本稿では、チャットボット用に作成したKerasベースのSeq2Seq(Sequence to Sequence)ニューラルネットワークを使って、1つの入力文から複数の文の連なり(文章)を生成することを目指します。文章生成にあたっては、文脈状態を利用します。なお、訓練用の日本語コーパスには、Wikipediaの公開データをダウンロードして使用しました。
以下は、川端康成の「雪国」冒頭を入力に、文章生成を行った結果です。
\>> 国境の長いトンネルを抜けると雪国だった。 この駅は、駅の南側に位置していた。 駅舎は構内の西側に位置し、ホームは線路の東側(名寄方面に向かって左手側)に存在した。 ホームは線路の西側に位置し、ホーム中央部分に接していた。 分岐器を持たない棒線駅となっていた。1. はじめに
1−1. 前回のおさらい
前回の投稿では、チャットボット用に構築したニューラルネットワークを再帰的に使用することによって、文章を生成しようと試みました。ところが、再帰入力を繰り返すと、出力文が同じ文に収束してしまいました。
1−2. 文脈状態について
文脈状態(context hidden state)とは、対話モデルにおいて過去の複数の発話文情報を応答文生成に活用するため、各発話文ごとに生成する隠れ層ベクトルのことです。基本的なアイデアはこちらの論文に依ります。この文脈状態を利用することにより、再帰入力による生成文収束を避けつつ、過去の文の内容を反映した文章生成が可能になると考えました。イメージは以下の通りです。
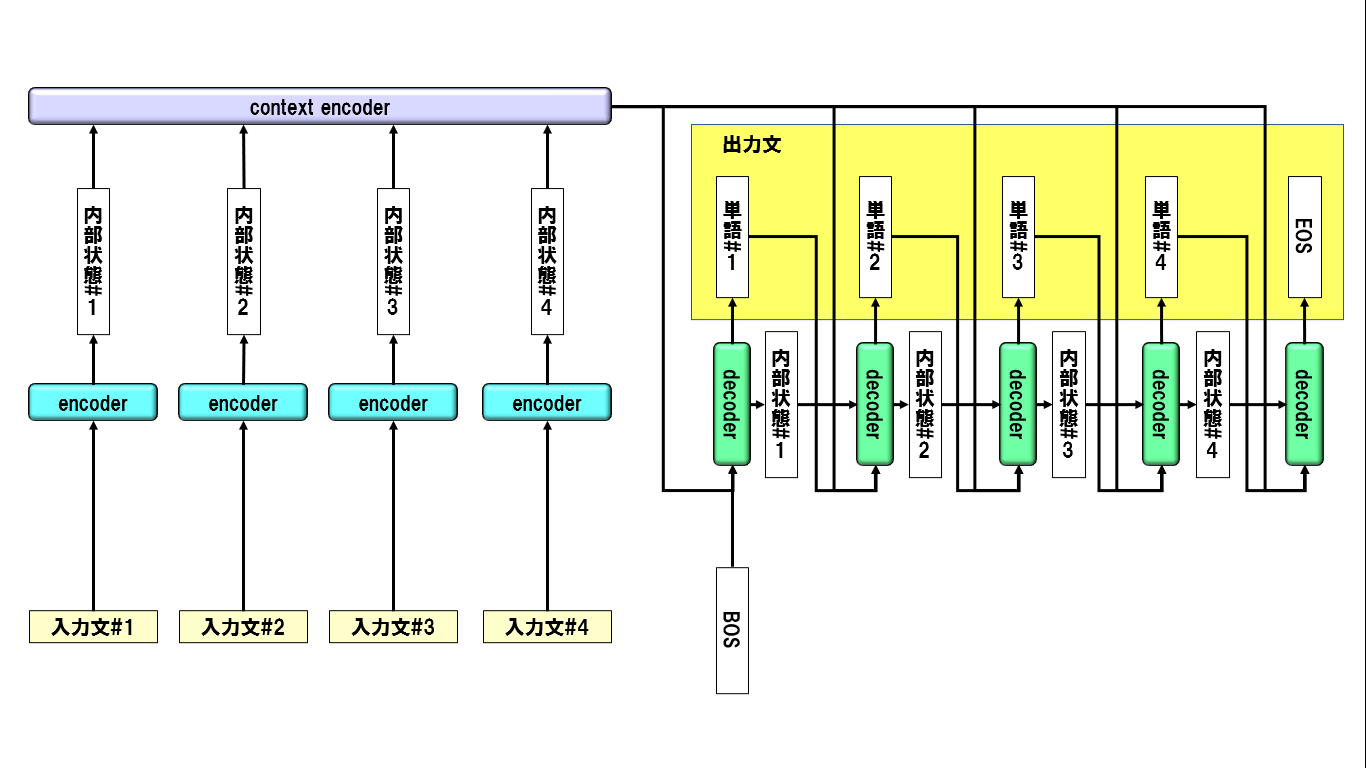
2. 本稿のゴール
以下の通りです。
- 文脈情報を利用して、一つの入力文から複数の文を連続生成する
訓練用日本語コーパスは、Wikipediaのデータを利用します。入手方法はこちらを参照ください。
なお、本稿の前提となるソフトウェア環境は、以下の通りです。
- Ubuntu 16.04 LTS
- Python 3.6.4
- Anaconda 5.1.0
- TensorFlow-gpu 1.3.0
- Keras 2.1.4
- Jupyter 4.4.0
また、後述の訓練処理が非常に重いので、ハードウェア環境としては、GPUマシンか、クラウドサービスの利用を推奨します。
3. ニューラルネットワーク構造の基本的な考え方
3-1. 生成文の順序別にニューラルネットワークを分離する
生成文の収束を避けるため、生成文の順序別にニューラルネットワークを、それぞれ別に用意します。1番目の生成文と2番目の生成文では、それぞれの文を生成するニューラルネットワークが、別であるということです。以下の図のようなイメージです。
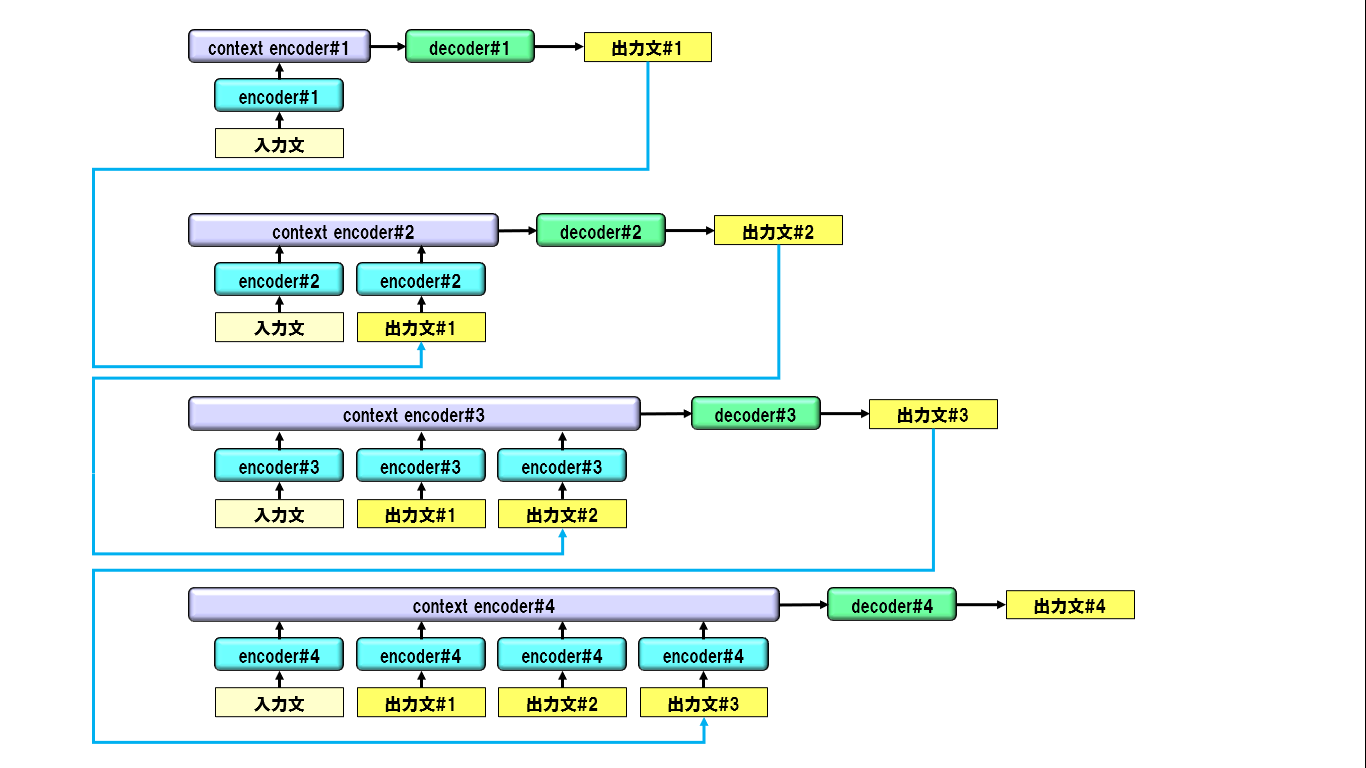
3-2. エンコーダーの構造
基本構成は、2層双方向LSTMです。context encoderにはGRUを使用します。statesが1層分と2層分の2つあるので、context statesも2種類あります。以下にイメージを示します。
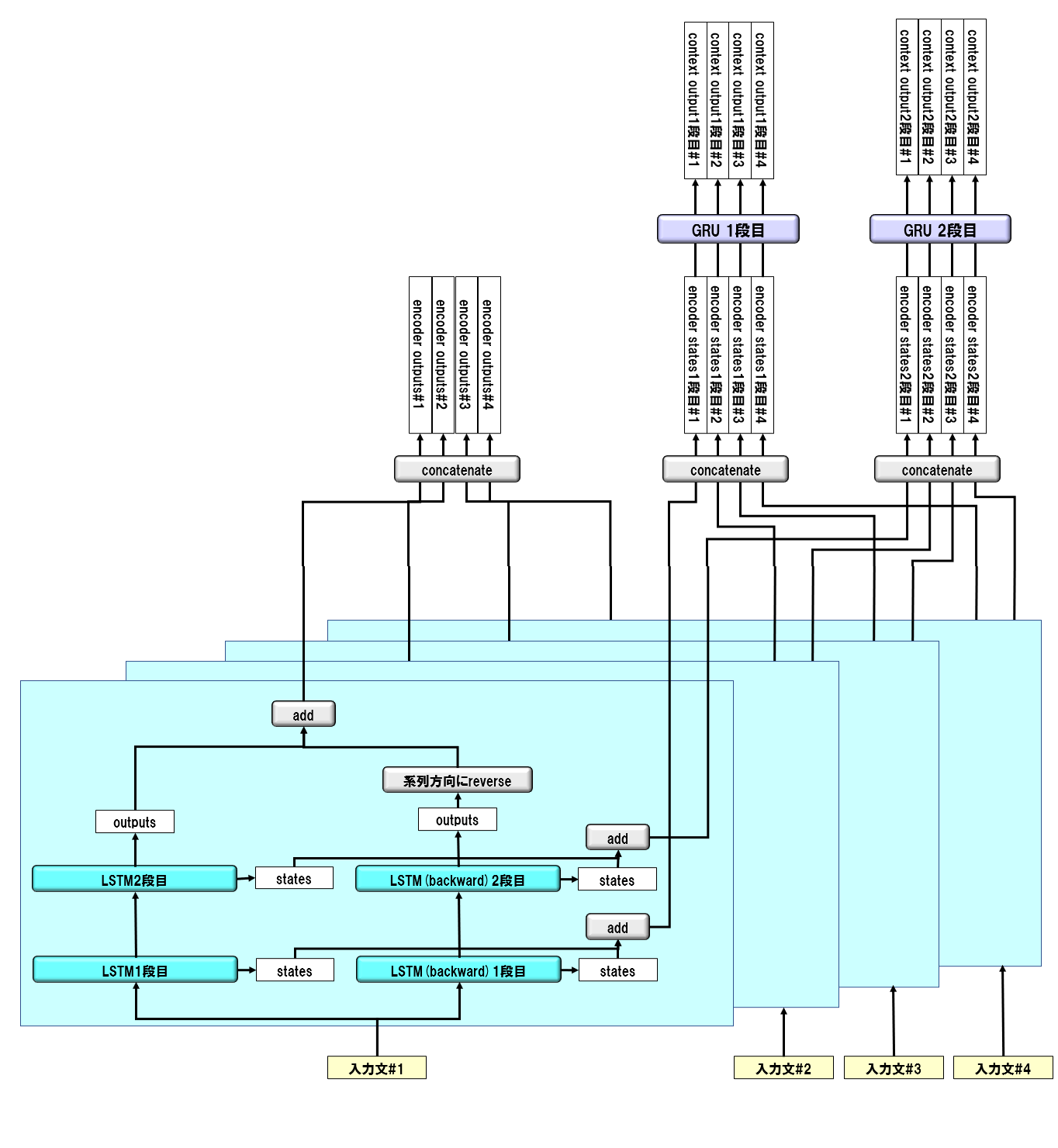
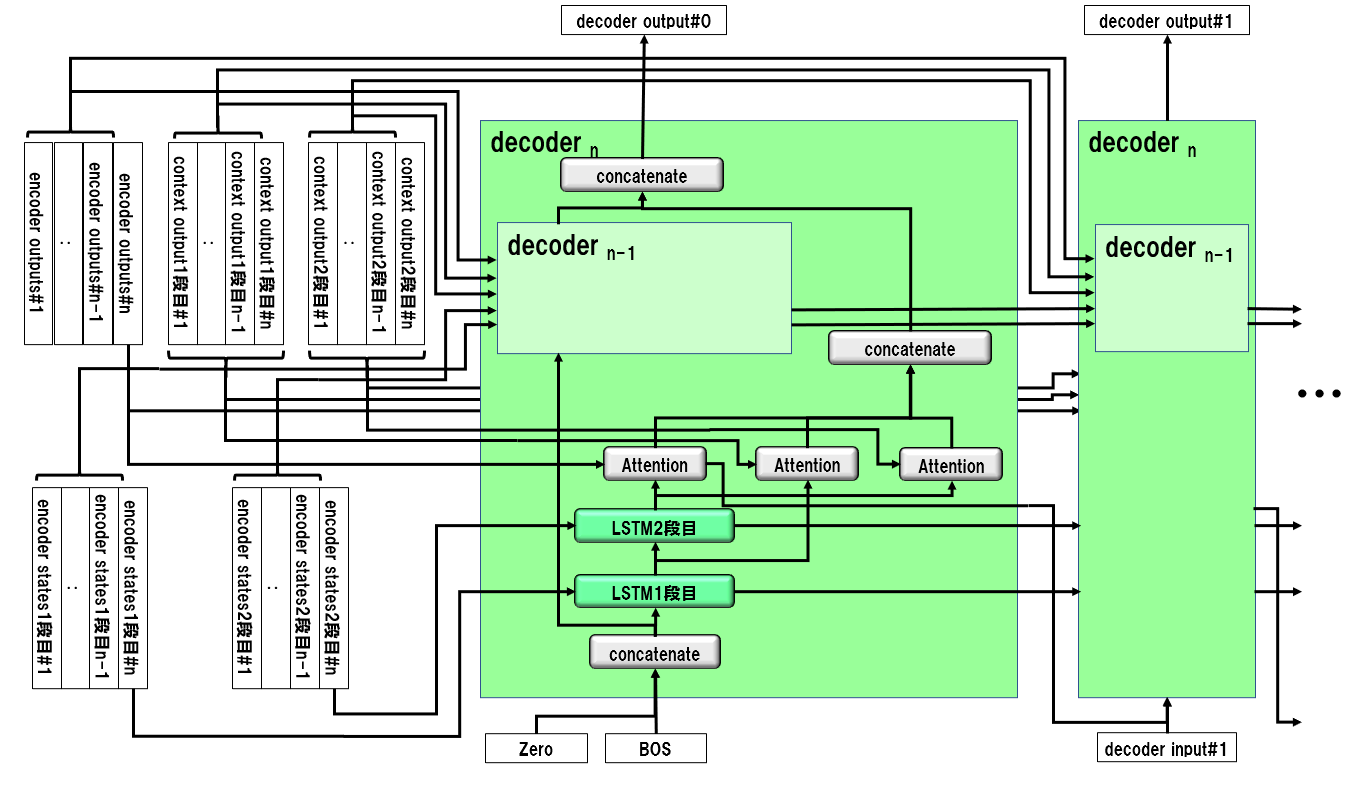
3-3. デコーダーの構造
生成文数$n$をインデックスとして、帰納的に定義します。
$n=1$のとき:
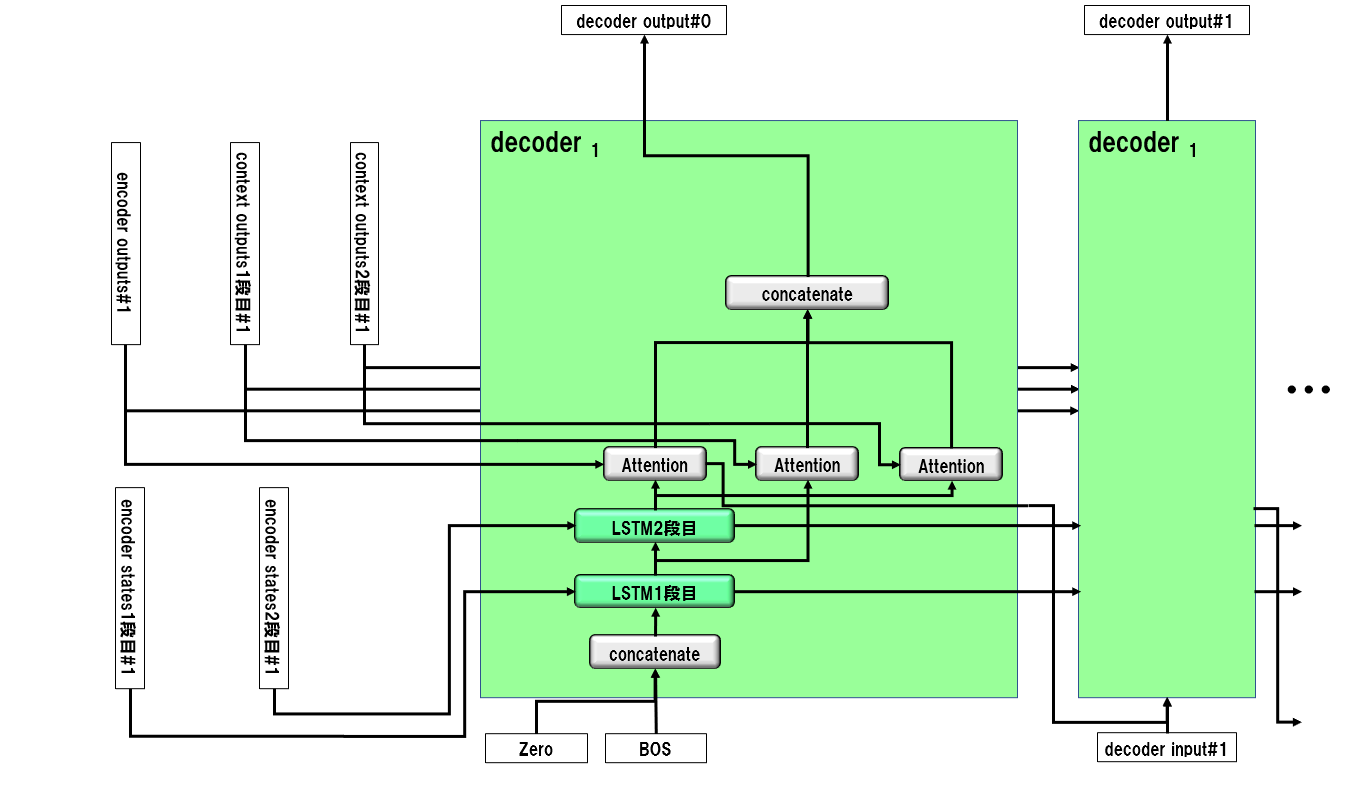
$n>1$のとき:
4. ソースコード
本稿で使用するソースコードの一覧は以下の通りです。
| ファイル名 | 説明 |
|---|---|
| 0500_generate_context_data.py | 文脈情報生成処理 |
| 0600_generate_training_data.py | 訓練データ生成処理 |
| 1000_seq2seq_wiki_context.py | 訓練実行処理 |
| 2000_gen_sentence.py | 文章生成処理 |
| context.py | ニューラルネットワークのクラス定義 |
| context_encoder.py | ニューラルネットワークのうち、エンコーダ部分の定義 |
| context_decoder.py | ニューラルネットワークのうち、デコーダ部分の定義 |
| context_attention.py | ニューラルネットワークのattention定義 |
| context_layers.py | ニューラルネットワークのレイヤ定義 |
| context_loss.py | 損失関数、評価関数定義 |
| context_train.py | ニューラルネットワークの訓練処理 |
数字で始まるソースコードは、コマンドラインから実行します。それ以外のソースコードはニューラルネットワークのクラス定義で、他のプログラムからimportされて動作します。これらの呼び出し関係は以下のとおりです。
context.py ─┬─ context_encoder.py ─── context_layers.py
├─ context_decoder.py ─┬─ context_layers.py
| └─ context_attention.py ─── context_layers.py
├─ context_train.py
├─ context_loss.py
└─ context_layers.py
実行に当たっては、すべてのファイルを、同一フォルダ内に配置してください。
以下、ファイル名をクリックすると、ソースコードが展開されます。
0500_generate_context_data.py
# coding: utf-8
# *******************************************************************************
# *
# 単語配列、コーパス配列、辞書のロード *
# *
# *******************************************************************************
def load_data():
#単語ファイルロード
with open('words.pickle', 'rb') as f :
words=pickle.load(f)
#作成した辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f)
with open('indices_word.pickle', 'rb') as g :
indices_word = pickle.load(g)
with open('indices_freq.pickle', 'rb') as g :
indices_freq = pickle.load(g)
#with open('freq_indices.pickle', 'rb') as g :
# freq_indices = pickle.load(g)
#コーパスロード
mat_urtext = np.load('mat_urtext.npy')
mat_urtext = mat_urtext.reshape((mat_urtext.shape[0],))
data = {'words':words,
'word_indices':word_indices,
'indices_word':indices_word,
'mat_urtext':mat_urtext,
# 'freq_indices':freq_indices,
'indices_freq':indices_freq}
return data
# *******************************************************************************
# *
# 訓練データ/ラベルテンソル作成処理 *
# *
# *******************************************************************************
def generate_train_data(data, maxlen) :
words = data['words']
word_indices = data['word_indices']
indices_word = data['indices_word']
mat_urtext = data['mat_urtext']
indices_freq = data['indices_freq']
maxlen_e = maxlen
maxlen_d = maxlen
#--------------------------------------------------------------------------*
# *
# コーパスをエンコーダ入力、デコーダ入力応答文のテンソルに変換 *
# *
#--------------------------------------------------------------------------*
#コーパスの最初の文脈デリミタ「TTTTTT」を、コーパスの最後に回す
ssssss = word_indices['SSSSSS']
tttttt = word_indices['TTTTTT']
mat_urtext[:-2] = mat_urtext[2:]
mat_urtext[-2] = tttttt
mat_urtext[-1] = ssssss
n_context = 4 # 入力文章数の最大値
delimiters = [i for i in range(len(mat_urtext)) if mat_urtext[i] == ssssss]
print(len(delimiters))
n = len(delimiters) - 1
dim = math.ceil(len(words) / 8)
#--------------------------------------------------------------------------*
# UNK有無判定処理 *
#--------------------------------------------------------------------------*
def unk_judge(mat) :
judge = False
for i in range (0,mat.shape[0]) :
if indices_word[int(mat[i])] == 'UNK' :
judge = True
break
elif int(mat[i]) == 0 :
break
return judge
#--------------------------------------------------------------------------*
# 長さがmaxlen未満でUNKを含まない文を抽出する *
#--------------------------------------------------------------------------*
sentences = []
len_list = []
paragraph = []
paragraph_len_list = []
paragraph_len = 0
index_list = [] # デバック用
for i in range(n) :
if i % 1000000 == 0 :
print(i)
delimiter1 = delimiters[i] # i番目の「SSSSSS」
delimiter2 = delimiters[i+1] # i+1番目の「SSSSSS」
sentence_len = delimiter2 - delimiter1 - 1
sentence = mat_urtext[delimiter1+1 : delimiter2]
sentence_padded = np.zeros((maxlen,), dtype='int32')
if (sentence_len < maxlen and sentence[0] != tttttt) and \
(paragraph_len == 0 or (paragraph_len > 0 and unk_judge(sentence) == False)) :
sentence_padded[:sentence_len] = sentence
paragraph.append(sentence_padded)
paragraph_len_list.append(sentence_len)
paragraph_len += 1
index_list.append(i)
else :
if paragraph_len >= n_context+1 : # 入力文章数(n_context)+出力文数(1)
sentences += paragraph
len_list += paragraph_len_list
sentence_padded[0] = tttttt # 段落セパレータ「TTTTTT」を挿入
sentences.append(sentence_padded)
len_list.append(1)
#print(index_list)
del paragraph, paragraph_len_list, index_list
paragraph = []
paragraph_len_list = []
index_list = []
paragraph_len = 0
#--------------------------------------------------------------------------*
# エンコーダインプット、デコーダインプット、ラベルデータ作成 *
#--------------------------------------------------------------------------*
e_list = []
d_list = []
t_list = []
e_len_list = []
d_len_list = []
m = len(sentences) - 1
for i in range(m) :
#for i in range(10) :
if i % 1000000 == 0 :
print(i)
if sentences[i][0] != tttttt :
e_row = np.zeros((maxlen,), dtype='int32')
d_row = np.zeros((maxlen,), dtype='int32')
t_row = np.zeros((maxlen,), dtype='int32')
e_row[:] = sentences[i][:]
d_row[0] = ssssss
d_row[1:] = sentences[i+1][:maxlen-1]
t_row[:] = sentences[i+1][:]
t_row[len_list[i+1]] = ssssss
e_list.append(e_row)
d_list.append(d_row)
t_list.append(t_row)
e_len_list.append(len_list[i])
d_len_list.append(len_list[i+1]+1) # 文長にセパレータの分を加算
else :
continue
maxlen_e = maxlen
maxlen_d = maxlen
e = np.array(e_list).reshape((len(e_list), maxlen_e))
d = np.array(d_list).reshape((len(d_list), maxlen_d))
t = np.zeros((len(t_list), maxlen_d,2),dtype='int32')
#--------------------------------------------------------------------------*
# ラベルデータをmod、catに分ける *
#--------------------------------------------------------------------------*
#print('SSSSSS', indices_freq[ssssss])
dim = math.ceil(len(words) / 8)
#print('SSSSSS%dim', indices_freq[ssssss]% dim)
for i in range(len(t)) :
for j in range(min(d_len_list[i], maxlen_d)) :
freq = indices_freq[t_list[i][j]]
t[i,j,0] = freq // dim
t[i,j,1] = freq % dim
if i % 1000000 == 0 :
print(i)
print(e.shape, d.shape, t.shape)
#訓練データをセーブ
np.save('data/e_context.npy', e)
np.save('data/d_context.npy', d)
np.save('data/t_context.npy', t)
#print(t[0,:])
# エンコーダインプット単語数リスト、デコーダインプット単語数リストをセーブ
with open('data/e_len_list.pickle', 'wb') as f :
pickle.dump(e_len_list , f)
with open('data/d_len_list.pickle', 'wb') as f :
pickle.dump(d_len_list , f)
#maxlenセーブ
with open('maxlen.pickle', 'wb') as maxlen :
pickle.dump([maxlen_e, maxlen_d] , maxlen)
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
if __name__ == '__main__':
import pickle
import numpy.random as nr
import numpy as np
import math
import sys
args = sys.argv
data = load_data()
generate_train_data(data, int(args[1]))
0600_generate_training_data.py
# coding: utf-8
from __future__ import print_function
# *********************************************************************************************
# *
# 訓練データ、ラベルデータ等をロードする *
# *
# *********************************************************************************************
def load_data() :
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words = pickle.load(ff)
# 辞書ファイルロード
with open('indices_word.pickle', 'rb') as g :
indices_word = pickle.load(g)
# 出現頻度ー単語インデックス変換辞書ロード
with open('freq_indices.pickle', 'rb') as g :
freq_indices = pickle.load(g)
# 単語インデックス−出現頻度変換辞書ロード
with open('indices_freq.pickle', 'rb') as g :
indices_freq = pickle.load(g)
#Encoder Input、Docoder Input、ラベルデータをロード
e_context = np.load('data/e_context.npy')
d_context = np.load('data/d_context.npy')
t_context = np.load('data/t_context.npy')
# エンコーダインプット単語数リスト、デコーダインプット単語数リストをセーブ
with open('data/e_len_list.pickle', 'rb') as f :
e_len_list = pickle.load(f)
with open('data/d_len_list.pickle', 'rb') as f :
d_len_list = pickle.load(f)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
data = {'words' :words,
'indices_word':indices_word,
'indices_freq':indices_freq,
'freq_indices':freq_indices,
'e_context' :e_context,
'd_context' :d_context,
't_context' :t_context,
'e_len_list' :e_len_list,
'd_len_list' :d_len_list,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d
}
return data
# *********************************************************************************************
# *
# 入力文脈リスト作成処理 *
# *
# *********************************************************************************************
def generate_context_list(data) :
indices_word = data['indices_word']
freq_indices = data['freq_indices']
e_context = data['e_context']
t_context = data['t_context']
dim = data['dim']
n_context_list = []
max_list = []
cnt_context = 0
for i in range(e_context.shape[0]) :
cnt_context += 1
n_context_list.append(cnt_context)
freq = t_context[i,0,0] * dim + t_context[i,0,1]
if indices_word[freq_indices[freq]] == 'TTTTTT' :
max_list += [cnt_context] * cnt_context
cnt_context = 0
if i % 1000000 == 0 :
print(i)
return n_context_list, max_list
# *********************************************************************************************
# *
# 訓練用テンソル作成処理 *
# *
# *********************************************************************************************
def generate_tensors(data, n_sentences) :
indices_word = data['indices_word']
e_context = data['e_context']
d_context = data['d_context']
t_context = data['t_context']
n_context_list = data['n_context_list']
max_list = data['max_list']
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_context = 4
#print(n_context_list[:40])
#print(max_list[:40])
def print_index(index) :
if index % 1000000 == 0 :
print(index)
return True
nr.seed(12345)
train_data = [[
[e_context[k, :] for k in range(j-n_sentences+1, j+1)],
[d_context[k, :] for k in range(j-n_sentences+1, j+1)],
[t_context[k, :] for k in range(j-n_sentences+1, j+1)]
]
for j in range(t_context.shape[0])
if max_list[j]-n_context+n_sentences-1 >= n_context_list[j] >= n_sentences
and print_index(j) == True
and indices_word[d_context[j,1]] != 'TTTTTT'
]
print('shuffle')
data_row = len(train_data) # 訓練データの行数
nr.shuffle(train_data) #シャッフル
e, d, t = zip(*train_data)
#print(np.array(e).shape)
e = np.array(e).reshape((data_row, maxlen_e*n_sentences))
d = np.array(d).reshape((data_row, maxlen_d*n_sentences))
t = np.array(t).reshape((data_row, maxlen_d*n_sentences, 2))
print(e.shape,d.shape,t.shape)
return e, d, t
# *********************************************************************************************
# *
# メイン処理 *
# *
# *********************************************************************************************
if __name__ == '__main__':
from context import Gen_Context
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
from keras.utils import plot_model
import codecs
args = sys.argv
n_sentences = int(args[1])
param_name = 'param_0'+'{0:0>2d}'.format(n_sentences)
data = load_data()
words = data['words']
dim = math.ceil(len(words) / 8)
data['dim'] = dim
n_context_list, max_list = generate_context_list(data)
data['n_context_list'] = n_context_list
data['max_list'] = max_list
input_dim = len(words)
e, d, t = generate_tensors(data, n_sentences)
# 作成データセーブ
np.save('data/e_0'+'{0:0>2d}'.format(n_sentences)+'.npy', e)
np.save('data/d_0'+'{0:0>2d}'.format(n_sentences)+'.npy', d)
np.save('data/t_0'+'{0:0>2d}'.format(n_sentences)+'.npy', t)
1000_seq2seq_wiki_context.py
# coding: utf-8
from __future__ import print_function
# sys.path.append("/home/ishigaki/pyknp-0.3")
# *********************************************************************************************
# *
# 訓練データ、ラベルデータ等をロードする *
# *
# *********************************************************************************************
def load_data(n_sentences) :
#Encoder Input、Docoder Input、ラベルデータをロード
e = np.load('data/e_0'+'{0:0>2d}'.format(n_sentences)+'.npy')
d = np.load('data/d_0'+'{0:0>2d}'.format(n_sentences)+'.npy')
t = np.load('data/t_0'+'{0:0>2d}'.format(n_sentences)+'.npy')
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
#dimロード
with open('dim.pickle', 'rb') as dim :
[n_hidden, input_dim, vec_dim, output_dim] = pickle.load(dim)
data = {
'e' :e,
'd' :d,
't' :t,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
'n_hidden' :n_hidden,
'input_dim' :input_dim,
'vec_dim' :vec_dim,
'output_dim' :output_dim
}
return data
# *********************************************************************************************
# *
# 訓練処理 *
# *
# *********************************************************************************************
def prediction(epochs, batch_size , param_name, states_name, n_sentences, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
e = data['e']
d = data['d']
t = data['t']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
data_row = e.shape[0] # 訓練データの行数
n_split = int(data_row*0.9)
e_train, e_test = np.vsplit(e,[n_split]) #エンコーダインプットデータを訓練用とテスト用に分割
d_train, d_test = np.vsplit(d,[n_split]) #デコーダインプットデータを訓練用とテスト用に分割
t_train, t_test = np.vsplit(t,[n_split]) #ラベルデータを訓練用とテスト用に分割
prediction = Gen_Context(n_sentences, maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim)
emb_param = param_name+'.hdf5'
model, _ = prediction.train(e_train, d_train, t_train,
batch_size, epochs, emb_param)
print()
perplexity, \
perplexity_mod,\
perplexity_cat = prediction.eval_perplexity(model, e_test, d_test, t_test, batch_size)
print('loss =',perplexity, perplexity_mod, perplexity_cat)
# *********************************************************************************************
# *
# メイン処理 *
# *
# *********************************************************************************************
if __name__ == '__main__':
from context import Gen_Context
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
from keras.utils import plot_model
import codecs
args = sys.argv
epochs = int(args[1])
batch_size = int(args[2])
n_sentences = int(args[3])
param_name = 'param_0'+'{0:0>2d}'.format(n_sentences)
states_name = 'states_0'+'{0:0>2d}'.format(n_sentences)
data = load_data(n_sentences)
# 訓練処理
prediction(epochs, batch_size ,param_name, states_name, n_sentences, data)
2000_gen_sentence.py
# coding: utf-8
# *************************************************************************************
# *
# import宣言 *
# *
# *************************************************************************************
from __future__ import print_function
from context import Gen_Context
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
from keras.utils import plot_model
sys.path.append("/home/ishigaki/pyknp-0.3")
from pyknp import Jumanpp
import codecs
# *************************************************************************************
# *
# 辞書ファイル等ロード *
# *
# *************************************************************************************
def load_data() :
#辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f) #単語をキーにインデックス検索
with open('indices_word.pickle', 'rb') as g :
indices_word=pickle.load(g) #インデックスをキーに単語を検索
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
#各単語の出現頻度順位(降順)
with open('freq_indices.pickle', 'rb') as f :
freq_indices = pickle.load(f)
#出現頻度→インデックス変換
with open('indices_freq.pickle', 'rb') as f :
indices_freq = pickle.load(f)
#dimロード
with open('dim.pickle', 'rb') as dim :
[n_hidden, input_dim, vec_dim, output_dim] = pickle.load(dim)
data = {'words' :words,
'indices_word':indices_word,
'indices_freq':indices_freq,
'freq_indices':freq_indices,
'word_indices':word_indices ,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
'n_hidden' :n_hidden,
'input_dim' :input_dim,
'vec_dim' :vec_dim,
'output_dim' :output_dim
}
return data
# *************************************************************************************
# *
# モデル初期化 *
# *
# *************************************************************************************
def initialize_models(len_output_context ,data) :
maxlen_e = data['maxlen_e']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
model = []
encoder_model = []
decoder_model = []
for i in range(1, len_output_context+1) :
gen_context = Gen_Context(i, maxlen_e, 1, n_hidden, input_dim, vec_dim, output_dim)
m, encoder_m ,decoder_m, save_m = gen_context.create_model()
param_file1 = 'param_0'+'{0:0>2d}'.format(i)+'.hdf5'
save_m.load_weights(param_file1)
#set_param(m, i, data) # 重み設定
#
model.append(m)
encoder_model.append(encoder_m)
decoder_model.append(decoder_m)
return model, encoder_model ,decoder_model
# *************************************************************************************
# *
# 入力文の品詞分解とインデックス化 *
# *
# *************************************************************************************
def encode_request(cns_input, data) :
maxlen_e = data['maxlen_e']
word_indices = data['word_indices']
words = data['words']
# Use Juman++ in subprocess mode
jumanpp = Jumanpp()
result = jumanpp.analysis(cns_input.replace(" ", ""))
input_text=[]
for mrph in result.mrph_list():
input_text.append(mrph.midasi)
mat_input=np.array(input_text)
#入力データe_inputに入力文の単語インデックスを設定
e_input=np.zeros((1,maxlen_e))
for i in range(0,len(mat_input)) :
if mat_input[i] in words :
e_input[0,i] = word_indices[mat_input[i]]
else :
e_input[0,i] = word_indices['UNK']
return e_input
# *************************************************************************************
# *
# 応答文組み立て *
# *
# *************************************************************************************
def generate_response(context_order, e_input, data) :
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
output_dim = data['output_dim']
freq_indices = data['freq_indices']
indices_word = data['indices_word']
word_indices = data['word_indices']
encoder_model = data['encoder_model'][context_order]
decoder_model = data['decoder_model'][context_order]
# Encode the input as state vectors.
#print(e_input)
e_result = encoder_model.predict(e_input)
encoder_outputs = e_result[0]
encoder_i_mask = e_result[1]
encoder_state_h = list(e_result[2:4])
encoder_state_c = list(e_result[4:6])
context_state = list(e_result[6:])
decoder_input_a = np.zeros((1, context_order+1, n_hidden))
decoder_input_h = encoder_state_h
decoder_input_c = encoder_state_c
decoded_sentence = ''
target_seq = np.zeros((1,context_order + 1) ,dtype='int32')
# Populate the first character of target sequence with the start character.
target_seq[0, -1] = word_indices['SSSSSS']
# 応答文字予測
#print(decoder_input_state1.shape)
for i in range(0,maxlen_d) :
d_result = decoder_model.predict([target_seq, decoder_input_a]
+ decoder_input_h
+ decoder_input_c
+ [encoder_outputs, encoder_i_mask]
+ context_state)
do_cat = d_result[0]
do_mod = d_result[1]
a_o = d_result[2]
d_h = list(d_result[3:5])
d_c = list(d_result[5:7])
# 予測単語の出現頻度算出
n_cat = np.argmax(do_cat[0, context_order, :])
n_mod = np.argmax(do_mod[0, context_order, :])
#print(n_cat)
freq = (n_cat * output_dim + n_mod).astype(int)
#print(freq)
#予測単語のインデックス値を求める
sampled_token_index = freq_indices[freq]
#予測単語
sampled_char = indices_word[sampled_token_index]
# Exit condition: find stop character.
if sampled_char == 'SSSSSS' :
break
decoded_sentence += sampled_char
# Update the target sequence (of length 1).
if i == maxlen_d-1:
break
target_seq[0, -1] = sampled_token_index
# 次段向け値設定
decoder_input_a = a_o
decoder_input_h = d_h
decoder_input_c = d_c
return decoded_sentence
# *************************************************************************************
# *
# メイン処理 *
# *
# *************************************************************************************
if __name__ == '__main__':
args = sys.argv
len_output_context = int(args[1]) # 出力文章数
#データロード
data = load_data()
#モデル初期化
model, encoder_model ,decoder_model = initialize_models(len_output_context ,data)
data['encoder_model'] = encoder_model
data['decoder_model'] = decoder_model
sys.stdin = codecs.getreader('utf_8')(sys.stdin)
#maxlen_e = data['maxlen_e']
n_hidden = data['n_hidden']
while True:
cns_input = input(">> ")
if cns_input == "q":
print("終了")
break
for i in range(len_output_context) :
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
if i == 0 :
e_input = encode_request(cns_input, data)
else :
e_input = np.concatenate([e_input, encode_request(cns_input, data)], -1)
#print(e_input)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence = generate_response(i, e_input, data)
cns_input = decoded_sentence
print(cns_input)
context.py
# coding: utf-8
from keras.layers.core import Masking
from keras import backend as K
from keras.layers import Input
from keras.layers import Lambda
from keras.layers import Reshape
from keras.models import Model
from keras.utils import plot_model
from context_layers import Layer_Embedding
from context_layers import Layer_BatchNorm
from context_encoder import Class_Encoder
from context_decoder import Class_Decoder
from context_train import train
from context_train import train_test_main
from context_loss import fn_cross_loss
from context_loss import fn_perplexity
from context_loss import fn_accuracy
import math
# *******************************************************************************
# *
# ニューラルネットワーククラス定義 *
# *
# *******************************************************************************
class Gen_Context :
def __init__(self, n_sentences, maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim):
n_context_hidden = n_hidden
n_context_attention = n_hidden
self.data = {
'n_sentences' : n_sentences,
'maxlen_e' : maxlen_e,
'maxlen_d' : maxlen_d,
'input_dim' : input_dim,
'vec_dim' : vec_dim,
'output_dim' : output_dim ,
'n_hidden' : n_hidden ,
'n_context_hidden' : n_context_hidden,
'n_context_attention': n_context_attention,
'dim_cat' : math.floor(input_dim / 12000),
'len_norm': 2,
#'r_lambda': 5e-06
#'r_lambda': 0.0
}
if n_sentences == 1 :
self.data['r_lambda'] = 2e-06
else :
self.data['r_lambda'] = 0.0
#***************************************************************************
# *
# ニューラルネットワーク定義 *
# *
#***************************************************************************
def create_model(self):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_sentences = self.data['n_sentences']
maxlen_e = self.data['maxlen_e']
maxlen_d = self.data['maxlen_d']
input_dim = self.data['input_dim']
vec_dim = self.data['vec_dim']
n_hidden = self.data['n_hidden']
n_context_hidden = self.data['n_context_hidden']
len_norm = self.data['len_norm'] # constraintの最大ノルム長
r_lambda = self.data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤ定義 *
# *
#***********************************************************************
class_Embedding = Layer_Embedding(max_value=len_norm,
reg_lambda=r_lambda)
class_BatchNorm = Layer_BatchNorm(max_value=len_norm,
reg_lambda=r_lambda)
embedding = class_Embedding.create_Embedding(emb_out_dim=vec_dim,
emb_in_dim=input_dim)
decoder_BatchNorm \
= class_BatchNorm.create_BatchNorm(bn_name='decoder_BatchNorm')
encoder = Class_Encoder(self.data)
decoder = Class_Decoder(self.data)
print('#3')
#***********************************************************************
# *
# エンコーダー(学習/応答文作成兼用) *
# *
#***********************************************************************
#---------------------------------------------------------
# 入力定義
#---------------------------------------------------------
encoder_input = Input(shape=(maxlen_e*n_sentences,),
dtype='int32', name='encorder_input')
e_input = Masking(mask_value=0, name="input_Mask")(encoder_input)
e_input = embedding(e_input)
#---------------------------------------------------------
# エンコーダメイン処理
#---------------------------------------------------------
encoder_outputs, \
encoder_state_h, \
encoder_state_c, \
context_state = encoder.encoder_nn(e_input)
#---------------------------------------------------------
# encoderマスク生成
#---------------------------------------------------------
encoder_i_mask = Lambda(lambda x: K.sign(x),
name='encoder_sign')(encoder_input)
#---------------------------------------------------------
# エンコーダモデル定義
#---------------------------------------------------------
encoder_model = Model(inputs=encoder_input,
outputs=[encoder_outputs,
encoder_i_mask]
+ encoder_state_h
+ encoder_state_c
+ context_state) #エンコーダモデル
print('#4')
#***********************************************************************
# デコーダー(学習用) *
# デコーダを、完全な出力シークエンスを返し、 *
# 内部状態もまた返すように設定します。 *
# 訓練モデルではreturn_sequencesを使用しませんが、推論では使用します。 *
#***********************************************************************
#---------------------------------------------------------
# 入力定義
#---------------------------------------------------------
decoder_inputs = Input(shape=(maxlen_d * n_sentences,),
dtype='int32', name='decoder_inputs')
d_i = Masking(mask_value=0)(decoder_inputs)
d_i = embedding(d_i)
d_i = decoder_BatchNorm(d_i)
d_input = d_i # 応答文生成で使う
#---------------------------------------------------------
# デコーダメイン処理
#---------------------------------------------------------
a_output = Lambda(lambda x: K.zeros_like(x),
name='zeros_like_attention')(encoder_state_h[0])
a_output = Reshape((n_sentences, n_hidden),
name='Reshape_attention')(a_output)
decoder_outputs_cat, \
decoder_outputs_mod, \
_, _, _ = decoder.decoder_nn(maxlen_d, d_i, a_output,
encoder_state_h, encoder_state_c,
encoder_outputs, encoder_i_mask,
context_state)
#---------------------------------------------------------
# 損失関数
#---------------------------------------------------------
mask = Lambda(lambda x: K.sign(x))(decoder_inputs)
perp_mask = K.cast(mask,dtype='float32')
def cross_loss(y_true, y_pred) :
return fn_cross_loss(y_true, y_pred, perp_mask, self.data)
#---------------------------------------------------------
# perplexity
#---------------------------------------------------------
def get_perplexity(y_true, y_pred) :
return fn_perplexity(y_true, y_pred, perp_mask, self.data)
#---------------------------------------------------------
# 評価関数
#---------------------------------------------------------
def get_accuracy(y_true, y_pred) :
return fn_accuracy(y_true, y_pred, mask, self.data)
#---------------------------------------------------------
# モデル定義、コンパイル
#---------------------------------------------------------
model = Model(inputs=[encoder_input, decoder_inputs],
outputs=[decoder_outputs_cat ,decoder_outputs_mod])
model.compile(loss=cross_loss,
optimizer="Adam", metrics=[get_perplexity, get_accuracy])
#***********************************************************************
# *
# デコーダー(応答文作成) *
# *
#***********************************************************************
print('#6')
#---------------------------------------------------------
#入力定義
#---------------------------------------------------------
decoder_input_h = [Input(shape=(n_sentences, n_hidden),
name='decoder_input_h'+str(i))
for i in range(2)]
decoder_input_c = [Input(shape=(n_sentences, n_hidden),
name='decoder_input_c'+str(i))
for i in range(2)]
decoder_input_context = [Input(shape=(n_sentences, n_context_hidden),
name='decoder_input_context'+str(i))
for i in range(2)]
decoder_input_a = Input(shape=(n_sentences, n_hidden),
name='decoder_input_a')
decoder_input_encoded = Input(shape=(maxlen_e * n_sentences,
n_hidden),
name='decoder_input_encoded')
decoder_input_mask = Input(shape=(maxlen_e * n_sentences,),
name='decoder_input_mask')
#---------------------------------------------------------
# デコーダー実行
#---------------------------------------------------------
#print('decoder_input_state1',K.int_shape(decoder_input_state1))
decoder_res_cat, \
decoder_res_mod, \
res_decoder_a_o, \
res_decoder_o_h, \
res_decoder_o_c \
= decoder.decoder_nn(1, d_input, decoder_input_a,
decoder_input_h, decoder_input_c,
decoder_input_encoded, decoder_input_mask,
decoder_input_context)
#---------------------------------------------------------
# モデル定義
#---------------------------------------------------------
decoder_model = Model(inputs= [decoder_inputs, decoder_input_a]
+ decoder_input_h
+ decoder_input_c
+ [decoder_input_encoded,
decoder_input_mask]
+ decoder_input_context,
outputs=[decoder_res_cat,
decoder_res_mod,
res_decoder_a_o]
+ res_decoder_o_h
+ res_decoder_o_c)
print('#7')
#***********************************************************************
# *
# weightセーブ用NN *
# *
#***********************************************************************
a_output_s = Lambda(lambda x: K.zeros_like(x),
name='zeros_like_attention_s')(encoder_state_h[0])
a_output_s = Reshape((n_sentences, n_hidden),
name='Reshape_attention_s')(a_output)
#print('a_output',K.int_shape(a_output))
decoder_outputs_cat_s, \
decoder_outputs_mod_s, _, _, _ \
= decoder.decoder_nn(1, d_i, a_output_s,
encoder_state_h, encoder_state_c,
encoder_outputs, encoder_i_mask,
context_state)
save_model = Model(inputs=[encoder_input, decoder_inputs],
outputs=[decoder_outputs_cat_s ,
decoder_outputs_mod_s])
return model, encoder_model, decoder_model, save_model
#***************************************************************************
# *
# 学習 *
# *
#***************************************************************************
def train(self, e_input, d_input, target,
batch_size, epochs, emb_param) :
print ('#2',target.shape)
model ,encoder_model , decoder_model, save_model = self.create_model()
# ネットワーク図出力
plot_model(model, show_shapes=True,to_file='wiki.png')
plot_model(encoder_model, show_shapes=True,to_file='wiki_encoder.png')
plot_model(decoder_model, show_shapes=True,to_file='wiki_decoder.png')
return model, train(model, save_model, e_input, d_input, target,
batch_size, epochs, emb_param, self.data)
#***************************************************************************
# *
# perplexity計算 *
# *
#***************************************************************************
def eval_perplexity(self, model, e_test, d_test, t_test, batch_size) :
params = {'model' : model,
'save_model': '',
'batch_size': batch_size,
'emb_param' : '' }
return train_test_main('test', e_test, d_test, t_test,
params, self.data)
context_encoder.py
# coding: utf-8
# *******************************************************************************
# *
# エンコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from keras.layers import Lambda
from keras.layers import Concatenate
from keras.layers import Add
from keras.layers import Reshape
from keras import backend as K
import numpy as np
from context_layers import Layer_LSTM
from context_layers import Layer_GRU
from context_layers import Layer_BatchNorm
class Class_Encoder :
def __init__(self, data):
self.data = data
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_hidden = data['n_hidden']
n_context_hidden = data['n_context_hidden']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_LSTM = Layer_LSTM(max_value=len_norm, reg_lambda=r_lambda)
class_GRU = Layer_GRU(max_value=len_norm, reg_lambda=r_lambda)
class_BatchNorm = Layer_BatchNorm(max_value=len_norm,
reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
self.encoder_BatchNorm \
= class_BatchNorm.create_BatchNorm(bn_name='encoder_BatchNorm')
self.e_o_BatchNorm \
= class_BatchNorm.create_BatchNorm(bn_name='e_o_BatchNorm')
self.e_h_BatchNorm \
= [class_BatchNorm.create_BatchNorm(bn_name='e_h_BatchNorm'+str(i))
for i in range(2)]
self.e_c_BatchNorm \
= [class_BatchNorm.create_BatchNorm(bn_name='e_c_BatchNorm'+str(i))
for i in range(2)]
self.e_s_BatchNorm \
= [class_BatchNorm.create_BatchNorm(bn_name='e_s_BatchNorm'+str(i))
for i in range(2)]
self.context_GRU = [class_GRU.create_GRU(n_context_hidden,
gru_return_sequences=True,
gru_name='context_GRU'+str(i))
for i in range(2)]
self.encoder_LSTM_fw = [class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_name='encoder_LSTM_fw'+str(i))
for i in range(2)]
self.encoder_LSTM_bw = [class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_go_backwards=True,
lstm_return_sequences=True,
lstm_name='encoder_LSTM_bw'+str(i))
for i in range(2) ]
def encoder_nn(self, e_input) :
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_sentences = self.data['n_sentences']
maxlen_e = self.data['maxlen_e']
n_hidden = self.data['n_hidden']
#***********************************************************************
# *
# レイヤー定義 *
# *
#***********************************************************************
e_input_timeslice1 = Lambda(lambda x: x[:, :maxlen_e],
name='e_input_timeslice1')
e_input_timeslice2 = Lambda(lambda x: x[:, maxlen_e:],
name='e_input_timeslice2')
e_o_reverse = Lambda(lambda x: K.reverse(x, 1),name='e_o_reverse')
e_o_Add = Add(name="e_o_ADD")
e_h_Add = [Add(name="e_h_ADD"+str(i)) for i in range(2)]
e_c_Add = [Add(name="e_c_ADD"+str(i)) for i in range(2)]
e_s_Concat0 = [Concatenate(axis=-1,name='e_s_Concat0'+str(i))
for i in range(2)]
e_h_Reshape = [Reshape((1,n_hidden),name='e_h_Reshape'+str(i))
for i in range(2)]
e_c_Reshape = [Reshape((1,n_hidden),name='e_c_Reshape'+str(i))
for i in range(2)]
e_h_Concat = [Concatenate(axis=1,name='e_h_Concat'+str(i))
for i in range(2)]
e_c_Concat = [Concatenate(axis=1,name='e_c_Concat'+str(i))
for i in range(2)]
e_s_Concat = [Concatenate(axis=1,name='e_s_Concat'+str(i))
for i in range(2)]
e_o_Concat = Concatenate(axis=1,name='e_o_Concat')
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
#---------------------------------------------------------
# 文章単位ループ前処理
#---------------------------------------------------------
e_input = self.encoder_BatchNorm(e_input)
#---------------------------------------------------------
# 文章ごとのエンコード処理
#---------------------------------------------------------
def encoding(e_i) :
e_o_fw1 ,h_fw1, c_fw1 = self.encoder_LSTM_fw[0](e_i) #前向き
e_o_bw1 ,h_bw1, c_bw1 = self.encoder_LSTM_bw[0](e_i) #後ろ向き
e_o_fw2 ,h_fw2, c_fw2 = self.encoder_LSTM_fw[1](e_o_fw1) #前向き
e_o_bw2 ,h_bw2, c_bw2 = self.encoder_LSTM_bw[1](e_o_bw1) #後ろ向き
e_o_bw2 = e_o_reverse(e_o_bw2) # 後ろ向き系列を正順に直す
e_o = e_o_Add([e_o_fw2, e_o_bw2])
h1 = e_h_Add[0]([h_fw1, h_bw1])
c1 = e_c_Add[0]([c_fw1, c_bw1])
h2 = e_h_Add[1]([h_fw2, h_bw2])
c2 = e_c_Add[1]([c_fw2, c_bw2])
return e_o, [h1, h2], [c1, c2]
#---------------------------------------------------------
# メイン処理
#---------------------------------------------------------
# 文章ごとのエンコーダインプット生成
for i in range(n_sentences) :
e_i = e_input_timeslice1(e_input)
e_input = e_input_timeslice2(e_input)
# 文章エンコード
e_o, h, c = encoding(e_i)
h = [e_h_Reshape[i](h[i]) for i in range(2)]
c = [e_c_Reshape[i](c[i]) for i in range(2)]
e_s = [e_s_Concat0[i]([h[i], c[i]]) for i in range(2)]
if i==0 :
c_state = e_s
e_outputs = e_o
e_h = h
e_c = c
else :
c_state = [e_s_Concat[i]([c_state[i], e_s[i]])
for i in range(2)]
e_outputs = e_o_Concat([e_outputs, e_o])
e_h = [e_h_Concat[i]([e_h[i], h[i]])
for i in range(2)]
e_c = [e_c_Concat[i]([e_c[i], c[i]])
for i in range(2)]
# 文脈状態取得
context_state = [self.context_GRU[i](c_state[i]) for i in range(2)]
#---------------------------------------------------------
# Batch Normalization
#---------------------------------------------------------
encoder_outputs = self.e_o_BatchNorm(e_outputs)
encoder_state_h = [self.e_h_BatchNorm[i](e_h[i])
for i in range(2)]
encoder_state_c = [self.e_c_BatchNorm[i](e_c[i])
for i in range(2)]
context_state = [self.e_s_BatchNorm[i](context_state[i])
for i in range(2)]
return encoder_outputs, encoder_state_h, \
encoder_state_c, context_state
context_decoder.py
# coding: utf-8
# *******************************************************************************
# *
# デコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from keras.layers import Lambda
from keras.layers import Concatenate
from keras.layers import Add
from keras.layers import Reshape
from keras import backend as K
from context_layers import Layer_LSTM
from context_layers import Layer_Dense
from context_attention import Class_Attention
class Class_Decoder :
def __init__(self, data):
self.data = data
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
output_dim = data['output_dim']
n_hidden = data['n_hidden']
dim_cat = data['dim_cat']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_Dense = Layer_Dense(max_value=len_norm, reg_lambda=r_lambda)
class_LSTM = Layer_LSTM(max_value=len_norm, reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
self.decode_LSTM = [class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_name='decode_LSTM'+str(i))
for i in range(2)]
self.decoder_Dense_cat = class_Dense.create_Dense(dim_cat,
dense_activation='softmax',
dense_name='decoder_Dense_cat')
self.decoder_Dense_mod = class_Dense.create_Dense(output_dim,
dense_activation='softmax',
dense_name='decoder_Dense_mod')
self.a = Class_Attention(self.data)
def decoder_nn(self, n_loop, decoder_input, a_output,
encoder_state_h, encoder_state_c,
encoder_outputs, encoder_i_mask,
context_state) :
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_sentences = self.data['n_sentences']
maxlen_e = self.data['maxlen_e']
maxlen_d = self.data['maxlen_d']
vec_dim = self.data['vec_dim']
n_hidden = self.data['n_hidden']
#***********************************************************************
# *
# レイヤー定義 *
# *
#***********************************************************************
#---------------------------------------------------------
# attemtion処理インスタンス
#---------------------------------------------------------
attention = self.a.attention
context_attention = self.a.context_attention
#---------------------------------------------------------
# デコーダー入力とattention結果のconcatenate
#---------------------------------------------------------
a_Concat1 = Concatenate(axis=-1,name='a_Concat1')
#---------------------------------------------------------
# 文脈状態attentionのtanh
#---------------------------------------------------------
c_tanh = Lambda(lambda x: K.tanh(x),name='c_tanh')
#---------------------------------------------------------
# デコーダー入力のタイムスライス
#---------------------------------------------------------
a_decode_input_slice1 = Lambda(lambda x: x[:,0,:],name='slice1')
a_decode_input_slice2 = Lambda(lambda x: x[:,1:,:],name='slice2')
a_Reshape1 = Reshape((1,vec_dim), name='a_Reshape1')
#---------------------------------------------------------
# デコーダー入力の文章単位スライス
#---------------------------------------------------------
e_outputs_slice1 = Lambda(lambda x: x[:, :maxlen_e, :],
name='e_outputs_slice1')
e_outputs_slice2 = Lambda(lambda x: x[:, maxlen_e:, :],
name='e_outputs_slice2')
d_input_slice1 = Lambda(lambda x: x[:, :maxlen_d, :],
name='d_input_slice1')
d_input_slice2 = Lambda(lambda x: x[:, maxlen_d:, :],
name='d_input_slice2')
h_slice1 = Lambda(lambda x: x[:, 0, :],name='h_slice1')
h_slice2 = Lambda(lambda x: x[:, 1:, :],name='h_slice2')
c_slice1 = Lambda(lambda x: x[:, 0, :],name='c_slice1')
c_slice2 = Lambda(lambda x: x[:, 1:, :],name='c_slice2')
mask_slice1 = Lambda(lambda x: x[:, :maxlen_e],name='mask_slice1')
mask_slice2 = Lambda(lambda x: x[:, maxlen_e:],name='mask_slice2')
mask_Reshape = Reshape((1,maxlen_e), name='mask_Reshape')
a_o_slice1 = Lambda(lambda x: x[:, 0, :],name='a_o_slice1')
a_o_slice2 = Lambda(lambda x: x[:, 1:, :],name='a_o_slice2')
a_o_Reshape = Reshape((1,n_hidden), name='a_o_Reshape')
#---------------------------------------------------------
# デコーダーの状態と出力のconcatenate
#---------------------------------------------------------
d_h_Concat = [Concatenate(axis=1,name='d_h_Concat'+str(i))
for i in range(2)]
d_c_Concat = [Concatenate(axis=1,name='d_c_Concat'+str(i))
for i in range(2)]
d_h_Reshape = [Reshape((1,n_hidden), name='d_h_Reshape'+str(i))
for i in range(2)]
d_c_Reshape = [Reshape((1,n_hidden), name='d_c_Reshape'+str(i))
for i in range(2)]
d_o_Concat1 = Concatenate(axis=-1,name='d_o_Concat1')
d_o_Concat2 = Concatenate(axis=-1,name='d_o_Concat2')
d_o_Concat3 = Concatenate(axis=1,name='d_o_Concat3')
d_o_Concat4 = Concatenate(axis=1,name='d_o_Concat4')
a_o_Concat = Concatenate(axis=1,name='a_o_Concat')
#***********************************************************************
# *
# 関数定義 *
# *
#***********************************************************************
#---------------------------------------------------------
# docoder単語単位処理
#---------------------------------------------------------
def decode(d_i_timeslice, a_output, decoder_h, decoder_c,
encoder_outputs, i_mask, context_state):
lstm_input = a_Concat1([d_i_timeslice, a_output])
h_output1, d_h1, d_c1 \
= self.decode_LSTM[0](lstm_input,
initial_state=[decoder_h[0], decoder_c[0]])
h_output2, d_h2, d_c2 \
= self.decode_LSTM[1](h_output1,
initial_state=[decoder_h[1], decoder_c[1]])
h_output = [h_output1, h_output2]
a_o = attention(h_output[-1], encoder_outputs, i_mask)
d_o = [context_attention(i, h_output[i], context_state[i])
for i in range(2)]
#d_output = d_o_Add([d_o[0], d_o[1], d_o[2]])
d_output = d_o_Concat1([d_o[0], d_o[1]])
return a_o, [d_h1, d_h2], [d_c1, d_c2], d_output
#--------------------------------------------------------
# 文章ごとのdecode処理
#--------------------------------------------------------
def main_by_sentence(n_loop,
d_i, encoder_outputs, i_mask, a_out,
e_h, e_c, context_state) :
#ループ前処理
decoder_h = e_h
decoder_c = e_c
a_output = a_out
# メイン処理(ループ)
for i in range(0,n_loop) :
d_i_timeslice = a_decode_input_slice1(d_i)
if i <= maxlen_d-2 :
d_i = a_decode_input_slice2(d_i)
d_i_timeslice = a_Reshape1(d_i_timeslice)
a_o, d_h, d_c, d_o = decode(d_i_timeslice, a_output,
decoder_h, decoder_c,
encoder_outputs, i_mask,
context_state
)
decoder_h = d_h # 次段decoder_state向け出力
decoder_c = d_c # 次段decoder_state向け出力
a_output = a_o # 次段attention処理向け出力
d_output = c_tanh(d_o)
d_output = d_o_Concat2([a_o, d_output])
if i == 0 :
decoder_outputs = d_output
else :
decoder_outputs = d_o_Concat3([decoder_outputs, d_output])
return decoder_outputs, a_output, decoder_h, decoder_c
#--------------------------------------------------------
# 入力データを文章ごとに分割
#--------------------------------------------------------
def slice_data(d_input, e_input, mask_e_input, e_h, e_c, a_out) :
d_i_1 = d_input_slice1(d_input)
d_i_2 = d_input_slice2(d_input)
e_i_1 = e_outputs_slice1(e_input)
e_i_2 = e_outputs_slice2(e_input)
mask_1 = mask_slice1(mask_e_input)
mask_1 = mask_Reshape(mask_1)
mask_2 = mask_slice2(mask_e_input)
h_1 = [h_slice1(e_h[i]) for i in range(2)]
h_2 = [h_slice2(e_h[i]) for i in range(2)]
c_1 = [c_slice1(e_c[i]) for i in range(2)]
c_2 = [c_slice2(e_c[i]) for i in range(2)]
a_o_1 = a_o_slice1(a_out)
a_o_1 = a_o_Reshape(a_o_1)
a_o_2 = a_o_slice2(a_out)
return [d_i_1, d_i_2], [e_i_1, e_i_2], [mask_1, mask_2], \
[h_1, h_2], [c_1, c_2], [a_o_1, a_o_2]
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
#---------------------------------------------------------
# 前処理
#---------------------------------------------------------
d_input = decoder_input
#print('d_input',K.int_shape(d_input))
e_input = encoder_outputs
mask_e_input = encoder_i_mask
e_state_h = encoder_state_h
e_state_c = encoder_state_c
a_out = a_output
#--------------------------------------------------------
# メイン処理
#--------------------------------------------------------
# 文章単位デコード
for i in range(n_sentences) :
# 入力情報を文単位に切り出し
d_i_sliced, e_i_sliced, mask_sliced, \
h_sliced, c_sliced, a_o_sliced \
= slice_data(d_input, e_input, mask_e_input,
e_state_h, e_state_c, a_out)
#print('e_input',K.int_shape(e_input))
d_input = d_i_sliced[1]
e_input = e_i_sliced[1]
mask_e_input = mask_sliced[1]
e_state_h = h_sliced[1]
e_state_c = c_sliced[1]
a_out = a_o_sliced[1]
c_state = [Lambda(lambda x: x[:, :i+1, :])(context_state[j])
for j in range(2)]
# 分単位デコード
d_o, a_o, d_h, d_c \
= main_by_sentence(n_loop, d_i_sliced[0], e_i_sliced[0],
mask_sliced[0], a_o_sliced[0],
h_sliced[0], c_sliced[0], c_state)
# 出力
d_h = [d_h_Reshape[i](d_h[i]) for i in range(2)]
d_c = [d_c_Reshape[i](d_c[i]) for i in range(2)]
if i == 0 :
decoder_outputs = d_o
decoder_a_output = a_o
decoder_h = d_h
decoder_c = d_c
else :
decoder_outputs = d_o_Concat4([decoder_outputs, d_o])
decoder_a_output = a_o_Concat([decoder_a_output, a_o])
decoder_h = [d_h_Concat[i]([decoder_h[i], d_h[i]])
for i in range(2)]
decoder_c = [d_c_Concat[i]([decoder_c[i], d_c[i]])
for i in range(2)]
#--------------------------------------------------------
# 後処理
#--------------------------------------------------------
# 応答文単語出力
decoder_outputs_cat = self.decoder_Dense_cat(decoder_outputs)
decoder_outputs_mod = self.decoder_Dense_mod(decoder_outputs)
return decoder_outputs_cat, decoder_outputs_mod, \
decoder_a_output, decoder_h, decoder_c
context_attention.py
# coding: utf-8
# *******************************************************************************
# *
# デコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from keras.layers import Lambda
from keras.layers import Multiply
from keras.layers import Maximum
from keras.layers import Concatenate
from keras.layers import Reshape
from keras.layers import Dot
from keras.layers import Softmax
from keras import backend as K
from context_layers import Layer_Dense
class Class_Attention :
def __init__(self, data):
self.data = data
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
maxlen_e = data['maxlen_e']
n_hidden = data['n_hidden']
n_context_hidden = data['n_context_hidden']
n_context_attention = data['n_context_attention']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_Dense = Layer_Dense(max_value=len_norm, reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤー定義 *
# *
#***********************************************************************
self.layers = {
#---------------------------------------------------------
# Denseインスタンス
#---------------------------------------------------------
'Dense1' : class_Dense.create_Dense(n_hidden, dense_name='Dense1') ,
'Dense2' : class_Dense.create_Dense(n_hidden, dense_name='Dense2') ,
'c_Dense1' : [class_Dense.create_Dense(n_context_hidden,
dense_name='c_Dense1_'+str(i))
for i in range(3)] ,
'c_Dense2' : [class_Dense.create_Dense(n_context_attention,
dense_name='c_Dense2_'+str(i))
for i in range(3)] ,
#---------------------------------------------------------
# attemtion用softmax(encoder_input可変長対応)
#---------------------------------------------------------
'attention_masking' : Multiply(name='attention_masking') ,
'mask_cast' : Lambda(lambda x: K.cast(x,dtype='float32'),
name='mask_cast') ,
'attention_sum' : Lambda(lambda x: K.sum(x, axis=-1, keepdims=True),
name='attention_sum') ,
'a_epsilon' : Lambda(lambda x: 1 / 2 * x + K.epsilon(),
name='a_epsilon') ,
'a_clip' : Maximum(name='a_clip') ,
'sum_Reciprocal' : Lambda(lambda x: 1 / x, name='sum_Reciprocal') ,
'sum_repeat' : Lambda(lambda x: K.repeat_elements(x, maxlen_e, -1),
name='sum_repeat'),
'sum_divide' : Multiply(name='sum_divide') ,
#---------------------------------------------------------
# attention用
#---------------------------------------------------------
'a_Dot1' : Dot(-1,name='a_Dot1') ,
'a_Softmax' : Softmax(axis=-1,name='a_Softmax') ,
'a_transpose' : Reshape((maxlen_e,1),name='Transpose') ,
'a_Dot2' : Dot(1,name='a_Dot2') ,
'a_tanh' : Lambda(lambda x: K.tanh(x),name='tanh') ,
'a_Concat2' : Concatenate(-1,name='a_Concat2') ,
#---------------------------------------------------------
# 文脈状態係数算出用
#---------------------------------------------------------
'c_Dot1' : [Dot(-1,name='c_Dot1_'+str(i)) for i in range(3)] ,
'c_Softmax' : [Softmax(axis=-1,name='c_Softmax'+str(i))
for i in range(3)] ,
'c_transpose' : [Lambda(lambda x: K.permute_dimensions(x, (0,2,1)),
name='c_Transpose'+str(i))
for i in range(3)] ,
'c_Dot2' : [Dot(1,name='c_Dot2'+str(i)) for i in range(3)] ,
'c_Concat' : [Concatenate(-1,name='c_Concat1_'+str(i))
for i in range(3)]
}
#***************************************************************************
# *
# attemtion用softmax(encoder_input可変長対応) *
# *
#***************************************************************************
def attention_softmax(self, a_o, i_mask) :
#***********************************************************************
# *
# レイヤー *
# *
#***********************************************************************
attention_masking = self.layers['attention_masking']
mask_cast = self.layers['mask_cast']
attention_sum = self.layers['attention_sum']
a_epsilon = self.layers['a_epsilon']
a_clip = self.layers['a_clip']
sum_Reciprocal = self.layers['sum_Reciprocal']
sum_repeat = self.layers['sum_repeat']
sum_divide = self.layers['sum_divide']
a_Softmax = self.layers['a_Softmax']
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
exp_a_o = a_Softmax(a_o)
casted_mask = mask_cast(i_mask)
exp_a_o = attention_masking([exp_a_o, casted_mask])
exp_sum = attention_sum(exp_a_o)
epsilon = a_epsilon(exp_sum)
exp_sum = a_clip([exp_sum, epsilon])
exp_sum = sum_Reciprocal(exp_sum)
exp_sum = sum_repeat(exp_sum)
exp_a_o = sum_divide([exp_a_o, exp_sum])
return exp_a_o
#***************************************************************************
# *
# attention処理 *
# *
#***************************************************************************
def attention(self, h_output, encoder_outputs, i_mask) :
#***********************************************************************
# *
# レイヤー *
# *
#***********************************************************************
Dense1 = self.layers['Dense1']
Dense2 = self.layers['Dense2']
a_Dot1= self.layers['a_Dot1']
a_transpose = self.layers['a_transpose']
a_Dot2 = self.layers['a_Dot2']
a_tanh = self.layers['a_tanh']
a_Concat2 = self.layers['a_Concat2']
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
a_o = Dense1(h_output)
a_o = a_Dot1([a_o, encoder_outputs]) #encoder出力の転置行列を掛ける
a_o = self.attention_softmax(a_o, i_mask) #softmax
a_o = a_transpose(a_o)
a_o = a_Dot2([a_o,encoder_outputs]) #encoder出力行列を掛ける
a_o = a_Concat2([a_o,h_output]) #ここまでの計算結果とGRU出力をconcat
a_o = Dense2(a_o)
a_o = a_tanh(a_o)
return a_o
#***************************************************************************
# *
# context_stateに係数を掛ける *
# *
#***************************************************************************
def context_attention(self, index, h_output, context_state) :
#***********************************************************************
# *
# レイヤー *
# *
#***********************************************************************
c_Dense1 = self.layers['c_Dense1']
c_Dense2 = self.layers['c_Dense2']
c_Dot1 = self.layers['c_Dot1']
c_Softmax = self.layers['c_Softmax']
c_transpose = self.layers['c_transpose']
c_Dot2 = self.layers['c_Dot2']
c_Concat = self.layers['c_Concat']
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
a_o = c_Dense1[index](h_output)
a_o = c_Dot1[index]([a_o, context_state]) #econtext_stateの転置行列を掛ける
a_o = c_Softmax[index](a_o) #softmax
a_o = c_transpose[index](a_o)
a_o = c_Dot2[index]([a_o,context_state]) #context_stateに係数を掛ける
a_o = c_Concat[index]([a_o, h_output]) #ここまでの計算結果とGRU出力をconcat
a_o = c_Dense2[index](a_o)
return a_o
context_layers.py
# coding: utf-8
# *******************************************************************************
# *
# レイヤークラス定義 *
# *
# *******************************************************************************
from keras.layers.core import Dense
from keras.layers.recurrent import LSTM
from keras.layers.recurrent import GRU
from keras.layers.embeddings import Embedding
from keras.layers.normalization import BatchNormalization
from keras.initializers import glorot_uniform
from keras.initializers import uniform
from keras.initializers import orthogonal
from keras.initializers import Ones
from keras import regularizers
from keras.constraints import max_norm
# *******************************************************************************
class Layer_LSTM :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_LSTM(self, units,
lstm_return_state=False, lstm_return_sequences=False,
lstm_go_backwards=False, lstm_name='LSTM') :
layer = LSTM(units, name=lstm_name ,
return_state=lstm_return_state,
return_sequences=lstm_return_sequences,
go_backwards=lstm_go_backwards,
recurrent_regularizer=regularizers.l2(self.reg_lambda) ,
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
kernel_initializer=glorot_uniform(seed=self.seed),
recurrent_initializer=orthogonal(gain=1.0, seed=self.seed),
bias_initializer=Ones(),
dropout=0.5, recurrent_dropout=0.5
)
return layer
# *******************************************************************************
class Layer_GRU :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_GRU(self, gru_units,
gru_return_state=False, gru_return_sequences=False,
gru_go_backwards=False, gru_name='GRU') :
layer = GRU(gru_units, name=gru_name ,
return_state=gru_return_state,
return_sequences=gru_return_sequences,
go_backwards=gru_go_backwards,
recurrent_regularizer=regularizers.l2(self.reg_lambda) ,
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
kernel_initializer=glorot_uniform(seed=self.seed),
recurrent_initializer=orthogonal(gain=1.0, seed=self.seed),
bias_initializer=Ones(),
dropout=0.5, recurrent_dropout=0.5
)
return layer
# *******************************************************************************
class Layer_Dense :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Dense(self, dense_units,
dense_activation=None, dense_name='Dense'):
if dense_activation==None :
act_reg = None
else :
act_reg = regularizers.l1(self.reg_lambda)
layer = Dense(dense_units, name=dense_name,
activation=dense_activation,
kernel_initializer=glorot_uniform(seed=self.seed),
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
bias_regularizer=regularizers.l2(self.reg_lambda) ,
activity_regularizer=act_reg,
)
return layer
# *******************************************************************************
class Layer_BatchNorm :
def __init__(self, max_value=2, reg_lambda=0.01):
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_BatchNorm(self, bn_name='BatchNorm'):
layer = BatchNormalization(axis=-1,
name=bn_name,
beta_regularizer=regularizers.l2(self.reg_lambda) ,
gamma_regularizer=regularizers.l2(self.reg_lambda) ,
beta_constraint=max_norm(max_value=self.max_value, axis=0),
gamma_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
# *******************************************************************************
class Layer_Embedding :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Embedding(self, emb_out_dim, emb_in_dim, emb_name='Embedding'):
layer = Embedding(output_dim=emb_out_dim, input_dim=emb_in_dim,
mask_zero=True, name=emb_name,
embeddings_initializer=uniform(seed=self.seed),
embeddings_regularizer=regularizers.l2(self.reg_lambda),
embeddings_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
context_loss.py
# coding: utf-8
from keras import backend as K
# *******************************************************************************
# *
# 損失関数 *
# *
# *******************************************************************************
def fn_cross_loss(y_true, y_pred, perp_mask, data) :
n_sentences = data['n_sentences']
maxlen_d = data['maxlen_d']
c = 1.5
#print('perp_mask',K.int_shape(perp_mask))
for i in range(n_sentences) :
s = maxlen_d * i
e = maxlen_d * (i+1)
mask_per_sentence = perp_mask[:, s:e]
y_t = y_true[:, s:e, :]
y_p = y_pred[:, s:e, :]
sum_mask = K.sum(mask_per_sentence, axis=-1, keepdims= True)
epsilons = 1 / 2 * y_p + K.epsilon()
cliped = K.maximum(y_p, epsilons)
log_pred = -K.log(cliped)
cross_e = y_t * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = mask_per_sentence * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
avg_per_sentence = sum_entropy / sum_mask
if i < n_sentences - 1 :
avg_per_sentence = avg_per_sentence * c
if i == 0 :
celoss = avg_per_sentence
else :
celoss = K.concatenate([celoss, avg_per_sentence], axis=-1)
return K.mean(celoss)
# *******************************************************************************
# *
# perplexity *
# *
# *******************************************************************************
def fn_perplexity(y_true, y_pred, perp_mask, data) :
n_sentences = data['n_sentences']
maxlen_d = data['maxlen_d']
i = n_sentences -1
s = maxlen_d * i
e = maxlen_d * (i+1)
mask_per_sentence = perp_mask[:, s:e]
y_t = y_true[:, s:e, :]
y_p = y_pred[:, s:e, :]
sum_mask = K.sum(mask_per_sentence, axis=-1, keepdims= True)
epsilons = 1 / 2 * y_p + K.epsilon()
cliped = K.maximum(y_p, epsilons)
log_pred = -K.log(cliped)
cross_e = y_t * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = mask_per_sentence * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
celoss = sum_entropy / sum_mask
perplexity = K.exp(celoss)
return K.mean(perplexity)
# *******************************************************************************
# *
# 評価関数 *
# *
# *******************************************************************************
def fn_accuracy(y_true, y_pred, perp_mask, data) :
n_sentences = data['n_sentences']
maxlen_d = data['maxlen_d']
i = n_sentences - 1
s = maxlen_d * i
e = maxlen_d * (i+1)
mask = perp_mask[:, s:e]
y_t = y_true[:, s:e, :]
y_p = y_pred[:, s:e, :]
y_pred_argmax = K.argmax(y_p, axis=-1)
y_true_argmax = K.argmax(y_t, axis=-1)
n_correct = K.abs(y_true_argmax - y_pred_argmax)
n_correct = K.sign(n_correct)
n_correct = K.ones_like(n_correct) - n_correct
n_correct = K.cast(n_correct, dtype='int32')
n_correct = n_correct * mask
n_correct = K.cast(K.sum(n_correct), dtype='float32')
n_total = K.cast(K.sum(mask), dtype='float32')
return n_correct / n_total
context_train.py
# coding: utf-8
from keras.utils import np_utils
import numpy as np
import sys
import math
import time
import os
class Color:
BLACK = '\033[30m'
RED = '\033[31m'
GREEN = '\033[38;5;10m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
PURPLE = '\033[35m'
CYAN = '\033[38;5;14m'
WHITE = '\033[37m'
END = '\033[0m'
BOLD = '\038[1m'
UNDERLINE = '\033[4m'
INVISIBLE = '\033[08m'
REVERCE = '\033[07m'
# *******************************************************************************
# *
# 訓練/テスト共通関数 *
# *
# *******************************************************************************
def train_test_main(kind, e_train, d_train, t_train, params, data) :
model = params['model']
save_model = params['save_model']
batch_size = params['batch_size']
emb_param = params['emb_param']
output_dim = data['output_dim']
dim_cat = data['dim_cat']
#損失関数、評価関数の平均計算用リスト
list_loss = []
list_loss_cat =[]
list_loss_mod =[]
list_perplexity_cat =[]
list_accuracy_cat =[]
list_perplexity_mod =[]
list_accuracy_mod =[]
s_time = time.time()
row=d_train.shape[0]
n_batch = math.ceil(row/batch_size)
for i in range(0,n_batch) :
s = i*batch_size
e = min([(i+1) * batch_size,row])
e_on_batch = e_train[s:e,:]
d_on_batch = d_train[s:e,:]
# ラベルテンソルをカテゴリビットごとにスライスする
t_on_batch = t_train[s:e,:,:]
t_on_batch_cat = np_utils.to_categorical(t_on_batch[:,:,0], dim_cat)
t_on_batch_mod = np_utils.to_categorical(t_on_batch[:,:,1], output_dim)
if kind == 'train' :
result = model.train_on_batch([e_on_batch, d_on_batch],
[t_on_batch_cat, t_on_batch_mod])
else :
result = model.test_on_batch([e_on_batch, d_on_batch],
[t_on_batch_cat, t_on_batch_mod])
list_loss.append(result[0])
list_loss_cat.append(result[1])
list_loss_mod.append(result[2])
list_perplexity_cat.append(result[3])
list_accuracy_cat.append(result[4])
list_perplexity_mod.append(result[5])
list_accuracy_mod.append(result[6])
elapsed_time = time.time() - s_time
if i % 100 == 0 :
sys.stdout.write("\r"+" "
+" "
+" "
+" "
+" ")
sys.stdout.flush()
if kind == 'train' :
ctl_color = Color.CYAN
else :
ctl_color = Color.GREEN
sys.stdout.write(ctl_color + "\r"+str(e)+"/"+str(row)+" "
+ str(int(elapsed_time))+"s "+"\t"
+ "{0:.4f}".format(np.average(list_loss))+"\t"
+ "{0:.4f}".format(np.average(list_loss_cat))+"\t"
+ "{0:.4f}".format(np.average(list_loss_mod))+"\t"
+ "{0:.4f}".format(np.average(list_perplexity_cat))+"\t"
+ "{0:.4f}".format(np.average(list_accuracy_cat))+"\t"
+ "{0:.4f}".format(np.average(list_perplexity_mod))+"\t"
+ "{0:.4f}".format(np.average(list_accuracy_mod))
+ Color.END)
sys.stdout.flush()
if i % 100 == 99 and kind == 'train':
save_model.save_weights(emb_param)
del e_on_batch,d_on_batch,t_on_batch, \
t_on_batch_cat, t_on_batch_mod
print()
return np.average(list_loss), \
np.average(list_perplexity_mod), \
np.average(list_accuracy_mod)
# *******************************************************************************
# *
# 学習 *
# *
# *******************************************************************************
def train(model, save_model, e_input, d_input, target,
batch_size, epochs, emb_param, data) :
#***************************************************************************
# *
# train_on_batch処理 *
# *
#***************************************************************************
def on_batch(e_input, d_input, target, batch_size, emb_param) :
n_split = int(d_input.shape[0]*0.1)
e_val = e_input[:n_split,:]
d_val = d_input[:n_split,:]
t_val = target[:n_split,:,:]
e_train = e_input[n_split:,:]
d_train = d_input[n_split:,:]
t_train = target[n_split:,:,:]
params = {'model' : model,
'save_model': save_model,
'batch_size': batch_size,
'emb_param' : emb_param
}
_, _, _ = train_test_main('train', e_train, d_train, t_train,
params, data)
save_model.save_weights(emb_param)
#perplexity評価
return train_test_main('test', e_val, d_val, t_val, params, data)
#***************************************************************************
# *
# メイン処理 *
# *
#***************************************************************************
if os.path.isfile(emb_param) :
save_model.load_weights(emb_param) #埋め込みパラメータセット
#elif n_sentences > 1 :
# set_layer_weights()
print ('number of params :', model.count_params())
#=========================================================
# train on batch
#=========================================================
#row=d_input.shape[0]
loss_bk = 10000
perplexity_bk = 10000
accuracy_bk = 0
patience = 0
print(Color.CYAN,model.metrics_names[0]+" "+model.metrics_names[1]+" "
+model.metrics_names[2]+" "+model.metrics_names[3]+" "
+model.metrics_names[4]+" "+model.metrics_names[5]+" "
+model.metrics_names[6] ,
Color.END)
for j in range(0,epochs) :
print(Color.CYAN,"Epoch ",j+1,"/",epochs,Color.END)
loss, perplexity_mod, accuracy_mod \
= on_batch(e_input, d_input, target, batch_size, emb_param)
#-----------------------------------------------------
# EarlyStopping
#-----------------------------------------------------
if j == 0 or (loss <= loss_bk and
perplexity_mod <= perplexity_bk and
accuracy_mod >= accuracy_bk):
loss_bk = loss
perplexity_bk = perplexity_mod
accuracy_bk = accuracy_mod
patience = 0
elif patience < 3 :
patience += 1
else :
print('EarlyStopping')
break
return loss, perplexity_mod, accuracy_mod
5. 訓練データ生成
5−1. 日本語コーパスの品詞分解と辞書作成
前回記事の3-1〜3-5節を実行してください。以下のファイルが出来上がります。
| ファイル名 | 説明 |
|---|---|
| indices_word.pickle | インデックス→単語変換辞書 |
| word_indices.pickle | 単語→インデックス変換辞書 |
| indices_freq.pickle | インデックス→出現頻度変換辞書 |
| freq_indices.pickle | 出現頻度→インデックス変換辞書 |
| mat_urtext.npy | 単語インデックス配列 |
| words.pickle | 単語一覧 |
5−2. 文脈情報生成処理
単語インデックス配列(すべての文が1列につながった1次元配列)から、引数で指定した系列長以下の文を抽出し、次元が(文数, 系列長)の配列を生成します。その際、それぞれの文が、元のwikipedia説明項目において何番目の文であったかを表す情報も生成します。
実行コマンド形式は以下のとおりです。引数は系列長(整数)です。なお、実行前に、実行フォルダ直下にdataという名称のフォルダを作成しておいてください。
>> python 0500_generate_context_data.py 系列長
本稿では、系列長に35を指定しました。
5−3. 訓練データ生成処理
訓練データ(エンコーダインプット、デコーダインプット、およびラベル)を生成します。どの順番の出力文を生成するかによって、ニューラルネットワークが異なりますので、訓練データもそれぞれ別のものを準備します。番数は引数で指定します。
実行コマンド形式は、以下のとおりです。引数は、出力文番数(整数)です。
>> python 0600_generate_training_data.py 出力文番数
なお、文の最大生成数はプログラム固定であり、今回の実装では4にしてあります。出力文番数は4までの値を指定してください。
6. 訓練
訓練に先立って、埋め込み次元数と隠れ層次元数を決める必要が有ります。本稿では、以下の値を指定しています。
| 項目名 | 値 |
|---|---|
| 埋め込み次元数 | 400 |
| 隠れ層次元数 | 600 |
以下のプログラムを実行し、これらを定義したファイルdim.picleを事前に作成しておいてください。
import pickle
import math
with open('words.pickle', 'rb') as ff :
words = pickle.load(ff)
input_dim = len(words)
output_dim = math.ceil(len(words) / 8)
n_hidden =600
vec_dim = 400
with open('dim.pickle', 'wb') as f :
pickle.dump([n_hidden, input_dim, vec_dim, output_dim] , f)
ここまでの準備が終了したら、以下のコマンドで訓練を実行します。引数は、エポック数、バッチサイズ、出力文番数(いずれも整数)の3つです。
>> python 1000_seq2seq_wiki_context.py エポック数 バッチサイズ 出力文番数
出力文の順番ごとにニューラルネットワークが別になっているので、すべての番数(今回の実装では1から4)で訓練を実行してください。
なお、訓練には、GPU環境でも結構時間がかかります。
7. 文章生成
以下のコマンドを実行します。引数は出力文番数です。
>> python 2000_gen_sentence.py 出力文番数
入力プロンプトが現れますので、最初の文を入力すると、引数で指定した数だけ、続きの文が出力されます。
以下は、最初の文として「国境の長いトンネルを抜けると雪国だった。」を入力したときの実行結果です。
>> 国境の長いトンネルを抜けると雪国だった。
この駅は、駅の南側に位置していた。
駅舎は構内の西側に位置し、ホームは線路の東側(名寄方面に向かって左手側)に存在した。
ホームは線路の西側に位置し、ホーム中央部分に接していた。
分岐器を持たない棒線駅となっていた。
結構、それらしい文が生成されています。「棒線駅」など、さすがはWikipediaです。しかし、よく見ると、文間で内容に矛盾が有ったりします。
コマンドを終了させるには、「q」を入力します。
8. おわりに
以上、文脈状態を利用した文章生成について記述しました。本稿でのロジックは複雑でかつ、メモリを大量に必要としますが、その割には今一歩の感が有ります。
文脈状態はもともと、対話における文脈の連続性を表現するために考案されたものなので、連続文生成にはあまり向かないのかも知れません。もう少し別の方法で改善できないか、検討してみることにします。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2020/11/26 | - | 初版 |