三行要約
・肌荒れに関するニーズを可視化するコードを書きました。
・「肌荒れ」に関するtweetを元データとしました。
・おまけで、日本語だけではなく、英語圏のツイートからもニーズを拾ってみました。
目次
1. 背景と目的
2. 私の実行環境
3. tweetの取得
4. データクレンジング
5. 形態素解析
6. tweetの可視化
7. tweetから読み取れるニーズ
8. 海外の人も似たような悩みを持っているか
9. まとめ
1. 背景と目的
最近友達とリモート飲み会をすると、必ずと言っていいほどニキビの話をします。
以前はそんなにニキビの話をしなかったのですが、、、世の中の皆さんも同じように肌荒れに関するお悩みが増えているのかが気になり、肌荒れに関するニーズの可視化を行ってみました。
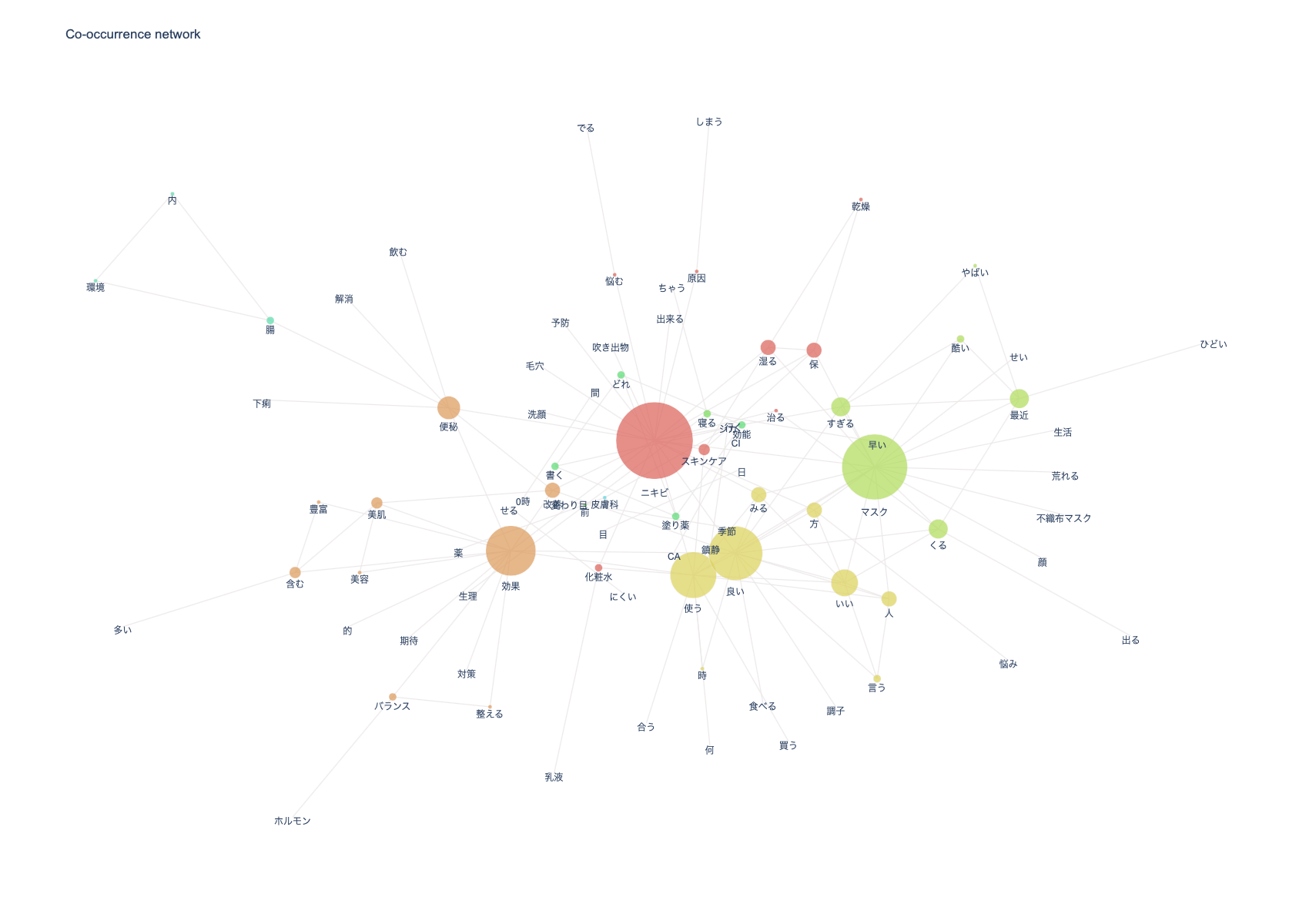
今回作成したコードで、下図のようにパッとみて肌荒れと関連のあるワードが分かる図が作れるようになりました。

2. 私の実行環境
Python 3.8.5 (anaconda, jupyter notebook)
MacBook Pro (M1)
3. tweetの取得
まずはtweetの取得を行います。
tweetの取得には、tweepyというライブラリを使用しました。
tweepyとは、twitter APIを使用した投稿、tweetの取得、いいねなどを簡単行うことができるライブラリです。
今回は、「肌荒れ」または「肌あれ」を含むツイートを10,000件取得しました。
import tweepy
import pandas as pd
# APIを使用するためのキー、トークン設定
Consumer_key = '****'
Consumer_secret = '****'
Access_token = '****'
Access_secret = '****'
# 認証
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
# 検索キーワード
q = "肌荒れ OR 肌あれ exclude:retweets"
# データ取得
tweet_doc =[]
for tweet in tweepy.Cursor(api.search, q=q,tweet_mode="extended").items(10000):
tweet_doc.append(tweet.full_text)
# sample data
target_col = "text"
df = pd.DataFrame({target_col: tweet_doc})
また、取得したツイートのうちプロモーションなどの必要なさそうなtweetは削除しました。
# プロモーション関係のtweetの削除
df = df.query('not text.str.contains("コード") or not text.str.contains("クーポン") or not text.str.contains("OFF")', engine='python')
4. データクレンジング
tweetには、URLなどニーズ分析には必要なさそうな文字が含まれています。
また、文字の表記ゆれも存在しますので、ライブラリを使ってデータクレンジングしていきます。
今回行ったデータクレンジングは以下の2つです。
① 全角・半角の統一と重ね表現の除去
neologdnというライブラリを使用
② URLや記号の削除、数字の置換
reライブラリと正規表現を使用
import re
import neologdn
def cleaning_text(text):
#全角・半角の統一と重ね表現の除去
normalized_text = neologdn.normalize(text)
#URLや記号の削除、数字の置換
text_without_url = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', normalized_text)
tmp = re.sub(r'(\d)([,.])(\d+)', r'\1\3', text_without_url)
text_replaced_number = re.sub(r'\d+', '0', tmp)
return text_replaced_number
上記の関数を使うと、下記のようにデータクレンジングを行うことができます。
text = 'この化粧水8000円もしたのに〜〜〜肌荒れした。このツイートの洗顔方法試してみよ!!!リンクだよ https://t.co'
print(cleaning_text(text))
>この化粧水0円もしたのに肌荒れした。このツイートの洗顔方法試してみよ!!!リンクだよ
この関数を、applyメソッドを使って先ほど取得した tweetたちに適用していきます。
df['text_wakati'] = df['text'].apply(cleaning_text)
5. 形態素解析
データの可視化を行うためには、tweetの形態素解析を行う必要があります。
形態素解析とは
まず、形態素とは「意味を持つ最小の言語単位」のことであり、単語は一つ以上の形態素を持ちます。そして形態素解析とは、辞書を利用して文章を形態素に分割し、さらに形態素ごとに品詞などのタグ付け(情報の付与)を行うことを指します。
日本語の形態素解析は、MecabやJanomeというライブラリを使用すれば簡単に行うことができます。
例えば、この文章「この化粧水8000円もしたのに肌荒れした。」をMecabで形態素解析すると、下記のような結果が返ってきます。
import MeCab
text = "この化粧水8000円もしたのに肌荒れした。"
m = MeCab.Tagger ('')
node = m.parse(text)
>
この コノ コノ 此の 連体詞 0
化粧 ケショー ケショウ 化粧 名詞-普通名詞-サ変可能 2
水 スイ スイ 水 接尾辞-名詞的-一般
8000 8000 8000 8000 名詞-数詞 0
円 エン エン 円-助数詞 名詞-普通名詞-助数詞可能 1
も モ モ も 助詞-係助詞
し シ スル 為る 動詞-非自立可能 サ行変格 連用形-一般 0
た タ タ た 助動詞 助動詞-タ 連体形-一般
の ノ ノ の 助詞-準体助詞
に ニ ニ に 助詞-格助詞
肌荒れ ハダアレ ハダアレ 肌荒れ 名詞-普通名詞-サ変可能 0
し シ スル 為る 動詞-非自立可能 サ行変格 連用形-一般 0
た タ タ た 助動詞 助動詞-タ 終止形-一般
。 。 補助記号-句点
EOS
実際にMecabを使ってtweetを形態素解析を行ってみる
今回のtweetの可視化では、「名詞、動詞、形容詞」の原型のみを使用します。
なので、Mecabで形態素解析した後に、「名詞、動詞、形容詞」の原型のみを抽出する関数を作成しました。
Mecabの辞書は新語なども拾うために、「mecab-ipadic-neologd」に設定しています。
また、「する、いる」など文章中でよく使われる単語は抽出されないように設定しました。
import MeCab
def sep_by_mecab(text):
m = MeCab.Tagger ('-d mecab-ipadic-neologdのフォルダパスを記入')
node = m.parseToNode(text)
word_list=[]
while node:
hinshi = node.feature.split(",")[0]
#名詞、動詞、形容詞のみを抽出する
if hinshi in ["名詞","動詞","形容詞"]:
origin = node.feature.split(",")[6]
#抽出したくない単語を、stopwprdとして設定する
if origin not in ["*","する","いる","なる","てる","れる","ある","こと","もの","天気"] :
word_list.append(origin)
node = node.next
return word_list
上記の関数を、先ほどデータクレンジングを行ったtweetたちに適用します。
df['text_wakati'] = df['text_wakati'].apply(sep_by_mecab)
6. tweetの可視化
tweetを可視化する準備が整いました。
今回はwordcloudと共起ネットワークでtweetの可視化を行おうと思います。
wordcloudとは
文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法のことを指します。
共起ネットワークとは
一つ一つの文書で出現する単語「抽出語」同士の関係性を表すネットワークのことです。
ネットワーク構造では、対象はノードで、関係はエッジで表現されます。エッジは重みを持ち、友だち関係のネットワークにおいては親密度にあたります。親密であればあるほど重みの値は大きくなります。
今回はノードに、tweetから抽出した「名詞、動詞、形容詞」を使用します。
エッジに使用される値の計算方法は色々ありますが、今回は抽出語ペアの出現回数をエッジとその重みとして使用します。
nlplotを使用してwordcloudと共起ネットワークを作成してみる
nlplotというライブラリを使用してtweetの可視化を行ってきます。nlplotは、本来ならば細々としたコードの記入が必要な様々な図を、簡単に作成できるライブラリです(詳しくはこちら)。
まずはnlplotのインスタンスを生成と、ストップワードの設定を行います。
import nlplot
# target_col as a list type or a string separated by a space.
npt = nlplot.NLPlot(df, target_col='text_wakati')
# 形態素解析後に追加で消したくなった言葉をstopwordに追加
stopwords = ["の","ん","ない","てる","0","肌荒れ","私","さん","やすい","思う","よう","肌","できる"]
wordcloudの作成を行います。
# wordcloudの作成
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)

次は、共起ネットワークの作成を行います。
# ビルド(データ件数によっては処理に時間を要します)
npt.build_graph(stopwords=stopwords, min_edge_frequency=50)
npt.co_network(
title='Co-occurrence network',
save=True
)
ちなみに、隣接するエッジが多いほど円のサイズが大きくなります。
ノードの色は、networkxのcommunitiesで計算したコミュニティを表しています。
一つのネットワークは、複数の部分ネットワーク(=コミュニティ)によって成り立っています。コミュニティ内の各ノードは、エッジで密につながっていることが特徴です。
上の図だと、「ニキビ、スキンケア、悩む、原因、、、etc」が一つのコミュニティですね。
7. tweetから読み取れるニーズ

wordcloudに少し手を加えてみました。
体調に関するワードはピンク色、スキンケアに関するワードは青色で塗りつぶしました(手動です)。
wordcloudから感じ取った肌荒れに対するニーズは下記の3点です。
① マスクによる肌荒れを治したい
マスクという言葉が一番目に入りますね。
調べてみると、マスクによる摩擦や、乾燥が原因で肌荒れが起きてしまうらしいです。
② 肌荒れの原因を知りたい
ストレス、乾燥、便秘などの言葉も目に入ります。環境や体調不良による肌荒れを気にしている人も多いようですね。肌が荒れ出すと、乾燥が酷くなったのかな、とか体のどこかで不調が起きているのかな、と感じる時が多いですよね。
考えてみると、自分の肌荒れの原因を正しく知っている人は少ない気がします。
原因を知れば、肌荒れの改善もできますし予防もできますよね。
③ 肌荒れの改善方法を知りたい
肌荒れの改善に直接関連するワードは、「洗顔、皮膚科、薬、スキンケア」くらいでしょうか。肌荒れに対する不満、肌荒れの原因に関するtweetは多いですが、肌荒れの改善方法に関するtweetは少ないのかも知れません。
肌荒れの原因を知らずに、ネット上の改善法を試すと、かえって肌荒れを悪化させる時もあります。自分の状態にあった、正しい改善法を知れるアプリなどがあれば便利なのではないでしょうか。

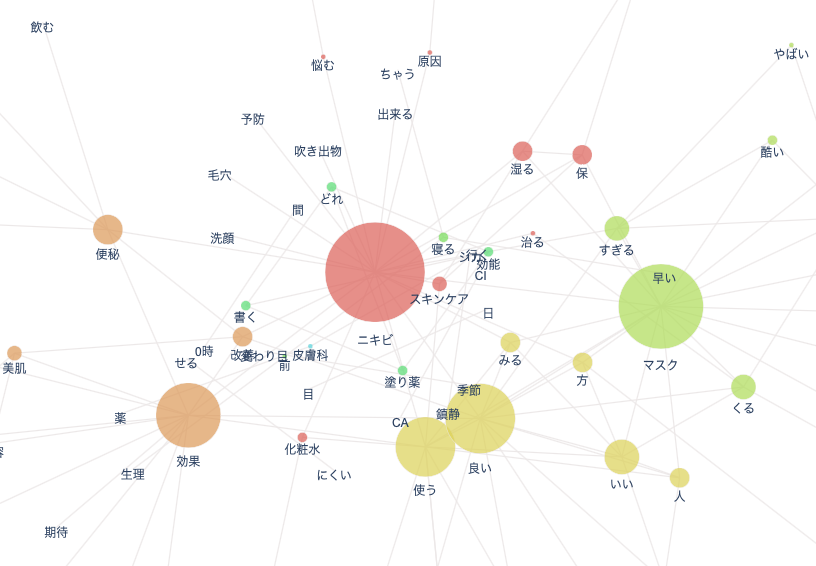
共起ネットワークも同じく手を加えました。
共起ネットワークでは頻出単語同士の関連性も見れるので、よりtweetの内容を深く見れる感じがします。
例えば、「皮膚科」と「薬」が一本の線で繋がっているので、この2つの単語は関連性があることになります。
他にも、「塗り薬」と「効果」、「塗り薬」と「どれ」、「効果」と「良い」などが繋がっていますね。
「原因」、「悩む」、「予防」、「改善」などのワードも、「ニキビ」と繋がっています。Twitter上で、肌荒れの改善方法を探す人は多いようです。
Twitterは拡散されやすいSNSとされていますよね。
実はめちゃくちゃお肌に悪いけど、ぱっと見てお手軽で効果の良さそうな改善法が拡散される可能性もあると考えれば、少し怖いです。
8. 海外の人も似たような悩みを持っているか
日本ではマスクによる肌荒れを気にしている人が多いようですが、海外ではどうなのかと気になったので、英語圏のtweetも解析することにしました。
外国語のtweetも、日本語と同じく形態素解析を行えばnlplotで可視化ができます。
今回は、nltkという外国語用の形態素解析ライブラリを使用して、英語圏での「肌荒れ」に関するツイートを解析してみました。
tweetの取得とデータクレンジング
tweetの取得とデータクレンジングは日本語の時と同じ方法で行っていきます。
tweetの取得とデータクレンジングのコード
import tweepy
import pandas as pd
import re
import neologdn
# APIを使用するためのキー、トークン設定
Consumer_key = '****'
Consumer_secret = '****'
Access_token = '****'
Access_secret = '****'
# 認証
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
# 検索キーワード
q = 'skin (problem OR problems OR rash OR rashes OR breakout) exclude:retweets'
# データ取得
tweet_doc =[]
for tweet in tweepy.Cursor(api.search, q=q,tweet_mode="extended").items(10000):
tweet_doc.append(tweet.full_text)
target_col = "text"
df = pd.DataFrame({target_col: tweet_doc})
df = df.query('not text.str.contains("fill") OR not text.str.contains("racist")', engine='python')
# データクレンジング
def cleaning_text(text):
normalized_text = neologdn.normalize(text)
text_without_url = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', normalized_text)
tmp = re.sub(r'(\d)([,.])(\d+)', r'\1\3', text_without_url)
text_replaced_number = re.sub(r'\d+', '0', tmp)
text_without_url = re.sub('@([A-Za-z0-9_]+)', "", text_replaced_number)
return text_without_url
# 取得したtweetたちにデータクレンジング関数を適用
df['text_wakati'] = df['text'].apply(cleaning_text)
形態素解析
英語の形態素解析は、nltkライブラリを使用して行ってきます。
Mecabで形態素解析する際に、stopwordを自分で設定する必要がありましたが、nltkライブラリには、英語のstopwordのリストがあらかじめ用意されています。
今回はそのリストをそのまま、stopwordとして使用しようと思います。
import nltk
from nltk.corpus import stopwords
# stopwordの設定
stopset = set(stopwords.words('english'))
# stopwordリストの中身(参考情報)
print(stopset)
>{'until', 'through', 'did', 'both', 'having', 'same', 'against', 'its', "you'll", 'hadn', 'which', 'hasn', 'will', 'when', 'below', 'between', 'here', 'from', 'now', 'some', "haven't", 'shan', 'won', 'he', 'hers', "that'll", 'my', 'yourselves', 'too', "couldn't", 'are', 'they', 'were', 'weren', 'into', 'than', 'where', 'myself', 'ourselves', 'him', 'been', 'i', 'yourself', 'this', 'own', 'ma', 'shouldn', 'about', 'at', 'does', 'has', "you've", 'with', 'down', 'more', 'other', 'to', "isn't", "she's", 'again', 'can', 'd', 's', "hadn't", 're', 'be', 'because', 'on', 'y', 'doing', 'after', 'don', "wasn't", "aren't", 'or', "you'd", 'mustn', 'himself', 'ours', 'have', 'our', "mustn't", 'once', 'then', 'during', 'is', 'didn', 'so', 'very', "wouldn't", 'in', 'under', 'these', 'you', 'm', 'while', "weren't", 'her', "it's", 'each', 'should', 'couldn', 'few', 'just', 'not', 'your', "don't", 'doesn', 'wasn', 'we', 'over', 't', 'who', 'a', "shan't", 'off', "you're", "mightn't", 'for', 'there', 'all', 'am', 'yours', 'and', "hasn't", 'such', "won't", 'their', 'why', 'mightn', "should've", 'an', 'o', 'whom', 'what', 'if', 'no', "didn't", "shouldn't", 'herself', 'his', "needn't", 'nor', 'by', 'do', 'me', 'as', 'll', 'how', 'them', 'was', 'needn', 'any', 've', 'ain', 'being', 'had', 'above', 'further', 'theirs', 'those', 'but', 'only', 'haven', 'isn', 'wouldn', 'she', 'of', 'it', 'the', 'up', 'aren', 'itself', 'most', 'that', 'before', "doesn't", 'out', 'themselves'}
stopwordの設定ができたので、実際に形態素解析を行っていきます。
日本語と同様に、「名詞、動詞、形容詞」の原型のみを抽出する関数を作成しました。
def sep_by_nltk(text):
tweet_words = []
clean_tweet = []
tokens = nltk.word_tokenize(text)
t = nltk.pos_tag(tokens)
tweet_words = [x for (x,y) in t if y in ['NN','JJ','JJR','JJS','NNS', 'NNP', 'NNPS','VB','VB','VBD','VBG','VBN','VBP','VBZ']]
clean_tweet = [i for i in tweet_words if i not in stopset]
return clean_tweet
# 取得したtweetたちに形態素解析関数を適用
df['text_wakati'] = df['text_wakati'].apply(sep_by_nltk)
tweetの可視化
tweetの可視化の準備が整ったので、nlplotを使用して可視化を行っていきます。
こちらも日本語の時と同じ方法です。
import nlplot
# target_col as a list type or a string separated by a space.
npt = nlplot.NLPlot(df, target_col='text_wakati')
# 追加でストップワードに追加したくなったものを追加
stopwords = ["'s","'m","'re","0","skin","problem","problems","amp","'ve","*"]
まずはwordcloudを作成します。
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)

日本語とは違い、「マスク」という言葉は見当たりませんね。ですが、「covid」という言葉が真ん中あたりにあります(赤丸で囲っている所です)。やっぱり英語圏でも、コロナに関連した肌荒れに悩まされている方が多いのかもしれません。
次は共起ネットワークを作成します。
# ビルド(データ件数によっては処理に時間を要します)
npt.build_graph(stopwords=stopwords, min_edge_frequency=15)
npt.co_network(
title='Co-occurrence network',
save=True
)
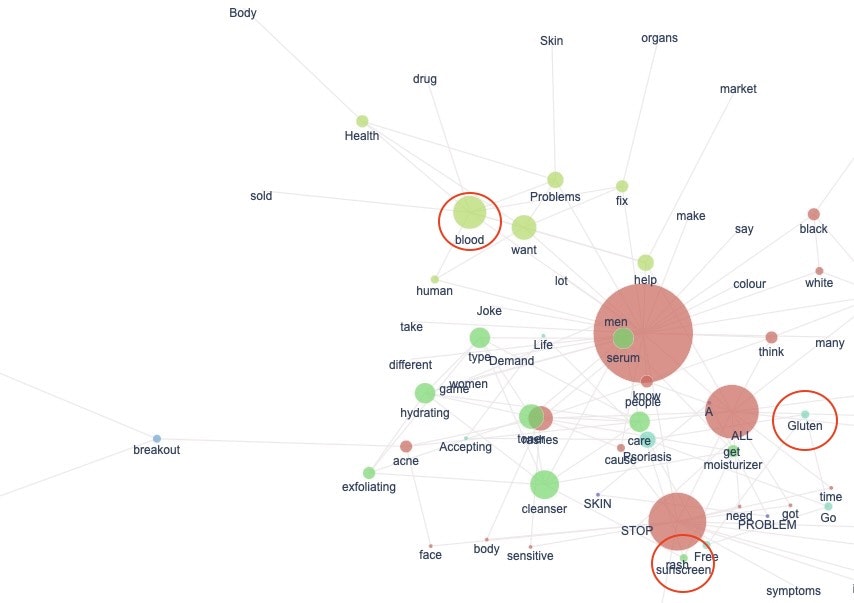
英語tweetで特徴的だと感じたワードに赤丸をつけてみました。
① Blood(血)
一見肌荒れと全く関係なさそうなワードなので、このワードを見た時はびっくりしました。
肌荒れとの関連を見るためには、肌荒れとbloodを含んだtweetを取得して、再度分析する必要がありそうです。
② Sunscreen(日焼け止め)
日本語tweetには「日焼け止め」というワードがなかったですよね。
英語圏では、日光浴をする人が多いイメージがありますが、何か関係があるのでしょうか、、、
③ Gluten(グルテン)
英語tweetの中でもすごく特徴的なワードだと感じました。海外では、グルテンフリーの食事を好む人が増加していますよね。肌荒れに関するtweetをする際、グルテンについて言及する人も多いようです。
外国で当たり前と考えられていても、日本では全く新しい発想だったりしますよね。
また、外国で流行っているものが遅れて日本にやってくる時も多いです。
外国のデータを可視化することで、新しいニーズや新たな発想を得ることができるかもしれません。可視化する際に、日本では見慣れない単語が含まれていないかどうかをチェックすると良さそうですね。
9. まとめ
今回は、tweetの可視化を行いましたが、やっぱり一回の分析だと読み取れるニーズは少ないなと感じました。
肌荒れのニーズをしっかり読み取るためには、今回出てきた結果からさらにKWの絞り込みを行ったり、KWの組み合わせを変えたり、データクレンジングの手法を変えたりして、たくさんのデータを見比べる必要がありそうです。
あとは、可視化を行う前に感情分析やデータの分類などを行って、必要なデータにだけ絞ることで、もっと新たなKWを見つけることができそうだと感じました。
(tweetの中には「推しの肌荒れ可愛い!」など、肌荒れに関するtweetでも意外とポジティブなtweetも混ざっていたので、、、)
長い長い文章を最後までお読みいただき、ありがとうございました!