本稿では、KerasベースのSeq2Seqニューラルネットワークの入出力にTwitter APIを組み込むことによって、Twitter上で自動応答するチャットボットを実現します。
1. はじめに
前回の投稿で作成、訓練したニューラルネットワークは、コマンドラインから入力した発話文に対する応答を、標準出力に出力します。Twitter APIを用いることで、この入出力をTwitter上に対して行うことができますので、これを利用してTwitter上で自動応答するチャットボットを実現します。
本稿の内容に従って実装したチャットボットが、Twitter上で動作中です。スクリーンネーム@Gacky01Bにつぶやくと、ニューラルネットワークが生成した応答文をリプライします。以下のような感じです。
本稿の前提となるソフトウェア環境は、以下の通りです。
- Ubuntu 16.04 LTS
- Python 3.6.4
- Anaconda 5.1.0
- TensorFlow-gpu 1.3.0
- Keras 2.1.4
- Jupyter 4.4.0
2. 処理仕様
2-1. アプリケーション登録とセッション確立
TwitterAPIを利用するには、Twitterの開発者用サイトで、自分が作ろうとするアプリケーションを登録して、そのアプリケーションが認証に使用する認証キーを発行してもらう必要があります。その方法については、例えば筆者の投稿「TwitterAPIを用いた会話データ収集」の3章をご参照ください。
取得した認証キーを引数にAPIを発行し、リターンとしてセッションオブジェクトを得ます。今回の実装では、認証キーはハードコーディングします。
ツイート取得やツイート送信は、セッションオブジェクトのgetメソッドやpostメソッドを使用して行います。
2-2. 発話文取得処理
自アカウントのスクリーンネームを含むツイート(自分に対するメンションとリプライ)を、処理の対象とします。セッションオブジェクトのgetメソッドにおいて、検索キーに自アカウントのスクリーンネームを指定することで、対象ツイートのみを取得できます。
2-3. 応答文生成処理
前回投稿の4-4節の処理を呼び出すことで、応答文を生成します。更に、発話者のスクリーンネームを先頭に付与します。
2-4. 応答文送信処理
セッションオブジェクトのpostメソッドを使って、応答文を送信します。その際、in_reply_to_status_idに発話ツイートidを指定します。
2-5. その他の処理
ツイート取得回数制限情報取得処理、不要文字削除処理は、筆者の投稿「TwitterAPIを用いた会話データ収集」の4章に準じます。
また、同一ツイートを重複処理しないよう、処理した発話ツイートidの中で最大のもの(=最も新しいもの)をファイルにセーブします。
次回処理時に、これを読みだしてgetメソッドのsince_idに指定すると、これより新しい発話ツイートのみを受信することができます。
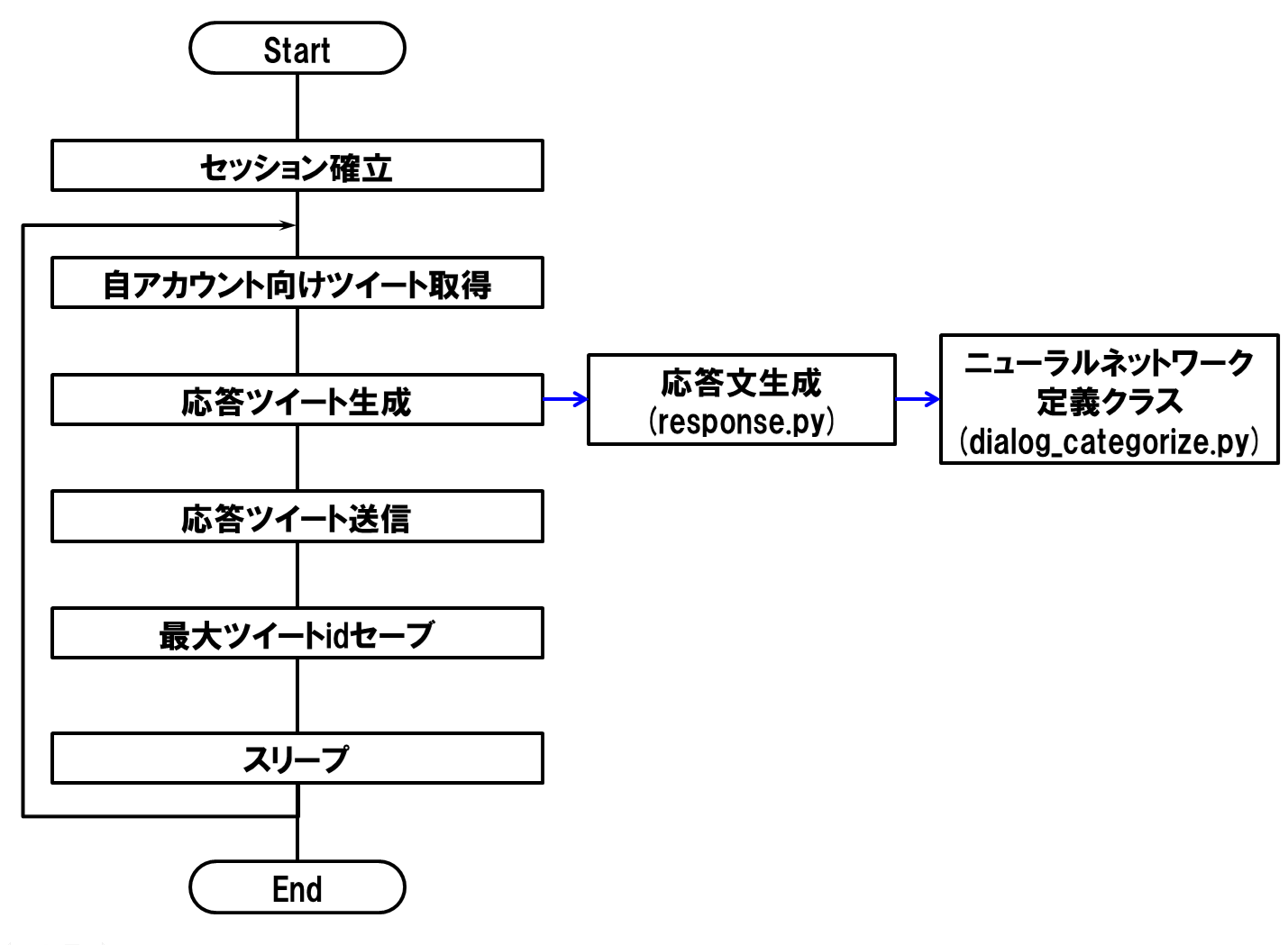
2-6. 処理フロー
以下に処理フローを示します。
3. 実装
3-1. 使用プログラム
以下の3本を使用します。項番2と項番3は、前回投稿と同じです。リンク先にソースコードがあります。3本とも、同一フォルダ内に配置します。
| 項番 | ファイル名 | 処理内容 |
|---|---|---|
| 1 | reply_twitter.py | ツイート取得と応答送信(今回作成) |
| 2 | response.py | 発話文に対する応答文生成 |
| 3 | dialog_categorize.py | 発話応答ニューラルネット定義クラス |
3-2. ソースコード
今回作成した、ツイート取得と応答送信処理のソースコードは、以下の通りです。認証キーおよびスクリーンネームはつぶしてありますので、使用される際には、適切な値で埋めてください。
# coding: utf-8
#*******************************************************************************
# *
# reply送信 *
# *
#*******************************************************************************
def postTweet(session, res_text, src_tweet_id) :
unavailableCnt = 0
url = "https://api.twitter.com/1.1/statuses/update.json" #ツイートポストエンドポイント
while True :
reset = checkLimit(session)
try :
res = session.post(url,
params = {'status':res_text,
'in_reply_to_status_id':src_tweet_id}
)
except SocketError as e:
print('ソケットエラー errno=',e.errno)
if unavailableCnt > 10:
raise
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
unavailableCnt += 1
continue
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
if res.status_code == 403: #post文重複対策
res_text = res_text + '_'
unavailableCnt += 1
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
else :
break
#*******************************************************************************
# *
# tweet本文取得 *
# *
#*******************************************************************************
def getTweet(res,since_id ,reset, BOT_user_name):
res_text = json.loads(res.text)
url1 = 'https://api.twitter.com/1.1/statuses/user_timeline.json' #今回こちらは使わない
url2 = 'https://api.twitter.com/1.1/statuses/lookup.json'
cnt_req = 0
max_tweet = since_id
tweet_list = [] # n_reply_to_status_idと応答tweetの対のリスト
for tweet in res_text['statuses']:
tweet_id=tweet['id'] # tweetのid
if max_tweet < tweet_id :
max_tweet = tweet_id
user = tweet['user']
screen_name = user['screen_name']
if screen_name == BOT_user_name :
continue
res_sentence = tweet['text']
#RTを対象外にする
if res_sentence[0:3] == "RT " :
continue
res_sentence = screening(res_sentence)
if res_sentence == '' :
continue
tweet_list.append([tweet_id, screen_name, res_sentence])
print(screen_name, res_sentence)
if len(tweet_list) == 0 :
return max_tweet,tweet_list
return max_tweet,tweet_list
#*******************************************************************************
# *
# tweet本文スクリーニング *
# *
#*******************************************************************************
def screening(text) :
s = text
#RTを外す
if s[0:3] == "RT " :
s = s.replace(s[0:3],"")
#@screen_nameを外す
while s.find("@") != -1 :
index_at = s.find("@")
if s.find(" ") != -1 :
index_sp = s.find(" ",index_at)
if index_sp != -1 :
s = s.replace(s[index_at:index_sp+1],"")
else :
s = s.replace(s[index_at:],"")
else :
s = s.replace(s[index_at:],"")
#改行を外す
while s.find("\n") != -1 :
index_ret = s.find("\n")
s = s.replace(s[index_ret],"")
#URLを外す
s = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", s)
#絵文字を「。」に置き換え その1
non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), '。')
s = s.translate(non_bmp_map)
#絵文字を「。」に置き換え その2
s=''.join(c if c not in emoji.UNICODE_EMOJI else '。' for c in s )
#置き換えた「。」が連続していたら1つにまとめる
while s.find('。。') != -1 :
index_period = s.find('。。')
s = s.replace(s[index_period:index_period+2],'。')
#ハッシュタグを外す
while s.find('#') != -1 :
index_hash = s.find('#')
s = s[0:index_hash]
return s
#*******************************************************************************
# *
# 回数制限を問合せ、アクセス可能になるまで wait する *
# *
#*******************************************************************************
def checkLimit(session):
unavailableCnt = 0
url = "https://api.twitter.com/1.1/application/rate_limit_status.json"
while True :
try :
res = session.get(url)
except SocketError as e:
print('erron=',e.errno)
print('ソケットエラー')
if unavailableCnt > 10:
raise
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
unavailableCnt += 1
continue
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
remaining_search, remaining_limit ,reset = getLimitContext(json.loads(res.text))
if remaining_search <= 1 or remaining_limit <= 1:
waitUntilReset(reset+30)
else :
break
return reset
#*******************************************************************************
# *
# sleep処理 resetで指定した時間スリープする *
# *
#*******************************************************************************
def waitUntilReset(reset):
seconds = reset - time.mktime(datetime.datetime.now().timetuple())
seconds = max(seconds, 0)
sys.stdout.flush()
time.sleep(seconds + 10) # 念のため + 10 秒
#*******************************************************************************
# *
# 回数制限情報取得 *
# *
#*******************************************************************************
def getLimitContext(res_text):
# searchの制限情報
remaining_search = res_text['resources']['search']['/search/tweets']['remaining']
reset1 = res_text['resources']['search']['/search/tweets']['reset']
# 制限情報取得の制限情報
remaining_limit = res_text['resources']['application']['/application/rate_limit_status']['remaining']
reset3 = res_text['resources']['application']['/application/rate_limit_status']['reset']
return int(remaining_search),int(remaining_limit) ,max(int(reset1),int(reset3))
#*******************************************************************************
# *
# 応答文生成 *
# *
#*******************************************************************************
def generate_reply(param, tweeted_sentence) :
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input = gen_res.encode_request(tweeted_sentence, maxlen_e, word_indices, words, encoder_model)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence = gen_res.generate_response(e_input, n_hidden, maxlen_d, output_dim, word_indices,
freq_indices, indices_word, encoder_model, decoder_model)
return decoded_sentence
#*******************************************************************************
# *
# メイン処理 *
# *
#*******************************************************************************
if __name__ == '__main__':
from requests_oauthlib import OAuth1Session
import json
import datetime, time, sys
import re
import datetime
import emoji
import sys
import pickle
import os
import math
from socket import error as SocketError
import errno
#--------------------------------------------------------------------------*
# *
# ニューラルネットワーク初期化 *
# *
#--------------------------------------------------------------------------*
import response as gen_res
args = sys.argv
#args[1] = 'param_001' # jupyter上で実行するとき用
vec_dim = 400
n_hidden = int(vec_dim*1.5 ) #隠れ層の次元
#データロード
word_indices ,indices_word ,words ,maxlen_e, maxlen_d ,freq_indices = gen_res.load_data()
#入出力次元
input_dim = len(words)
output_dim = math.ceil(len(words) / 8)
#モデル初期化
model, encoder_model ,decoder_model = gen_res.initialize_models(args[1] ,maxlen_e, maxlen_d,
vec_dim, input_dim, output_dim, n_hidden)
#--------------------------------------------------------------------------*
# *
# twitter_auth *
# *
#--------------------------------------------------------------------------*
CK = '*************************' # Consumer Key
CS = '**************************************************' # Consumer Secret
AT = '**************************************************' # Access Token
AS = '*********************************************' # Accesss Token Secert
session = OAuth1Session(CK, CS, AT, AS)
#--------------------------------------------------------------------------*
# *
# tweet取得処理 *
# *
#--------------------------------------------------------------------------*
#total= -1
BOT_user_name = '********'
BOT_screen_name = '@' + BOT_user_name
total_count = 0
cnt = 0
unavailableCnt = 0
url = 'https://api.twitter.com/1.1/search/tweets.json'
#since_idロード
if os.path.isfile('since_id.pickle') :
with open('since_id.pickle', 'rb') as f :
since_id=pickle.load(f)
else :
since_id = 1092760343191871493
while True:
#----------------
# 回数制限を確認
#----------------
#
reset = checkLimit(session)
get_time = time.mktime(datetime.datetime.now().timetuple()) #getの時刻取得
try :
res = session.get(url, params = {'q':BOT_screen_name, 'since_id':since_id, 'count':100})
except SocketError as e:
print('ソケットエラー errno=',e.errno)
if unavailableCnt > 10:
raise
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
unavailableCnt += 1
continue
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
res_text = json.loads(res.text)
#print(res_text)
#----------------
# tweet本文と発信者取得
#----------------
since_id ,tweet_list = getTweet(res,since_id,reset, BOT_user_name)
#----------------
# 応答送信
#----------------
for i in range(len(tweet_list)) :
res_text = '@'+tweet_list[i][1] + ' '+ generate_reply(args[1], tweet_list[i][2])
print(res_text)
postTweet(session, res_text, tweet_list[i][0])
#----------------
#since_id 保存
#----------------
with open('since_id.pickle', 'wb') as f :
pickle.dump(since_id , f)
current_time = time.mktime(datetime.datetime.now().timetuple())
# 処理時間が2秒未満なら2+10秒wait
if current_time - get_time < 2 :
waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 2)
4. 実行
今回作成したreply_twitter.pyは、引数を1つ持ち、重み行列ファイル名(拡張子を除く)を指定するようになっています。以下に起動コマンドの投入例を示します。
$ python reply_twitter.py param_01
コマンドが起動されると、プログラムは自アカウント向けツイートの有無を一定間隔でポーリングし、ツイートがあればその応答を自動送信します。
処理を終了するには、ctrl+cを入力します。
5. おわりに
以上、前回投稿で作成、訓練したニューラルネットワークを使用したTwitter自動応答チャットボットの実装について、記述しました。
次のアクションとして、チャットボットの24H運転にチャレンジしました。まず、AWSのサーバレスサービス(AWS Lambda)を利用して実現しようとしましたが、これはうまくいきませんでした。
そこで、VPS(Virtual Private Server)を利用することにしました。こちらはうまくいきました。料金はそれなりにかかりますが、メモリやストレージの制約がないのは快適です。スクリーンネーム@Gacky01Bにつぶやくと、ニューラルネットワークが生成した応答文をリプライします。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2019/2/7 | - | 初版 |
| 2 | 2019/2/27 | 5章 | 筆者投稿「ニューラルネットワークを動作させようとしたが、リソース不足で涙を呑んだ件」へのリンク追加 |
| 3 | 2019/3/25 | 1章、5章 | Twitterボット@Gacky01Bへのリンク追加 |