はじめに
この記事はSLP KBIT Advent Calendar 20218日目の記事です。
最近は翻訳やAIチャットボットの精度が高くて驚きですよね。
自分も自然言語処理関連で何かやりたいなと思いword2vecを実装してみました。
word2vecとは?
word2vecについて簡単に説明しておこうと思います。
まず前提としてword2vecは文章において「単語の意味はその周辺に出てくる単語によって決定される」という考え方が元となっています。
word2vecとは文章を単語ごとに分解し、その単語をベクトル化してベクトルによって単語と単語の関係付けを可能にするといった技術です。
またword2vecでもCBoWとSkip-gramと2つの種類があります。
CBoW
CBoWは一つの対象の単語を周辺の単語によって予測します。
例えば「私は〇を飼っている」という文章があった場合、「犬」や「猫」など文章の〇のところに入っても意味が成り立つような単語を予測できるような学習を行います。
Skip-gram
Skip-gramはCBowと逆の学習方法で一つの単語から周辺の単語を予測します。
例えば「私は犬を飼っている」という文章が学習データに入っているとすると、犬と入力すると「私、は、を、飼っ、て、いる」と文章の周辺単語が予測として出力されるような学習を行います。
簡単な説明となっているのでword2vecの主な概要だけとなっています。
より詳しいく知りたい方は絵で理解するWord2vecの仕組みを読んでみてください。
word2vecの実装
今回は対象の単語と同じ分類の単語を取り出したり単語と単語の足し算、引き算をしてみました。その前になぜこんなことが可能なのかだけを少し説明しておこうと思います。(わかる人は読み飛ばしちゃってください)
なぜできるのか?
先ほどのword2vecの説明だと文章の穴抜き問題が解けるという説明だったと思います。ではなぜ分類分けできるのか具体例を交えながら説明します。
「私は〇を飼っている」
このような文章の〇に入る言葉として犬また猫など動物が入るだろうと予想できます。そしてword2vecの説明で言ったように単語を文章の周辺単語によって単語をベクトル化します。つまり〇に入りそうな単語は単語の使われ方も似ているとベクトルの値も類似します。
このような仕組みでベクトルの値を決定していることによって単語の分類、計算が可能になっています。ちなみに単語のベクトルがどれだけ似ているかはコサイン類似度という計算で求められています。
環境
・Python3
・Visual Studio Code
・Python3のライブラリ
ライブラリは以下の通りです
import pandas as pd
import os
import glob
import pathlib
import re
from janome.tokenizer import Tokenizer
from gensim.models import word2vec
import matplotlib.pyplot as plt
データセットの作成
今回はデータセットとしてlivedoorニュースコーパスを使用しています。まずはこの文章を抽出して不要な文章を除いていきます。
text_dataでファイル内にある記事の本文を取り出しpandasのデータフレームでまとめています。
import pandas as pd
import os
import glob
import pathlib
import re
from janome.tokenizer import Tokenizer
def text_data(path):
p_temp = pathlib.Path(path)
article_list = []
# フォルダ内のテキストファイルを全てサーチ
for p in p_temp.glob('**/*.txt'):
# 第二階層フォルダ名がニュースサイトの名前になっているので、それを取得
pathname = os.path.split(p)
media = pathname[0]
file_name = pathname[1]
# テキストファイルを読み込む
with open(p, 'r', encoding='utf-8') as f:
# テキストファイルの中身を一行ずつ読み込み、リスト形式で格納
article = f.readlines()
# 不要な改行等を置換処理
article = [re.sub(r'[\n \u3000]', '', i) for i in article]
# ニュースサイト名・記事タイトル・本文の並びでリスト化
article_list.append([media,article[2], ''.join(article[3:])])
article_df = pd.DataFrame(article_list, columns=['名前', 'タイトル', '本文'])
return article_df
cutsentenceで不要な文字、記号などを取り除き1文ずつに分割しリストに入れています。
今回はアルファベットも取り除きました。
def cutsentence(s):
#全角スペースなどを削除
s.strip()
#半角数字,半角英字、全角英字を削除
s=re.sub(r'[0-9]','',s)
s=re.sub(r'[a-z]','',s)
s=re.sub(r'[A-Z]','',s)
s=re.sub(r'[A-Z]','',s)
s=re.sub(r'[a-z]','',s)
#不要な記号を削除
code_regex = re.compile('[!"#$%&\'\\\\()*+,-./:;<=>?дД⇒┐‾♯@[\\]^○◯♂♡♪■〝〟,.┃┗┏━_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥★¥±°–—•″⇔∀∞≒≪≫①②③④⑤│┌^]')
s = code_regex.sub('', s)
#一文ずつ取り出してリスト化
text_data = s.split('。')
return text_data
文章をword_listで形態素解析を行い単語単位で分解していき接続詞と記号以外をリストに入れます。
def word_list(word):
t = Tokenizer()
word_data = []
#形態素解析で単語ごとに分解する
for token in t.tokenize(word):
surface = token.surface #単語
speech = token.part_of_speech.split(',')[0] #品詞
if speech != '接続詞' and speech != '記号':
#取り出した単語と品詞をリスト化
word_data.append([surface, speech])
return word_data
これでデータセットは完了です。
word2vecで学習
今回はgensim.modelをつかってCBoWとSkip-gramの両方の方法で学習しました。
from gensim.models import word2vec
def word2vc(word_list):
#word2vecの引数
#sg(=0の時CoBW=1の時Skip-gram),sentense(学習させる文章),vecter_size(次元数),min_count(最小単語回数),epochs(学習率)
model = word2vec.Word2Vec(sg=1,sentences=word_list,vector_size=200,min_count=5, window=5, epochs=200)
#学習モデルをファイルに保存
model.save("../word2vec_model/article_sg.model")
学習結果
学習したモデルから入力の単語に近しいベクトルを持つ単語を棒グラフによって出力、可視化します。
コードはこんな感じ
from gensim.models import word2vec
import matplotlib.pyplot as plt
#モデルファイルの読み込み
model = word2vec.Word2Vec.load("../word2vec_model/article_sg_3.model")
#モデル内のすべての単語を取得
words = model.wv.index_to_key
pro = []
x_label = [x for x in range(10)]
#対象単語入力
key = input()
for w in words:
if w == key:
continue
#対象単語との近さの割合を検出
similer_percent = model.wv.similarity(key, w)*100
pro.append((w, similer_percent))
#上から順になるように並び替え
re = sorted(pro, reverse=True, key=lambda x: x[1])
#ラベルの作成
word_labels = [x[0] for x in re]
height = [x[1] for x in re]
# 日本語表示のためのフォント指定
plt.rcParams['font.family'] = "MS Gothic"
#棒グラフの作成
#上位10個を表示
plt.bar(x_label, height[:10], width=0.5)
plt.xticks(x_label, word_labels[:10], fontsize=5)
plt.show()
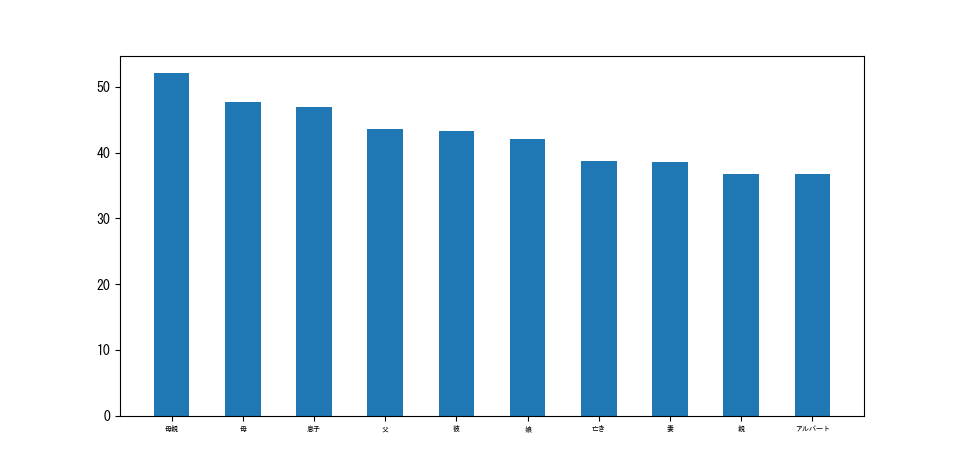
以下が「父親」という単語にした結果です。CBoWとSkip-gramの両方で試してみました
・CBoW
・Skip-gram
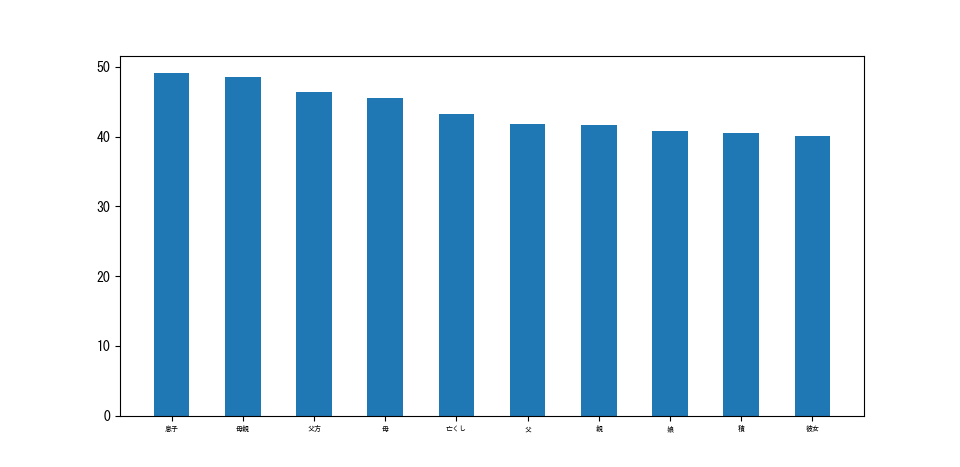
若干CBoWの方が良い感じの結果になっていますね。
学習データをもっと大きくしたり次元数や学習率をより最適なものにするとより精度が上がるかも…
単語のベクトルを散布図で可視化
次は散布図で学習した単語の全体を可視化します
コードはこんな感じ
from gensim.models import word2vec
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
##TSNEで次元の削減
tsne = TSNE(n_components=2, random_state=0)
#モデルの読み込み
model = word2vec.Word2Vec.load("../word2vec_model/article_sg_3.model")
#モデル内にある単語を全て取得
words = model.wv.index_to_key
key=input()#キー単語
words_label = []
vector = []
for w in range(len(words)):
words_label.append(words[w])
#単語のベクトルを取得
word_vector = model.wv.get_vector(words[w])
vector.append(word_vector)
#ベクトルを2次元ベクトルに変換
vector = tsne.fit_transform(vector)
x_vector = [x[0] for x in vector]#x座標
y_vector = [x[1] for x in vector]#y座標
#日本語表示のためのフォント指定
plt.rcParams['font.family'] = "MS Gothic"
fig, ax = plt.subplots()
#散布図作成
sc = plt.scatter(x=x_vector, y=y_vector, s=5)
for i in range(len(words_label)):
#キー単語のみ点の色を赤に変更する
if key==words_label[i]:
ax.scatter(x_vector[i],y_vector[i],c="red")
#単語ラベル表示の設定
annot = ax.annotate("", xy=(0, 0), xytext=(20, 20), textcoords="offset points",
bbox=dict(boxstyle="round", fc="w"),
arrowprops=dict(arrowstyle="->"))
#通常は隠しておく
annot.set_visible(False)
#マウスイベント
def update_annot(ind):
i = ind["ind"][0]
pos = sc.get_offsets()[i]
annot.xy = pos
text = words_label[i]
annot.set_text(text)
#マウスが対象の座標を指しているか判定
def hover(event):
vis = annot.get_visible()
if event.inaxes == ax:
cont, ind = sc.contains(event)
if cont:
update_annot(ind)
annot.set_visible(True)
fig.canvas.draw_idle()
else:
if vis:
annot.set_visible(False)
fig.canvas.draw_idle()
#マウスイベント
fig.canvas.mpl_connect("motion_notify_event", hover)
plt.show()
ラベルはマウスが点を指すと表示するように設定しています。
こちらもCBoWとSkip-gramの両方で実装してみましょう。
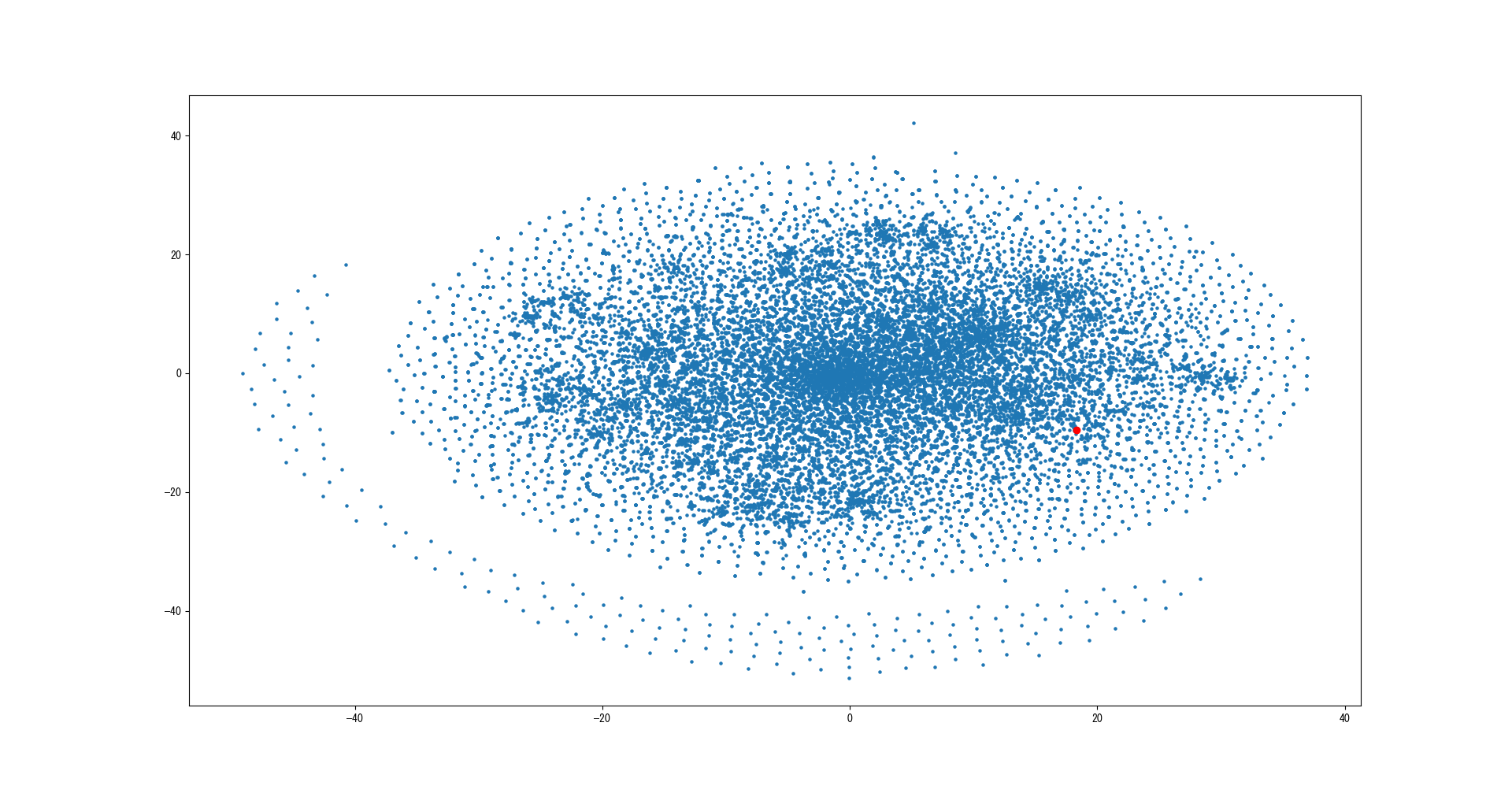
keyを「父親」に設定して実行した結果がこちらです。
・CBoW
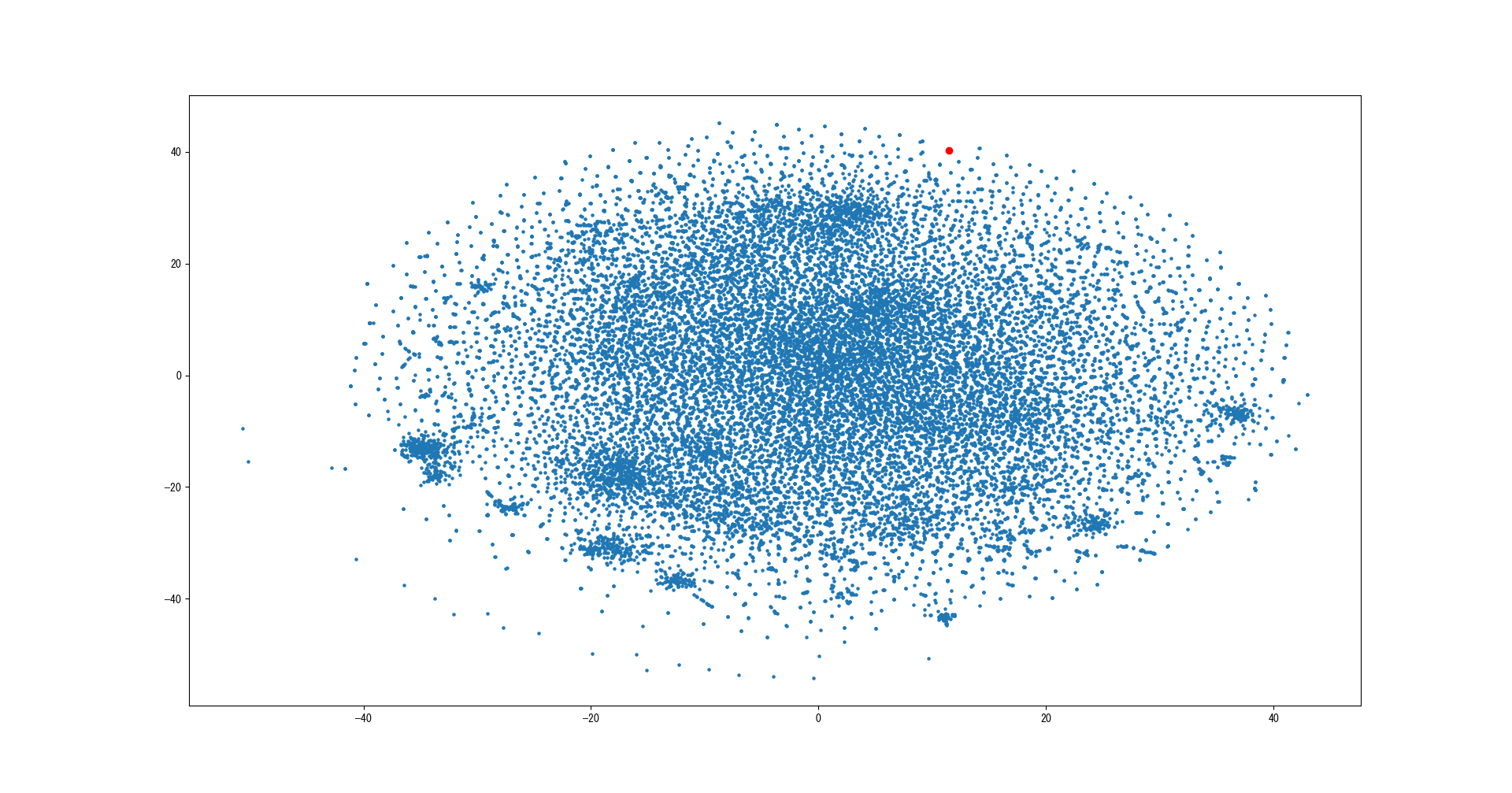
赤点が「父親」の単語のベクトルです。ものすごい真ん中に密集していますね(汗)。では拡大してみましょう。
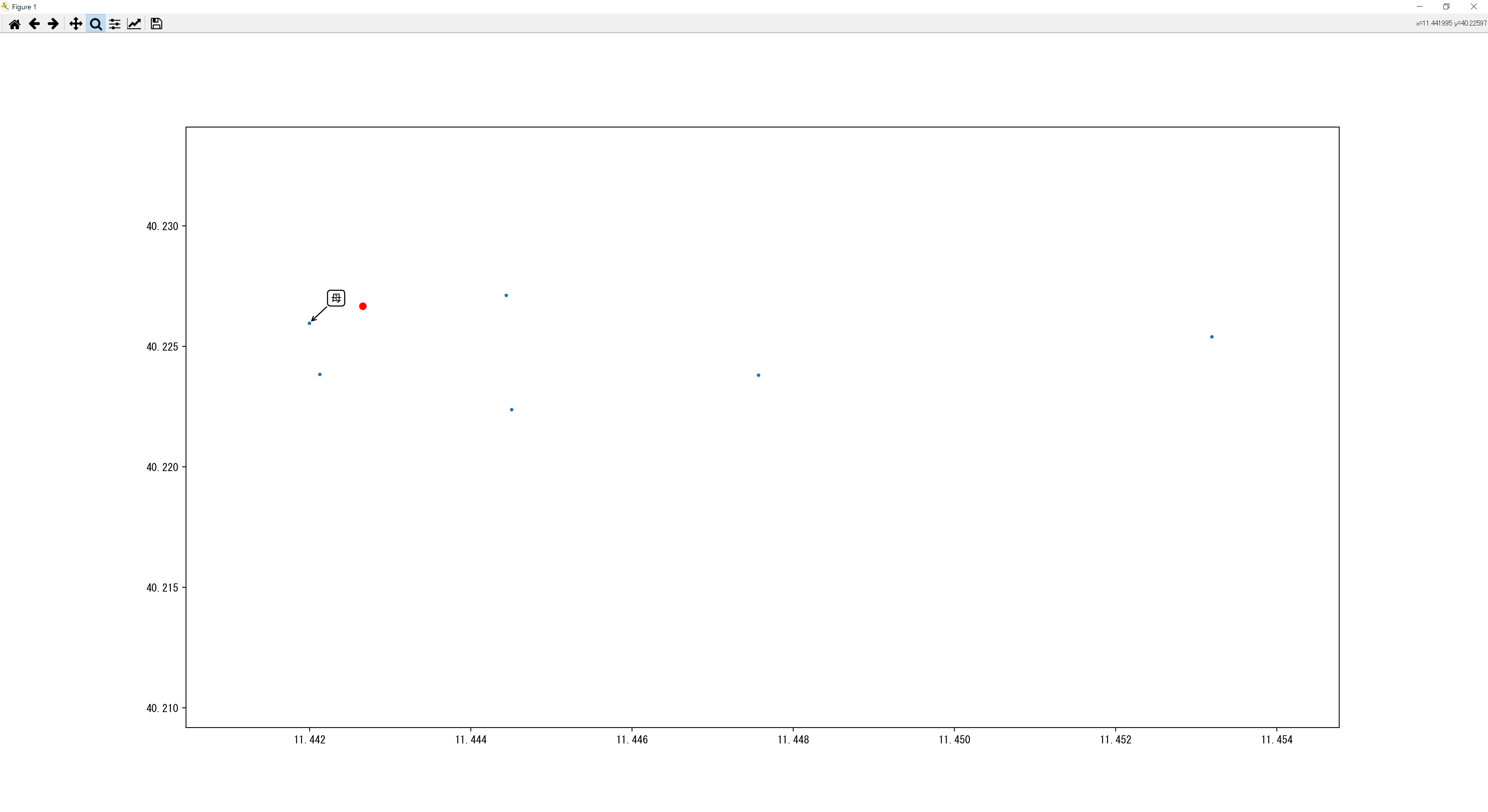
父親に一番近い単語が母となっているので正しく表示されてそう。CBoWの棒グラフの方も上の図はCBoWで学習したモデルを使用しています。ではSkip-gramの方はどうなるかもやってみようと思います。
こちらがSkip-gramの方の結果です。
・Skip-gram
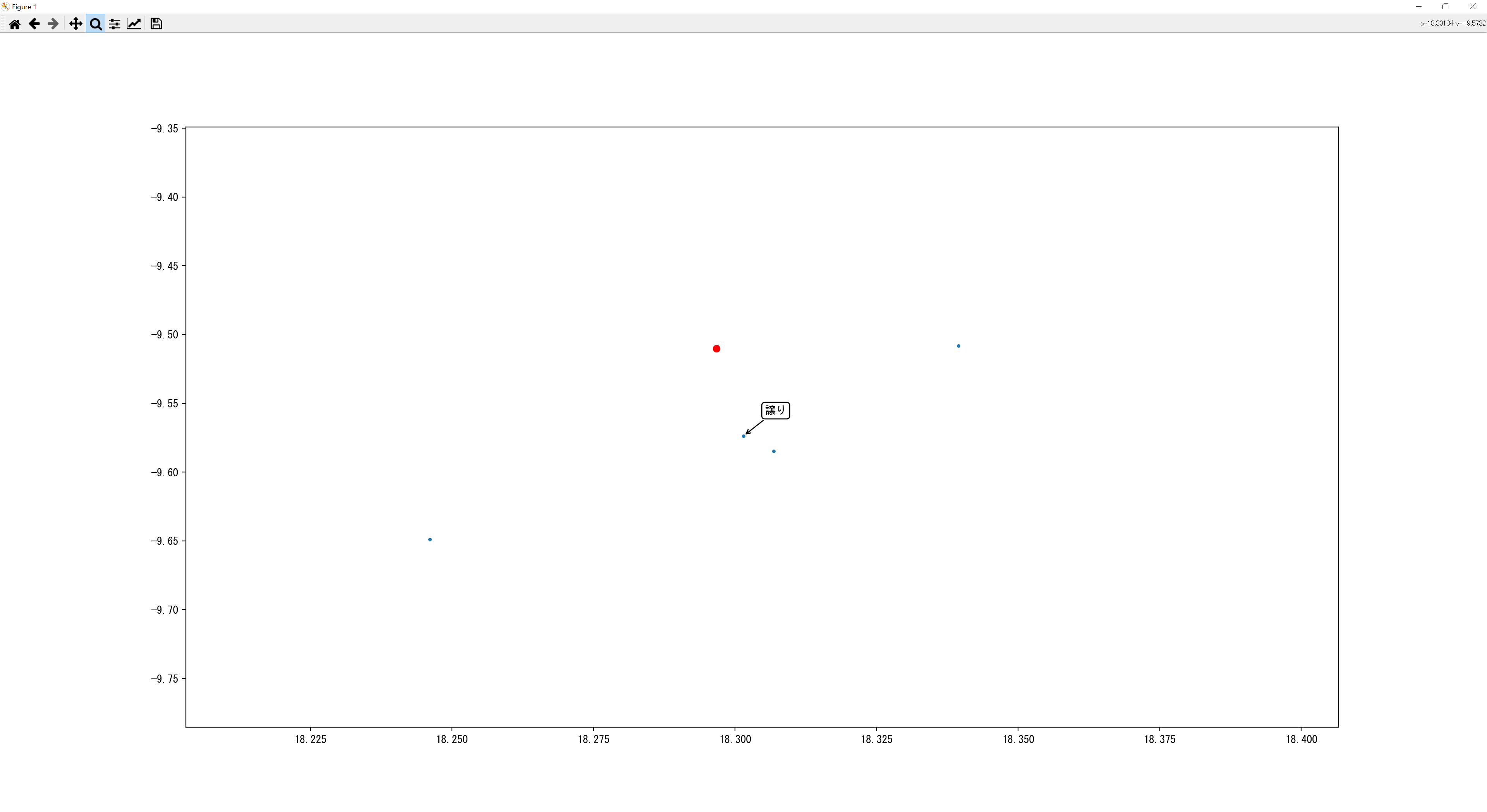
Skip-gramの方は棒グラフと比較するといい結果になってません。おそらくCBoWのほうは成功していたので次元削減の所でノイズが入ったのかな?
しかし他の単語でやってみたところ似ている意味が固まっていたのである程度可視化は成功してそうです。
まとめ
実装結果はそれなりにはくみ取れている結果となっていますが、やはりどうしても予想外の結果になったりノイズが混ざってしました。おそらく学習データによって変わってくると思うのでまた別のデータで実装してみるのも面白そうですね。次回は自然言語処理の続きとして文章生成をやってみようと思います。
最後まで記事を読んでくださりありがとうございました。
説明で不明な点や間違っている部分があればお知らせください。(おそらくありそう…)
コードはGithubにあげてます。
https://github.com/ganbon/word2vec/tree/main
参考文献
絵で理解するWord2vecの仕組み
matplotlib で散布図 (Scatter plot) を描く
Matplotlibでマウスオーバーすると対応する画像を表示させる
【Python】Word2Vecの使い方
など