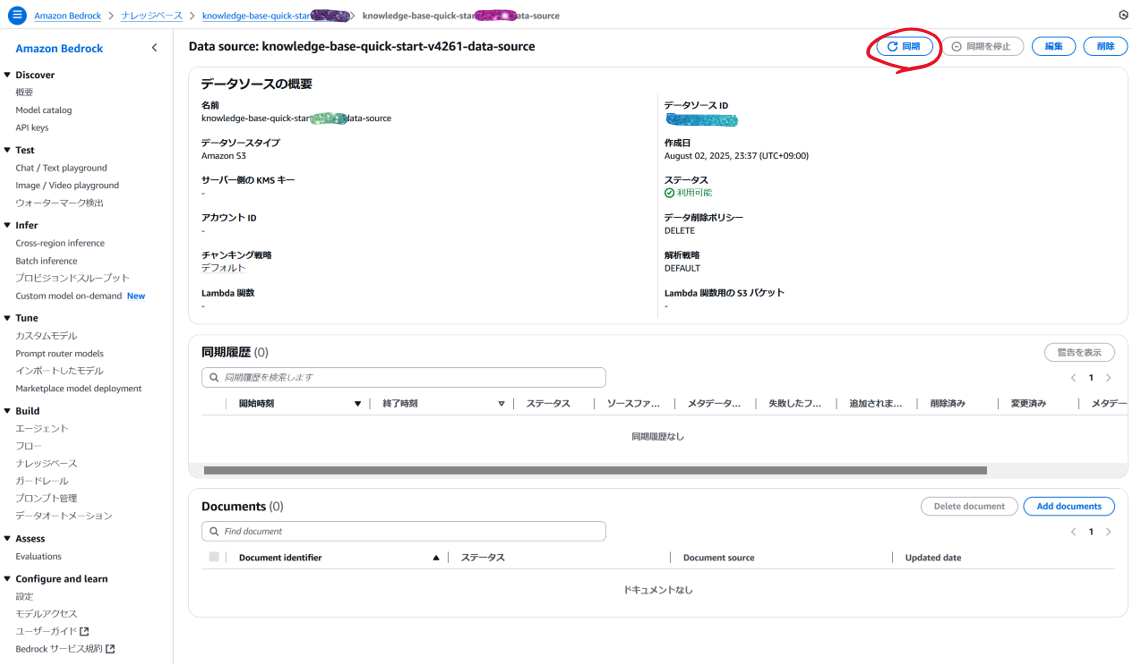
-
しばらく待って画面をリロードします。(更新ボタンが現状なさそう)
-
インデックス作成はなぜか一部失敗することがあります。繰返し「同期」ボタンを押せば,そのうち全ファイルがインデックス完了します。
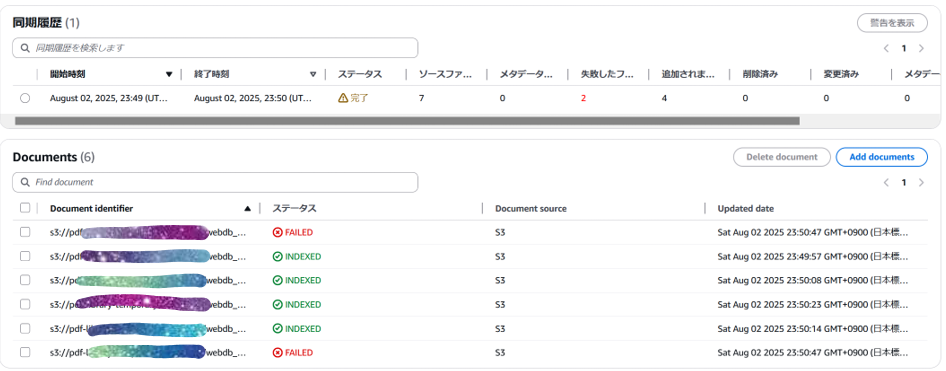
もしRAGに食わせるファイルが増えた場合には,S3バケットにファイルをアップロードし「同期」を再実行します。
手順4:ナレッジベースをテストする
-
「Bedorock」→「ナレッジベース」→ナレッジベースの名前をクリック
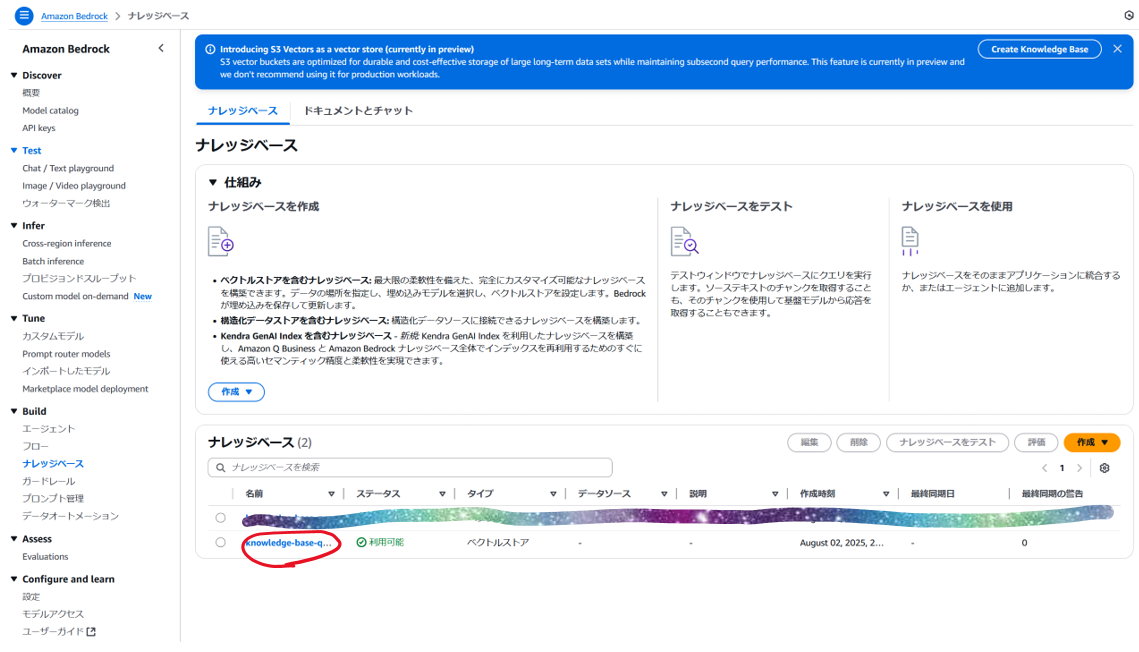
-
「ナレッジベースをテスト」をクリック
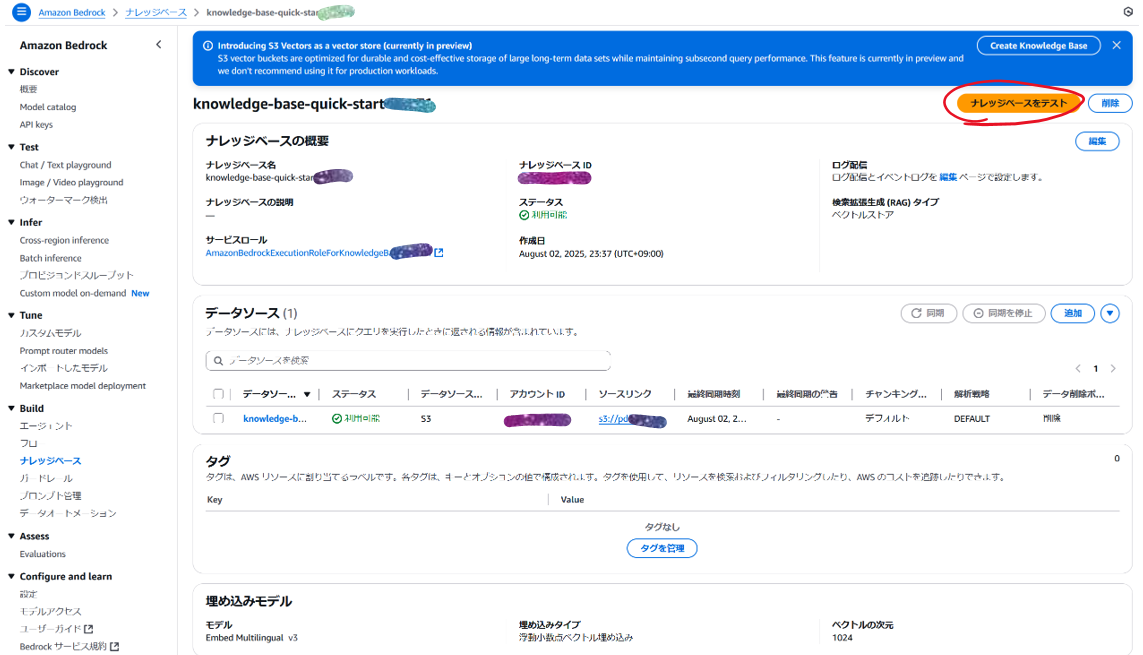
-
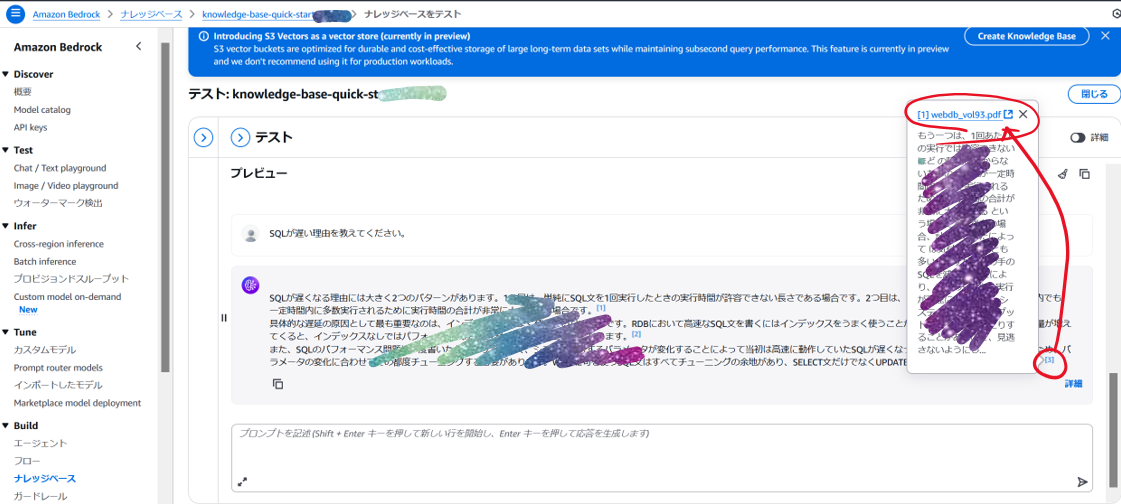
このあとはPlaygroundとほぼ同じです。モデルを選択し,プレビューからプロンプトを入力します。
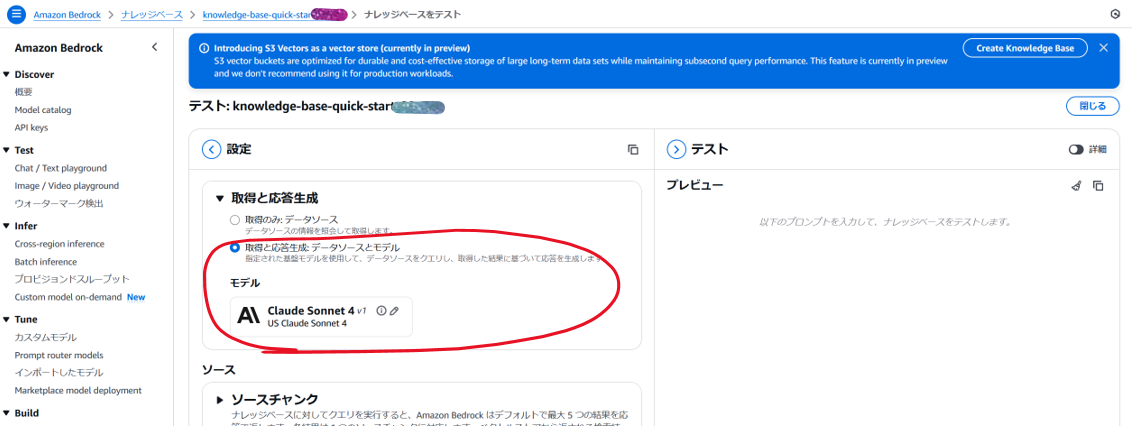
-
応答には,根拠のファイルへのリンクが付与されます。クリックすると,どのファイルのどの部分を参照したのかが確認できます。
後始末
S3vectorで使うベクトルバケットや,その中にあるベクトルインデックスは現状GUIから削除や変更ができません。Cloudshellからawsコマンドで消してしまいましょう。ARNはGUIからコピペします。
~ $ aws s3vectors delete-index --index-arn arn:aws:s3vectors:us-east-1:(以下略)
~ $ aws s3vectors delete-vector-bucket --vector-bucket-arn arn:aws:s3vectors:us-east-1:(以下略)