今回は、MNIST を使った畳み込みニューラルネットワークによる数字の分類を行います。
MNIST
MNIST は、0〜9 までの手書き文字画像のデータセットになります。
このデータセットには、画像サイズ 28x28 のデータが、トレーニングデータとして 60,000件、
テストデータとして 10,000件 含まれています。
又、正解ラベルのデータも同数含まれています。

このデータセット使い、対象の画像の数字が何であるかを求めます。
事前準備
予めの MNIST サンプルコードをダウンロードしておきます。
実装コード全体
実装内容は、TensorFlowの MNIST サンプルコードをベースに
Deep MNIST for Experts の記載内容の取り込み、一部修正を行ったものになります。
実装コードの全体は以下となります。
このソースコードを先程ダウンロードしたサンプルの mnist ディレクトリ直下へ配置します。
※ tensorflow/tensorflow/examples/tutorials/mnist
deep_mnist_softmax.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
# 重み変数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# バイアス変数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 畳み込み
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# プーリング
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def main(_):
# データ取得
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# placeholder作成
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
# 畳み込み1層目
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み2層目
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 全結合層
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# ドロップアウト層
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 出力層
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
# 損失関数(交差エントロピー誤差)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_conv, y_))
# 勾配
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 精度
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# セッション
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# トレーニング
for i in range(5000):
batch = mnist.train.next_batch(50)
if i % 500 == 0:
# 途中経過(500件ごと)
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %f" % (i, train_accuracy))
# トレーニング実行
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 評価
print("test accuracy %f" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
ニューラルネットワーク
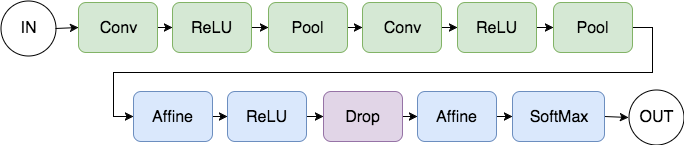
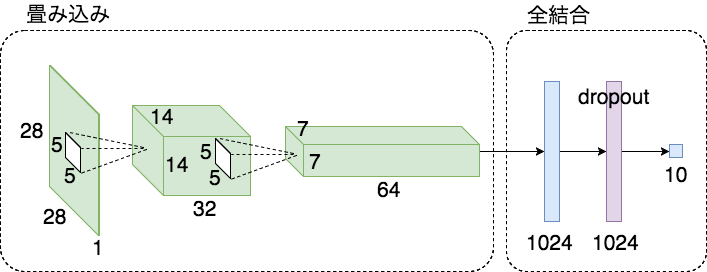
上記コードの処理の流れとニューラルネットワークの形状は以下のようになります。
処理の流れ
形状
実装コード詳細
実装コードの詳細を以下に記載します。
- 重み
# 重み変数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
重み変数として、正規分布からランダム値で初期化します。
- バイアス
# バイアス変数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
バイアス変数として、定数(0.1)で初期化します。
shape [2, 3] の場合
[[0.1, 0.1, 0.1],
[0.1, 0.1, 0.1]]
- 畳み込み
# 畳み込み
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
重み(フィルターサイズ) W の形状で ストライドstrides と パディングpadding を指定して
畳み込みを行います。
- プーリング
# プーリング
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
プーリングサイズ ksize の形状で ストライドstrides と パディングpadding を指定して
プーリングを行います。
ksize:プーリングサイズ指定方法
2x2 の場合は [1, 2, 2, 1]
3x3 の場合は [1, 3, 3, 1]
- データ取得
# データ取得
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
MNISTデータの取得を行います。
- placeholder
# placeholder作成
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
入力データ: x として n x 784 を placeholder として作成します。
ラベル(正解)データ: y_ として n x 10 を placeholder として作成します。
placeholder は、実行時にデータを入力します。
784 は 28x28(=784) の画像を一次元として扱った場合の数値です。
- 畳み込み層
# 畳み込み1層目
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み2層目
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
ここでは以下の流れで処理を行います。
- フィルターサイズ(5x5)、出力数 32 で畳み込み
- バイアス加算
- 活性化関数 ReLU を適応
- プーリングサイズ(2x2)でプーリング
- 2層目へ
- フィルターサイズ(5x5)、出力数 64 で畳み込み
- 1層目と同様の処理をし、全結合層へ
- 全結合層
# 全結合層
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
[7 * 7 * 64, 1024] は、7 * 7 が、畳み込み2層目でプーリングされたサイズ、
64 が、畳み込み2層目での出力数、1024 が、全結合層の出力数となります。
ここでは以下の流れで処理を行います。
- 乗算をするため、畳み込み2層目の出力結果を2次元に整形
- 畳み込み2層目出力(n, 7x7x64) と 重み(7x7x64, 1024) で乗算
- バイアス加算
- 活性化関数 ReLU を適応
- 次の層へ
- ドロップアウト層
# ドロップアウト層
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
keep_prob はドロップ率を指定します。
※placeholder のため、実行時にドロップ率を入力します。
- 出力層
# 出力層
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
出力する分類数である 10 を指定します。
- 損失関数・勾配・精度
# 損失関数(交差エントロピー誤差)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_conv, y_))
# 勾配
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 精度
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
損失関数として、交差エントロピー誤差を指定
勾配は Adam を指定。1e-4 は学習率になります。
精度は正解の平均(正解数 / n)となります。
- セッション
# セッション
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
セッションを生成します。ここでは、
sess.run(tf.global_variables_initializer()) にて tf.Variable を初期化しています。
- トレーニング
# トレーニング
for i in range(5000):
batch = mnist.train.next_batch(50)
if i % 500 == 0:
# 途中経過(500件ごと)
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %f" % (i, train_accuracy))
# トレーニング実行
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
トレーニング回数は、5000回を設定(時間がかかるため少なめに指定)
一度のトレーニングで、トレーニングデータを 50件ずつ読み込み train_step を実行します。
また、途中経過として、500回毎に精度を print出力しています。
(この途中経過の精度出力は、算出データとしてトレーニングデータをそのまま使っており、
かつ、データ件数も50件と少ないため信頼度は低くなっています)
補足
・mnist.train.next_batch()は、データを最後まで読み込んだ時点でデータのシャッフルを行い、
再び先頭からデータを読み込みます。
・feed_dict={x: batch[0], y_: batch[1]は、placeholder のデータを入力しています。
・keep_prob: 0.5は、ドロップ率 50% を指定しています、1.0 を指定するとドロップしません。
評価や予測時には、1.0 を指定します。
- 評価
# 評価
print("test accuracy %f" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
ここでは、テストデータ 10,000件 を使って精度を算出します。
keep_prob は、1.0 を指定しています。
実行
コードを実行します。
python deep_mnist_softmax.py
※前回のエントリーでの作成した環境で実行する場合は、仮想環境を起動後に実行します。
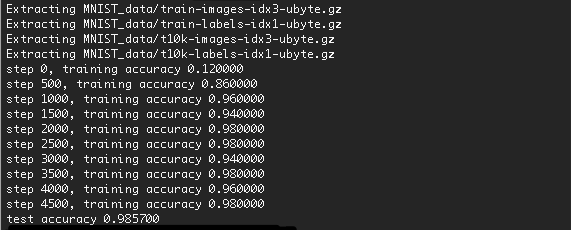
結果
実行結果は以下のようになります。
精度は、98.57% まで上がりました。
トレーニング回数を増やすことでもう少し精度が上がるはずです。
初回はデータのダウンロードが発生するため少し時間がかかります。
以上、今回は MNIST を使った畳み込みニューラルネットワークによる数字分類を行いました。