はじめに
この記事はSLP KBIT Advent Calendar 20227日目の記事です
こんにちは、あっという間に1年が過ぎてしまいましたね~
今回は自然言語処理という分野について説明できたらなと思っています。
最近話題になっている「ChatGPT」も自然言語処理を用いたAIです。
面白い分野なのでこの記事を通して興味を持ってもらえると嬉しいです。
自然言語処理とは
自然言語処理とは名前の通り自然言語をコンピュータに処理する技術の総称です。
プログラミング言語などを「人工言語」と呼ぶのに対して、我々が使用している言語(日本語や英語)などを「自然言語」と呼ばれます。
つまり、日本語や英語など我々が使っている言葉をコンピュータに処理、理解させる技術の総称です。
応用例として以下のものがあげられます。
- 機械翻訳
- 仮名漢字変換
- 情報探索
- 対話システム など
機械翻訳などはGoogle翻訳やDeepLでなじみ深いのではないでしょうか。
僕もこれらにはいつもお世話になっています(笑)
自然言語処理の処理技法
今回は日本語にフォーカスして話を進めていこうと思います。
日本語の文章のままだとコンピュータは理解してくれません。
コンピュータが言語を理解するために以下のステップが必要だと考えられています。
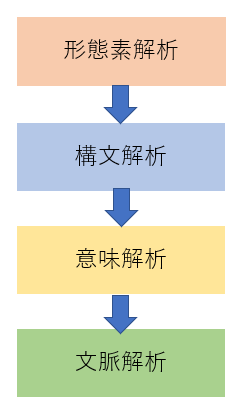
下に進んでいくほど処理が難解になってきます。
形態素解析
文章を単語に分割していく処理です。この分割した単語のことを「形態素」と呼びます。
あらかじめ作成された辞書と形態素分析器を用いて形態素に分割しています。
代表的な辞書としてIPA辞書やUnidic、NEologdなどがあり、代表的な形態素解析器としてMeCabやJuman++,Ochasenなどがあります。
では、実際にプログラム上で形態素解析を行ってみましょう。
今回はMeCabとIPA辞書を用いて実装します。
import MeCab
text = "今日の天気は晴れです"
mecab = MeCab.Tagger()
print(mecab.parse(text))
実行結果として、形態素とその形態素の品詞や読み方などが解析され表示されます。
>> python morpheme.py
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
の 助詞,連体化,*,*,*,*,の,ノ,ノ
天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
晴れ 名詞,一般,*,*,*,*,晴れ,ハレ,ハレ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
EOS
辞書や形態素解析器を変えると実行結果が変わってきます。
辞書や形態素解析器によって、固有名詞を認識するしないなど分割方法がが分かれてくるので、タスクによって使い分けるのがいいと考えられます。
構文解析
形態素解析を行った後、形態素同士の関係性を解析します。
今回は解析方法として、よく用いられる係り受け解析(依存構造解析)について紹介します。
例えば先ほど形態素解析した「今日の天気は晴れです」という文章を京都大学が公開している構文解析器KNPで係り受け解析してみると以下のようになります。
今日の──┐ <体言>
天気は──┐ <体言>
晴れです<体言><用言:判><格解析結果:ガ/天気;ガ2/->
EOS
先ほどの文章は比較的簡単な文章で行いました。
では「目が黒くて大きい猫」という文章だとどうでしょう?
この文章は2パターンに分かれると思います。
- 「黒くて」と「大きい」が「目」にかかっているパターン
- 「黒くて」が目に「大きい」が猫にかかっているパターン
このように文章によって人間でも意見が分かれそうな係り受けパターンがあるというところが構文解析の難しい理由です。
意味解析・文脈解析
文の意味、文脈をコンピュータに理解させるための解析です。
大体の応用タスクがこれらの解析をもとに作られています。
意味解析、文脈解析の一部として照応解析、固有表現抽出があります。
照応解析は代名詞がどの名詞を表しているのかを明確にする解析であり、固有表現抽出は文章中から固有名詞を抽出し、固有名詞がどのような意味、分類かを判断する解析です。
例えば、「りんご」という単語のみではがりんごが食べ物であるということをコンピュータは判断できません。なので、りんごが食べ物と判断できるような処理を入れる必要があり、その処理のことを固有表現抽出と呼びます。
意味解析・文脈解析を行う方法としてルールに基づいて処理を行う「ルールベース型」と統計的に処理をする「統計型」ニューラルネットワークを用いて処理を行う「ニューラル型」があります。
今回はニューラル型のアルゴリズムについていくつか紹介しようと思います。
代表的なニューラル型言語モデル
Word2vec
2015年ほどに発表された現代の言語処理の考え方の基礎になっている「分布仮説」を用いたモデルです。分布仮説は「単語の意味はその周辺に出てくる単語によって決定される」と呼ばれるもので、word2vecはこれを利用して周りの単語ベクトルによって対象の単語ベクトルを決定するといったモデルです。
詳しい内容は実装は長くなるのでこちらにまとめました。 興味がある方は是非読んでみてください。
RNN・LSTM
RNN、LSTMは一般的に再起型ニューラル言語モデルと呼ばれます。
再帰ニューラル言語モデルは以下のように対象の入力単語ベクトルとその前の単語ベクトルから出力を生成しています。
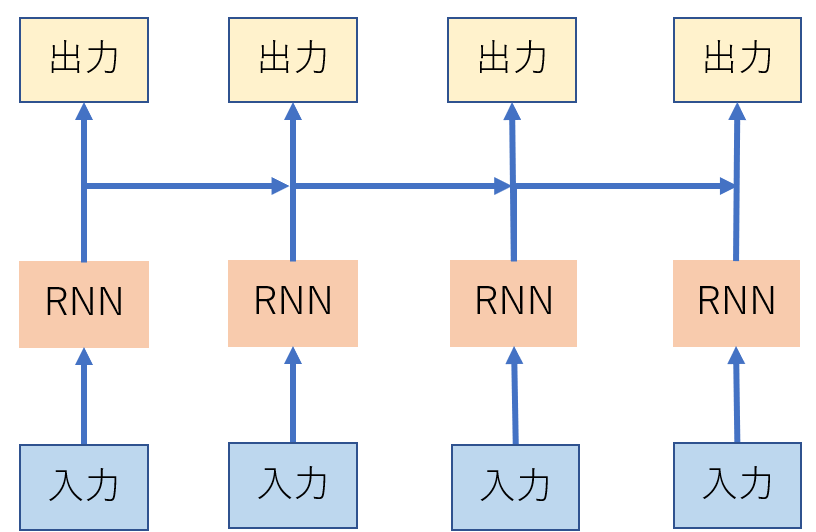
RNNは前のベクトルの特徴量をすべて取り入れて対象の単語のベクトルを生成していましたが、LSTMでは長期記憶と短期記憶をもとに、必要な特徴量分のみを取り入れて生成するという方法をとっています。
この方法で翻訳や、文章生成等の精度はある程度精度は上がりました。しかし、再帰ニューラル言語モデルには長文になると精度が低下してしまうという課題がありました。
Transfromer
再帰ニューラル言語モデルで挙げられた課題を解決するモデルとして紹介されました。翻訳タスクで高い性能を出したモデルです。 なかなか複雑なモデルですが、僕は作って理解する Transformer / Attention を参考にしましたので、詳しく知りたい方は是非読んでみてください。
BERT・GPT
BERT・GPTは事前学習済みモデルをファインチューニング(転移学習)することによって、様々なタスクに対応させる汎用型モデルとなってます。事前学習では大量のラベルなしのテキストを学習させることで文章の構文、単語の意味をベクトルとして特徴抽出を行います。そのあとファインチューニングでそれぞれのタスクに合わせた特徴量に変換していくというモデルです。BERTはTransformerのEncoder部分を用いており、GPTではDecoder部分を用いています。事前学習済みモデルのメリットとして、1つのタスクを学習するにおいて何万ものデータが必要でしたが、事前学習済みモデルで俯瞰的な特徴量抽出ができているので、数千ほどのデータ量でもそれなりの精度が出るモデルが作成できるようになったことがあげられます。
参考になった本
最期に僕が自然言語処理を勉強するにおいて、よかったと思った本を紹介しようと思います
-
IT Text 自然言語処理の基礎
自然言語処理について基礎から最近のモデルの仕組みまで詳しく説明されています。今回の記事の執筆においても参考にしました。 - ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 - オライリージャパン
-
ゼロから作るDeep Learning ❷ ―自然言語処理編 - オライリージャパン
近年の言語処理モデルはニューラル型モデルがほとんどであるので、ニューラルネットワークについての知識が必須になってきています。なのでこの2冊でニューラルネットワークについての知識を学びました。実装しながら体系的に学べるので、理解しやすいと思います。
最後に
ニューラル型モデルの説明に関しては文量上概要のみとなったり、最後の項目も参考書の紹介などお粗末な記事になってしまいましたが、この記事を今年の締めくくりとさせていただきます。
また、最初に紹介した「ChatGPT」は現段階ではGoogleアカウントがあれば無料で使えるので興味のある方はぜひ使ってみてください。
最後まで読んでくださった方ありがとございました。では皆さんよいお年を~