試せるWebアプリ(2019.12.22追記)
以下でWebアプリとして公開したので、自分のQiita記事だとどんなタグが生成されるのか試したい方はどうぞ。
https://auto-create-qiita-tags.herokuapp.com/
Heroku使ってます。詳細は別のQiita記事として書いたので興味あれば見てみてください。
Docker+GitHub+HerokuでCI/CDっぽく
やったこと
自然言語処理を用いて、Qiitaの記事から自動的にタグを生成するプログラムを作ってみました。
専門用語(キーワード)を抽出するPythonモジュールtermextractを使いました。
以下、ざっくり全体図です。
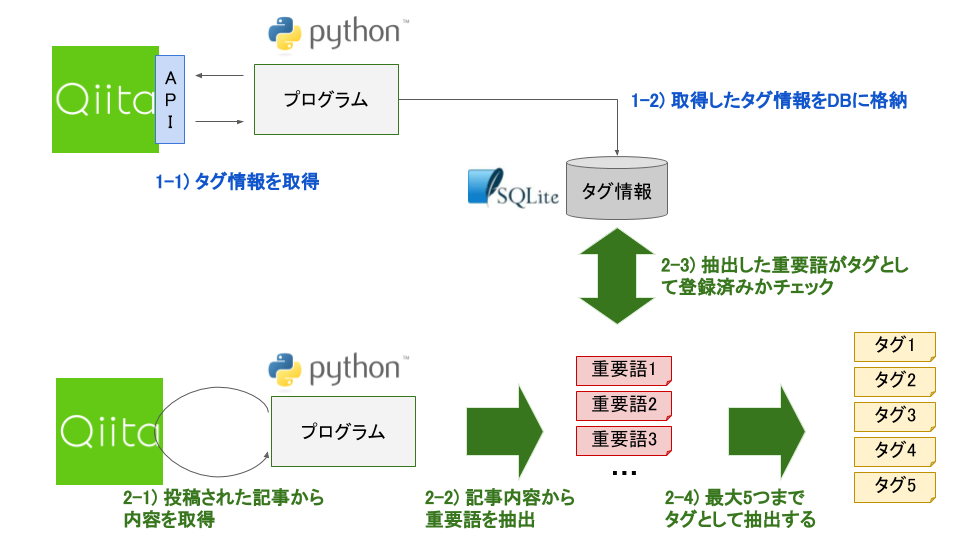
Qiita記事のタグ付け
Qiitaで投稿するときにタグつけますよね。
でも、タグってみなさんどうやってつけてますか?
私は正直あまり深く考えずそれっぽいかなという軽い感じでつけてました。
そもそも、タグとはその記事が何に関連するのかを表したものであり、見る人にしてみると
特定のタグをフォローすることで、興味のある分野の情報を的確に取得することができます。
Qiitaの公式ページにも書かれています。
タグやユーザーをフォローしよう
極端な話にはなりますが、せっかく有用な記事を書いていても、
タグの付け方1つで情報が行き届かない可能性もあるので
当たり前ですがタグ付けって結構大事ですね...
termextractとは?
テキストデータから専門用語を取り出すためのPython3モジュールです。
専門用語は複合語も含まれており、重要度でランキングされます。
http://gensen.dl.itc.u-tokyo.ac.jp/pytermextract/
以下、公式ページに記載されているコンセプト図です。
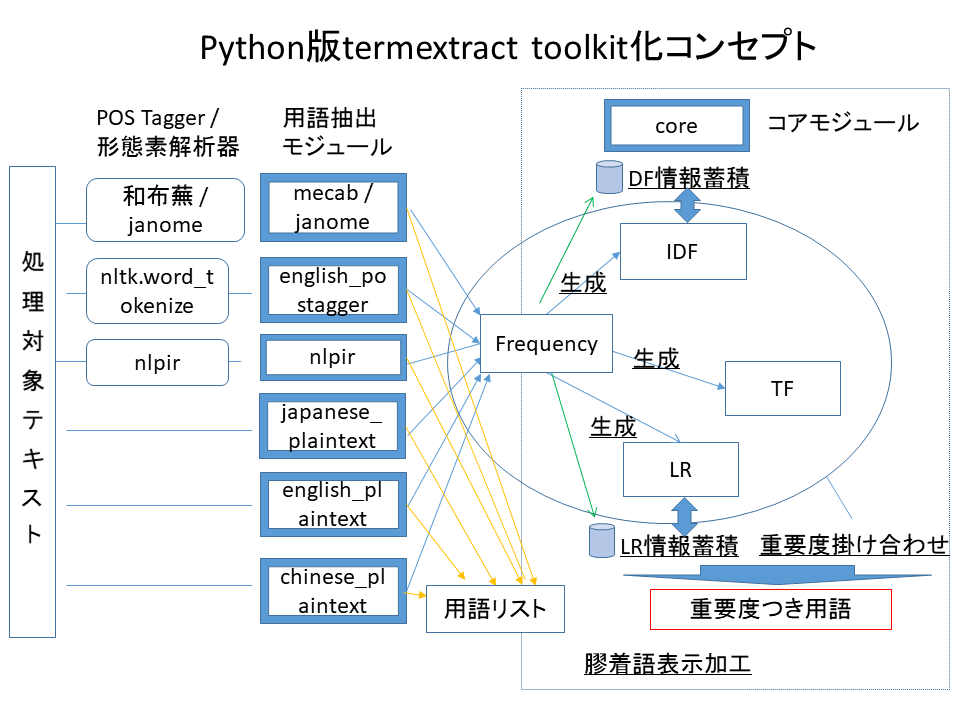
termextractを使いQiitaの記事から抽出された専門用語をタグとみなしました。
テキストデータをそのまま処理することもできますが、今回は取得したQiitaの記事を
janomeで形態素解析した結果を入力データとしています。
いざ実践
Qiitaの記事から内容を取得
まずはQiitaの記事から内容を抽出します。
Pythonでスクレイピングをする時によく使われるBeautiful Soupを利用しました。
Qiitaの記事のサンプルとして、私が過去に投稿したHelloMinikubeでk8sのお勉強を利用します。
import requests
from bs4 import BeautifulSoup
def extractText(url):
text = ''
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
#プログラムのコードは除去
for tag in soup.find_all('div',{'class':'code-frame'}):
tag.decompose()
#記事内容を抽出
for tag in soup.find_all('section'):
text += tag.getText()
return text
if __name__ == '__main__':
url = 'https://qiita.com/fukumasa/items/884eadd2694de19d64ff'
text = extractText(url)
print(text)
以下、実行結果です。
Kubernetesはじめました
世間的には結構前から話題になっていますが、仕事でこれから少しKubernetesをさわることになるため、ただいま必死こいて勉強中です。自宅でもKubernetesを勉強したいですが、なんせ使っているMacBookAirが弱小なので・・・お手軽だと噂のMinikubeを試してみました。
勉強するにあたり、以下の本を数日前に購入し、サラーっと最後まで読みましたが、
Kubernetesってカバー範囲が広いし、ほんと奥が深いのね・・・。
Minikubeとは?
WindowsやMacなど手元のマシン上にローカルKubernetesを簡単に構築・実行することが出来るツールです。手軽な反面、Kubernetesの一部機能が使えないなどの制約があります。
MinikubeはVMにMasterとNodeを立てるので、VirtualBoxやHyper-Vなどのハイパーバイザーが必要になります。
my環境
MacBook Air (13-inch, Mid 2012)
OS : macOS Catalina(10.15)
プロセッサ : 1.8 GHz デュアルコアIntel Core i5
メモリ : 4 GB 1600 MHz DDR3
ディスク : 128GB (外部ストレージ : 1TB)
ツール
バージョン
VirtualBox
6.0.12 r133076 (Qt5.6.3)
Kubernetes
v1.16.0
Docker
18.09.9
Minikube
v1.4.0 on Darwin 10.15
kubectl (Client)
v1.10.3 → v1.16.0
kubectl (Server)
v1.16.0
絵にすると多分こんな感じだと思います。
Kubernetesでは、コンテナ(Pod)が稼働するNodeと、コンテナのスケジューリングなどKubernetesを管理するMasterはそれぞれ別ノード(サーバ)で動かしますが、Minikubeでは1つのVM内に両方が稼働しています。
それぞれのノードは複数のコンポーネントから構成されており、VM内ではそれらがDockerコンテナとして稼働しています。コンポーネント詳細については公式ドキュメントなどを参考にして見てください。
Hello Minikubeやってみた
Hello MinikubeをベースにMinikubeと戯れてみました。
0. 事前準備
Homebrewをアップデート
VirtualBoxをインストール
1. Minikubeをインストール
2. Minikubeを起動
VirtualBoxでminikubeというVMが作られました。
Kubernetesと同じ画面がMinikubeにもついています。
いわゆるdashboardというやつです。
ブラウザが自動起動し画面が表示されました。まだ見方がさっぱりん...
・・・(長いので、以下略)・・・
うまく取得出来ました!
Qiitaの記事から専門用語を抽出
termextractを使って専門用語を抽出してみます。
まずはtermextractをインストールします。
公式ページにも書かれていますが、シンプルで簡単です。
# 本体をダウンロード
$ wget http://gensen.dl.itc.u-tokyo.ac.jp/soft/pytermextract-0_01.zip
# ダウンロードしたファイルを解凍
$ unzip pytermextract-0_01.zip
# セットアップ
$ cd pytermextract-0_01/
$ python setup.py install
termextractに含まれているサンプルプログラムをベースにして、専門用語を抽出するプログラムを書いてみます。
import sys
import collections
import dbm
from janome.tokenizer import Tokenizer
import termextract.janome
import termextract.core
import requests
from bs4 import BeautifulSoup
'''
重要度が高い順に表示
'''
def output(data):
data_collection = collections.Counter(data)
for cmp_noun, value in data_collection.most_common():
print(termextract.core.modify_agglutinative_lang(cmp_noun), value, sep='\t')
'''
Qiitaの記事から内容を抽出する
'''
def extractText(url):
text = ''
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
for tag in soup.find_all('div',{'class':'code-frame'}):
tag.decompose()
for tag in soup.find_all('section'):
text += tag.getText()
return text
if __name__ == '__main__':
url = 'https://qiita.com/fukumasa/items/884eadd2694de19d64ff'
text = extractText(url)
# janomeで形態素解析
t = Tokenizer()
tokenize_text = t.tokenize(text)
# 複合語抽出処理
frequency = termextract.janome.cmp_noun_dict(tokenize_text)
# FrequencyからLRを生成
lr = termextract.core.score_lr(
frequency,
ignore_words=termextract.janome.IGNORE_WORDS,
lr_mode=1, average_rate=1)
# FrequencyとLRを組み合わせFLRの重要度を出す
term_imp = termextract.core.term_importance(frequency, lr)
output(term_imp)
以下、実行結果です。
Kubernetes 24.0
Minikube 17.0
コンテナ 8.485281374238571
v 7.0
LoadBalancerサービス 6.344227580643384
VM 6.0
Hello 6.0
IP 5.196152422706632
Pod 5.0
Deployment 5.0
ReplicaSet 5.0
クラスタ 4.898979485566356
サービス 4.47213595499958
NodePort 4.242640687119286
環境 4.242640687119286
VirtualBox 4.0
kubectl 4.0
minikube 4.0
Service 4.0
LoadBalancer 4.0
仮想IP 3.4641016151377544
最後 3.0
バージョン 3.0
感じ 3.0
画面 3.0
ClusterIP 3.0
ノード 2.8284271247461903
参考 2.8284271247461903
クラスタ外 2.0597671439071177
Kubernetesクラスタ外 2.0396489026555056
勉強 2.0
Mac 2.0
ツール 2.0
Master 2.0
Node 2.0
GB 2.0
サーバ 2.0
インストール 2.0
ブラウザ 2.0
... 2.0
Development 2.0
作成 2.0
・・・(長いので、以下略)・・・
KubernetesやVMなどの専門用語が抽出出来ています。
ただ、Helloのようにあまり意味がない単語や...のようなノイズなどが含まれているため、
このままタグとして使うのは難しそうです。
termextractではIGNORE_WORDSというパラメータを使えば、対象外とする単語を指定することも出来るそうですが、どんな単語が来るか分からない中で1つ1つ指定するのは現実的でないと思いました。
色々調べてみると、Qiitaがタグ一覧を公開していることが分かったのでそれを使うことにしました。
具体的には、抽出できた専門用語のうち、Qiitaで既にタグとして登録されているものに絞って使うことにしました。
Qiitaのタグ一覧を取得
利用するQiitaのAPIはGET /api/v2/tagsです。
Qiita API v2ドキュメント
例えば、以下のように指定することで記事数が多いTOP100のタグを取得できます。
https://qiita.com/api/v2/tags?page=1&per_page=100&sort=count
ただし、pagaおよびper_pageに指定できるMAXは100なので、
このAPIで取得できるタグは最大で100ページ x 100ワード/ページ = 10,000ワードです。
あと、もう1点注意事項としてAPIの利用制限があります。
今回は100回呼び出しを行っているので、認証している状態で呼び出しを行いました。
認証している状態ではユーザごとに1時間に1000回まで、認証していない状態ではIPアドレスごとに1時間に60回までリクエストを受け付けます。
10,000ワードという情報量はまあまあ多いので、SQLiteを使いDBに保存しています。
import requests
import json
import sqlite3
# Qiitaの管理画面からアクセストークンを取得し指定します
headers = {
'Authorization': 'Bearer xxx'
}
# SQLiteのDB、テーブルを作成
con = sqlite3.connect('tags.db')
cursor = con.cursor()
cursor.executescript('''
DROP TABLE IF EXISTS tags;
CREATE TABLE tags(id,followers_count,items_count)
''')
# Qiita APIにアクセスしてタグ情報を取得し、SQLiteに格納
base_url = 'https://qiita.com/api/v2/tags?page={}&per_page=100&sort=count'
sql = 'INSERT INTO tags VALUES(?,?,?)'
for page in range(1,101):
url = base_url.format(page)
r = requests.get(url, headers=headers)
data = r.json()
for elm in data:
# 文字の揺らぎを少なくするために小文字で統一
cursor.execute(sql,(elm['id'].lower(),elm['followers_count'],elm['items_count']))
con.commit()
取得できたデータを少し確認してみます。
import sqlite3
con = sqlite3.connect('tags.db')
cursor = con.cursor()
# 全レコード数をカウント
sql = 'SELECT count(*) FROM tags'
rows = cursor.execute(sql)
res = cursor.fetchall()
print(res)
# Pythonのタグ情報を取得
sql = 'SELECT * FROM tags WHERE id=?'
word = 'Python'
rows = cursor.execute(sql,(word.lower(),))
res = cursor.fetchall()
print(res)
以下、結果です。
レコード数は10,000、Pythonのタグ情報は取得できています。
[(10000,)]
[('python', 63098, 32554)]
抽出した専門用語からタグを生成
今までのプログラムを組み合わせて、最終的に以下のようなソースコードを書きました。
なお、生成された各タグは以下の情報を持ちます。
- タグ名(name) : タグの名前
- 重要度(value) : タグの重要度(termextractが抽出した各単語に付与)
- フォロワー数(followers) : タグをフォローしているユーザの数(QiitaAPIより取得)
- 記事数(items) : タグが付けられた記事の数(QiitaAPIより取得)
import sys
import collections
import dbm
from janome.tokenizer import Tokenizer
import termextract.janome
import termextract.core
import requests
from bs4 import BeautifulSoup
import sqlite3
# 自動生成した全タグ情報
all_tags = []
'''
Qiitaの記事からタグを自動生成する
'''
def createTags(text):
# Qiitaの記事から専門用語を抽出
t = Tokenizer()
tokenize_text = t.tokenize(text)
frequency = termextract.janome.cmp_noun_dict(tokenize_text)
lr = termextract.core.score_lr(
frequency,
ignore_words=termextract.janome.IGNORE_WORDS,
lr_mode=1, average_rate=1)
data = termextract.core.term_importance(frequency, lr)
data_collection = collections.Counter(data)
# Qiitaのタグ情報を格納したDBに接続
sql = 'SELECT * FROM tags WHERE id=?'
con = sqlite3.connect('tags.db')
cursor = con.cursor()
# 抽出した専門用語を1つずつ取得
for cmp_noun, value in data_collection.most_common():
word = termextract.core.modify_agglutinative_lang(cmp_noun).lower()
# Qiitaに登録済みのタグか確認
rows = cursor.execute(sql,(word,))
res = cursor.fetchone()
# Qiitaに登録済みのタグのみに絞る
if res:
tag = {}
tag['name'] = word
tag['value'] = value
tag['followers'] = res[1]
tag['items'] = res[2]
all_tags.append(tag)
'''
Qiitaの記事から内容を抽出する
'''
def extractText(url):
text = ''
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
#プログラムのコードは除去
for tag in soup.find_all('div',{'class':'code-frame'}):
tag.decompose()
#記事内容を抽出
for tag in soup.find_all('section'):
text += tag.getText()
return text
'''
Qiitaの記事から現在登録されているタグを抽出する
'''
def extractTags(url):
tags = []
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
# Qiitaのタグ情報を格納したDBに接続
sql = 'SELECT * FROM tags WHERE id=?'
con = sqlite3.connect('tags.db')
cursor = con.cursor()
# 生成したタグ情報よりタグ名のリストを取得
t_name = [t.get('name') for t in all_tags]
# Qiitaの記事に現在登録されているタグを取得
for keyword in soup.find('meta', attrs={'name':'keywords'}).get('content').split(','):
#タグの情報を取得
keyword = keyword.lower()
rows = cursor.execute(sql,(keyword,))
res = cursor.fetchone()
followers = int(res[1]) if res else 0
items = int(res[2]) if res else 0
value = all_tags[t_name.index(keyword)]["value"] if keyword in t_name else 0
tag = {}
tag['name'] = keyword
tag['value'] = value
tag['followers'] = followers
tag['items'] = items
tags.append(tag)
return tags
if __name__ == '__main__':
url = 'https://qiita.com/fukumasa/items/884eadd2694de19d64ff'
text = extractText(url)
createTags(text)
print('■自動生成したタグ情報(重要度順 TOP5)')
tags = sorted(all_tags, key=lambda tag: tag['value'], reverse=True)[0:5]
for tag in tags:
print(tag)
print('------------------------------------')
print('■自動生成したタグ情報(フォロワー数順 TOP5)')
tags = sorted(all_tags, key=lambda tag: tag['followers'], reverse=True)[0:5]
for tag in tags:
print(tag)
print('------------------------------------')
print('■自動生成したタグ情報(記事登録数順 TOP5)')
tags = sorted(all_tags, key=lambda tag: tag['items'], reverse=True)[0:5]
for tag in tags:
print(tag)
print('------------------------------------')
print('■現在登録されているタグ情報')
tags= extractTags(url)
for tag in tags:
print(tag)
以下、結果です。
自動生成されたタグを、3つの観点でソートして表示してみました。
参考までに今登録されているタグはこちらです。
mac kubernetes minikube hellominikube
単語の重要度(value)が高いTOP5
kubernetes minikube コンテナ v vm
{'name': 'kubernetes', 'value': 24.0, 'followers': 1611, 'items': 2542}
{'name': 'minikube', 'value': 17.0, 'followers': 26, 'items': 135}
{'name': 'コンテナ', 'value': 8.485281374238571, 'followers': 16, 'items': 96}
{'name': 'v', 'value': 7.0, 'followers': 4, 'items': 9}
{'name': 'vm', 'value': 6.0, 'followers': 2, 'items': 38}
→ kubernetes minikube コンテナ辺りを含んでいますね。vって何かと思ったらv言語というやつでした。全然知らんかった・・・ただ、今回はあまり関係なさそうなワードですが、これを除けば結構いい感じではないでしょうか。
タグをフォローしているユーザ数(followers)が多いTOP5
qiita mac ssh aws docker
{'name': 'qiita', 'value': 1.0, 'followers': 48790, 'items': 1776}
{'name': 'mac', 'value': 2.0, 'followers': 31623, 'items': 8268}
{'name': 'ssh', 'value': 1.0, 'followers': 19828, 'items': 2189}
{'name': 'aws', 'value': 1.0, 'followers': 6990, 'items': 14959}
{'name': 'docker', 'value': 1.4142135623730951, 'followers': 6544, 'items': 11757}
→ dockerは使えそうですが、qiita aws ssh辺りはタグとしては少し違う気がします。macも自分でも付けてますが今更ながらちょっと違うかも・・・全体的にあまりパッとしない結果になりました。
タグが付けられた記事数(items)が多いTOP5
aws docker mac windows r
{'name': 'aws', 'value': 1.0, 'followers': 6990, 'items': 14959}
{'name': 'docker', 'value': 1.4142135623730951, 'followers': 6544, 'items': 11757}
{'name': 'mac', 'value': 2.0, 'followers': 31623, 'items': 8268}
{'name': 'windows', 'value': 1.0, 'followers': 1312, 'items': 6137}
{'name': 'r', 'value': 1.0, 'followers': 2015, 'items': 2909}
→ 先ほどのフォロワー数TOP5となんとなく似てますね。rはR言語なので今回のタグとしては違いますね。
まとめると、一番最初の 「重要度順TOP5」 が一番よい結果になりました。
他のQiita記事でも試してみた
勝手にいくつか記事を抜粋してどんな結果になるか試してみました。
4歳娘「パパ、セッションとCookieってなあに?」
| タグ種別 | タグ情報 |
|---|---|
| 現在 |
http cookie セッション
|
| 1. 自動生成 (重要度順TOP5) |
サーバ cookie セッション ブラウザ ログイン
|
| 2. 自動生成 (フォロワー数順TOP5) |
javascript html jquery twitter 質問
|
| 3. 自動生成 (記事数順TOP5) |
javascript html jquery twitter cookie
|
→ タイトルのセッションとCookieを含んでいますし、 「重要度順TOP5」 が良さそうな気がします。下2つはほぼ同じですね。
『イラストで読む AI 入門』読書メモ 01 : AI ブームの歴史 (パーセプトロン, バックプロパゲーション, ディープラーニング)
| タグ種別 | タグ情報 |
|---|---|
| 現在 |
入門 ディープラーニング ai 歴史 人工知能
|
| 1. 自動生成 (重要度順TOP5) |
ai 人工知能 機械学習 パーセプトロン 学習
|
| 2. 自動生成 (フォロワー数順TOP5) |
qiita 機械学習 azure アルゴリズム 深層学習
|
| 3. 自動生成 (記事数順TOP5) |
機械学習 azure qiita アルゴリズム メモ
|
→ aiや人工知能はやはり外せないと思うので、 「重要度順TOP5」 が良さそうな気がします。筆者の方が付けられている入門や歴史などのタグもあった方がどんな位置付けの内容か分かりやすいですね。
個人的に超絶為になったので新人エンジニアに勧めたい記事まとめ
| タグ種別 | タグ情報 |
|---|---|
| 現在 |
初心者 まとめ 初心者向け 新人プログラマ応援
|
| 1. 自動生成 (重要度順TOP5) |
技術書 コード 方法 勉強方法 エンジニア
|
| 2. 自動生成 (フォロワー数順TOP5) |
git aws 初心者 vscode オブジェクト指向
|
| 3. 自動生成 (記事数順TOP5) |
aws git 初心者 vscode プログラミング
|
→ 勉強方法や技術書などのタグが含まれているので、 「重要度順TOP5」 が一番伝わりやすそうな気がします。下2つはどちらかと言うと具体的な技術用語が多いですね。筆者の方が付けられている新人プログラマ応援というタグですが、文中に出てこないワードなので、今回のtermextractを使っても自動生成する事は出来ません。
個人的な感想に近いですが、私の記事の時と同様 「重要度順TOP5」 がいずれの記事も良さそうな結果となりました。にしても、みなさんちゃんとタグ考えて付けてらっしゃいますね〜・・・
まとめ
termextractを使ってQiitaタグの自動生成を行ってみましたが、特に 「重要度順TOP5」 は結構いい感じの結果になったのではないでしょうか。ただ、termextractは内容に含まれていないワードはタグとして生成出来なかったり、重要度がいくら高くても意味的には関係がないタグを生成したりと課題もあるため、現状では人間が作り出すタグの方が長けていると思います。
今回はQiitaAPIを使って既に登録済みのものに絞ってタグを生成しましたが、逆に登録がないものをタグとして生成するようにすれば、新たなタグを生成することが出来るかもしれません。やっぱり、自然言語処理は面白い!
ニーズあるか分かりませんが、簡易画面付きで簡単に試せるようなアプリを作成中なので、また完成次第GitHubにでも公開します。
おまけ(2019.10.29追記)
公開後にこの記事を対象にタグの自動生成してみたら、 「重要度順TOP5」 は以下のような結果になりました。
タグ 自動生成 qiita top 情報
{'name': 'タグ', 'value': 163.1686244349691, 'followers': 0, 'items': 31}
{'name': '自動生成', 'value': 33.895612242701944, 'followers': 2, 'items': 16}
{'name': 'qiita', 'value': 33.54101966249685, 'followers': 48790, 'items': 1776}
{'name': 'top', 'value': 20.0, 'followers': 0, 'items': 15}
{'name': '情報', 'value': 9.486832980505138, 'followers': 0, 'items': 7}
topや情報は少し違うかな。。
伝えたいtermextractが入っていないし、少し残念な結果となってしまいました・・・。