Azure Machine Learning に Prompt flow が搭載され、パブリックプレビューが開始されました。Prompt flow は大規模言語モデル (LLM) を利用した AI アプリケーションの開発サイクル全体を合理化するように設計された新時代の開発ツールです。
Azure AI Studio
Azure AI Studio は Azure OpenAI Studio の Chat Playground や Azure Machine Learning の Prompt flow を包含するサービスというイメージですが、まだ全貌は明らかになっておりません。 Prompt flow は現状は Azure Machine Learning の中の 1 機能として公開されましたが、今後は Azure AI Studio なる UI からも呼べるようになるのではないかと思います。
Azure AI Studio は Copilot stack における AI オーケストレーションの層を担う重要なコンポーネントです。

さらに、Prompt flow の中で使用できる機能スタックにブレークダウンします。

基本的には Azure ML のコンピューティングインスタンス(VM)上の Python 実行基盤となり、OpenAI モデルや Azure Cognitive Search、Faiss のベクトルインデックスなどを接続して Grounding することができます。Prompt flow ではプロンプトエンジニアリングの評価・比較を行ったり、完成したオーケストレーターをマネージドオンラインエンドポイントにデプロイして、UI から呼び出せるようにできます。
Azure Cognitive Search
Azure Cognitive Search は Prompt flow にネイティブ対応しており、「Vector DB Lookup」ツールを利用してベクトル検索することができます。モデルが知らない内容を外部検索システムから検索した情報を付加して質問などに回答させる Retrieval Augmented Generation(RAG) を構築可能です。

本日はこのようなアーキテクチャ(の RAG 部分)を Prompt flow を使って実装していきましょう。
Prompt flow の構築
コネクションの作成
Azure OpenAI との接続
Azure OpenAI リソースを作成し、Embeddingsモデル「text-embedding-ada-002」とチャット系の「gpt-35-turbo」モデルをデプロイしておきます。

「接続」タブから「AzureOpenAI」を選択します。

Azure OpenAI の接続情報を入力します。API version に最新 GA 版の 2023-05-15 と入れると、Prompt flow の「deployment_name」ドロップダウンに選択肢が表示されない現象が出ました。(自分だけ?)一度デフォルトの 2023-03-15-preview でフローを作成してから、接続設定を変更するとギリいけました💦 裏技…
Azure Cognitive Search との接続

「接続」タブから「CognitiveSearch」を選択し、Azure Cognitive Search への接続情報を入力します。ベクトルインデックスはいつもの戦国武将データを使っています。
ランタイムの作成
Prompt flow の実行基盤であるコンピューティングインスタンス(VM)を作成し、ランタイムとしてアタッチします。ちょっとしたテストにしか使いませんので、お安い「STANDARD_DS2_V2」にしました。

Prompt flow の作成
「フロー」タブから「+作成」ボタンを押して、ギャラリーから「Bring Your Own Data QnA」を選んで「詳細の表示」を押してから「複製」ボタンを押せば自動的に展開されます。

入力
ランタイム設定のところに、作成済みのランタイムをアタッチします。次にフローの一番上の「入力」にテストする質問を入力します。

Vector DB Lookup ツール
デフォルトのフローではベクトルインデックスが FAISS のインデックス になってしまっているのでこれをゴミ箱ボタンを押して削除します。

次に「+その他のツール」から「Vector DB Lookup」ツールを選択し、以下のように作成済みベクトルインデックスへのマッピングを行います。

重要なのは vector クエリフィールドですね。ここにはひとつ前のノードである「embed_the_question」ノードの出力結果 ${embed_the_question.output} を指定する必要があります。Azure Machine Learning のフローは有向非巡回グラフを形成し、前後のノードの関連性はデータの入出力によって決定されます。
Source フィールドについて
デフォルトでは、「ファイル名」のフィールドが無いですね… これは次のノードである「generate_prompt_context」コードを以下で置き換えることで取得することができます。
from typing import List
from promptflow import tool
from embeddingstore.core.contracts import SearchResultEntity
@tool
def generate_prompt_context(search_result: List[dict]) -> str:
def format_doc(doc: dict):
return f"Content: {doc['Content']}\nSource: {doc['Source']}"
SOURCE_KEY = "sourcepage"
#URL_KEY = "url"
retrieved_docs = []
for item in search_result:
entity = SearchResultEntity.from_dict(item)
content = entity.text or ""
source = ""
if entity.original_entity is not None:
if SOURCE_KEY in entity.original_entity:
source = entity.original_entity[SOURCE_KEY] or ""
#if URL_KEY in entity.original_entity[SOURCE_KEY]:
# source = entity.original_entity[SOURCE_KEY][URL_KEY] or ""
retrieved_docs.append({
"Content": content,
"Source": source
})
doc_string = "\n\n".join([format_doc(doc) for doc in retrieved_docs])
return doc_string
コードを置き換えたら、以下のように前のノードの出力を入力にセットすることで、ノード間の関連が作成されます。

Python コード内で print した場合は「出力」の「ログ」タブに標準出力が表示されます。
Vector DB Lookup ノードの前後の関係が完成
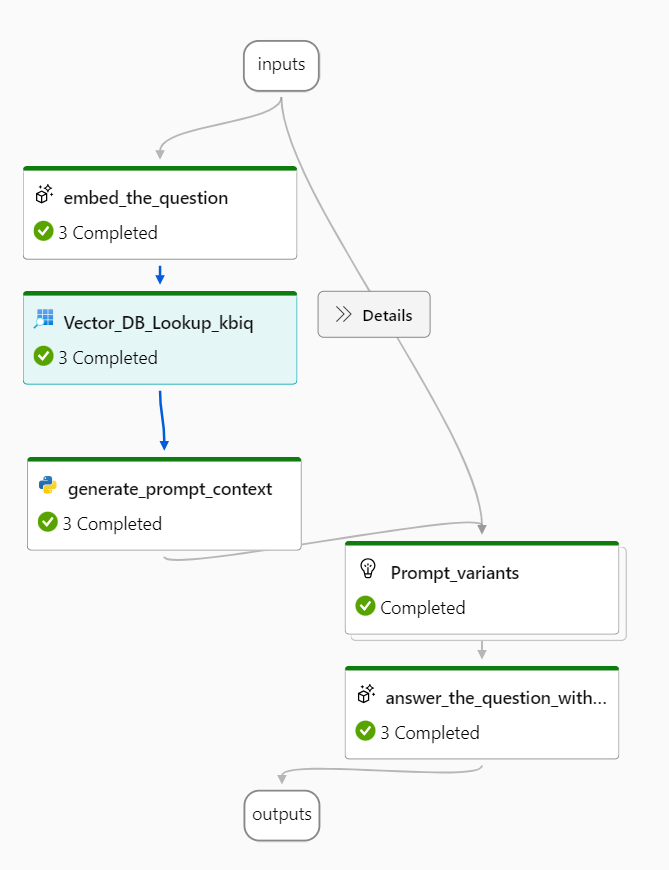
Prompt variants でプロンプトエンジニアリングの比較を実施
プロンプトエンジニアリングの評価・比較ができる目玉機能です。「Prompt_variants」ノードを見るとデフォルトで 3 種類のプロンプトが比較対象として登録されています。variants に登録しておけば、同じインプットデータで結果がどう変わるのかを一覧で比較できるのです。
Variant_0 英語の system プロンプト

Variant_1 日本語の system プロンプト

+αで Few-shot サンプルを入れた variant も加えます。プロンプトフローの評価のみを行う場合は評価フローテンプレートを利用できます。利用可能な評価メトリクスは以下を参考にしてください。
フローの実行
右上の「実行」ボタンを押してバリアントを実行するノードを選択して「送信」ボタンを押すとフロー全体の処理が実行されます。「実行が完了しました」と表示されたら、以下の「出力の表示」ボタンを押して結果を確認します。

用意した 3 種類のプロンプト variant の実行結果がそれぞれ表示されました。

なんか output 欄小さくない?気づいた点はフィードバックしましょう。

ブラウザの DevTools のようなトレース機能もついており、処理時間をノードごとに可視化できます。
デプロイ
完成したフローをリアルタイム推論用のマネージド オンライン エンドポイントへデプロイできます。

さいごに
プロンプトエンジニアリングの評価を簡単に行えるようになったというのは非常に便利ですね。テストデータを用意して一括テストする機能もあるので、今後 LLM 開発の重要なツールになりそうです。
パブリックプレビュー開始時点では、Build の動画にあった Semantic Kernel ボタンや LangChain ボタンがありませんね。こちらは登場まで待つ必要があるかもしません。