これは、PostgreSQL Advent Calendar 2017の16日目の記事です。
はじめに
以前の記事で、パーティション数が多いほどプラン生成時間が長くなることを、パーティション数0〜1000で確認しました。今回は、20万パーティションを作成したい気分だったので、パーティションを1000ずつ20万まで作成ながら、各パーティション数でのプラン生成時間を確認します。
パーティションの作成
ネイティブ・パーティショニング機能を使い、以下のようなパーティションを作成します。パーティションにはレコードを格納せず、空のままとします。PostgreSQLのバージョンは10.1(を改造したもの1)です。
-- (親)テーブル
CREATE TABLE test (key INT, val TEXT) PARTITION BY LIST (key);
-- パーティション
CREATE TABLE test_0000001 () PARTITION OF test FOR VALUES IN (1);
CREATE TABLE test_0000002 () PARTITION OF test FOR VALUES IN (2);
CREATE TABLE test_0000003 () PARTITION OF test FOR VALUES IN (3);
…
CREATE TABLE test_0200000 () PARTITION OF test FOR VALUES IN (200000);
プラン生成時間の計測
パーティション数が1000増える毎に、EXPLAIN ANALYZEで下記SQLのプラン生成時間を5回計測し、その中央値を結果として採用します。
-- アクセス先が1つのパーティションに絞り込まれるSQL
SELECT * FROM test WHERE key = 99;
結果
さっそく結果です。以下は、横軸パーティション数、縦軸プラン生成時間のグラフです。
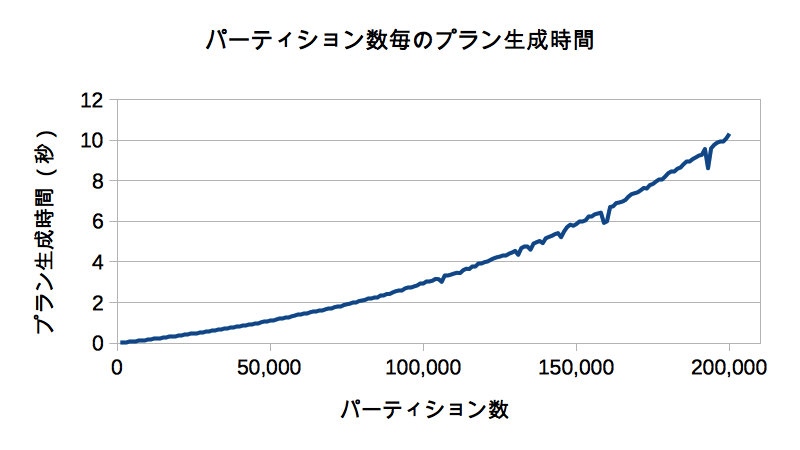
やはりパーティション数に応じてプラン生成時間は増えていき、パーティション数が20万になると単純なSQLでもプラン生成だけで10秒以上かかることを確認できました。
さて、このプラン生成時間の問題ですが、改善のパッチ2は提案されていて、バージョン11以降では解消されているかもしれません。乞うご期待!!
付録
以降は、参考までに、プラン生成時間以外に計測した結果やパーティション作成時の注意事項などです。
パーティション作成時間
以下は、横軸パーティション数、縦軸1000パーティションの作成時間のグラフです。
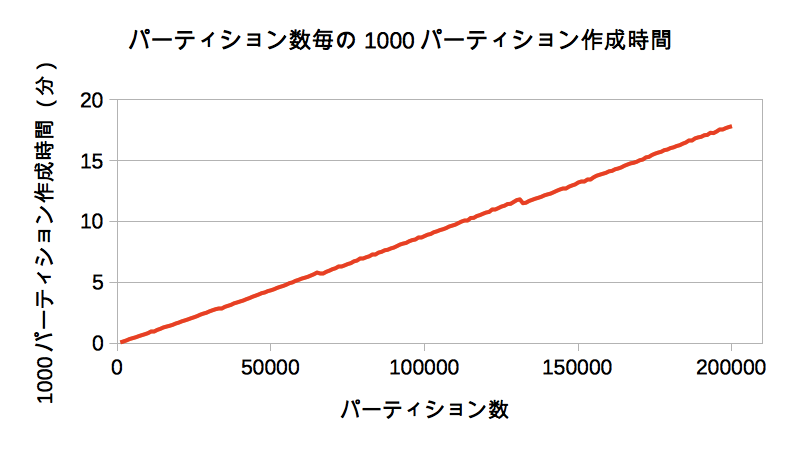
パーティションの作成時間も、作成済パーティション数に応じて増えていき、19万9000のパーティションが作成済の状態で、新たにパーティションを1000作成して20万にする場合は約18分もかかることを確認できました。プラン生成だけでなくパーティション作成にも、パーティション数に応じて時間のかかる内部処理があるようで、こちらも今後の改善を期待したいです。
なお、今回は、パーティション作成時間を短縮するためにfsyncを無効化しています。これは、fsync=onのデフォルト設定のままだと、パーティション作成毎にデータファイルが同期書き込みされて作成時間が非常に長くなるためです。ちなみに、fsync=onでパーティション作成中にpg_stat_activityを見ると、wait_eventにDataFileImmediateSyncがよく出てきて、データファイルの同期書き込みがパーティション作成の遅延要因だと確認できるはずです。
データベースサイズ
以下は、横軸パーティション数、縦軸データベースサイズのグラフです。
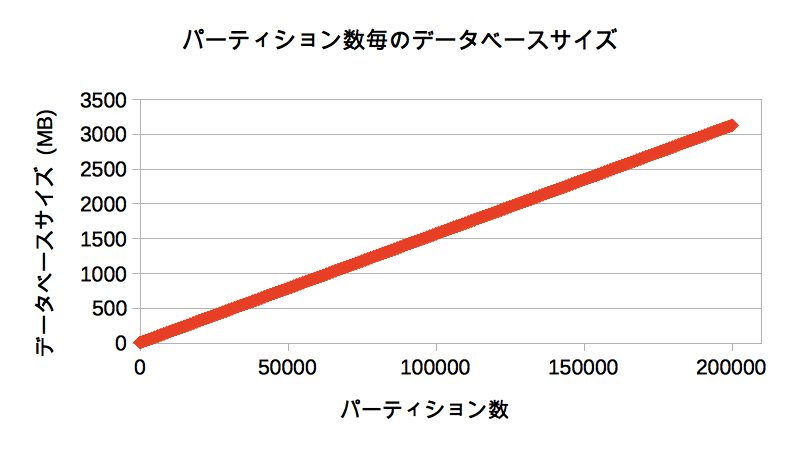
今回作成するパーティションは空ですが、パーティション数に応じてデータベースサイズも増えていき、20万パーティションでは約3GBものサイズになることを確認できました。
パーティション作成とプラン生成時間の計測を行うシェル
突貫で作ったので汚いですが、以下のシェルでパーティションを1000ずつ作成し、プラン生成時間を計測しました。
# !/bin/sh
# psqlのパスを設定
PSQL=bin/psql
# プラン生成時間などの計測結果の出力先ファイルのパスを設定
CREATETBLLOG=${HOME}/createtbl.log
DBSIZELOG=${HOME}/dbsize.log
PLANTIMELOG=${HOME}/plantime.log
# 一時ファイル
TMPFILE=$(mktemp)
# 前回の出力ファイルを削除
rm -f ${CREATETBLLOG} ${DBSIZELOG} ${PLANTIMELOG}
# パーティションを作成する関数
# テーブル名と作成するパーティション数を指定する
create_partition ()
{
NSP=$1
TBL=${NSP}.$1
SEQ=${TBL}_seq
PARTNUM=$2
LOOPNUM=$(echo "${PARTNUM} / 1000" | bc)
# スキーマとテーブルを作成
# プラン生成時間の集計用のテーブル plantime も作成
cat <<EOF | $PSQL
DROP SCHEMA ${NSP} CASCADE;
CREATE SCHEMA ${NSP};
CREATE TABLE ${TBL} (key INT, val TEXT) PARTITION BY LIST (key);
CREATE SEQUENCE ${SEQ};
CREATE TABLE IF NOT EXISTS plantime (ptime DOUBLE PRECISION);
EOF
# パーティション未作成時点のデータベースサイズを計測
cat <<EOF | $PSQL >> ${DBSIZELOG}
\copy (SELECT '0', pg_database_size(current_database())) to stdout with csv
EOF
# パーティションを1000ずつ作成ながら計測を行うループ
for num in $(seq 1 $LOOPNUM); do
# 1000パーティションはDO文を使って一括作成
# 作成時間を計測
cat <<EOF | $PSQL | grep Time | awk '{print $2}' | sed -E s/^/${num}000,/g >> ${CREATETBLLOG}
\timing on
DO \$\$
DECLARE
i INT;
key INT;
part TEXT;
BEGIN
FOR i IN 1 .. 1000 LOOP
key := nextval('${SEQ}');
part := '${TBL}_' || to_char(key, 'FM0000000');
EXECUTE 'CREATE TABLE ' || part || ' PARTITION OF ${TBL} FOR VALUES IN (' || key || ')';
END LOOP;
END;
\$\$ LANGUAGE plpgsql;
EOF
# 1000パーティション作成後にデータベースサイズを計測
cat <<EOF | $PSQL >> ${DBSIZELOG}
\copy (SELECT '${num}000', pg_database_size(current_database())) to stdout with csv
EOF
# EXPLAIN ANALYZEでプラン生成時間を5回計測
cat <<EOF | $PSQL | grep Planning | awk '{print $3}' > ${TMPFILE}
EXPLAIN ANALYZE SELECT * FROM ${TBL} WHERE key = 99;
EXPLAIN ANALYZE SELECT * FROM ${TBL} WHERE key = 99;
EXPLAIN ANALYZE SELECT * FROM ${TBL} WHERE key = 99;
EXPLAIN ANALYZE SELECT * FROM ${TBL} WHERE key = 99;
EXPLAIN ANALYZE SELECT * FROM ${TBL} WHERE key = 99;
EOF
# プラン生成時間の計測結果を集計用テーブルにロード
cat <<EOF | $PSQL
TRUNCATE plantime;
\copy plantime from ${TMPFILE}
EOF
# 集計用テーブル上でプラン生成時間の最小値、中央値、平均値、最大値を計算
cat <<EOF | $PSQL | sed -E s/^/${num}000,/g >> ${PLANTIMELOG}
\copy (SELECT min(ptime), percentile_cont(0.5) WITHIN GROUP (ORDER BY ptime), avg(ptime), max(ptime) FROM plantime) to stdout with csv
EOF
done
rm -f ${TMPFILE}
}
# テーブル名 test で20万パーティションを作成
time create_partition test 200000
大量パーティションの取り扱いに失敗する件その1
大量のパーティションを取り扱う場合、共有ロックテーブルのエントリ数上限にひっかかり、以下のERRORが発生してSQL実行が失敗しがちです。
ERROR: out of shared memory
HINT: You might need to increase max_locks_per_transaction.
共有ロックテーブルのエントリ数が少なくともパーティション数より多くなるように、max_locks_per_transactionの設定値を大きくする必要があります。今回は、(大きすぎですが念のため)100000に設定しました。
大量パーティションの取り扱いに失敗する件その2
PostgreSQLの隠れた制約で、パーティション数が65000以上のときにSQLを実行すると、以下のERRORが発生してSQLは失敗します。
ERROR: too many range table entries
今回は、この制約を回避して20万パーティションでSQL実行したかったので、ERRORを発生させるソース箇所をコメントアウトした改造版PostgreSQLを使うことにしました。コメントアウトしたソース箇所はsrc/backend/optimizer/plan/setrefs.cの以下です。
if (IS_SPECIAL_VARNO(list_length(glob->finalrtable)))
ereport(ERROR,
(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
errmsg("too many range table entries")));
ネイティブ・パーティショニング機能の主要開発者であるAmitさん(@amitlan)によると、“That's something we'll need to fix someday.”とのことで、これもいつか改善されるかもです(ニッチなニーズなので改善まで時間かかるかもですが…)。
-
PGConf Asia 2017の講演「Declarative Partitioning Has Arrived」で、発表資料-1の最後に取り上げられている Partition Pruning のパッチです。おそらく。 ↩