本稿では、チャットボット用に作成したKerasベースのSeq2Seq(Sequence to Sequence)ニューラルネットワークを使って、文章生成にトライした結果を記述します。訓練用の日本語コーパスには、Wikipediaの公開データをダウンロードして使用しました。
以下は、川端康成の「雪国」冒頭を入力に、文章生成を行った結果です。
国境の長いトンネルを抜けると雪国だった。列車の運転には代表をしていたが、突然横に落ちてくる車を見つける。車は中に入ってくる車に乗っているものの、車が五郎のもとにトラストの「遠隔車」に押され、車は線路上に転落死する。それからしばらく後、ついに日本車は本来の基地に戻される。その後、同基地にある日本基地の調査員が到着する。第一次世界大戦においてアメリカが英米に協力していた。アメリカはドイツとアメリカに協力し、アメリカとフランスの利害関係を維持するために、英国による占領を拒否した(アメリカの対米宣戦)。
続き
アメリカの外交工作は、アメリカ合衆国の輸入のもしくはドイツの主権が問題視された。この問題から、イギリスとドイツは、アメリカの主権が合衆国の主権を維持すると主張し、イギリスはイギリスの主権を維持することを求めていた。フランスは、イギリスに対し、イギリスが戦争を開始することを禁止したことを主張した。イギリスは非難を表明し、フランスはこの条約を同盟国とすることを認めた。これにより、フランスはイギリスがその地位にAVを派遣することを決めた。フランスはAVをはじめ、その他の映画監督を招聘している。女優をはじめ、車や雑誌などでは、映画撮影などに使われることもある。日本国内では、映画撮影に用いられる映画もある。また、『文藝春秋』では、「私が語るな」と線路を便に乗せて海を茂に譲っていたという。また、『文藝春秋』では、本の話で「私は途中で見たい」などと述べている。また、「私は、私がもう一人の人物を演じるからである」と語っていた。この作品の中では、「私は、この女性を2人の人物と呼ぶべき」という。「私は、自分は自分のことを本当に人間か、物語の中で、最後の女性として生きるのが、この女性の形を取る」という埋葬感情に触れている。この言葉は、「私の娘」という言葉を基にしており、このフランク・ロイド・ジョージによって、「私は私の死を感じた。私とは別に、私の娘」とも呼ばれた。妻とは親友である。2人の娘は野球部の監督でもあり、1975年の世界選手権で優勝した。モントリオールオリンピックでの優勝経験は、オリンピック出場ではなく、イタリア代表監督としての活躍だった。現役引退後は、イタリアサッカー協会の指導者を務めている。2009-10シーズンのセリエBにおいては、シーズン開幕前にクラブの監督に就任した。2010年に退団し、2014年まで、いわば2014-15シーズンの監督に就任した。2015年、UEFAチャンピオンズカップ優勝を経験した。2015年4月、私はリーガ・エスパニョーラのセグンダ・ディビシオンに復帰した。2014-15シーズンはプリメーラ・ディビシオンへの昇格を果たした。2015年3月22日、セグンダ・ディビシオンB(1部)のセグンダ・ディビシオンB(1部)昇格を決めたセリエC.89の創設者として初参加を果たした。2017-18シーズン、セグンダ・ディビシオンB(1部)でリーグ優勝を果たした。2016年シーズンにセグンダ・ディビシオン(2部)へ昇格したが、昇格プレーオフで下位クラブと対戦。この試合では勝ち点3を記録したものの勝ち点1と、結果を残せずにシーズンを終えた。2017年11月7日、FCミラーと契約した。2016年9月、インテルCO. (期限付きオプション付き) に移籍した。1. はじめに
1-1. LSTMによる単語逐次生成型の文章生成
筆者は以前、単語列の入力から次の単語を予測するニューラルネットワークをKerasベースのLSTMで実装し、これを再帰的に動かすことで、文章生成にチャレンジしてみました。下図はそのイメージです。
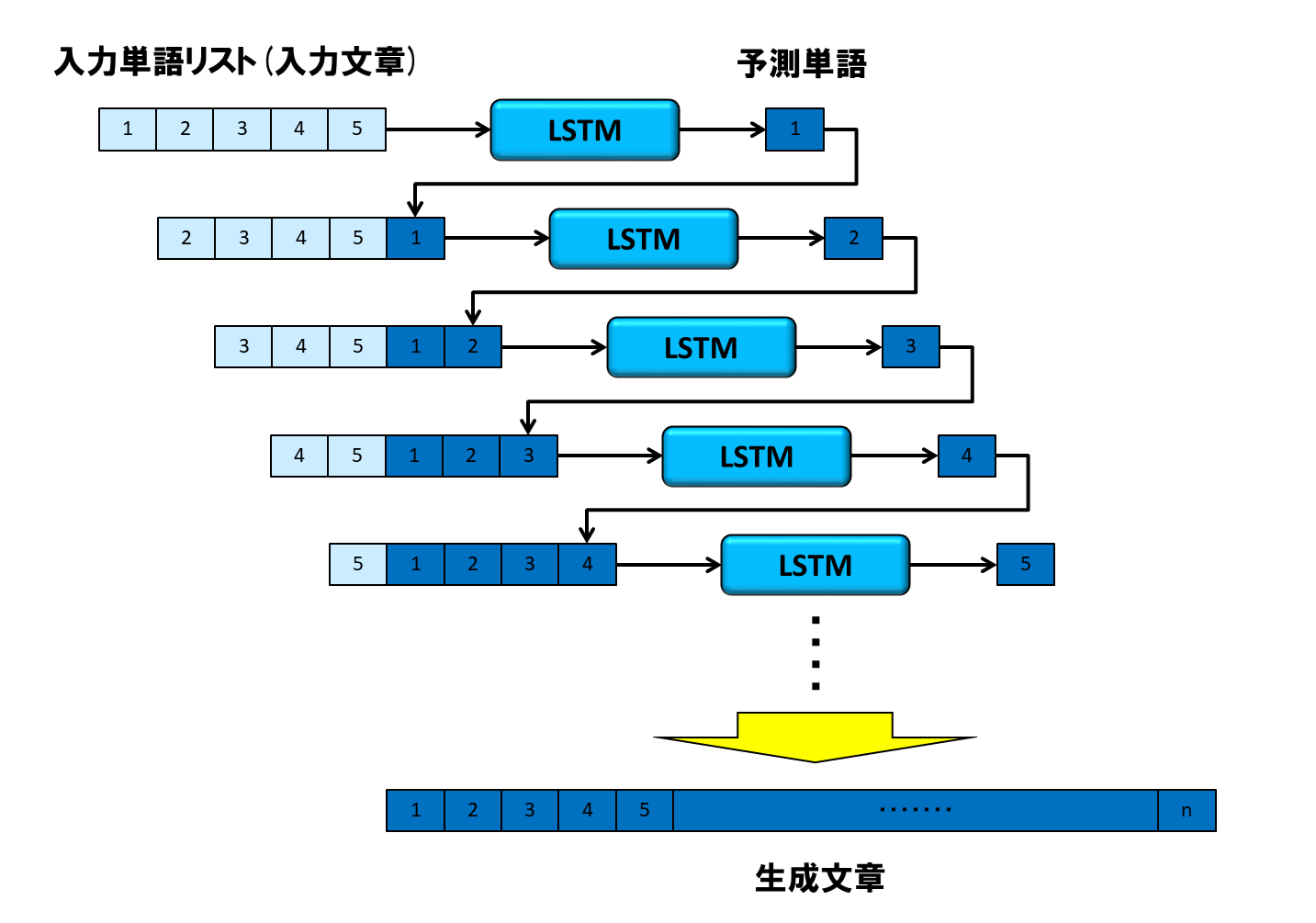
予測精度を向上させるために各種施策を打ったのですが、学習データに無い文章を入力したときの生成文章は、正直微妙なものでした。
1-2. Seq2Seqによる文逐次生成型の文書生成
そこで今回は、Seq2Seqを文章生成に応用してみることにしました。チャットボット用に構築したSeq2Seqニューラルネットワークは、発話文から応答文を出力するので、これを再帰的に使用すれば、長い文章を自動生成できるのではないかと考えました。下図はそのイメージです。
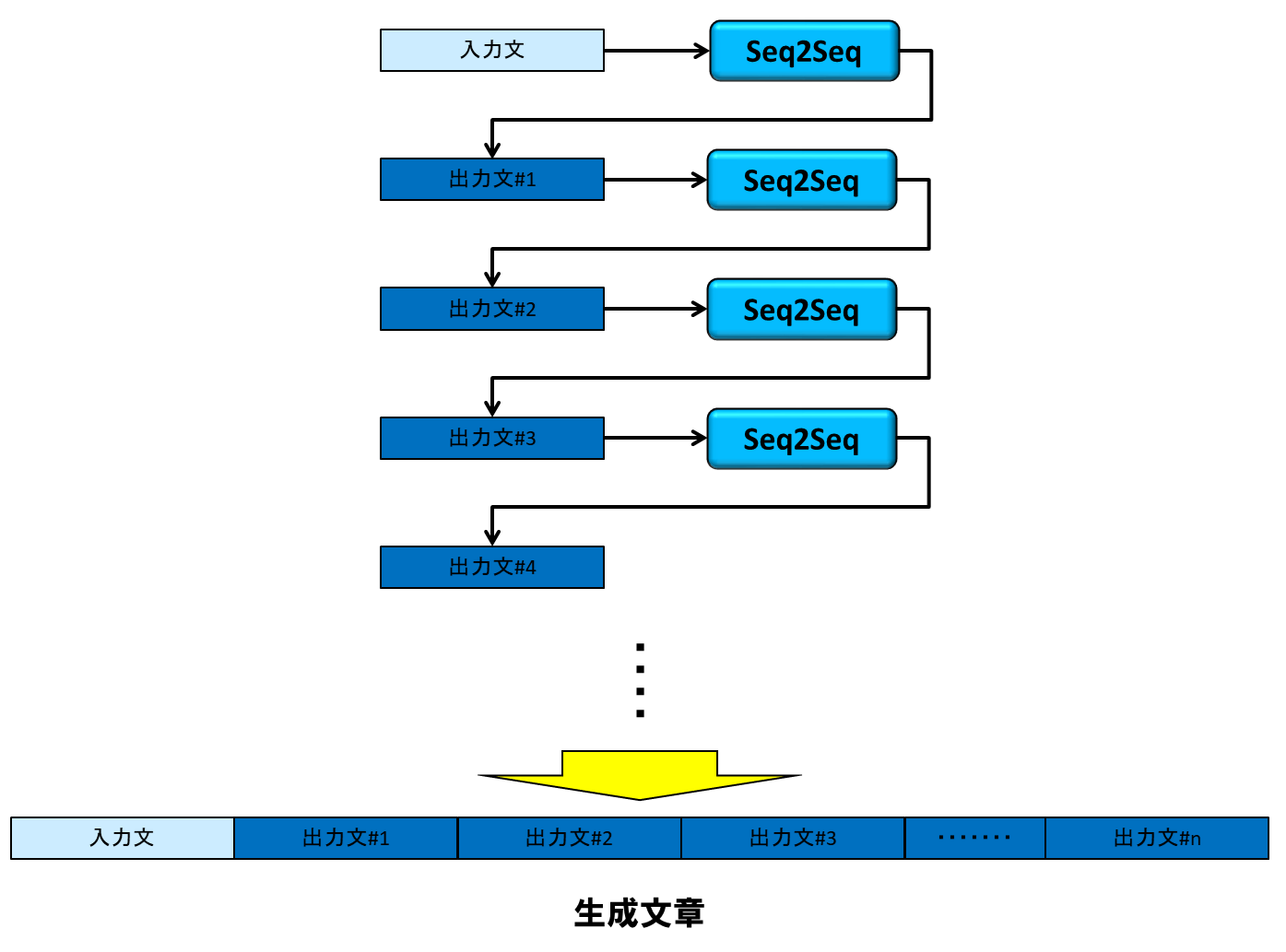
1-3. 訓練用日本語コーパスの入手について
ニューラルネットワークの出力単位が、単語から文に変わるので、大量の日本語コーパスが必要になります。そこで今回は、Wikipediaのデータをダウンロードして使用することにします。
2. 本稿のゴール
以下の通りです。
- Wikipediaのデータを使って、チャットボット作成時に構築したSeq2Seqニューラルネットワークを訓練し、長文を生成します
なお、本稿の前提となるソフトウェア環境は、以下の通りです。
- Ubuntu 16.04 LTS
- Python 3.6.4
- Anaconda 5.1.0
- TensorFlow-gpu 1.3.0
- Keras 2.1.4
- Jupyter 4.4.0
また、後述の訓練処理が非常に重いので、ハードウェア環境としては、GPUマシンか、クラウドサービスの利用を推奨します。
3. 日本語コーパスの入手と訓練データ生成
3-1. Wikipediaデータベースのダウンロード
上述のとおり、Wikipediaの記事をコーパスに使用します。これの入手方法については、たとえばこちらのページに、ダウンロードとテキストへの展開方法が記述されています。
展開が成功すると、以下のように、複数のディレクトリ配下に複数のファイルが配置されます。
└── wikipedia
├── AA
│ ├── wiki_00
│ ├── wiki_01
│ ├── wiki_02
│ ├── wiki_03
│ ├── wiki_04
~ ~
│ ├── wiki_98
│ └── wiki_99
├── AB
│ ├── wiki_00
│ ├── wiki_01
│ ├── wiki_02
│ ├── wiki_03
│ ├── wiki_04
~ ~
│ ├── wiki_98
│ └── wiki_99
└── BB
├── wiki_00
├── wiki_01
├── wiki_02
├── wiki_03
├── wiki_04
~
├── wiki_46
└── wiki_47
3-2. コーパスの整形と、不要文字の削除
展開されたファイルの中身は、各項目ごとにタグ<doc id="n" url="https://ja.wikipedia.org/wiki?curid=n" title="ほにゃらら">および、</doc>で囲まれているので、これらを外します。
また、文の最後が句読点で終わっていない場合は、それは地の文ではなく、見出しや箇条書き等である可能性があるので、その文は処理をスキップし、コーパスとして採用しません。
一方、1文の長さがあまり長くならないようにするため、1つの文に複数の句点が存在する場合は、文を複数に分割します。
今時点では、1行1文になっていて、文の切れ目は明らかですが、後に単語単位に分解してしまうと、文の先頭がわからなくなるので、この段階でセパレータ「SSSSSS:」を挿入します。
同様の理由で、各項目の説明文の切れ目に、セパレータ「TTTTTT」を挿入します。
処理イメージは以下の通りです・
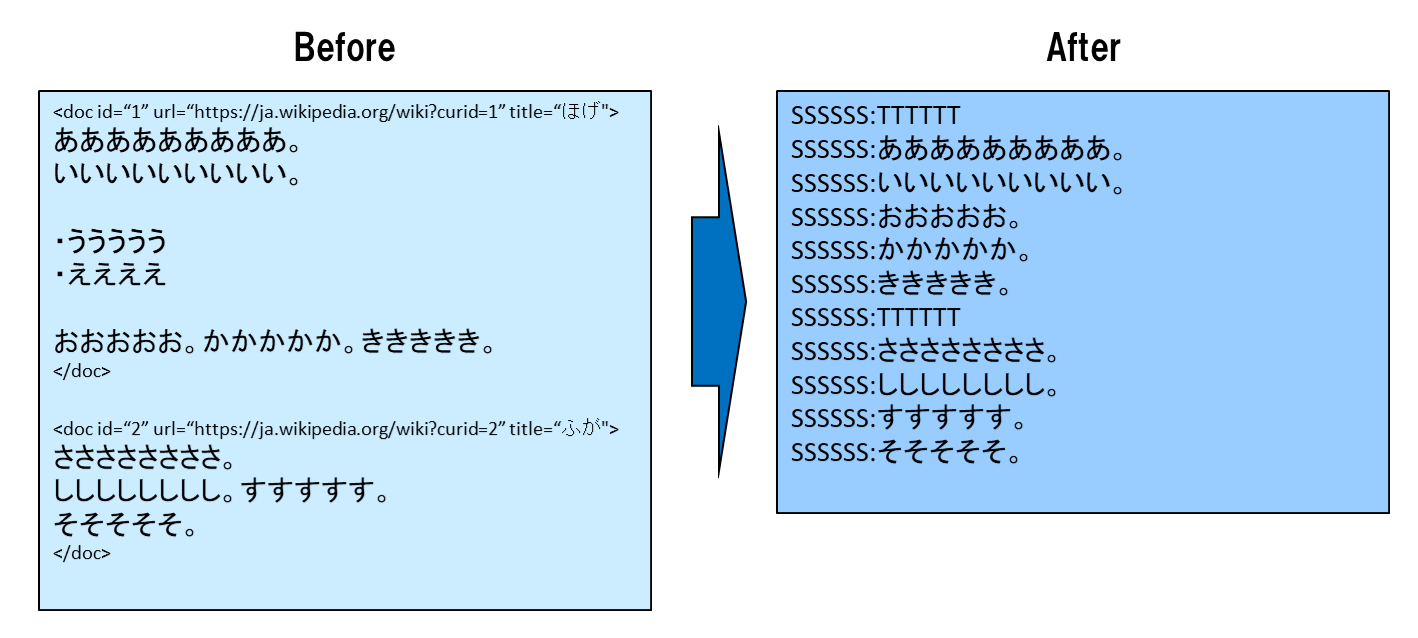
これらの処理を、各ファイルごとに実施します。
コードは以下のとおりです。
# coding: utf-8
import numpy as np
import csv
import glob
import re
def make_data(fname) :
data2=[]
f = open(fname, 'r')
df1 = csv.reader(f,delimiter="\t")
data1 = [ v for v in df1]
#print(len(data1))
#ファイル読み込み
text = ''
for i in range(0,len(data1)):
if len(data1[i]) == 0:
continue
s = data1[i][0]
if s[0:8] == "<doc id=" :
s = "TTTTTT"
data2.append("SSSSSS:"+s)
continue
if s == "" :
continue
if s[-1] !="。" and s[-1] !="、" and s[-1] !="!" and s[-1] !="?" :
continue
if s[0:1] == "<" :
continue
if s[0:1] == "\n" :
continue
while s.find("。") != -1 :
n_period = s.find("。")
data2.append("SSSSSS:"+s[0:n_period+1])
s = s[n_period+1:]
if len(s) > 1 :
data2.append("SSSSSS:"+s)
f.close()
return data2
if __name__ == '__main__':
file_list = glob.glob('wiki_text/wikipedia/*/*')
file_list.sort()
print(len(file_list))
for j in range(0,len(file_list)) :
print(file_list[j])
data2 = make_data(file_list[j])
#ファイルセーブ
file_name = 'input_text/text_'+'{0:0>4d}'.format(j)+'.txt'
f = open(file_name,'w')
for i in range(0,len(data2)):
f.write(str(data2[i])+"\n")
f.close()
print(file_name, len(data2))
コードの実行フォルダ上にinput_textフォルダを作成したうえで、以下のように実行します。引数はありません。
$ python 0100_corpus_wiki.py
input_textフォルダ内に、以下のように整形後のテキストファイルが格納されます。
input_text
├── text_0000.txt
├── text_0001.txt
├── text_0002.txt
├── text_0003.txt
├── text_0004.txt
├── text_0005.txt
├── text_0006.txt
├── text_0007.txt
├── text_0008.txt
├── text_0009.txt
├── text_0010.txt
~
3-3. 品詞分解
前節で作成したファイル単位に、日本語形態素解析システムJUMAN++を用いて品詞分解を行います。使用するバージョンは、まだ開発版ですが非常に高速に動作する2.0.0-rc2を採用しました。インストール等については、こちらをご参照ください。
コードは以下の通りです。ファイル単位に以下の処理を実行します。
-
JUMAN++の実行コマンド
jumanppを実行 -
JUMAN++の実行結果(csvファイル)の1列目に品詞分解結果があるので、これを取り出してファイルに書き込む処理
generate_npy.pyを実行
# coding: utf-8
import subprocess
import numpy as np
import csv
import glob
import re
import pickle
import os
if __name__ == '__main__':
file_list = glob.glob('input_text/*')
print(len(file_list))
file_list.sort()
for i in range(0,len(file_list)) :
# 品詞分解
cmd = 'cat '+ file_list[i] + '| /usr/local/juman2/bin/jumanpp > ' + 'juman/juman.csv'
result = os.system(cmd)
if result != 0 :
print('ERROR',i,file_list[i])
break
# 単語配列作成
subprocess.call(['python','generate_npy.py','juman/juman.csv', str(i)])
generate_npy.pyの処理内容ですが、JUMAN++の出力結果は、デリミタが半角スペースのCSVファイルの形態をとっています。これに対し、
- 1列目を取り出す
- 「@」で始まる行(同音異義語)や「EOS」の行を削除する
- デリミタ「SSSSSS:」はJUMAN++によって「SSSSSS」と「:」に分解されるので、「SSSSSS」の次の行が「:」なら、その行を削除する
という加工をします。
これらの処理によって得た単語を、出現順にリストにします。
generate_npy.pyのコードは以下の通りです。
# coding: utf-8
import numpy as np
import csv
import re
import pickle
import sys
# **********************************************************************************
# *
# juman++の品詞分解結果をリストに書き出し *
# *
# **********************************************************************************
if __name__ == '__main__':
args = sys.argv
#args[1] = 'juman/juman2018-11-25.csv' # jupyter上で実行するとき用
list_corpus = []
with open(args[1], 'r') as f :
df2 = csv.reader(f,delimiter=' ',quoting=csv.QUOTE_NONE)
mat = [ v for v in df2]
#補正
for i in range(0,len(mat)):
if len(mat[i]) != 0 :
if mat[i][0] != '' :
if mat[i][0] == ':' and mat[i-1][0] == 'SSSSSS' :
continue
if mat[i][0] != '@' and mat[i][0] != 'EOS' and len(mat[i]) > 5 :
list_corpus.append([mat[i][0],mat[i][3],mat[i][4],mat[i][5]])
else :
list_corpus.append([' ','特殊','1','空白'])
with open('list_corpus/list_corpus_'+'{0:0>4d}'.format(int(args[2]))+'.pickle', 'wb') as g :
pickle.dump(list_corpus , g)
print(args[2] ,len(list_corpus))
0200_generage_word_list.pyの実行に当たっては、コードの格納フォルダ上にjumanフォルダとlist_corpusフォルダを作成したうえで、以下のように実行します。引数はありません。
$ python 0200_generage_word_list.py
品詞分解結果は、以下のようにlist_corpusフォルダ配下に格納されます。
list_corpus
├── list_corpus_0000.pickle
├── list_corpus_0001.pickle
├── list_corpus_0002.pickle
├── list_corpus_0003.pickle
├── list_corpus_0004.pickle
├── list_corpus_0005.pickle
├── list_corpus_0006.pickle
├── list_corpus_0007.pickle
├── list_corpus_0008.pickle
├── list_corpus_0009.pickle
├── list_corpus_0010.pickle
3-4. 辞書作成(一次処理)と単語出現頻度カウント
前節で作成した品詞分解結果をもとに、各単語に一意のインデックスを付与し、各単語の出現頻度をカウントします。
コードは以下の通りです。
# coding: utf-8
# *************************************************************************************
# *
# 単語リストと単語−品詞対応表作成 *
# *
# *************************************************************************************
def generate_words(file_list) :
words = []
parts = []
len_mat = 0
#for i in range (0,3) :
for i in range (0,len(file_list)) :
with open(file_list[i],'rb') as f :
list_corpus=pickle.load(f) #生成リストロード
len_mat += len(list_corpus)
words.extend(list(map(list, zip(*list_corpus)))[0])
parts.extend(list_corpus)
parts = list(set(list(map(tuple,parts))))
del list_corpus
words = sorted(list(set(words)))
#parts = list(set(parts))
if i % 10 == 0 :
print(i)
#print(len(words))
print('テキスト長 =',len_mat)
return words, parts, len_mat
# *************************************************************************************
# *
# 単語出現数カウント *
# *
# *************************************************************************************
def count_freq(file_list, word_indices, indices_word, words) :
cnt = np.zeros(len(words))
#for i in range (0,3) :
for i in range (0,len(file_list)) :
with open(file_list[i],'rb') as f :
list_corpus=pickle.load(f) #生成リストロード
for j in range(0, len(list_corpus)) :
cnt[word_indices[list_corpus[j][0]]] += 1
del list_corpus
if i % 50 == 0 :
print(i)
return cnt
# *************************************************************************************
# *
# メイン処理 *
# *
# *************************************************************************************
if __name__ == '__main__':
import numpy as np
import pickle
import glob
file_list = glob.glob('list_corpus/*')
file_list.sort()
print('ファイル数 =',len(file_list))
n = 20
n_file = len(file_list) // n + 1
words = []
parts = []
len_mat = []
for i in range(0,n) :
separated_file_list = file_list[n_file * i : min(n_file*(i+1),len(file_list))]
print(separated_file_list[0],separated_file_list[-1])
output_words, output_parts, output_len_mat = generate_words(separated_file_list)
words.extend(output_words)
words = sorted(list(set(words)))
print('words:',len(words))
parts.extend(output_parts)
parts = list(set(list(map(tuple,parts))))
len_mat.append(output_len_mat)
#words, parts = generate_words(file_list)
parts = [ list(v) for v in parts]
print(len(parts))
print(parts[0:5])
print('total words:', len(words))
word_indices = dict((w, i) for i, w in enumerate(words)) #単語をキーにインデックス検索
indices_word = dict((i, w) for i, w in enumerate(words)) #インデックスをキーに単語を検索
print(words[0:20])
print(len_mat)
#単語の出現数をカウント
cnt = count_freq(file_list, word_indices, indices_word, words)
#作成した辞書をセーブ
with open('proto_word_indices.pickle', 'wb') as f :
pickle.dump(word_indices , f)
with open('proto_indices_word.pickle', 'wb') as g :
pickle.dump(indices_word , g)
#単語ファイルセーブ
with open('proto_words.pickle', 'wb') as h :
pickle.dump(words , h)
#単語出現数リストセーブ
with open('cnt.pickle', 'wb') as h :
pickle.dump(cnt , h)
#単語ー品詞対応表セーブ
with open('parts.pickle', 'wb') as h :
pickle.dump(parts , h)
#テキスト長リストセーブ
with open('len_mat.pickle', 'wb') as h :
pickle.dump(len_mat , h)
コードは以下のコマンドで実行します。引数はありません。
$ python 0300_generate_proto_words.py
3-5. 辞書作成(二次処理)と単語インデックス配列作成
前節で各単語にインデックスを付与しましたが、単語数は100万のオーダーに到達しました。単語数は、文章生成ニューラルネットワークの入出力次元であり、これが大きいと、学習コストの割に予測精度が上がりません。そもそも、入出力次元がこんなに大きいと、ニューラルネットワークを動作させることすら困難になるので、出現頻度の低い単語は思い切って、十把一絡げに不明単語を表す文字列「UNK」に置き換えます。
UNK置き換えのしきい値は、半角文字のみの単語の場合は87、それ以外の単語は16としました。
その後、各単語のインデックス付与と辞書作成を、再度行います。
なお、インデックス0は、ニューラルネットワークのMasking用に予約したいので、これに単語がアサインされないよう、単語ファイルwordsに、単語ソート時に必ず先頭に来る「\t」(タブ)を追加します。
次に、単語リスト(3-3節で作成した、品詞分解の結果ファイル)の単語の並び順に、単語のインデックスを配したN×1次元配列を生成します。単語リストのファイルは複数個ありますが、N×1次元配列は1つにまとめます。
# coding: utf-8
def reduced_words() :
#単語ファイルロード
with open('proto_words.pickle', 'rb') as f :
words=pickle.load(f)
#単語出現数リストロード
with open('cnt.pickle', 'rb') as f :
cnt=pickle.load(f)
#作成した辞書をロード
with open('proto_word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f)
with open('proto_indices_word.pickle', 'rb') as g :
indices_word = pickle.load(g)
words_unk = [] #未知語一覧
for k in range(0,len(words)):
if indices_word[k][0].isalnum() :
if cnt[k] <= 87 :
words_unk.append(words[k])
words[k] = 'UNK'
else :
if cnt[k] <= 16 :
words_unk.append(words[k])
words[k] = 'UNK'
print('words_unk:',len(words_unk)) # words_unkはunkに変換された単語のリスト
#低頻度単語をUNKに置き換えたので、辞書作り直し
words = list(set(words))
words.append('\t') #0パディング対策。インデックス0用キャラクタを追加
words = sorted(words)
print('new total words:', len(words))
return words
def genarate_urtext(word_indices, indices_word, words) :
#テキスト長リストロード
with open('len_mat.pickle', 'rb') as f :
len_mat=pickle.load(f)
#単語インデックス配列の次元数計算
dim_mat = sum(len_mat) + 1
#単語インデックス配列作成
mat_urtext = np.zeros((dim_mat,1),dtype=int)
#コーパスファイルリスト取得
file_list = glob.glob('list_corpus/*')
file_list.sort()
k = 0
#for i in range (0,3) :
for i in range (0,len(file_list)) :
with open(file_list[i],'rb') as f :
list_corpus=pickle.load(f) #生成リストロード
for j in range(0,len(list_corpus)):
w = list_corpus[j][0]
if w in word_indices : #出現頻度の低い単語のインデックスをunkのそれに置き換え
mat_urtext[k,0] = word_indices[w]
else:
mat_urtext[k,0] = word_indices['UNK']
k += 1
del list_corpus
if i % 20 == 0 :
print(i)
mat_urtext[-1,0] = word_indices['SSSSSS']
print(mat_urtext[-1,0])
return mat_urtext
if __name__ == '__main__':
import numpy as np
import pickle
import glob
#出現頻度の少ない単語を「UNK」で置き換え
words = reduced_words()
#低頻度単語をUNKに置き換えたので、辞書作り直し
word_indices = dict((w, i) for i, w in enumerate(words)) #単語をキーにインデックス検索
indices_word = dict((i, w) for i, w in enumerate(words)) #インデックスをキーに単語を検索
#単語インデックス配列作成
mat_urtext = genarate_urtext(word_indices, indices_word, words)
print(mat_urtext.shape)
print(mat_urtext[0:20,0])
print([indices_word[v] for v in mat_urtext[0:20,0]])
print(mat_urtext[-21:,0])
print([indices_word[v] for v in mat_urtext[-21:,0]])
#作成した辞書をセーブ
with open('word_indices.pickle', 'wb') as f :
pickle.dump(word_indices , f)
with open('indices_word.pickle', 'wb') as g :
pickle.dump(indices_word , g)
#単語ファイルセーブ
with open('words.pickle', 'wb') as h :
pickle.dump(words , h)
#コーパスセーブ
np.save('mat_urtext.npy', mat_urtext)
コードは以下のコマンドで実行します。引数はありません。
$ python 0400_generate_index_matrix.py
本処理で作成されるファイルは、以下の通りです。
| ファイル名 | 形式 | 内容 |
|---|---|---|
| word_indices.pickle | pickle | 辞書ファイル(単語→インデックス) |
| indices_word.pickle | pickle | 辞書ファイル(インデックス→単語) |
| words.pickle | pickle | 単語ファイル |
| mat_urtext.npy | NumPy配列 | 単語インデックス配列 |
mat_urtext.npyのみNumPy配列なのは、pickleには最大サイズ4GBの制約があるからです。
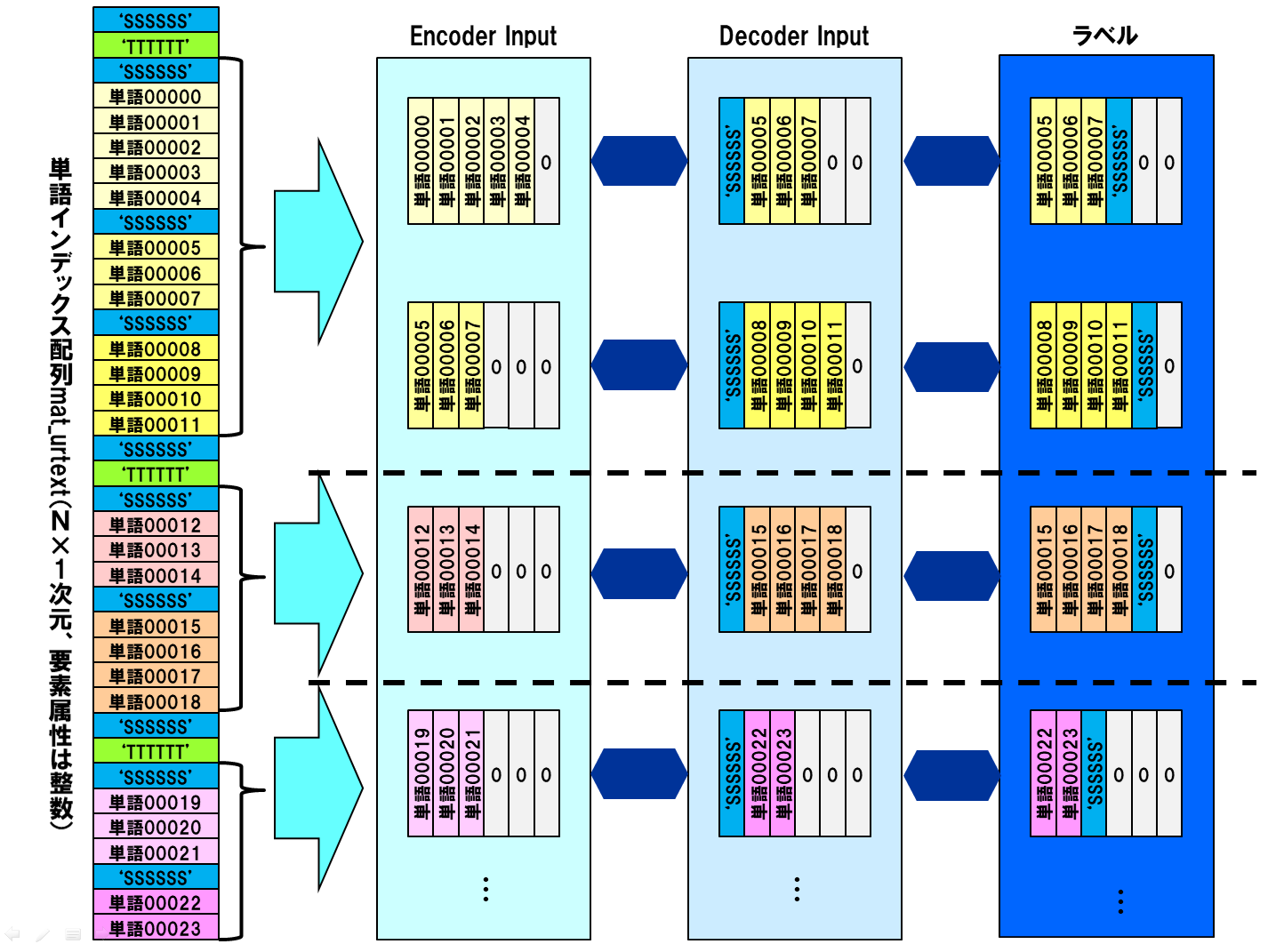
3-6. 訓練データ生成
前節で作成した単語インデックス配列から、Seq2Seqモデル用のエンコーダインプット、デコーダインプット、およびラベルを生成します。これらがニューラルネットワークでどのように使われるのかについては、こちらをご覧ください。
基本的に前の文から後の文が生成されるように、訓練データを作成しますが、エンコーダインプットとデコーダインプット/ラベルの対が項目説明をまたがないように、デリミタ「TTTTTT」を使って制御します。
訓練データ生成イメージを下図に示します。文を構成する単語の数は可変なので、列幅をそろえるために各行で0パディングします。
更に、使用メモリ削減と学習精度向上のため、こちらの記事のやり方にしたがって、出力次元数を削減します。
出現単語を出現頻度によって複数のカテゴリー(今回の実装では8)に分け、各カテゴリー内で一意のインデックスを付与します。各単語はカテゴリー番号と、カテゴリーインデックスの2つの数字を持つことになりますが、これらのそれぞれに対してsoftmax関数を活性化関数に用います。
コードは以下の通りです。
# coding: utf-8
# *******************************************************************************
# *
# 訓練データ/ラベルテンソル作成処理 *
# *
# *******************************************************************************
def generate_tensors(maxlen_e,maxlen_d) :
#--------------------------------------------------------------------------*
# *
# 単語配列、コーパス配列、辞書のロード *
# *
#--------------------------------------------------------------------------*
#単語ファイルロード
with open('words.pickle', 'rb') as f :
words=pickle.load(f)
#作成した辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f)
with open('indices_word.pickle', 'rb') as g :
indices_word = pickle.load(g)
#コーパスロード
mat_urtext = np.load('mat_urtext.npy')
#--------------------------------------------------------------------------*
# *
# UNK有無判定処理 *
# *
#--------------------------------------------------------------------------*
def unk_judge(mat) :
judge = False
for i in range (0,mat.shape[0]) :
if indices_word[int(mat[i])] == 'UNK' :
judge = True
break
elif int(mat[i]) == 0 :
break
return judge
#--------------------------------------------------------------------------*
# *
# コーパスをエンコーダ入力、デコーダ入力応答文のテンソルに変換 *
# *
#--------------------------------------------------------------------------*
ssssss= word_indices['SSSSSS']
delimiters = []
#コーパス上のデリミタの位置を特定する
for i in range(0,mat_urtext.shape[0]) :
if mat_urtext[i,0] == ssssss:
delimiters.append(i)
if i % 10000000 == 0 :
print(i)
print(len(delimiters))
n = len(delimiters) - 2
#入力、ラベルテンソルの初期値定義(0値マトリックス)
enc_input = np.zeros((n, maxlen_e))
dec_input = np.zeros((n, maxlen_d))
target = np.zeros((n, maxlen_d))
#デリミタを目印に、コーパスから文章データを切り出して入力/ラベルマトリックスにコピー
j = 0
#err_cnt = 0
for i in range(0,n) :
#for i in range(0,10) :
index1=i # 「SSSSSS」のインデックス
index2=i+1 # 次の「SSSSSS」のインデックス
index3=i+2 # その次の「SSSSSS」のインデックス
#print('index1',index1,'index2',index2,'index3',index3)
len_e = delimiters[index2] - delimiters[index1] - 1
len_d = delimiters[index3] - delimiters[index2]
# 会話文長が0のときはスキップ
if len_e == 0 or len_d == 0 :
continue
# 項目説明文の境目はスキップ
if (mat_urtext[delimiters[index1]+1] == word_indices['TTTTTT'] or
mat_urtext[delimiters[index2]+1] == word_indices['TTTTTT']) :
continue
#系列長より短い会話でかつ応答文にUNKが含まれない場合のみ、入力/ラベルマトリックスに書き込む
if (len_e <= maxlen_e and len_d <= maxlen_d
and unk_judge( mat_urtext[delimiters[index2]:delimiters[index3],0]) == False):
#print(indices_word[mat_urtext[delimiters[index1]+1,0]])
enc_input[j,0:len_e] = mat_urtext[delimiters[index1]+1:delimiters[index2],0].T
dec_input[j,0:len_d] = mat_urtext[delimiters[index2]:delimiters[index3],0].T
target[j,0:len_d] = mat_urtext[delimiters[index2]+1:delimiters[index3]+1,0].T
#print(j)
j += 1
if i % 1000000 == 0 :
print(i)
print('会話対数:', j)
#会話文データを書き込んだ分だけ切り出す
e = enc_input[0:j,:].reshape(j,maxlen_e,1)
d = dec_input[0:j,:].reshape(j,maxlen_d,1)
t_ = target[0:j,:].reshape(j,maxlen_d,1)
#ラベルテンソル定義
t = np.zeros((j,maxlen_d,2),dtype='int32')
#各単語の出現頻度カウント
cnt = np.zeros(len(words),dtype='int32')
for i in range (0,mat_urtext.shape[0]) :
#for i in range (0,100000) :
cnt[mat_urtext[i,0]] += 1
if i % 10000000 == 0 :
print(i)
#出現頻度の降順配列
freq_indices = np.argsort(cnt)[::-1] #出現頻度からインデックス検索
indices_freq = np.argsort(freq_indices) #インデックスから出現頻度検索
#
dim = math.ceil(len(words) / 8)
#ラベルテンソル作成
for i in range(0,j) :
for k in range(0,maxlen_d) :
if t_[i,k] != 0 :
freq = indices_freq[int(t_[i,k])]
t[i,k,0] = freq // dim
t[i,k,1] = freq % dim
else :
break
if i % 1000000 == 0 :
print(i)
for i in range(0,50) :
#print([indices_word[v] for v in mat_urtext[0:200,0]])
print([indices_word[v] for v in e[i,:].reshape((maxlen_e,))])
print([indices_word[v] for v in d[i,:].reshape((maxlen_d,))])
#print(t[0,:,:])
#print([indices_word[v] for v in e[i+1,:].reshape((maxlen_e,))])
#print([indices_word[v] for v in d[i+1,:].reshape((maxlen_d,))])
#print(t[1,:,:])
# シャッフル処理
z = list(zip(e, d, t))
nr.seed(12345)
nr.shuffle(z) #シャッフル
e,d,t=zip(*z)
nr.seed()
e = np.array(e).reshape(j,maxlen_e,1)
d = np.array(d).reshape(j,maxlen_d,1)
t = np.array(t).reshape(j,maxlen_d,2)
print(e.shape,d.shape,t.shape)
#--------------------------------------------------------------------------*
# *
# 作成したエンコーダ/デコーダ入力テンソル、ラベルテンソルをセーブ *
# *
#--------------------------------------------------------------------------*
#Encoder Inputデータをセーブ
np.save('e.npy', e)
#Decoder Inputデータをセーブ
np.save('d.npy', d)
#ラベルデータをセーブ
np.save('t.npy', t)
#maxlenセーブ
with open('maxlen.pickle', 'wb') as maxlen :
pickle.dump([maxlen_e, maxlen_d] , maxlen)
#各単語の出現頻度順位(降順)
with open('freq_indices.pickle', 'wb') as f :
pickle.dump(freq_indices , f)
#出現頻度→インデックス変換
with open('indices_freq.pickle', 'wb') as f :
pickle.dump(indices_freq , f)
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
if __name__ == '__main__':
import numpy.random as nr
import pickle
import numpy as np
import math
import sys
args = sys.argv
#args[1] = 50 # jupyter上で実行するとき用
#args[2] = 50 # jupyter上で実行するとき用
generate_tensors(int(args[1]) ,int(args[2]))
デコーダインプット側の文に「UNK」が含まれる場合は、処理をスキップしていますが、これは、出力側に「UNK」が含まれないデータのみを学習に使うことによって、文章生成時に「UNK」が出てくるのを防ぐためです。
また、処理の後のほうにあるshuffleは、対象データが多いため、メモリが十分にないと非常に重い(16GBでは足りなかった)ので、筆者のようにメモリを増設するか、または小分けにshuffleするようにしてみてください。
実行コマンドは以下の通りです。 今回は引数があります。エンコーダ系列長、デコーダ系列長を指定するようになっていますので、適当な値を指定してください。以下の例では、双方とも20を指定してあります。
$ python 0500_generate_data.py 20 20
系列長というのは、入力文長の最大値です。この値以下のデータを、エンコーダインプット等に右詰めで設定します。
4. 訓練
チャットボット実装時のニューラルネットワークdialog_categorize.pyおよび訓練処理generate_data.pyを、ほぼそのまま使用できます。詳細はこちらを参照ください。
ただし、エンコーダインプット、デコーダインプット、およびラベルのファイル種別を、サイズの関係からpicleからNumpy配列に変更していますので、もし実行する場合には、これにあわせて、訓練処理generate_data.pyのファイル読み込みの部分を修正してください。
訓練結果は、入力系列長=60、出力系列長=50、訓練データ量=約893万(入出力文対の数)という条件下で、Perplexity= 31.7まで学習が進みました。このサイズのデータ量だと、1エポックの訓練実施に約22時間かかります。
5. 文章生成
こちらの記事の応答文生成処理response.pyを実行し、文章を生成します。最初に適当な文を入力し、生成された文を再び入力します。このようにして、文を順次生成していきます。
以下は、最初の文として「国境の長いトンネルを抜けると雪国だった。」を入力したときの実行結果です。
>> 国境の長いトンネルを抜けると雪国だった。
そこで、彼は、自分の家にいるということを知らされた。
>> そこで、彼は、自分の家にいるということを知らされた。
彼は、彼の息子の名前を「私」と呼んでいる。
>> 彼は、彼の息子の名前を「私」と呼んでいる。
彼は、彼の息子である。
>> 彼は、彼の息子である。
彼は、彼の息子である。
文生成を何回か繰り返していくと、生成結果が「収束」してしまいました。これは他の入力文の場合でも同じです。
文の入力を再帰的に繰り返していくことにより、いくらでも長い文章が生成されると期待していたので、この結果は意外でした。
6. 文生成結果を確率変動させてみる
文決定における出力単語の決定にあたっては、ニューラルネットワークが出力するsoftmaxの結果から、argmaxによって単語のインデックスを決定しています。
ここでインデックスの決定を、softmax値を重みとしてランダムに決定することによって、出力結果が毎回異なるようにしてみました。このアイディアは、こちらを参考にしています。
この対処を追加した文生成処理のコードは、以下の通りです。
# coding: utf-8
# *************************************************************************************
# *
# import宣言 *
# *
# *************************************************************************************
from __future__ import print_function
from dialog_categorize import Dialog
# import tensorflow as tf
import numpy as np
import csv
import random
import numpy.random as nr
# import keras
import sys
import math
import time
import pickle
import gc
import os
from keras.utils import plot_model
sys.path.append("/home/ishigaki/pyknp-0.3")
from pyknp import Jumanpp
import codecs
# *************************************************************************************
# *
# 辞書ファイル等ロード *
# *
# *************************************************************************************
def load_data() :
#辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f) #単語をキーにインデックス検索
with open('indices_word.pickle', 'rb') as g :
indices_word=pickle.load(g) #インデックスをキーに単語を検索
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
#各単語の出現頻度順位(降順)
with open('freq_indices.pickle', 'rb') as f :
freq_indices = pickle.load(f)
#出現頻度→インデックス変換
with open('indices_freq.pickle', 'rb') as f :
indices_freq = pickle.load(f)
return word_indices ,indices_word ,words ,maxlen_e, maxlen_d, freq_indices
# *************************************************************************************
# *
# モデル初期化 *
# *
# *************************************************************************************
def initialize_models(emb_param ,maxlen_e, maxlen_d ,vec_dim, input_dim,output_dim, n_hidden) :
dialog= Dialog(maxlen_e, 1, n_hidden, input_dim, vec_dim, output_dim)
model ,encoder_model ,decoder_model = dialog.create_model()
param_file = emb_param + '.hdf5'
model.load_weights(param_file)
plot_model(encoder_model, show_shapes=True,to_file='seq2seq0212_encoder.png')
plot_model(decoder_model, show_shapes=True,to_file='seq2seq0212_decoder.png')
return model, encoder_model ,decoder_model
# *************************************************************************************
# *
# 入力文の品詞分解とインデックス化 *
# *
# *************************************************************************************
def encode_request(cns_input, maxlen_e, word_indices, words, encoder_model) :
# Use Juman++ in subprocess mode
jumanpp = Jumanpp()
result = jumanpp.analysis(cns_input)
input_text=[]
for mrph in result.mrph_list():
input_text.append(mrph.midasi)
mat_input=np.array(input_text)
#入力データe_inputに入力文の単語インデックスを設定
e_input=np.zeros((1,maxlen_e))
for i in range(0,len(mat_input)) :
if mat_input[i] in words :
e_input[0,i] = word_indices[mat_input[i]]
else :
e_input[0,i] = word_indices['UNK']
return e_input
# *************************************************************************************
# *
# 応答文組み立て *
# *
# *************************************************************************************
def generate_response(e_input, n_hidden, maxlen_d, output_dim, word_indices,
freq_indices, indices_word, encoder_model, decoder_model) :
# Encode the input as state vectors.
encoder_outputs, state_h_1, state_c_1, state_h_2, state_c_2 = encoder_model.predict(e_input)
states_value= [state_h_1, state_c_1, state_h_2, state_c_2]
decoder_input_c = np.zeros((1,1,n_hidden) ,dtype='int32')
decoded_sentence = ''
target_seq = np.zeros((1,1) ,dtype='int32')
# Populate the first character of target sequence with the start character.
target_seq[0, 0] = word_indices['SSSSSS']
# 応答文字予測
for i in range(0,maxlen_d) :
output_tokens_cat, output_tokens_mod, d_output, h1, c1, h2, c2 = decoder_model.predict(
[target_seq,decoder_input_c,encoder_outputs]+ states_value)
# 予測単語の出現頻度算出
n_cat = np.argmax(output_tokens_cat[0, 0, :])
#print(n_cat)
# 予測を確率変動させる
temperature = 0.7
delta = 1e-6
output_dim = output_tokens_mod.shape[2]
preds = [np.log(v+delta)/temperature for v in output_tokens_mod[0, 0, :].reshape((output_dim,))]
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds) / (1.+ delta)
#print(np.sum(preds))
probas = np.random.multinomial(1, preds, 1)
n_mod = np.argmax(probas)
#n_mod = np.argmax(output_tokens_mod[0, 0, :])
freq = (n_cat * output_dim + n_mod).astype(int)
#予測単語のインデックス値を求める
sampled_token_index = freq_indices[freq]
#予測単語
sampled_char = indices_word[sampled_token_index]
# Exit condition: find stop character.
if sampled_char == 'SSSSSS' :
break
decoded_sentence += sampled_char
# Update the target sequence (of length 1).
if i == maxlen_d-1:
break
target_seq[0,0] = sampled_token_index
decoder_input_c = d_output
# Update states
states_value = [h1, c1, h2, c2]
#states_value = [h1, c1, h2, c2, h3, c3]
return decoded_sentence
# *************************************************************************************
# *
# メイン処理 *
# *
# *************************************************************************************
if __name__ == '__main__':
vec_dim = 400
n_hidden = int(vec_dim*1.5 ) #隠れ層の次元
args = sys.argv
#args[1] = 'param_003' # jupyter上で実行するとき用
#データロード
word_indices ,indices_word ,words ,maxlen_e, maxlen_d ,freq_indices = load_data()
#入出力次元
input_dim = len(words)
output_dim = math.ceil(len(words) / 8)
#モデル初期化
model, encoder_model ,decoder_model = initialize_models(args[1] ,maxlen_e, maxlen_d,
vec_dim, input_dim, output_dim, n_hidden)
sys.stdin = codecs.getreader('utf_8')(sys.stdin)
while True:
cns_input = input(">> ")
if cns_input == "q":
print("終了")
break
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input = encode_request(cns_input, maxlen_e, word_indices, words, encoder_model)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence = generate_response(e_input, n_hidden, maxlen_d, output_dim, word_indices,
freq_indices, indices_word, encoder_model, decoder_model)
print(decoded_sentence)
追加された処理は、以下の通りです。応答文組み立てgenerate_responseのforループの中にあります。
# 予測を確率変動させる
temperature = 0.7
delta = 1e-6
output_dim = output_tokens_mod.shape[2]
preds = [np.log(v+delta)/temperature for v in output_tokens_mod[0, 0, :].reshape((output_dim,))]
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds) / (1.+ delta)
#print(np.sum(preds))
probas = np.random.multinomial(1, preds, 1)
n_mod = np.argmax(probas)
#n_mod = np.argmax(output_tokens_mod[0, 0, :])
freq = (n_cat * output_dim + n_mod).astype(int)
#予測単語のインデックス値を求める
sampled_token_index = freq_indices[freq]
#予測単語
sampled_char = indices_word[sampled_token_index]
コードの中の定数temperatureは、変動の度合いを制御するパラメータです。値を大きくすると、より変動しやすくなります。
このtemperatureを考慮した確率変数predsを求め、np.random.multinomialでサイコロを振って、単語インデックスを決定します。
定数deltaは微小量です。 predsを求めるときに、(1.+ delta)で割っているのは、こうしないとpredsの要素の和が1を超えてしまうからです(np.random.multinomialでエラーが発生します)。predsの計算式からは、そんなことは起きそうにありませんが、おそらく、preds算出時に対数や指数計算の誤差が積みあがっているのではないかと考えています。
定数deltaの値が1e-6と微妙なのは、1e-7では小さすぎて、np.random.multinomialがエラーになってしまったからです。
対処後の文章生成結果は、以下の通りです。
>> 国境の長いトンネルを抜けると雪国だった。
列車の運転には代表をしていたが、突然横に落ちてくる車を見つける。
>> 列車の運転には代表をしていたが、突然横に落ちてくる車を見つける。
車は中に入ってくる車に乗っているものの、車が五郎のもとにトラストの「遠隔車」に押され、車は線路上に転落死する。
>> 車は中に入ってくる車に乗っているものの、車が五郎のもとにトラストの「遠隔車」に押され、車は線路上に転落死する。
それからしばらく後、ついに日本車は本来の基地に戻される。
>> それからしばらく後、ついに日本車は本来の基地に戻される。
その後、同基地にある日本基地の調査員が到着する。
>> その後、同基地にある日本基地の調査員が到着する。
第一次世界大戦においてアメリカが英米に協力していた。
>> 第一次世界大戦においてアメリカが英米に協力していた。
アメリカはドイツとアメリカに協力し、アメリカとフランスの利害関係を維持するために、英国による占領を拒否した(アメリカの対米宣戦)。
>> アメリカはドイツとアメリカに協力し、アメリカとフランスの利害関係を維持するために、英国による占領を拒否した(アメリカの対米宣戦)。
アメリカの外交工作は、アメリカ合衆国の輸入のもしくはドイツの主権が問題視された。
>> アメリカの外交工作は、アメリカ合衆国の輸入のもしくはドイツの主権が問題視された。
この問題から、イギリスとドイツは、アメリカの主権が合衆国の主権を維持すると主張し、イギリスはイギリスの主権を維持することを求めていた。
>> この問題から、イギリスとドイツは、アメリカの主権が合衆国の主権を維持すると主張し、イギリスはイギリスの主権を維持することを求めていた。
フランスは、イギリスに対し、イギリスが戦争を開始することを禁止したことを主張した。
>> フランスは、イギリスに対し、イギリスが戦争を開始することを禁止したことを主張した。
イギリスは非難を表明し、フランスはこの条約を同盟国とすることを認めた。
>> イギリスは非難を表明し、フランスはこの条約を同盟国とすることを認めた。
これにより、フランスはイギリスがその地位にAVを派遣することを決めた。
>> これにより、フランスはイギリスがその地位にAVを派遣することを決めた。
フランスはAVをはじめ、その他の映画監督を招聘している。
>> フランスはAVをはじめ、その他の映画監督を招聘している。
女優をはじめ、車や雑誌などでは、映画撮影などに使われることもある。
>> 女優をはじめ、車や雑誌などでは、映画撮影などに使われることもある。
日本国内では、映画撮影に用いられる映画もある。
>> 日本国内では、映画撮影に用いられる映画もある。
また、『文藝春秋』では、「私が語るな」と線路を便に乗せて海を茂に譲っていたという。
>> また、『文藝春秋』では、「私が語るな」と線路を便に乗せて海を茂に譲っていたという。
また、『文藝春秋』では、本の話で「私は途中で見たい」などと述べている。
>> また、『文藝春秋』では、本の話で「私は途中で見たい」などと述べている。
また、「私は、私がもう一人の人物を演じるからである」と語っていた。
>> また、「私は、私がもう一人の人物を演じるからである」と語っていた。
この作品の中では、「私は、この女性を2人の人物と呼ぶべき」という。
>> この作品の中では、「私は、この女性を2人の人物と呼ぶべき」という。
「私は、自分は自分のことを本当に人間か、物語の中で、最後の女性として生きるのが、この女性の形を取る」という埋葬感情に触れている。
>> 「私は、自分は自分のことを本当に人間か、物語の中で、最後の女性として生きるのが、この女性の形を取る」という埋葬感情に触れている。
この言葉は、「私の娘」という言葉を基にしており、このフランク・ロイド・ジョージによって、「私は私の死を感じた。
>> この言葉は、「私の娘」という言葉を基にしており、このフランク・ロイド・ジョージによって、「私は私の死を感じた。
私とは別に、私の娘」とも呼ばれた。
>> 私とは別に、私の娘」とも呼ばれた。
妻とは親友である。
>> 妻とは親友である。
2人の娘は野球部の監督でもあり、1975年の世界選手権で優勝した。
>> 2人の娘は野球部の監督でもあり、1975年の世界選手権で優勝した。
モントリオールオリンピックでの優勝経験は、オリンピック出場ではなく、イタリア代表監督としての活躍だった。
>> モントリオールオリンピックでの優勝経験は、オリンピック出場ではなく、イタリア代表監督としての活躍だった。
現役引退後は、イタリアサッカー協会の指導者を務めている。
>> 現役引退後は、イタリアサッカー協会の指導者を務めている。
2009-10シーズンのセリエBにおいては、シーズン開幕前にクラブの監督に就任した。
>> 2009-10シーズンのセリエBにおいては、シーズン開幕前にクラブの監督に就任した。
2010年に退団し、2014年まで、いわば2014-15シーズンの監督に就任した。
>> 2010年に退団し、2014年まで、いわば2014-15シーズンの監督に就任した。
2015年、UEFAチャンピオンズカップ優勝を経験した。
>> 2015年、UEFAチャンピオンズカップ優勝を経験した。
2015年4月、私はリーガ・エスパニョーラのセグンダ・ディビシオンに復帰した。
>> 2015年4月、私はリーガ・エスパニョーラのセグンダ・ディビシオンに復帰した。
2014-15シーズンはプリメーラ・ディビシオンへの昇格を果たした。
>> 2014-15シーズンはプリメーラ・ディビシオンへの昇格を果たした。
2015年3月22日、セグンダ・ディビシオンB(1部)のセグンダ・ディビシオンB(1部)昇格を決めたセリエC.89の創設者として初参加を果たした。
>> 2015年3月22日、セグンダ・ディビシオンB(1部)のセグンダ・ディビシオンB(1部)昇格を決めたセリエC.89の創設者として初参加を果たした。
2017-18シーズン、セグンダ・ディビシオンB(1部)でリーグ優勝を果たした。
>> 2017-18シーズン、セグンダ・ディビシオンB(1部)でリーグ優勝を果たした。
2016年シーズンにセグンダ・ディビシオン(2部)へ昇格したが、昇格プレーオフで下位クラブと対戦。
>> 2016年シーズンにセグンダ・ディビシオン(2部)へ昇格したが、昇格プレーオフで下位クラブと対戦。
この試合では勝ち点3を記録したものの勝ち点1と、結果を残せずにシーズンを終えた。
>> この試合では勝ち点3を記録したものの勝ち点1と、結果を残せずにシーズンを終えた。
2017年11月7日、FCミラーと契約した。
>> 2017年11月7日、FCミラーと契約した。
2016年9月、インテルCO. (期限付きオプション付き) に移籍した。
今度は、延々とどこまでも続けられます。ただ、脈絡のなさは笑ってしまうレベルです。
7. おわりに
以上、Seq2Seqを利用した文章生成について、記述しました。Seq2Seqを使って再帰的に文章を生成しようとすると、結果が収束して入出力が同じになってしまうというのは、意外な発見でした。
また、出力を確率変動させることにより、出力の収束を防ぐことは可能ですが、何かの役に立つレベルに到達することはできませんでした。
この点について打開策があるかどうか、引き続き検討してみましたが、その結果についてはこちらをご覧ください。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2019/6/18 | - | 初版 |
| 2 | 2020/11/26 | タイトル | 「その2」以下を追加 |
| 3 | 2020/11/26 | 7章 | 筆者の投稿「Seq2Seqを利用した文章生成 −その2 文脈状態の利用」へのリンク追加 |