はじめに
XP祭り2025のワークショップ
「AIアシスタントを使って、LLMアプリをつくる前提のモブプロワークをやろう」に参加しました。
このワークショップでは、
講師の家永さんのClaude Codeを大画面に映して、みんな(10名)で機能追加をモブプロする という内容でした。
モブプロの本筋とは別に、手元の自分のノートパソコンで動かせるかトライしてみたのですが、時間内では OpenAI API の登録が間に合わず(クレカ登録の心理的ハードルが高くて😅)。
その場では実行できなかったのですが、そのあと別のセッションを聞きながらゆっくり試したところ、ローカルで動くLLM「Ollama」 を入れて動かせたので、ここではその際の Ollamaの導入から起動までの手順 を記録しておきます。
実行環境
Windows 11
WSLg 上の Ubuntu 22.04
Node.js v20.19.5
npm 10.8.2
プロジェクト概要
使用したリポジトリはこちらです。
haru01/xp-matsuri-2025-ai-todo
AIチャット機能が統合されたReact + TypeScript製のTODOアプリで、
Mastra.aiを利用して複数のLLMプロバイダー(Ollama / OpenAI / Anthropic / Gemini)を切り替えられるようになっています。
Ollamaの導入手順(Ubuntu)
1. インストール
以下のコマンドを実行します。
curl -fsSL https://ollama.com/install.sh | sh
途中でダウンロードが失敗する場合は、再度同じコマンドを実行してください。
インストールが完了すると /usr/local/bin/ollama に配置されます。
確認コマンド:
ollama --version
2. サーバー起動
Ollamaはローカルでサーバーを立ち上げる形で動作します。
次のコマンドで起動します。
ollama serve
バックグラウンドで動かしたい場合は、systemd などを利用できますが、
まずは動作確認のためにフォアグラウンドで起動するのがおすすめです。
デフォルトでは 127.0.0.1:11434 で待ち受けます。
動作確認:
curl http://127.0.0.1:11434/api/tags
結果に {"models":[]} のようなレスポンスが返ってきたらサーバーは起動しています。
3. モデルのダウンロード
Ollamaはモデルを手元にダウンロードして利用します。
今回のTODOアプリでは gpt-oss:20b がデフォルトでしたが、
軽量モデルから試すことも可能です。
例:
ollama pull llama3.2:latest
ダウンロード後、利用可能モデルを確認:
ollama list
4. .env の設定
.env に以下を設定します。
LLM_PROVIDER=ollama
LLM_MODEL=llama3.2:latest
WS_PORT=3002
OpenAIを使う場合は OPENAI_API_KEY を設定しますが、
Ollamaを利用する場合は不要です。
5. アプリの起動
npm install
npm run dev:all
起動後、以下のURLでアクセスできます。
- フロントエンド: http://localhost:5173
- TODO API: http://localhost:3001
- WebSocket: http://localhost:3002
初回はOllamaのモデル読み込みに少し時間がかかりますが、
「こんにちは」などと入力すると、ローカルLLMからの応答が返るようになります。
実行時の画面
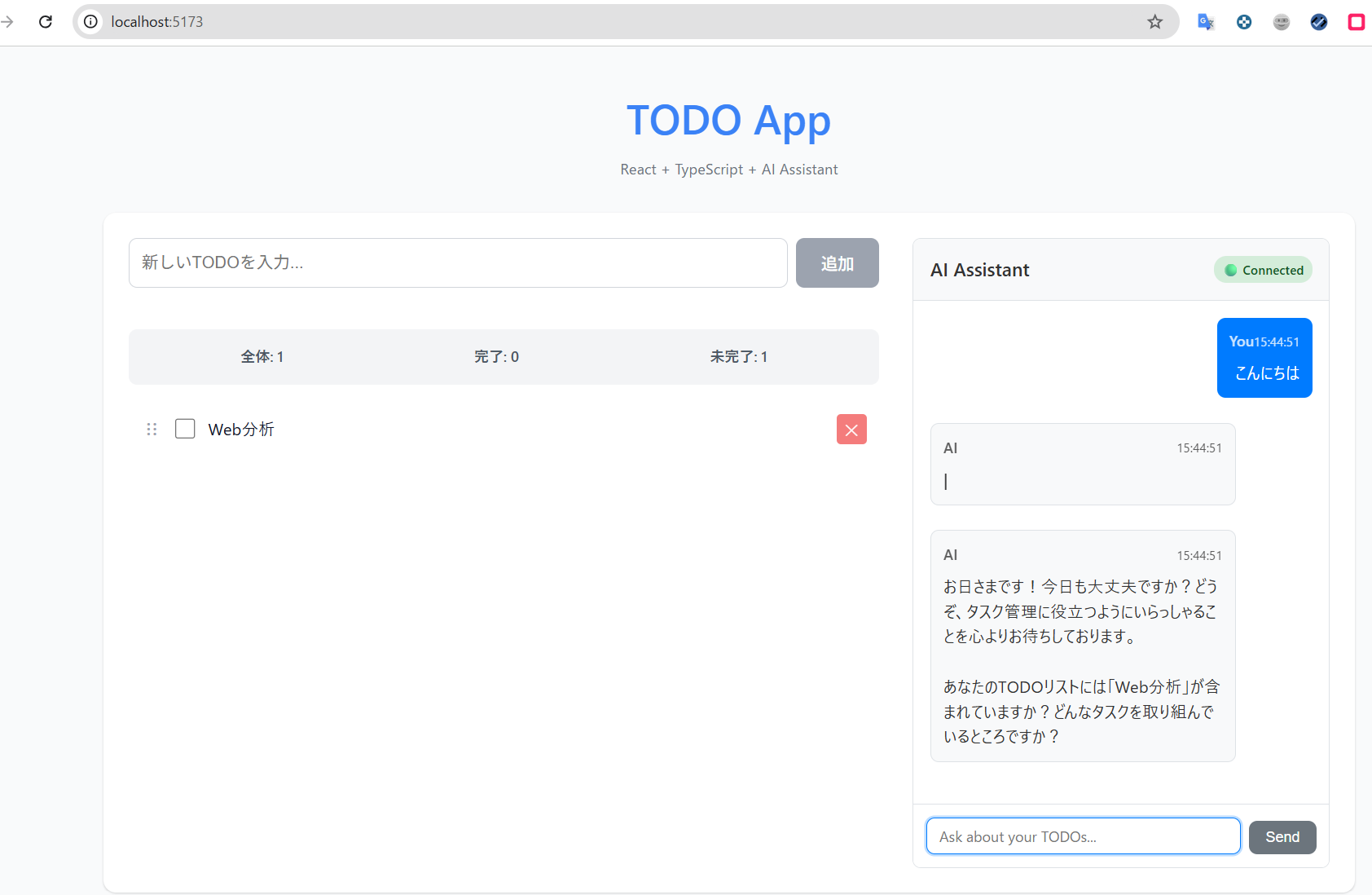
まとめ
- Ollamaを使えば、クレジットカード登録不要で、オフライン環境でもLLMアプリの開発が可能です。
- Mastra.aiのようなエージェントフレームワークと組み合わせると、LLMの差し替えも簡単です。
- たのしいワークショップをありがとうございました! :-)