1. はじめに
大規模言語モデル(LLM)が回答を生成するとき、内部でどんな判断をしているのか気になりますよね。
その見えない内部シグナルを探る方法の一つにプロービングという手法があります。
この記事では、Qwen3 235B A22B Thinking 2507 をベースにQLoRAで訓練したモデルを対象に、回答生成時の内部表現(隠れ状態)を取得し、どの層に正誤を判断するための(妥当性判断)情報が現れるのかを、プロービングによって可視化する方法を紹介します。
このモデルを訓練したのは、松尾研LLM開発コンペ2025 におけるoNo.1チーム(決勝戦では、チームきつねと統合、また蝉時雨・朱雀・TruthOwl・Cogito・ねこ・Promptia・K.A.T.Oチームからの志願メンバーも含む)です。
記事の前半では、コンペの決勝においてどのようなベンチマークに対し、訓練によってモデルの成績がどのくらい伸びたかを、評価部門の立場から報告します。
後半ではプロービングにより、訓練前後で内部表現における妥当性を判断する特徴のエンコーディングがどのように変化したかを示します。
1.1 想定読者
- 松尾研LLM開発コンペに参加したい/した方
- LLMの内部表現の解析手法であるプロービング(Probing)に興味のある方
2. コンペのベンチマークについて
松尾研LLM開発コンペ2025のメインのベンチマークは Humanity's Last Exam(通称HLE) 、日本語に訳すと「人類最後の試験」という終末論的なネーミングのデータセットです1。
HLE公開以前の、既存のMMLUなどのベンチマークは、すでに最先端のLLMが90%超の精度を達成してしまったため、「ベンチマーク飽和」危機に陥っていました。
これを解決するため、Center for AI Safety と Scale AI が共同で開発した2HLE(2025年1月24日にバージョン1発表)は、2025年11月現在もモデル単独では精度30%を破られずに3、フロンティアモデルの学術的能力の限界を測るもっとも有名なベンチマークの一つになりました。
HLEの問題4は、公開時点の State-of-the-Art モデルが解けない難問のみを採用しているだけに、私が翻訳して内容を読んだとしても問題の意味をほとんど理解することができません5。
HLEの論文は、開くと3ページ目までデータセットの貢献者および監査役の名前がびっしり並び、4ページからAbstractが始まる、冒頭が印象的な論文です。
作問者の人数も多いですが、特定の作問者が数十個の問題に寄与しているケースも多くみられます(「人文社会」分野の作問者と問題数の可視化↓)。

HLEの問題カテゴリと回答形式(完全一致問題 OR 多肢選択問題)の構成を見ると(下のグラフ)、数学問題が42.5%を占め、76%が完全一致問題(出力された文字列が完全一致するか否かを評価)でした6。

※ 簡易的ですがインタラクティブなグラフはこちら
3. ベースモデルの推論
私たちのチームは、コンペの決勝戦で、Qwen3-235B-A22B-Thinking-2507(以下、Qwen3-235B-A22B)をベースモデルとしました。
モデル推論時のパラメータは、HLE開発元のScale AIが公開する HLE(Text Only)のダッシュボード のQwen3-235B-A22Bに付随する!マークのポップアップを参考にし(下図)、max_tokens(max_completion_tokens)は32,768(出力トークン合計)に設定しました。
temperatureについては、1度しかサンプリングしないことから(多数サンプリングを行うTest-Time Scalingはコンペのルールでは使用不可)、0.6ではなく、決定論的なサンプリングを行う0.0を採用しました。

この設定でベースモデルがHLEを解くと、有効な回答数が1,743件/2,158件(有効回答数 / 全問題数)で、正解が293件という結果になりました。
不正解には、モデルの回答が無効のケースと、モデルの回答は有効だが答えを間違っているケースの2種類があります7。
つまり、不正解を減らすには、モデルの有効な回答数を増やすか、現在の有効な回答の中で間違いを減らすか、の2つの方向性が考えられます。
ここで、同じ設定でコンペ予選時のベースモデルDeepSeek-R1-0528と、Qwen3-235B-A22Bを比較してみました。
| 有効回答数 | 正解数 | |
|---|---|---|
| Qwen3-235B-A22B | 1719 | 323 |
| DeepSeek-R1-0528 | 1960 | 290 |
Qwen3-235B-A22Bは、DeepSeek-R1-0528と比べて有効回答数こそ少ないものの、有効回答に対する正解率(正解数 / 有効回答数)は高く、モデルの推論品質はより優れていると考えられます。
一方、有効回答数の少なさには、推論能力以外の要因(長い思考の連鎖によるmax_tokens超過やフォーマット崩れ)が影響している可能性があります。
この特徴を踏まえ、有効回答数そのものを増やすよりも、まずは既存の有効回答における誤答を削減し、推論の正確性を改善することを優先しました。
4. モデルの外部出力の評価
決勝では33ものモデルが開発されました。
以下は、ベースモデル含む34モデルのスコア比較です。トップモデルのスコアは15.89%、ベースモデルは13.57%なので、2.32%ほどスコアが伸びました。

※ 黄色い各点はAccuracy(正解数/全問 = 正解率)スコアを、赤いバーは95%信頼区間(真の正解率pがこの範囲にあると95%の確率で言える区間)を示す。左端の青い矢印はAccuracyがトップのモデル(difficult_problem_dataset_v4_500_n500)を、右側の青い矢印はベースモデル(qwen3-235b-a22b-thinking)のスコアを指している。
4.1 oNo.1チームのQLoRA
私たちのチームはこのトップモデルの訓練にQLoRAを採用し、ベースモデルのTransformerの最終ブロックにあるQwen3MoeAttentionの各線形変換の重み行列(W_Q, W_K, W_V, W_O)に対してのみLoRAアダプタ(ΔW_*)を追加し、このLoRAのパラメータを学習させました。
以下は、LoRAアダプタの挿入位置のイメージ↓
[ Transformer Block L−1(最終ブロック) ]
│
├─ input_layernorm: h_norm = LayerNorm(h_{L−1})
├─ Qwen3MoeAttention
│ ├─ Q_raw = h_norm @ (W_Q.T + ΔW_Q) ← LoRAアダプタ追加
│ ├─ K_raw = h_norm @ (W_K.T + ΔW_K) ← LoRAアダプタ追加
│ ├─ V = h_norm @ (W_V.T + ΔW_V) ← LoRAアダプタ追加
│ ├─ Q = RMSNorm(Q_raw)
│ ├─ K = RMSNorm(K_raw)
│ ├─ 各ヘッド出力: Q̂_i = softmax(Q_i K_iᵀ / √d) V_i
│ └─ 出力統合:
│ O = Concat(Q̂₁,…,Q̂ₕ) @ (W_O.T + ΔW_O) ← LoRAアダプタ追加
│
※ 上の図のh_{L−1}は前段ブロック(L−2)が生成した隠れ状態(hidden_states)を示す。隠れ状態は、各ブロックでの注意機構やMLPが加える変換を通じて、情報が選択的に強調された高次の表現へと更新されていくベクトルのこと。
通常は数千次元規模の連続ベクトルで、トークンの意味的・構文的情報や、推論に必要な関係性が圧縮された内部表現となっている。
※ oNo.1チームのモデル開発の詳細は、下記モデル部門メンバーの記事をご覧下さい(`・∀・´)
- Qwen3-235B-A22B-Thinking-2507にHARIする方法について
- LLMモデル開発初心者がDeepSeek R1 6,710億パラメータのマルチノード推論・SFTを成功するまでの記録
5. モデル内部からの評価
前述のように、モデルの外部出力をスコアで評価すると、トップモデルがベースモデルより勝っていました(15.89% vs 13.57%)。
私たちのチームの、最終ブロックのみLoRAアダプタを挿入するParameter-Efficient Fine-Tuning(PEFT)手法は、ベースモデルにほとんど変更を加えていないため、ベースモデルとのスコア差は誤差範囲ではないかと、自分たちですら疑うこともありました。
そこで、トップモデルがベースモデルに勝っていることを示す特徴はないものかと思い、コンペが終わった今、プロービングを用いてLLMの内部表現を調査することにしました。
5.1 プロービングとは
プロービング(Probing)とは、ニューラルネットワークモデルの内部表現(隠れ状態)にどのような情報がエンコードされているのかを調べるための実験的な解析手法です。
具体的には、モデルのある層(あるいはブロック)の内部表現から、特定の属性(例:文法構造やタスクの難易度など)を線形分類器8などで予測するタスクを作り、分類性能を測ることで内部にその属性情報が存在することを推定します。
プロービングは従来、言語的特性の有無を問うシンプルな目的で用いられていましたが、エラー検出などの高次の内部シグナルを解析する研究へと応用範囲が広がってきています。
5.2 プロービングの応用
Orgad et al.(2024)では、応用的なプロービングタスクを設計し、LLMが外部出力でHallucinationを起こすことを、LLMの内部表現から予測できる(エラー検出できる)ことを示しました。
この結果は、LLMが外部出力で誤答していても、内部表現には誤りであることを示す手がかりが潜在的に保持されている可能性を示唆しています。
この論文のプロービングをさらに応用して、コンペの2つのモデルの内部表現を比較すれば、妥当性(例:この文は数学的に正しい)に関する情報に差異が見つかる可能性があります。
そこで、「コンペのトップモデルがベースモデルより性能が高いのであれば、内部表現に妥当性に関する特徴がより強くエンコードされているはずだ」という仮説を立てて、プロービングを用いて検証してみました。
5.3 妥当性を内部表現から予測する
「内部表現に妥当性に関する特徴がより強くエンコードされている」とは、例えば問題文「+45と-30の和は-15である」をLLMに入力し、それが妥当かどうかを推論させた際の内部表現に、その問題の妥当性を示す手がかりが潜在的に含まれている、という状態を指します。
ロジスティック回帰のような分類器に、このLLMの内部表現を特徴量として入力し、CONSISTENCY(1)/ INCONSISTENCY(0)というラベル(※問題文が数学的に正しい場合は1、誤っている場合は0)を予測するように分類器を訓練すれば、「内部表現に妥当性情報がどの程度表れているか」を調べるプロービングが成立します9。
もし分類器が高い精度で妥当性を予測できれば、それはLLMの内部表現が問題文の妥当性を識別するための特徴を潜在的に保持していると考えられます。
したがって、「内部表現に妥当性に関する特徴がより強くエンコードされている」という仮説が支持されます。
5.4 実験データセット準備
まずは、LLMの推論用のデータセットを準備します。5択のMCQ(多肢選択式質問)のAquA-RAT(Apache License 2.0)を、妥当性(※問題文が数学的に正しいかどうか)を推定する問題形式に加工しました。
元の問題サンプル
{
"query": "Q: A sales person gets a 10% commission on each sale he makes. How many sales of $250 each must he make in order to reach a salary of at least $1000? Answer Choices: (A)15 (B)24 (C)25 (D)40 (E)52\nA: Among A through E, the answer is",
"choices": ["(A)15", "(B)24", "(C)25", "(D)40", "(E)52"],
"gold": [3]
}
LLMに与える指示は、元の5択の問題サンプルに対する生徒の選択肢を1つ提示し、この選択肢が妥当かどうかを教師として判定させるようなプロンプトを作成しました。
回答は、1~2文の簡潔な推論を示した後、CONSISTENCYかINCONSISTENCYを答えるように指示しました。
加工したプロンプト
"""You are given a student's answer to a problem.
Please check whether each step and the final conclusion are self-consistent.
You may show your reasoning in 1–2 concise sentences, then fill in the following fields.
Student reasoning:
Q: A sales person gets a 10% commission on each sale he makes. How many sales of $250 each must he make in order to reach a salary of at least $1000? Answer Choices: (A)15 (B)24 (C)25 (D)40 (E)52
A: Among A through E, the answer is
The student claims the answer is: (D) 40
Your response:
Reasoning (brief):
CONSISTENCY:
"""
5.5 内部表現の取り出し
今回検証したいコンペの2つのモデル(235B)のファイルサイズはどちらも470GBです。
この実験で、HLEほど高度な推論を求めるデータセットは使用しないので、推論時のモデルを4bit量子化することにしました。
bf16のモデルファイルをストレージに保存し、4bitに量子化してGPU RAMへロードすると、GPU RAM 80GB * 2でも推論が可能になるため、NVIDIA A100(80GB)*2基と、SSD 600 GBの環境を用意しました。
コンペ時のような潤沢な実行環境を自腹で用意できないので、コストを$100未満に抑えられるよう最小限の構成でインスタンスを借りました10。
前述の加工したプロンプトをLLMに与え、出力トークンを1つ生成するたびに、その最後の内部表現を4ブロック分(最終ブロックから遡って4ブロック)抽出しました(例:hidden_states[Li][:, -1, :]11で、i番目のブロックの最後のトークン位置の隠れベクトルを抽出する)。
合計で96トークン分の内部表現を取り出しました。この抽出をデータセット254サンプル分繰り返します。
抽出したすべての内部表現ベクトルのshapeは[254, 96, 4, 4096](内訳:[num_samples, NUM_STEPS, NUM_LAYERS_KEPT, HIDDEN_DIM])です。
5.6 プロービングの結果
ロジスティック回帰(Probe)に、前述した内部表現と、正解ラベル {1: CONSISTENCY, 0:INCONSISTENCY} をペアで入力して学習させます。
ここで内部表現(hidden_states)は各トークン位置および各ブロックで独立に評価したいため、各ステップ × 各ブロックごとに1つのProbeインスタンスを個別に訓練します。1ステップ分(1トークン分)のブロックごとの内部表現の抽出からProbeの出力までを下図のように表せます。

具体的には、各Probeが受け取る特徴量は[train_samples, HIDDEN_DIM](特定のstepとlayerのhidden vectorのみ)であり、これらをNUM_STEPS × NUM_LAYERS_KEPT個分それぞれ独立に学習します。
Probeの性能(分類器の予測スコア)は、プロービングの先行研究で用いられているAUC(Area Under the ROC Curve)で評価します。
AUCは、正例(1)と負例(0)のペアを比較したとき、本来高いスコアを持つべき正例の方が、負例よりも高いスコアが割り当てられるケースが多いほど、値が大きくなる指標です(0〜1の範囲)。
この指標を用いることで、モデルの内部表現に問題文の妥当性に関する情報がどれくらい明確にエンコードされているかを、閾値に依存せず評価できます。
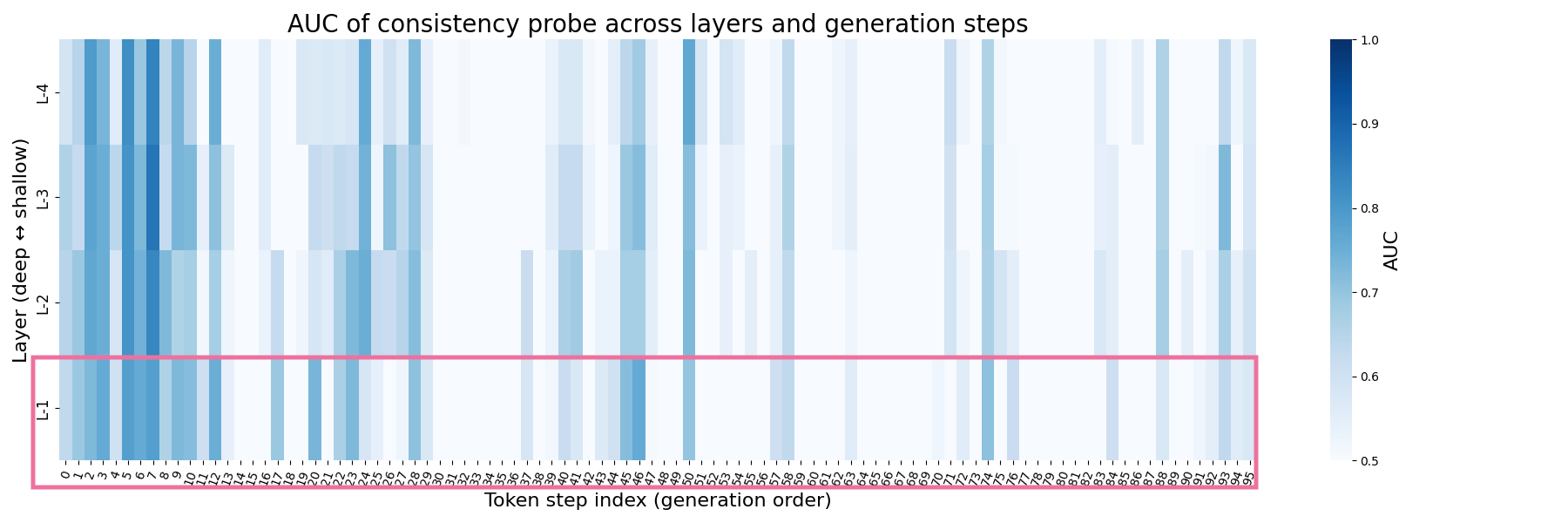
以下の2つのヒートマップは、ベースモデル/トップモデルそれぞれについて、各ブロック・各トークン位置でのProbeの性能評価(AUC)を可視化したものです。
x軸の目盛は0から95番目までのトークン位置、y軸は下から上に向かって浅くなるように4ブロックを並べています(L-1が最終ブロック)。
問題文の妥当性に関する手がかりが内部表現に強く現れるトークン位置で、AUCがピークに達します(色が濃くなる)。
このピークは、モデルが「提示された選択肢が数学的に正しいかどうか」を判断する際に内部で重要な処理を行っているタイミング(例えば問題の主要数字を読み終えた直後や、選択肢との照合が始まる位置)に対応している可能性があります。
ベースモデル
トップモデル
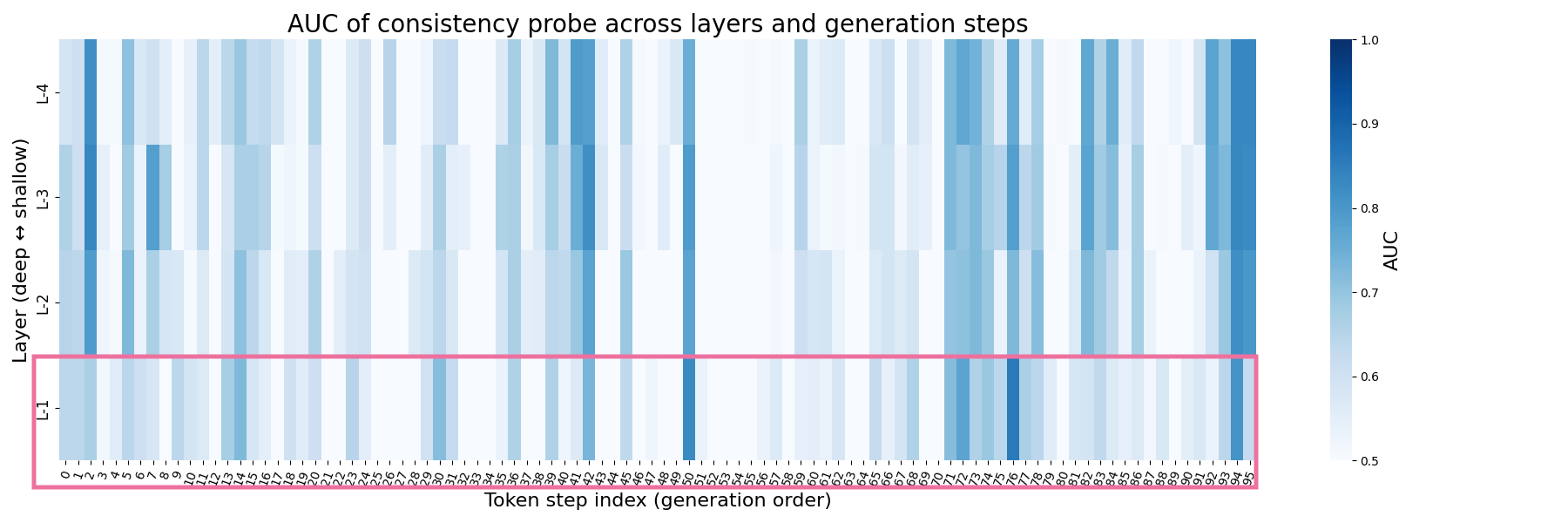
赤枠で囲んだ最終ブロックに注目すると、下のトップモデルは特定のトークン位置(50番目、76番目など)において色が濃く(AUC > 0.8~0.9)なっていることから、妥当かどうかを強く判別できる情報を局所的に内包していると考えられます。
これに対してベースモデルでは、最終ブロックより浅いブロック(L-4からL-2)まで保持されていた妥当性を判別できる情報が、最終ブロック(L-1)では薄くなり、埋もれてしまいました。
2つの赤枠は、ベースモデルで埋もれてしまった妥当性に関する判別情報が、トップモデルでは最終ブロックでシャープに現れるようになったことを示しています。
これは、トップモデルの方が外部出力(回答)の評価(Accuracy)が高くなったことを、内部表現の観点から裏付けるものと解釈できます。
つまり、最終ブロックのみのLoRA適用という小さな介入が、モデルの推論過程において重要な特徴を最終層まで保持する効果をもたらし12、それが実際のスコア差(15.89% vs 13.57%)に現れた、と考えられそうです。
6. さいごに
私たちのチームの最小限のQLoRAにより、最終ブロックで妥当性判断に関する情報が明示的に保持されることがわかったのはよかったです。
ただし、今回のプロービングで特定した隠れ状態の際立った特徴が、実際に外部出力へどの程度寄与しているかは、この実験だけでは判断できません。モデルが実際にその特徴を出力生成に利用していることを示すには、介入実験によるさらなる検証が必要です。
コンペ決勝戦の結果の方は3位でした。
1位/2位チームの成果から、max_completion_tokensを 248,741 まで伸ばすと、ベースモデルでも正解率を19.37%まで伸ばせることを知り(参考にしたScale AIのダッシュボードのmax_completion_tokens = 32,768の値より、ずっと大きくする必要があった)、
評価部門のリーダーとして「モデルの有効な回答数を増やす」方向を早い時期から探る必要があった点を反省しました。
いつの間にか前提を固定して過信してしまったことは、自分に戒めようと思います( • ̀ω•́ )ﻭ
6.1 謝辞
oNo.1チーム(+合流メンバー)のよいところは、(PM/リーダー陣をはじめ)ポジティブで、まっすぐに勝ちへこだわる姿勢です。それに感化されて、たくさんのチームメンバーといっしょに同じ目標を真剣に追いかけられた日々が誇らしいです。
メンバーの皆さん、主催・運営してくれた方々、ありがとうございました。
ここまで記事を読んでくださった方も、ありがとうございます!
7. 参考文献
Phan, L., et al. "Humanity's Last Exam".arXiv:2501.14249, 2025.
Orgad, H., et al. "LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations". arXiv:2410.02707, 2024.
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます。
-
ちなみにタイトルの「Last(最後)」とは、「AIの最後の学術的な試験」という文脈での最後であって、「AIの最後のベンチマーク」という意味ではないそう。HLEはAIのベンチマークの終点からはほど遠く、これ以降は、多様なアプローチや創造的な問題解決能力を要する問題が求められるとのこと。 ↩
-
Center for AI Safety は、AIの安全な開発と展開を推進するサンフランシスコの非営利団体で、Scale AIは、データラベリングおよび機械学習モデルの評価を専門とする、同じくサンフランシスコの企業です。 ↩
-
HLEの論文では、2025年末には精度50%を超えるモデルが出現する可能性も予想していました。今年も残りわずか数十日ですね...。 ↩
-
ちなみにHLEはテストデータのみ与えられているため(test splitのみ)、コンペ中は問題を分析することが認められていません。 ↩
-
学術的な問題だけでなく、HLEのOtherカテゴリには『パルプ・フィクション』や『惑星ソラリス』のような映画から出題される問題も含まれています。 ↩
-
LLMコンペ2025では画像を含むマルチモーダルな問題は除き、テキストのみの問題 2,158件(全問は2,500件)を使用。 ↩
-
無効のケースには、モデルの応答なし、あるいは、フォーマット崩れ(トークン切れ含む)の回答が含まれる。 ↩
-
この分類器(Classifier)自体をプローブ(Probe)と呼ぶ。 ↩
-
通常の分類器の訓練では、問題「+45と-30の和は-15である」を特徴量として入力し、この特徴量がCONSISTENCY(1)かINCONSISTENCY(0)のどちらであるかを予測するように訓練するが、この入力の問題文を内部表現に置き換えている。 ↩
-
コンペの決勝では1チームにつき、H100(80GB) x 8基を8ノードというリッチな環境を利用させてもらえました(1千万円以上かかっているはず...)。 ↩
-
Liは、最終層を基準にした(最終層からのオフセットで示した)層番号。i=1のときは最終ブロック(L−1)、i=2のときはその1つ前のブロック(L−2)、という意味。 ↩
-
ただし、この効果が「最終層までの保持機構が強化された」ことによるものか、あるいは「不要なノイズが抑制されて判別信号が相対的に際立った」ためなのかという区別は、今回のプロービングだけでは特定できません。 ↩