はじめに
Pythonによるデータ分析は、仕事でサクッとできるとこいつデキルと思われるお得なスキルの1つです。本記事では、pandasを使ったCSV・Excelファイルの読み込みからデータ加工・集計・グラフ化まで、比較的簡単に新入社員でできる基本的な操作を記載します。これからPythonやpandasでデータ分析を始めたい方は、ぜひ参考にしてください。
参考文献
ほぼこの書籍の順に記載しています。
この本は実際の仕事のユースケースごとに書かれているので勉強しやすかったです。
100本ノックシリーズとしてシリーズ化されているので他の本もぜひ読んでみてください。

それでは始めます。
pandasインポート
import pandas as pd
まずはライブラリpandasをインポートします。
CSVファイル読み込み
customer_master = pd.read_csv('customer_master.csv')
customer_master.head()
次に、customer_master.csv というCSVファイルを Pandasのデータフレーム として読み込みます。
pd.read_csv() は、CSVファイルをPandasのデータフレームに変換する関数です。
このCSVファイルには顧客情報が表形式で保存されている想定で、読み込んだデータは customer_master という変数に格納します。
次に、customer_master.head() を実行して、データの先頭5行を表示します。
head() メソッドで、データが正しく読み込まれているかを確認します。
ポイント
- CSV読み込みには pd.read_csv() メソッドを使用します。
- head() メソッドはデータ確認に便利で、引数で表示行数を変更できます。
型の確認
customer_master.dtypes
customer_master.dtypes を実行すると、データフレームの各列(カラム)のデータ型を確認できます。
データ型とは、その列にどのような種類のデータが入っているかになります。
例えば、数値なら int64(整数)や float64(小数)、文字列なら object 型で表示されます。
データ型を確認することで、分析や加工時に正しく処理できるか予期せぬエラーにならないか確認することができるの最初に確認しておくことが重要です。
例えば、数値として扱うべき列が文字列になっていた場合は型変換が必要で、日付として扱うべき列が文字列の場合もよくある印象です。
ポイント
- dtypes で全列のデータ型を一覧で確認できます。
- この結果を基に、型変換やデータクリーニングの必要性を判断します。
欠損値の確認
customer_master.isnull().sum()
customer_master.isnull().sum() で、データの中に欠損値(NULL)がどれだけあるかを確認します。NULLは皆さんよく悩まされますよね。最初のSTEPでその存在を確認しましょう。
isnull()
- 各セルの値が欠損(NULL)かどうかを調べ、True または False で返します。
True:欠損している
False:値がある
sum()
- True を 1、False を 0 としてカウントし、列ごとに合計します。
- これにより、各列の欠損数を数値で表示します。
データ分析や機械学習では、欠損値があると正しく処理できないことがあります。
欠損の多い列を特定し、補完や削除などの対応を決定します。
ポイント
- isnull() で欠損状況を確認できます。
- sum() と組み合わせることで、列ごとの欠損数を簡単に集計できます。
データの結合(ユニオン):行の追加
transaction_1 = pd.read_csv('transaction_1.csv')
transaction_1.head()
transaction_2 = pd.read_csv('transaction_2.csv')
transaction = pd.concat([transaction_1, transaction_2], ignore_index=True)
transaction.head()
print(len(transaction_1))
print(len(transaction_2))
print(len(transaction))
少しレベルアップです。実際の現場では1つのファイルで完結しないことがほとんどです。そのため、複数のCSVファイルを結合して1つのデータフレームを作成します。
CSVファイルの読み込み
transaction_1.csv と transaction_2.csv をそれぞれPandasのデータフレームとして読み込みます。
データフレームの結合
pd.concat([transaction_1, transaction_2], ignore_index=True) で2つのデータフレームを縦方向に結合します。
ignore_index=True は、結合後に インデックスを再振り分け するオプションです。
これを指定しない場合、元のインデックスがそのまま引き継がれます。
ポイント
- pd.read_csv() で複数ファイルを個別に読み込みます。
- pd.concat() は、リストで渡した複数のデータフレームを結合する関数です。
売上データ同士の結合(ジョイン):"transaction_id", "payment_date", "customer_id"列の追加
transaction_detail = pd.read_csv('transaction_detail_1.csv')
transaction = pd.read_csv('transaction_1.csv')
join_data = pd.merge(transaction_detail, transaction[["transaction_id", "payment_date", "customer_id"]], on="transaction_id", how="left")
join_data.head()
print(len(transaction_detail))
print(len(transaction))
print(len(join_data))
取引明細データと取引データを結合して1つのデータフレームを作成します。
CSVファイルの読み込み
transaction_detail_1.csv を transaction_detail に、transaction_1.csv を transaction に読み込みます。
必要な列だけ抽出
transaction[["transaction_id", "payment_date", "customer_id"]] で必要な列だけを選びます。
データの結合(マージ)
pd.merge() で transaction_detail と transaction のデータを transaction_id 列で結合します。
how="left" で、transaction_detail のすべての行を保持しつつ、transaction の情報を左結合で追加します。
ポイント
- pd.merge() でSQLのJOINのようにデータフレームを結合できます。
- on="transaction_id" で結合キーを指定します。
- how="left" で左側のデータフレームの行をすべて保持します。
必要なデータ列の作成:新しい列の追加
transaction["price"] = transaction["quantity"] * transaction["item_price"]
transaction[["quantity", "item_price", "price"]].head()
分析に必要なデータは適宜自分で追加しましょう。
この例では、取引データに合計金額の列を追加します。
新しい列の作成
transaction["price"] で新しく price(合計金額)列を作成します。
計算式は transaction["quantity"] * transaction["item_price"] です。
- quantity:購入した商品の数量
- item_price:1個あたりの価格
この2つを掛け算することで、1行ごとの合計金額を算出します。
ポイント
- 列同士の演算は各行ごとに自動計算されます。
- 新しい列は データフレーム["列名"] = 式 で追加します。
各種統計量の確認
# 統計量の把握
transaction.describe()
# 最小/最大の把握
print(transaction["price"].min())
print(transaction["price"].max())
取引データの統計量や価格の最小・最大値を確認します。
統計量の把握
transaction.describe() により、数値列の基本的な統計量を確認し、ざっくりどんなデータなのか確認しましょう。
統計量には以下が含まれます:
- count:データ件数
- mean:平均値
- std:標準偏差(データのばらつき)
- min:最小値
- 25%:下位25%の値(第1四分位数)
- 50%:中央値(第2四分位数)
- 75%:上位25%の値(第3四分位数)
- max:最大値
特定列の最小/最大の把握
transaction["price"].min() で、価格の最小値を取得します。
transaction["price"].max() で、価格の最大値を取得します。
ポイント
- describe() で基本統計量を一度に確認できます。
- min() と max() で特定列の範囲を把握できます。
月別・商品別でデータを集計
transaction["payment_date"] = pd.to_datetime(transaction["payment_date"])
# 年単位:strftime("%Y")、月単位:strftime("%Y%m")、日単位:strftime("%Y%m%d")
transaction["payment_month"] = transaction["payment_date"].dt.strftime("%Y%m")
transaction[["payment_date", "payment_month"]].head()
# 月別・商品別にpriceの合計を計算
transaction.groupby(["payment_month","item_name"])["price"].sum()
# 月別・商品別にpriceとquantityの合計を計算
transaction.groupby(["payment_month","item_name"])[["price", "quantity"]].sum()
# テーブル形式で表記(商品ごとの月別のpriceとquantityの合計)
# index:行に指定するカラム、columns:列に指定するカラム、values:集計する数値カラム、aggfunc:集計方法
pd.pivot_table(transaction, index='item_name', columns='payment_month', values=['price', 'quantity'], aggfunc='sum')
# 横軸縦軸変更(月別の商品ごとprice合計)
graph_data = pd.pivot_table(transaction, index='payment_month', columns='item_name', values='price', aggfunc='sum')
graph_data.head()
# グラフ化
import matplotlib.pyplot as plt
# 横軸、縦軸、ラベル名の順に指定する
plt.plot(list(graph_data.index), graph_data["PC-A"], label='PC-A')
plt.plot(list(graph_data.index), graph_data["PC-B"], label='PC-B')
plt.plot(list(graph_data.index), graph_data["PC-C"], label='PC-C')
plt.plot(list(graph_data.index), graph_data["PC-D"], label='PC-D')
plt.plot(list(graph_data.index), graph_data["PC-E"], label='PC-E')
plt.legend()
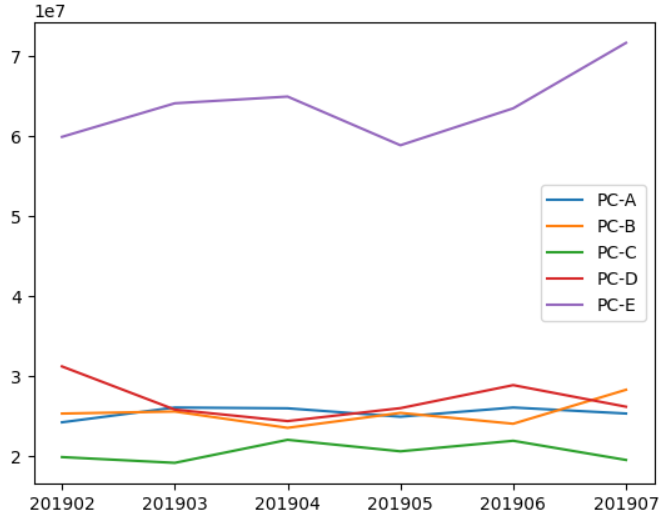
よくある分析例です。
月別・商品別に取引データを集計し、グラフ化します。
処理内容
pd.to_datetime() で日付型に変換し、.dt.strftime("%Y%m") で年月形式に変換して payment_month 列に格納します。
groupby() で月別・商品別にデータをまとめ、sum() で合計を計算します。
pivot_table で商品ごとの月別合計をテーブル形式で表示します。
月ごとの商品別売上を グラフ化しやすい形 に変換。
行を月、列を商品、値を売上(price)に設定。
matplotlib.pyplot を使って折れ線グラフを作成。
graph_data.index を横軸(年月)、各商品ごとの売上を縦軸としてプロット。
label で凡例を設定し、plt.legend() でグラフ上に表示。
次のようなグラフが表示されます。
ポイント
- pd.to_datetime() で日付型に変換し、日付操作が容易になります。
- groupby() と pivot_table() で柔軟な集計が可能です。
- matplotlib で集計結果をグラフ化し、売上傾向を直感的に把握できます。
- strftime("%Y%m") で年月単位の集計が可能です。
Excel読み込み
kokyaku_data = pd.read_excel("kokyaku_daicho.xlsx")
kokyaku_data.head()
CSVではなくExcel形式の場合は、このようにExcelファイルから顧客データを読み込みます。
メソッドを変えるだけで簡単です。
Excelファイルの読み込み
pd.read_excel("kokyaku_daicho.xlsx") で、Excel形式のファイルをPandasのデータフレームとして読み込みます。
読み込んだデータは kokyaku_data という変数に格納します。
ポイント
- pd.read_excel() でExcelファイルを簡単に読み込めます。
カウント
# 行数カウント
print(len(uriage_data["item_name"]))
# 重複行を排除してカウント(ユニークな行数)
print(len(pd.unique(uriage_data["item_name"])))
# 重複行を排除して表示(ユニークな行のみ表示)
print(pd.unique(uriage_data["item_name"]))
次は、様々なカウント方法です。
単純なカウントからユニーク行数のカウントなどデータの件数や重複を確認する処理を解説します。
行数カウント
len(uriage_data["item_name"]) で、item_name 列の全行数を取得。
データに何件の商品が登録されているかを把握できます。
ユニークな行数のカウント
pd.unique(uriage_data["item_name"]) で重複を排除した値を取得。
その長さを len() で計算すると、ユニーク(重複なし)の商品数 がわかります。
ユニークな値の表示
pd.unique(uriage_data["item_name"]) で、重複を排除した商品名の一覧を表示。
どんな商品が含まれているかを確認できます。
ポイント
- len() で全行数や配列の長さを取得できます。
- pd.unique() で重複を除いた値を取得できます。
文字列補正
# 大文字変換
uriage_data["item_name"] = uriage_data["item_name"].str.upper()
# 全角スペース削除
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
# 半角スペース削除
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
# 文字列昇順ソート
uriage_data.sort_values(by=["item_name"], ascending=True)
実際のデータにはデータの表記方法がぶれていることがよくあります。
ここでは、いつくかの文字列編集を説明します。
サンプルとして、商品名列の文字列を整形してソートします。
大文字変換
str.upper() を使って、item_name 列の文字をすべて大文字に変換。
「PC-a」や「pc-b」を統一して「PC-A」「PC-B」のように揃えるため。
全角スペース削除
str.replace(" ", "") で全角スペース(日本語入力のスペース)を削除。
データ入力時の余分なスペースを取り除く。
半角スペース削除
str.replace(" ", "") で半角スペースを削除。
「PC - A」のような不統一な表記を整える。
文字列昇順ソート
sort_values(by=["item_name"], ascending=True) で商品名を アルファベット順に昇順 で並び替え。
ポイント
- str.upper() で文字列を統一。
- str.replace() で不要なスペースを削除。
- sort_values() で見やすく整列し、分析しやすくする。
欠損値補完
flg_is_null = uriage_data["item_price"].isnull()
for trg in list(uriage_data.loc[flg_is_null, "item_name"].unique()):
price = uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"] == trg), "item_price"].max()
uriage_data.loc[(flg_is_null) & (uriage_data["item_name"]==trg),"item_price"] = price
uriage_data.head()
次に、欠損している商品価格を埋める処理を解説します。
欠損値=NULLの場合を正しく事前処理しておきましょう。
欠損値フラグの作成
uriage_data["item_price"].isnull() で item_price が欠損している行を True、欠損していない行を False とするフラグを作成。
flg_is_null に格納。
商品ごとに欠損を補完
uriage_data.loc[flg_is_null, "item_name"].unique() で、価格が欠損している商品のリストを取得。
for trg in list(...) で、欠損商品ごとに処理を繰り返す。
欠損値に最大価格を代入
price = uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"] == trg), "item_price"].max()
欠損でない同じ商品名の item_price の最大値を取得。
uriage_data.loc[(flg_is_null) & (uriage_data["item_name"]==trg),"item_price"] = price
欠損している行に、その最大価格を代入。
ポイント
- isnull() で欠損値を判定。
- loc と条件式を組み合わせて特定行を抽出・更新。
- unique() で重複を排除し、商品ごとに一度だけ補完処理を実行。
- 価格補完に max() を使うことで、最も高い値で欠損を埋める。
Excel日付の揺れを補正
# 数値形式の項目を日付形式にフォーマット
flg_is_serial = kokyaku_data["登録日"].astype("str").str.isdigit()
flg_is_serial.sum()
fromSerial = pd.to_timedelta(kokyaku_data.loc[flg_is_serial, "登録日"].astype("float") - 2, unit="D") + pd.to_datetime('1900/1/1')
fromSerial
# 日付形式の項目のフォーマット変換(/区切りから-区切りへ変換)
fromString = pd.to_datetime(kokyaku_data.loc[~flg_is_serial, "登録日"])
fromString
# 登録日カラムを補正
kokyaku_data["登録日"] = pd.concat([fromSerial, fromString])
kokyaku_data
次に、顧客データの「登録日」を数値形式や文字列形式から統一して日付形式に変換する処理を解説します。
数値形式の判定
kokyaku_data["登録日"].astype("str").str.isdigit() で、登録日が数字のみで構成されている行を判定。
flg_is_serial に True/False のフラグを格納。
数値形式を日付に変換
Excelでは日付がシリアル値(1900年1月1日からの日数)として保存される場合があります。
pd.to_timedelta(..., unit="D") + pd.to_datetime('1900/1/1') により、シリアル値を日付形式に変換。
-2 の補正はExcelの日付シリアル値のずれを修正するため。
文字列形式を日付に変換
数字以外の文字列(例:'2025/08/01')は pd.to_datetime() で日付形式に変換。
これにより、/区切りも自動的に解釈され、日付型に統一されます。
登録日カラムを補正
数値形式の変換結果と文字列形式の変換結果を pd.concat() で結合し、元の 登録日 列を置き換え。
これにより、全ての登録日が統一された日付形式になります。
ポイント
- 数値形式はシリアル値、文字列形式は日付文字列として処理を分ける。
- pd.to_timedelta() と pd.to_datetime() を組み合わせることでシリアル値も日付型に変換可能。
- pd.concat() で数値・文字列から変換した日付を1つの列に統合。
列整形/CSVファイル出力
join_data = pd.merge(uriage_data, kokyaku_data, left_on="customer_name", right_on="顧客名", how="left")
# 結合した結果重複している不要列の削除
join_data = join_data.drop("customer_name", axis=1)
join_data
# 列順の変更
dump_data = join_data[["purchase_date", "purchase_month", "item_name", "item_price", "顧客名", "かな", "地域", "メールアドレス", "登録日"]]
dump_data
# CSV出力
dump_data.to_csv("dump_data.csv", index=False)
入力ファイルを加工、整形して正しい状態をなったら、次に売上データと顧客データを結合して整形し、CSVとして出力する処理を解説します。
データの結合
pd.merge() を使って売上データ(uriage_data)と顧客データ(kokyaku_data)を結合。
left_on="customer_name", right_on="顧客名" により、売上データの顧客名と顧客データの顧客名をキーに結合。
how="left" により、売上データを基準に結合(左結合)し、顧客情報を追加。
不要列の削除
結合により重複した customer_name 列を drop() で削除。
列順の変更
必要な列だけを抽出し、分析や出力に適した順序に並び替え。
dump_data に格納。
CSV出力
to_csv("dump_data.csv", index=False) で、整形したデータをCSVファイルとして保存。
index=False により、行番号は出力しない。
ポイント
- pd.merge() で複数のデータフレームをキーで結合可能。
- drop() で不要な列を削除してデータを整理。
- to_csv() で簡単にCSV出力でき、外部での利用が容易。
- 列順の調整により、CSVの可読性や分析しやすさを向上させる。
私が考えて基本的な操作はここまでです。
入力ファイルを使って結合、加工、整形、必要であれば新しい出力ファイルとすることで徐々に分析しやすいデータが出来上がっていきます。
これらを組み合わせることでデータ分析をしていきましょう。
まとめ文
本記事では、Pythonのpandasライブラリを活用したデータ分析の基本操作を、CSV・Excelファイルの読み込みからデータ加工・集計・グラフ化、ファイル出力まで解説しました。新入社員の方でも、この記事を参考にすれば、実務で必要なデータ処理の流れを理解し、すぐに現場で活用できるはずです。pandasやPythonによるデータ分析のスキルを身につけて、業務効率化やデータ活用を行い、こいつデキルと思われる存在になってください!