はじめに
- 「詳解 ディープラーニング ~TensorFlow・Kerasによる時系列データ処理~」でRNNを勉強中。Amazon
- Attentionモデルによる処理の内容を調べてみた。
Sequence-to-sequenceモデルの処理内容
Sequence-to-sequenceモデルによる処理の流れを以下に示す。
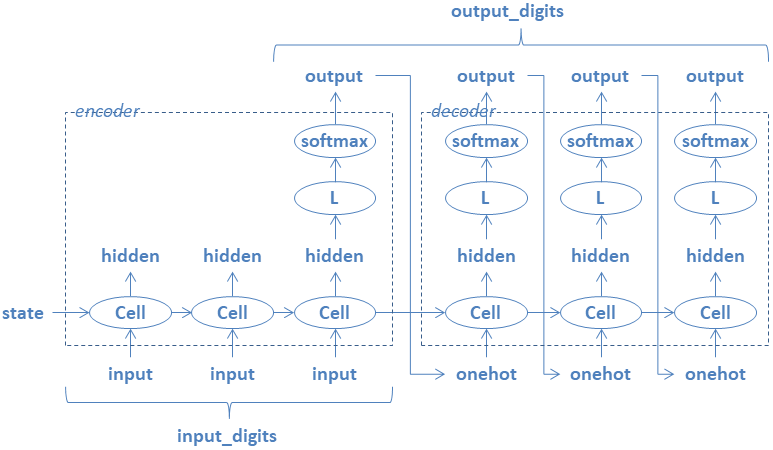
- 左側の枠がencoderを、右側の枠がdecoderを表す。
- input_digitsは、入力の時系列データの長さを表す。
- output_digitsは、出力の時系列データの長さを表す。
- encoderのCellノードで入力の時系列データを処理する。
- decoderのCellノードを実行して出力の時系列データを生成する。
- CellノードはベースとなるRNNCellノードによる変換を表す。
- BasicRNNCellの場合は、tanh-linear変換となる。
- Lノードはlinear変換を表す。
- encoderからdecoderにstateを引き継ぐ。
- decoderでは、直前のoutputをonehotに変換したものを入力とする。
BasicRNNCellノードの処理の内容をソースコードで表現すると以下のようになる。
処理内容を分かり易くするためにノードの生成時に必要となるサイズパラメータを全て指定している。
def weight_variable_uniform(shape, name=None):
sd = np.sqrt(6.0/np.sum(shape))
initial = tf.random_uniform(shape, -sd, sd)
return tf.Variable(initial, name=name)
def weight_variable(shape, name=None):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial, name=name)
def bias_variable(shape, name=None):
initial = tf.zeros(shape, dtype=tf.float32)
return tf.Variable(initial, name=name)
class my_rnn_cell:
def __init__(self, num_units, n_in):
self._num_units = num_units
self._w = weight_variable_uniform([n_in + num_units, num_units], name="my_rnn_cell_kernel")
self._c = bias_variable([num_units], name="my_rnn_cell_bias")
def __call__(self, inputs, state):
res = tf.matmul(tf.concat([inputs, state], 1), self._w) + self._c
output = tf.tanh(res)
return output, output
@property
def state_size(self):
return self._num_units
@property
def output_size(self):
return self._num_units
def zero_state(self, n_batch, dtype=tf.float32):
return tf.zeros([n_batch, self._num_units])
Attentionモデルの処理内容
tensorflowに用意されているAttentionCellWrapperノードによる処理の流れを以下に示す。
Sequence-to-sequenceモデルにおける縦一列の処理に対応する。
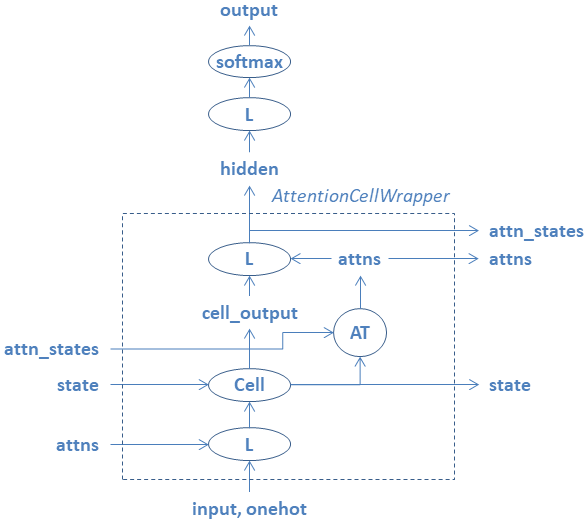
- 新たにattnsとattn_statesが追加されている。
- 最初にinputと更新前のattnsを結合してLノードで処理する。
- 次にCellノードにより、cell_outputとstateを算出する。
- ATノードにより、stateと更新前のattn_statesから更新後のattnsを算出する。
- cell_outputと更新後のattnsを結合してLノードで処理したものをhiddenとする。
- hiddenがAttentionCellWrapperノードの出力となる。
- 直近のhiddenをattn_length個だけ連結したものを更新後のattn_statesとする。
- attn_lengthは、入力の時系列データの長さを表す。(input_digits)
- 一個のinputを処理するのに、更新前と更新後のattnsを両方使用している。
ATノードによる処理の流れを以下に示す。
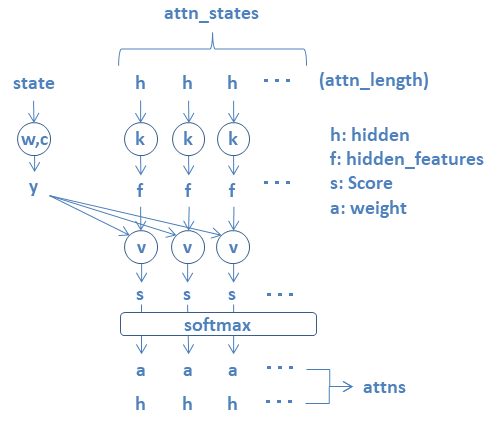
- attn_statesを構成するhiddenを線形変換したものをhidden_featuesとする。
- stateを線形変換したものをyとする
- hidden_featuesとyを加算してvを乗算・集計したものをscoreとする。
- scoreから重みaを算出する。(softmax)
- 重みaでhiddenを加重平均したものをattnsとする。
AttentionCellWrapperノードの処理の内容をソースコードで表現すると以下のようになる。
処理内容を分かり易くするためにノードの生成時に必要となるサイズパラメータを全て指定している。
ATノードは、_attention()に対応している。
class my_AttentionCellWrapper:
def __init__(self, cell, n_in, attn_length, attn_size, attn_vec_size, input_size):
self._cell = cell
self._attn_length = attn_length
self._attn_size = attn_size
self._in_w = weight_variable_uniform([n_in + attn_size, input_size], name="my_attention_in_kernel")
self._in_c = bias_variable([input_size], name="my_attention_in_bias")
self._k = weight_variable_uniform([attn_size, attn_vec_size], name="my_attention_cell_k")
self._v = weight_variable_uniform([attn_vec_size], name="my_attention_cell_v")
self._w = weight_variable_uniform([cell.state_size, attn_vec_size], name="my_attention_cell_w")
self._c = bias_variable([attn_vec_size], name="my_attention_cell_c")
self._out_w = weight_variable_uniform([attn_size + attn_size, attn_size], name="my_attention_out_kernel")
self._out_c = bias_variable([attn_size], name="my_attention_out_bias")
def __call__(self, inputs, state):
state, attns, attn_states = state
inputs = tf.matmul(tf.concat([inputs, attns], 1), self._in_w) + self._in_c
cell_output, state = self._cell(inputs, state)
attns = self._attention(state, attn_states)
output = tf.matmul(tf.concat([cell_output, attns], 1), self._out_w) + self._out_c
attn_states = tf.concat([attn_states[:,1:,:], tf.expand_dims(output, 1)], 1)
return output, (state, attns, attn_states)
def _attention(self, state, attn_states):
hidden_features = tf.einsum('ijk,kl->ijl', attn_states, self._k)
y = tf.matmul(state, self._w) + self._c
y = tf.expand_dims(y, 1)
s = tf.reduce_sum(self._v * tf.tanh(hidden_features + y), axis=2)
a = tf.nn.softmax(s)
attns = tf.reduce_sum(tf.expand_dims(a, 2) * attn_states, axis=1)
return attns
def zero_state(self, n_batch, dtype=tf.float32):
state = self._cell.zero_state(n_batch, dtype)
attns = tf.zeros([n_batch, self._attn_size])
attn_states = tf.zeros([n_batch, self._attn_length, self._attn_size])
return (state, attns, attn_states)
Inference処理の内容
上記のクラス定義を使用して、Inference処理を記述すると以下のようになる。
サイズパラメータはグローバル変数を参照している。
def inference(x, y, n_batch, is_training):
# global n_in # 12
# global n_out # 12
# global input_digits # 7
# global output_digits # 4
# global attn_size # 128
# global attn_vec_size # 128
# global input_size # 12
# Encoder
encoder_outputs = []
encoder_states = []
with tf.variable_scope('Encoder'):
encoder = my_rnn_cell(attn_size, input_size)
encoder = my_AttentionCellWrapper(encoder, n_in, input_digits, attn_size, attn_vec_size, input_size)
state = encoder.zero_state(n_batch, tf.float32)
for i in range(input_digits):
(output, state) = encoder(x[:, i, :], state)
encoder_outputs.append(output)
encoder_states.append(state)
w = weight_variable([attn_size, n_out], name="kernel")
c = bias_variable([n_out], name="bias")
outputs = []
# Decoder
state = encoder_states[-1]
decoder_outputs = [encoder_outputs[-1]]
with tf.variable_scope('Decoder'):
decoder = my_rnn_cell(attn_size, input_size)
decoder = my_AttentionCellWrapper(decoder, n_in, input_digits, attn_size, attn_vec_size, input_size)
for i in range(1, output_digits):
if is_training is True:
(output, state) = decoder(y[:, i-1, :], state)
else:
linear = tf.matmul(decoder_outputs[-1], w) + c
out = tf.nn.softmax(linear)
outputs.append(out)
out = tf.one_hot(tf.argmax(out, -1), depth=n_out)
(output, state) = decoder(out, state)
decoder_outputs.append(output)
if is_training is True:
output = tf.reshape(tf.concat(decoder_outputs, axis=1), [-1, output_digits, attn_size])
linear = tf.matmul(output, w) + c
return tf.nn.softmax(linear)
else:
linear = tf.matmul(decoder_outputs[-1], w) + c
out = tf.nn.softmax(linear)
outputs.append(out)
output = tf.reshape(tf.concat(outputs, axis=1), [-1, output_digits, n_out])
return output
さいごに
例題である3桁の加算問題の場合、200epochで予測精度は98.8%となった。