はじめに
オーディオプラグインで実装しようと思ったのですが、プラグインに深層学習FWを組み込むためのベストプラクティスが分からないため、今回はC#でWindowsのアプリを作成してマイクから音声を取得するところから考えます。
検証環境
OS: Windows 10 Home
CPU: Intel Core i5-5257U CPU @ 2.70GHz
RAM: 8GB
GPU: なし
Audio I/F: Tascam US-2x2HR
マイク: AKG P170

試しにコンデンサマイクというものを買ってみました。よく考えずに単一指向性のマイクを買ってしまいましたが、無指向性の方が良かったかもしれません。というかノートPCに付いてるマイクに十分のような気もする。
WASAPIを使って音声を取得する
WASAPIを使います。
Windows Vista以降でサポートされているWindowsのオーディオドライバーのインターフェースの名前で「Windows Audio Session API」の略語
音声の取得はこちらのC++のサンプルコードを参考にします。
COMなのでC#からでも呼び出せるはずなのですが、やり方がわからないのでNAudioを使います。
オーディオデバイスから音声を取得するC#コンソールアプリ
練習としてC++のサンプルコードを参考に音声を取得するC#コンソールアプリを書きます。
using System.Runtime.InteropServices;
using NAudio.CoreAudioApi;
namespace WasapiConsole
{
public class NativeMethods
{
[DllImport("api-ms-win-core-synch-l1-2-0.dll")]
public static extern IntPtr CreateEvent(IntPtr lpEventAttributes, bool bManualReset, bool bInitialState, IntPtr lpName);
[DllImport("api-ms-win-core-handle-l1-1-0.dll")]
public static extern bool CloseHandle(IntPtr hObject);
[DllImport("api-ms-win-core-synch-l1-2-0.dll")]
public static extern int WaitForSingleObject(IntPtr hEvent, int milliseconds);
}
internal class Program
{
static void Main(string[] args)
{
// デフォルトのキャプチャデバイス取得
var deviceEnumerator = new MMDeviceEnumerator();
var device = deviceEnumerator.GetDefaultAudioEndpoint(DataFlow.Capture, Role.Console);
Console.WriteLine("Default Capture Device: {0}", device.FriendlyName);
// AudioClient取得
var client = device.AudioClient;
// 初期化
client.Initialize(
AudioClientShareMode.Shared,
AudioClientStreamFlags.EventCallback,
client.DefaultDevicePeriod,
client.DefaultDevicePeriod,
// new NAudio.Wave.WaveFormat(16000, 16, 1),
new NAudio.Wave.WaveFormat(48000, 16, 2),
Guid.Empty);
// バッファイベントを登録する
IntPtr frameEventWaitHandle = NativeMethods.CreateEvent(IntPtr.Zero, false, false, IntPtr.Zero);
client.SetEventHandle(frameEventWaitHandle);
// バッファサイズを取得する
int bufsize = client.BufferSize;
// AudioCaptureClient取得
var captureClient = client.AudioCaptureClient;
// キャプチャ開始
client.Start();
bool stop = false;
Task.Run(() =>
{
// Enterキーが押されたら終了
Console.ReadLine();
Console.WriteLine("enter key pressed");
stop = true;
});
do
{
// バッファがいっぱいになるまで待つ
NativeMethods.WaitForSingleObject(frameEventWaitHandle, -1);
// バッファ取得
IntPtr p = captureClient.GetBuffer(
out int numFrameToRead,
out AudioClientBufferFlags bufferFlags);
if (bufferFlags == AudioClientBufferFlags.None)
{
Console.WriteLine("numFrameToRead: {0}", numFrameToRead);
//////////////
// 何かする //
//////////////
}
// バッファ解放
captureClient.ReleaseBuffer(numFrameToRead);
} while (stop == false);
// キャプチャ停止
client.Stop();
// 後始末
NativeMethods.CloseHandle(frameEventWaitHandle);
client.Dispose();
device.Dispose();
deviceEnumerator.Dispose();
}
}
}
Default Capture Device: マイク (US-2x2 HR)
numFrameToRead: 0
numFrameToRead: 480
numFrameToRead: 480
numFrameToRead: 480
・・・省略・・・
enter key pressed
numFrameToRead: 480
音声が取得できていそうなことは確認できました。
後述する音声認識モデルが16000Hzで学習しているため、それに合わせて16000Hzで取得したかったのですが、Audio I/Fが対応してなかったため48000Hzで取得した後に間引くことにします。
音声認識モデル(Audio Spectrogram Transformer)
AudioSetデータセットで学習したAudio Spectrogram Transformerを使います。
TorchScriptにエクスポート
Python以外でも扱いやすくするため、モデルをTorchScriptにエクスポートします。前処理と推論処理をまとめたかったのですが、traceでコケてしまうので別々に作成します。約5秒(≒512フレーム x 10ms間隔)に1回推論するようにします。
import torch
import torchaudio
def preprocess(waveform):
fbank = torchaudio.compliance.kaldi.fbank(
waveform,
frame_shift = 10,
htk_compat = True,
sample_frequency = 16000,
num_mel_bins = 128,
window_type = 'hanning')
fbank = (fbank - (-4.2677393)) / (4.5689974 * 2)
return fbank
waveform = torch.rand((1, 400 + 160 * 511))
preprocess_pt = torch.jit.trace(preprocess, waveform)
preprocess_pt.save("preprocess.pt")
import torch
from models import ASTModel
ast = ASTModel(
label_dim = 527,
input_tdim = 512,
imagenet_pretrain = True,
audioset_pretrain = True)
ast.eval()
fbank = torch.rand((1, 512, 128))
ast_pt = torch.jit.trace(ast, fbank)
ast_pt.save("ast.pt")
TorchSharpで推論する
TorchSharpを使います。
TorchScriptをロードして推論が出来るか確認してます。
using TorchSharp;
namespace TorchSharpConsole
{
internal class Program
{
static void Main(string[] args)
{
// モデルをロード
var preprocess = torch.jit.load("preprocess.pt");
var ast = torch.jit.load("ast.pt");
using (var guard = torch.no_grad())
{
// 適当な音声データ
var x = torch.rand(1, 400 + 160 * 511);
// 前処理
x = (torch.Tensor)preprocess.forward(x);
// 推論
x = (torch.Tensor)ast.forward(x.unsqueeze_(0));
x = x.sigmoid_()[0];
Console.WriteLine(x);
}
}
}
}
[527], type = Float32, device = cpu
ラベル毎の信頼度が出力されてそうなことが確認出来ました。
WPFで画面を作る
WPFで画面を作ります。約5秒間隔で推論して信頼度Top5のラベルを色付けします。
527クラスもあったので心配だったのですがなんとか収まりました。
実験
アコースティックギターの音(YouTubeで検索)をマイクの近くで再生させてどうなるか見てみます。
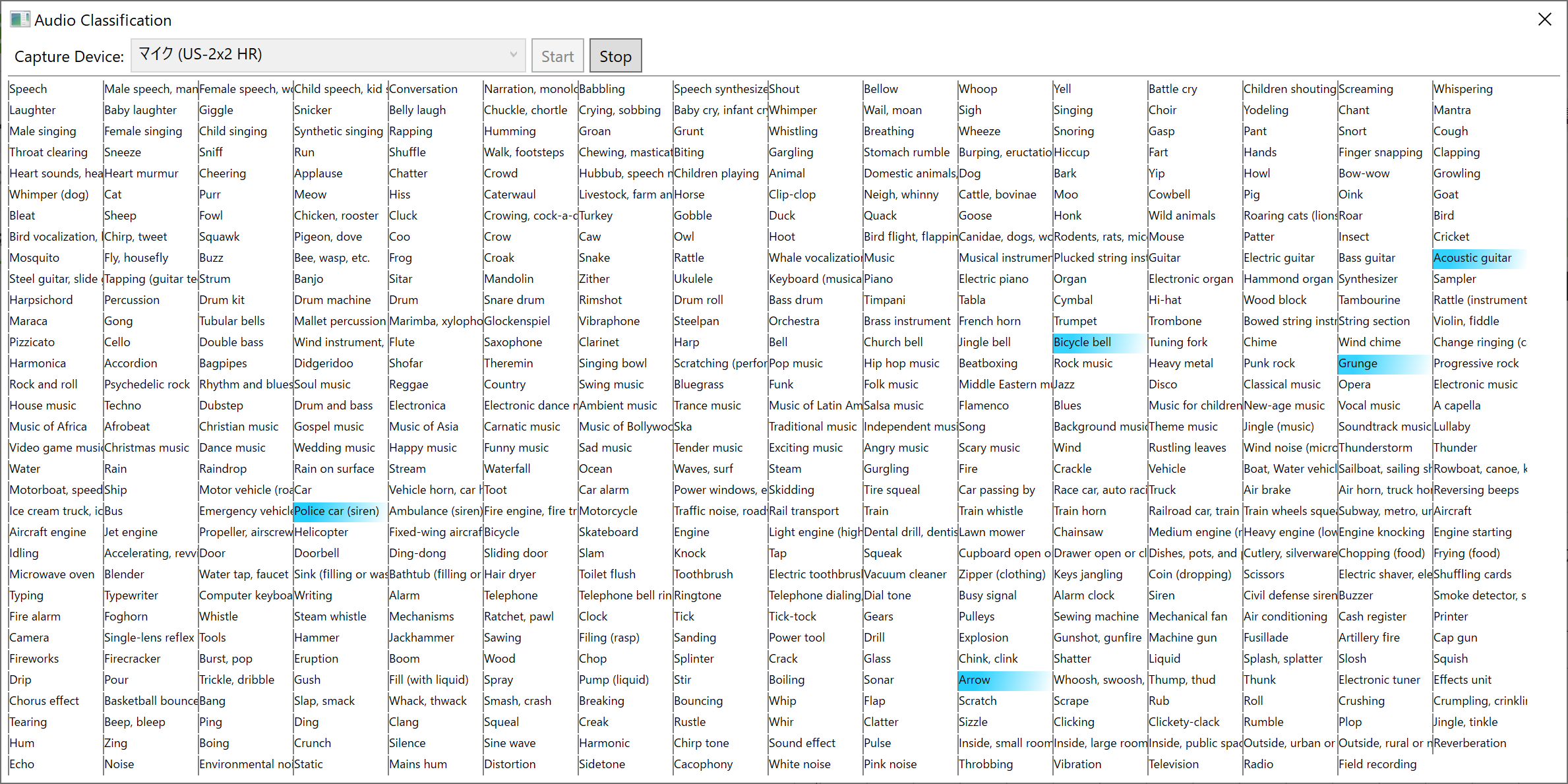
丁度「Acoustic guitar」に反応したときのスクショを取りましたが、「Dubstep」に反応したりしてちゃんと動作しているか微妙な気もしてきました。