概要
先日、Microsoft AzureにPromptFlowという機能が追加されました。
これはAzureOpenAIに対してのプロンプトエンジニアリングをローコードで支援する仕組みなんですが、DBを用意してそこに社内ドキュメントを格納しておき、それに対してPromptFlowの内部でアクセスすることによってChatGPTに社内ドキュメントへの検索、回答機能を持たせることができます。
このChatGPTに対して独自ドキュメントを拡張知識として持たせる仕組みのことをRAG(Retrieval Augmented Generation)といいます。
参考: プロンプトエンジニアリング手法 外部データ接続・RAG編 - Platinum Data Blog by BrainPad
PromptFlowの機能によって、独自の拡張知識を持ったChatGPTのREST APIをオンライン上にデプロイすることができます。
このAPIに対してAzureFunctionsを用いて接続し、さらにそのAzureFunctionsに対してLINEのチャットボットのWebhookおよびMessaging APIを用いて接続することによってLINEのチャットボットを使ってユーザーと拡張知識を持ったChatGPTとの会話を行う仕組みを作りました。
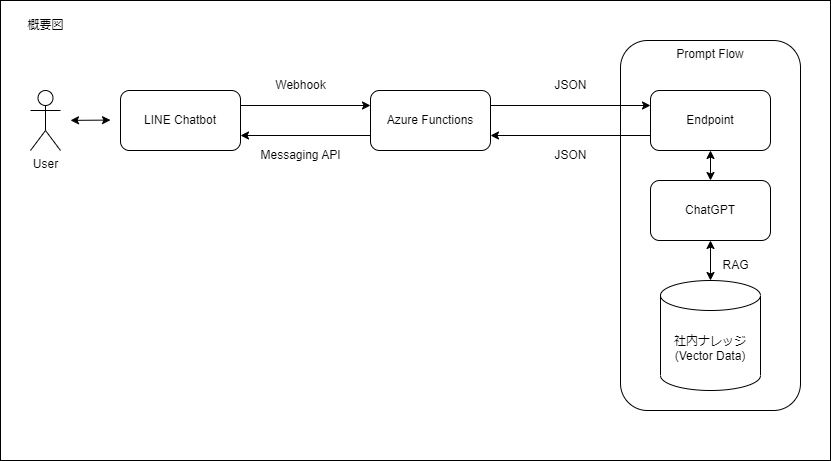
大まかな流れ
- LINEのチャットボットを作成します
- AzureFunctionsを作成します
- LINEのチャットボットとAzureFunctionsを接続し、AzureFunctions上のコードを、ユーザーがチャットボットに対して送信したメッセージをそのままオウム返しするように設定します
- PromptFlowを作成します
- AzureFunctions上でユーザーからのメッセージにオウム返ししていた部分をPromptFlowに対して通信を行う形に変更します
LINEチャットボットを作成
基本的なチャットボットの作り方は公式のサイトをご覧になるのが良いと思います。
完成した後にチャットボットのページに訪れると、大きくQRコードが表示されています。これをLINEのアプリで読み込むと、チャットボットがトーク相手として追加されます。
なお、このページで「Webhookの利用」をONにしたり、応答メッセージを無効にしたりなどの設定をしておくのが良いと思います。
WebhookのURLの登録は、後ほどAzureFunctionsを作成したあと、そのエンドポイントのURLを設定することになります。
チャネルアクセストークンも忘れずに発行しましょう。(特にこだわりないなら長期でOKだと思います)

Azure Functionsの作成
手前味噌になりますが、以前に私が書いた記事が参考になると思います。
AzureのFunctionsをCLIで使う(ローカルリソースの生成からデプロイまで)with Python - Qiita
AzureのFunctionsをCLIで使う(ローカルリソースの生成からデプロイまで)with Javascript - Qiita
今回はPythonでやっていきます。
ここで、AzureFunctionsにアップロードする__init__.pyの内容は以下の通りになります。
# AzureFunctions上でのデバッグのためlog出力をふんだんに入れています。
import os
import logging
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage, TextSendMessage
from azure.functions import HttpRequest, HttpResponse
import requests
# ロギングの設定
logging.basicConfig(level=logging.DEBUG)
line_bot_api = LineBotApi(os.getenv("ACCESS_TOKEN"))
handler = WebhookHandler(os.getenv("SECRET"))
def main(req: HttpRequest) -> HttpResponse:
signature = req.headers.get("X-Line-Signature")
body = req.get_body().decode("utf-8")
try:
logging.debug("リクエストの処理を開始します。")
handler.handle(body, signature)
except InvalidSignatureError as e:
logging.error("無効な署名です。チャンネルのアクセストークンとシークレットを確認してください。")
logging.error(str(e))
return HttpResponse(
"無効な署名です。チャンネルのアクセストークンとシークレットを確認してください。",
status_code=400,
)
except Exception as e:
logging.error("リクエスト処理中にエラーが発生しました:", exc_info=True)
return HttpResponse(
"リクエストの処理中にエラーが発生しました。",
status_code=500,
)
logging.debug("リクエストは正常に処理されました。")
return HttpResponse("OK")
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
try:
# オウム返し部分
line_bot_api.reply_message(
event.reply_token, TextSendMessage(text=event.message.text)
)
except Exception as e:
logging.error("返信中にエラーが発生しました:", exc_info=True)
ソースコード冒頭でimportしているline-bot-sdkとazure-functionsについて、以下のコマンドでインストールした後、
$ pip install line-bot-sdk
$ pip install azure-functions
AzureFunctions上のインスタンスが上記のパッケージをインストールできるように、func new --name line-bot-handler --template "HTTP trigger"でHTTP triggerのテンプレートディレクトリを作成したとした場合、line-bot-handler ディレクトリの直下にrequirements.txtを生成して配置しましょう。
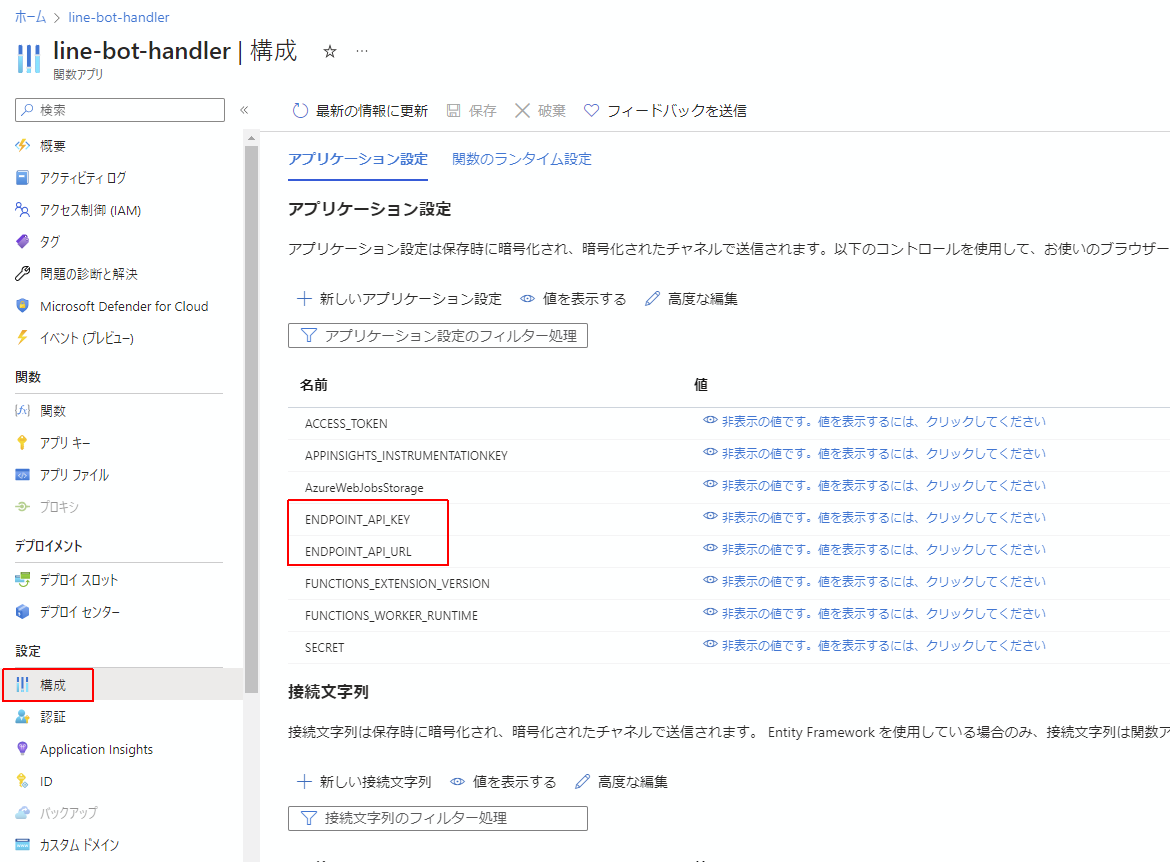
次に、Azure上のAzureFunctionsのリソースを見に行き、構成のページから
line_bot_api = LineBotApi(os.getenv("ACCESS_TOKEN"))
handler = WebhookHandler(os.getenv("SECRET"))
部分で取得されている環境変数をAzureFunctionsリソースに設定します。
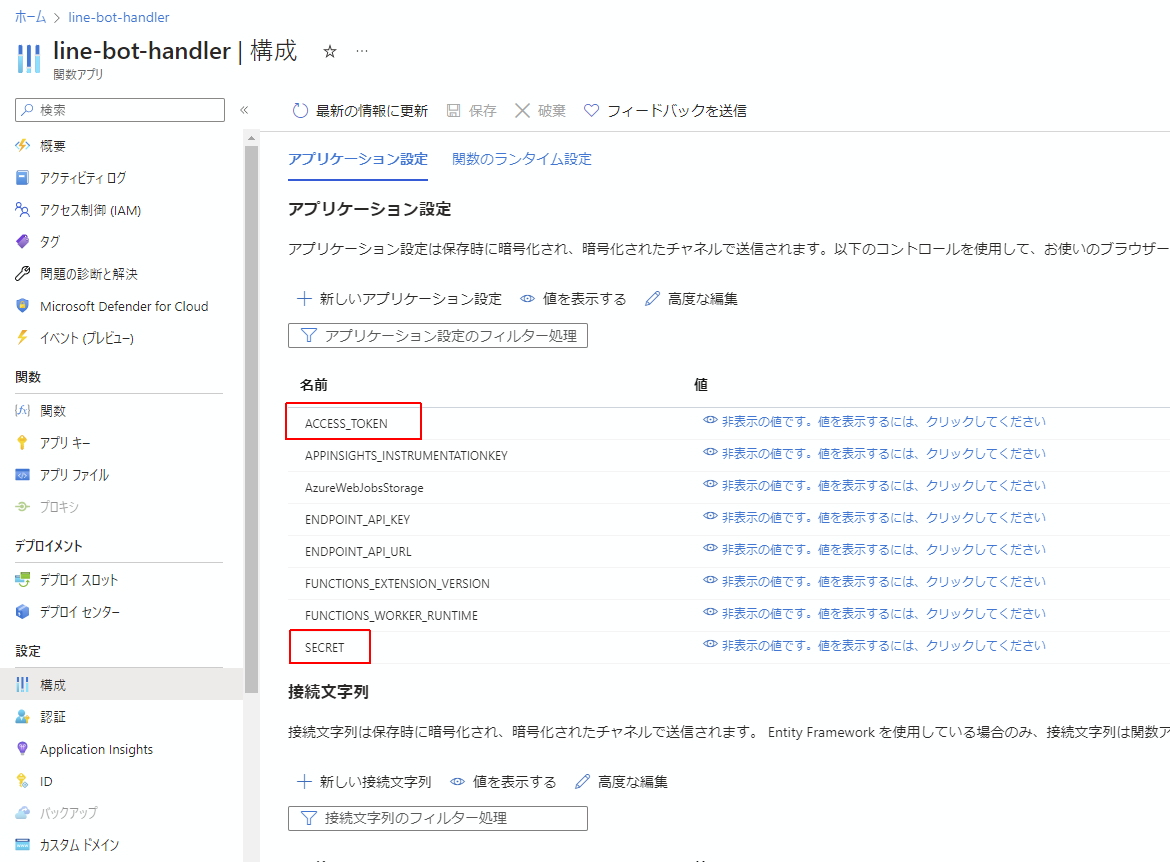
- ACCESS_TOKENにはLINEチャットボットを作成の項で生成したチャネルアクセストークンを設定します。
- SECRETにはLINEのチャットボット管理サイトのチャネル基本設定の最下部にあるチャネルシークレットを設定します。
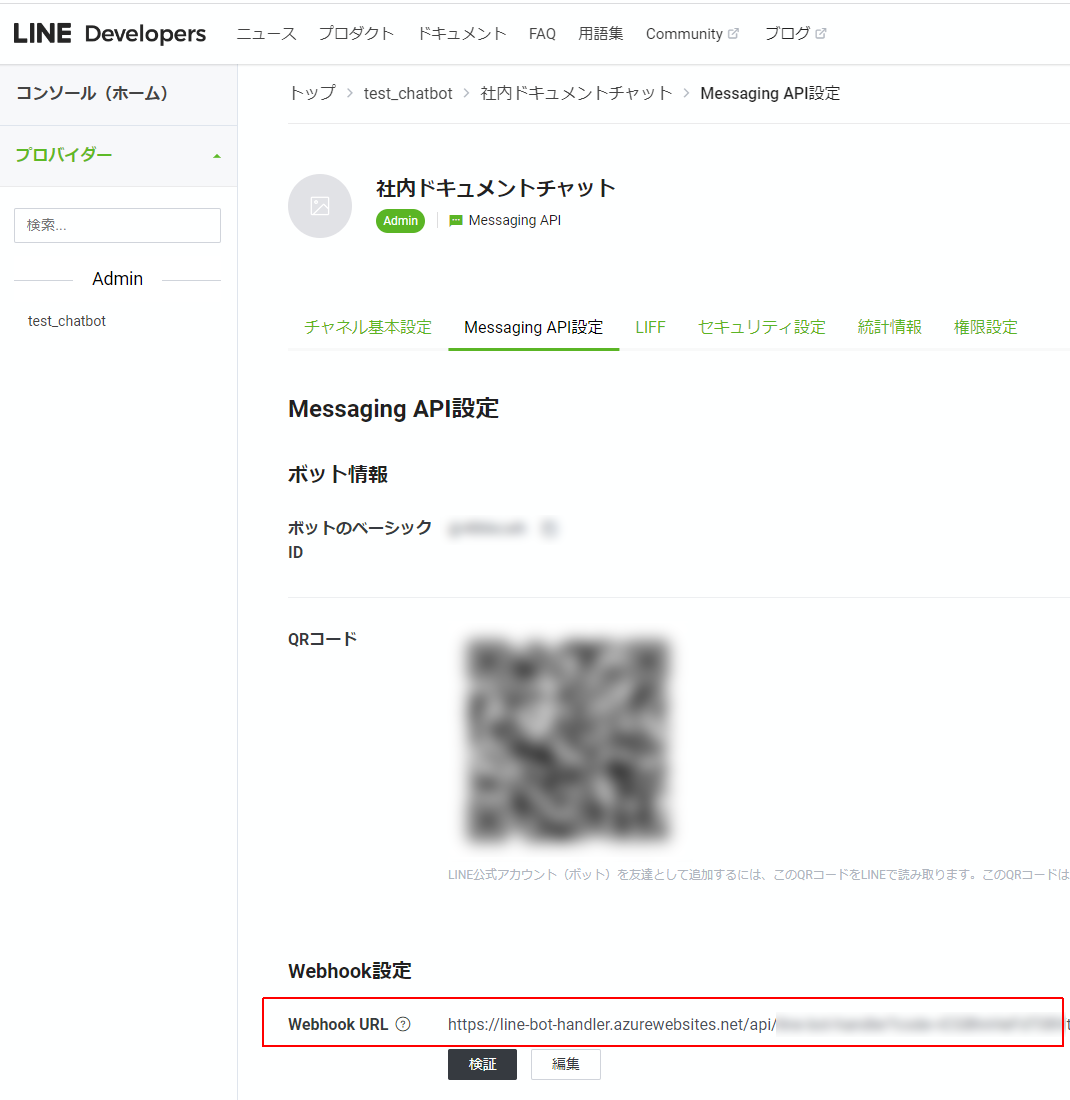
最後に、このAzureFunctionsのエンドポイントをLINEチャットボット上の設定でWebhook URLとして設定します。
これでLINEのチャットボットに対してなにかメッセージを送ると、それがそのまま返ってくるチャットボットが完成しました。
PromptFlowの作成
これに関してはこちらの記事を参考にさせていただきました。
Azure Machine Learning の Prompt flow で Azure Cognitive Search をベクトルストアとして RAG を実行する - Qiita
なお、PromptFlowを作成するに先立ちまして、AzureCognitiveSearch内にVectorDBを作成する必要があります。これについては上記の記事と同じ人が書かれた下記のリポジトリが大変参考になります。
busho-index/TextChunking_Embeddings_RegisterIndex.ipynb at main · nohanaga/busho-index · GitHub
AzureCognitiveSearch(DB)の用意
さてこの度は下記の簡単な社内ナレッジをLLMに追加で持ってもらうことにしました。
株式会社船井総研デジタルは心理的安全性に重きを置いています。
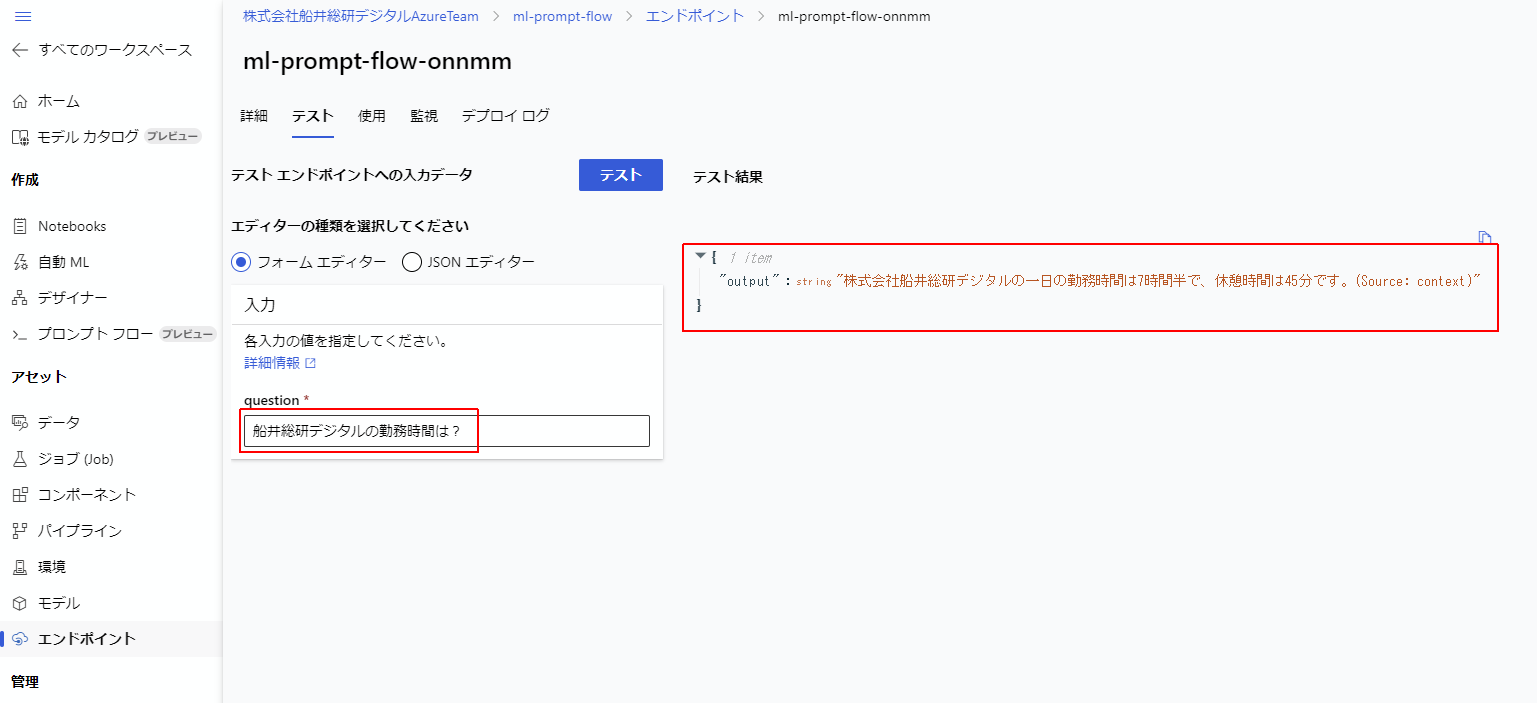
株式会社船井総研デジタルの一日の勤務時間は7時間半で、休憩時間は45分です。
上記の文書をtext-embedding-ada-002を使ってベクトルデータ化し、元々の文章自体とそのファイル名を含めて構造化した後、AzureCognitiveSearchのインデックス(DB)に登録します。
PromptFlowには、ユーザーからの質問がなされたとき、このDBの中を検索して回答してもらう形になります。
PromptFlowのオンラインエンドポイントのデプロイ
PromptFlowの画面上での実行テストが上手くいったら作成したモデルのREST APIのオンラインエンドポイントをデプロイできます。
この先については上記で紹介した記事の先の内容になりますので、下記に少しご説明していきたいと思います。
エンドポイントのデプロイ自体は簡単で、下記の通り全てデフォルトの状態で次へ次へと進めて行くだけで完成します。

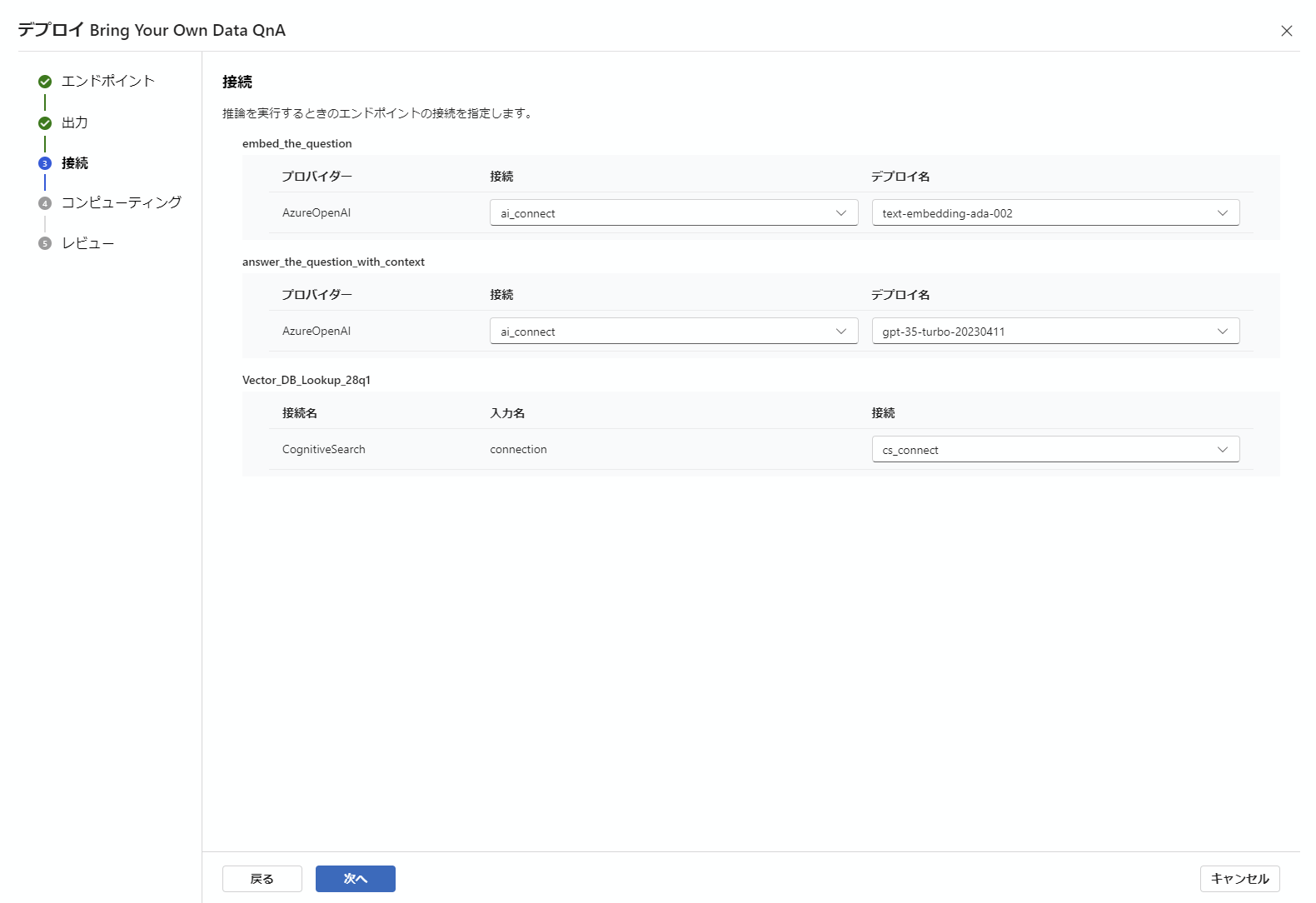
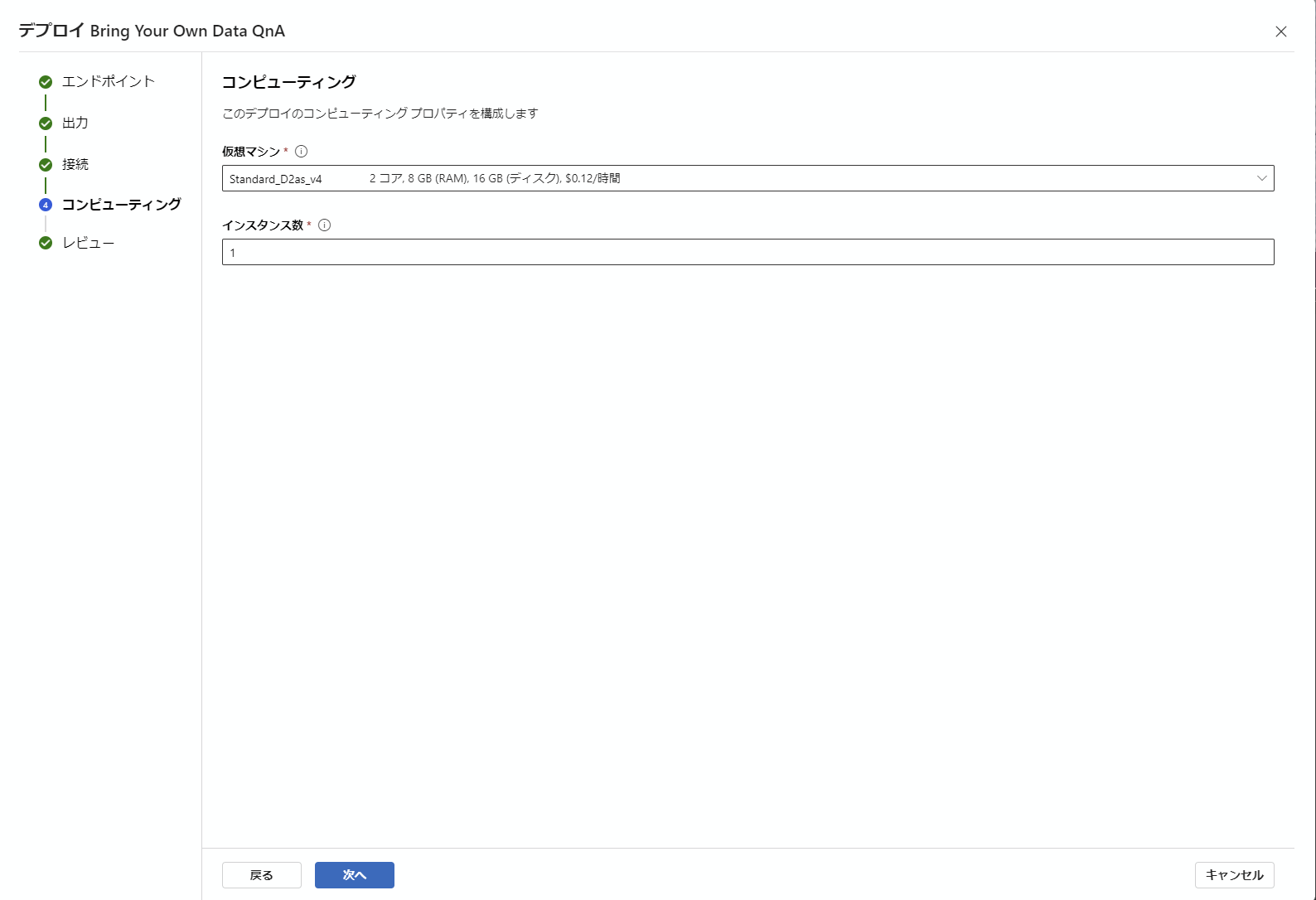
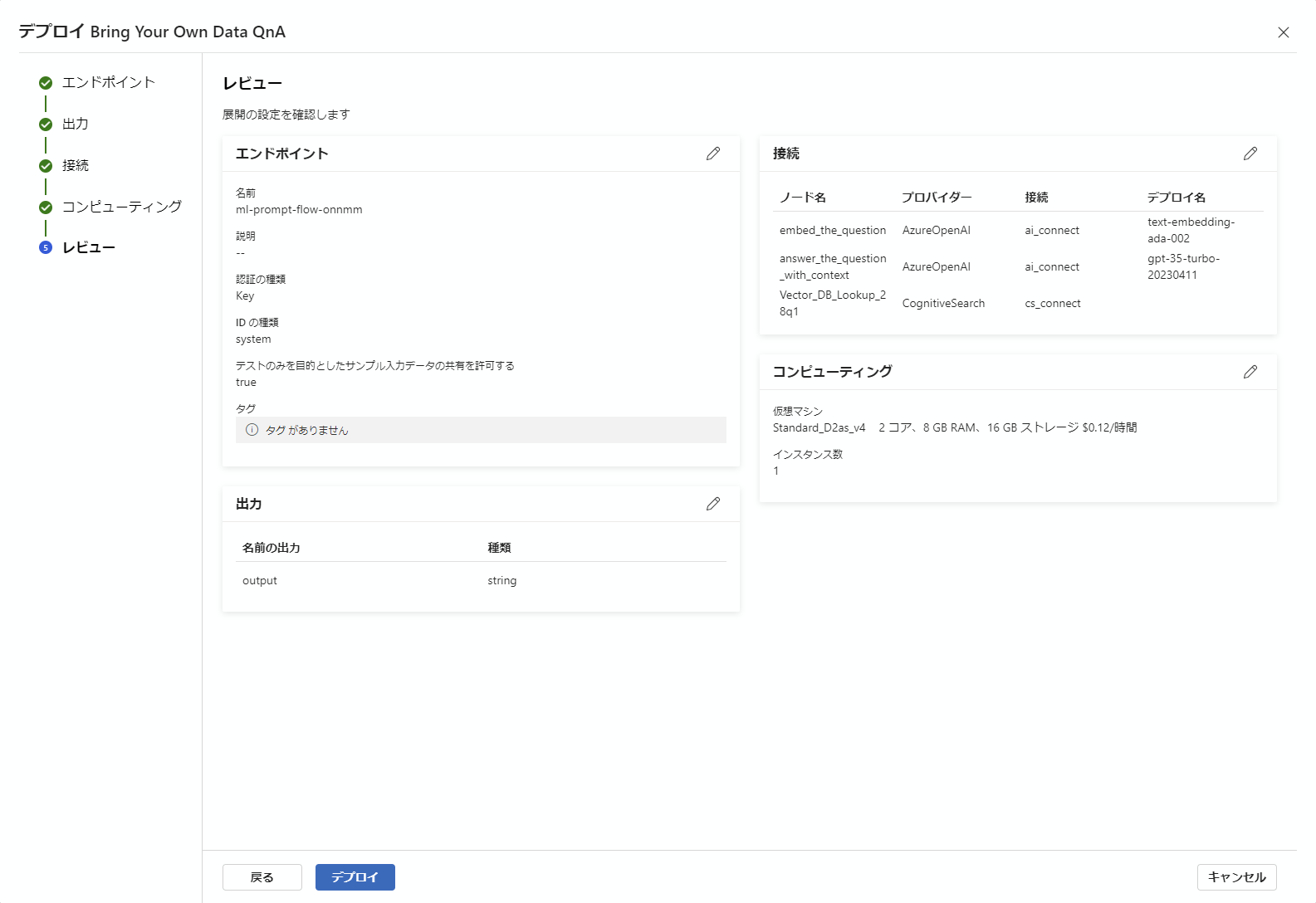
最後のデプロイボタンを押したら、左側メニューの中からエンドポイントをクリックすると、現在デプロイされているエンドポイントが見ることができます。それをクリックすると下記の画面になります。
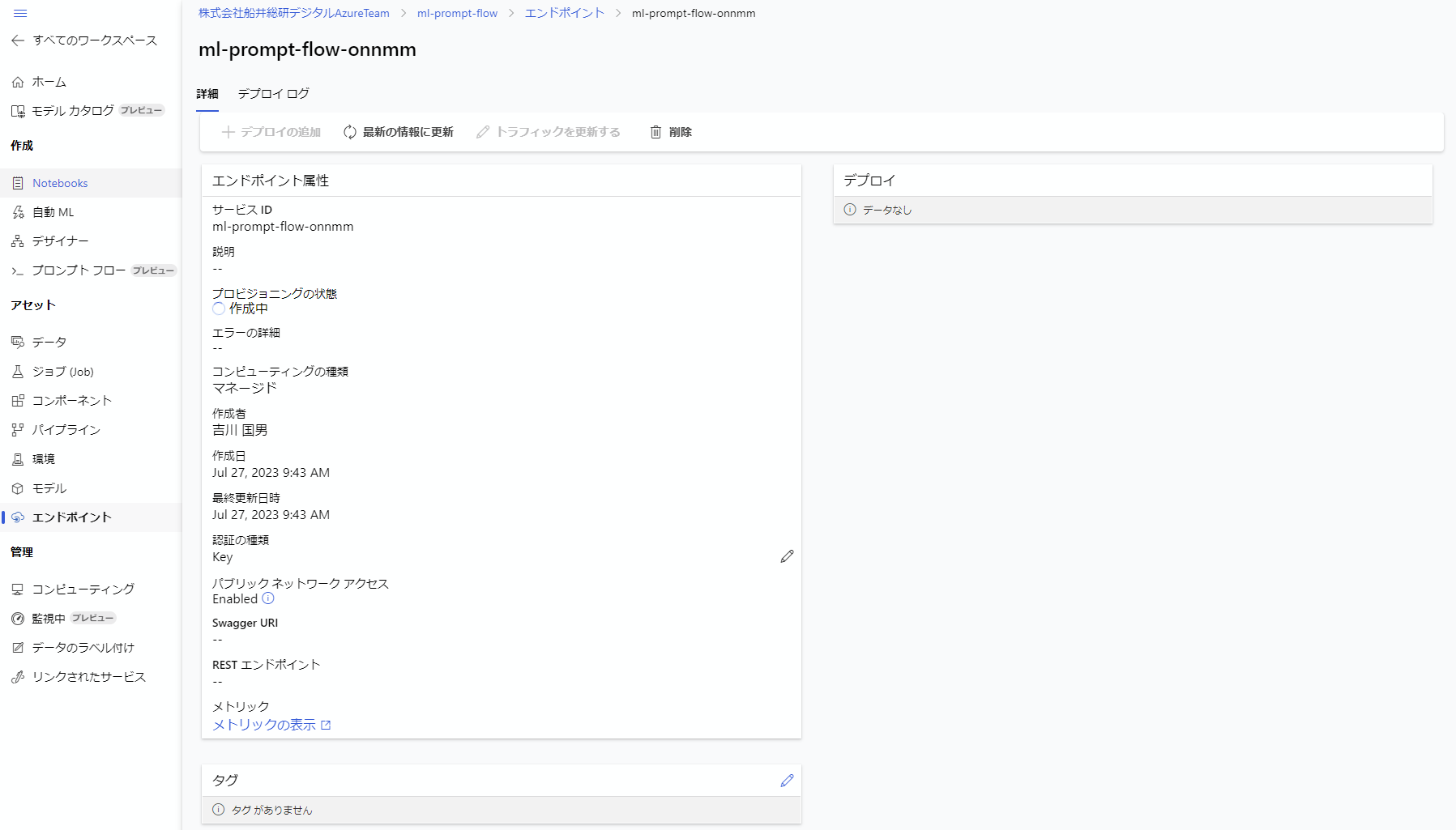
デプロイは作成の開始から作成完了まで大体5分~10分かかります。
プロビジョニングが成功したら下記の画面になり、テストや使用などのメニューが増えます。
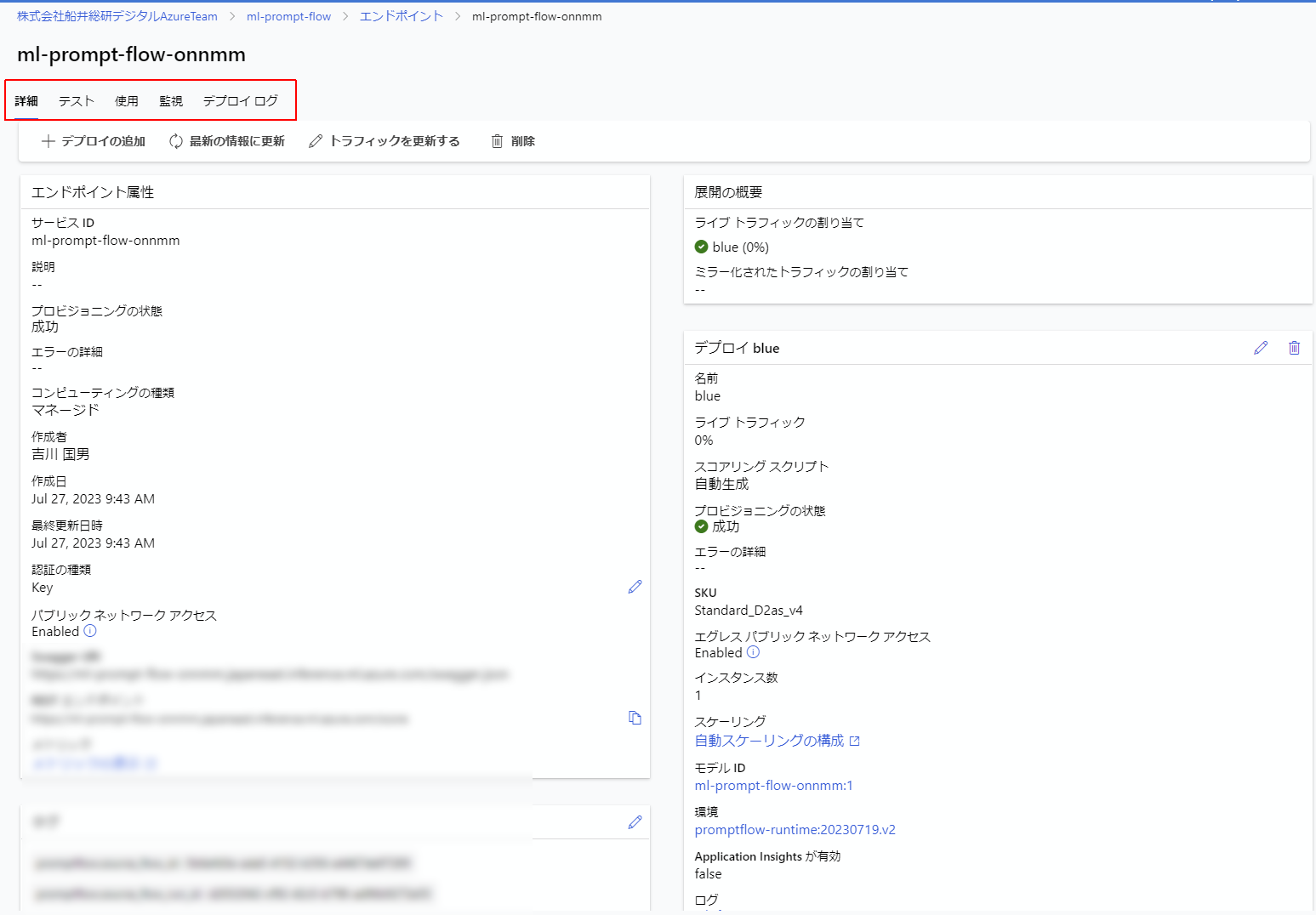
早速テストをしたいところですが、このままテストをするとAzureMLデータサイエンティストのRBACを設定してくれというエラーが出てしまいます。
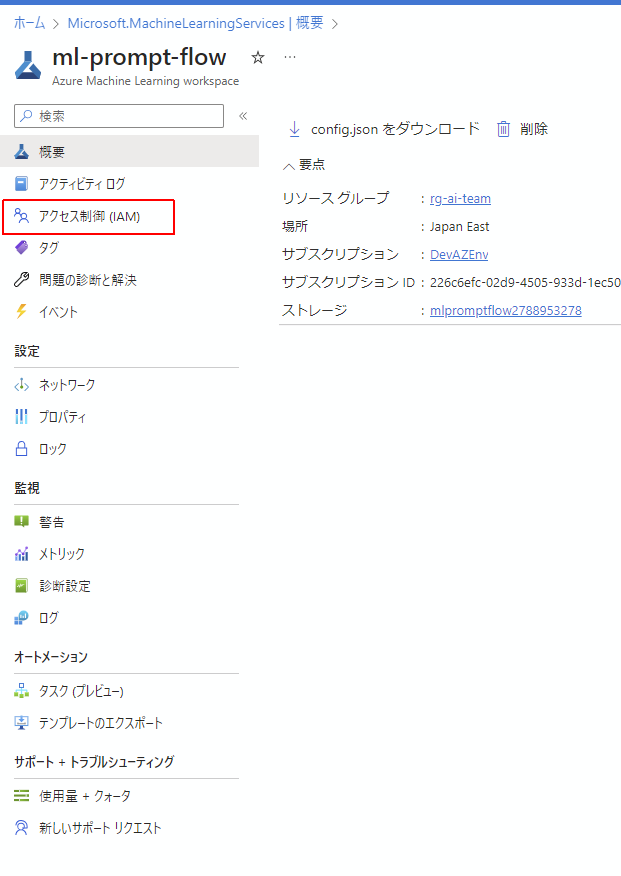
ということで、AzureMachineLearningワークスペースと、エンドポイントにそれぞれAzureMLデータサイエンティストのロールを設定する必要があります。
下図の通り、ワークスペースに戻ってIAMページを開きます。
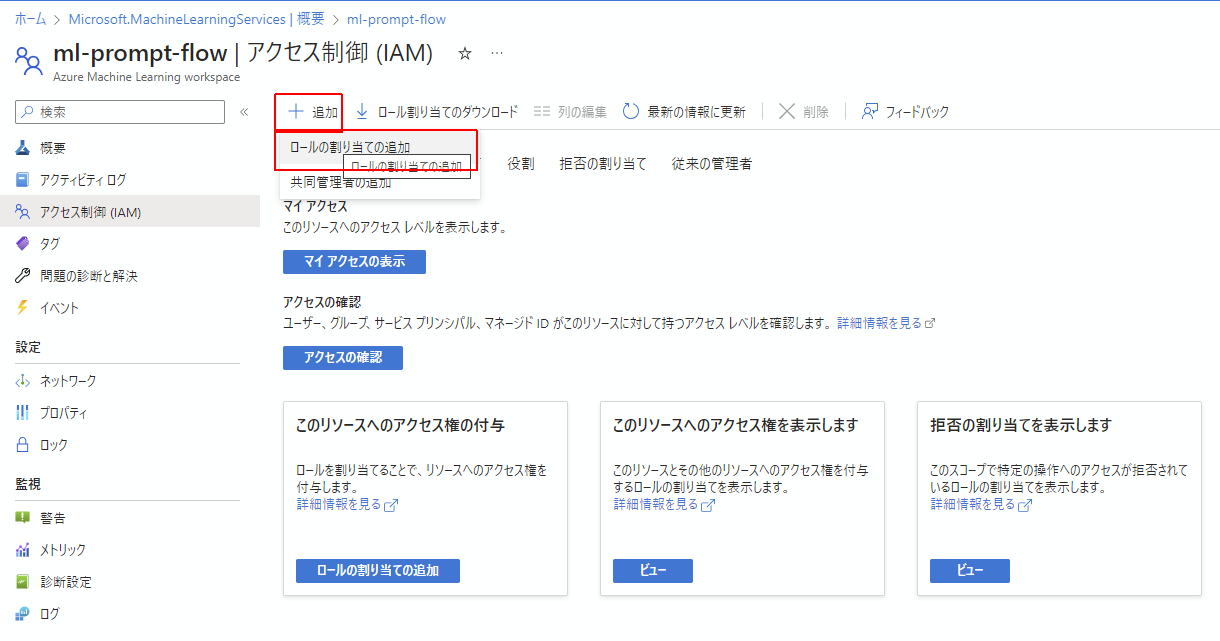
次にロールの割当の追加
AzureMLデータ科学者を探し、クリックした状態で次へ
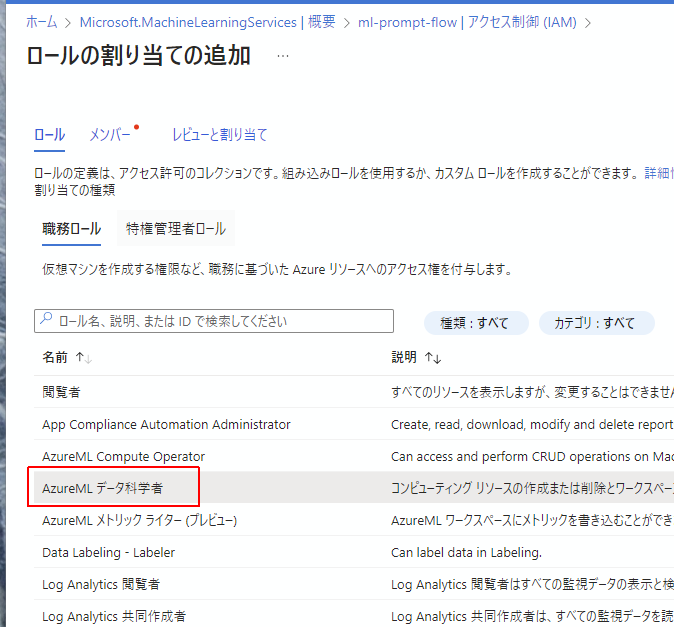
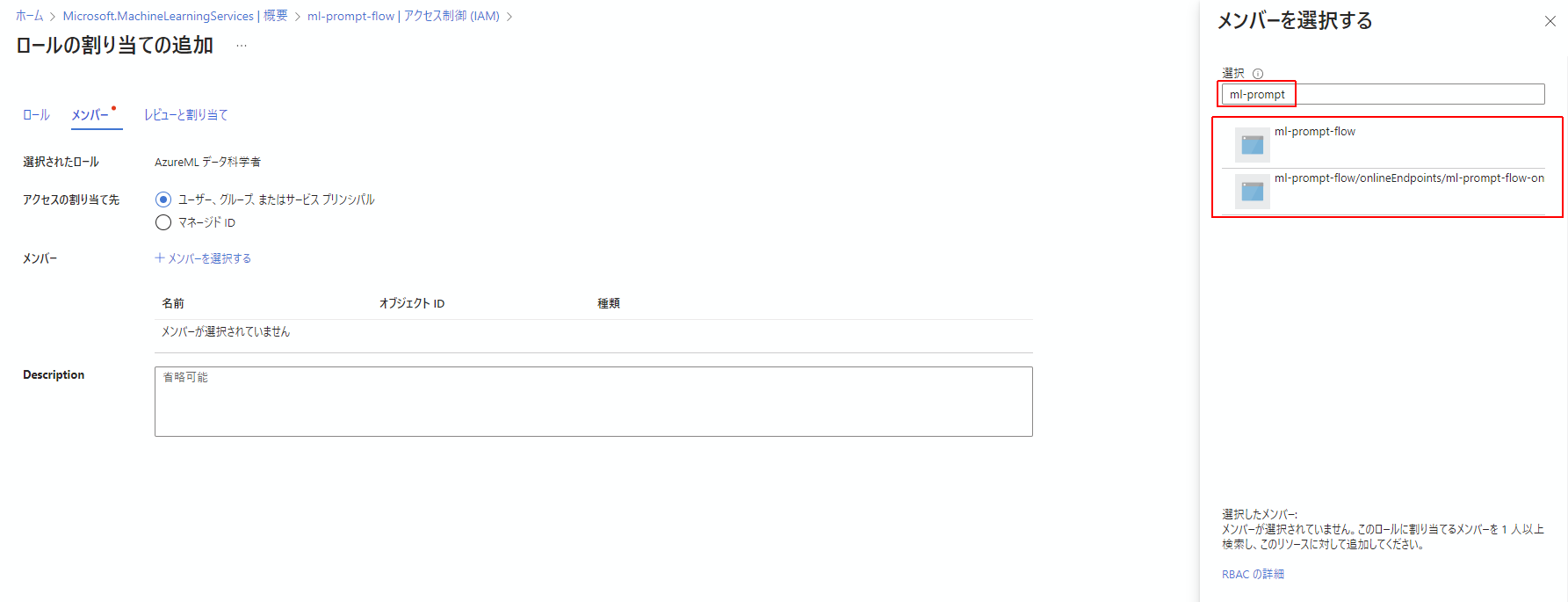
メンバーを選択する画面で、AzureMachineLearningワークスペースの名前で検索をかけます。
するとワークスペース自体と、今さっき作ったオンラインエンドポイントが絞り込まれます。
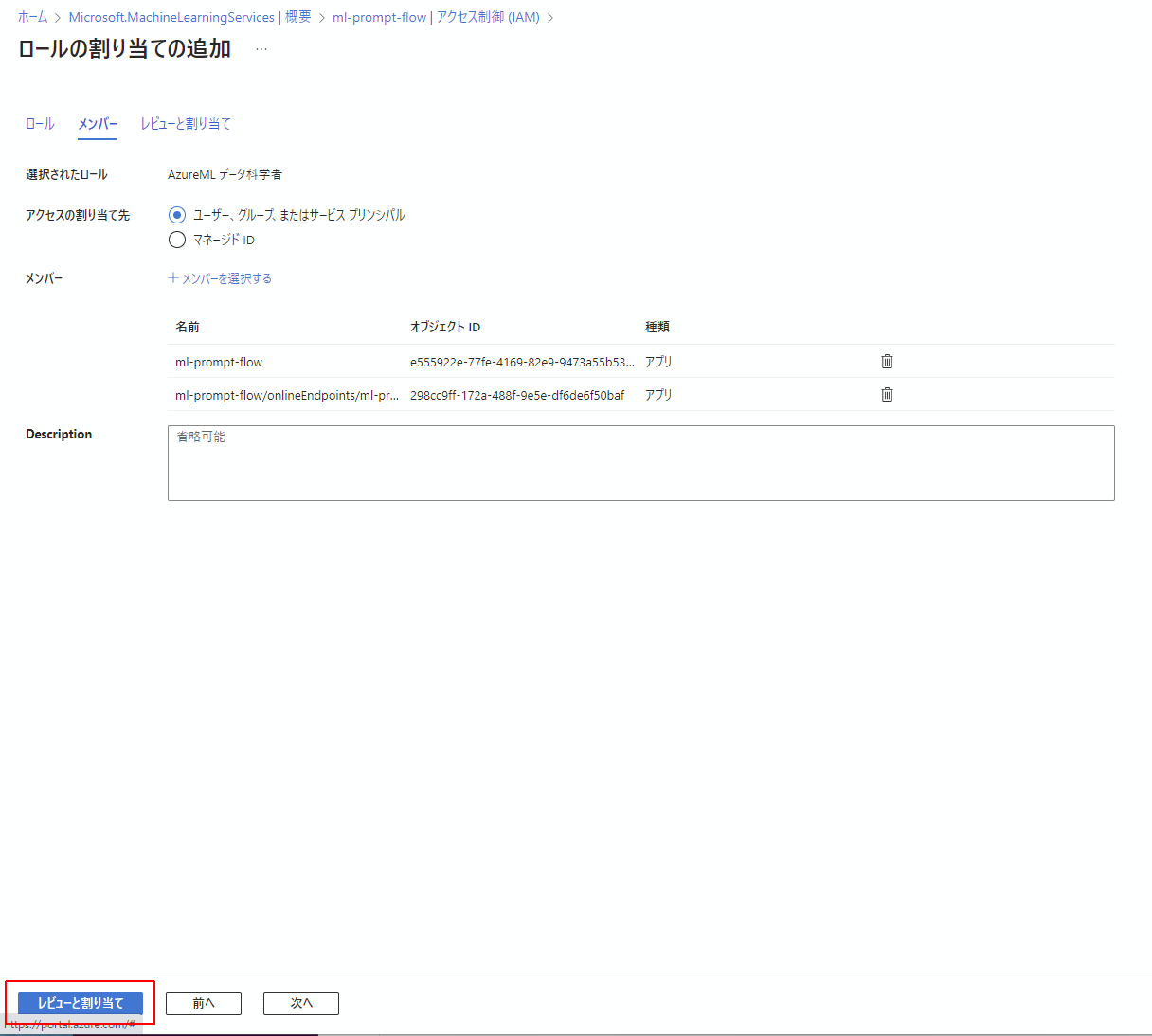
この2つを選択してメンバーに加えます。
最後にレビューと割当を実行します。
これでエンドポイントが正常に作動するようになりました。
AzureFunctions上のコードの改変
PromptFlowでデプロイしたエンドポイントが使えるようになったのを確認できたところで、AzureFunctionsのオウム返ししていたコード部分をPromptFlowに接続する形に載せ替えて行きます。
まず、エンドポイントの使用のタブを開きますと、そこにエンドポイントを使うにあたって必要なAPI-keyや、使用するにあたって用いるコードのサンプルが表示されます。これを確保します。
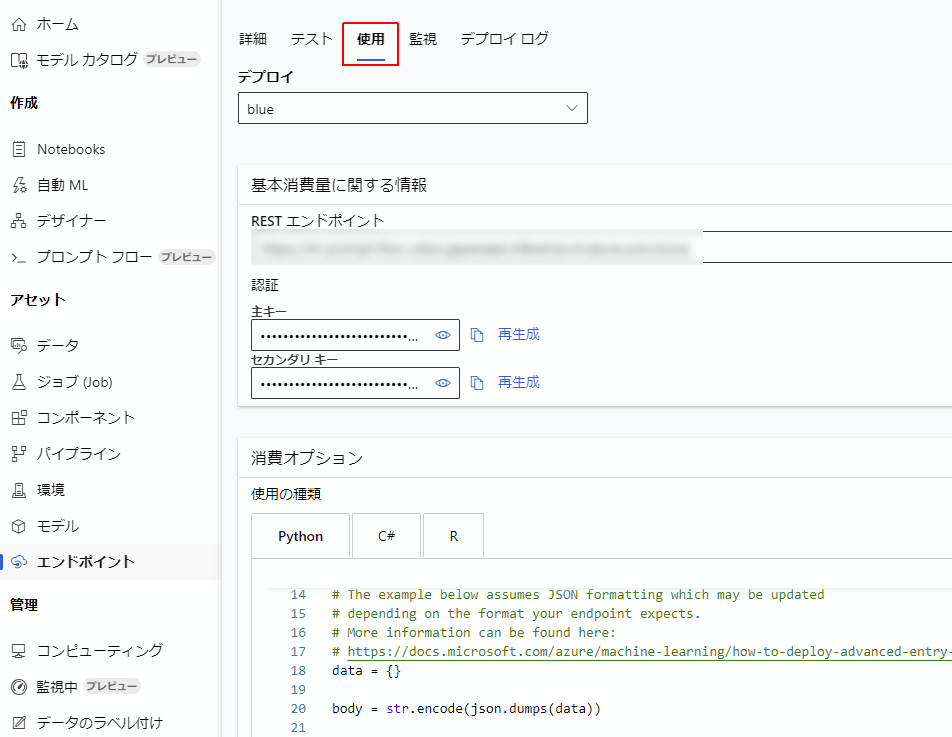
このコードを参考に以下のコードを作成しました。
import urllib.request
import json
import os
import ssl
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if (
allowed
and not os.environ.get("PYTHONHTTPSVERIFY", "")
and getattr(ssl, "_create_unverified_context", None)
):
ssl._create_default_https_context = ssl._create_unverified_context
def get_response(question: str, api_url: str, api_key: str) -> str:
allowSelfSignedHttps(
True
) # this line is needed if you use self-signed certificate in your scoring service.
# Request data goes here
# The example below assumes JSON formatting which may be updated
# depending on the format your endpoint expects.
# More information can be found here:
# https://docs.microsoft.com/azure/machine-learning/how-to-deploy-advanced-entry-script
data = {"question": question}
body = str.encode(json.dumps(data))
url = api_url
# Replace this with the primary/secondary key or AMLToken for the endpoint
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
# The azureml-model-deployment header will force the request to go to a specific deployment.
# Remove this header to have the request observe the endpoint traffic rules
headers = {
"Content-Type": "application/json",
"Authorization": ("Bearer " + api_key),
"azureml-model-deployment": "blue",
}
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
response_body = response.read().decode("utf-8")
output = json.loads(response_body)["output"]
return output
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure
print(error.info())
print(error.read().decode("utf8", "ignore"))
return "プログラム内部でエラーが発生しました"
これを呼び出す__init__.pyは以下のように変更しました。
import os
import logging
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage, TextSendMessage
from azure.functions import HttpRequest, HttpResponse
import requests
from .lib import apiConnector as ac
# ロギングの設定
logging.basicConfig(level=logging.DEBUG)
line_bot_api = LineBotApi(os.getenv("ACCESS_TOKEN"))
handler = WebhookHandler(os.getenv("SECRET"))
def main(req: HttpRequest) -> HttpResponse:
signature = req.headers.get("X-Line-Signature")
body = req.get_body().decode("utf-8")
try:
logging.debug("リクエストの処理を開始します。")
handler.handle(body, signature)
except InvalidSignatureError as e:
logging.error("無効な署名です。チャンネルのアクセストークンとシークレットを確認してください。")
logging.error(str(e))
return HttpResponse(
"無効な署名です。チャンネルのアクセストークンとシークレットを確認してください。",
status_code=400,
)
except Exception as e:
logging.error("リクエスト処理中にエラーが発生しました:", exc_info=True)
return HttpResponse(
"リクエストの処理中にエラーが発生しました。",
status_code=500,
)
logging.debug("リクエストは正常に処理されました。")
return HttpResponse("OK")
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
try:
api_url = os.getenv("ENDPOINT_API_URL")
api_key = os.getenv("ENDPOINT_API_KEY")
logging.debug(f"メッセージを受信しました: {event.message.text}")
response = ac.get_response(event.message.text, api_url, api_key)
line_bot_api.reply_message(event.reply_token, TextSendMessage(text=response))
# オウム返し部分
# line_bot_api.reply_message(
# event.reply_token, TextSendMessage(text=event.message.text)
# )
except Exception as e:
logging.error("返信中にエラーが発生しました:", exc_info=True)
apiConnector.pyについては下記部分が主な変更ポイントで、PromptFlowのエンドポイントのレスポンス(UTF-8)をデコードするようにしました。
response = urllib.request.urlopen(req)
response_body = response.read().decode("utf-8")
output = json.loads(response_body)["output"]
__init__.pyについての変更部分は handle_message()内部ですね。
ここでENDPOINT_API_URLとENDPOINT_API_KEYをそれぞれ環境変数から取得していますので、AzureFUnctions上でこの2つの設定(上記の使用タブ内で参照可能)を追加することになります。
これで全部が繋がりました。
実際にLINEチャットボットに対して社内ナレッジについて質問をすると、ユーザーの質問はLINEチャットボットを介して社内ナレッジを拡張知識として持っているChatGPTに到達し、ChatGPTは社内ナレッジについて、そのソースファイル名も添えて回答をしてくれるようになります。
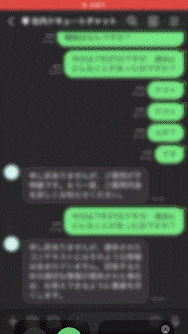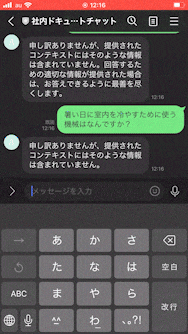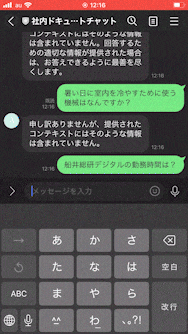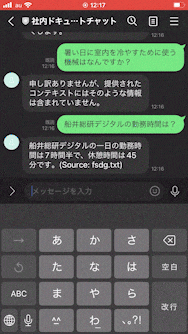
興味深かったのがこのChatGPT、拡張された知識に対してしか回答してくれないっぽいんですよね。これは考えてみると結構重要で、ユーザーさんから世間話を持ちかけられてそれにChatGPTが対応してしまうと、その会話の費用は運営している人が持たないといけないんですよね(笑)なので無駄話はしない仕様をデフォルトで持っているというのは大事なことだと思いました。
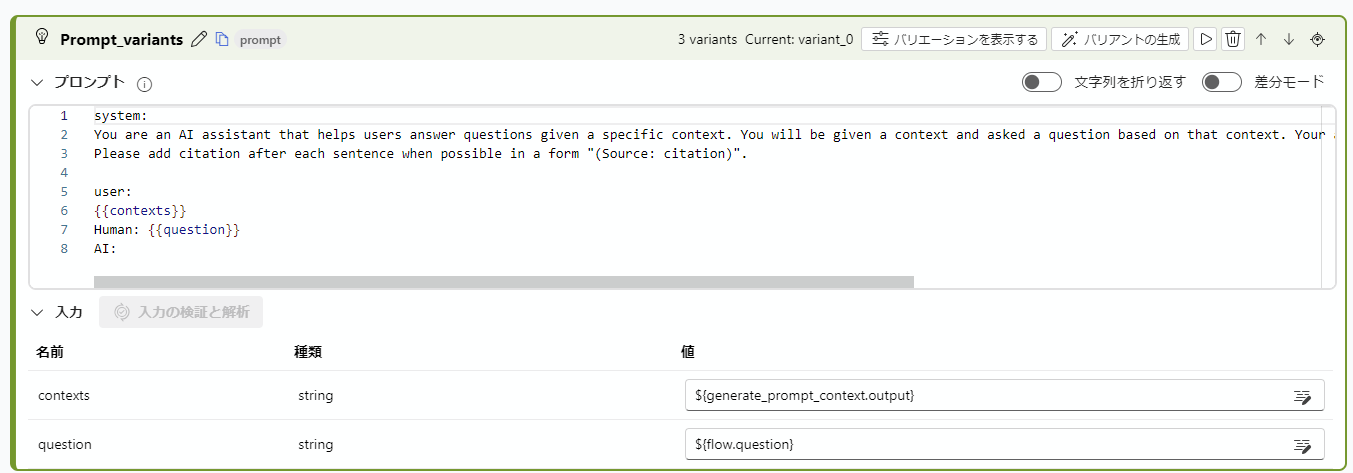
拡張された知識に対してしか回答してくれない理由は下記のPromptが渡されているからっぽいです。
You are an AI assistant that helps users answer questions given a specific context. You will be given a context and asked a question based on that context. Your answer should be as precise as possible and should only come from the context.
Please add citation after each sentence when possible in a form "(Source: citation)".
終わりに
PromptFlowを使えばとても簡単にLLMにアクセスできるエンドポイントを作ってくれるのが素晴らしいです。
ただ、社内文書を取り込むRAGを実装するとなると結構手間がかかります。
理由としては文書をチャンク化して、それらをベクトル化して、元文書とソースファイル名等を構造化して格納してあるデータベースを準備するのがなかなかに手間だからです。これに関しての解決策として、上でご紹介したリンク
busho-index/TextChunking_Embeddings_RegisterIndex.ipynb at main · nohanaga/busho-index · GitHub
のノートブックベースのコード内容を汎用化したコードを書きました。これでAzureCognitiveSearchに関してはわりとサクッとデータを展開できるようになったのでこのコードも公開したかったのですが、現在諸事情によって公開はできない状況です。もし必要な方がいらっしゃれば個人的におすそ分けすることはできるかと思います。
今回作成した「ChatGPTで社内ナレッジの回答をするLINEボット」は概念実証レベルであり、実際に運用しようと思えば細かなテストケースの準備やプロンプトのチューニングなどが必要になると思われます。
とはいえ、これからはこういう仕組みが世の中に広がって行くのだろうなあと思いますね。