本稿は、Keras+Seq2SeqベースのTwitter自動応答チャットボットをAWS Lambda上で動作させようとしたものの、リソース不足で実現できなかった顛末について、Lambda関数の作成方法やコードの登録方法を含めて記述します。
1. はじめに
前回の投稿で、Keras+Seq2SeqベースのTwitter自動応答チャットボットを作成しました。これを24H連続運転して、いつでも使えるようにしたいところですが、自宅のPCを通電しっ放しにするのは何となく気が引けるし、そもそもコンシューマー向けPCというのは、そういう用途を想定していないのではないか、と不安になりました。
そこでクラウドの登場です。筆者はAWSのアカウントを持っているのですが、EC2の無料期間はとうに過ぎてしまっていて、どうしようかと思案していたところ、昨今はサーバーレスというのが流行っている、ということに思い当たりました。
早速ググってみると、AWSのサーバーレスサービスはLambdaという名称であることがわかりました。Kerasに出てくるLambdaと紛らわしいと思いましたが、料金をググるとかなり安いように見えます。「上手く使えばロハで行けるのでは」と、Lambda上でのチャットボット運転にチャレンジすることにしました。
この時点では、Lambdaのリソース上の制限について、筆者は全く理解していません(笑)。
2. 動作対象のニューラルネットワークについて
動作させようとしているのは、Seq2Seqのエンコーダー及びデコーダーで、入力の発話文に対する応答文を出力します。LSTMのBidirectional(順方向のLSTMと逆方向のLSTMを多段に積む)と、Attention機能を持っています。Kerasを使って実装してあります。
エンコーダーのモデル図は以下のとおりです。
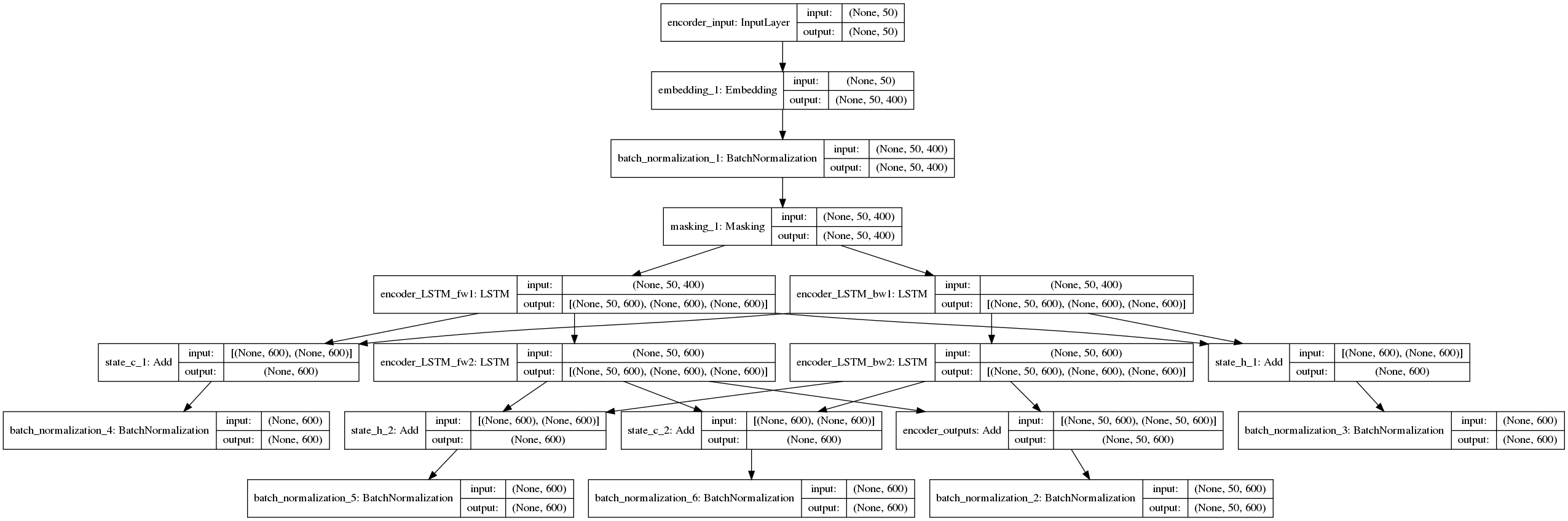
また、デコーダーのモデル図は、以下のとおりです。
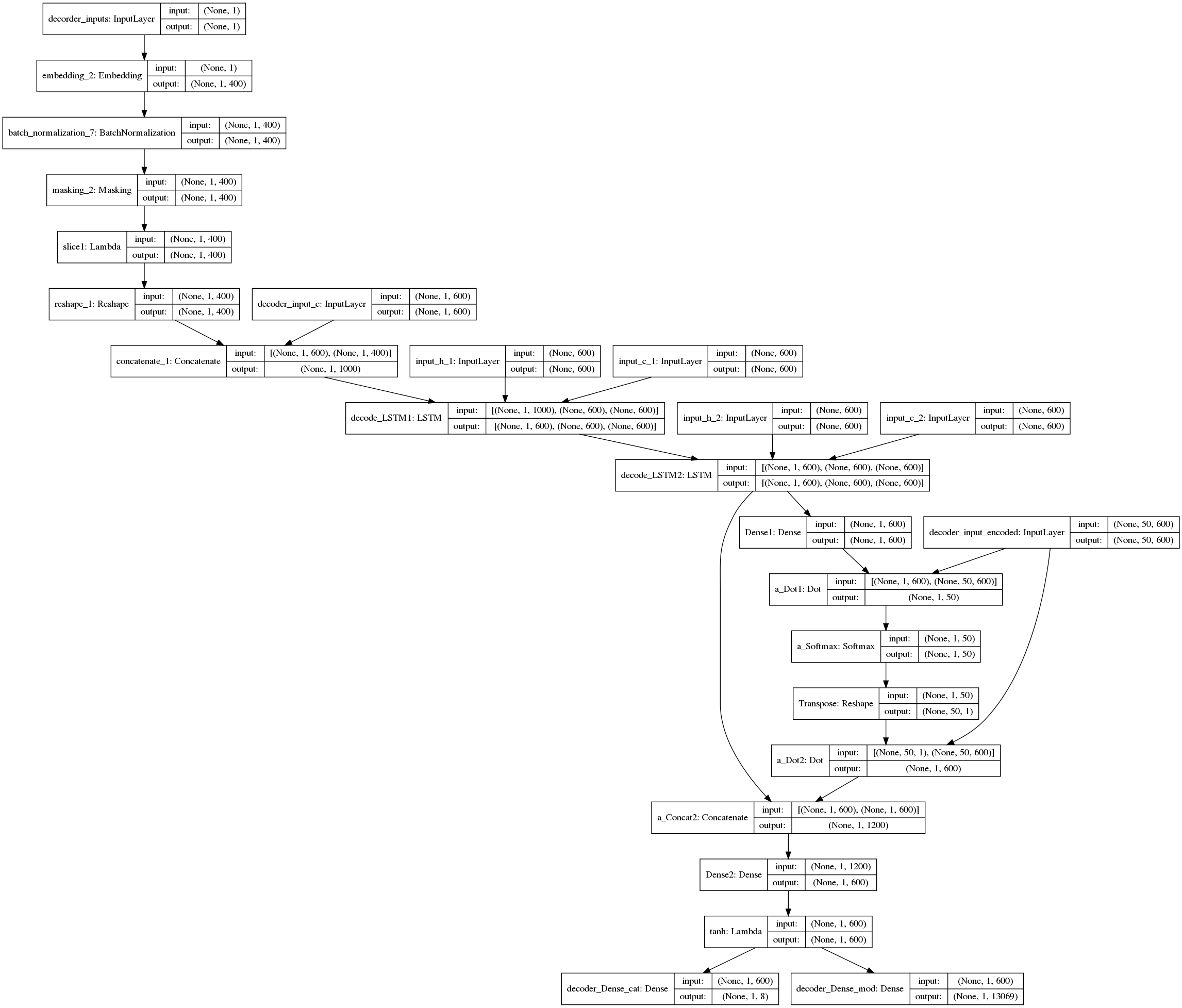
それぞれ、どのように実装しているのかについては、筆者の以下の投稿をご覧ください。
このニューラルネットワークにTwitter APIを組み合わせ、自アカウント向けtweetをポーリングし、もしそれがあればエンコーダーとデコーダーを通して応答文を生成し、Twitter API経由でリプライします。
3. AWS Lambda利用手順
3-1. Lambda関数の定義
AWS Lambdaにおける関数とは、利用者が実行させたいプログラムのことです。定義された何らかのトリガにしたがって、Lambdaが関数を実行します。利用者が用意するのは関数を構成するプログラムだけでよいというのが、Lambdaのキモです。
まず、サービスコンソールから「Lambda」を選択します。
関数作成の画面が開きますので、「関数の作成」をクリックします。
以下の画面が現れます。
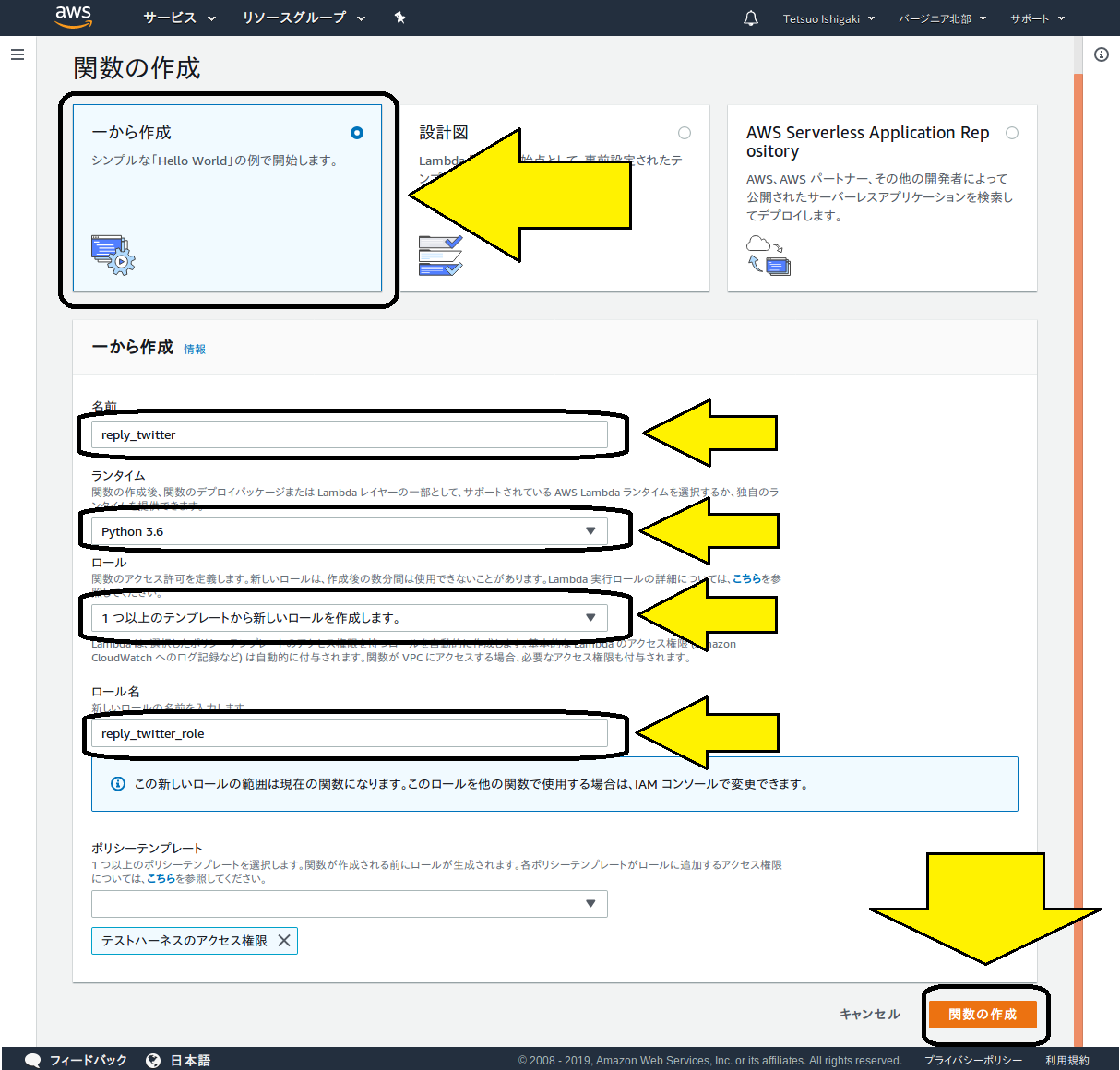
作成方法に3つの選択肢がありますが、今回のように既存のプログラムをLambdaで動作させたいときには、「一から作成」を選択してください。
引き続き、各種情報を入力します。
名前
好きな名称を入力してください。今回の事例では、reply_twitterとしています。ランタイム
使用言語の選択です。Pythonのほか、Node.js等、各種言語が選べます。Pythonでは2019年2月現在、2.7、3.6、3.7が選べます。ロール
ここら辺から、だんだんわからなくなってきますが、今回のように初めてLambdaを利用する場合は、デフォルトの「1つ以上の~」を選択してください。ロール名
好きな名称を入力してください。
「ポリシーテンプレート」という項目もありますが、とりあえずそのままにしておいてください。
最後に、「関数の作成」ボタンをクリックします。
3-2. トリガーの定義
前項で「関数の作成」ボタンをクリックすると、以下の画面が現れるので、Lambda関数の起動トリガーを定義します。
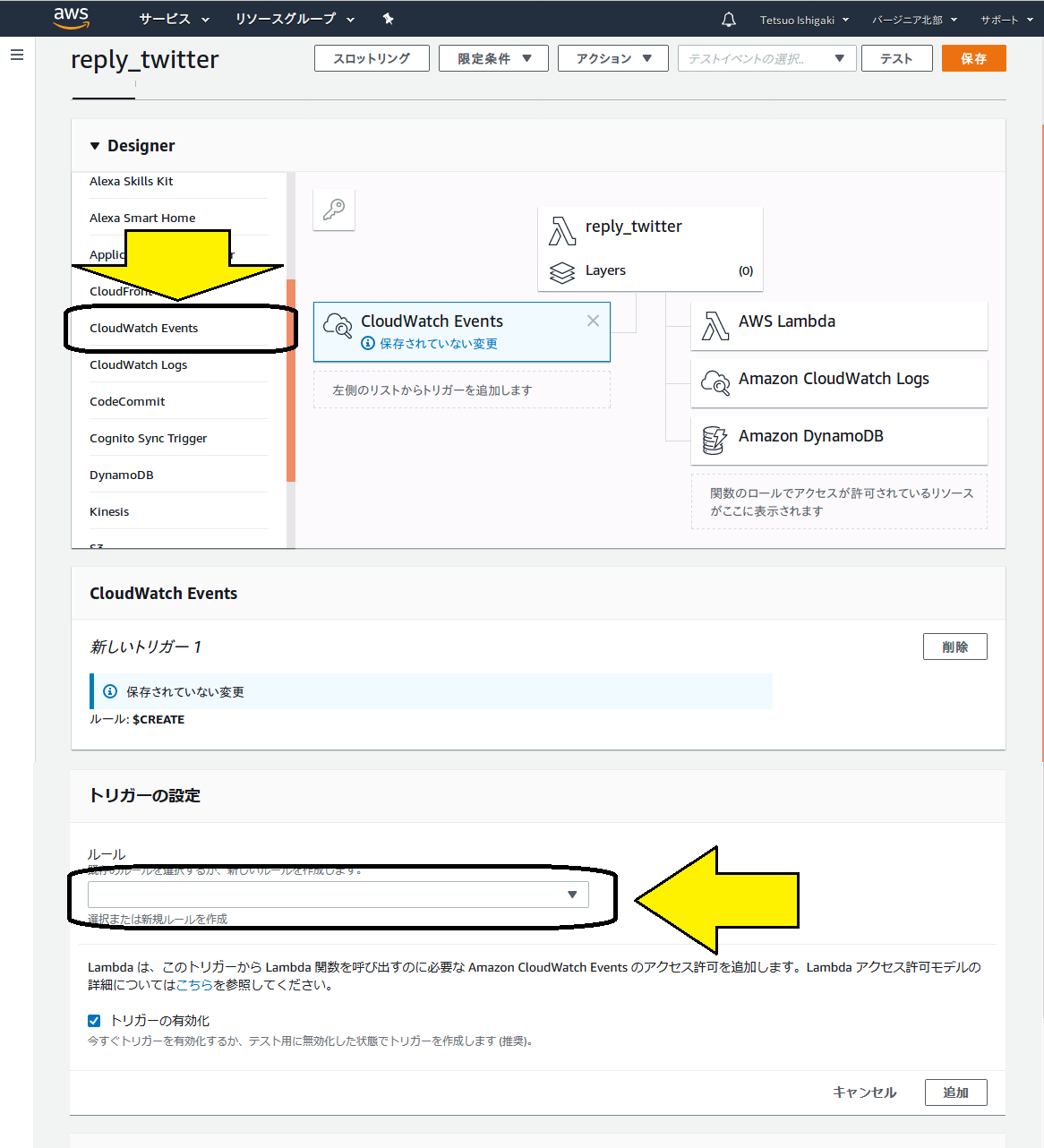
画面の左側にトリガーの選択肢があります。今回は定期起動をやりたいので、「CloudWatch Events」を選択します。
すると、下のほうにトリガーの設定メニューが現れますので、「ルール」のダイアログボックスで「新規ルールを作成」を選択します。
以下のように更に入力項目が現れますので、値を設定します。
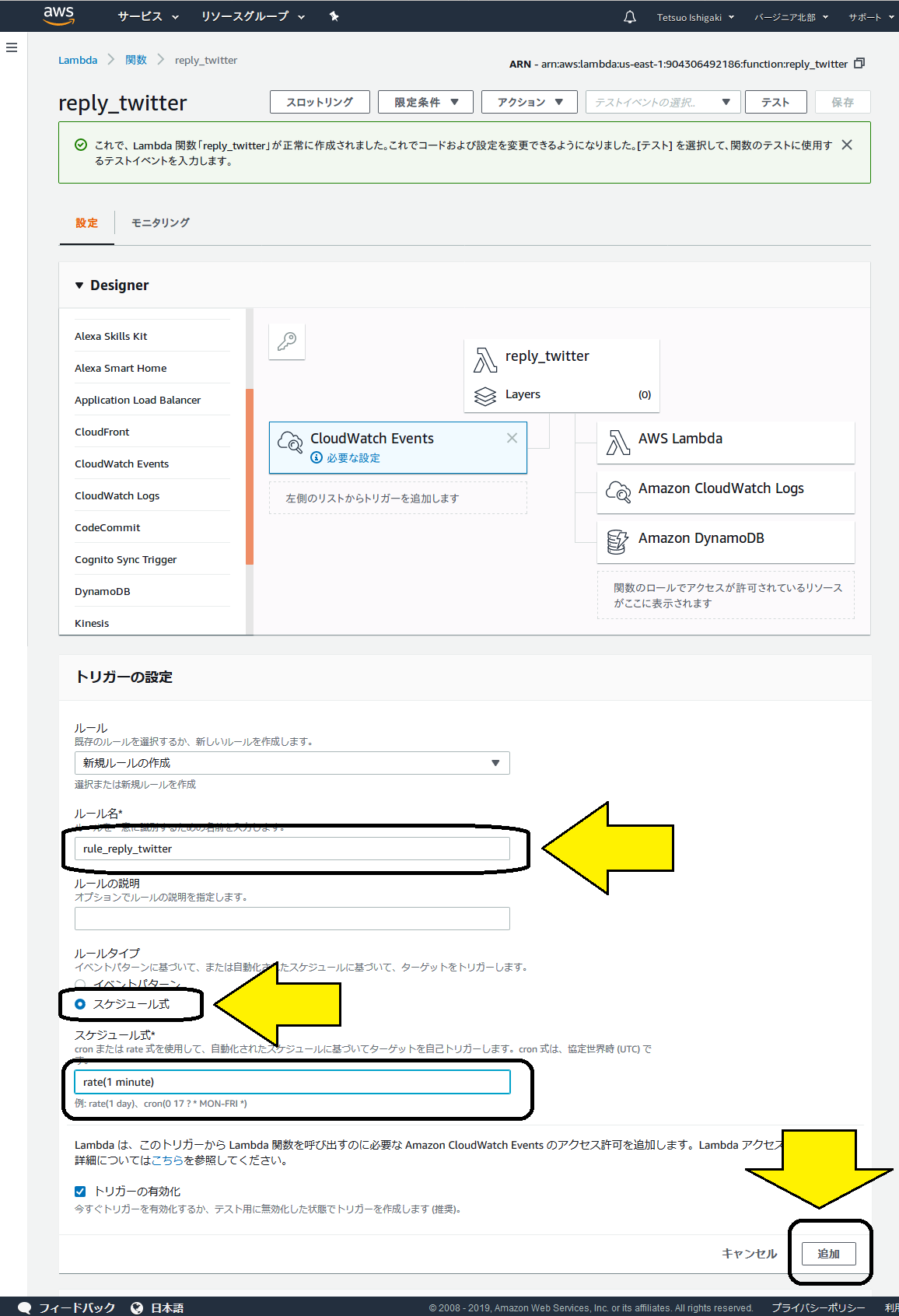
ルール名
好きな名称を入力します。ルールタイプ
「スケジュール式」を選択します。スケジュール式
定間隔起動と、cron風定刻起動の2種類から選べます。筆者は定間隔起動の方を選択しました。定間隔起動の指定フォーマットは以下の通りです:
rate(間隔値 単位)
間隔値は1以上の整数、単位はday、hour、miniteなどです。単数形と複数形の使い分けがあるので注意してください。指定できる時間間隔の最小値は1分です。
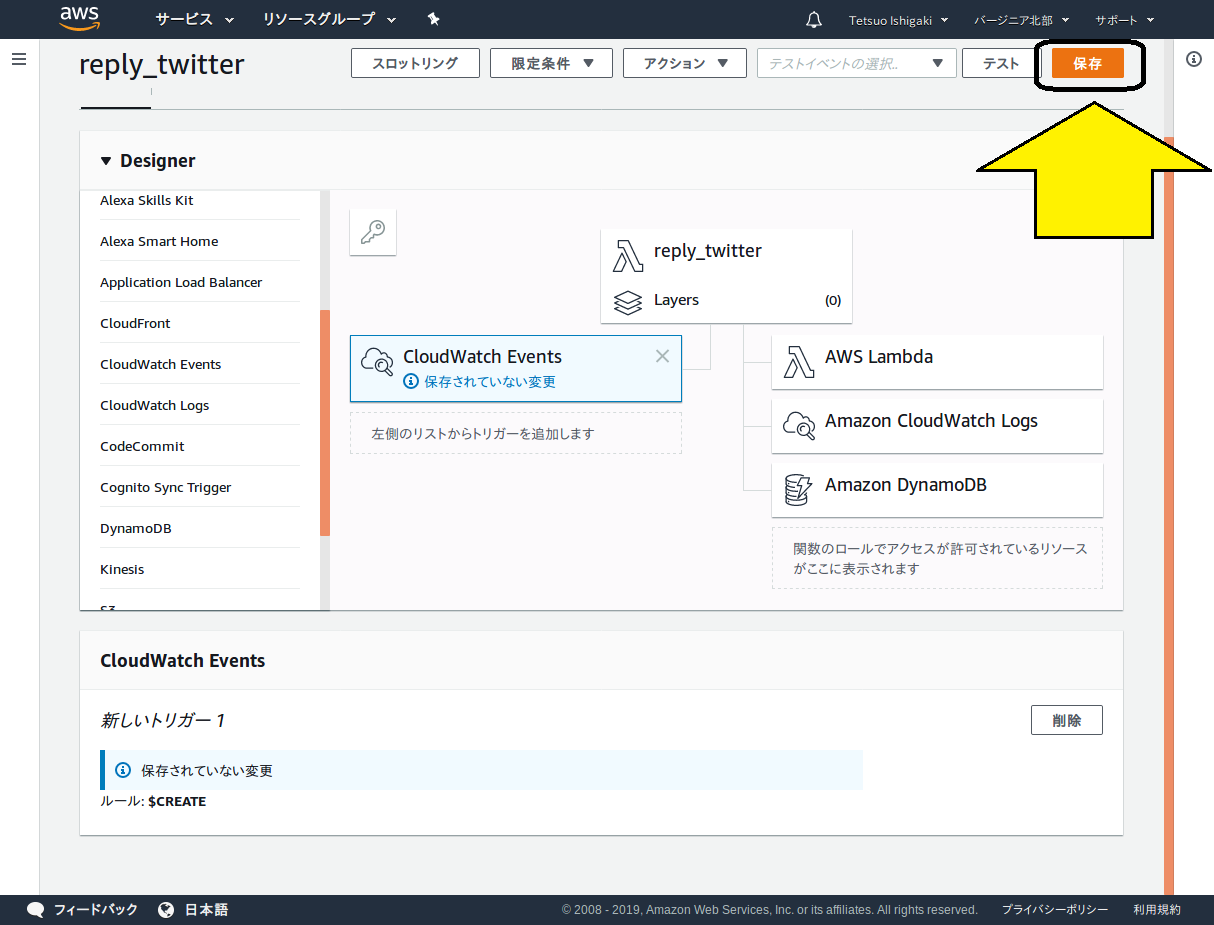
最後に、一番下にある「追加」ボタンをクリックします。画面内容が切り替わりますので、一番上にある「保存」をクリックします。
3-3. ハンドラの登録
トリガーがLambda関数を起動するためには、具体的に何を叩けばいいのか、指定してやる必要があります。これを定義するのが、ハンドラです。
前項の最後の状態で、関数名が書いてあるボタンをクリックすると、下のほうが関数コードの画面に切り替わります。その右のほうに、「ハンドラ」の入力ボックスがあるので、値を入れます。
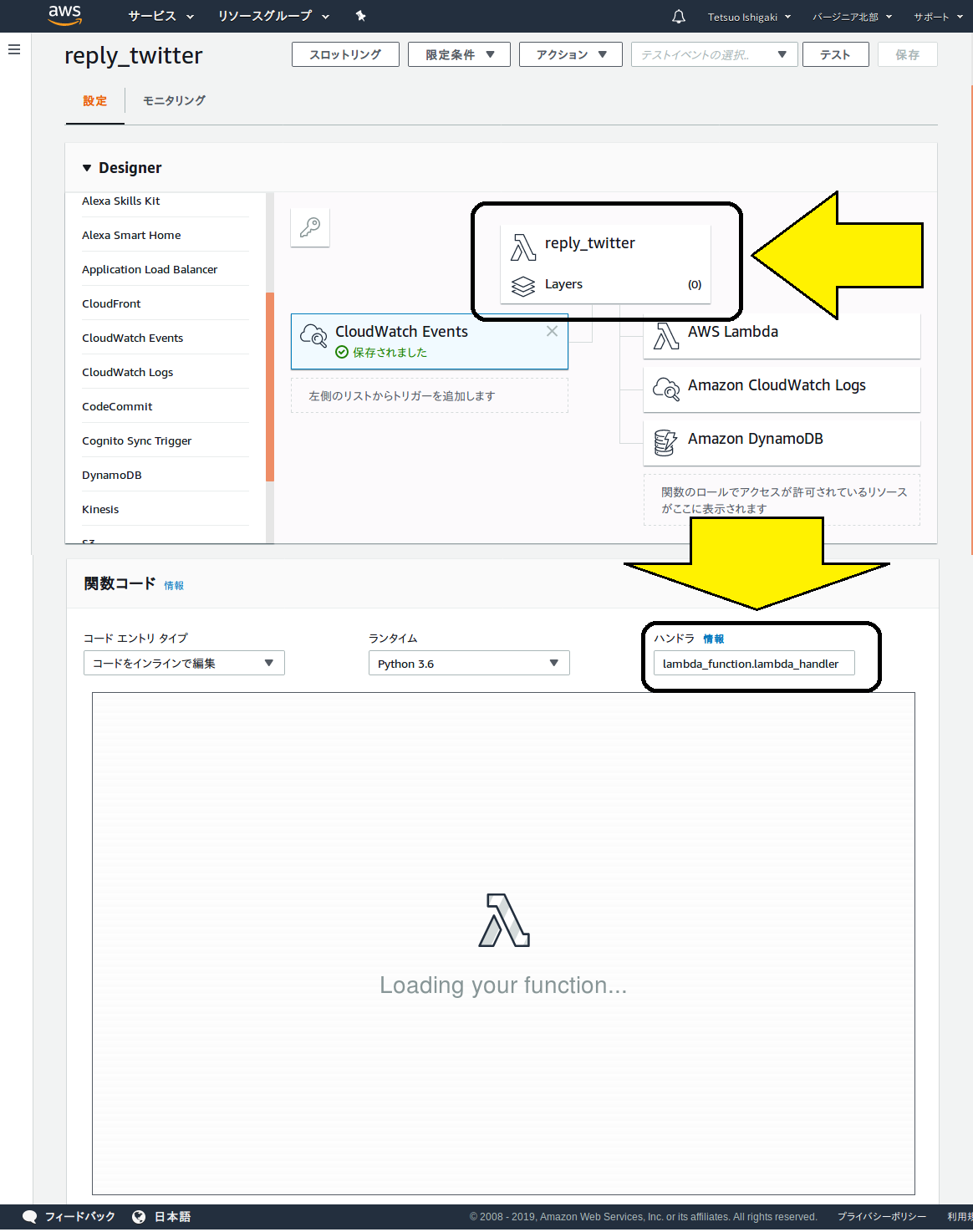
ハンドラの書式は以下の通りです:
トリガーが起動するプログラムファイル名.トリガーが起動するメソッド名
今回の場合、トリガーが呼び出すプログラムがreply_twitter_lambda.py、メソッド名がデフォルト通りlambda_handlerなので、ハンドラの指定値は以下のとおりです。
reply_twitter_lambda.py.lambda_handler
今回のように既存のプログラムをLambdaで動かす場合は、メイン処理名とハンドラの起動メソッド名を一致させます。具体的には、以下のように変更します。
BEFORE
if __name__ == '__main__':
AFTER
def lambda_handler(event, context):
ここでevent、contextは、トリガーが起動プログラムに渡す引数です。このように、2つの引数が渡されるのは決まっていることなので、必ずこのようにコーディングしてください。
引数として渡す情報は、トリガーの定義のところで指定できるようですが、今回は使用しないので何もしていません。
3-4. 関数パッケージの作成
既存のプログラムをLambda上で動かすには、動かしたいプログラムの他に、依存関係にある他のプログラム、パッケージ(numpyやtensorflowなど。mathなど、python標準のパッケージは除く)、更には学習済みパラメータファイルなどの、プログラムが読み込むファイル(read onlyのものに限る)をzipに固めて、Lambdaに登録する必要があります。
ここでread onlyと制限しているのは、(恐らく)登録したファイルを更新することができないからです(試したわけではない)。
書き込みをしたいファイルを扱う場合は、/tmpという書き込み権のあるテンポラリ領域があるので、後述するように、ここにファイルを置いて、各種操作を行ってください。
なお、/tmp配下のファイルは、(恐らく)次回の関数起動時に引き継がれないので、関数の処理が終わるまでに、s3などに保存しておく必要があります。
実際に関数パッケージのZIPファイルを作成するにあたって問題になるのが、パッケージの実体がどこにあるか、ですが、これはpip showコマンドで調べることができます。以下の要領です。
$ pip show requests
Name: requests
Version: 2.20.1
Summary: Python HTTP for Humans.
Home-page: http://python-requests.org
Author: Kenneth Reitz
Author-email: me@kennethreitz.org
License: Apache 2.0
Location: /home/gacky01/.pyenv/versions/3.6.7/lib/python3.6/site-packages
Requires: chardet, urllib3, idna, certifi
Required-by: requests-oauthlib
たいていのパッケージはsite-package配下にあるので、まずそれら全部を固めて、そこに自作のプログラム等を追加します。
以下の例では、zipファイルの名称はlambda_twitter.zipです。ハンドラが叩くメインのプログラムがreply_twitter_lambda.py、これに依存関係があるプログラムがresponse.pyとdialog_categorize.py、その他のファイルは各プログラムが参照するファイルです。
最初のzipコマンドでsite-packages配下を固め、次のコマンドでプログラムを追加し、最後のコマンドでその他のファイルを追加しています。
$ cd ~/.pyenv/versions/3.6.7/lib/python3.6/site-packages
~/.pyenv/versions/3.6.7/lib/python3.6/site-packages$ zip -r9 ~/lambda_twitter.zip .
$ cd
$ zip -r9 lambda_twitter.zip dialog_categorize.py reply_twitter_lambda.py response.py
$ zip -r9 lambda_twitter.zip param_003.hdf5 indices_freq.pickle freq_indices.pickle indices_word.pickle maxlen.pickle word_indices.pickle words.pickle
3−5. 関数パッケージの登録
3-5-1. ZIPファイルの登録
前節で作成したZIPファイルをLambdaに登録します。
以下の図のように、関数作成の画面で、3-3節のように関数名のボタンを押し、下のほうに現れる関数コードの画面の右にある「コードエントリタイプ」で、「ZIPファイルをアップロード」を選択します。
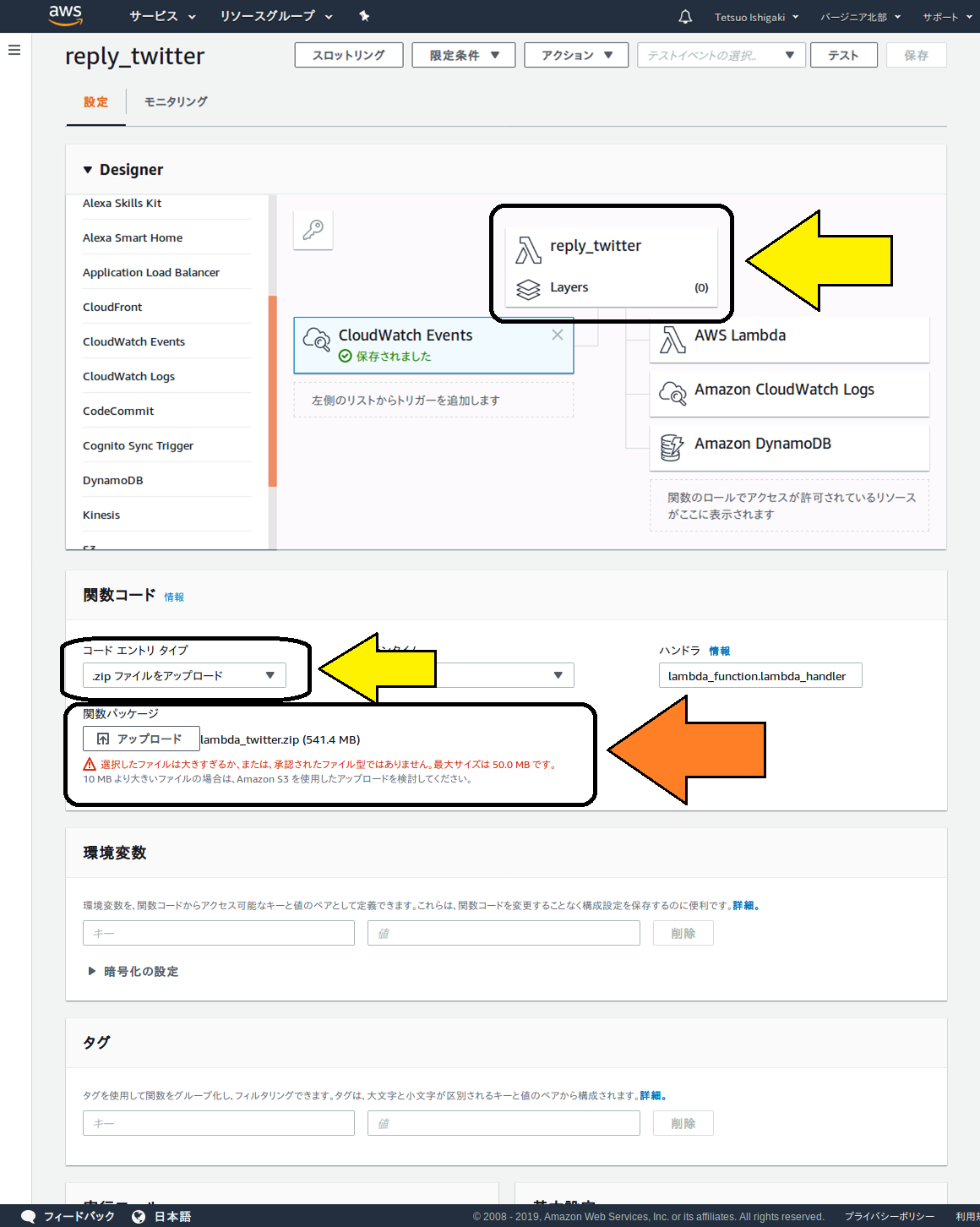
その下のダイアログボックスでアップロードしたいZIPファイルを指定すると、普通はLambdaにアップロードできますが、今回の場合、サイズが大きすぎるとか怒られてしまいましたorz。
現れた注意書きには、大きいファイルはs3経由でアップロードしてくださいとあるので、そうすることにします。
3-5-2. s3からの登録
サービスコンソール(3-1節参照)に戻って、s3を使えるようにします。手順は省略しますが、簡単にできます。s3の準備ができたら、パッケージファイルをアップロードしておきます。
改めてLambdaの関数作成画面で、コードエントリタイプに「Amazon s3からのファイルのアップロード」を選択し、その下のダイアログボックスに、s3にアップロードしたパッケージファイルのURLを設定します。
するとまたしても、サイズが大きすぎるエラーですorz。メッセージによると、解凍状態で262,144,000バイト未満でないといけないようです。
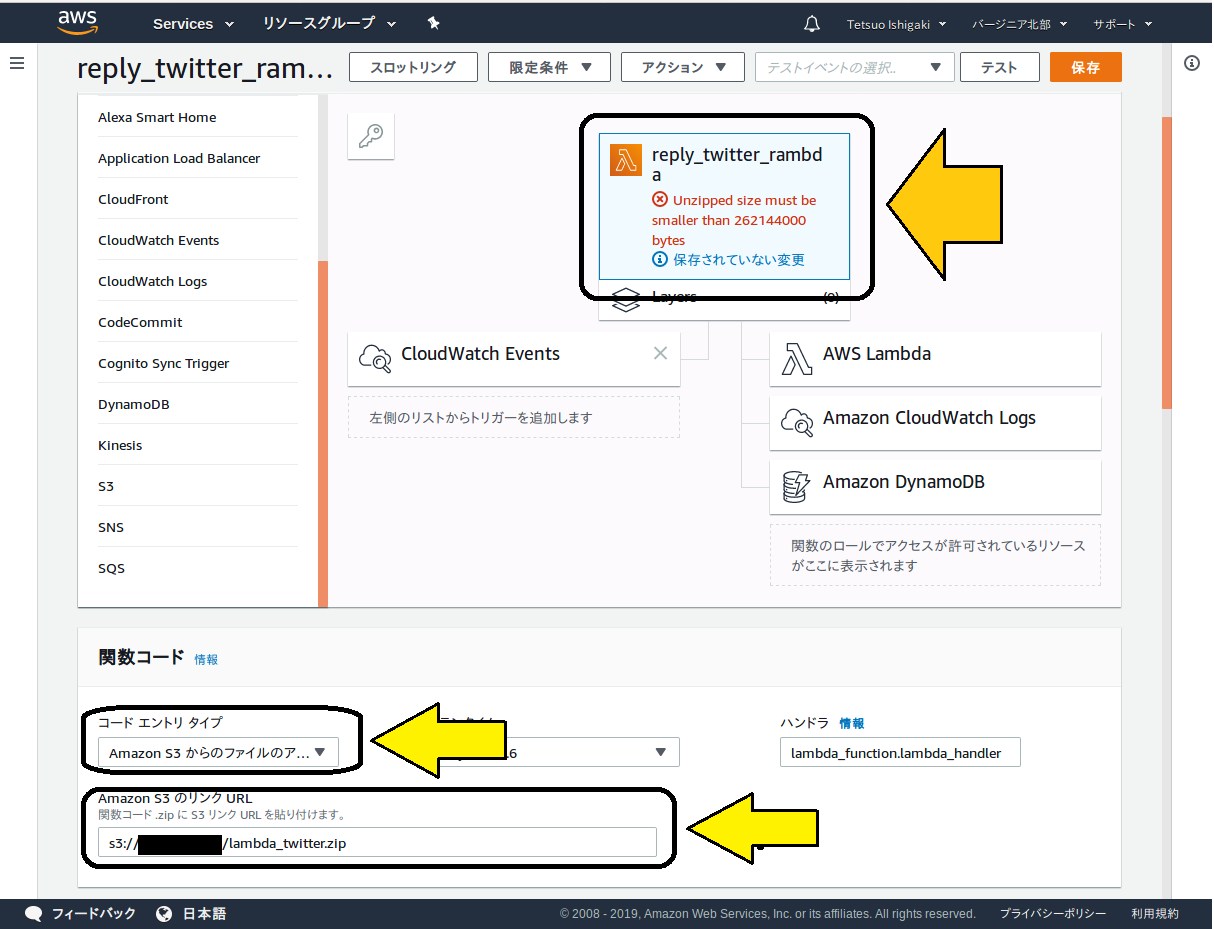
TensorFlowだけで275MBもあるので、これはもう万事休すかと思いましたが、ここで筆者は、Lambdaには/tmpという読み書き自由な作業領域が用意されていることを思い出しました。これを活用してプログラム処理で必要なファイルを/tmpにダウンロードする、すなわち
「Lambdaに登録した関数の処理で、s3から/tmpにファイルをダウンロードし、ここからパッケージをimportすれば、ひょっとして動くのでは」
と考えました。
ここまでリソースサイズで2度失敗しているので、まずは/tmpの要領確認です。調べると、512MBでした。一方、ダウンロードしたいファイルの総容量は512MBを超えるので、2度に分けてダウンロードします。1つ目のファイルをダウンロード、importしたあと、/tmpを空にして、次のファイルをダウンロードするという算段です。
ダウンロード対象のファイルは、以下の2つになります。
- TensorFlowとゆかいな仲間たち(ZIPファイル、80MB)
- ニューラルネットワークのパラメータファイル(非圧縮、418MB)
3-5-3. ファイルの配置先に/tmpを利用する
まず、Lambda関数がs3をアクセスできるように、Lambdaにs3を認識させます。
3-2節でCloudWatch Eventsを登録した時と同じ要領で、関数作成の画面の左側にあるs3のボタンをクリックすると、以下のようにs3関連の設定画面が表示されます。
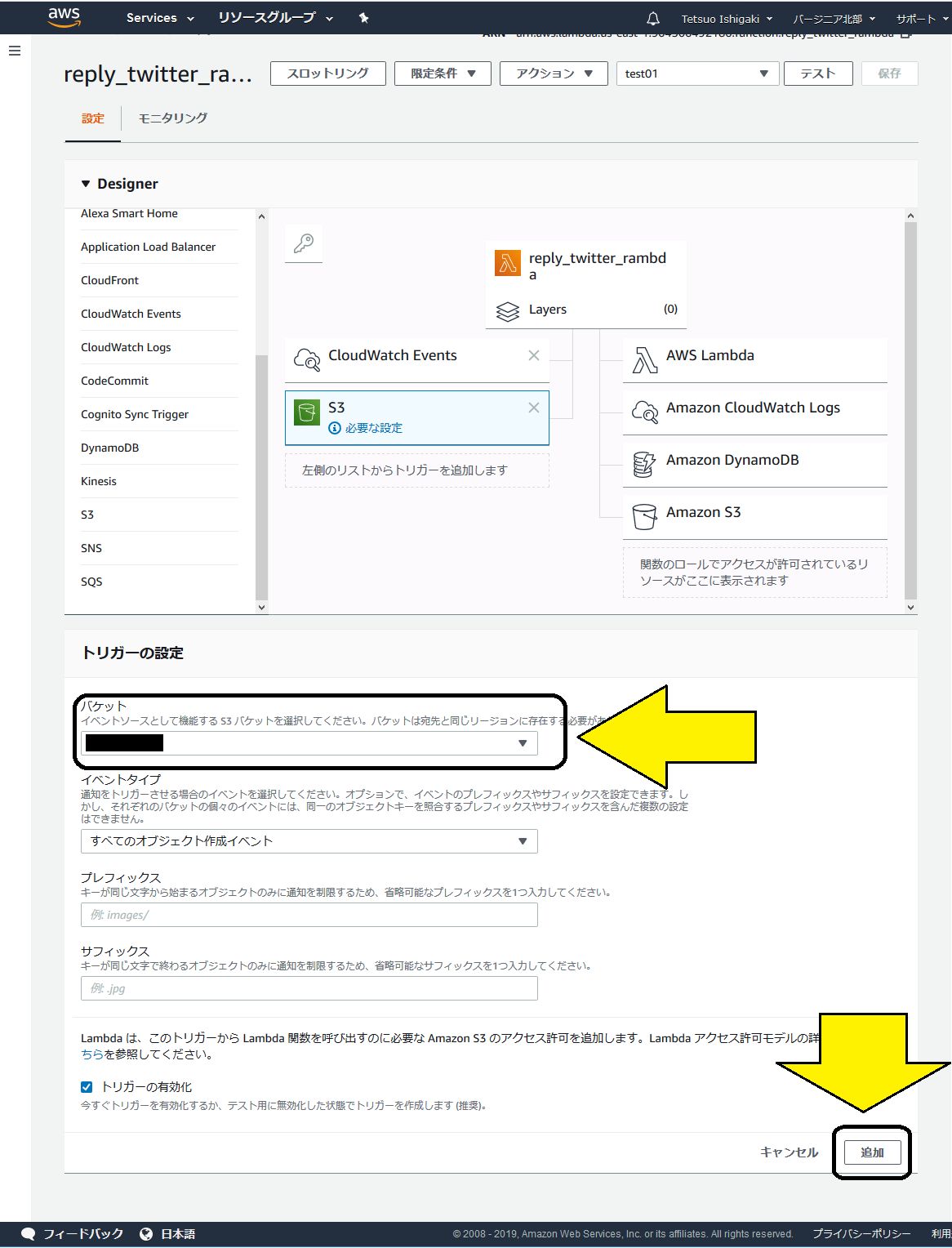
Lambdaに連動させたいバケット名を設定し、下のほうにある「追加」ボタンをクリックします。
CloudWatch Eventsの時と同じように画面が遷移しますので、上のほうにある「保存」をクリックします。
s3関連の設定はこれで終わりではなく、引き続いてアクセス権の設定を行います。
ここで最初のほうに出てきた謎の「ロール」の登場です。
サービスコンソールに戻って、「IAM」を選択します。
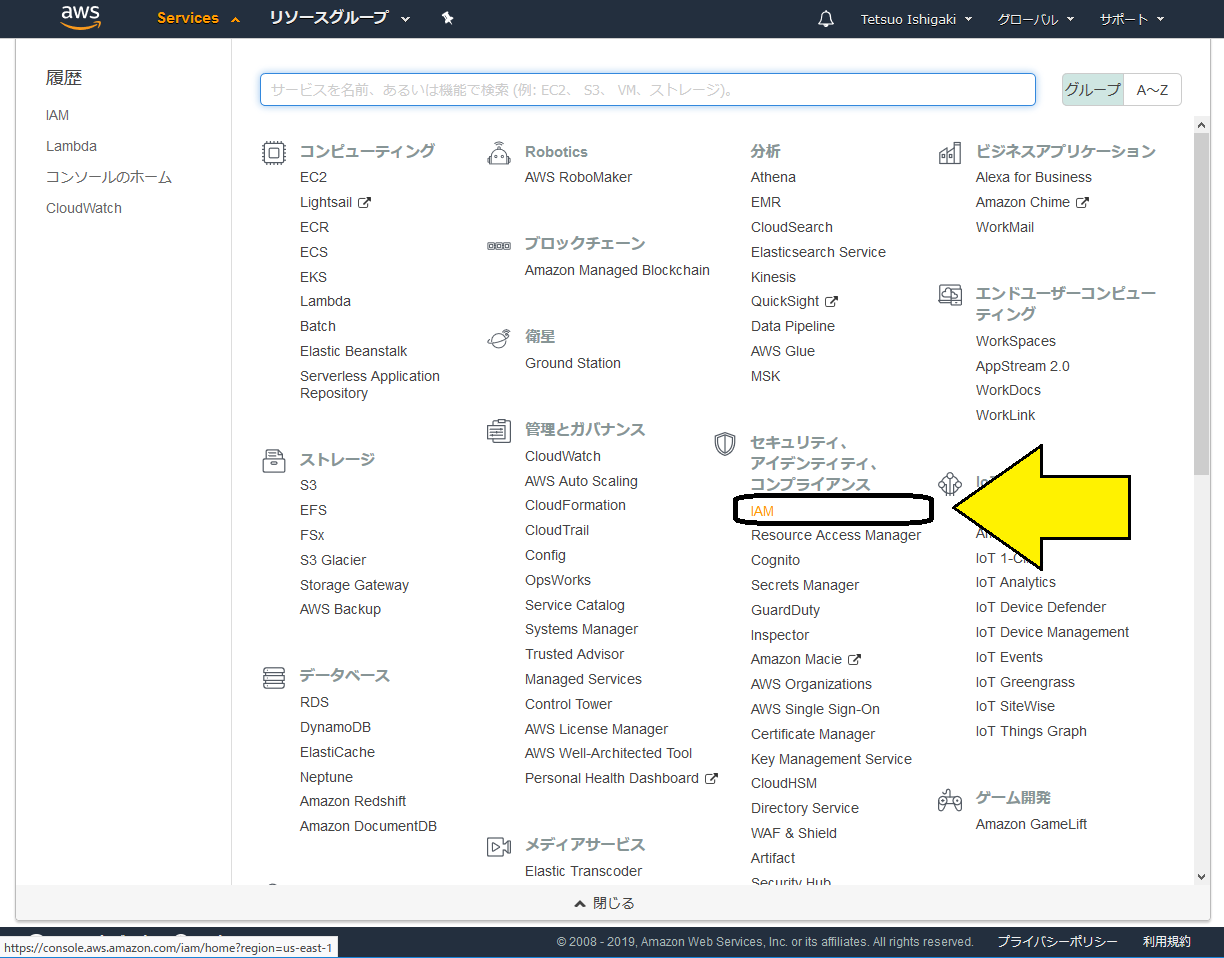
IAMの管理画面に遷移しますので、左のほうにある「ロール」を選択します。すると、先ほど作成したロールが一覧の中にありますので、これをクリックします。
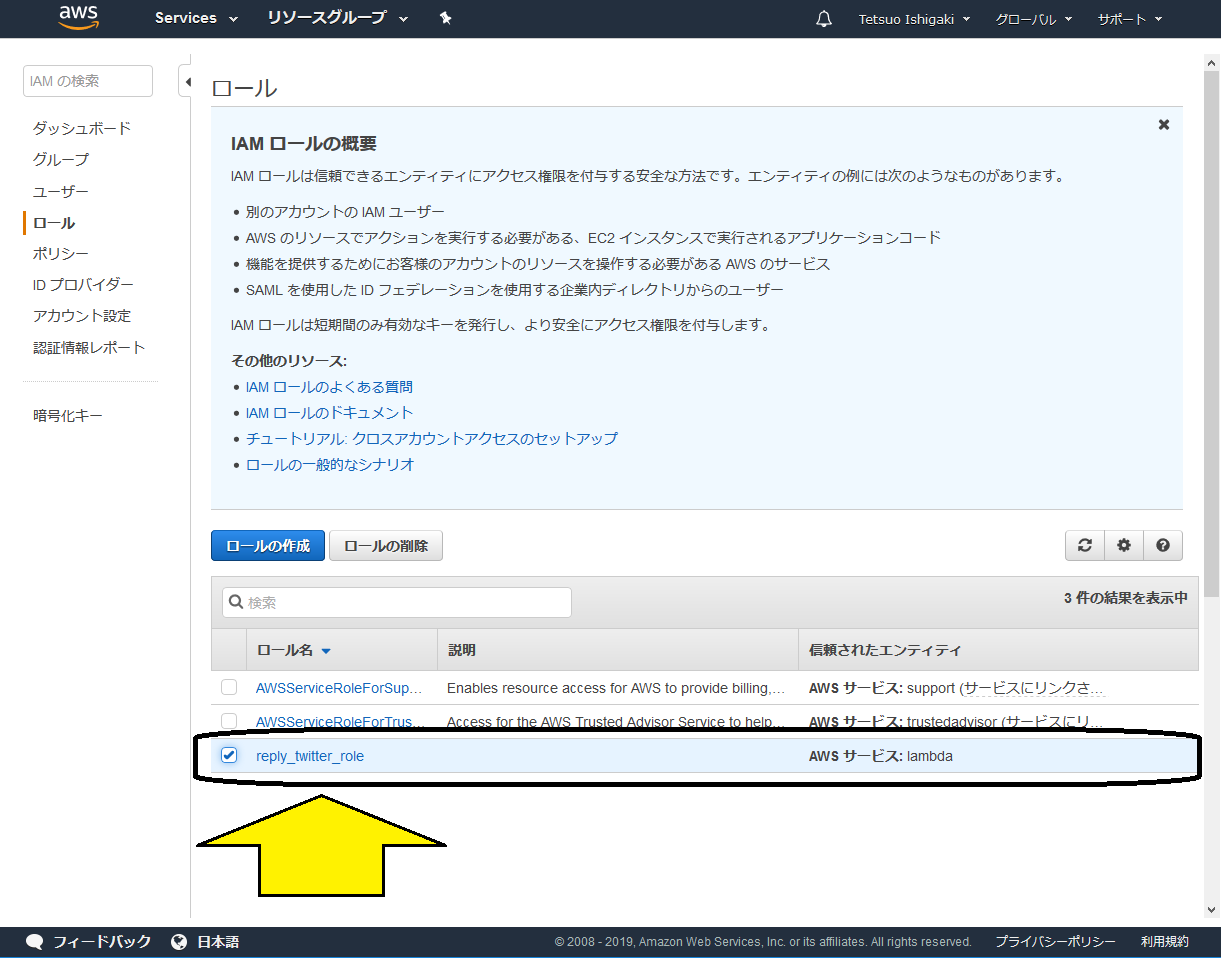
「ポリシー」を設定する画面に遷移しますので、「ポリシーをアタッチします」ボタンをクリックします。
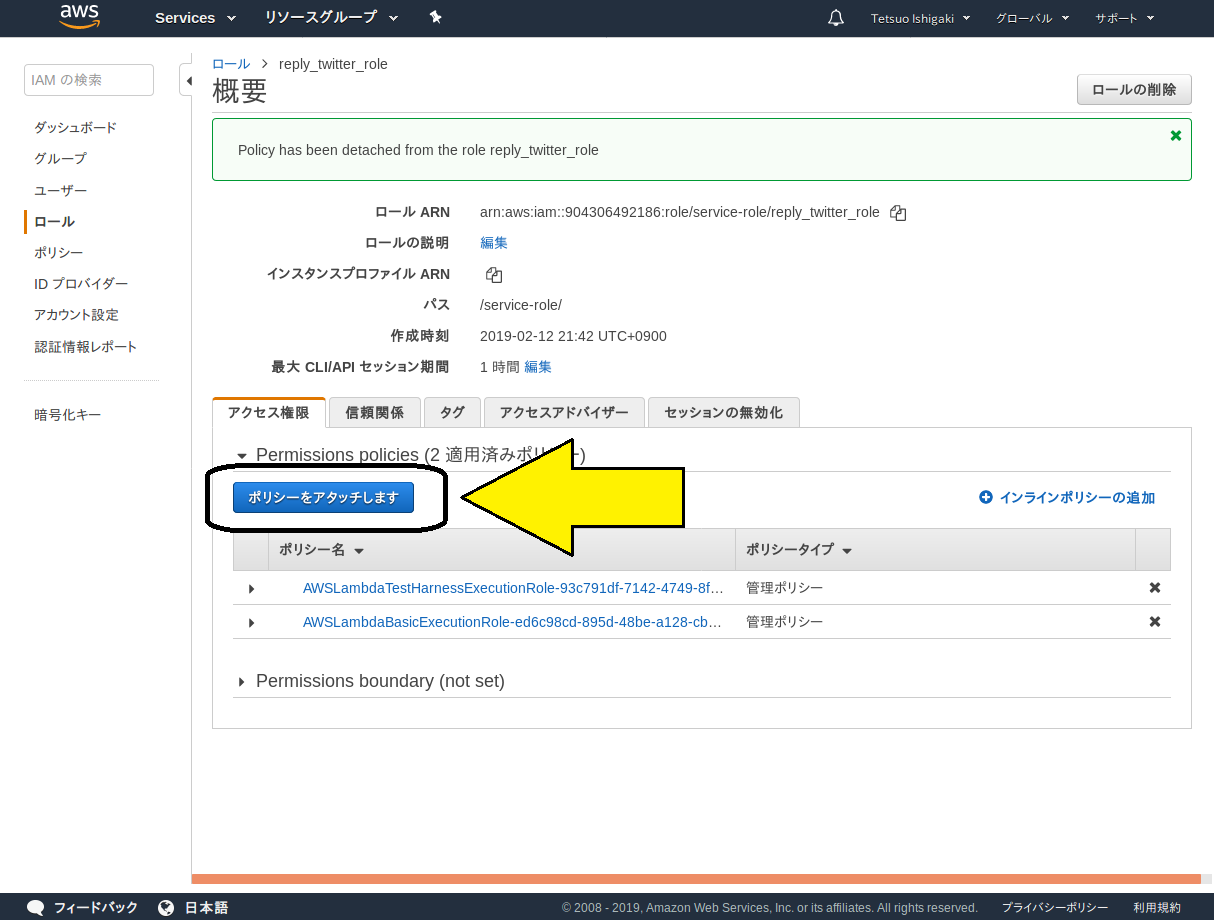
ポリシーの選択肢が現れます。今回はs3に対して読み書きの両方を実施しますので、フルアクセスを選択します。
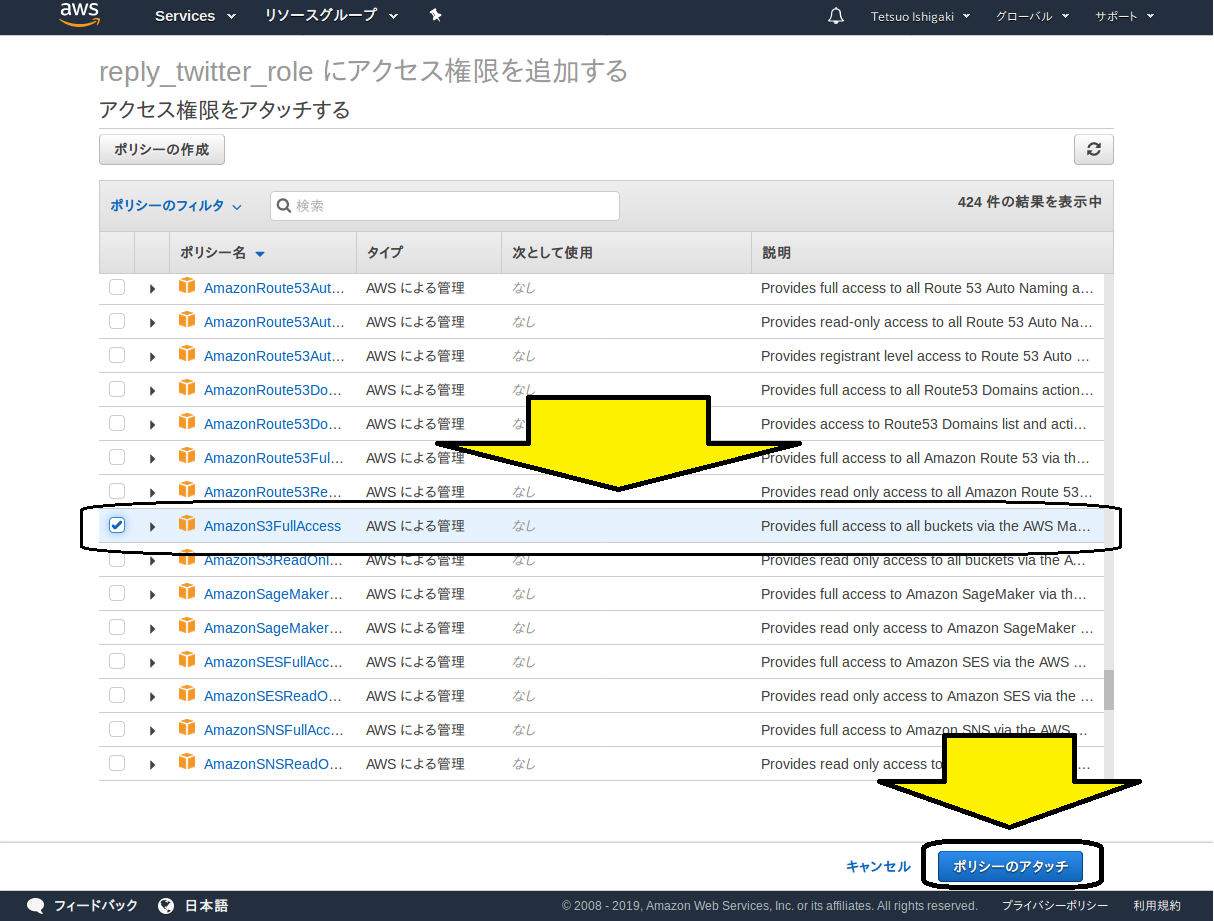
「ポリシーのアタッチ」ボタンをクリックすれば、登録完了です。
s3からファイルをダウンロードするコードは、以下の通りです。
import boto3
bucket_name = 'XXXXXXXXXX' #バケット名
s3_resource = boto3.resource('s3')
bucket = s3_resource.Bucket(bucket_name)
fname_tf = 'tf.zip'
key = fname_tf #s3上のファイル名
file_path_tf = '/tmp/' + fname_tf #ダウンロード先path
try:
bucket.download_file(key, file_path_tf) #ダウンロード処理
except Exception as e:
print(e)
ZIPファイルの解凍処理は、以下の通りです。
import zipfile
with zipfile.ZipFile(file_path_tf) as existing_zip:
existing_zip.extractall('/tmp')
Pythonに/tmpがパッケージの在処だと認識させるための処理は、以下の通りです。
import sys
sys.path.append("/tmp")
これで晴れて、tensorFlowがimportできます。
import tensorflow as tf
次のダウンロードに備えて、/tmpを空にしておきます。
import os
import shutil
import glob
# ZIPファイル削除
fname_tf = 'tf.zip'
file_path_tf = '/tmp/' + fname_tf
os.remove(file_path_tf) #tensorflowのファイルを削除
# パッケージ削除
file_list = glob.glob("/tmp/*")
print('削除前',file_list)
for i in range(0,len(file_list)) :
if file_list[i] != '/tmp/since_id.pickle' :
shutil.rmtree(file_list[i])
file_list = glob.glob("/tmp/*")
print('削除後',file_list)
削除しないファイルが1つありますが、これは処理履歴のファイルで、サイズは20Bくらいです。最後にs3に書き戻します。
ニューラルネットワークのパラメータファイルも同様の手順でs3からダウンロードします。
3-6. テスト
登録した関数を、テストします。関数作成画面の上のほうに、「テストイベントの選択」のダイアログボックスがあるので、ここから新規のテストイベントを登録します。ただ動かすだけなので、設定はデフォルトのままでOKです。
テストイベントが登録できたら、その右の「テスト」ボタンをクリックします。関数が起動され、その結果が同じ画面上に表示されます。
その結果ですが、TensorFlowのimportは目論見通り成功しました。ニューラルネットワークの生成もちゃんとできたのですが、そのあとのパラメータファイルダウンロード処理が、容量不足で失敗しました。以下はそのエラーメッセージです。
[Errno 28] No space left on device
/tmp配下のファイルが無くなっているのはメッセージから確認しましたので、削除は成功していると考えています。何か見えないゴミのようなものが残っているのか、それとも512MBというのは書き込み総量で、何度も書いたり消したりはできないとか、ちょっとわかりませんが、これ以上の対策は思いつかなかったので、残念ながら詰んだと判断しました。
4. おわりに
以上、AWS Lambda上でニューラルネットワークを動作させる試みについて記述いたしました。残念ながら容量不足で動かすことはできませんでした。
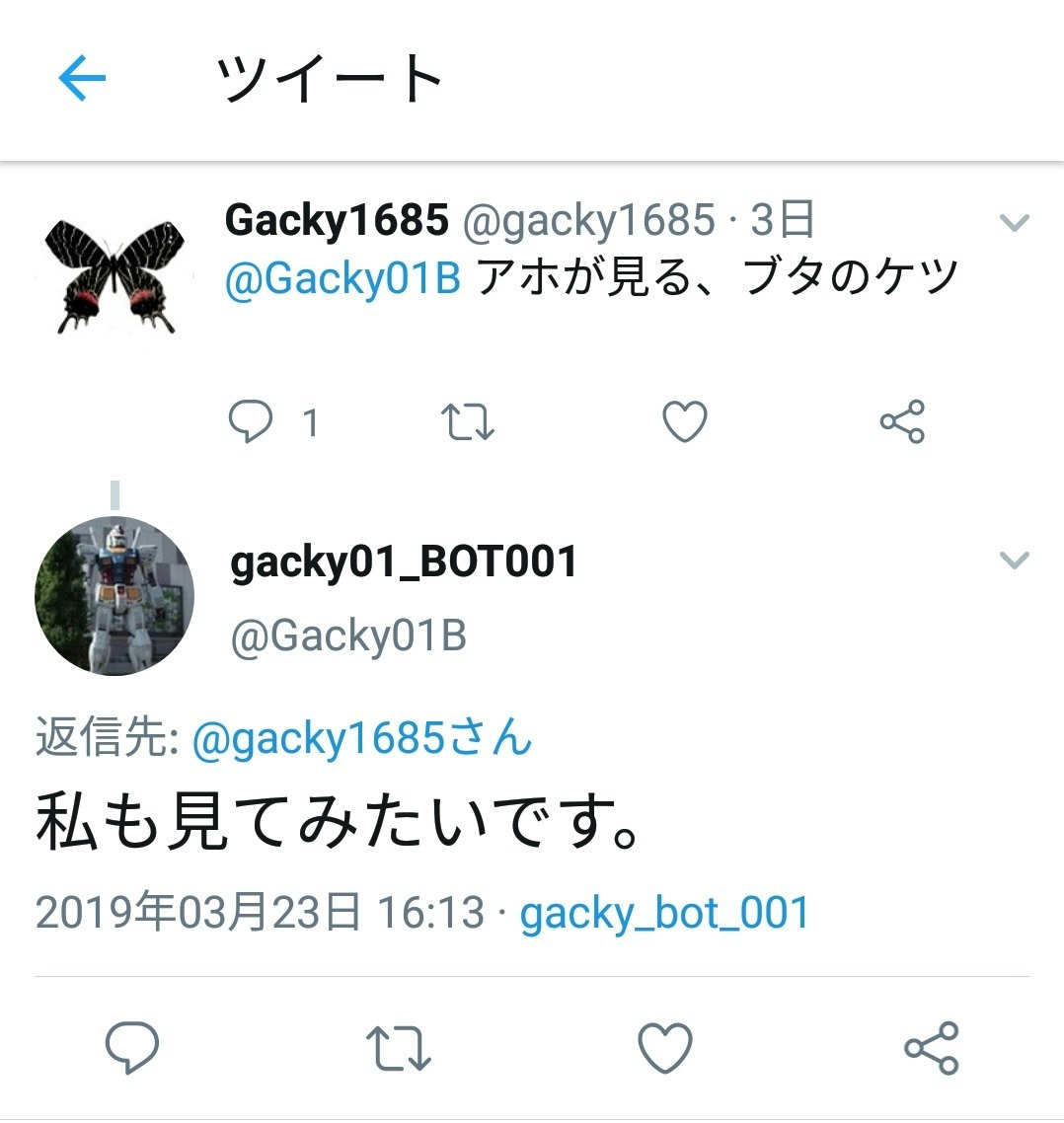
しかし、別途VPS(Virtual Private Server)を利用した試みはうまくいきました。スクリーンネーム@Gacky01Bにつぶやくと、ニューラルネットワークが生成した応答文をリプライします。以下のような感じです。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2019/2/27 | - | 初版 |
| 2 | 2019/3/25 | 4章 | Twitterボット@Gacky01Bへのリンク追加 |