はじめに
はじめまして。深層学習を用いた画像解析などのアルバイトをしている大学生です。
アルバイトでセマンティックセグメンテーションのお仕事をさせていただく機会があり、その復習ということで基本的なことから一般的な手法、チュートリアルなどをまとめてみました。
対象読者
セマンティックセグメンテーションを、これから学んで取り組みたいといった人向けです。
記事を読んで、セマンティックセグメンテーションの概要や一般的な手法についてざっくり学び、実際に試せるように仕上げていきたいと思いますので、間違いや微妙な表現、追加情報などありましたらコメントいただけると幸いです。
この記事で説明すること
以下のような流れで説明させていただきます。
- 基本
- セマンティックセグメンテーションとは?
- どういった場面で使われるか?
- 技術的な話
- 一般的な手法
- 評価指標
- 損失関数
- 実際にやってみる
- Google Colaboratoryで動かしてみる
- チュートリアルなどの紹介
- もう少し深くやってみる
- 自前でデータセットを準備する
- データセット紹介
基本
セマンティックセグメンテーションとは何か?
セマンティックセグメンテーションとは、画像のピクセル(画素)一つ一つに対して、何が写っているかといった、ラベルやカテゴリを関連付ける問題です。
以下のような入力画像(左)とマスク画像(右)がセットとなったデータセットを使い、入力からマスク画像のような出力を目指して学習させます。


出典:stanford background dataset
どういった場面で使われるか?
セマンティックセグメンテーションは以下のような、画像に写っているものを識別することでメリットを得られる、幅広い場面で使用されます。
- 手書き認識(単語や行を抽出)
- Googleポートレートモード(前景と背景を分離)
- YouTubeストーリー
- 仮想メイク(仮想リップスティック)
- 仮想試着
- 視覚的画像検索
- 工場で製品の傷検出
- 医療画像診断(病変部分の検出など)
- 自動運転(環境把握、走行可能な経路の識別)
- 衛星画像で地形を識別
- ロボティックビジョン(物体や地形の識別とナビゲーション)
- フォントの違いを調べる
参考
A 2020 guide to Semantic Segmentation
セマンティックセグメンテーション - MATLAB & Simulink
技術的な話
セマンティックセグメンテーションの手法
セマンティックセグメンテーションで用いられる手法の中から、有名なものを簡単にまとめておきます。
FCN(Fully Convolutional Networks)
一般的なCNNの全結合層を、領域全体をカバーする1x1の畳み込みを行うと考えることで、全結合層を畳み込み層に置き換えても同じような結果を得ることができるというもの。これにより、入力画像のサイズを修正する必要がなくなくなるというメリットがある。
また、出力される部分はクラスだけでなく、入力画像の特徴マップとなりセグメンテーションに有効な情報を得ることができるが、終盤では入力時よりかなり解像度が落ちているので、後処理として特徴マップ元の解像度まで戻す仕組みが必要がある。
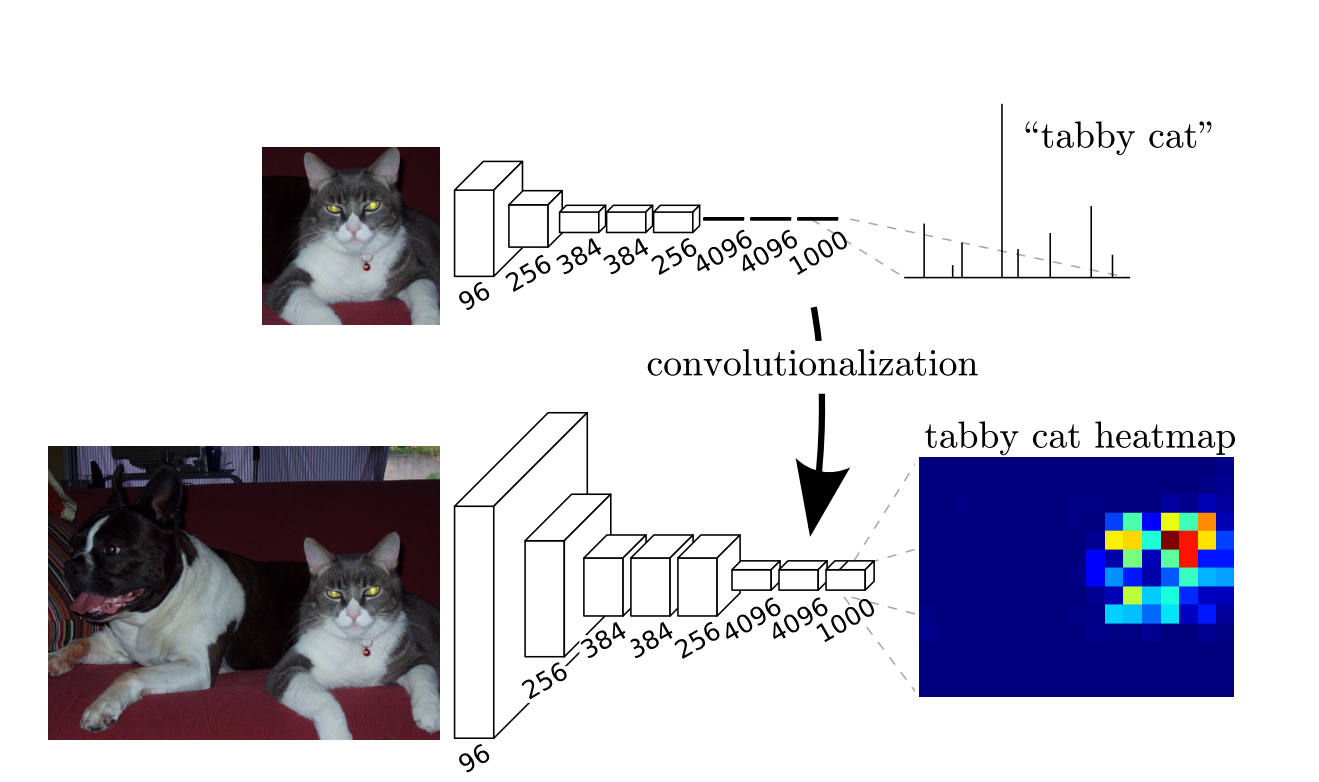
出典:Fully Convolutional Networks for Semantic Segmentation
SegNet
Encoder-Decoder型のFCNであり、前半Encoder側でプーリングを行うのと同じ回数だけ,後半のDecoderでアップサンプリングを行う。(最大値)プーリングの際にその位置を記録し、その位置へアップサンプリングを行うことで、情報の一貫性を保持している。
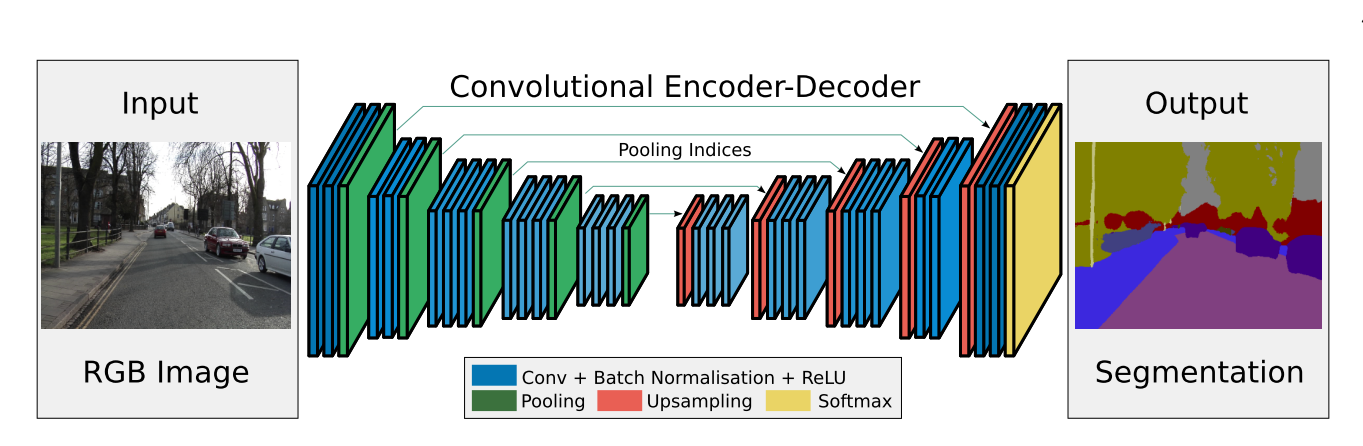
出典:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
U-Net
Encoder-Decoder型で、**低次元の特徴を高次元の特徴へスキップして結合する「スキップ接続」**が特徴。FCNではダウンサンプリングの際に失われてしまう情報があるので、ダウンサンプリングされた特徴マップを,Decoder側の対応する空間解像度の場所に受け渡す(スキップ接続する)ことで情報の回復をする。
Decoder側のチャンネルが2倍になる分パラメータが多くなり、過学習や推論時間の増加が懸念される。
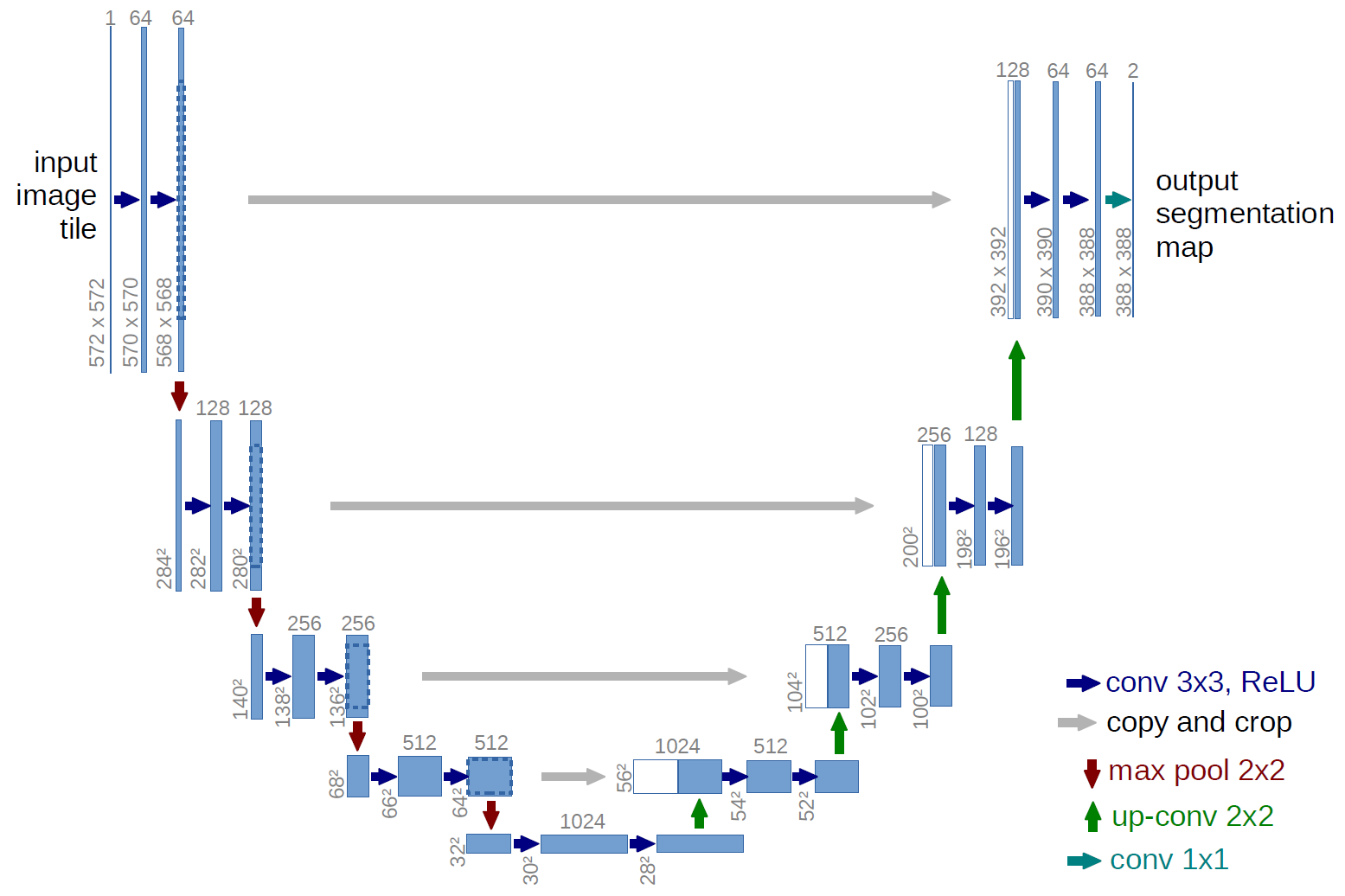
出典:
U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net: Convolutional Networks for Biomedical Image Segmentation
PSPNet
Encoder-Decoder型で、Spatial Pyramid Poolingを用い、リッチな周辺コンテキストを得ることで高精度のセマンティックセグメンテーションを可能にしたもの。
具体的には、Encoderで抽出された特徴マップに対して、グリッド範囲の広さ別にAverage Poolingを4回行う「(Spatial) Pyramid Poolingモジュール」を用いて,グリッド領域サイズ別にPoolingされた特徴マップを4チャンネル作成し、この4チャンネルを元のCNN特徴マップの後ろに結合し,最終的なクラス識別に用いる。(EncoderとDecoderの間にPyramid Pooling Moduleを追加)

出典:Pyramid Scene Parsing Network
DeepLab (v1~v3+)
v1では、畳み込み層に**Atrous convolution(Dilated convolution)**を用いる手法を、v2では、Spatial Pyramid Poolingから着想を得た、**Atrous Spatial Pyramid Pooling(ASPP)**を追加した。
v3ではv2で追加したASPPを改良した「改良型ASPP」を用いるとともに、v1, v2で行っていたCRFによる後処理を廃止、v2の「画像のマルチスケール処理」を「特徴のマルチスケール処理」に変更し計算効率化、Batch Normalizationの導入をしている。
v3+ではv3をさらに改良し、シンプルで効果的なデコーダモジュールを追加、バックボーンにXceptionモデルの導入、Atrous Spatial Pyramid Poolingとデコーダモジュールの両方に深度方向畳み込み分解(depthwise separable convolution)を適用することによる、より高速で強力なネットワークの構築をされている。
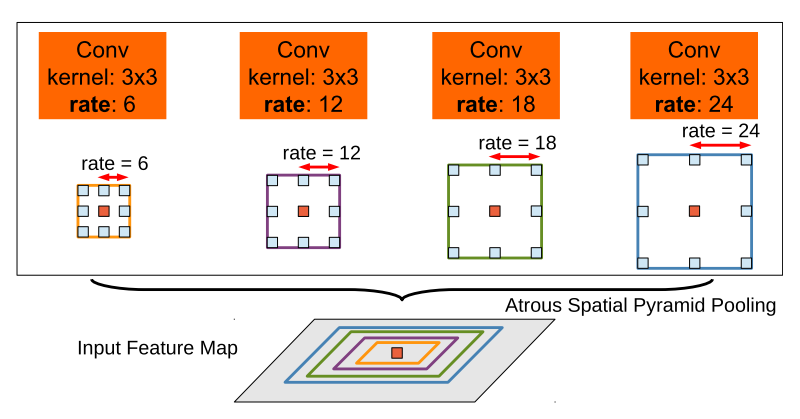
手法の基本方針
セマンティックセグメンテーションは、各画素周辺の広範囲の周辺コンテキストやシーン全体のコンテキストを知っておくほど誤識別が減るので、広範囲の周辺コンテキスト特徴を多重解像度的に集めてPoolingするのが基本方針となっている。
しかし、コンテキストを積極的に取り込むことは「バイアス(特にラベルの偏り)」を積極的に取り込んでしまい,過学習につながる可能性もある。
参考:セマンティックセグメンテーション [初期の手法(FCN/SegNet/U-Net)から,PSPNet, DeepLab v3 まで]
その他の手法
2019年の論文にあるFastFCNでは、Joint Pyramid Upsampling (JPU)というモジュールを導入し、精度を落とすことなく計算コストを3倍以上減らす、既存の手法の計算量改善を目指したものもあります。すべてを確認できていませんが、他にもさまざまな手法が提案されています。
以下では多くの手法についてのリンクがまとめられていましたので、時間があるときに確認してみたいです。
Awesome Semantic Segmentation
手法全体の主な参考元
セマンティックセグメンテーション [初期の手法(FCN/SegNet/U-Net)から,PSPNet, DeepLab v3 まで]
A 2020 guide to Semantic Segmentation
評価指標の紹介
学習後の結果は、一般的に**Pixel accuracy(Accuracy)やMean Intersection over Union (mIoU)**で評価されます。以下には、セマンティックセグメンテーションの評価指標を調べて、出てきたものをまとめておきます。
- Pixel accuracy (Accuracy)
- GlobalAccuracy
- Mean Accuracy (Class Accuracy)
- Intersection Over Union (IoU)
- Mean Intersection over Union (mIoU)
- Frequency weighted IOU
- F1 Score
- Average Precision
主な参考元
A 2020 guide to Semantic Segmentation
5. 実践編: MRI画像のセグメンテーション
Semantic segmentation
セマンティックセグメンテーションにおける Skip Connect手法の比較
Image Segmentation Evaluation
損失関数の紹介
ニューラルネットワークを最適化するために使われる損失関数についても紹介します。調べて出てきた一般的なものについてまとめておきます。
- Cross Entropy Loss
- Focal Loss
- Dice Loss
- Tversky Loss
- Hausdorff distance
主な参考元
A 2020 guide to Semantic Segmentation
Loss functions for image segmentation
A survey of loss functions for semantic segmentation
実際にやってみる
実際に動かしてみたいと思います。以下ではGoogle Colaboratoryで動かせるようにしたものといくつかのチュートリアルの紹介をします。
Google Colaboratoryで動かしてみる
今回は簡単に試すことを目的としたいので、データセット、ネットワークには、既に準備されているものを使用します。また、その他の部分に関しても大まかに作ったので詳細に関してご質問、ご意見などありましたらコメントよろしくお願いいたします。
データセット、ネットワークには以下を使用します。
既存の公開データセットから選ばれた715枚の画像について、三種類のマスクデータがあるデータセットです。
以下のPDFリンク
S. Gould, R. Fulton, D. Koller. Decomposing a Scene into Geometric and Semantically Consistent Regions. Proceedings of International Conference on Computer Vision (ICCV), 2009.
一般的な手法でも紹介したU-NetやPSPNetが簡単に利用できるPythonのパッケージです。今回はこのチュートリアルでも使われているU-Netを使用します。
必要なパッケージのインストール
構築済みモデルを使えるパッケージをインストールします。
!pip install -U segmentation-models
!pip install tensorflow==2.1.0
現状(2020.11.3)のColabだと2.3.0で、このバージョンだとsegmentation_modelsをインポートする際に以下のエラーが出ることがあります次のいずれかの方法で解決します。
AttributeError: module 'keras.utils' has no attribute 'generic_utils'
- generic_utilsをインポート
- バージョンを下げて解決(2.2.0はダメでした)
他の解決方法があれば教えていただきたいです
解決方法1:generic_utilsをインポート
# generic_utilsをインポート
from keras.utils import generic_utils
解決方法2:バージョンを下げて解決
!pip install tensorflow==2.1.0
インストール後にランタイムの再起動が必要になることがあります。その際に以下のような警告が出ますが、その下に出る「RESTART RUNTIME」をクリックするか、上にあるツールバーの「ランタイム」から再起動するなどしてください。
WARNING: The following packages were previously imported in this runtime:
[gast,tensorboard,tensorflow]
You must restart the runtime in order to use newly installed versions.
データセットのダウンロード
stanford background dataset をダウンロードおよび解凍します。
# ダウンロード
!wget http://dags.stanford.edu/data/iccv09Data.tar.gz
# 解凍
!tar -xzvf iccv09Data.tar.gz
どんな画像があるか確認してみます。
import matplotlib.pyplot as plt
import numpy as np
import cv2
# どんな画像があるか確認
name = '0000047' # ファイル名を指定
img = cv2.imread(f'./iccv09Data/images/{name}.jpg') # jpg画像
label_regions = np.loadtxt(f'./iccv09Data/labels/{name}.regions.txt') # 意味クラス(空, 木, 道, 草, 水, 建物, 山, 前景のオブジェクト)を示すマスク
label_surfaces = np.loadtxt(f'./iccv09Data/labels/{name}.surfaces.txt') # 幾何学的なクラス (空, 水平, 垂直) を示すマスク
label_layers = np.loadtxt(f'./iccv09Data/labels/{name}.layers.txt') # 別々の画像領域を示すマスク
# 画像表示
display_list = [img, label_regions, label_surfaces, label_layers]
title = ['jpg', 'regions', 'surfaces', 'layers']
plt.figure(figsize=(15, 15))
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(display_list[i])
plt.axis('off')
plt.show()
結果は以下のようになります。

モデル、データセットの準備
segmentation-modelsのチュートリアルを参考にモデルの下準備とデータセットの準備をおこなっていきます。
正解ラベルの画像は、各クラスごとに画像を作成(クラス0であれば、元のマスク0の部分が1、それ以外は0の画像となるように)します。
※注意点としては、入力サイズは32の倍数でないといけない点です。https://github.com/qubvel/segmentation_models/issues/1
# チュートリアル=>シンプルなトレーニングパイプラインを参考
from segmentation_models import Unet
from segmentation_models import get_preprocessing
BACKBONE = 'resnet34'
preprocess_input = get_preprocessing(BACKBONE)
import glob
# データセットの準備(今回は3種類のマスクの内、surfacesを選択)
# 画像の一覧取得
images = sorted(glob.glob(f'./iccv09Data/images/*.jpg'))
labels = sorted(glob.glob(f'./iccv09Data/labels/*.surfaces.txt'))
x = []
y = []
classes = 3 # クラス数
ratio = 0.8 # 学習データの割合
input_shape = (224, 224) # 32の倍数でないといけない https://github.com/qubvel/segmentation_models/issues/1
# 入力画像
for img_path in images:
img = cv2.imread(img_path)
img = cv2.resize(img, input_shape) # 入力サイズに変換
img = np.array(img, dtype=np.float32) # float形に変換
img *= 1./255 # 0~1に正規化
x.append(img)
# 正解ラベル
for label_path in labels:
label = np.loadtxt(label_path)
label = cv2.resize(label, input_shape) # 入力サイズに変換
img = []
for label_index in range(classes): # 各クラスごとに画像を作成(クラス0であれば、元のマスク0の部分が1、それ以外は0の画像となる)
img.append(label == label_index)
img = np.array(img, np.float32) # float形に変換
img = img.transpose(1, 2, 0) # (クラス数, 224, 224) => (224, 224, クラス数)
y.append(img)
x = np.array(x)
y = np.array(y)
x = preprocess_input(x)
# データを分割
p = int(ratio * len(x))
x_train = x[:p]
y_train = y[:p]
x_val = x[p:]
y_val = y[p:]
学習
先ほど同様にチュートリアルを参考にモデルを定義、学習していきます。
# チュートリアル=>シンプルなトレーニングパイプラインを参考
# モデルを定義
model = Unet(BACKBONE, classes=classes, encoder_weights=None)
model.compile('Adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習
history = model.fit(
x=x_train,
y=y_train,
batch_size=16,
epochs=20,
validation_data=(x_val, y_val)
)
結果の確認
学習後に学習曲線と実際に予測させた結果を確認します。
# 学習曲線のグラフ
fig, (axL, axR) = plt.subplots(ncols=2, figsize=(10, 4))
# [左側] metricsについてのグラフ
axL.plot(history.history['accuracy'])
axL.plot(history.history['val_accuracy'])
axL.grid(True)
axL.set_title('Accuracy_vs_Epoch')
axL.set_ylabel('accuracy')
axL.set_xlabel('epoch')
axL.legend(['train', 'val'], loc='upper left')
# [右側] lossについてのグラフ
axR.plot(history.history['loss'])
axR.plot(history.history['val_loss'])
axR.grid(True)
axR.set_title("Loss_vs_Epoch")
axR.set_ylabel('loss')
axR.set_xlabel('epoch')
axR.legend(['train', 'val'], loc='upper left')
# グラフを表示
plt.show()
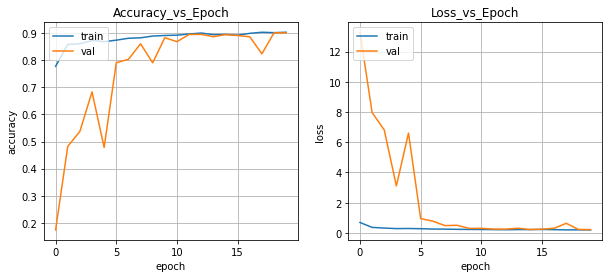
学習曲線は以下のようになりました。学習が進むにつれて、検証データのAccuracyが上がりlossが減っていることが確認できました。
# 結果を確認
num = 0 # 確認したい画像を指定
input_img = x_train[num] # 入力画像
true_img = cv2.resize(np.loadtxt(labels[num]), input_shape) # 正解マスク
preds = model.predict(x_train[num][np.newaxis, ...]) # 予測(長さ1の配列で渡す)
pred_img = np.argmax(preds[0], axis=2) # 予測マスク (224, 224, クラス数) => (224, 224)
# 結果表示
display_list = [input_img, true_img, pred_img]
title = ['Input Image', 'True Mask', 'Predicted Mask']
plt.figure(figsize=(15, 15))
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(display_list[i])
plt.axis('off')
plt.show()
以下が予測結果です。それらしい感じの結果が見られて少し安心しました。

以上のコードをノートブック形式にまとめました。
fujiya228/semantic-segmentation-demo
チュートリアルなどの紹介
上記では、ざっくりと試しましたが他にももう少し詳しい説明のあるチュートリアルなどがあるのでいくつか紹介します。すべてを確認することは出来ていないので、使えないものなどがありましたら、コメント等でご指摘いただけると幸いです。
- Image segmentation (https://www.tensorflow.org/tutorials/images/segmentation)
- DeepLab Demo
- Google ColabでMask R-CNNを試す
- DeepLab v3+でオリジナルデータを学習してセマンティックセグメンテーションする
- U-NetでPascal VOC 2012の画像をSemantic Segmentationする (TensorFlow)
- 最強のSemantic Segmentation「Deep lab v3 plus」を用いて自前データセットを学習させる
- TensorFlow Image Segmentation: Two Quick Tutorials
- セマンティックセグメンテーションでフォントの違いを検出
- CaDIS: a Cataract Datasetで画像セグメンテーション
もう少し深くやってみる
自前でデータセットを準備する
ここでは、自前でデータセットを準備する場合に便利なアノテーションツール紹介します。できる限りセマンティックセグメンテーションに使えるものを確認しましたが、使えないものなどありましたら、コメント等でご指摘いただけると幸いです。
- Lionbridge AI
- Flow
- Microsoft VoTT
- LabelMe
- Labelbox
- LEAR Image Annotation Tool
- semantic-segmentation-editor
- CVAT (Computer Vision Annotation Tool)
データセット紹介
ここでは、公開されているデータセットについていくつか紹介します。
以下に多くまとめられているので、いつか確認できればと思います。
Awesome Semantic Segmentation
まとめ
今回はセマンティックセグメンテーションの概要や一般的な手法などについてまとめていきました。ある程度調べ直して理解が深まるとともに、まだまだ奥が深いことが分かったので時間がある際にはいろいろと試してみたいと思います。