まえがき
こちらの方のQiitaを拝見し、面白そう!やってみたい!と思い、実践してみました。
非常に長くなってしまったので、
ご興味を持っていただけましたらお読みいただけると嬉しいです。
「twarc」というライブラリの存在をこの時に初めて知りました。
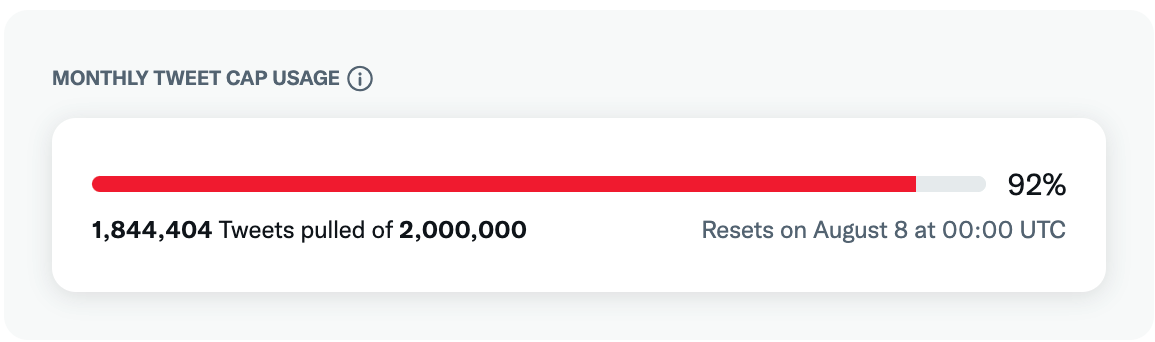
Twiiter APIでのツイート取得数はMAX100件(※Elevated)に対し、
こちらは一度コマンドを実行すると何万件と非常に多くのツイートを取得することが出来るので
分析に打って付けだなぁと思いました(TwitterAPIの月間取得件数に注意が必要です。
Elevatedの場合は月200万ツイート)。
BMSG所属のBE:FIRSTについて、2022年07月18日〜2022年07月24日間で、
どれくらい「BE:FIRST」という単語がツイートされているのか調べてみることにしました
(タグではなくツイート文中にある単語として取得、
どのような単語と一緒に使われているのか知りたかったからです)。
その後、MeCabで形態素解析、seabornでグラフ化しました。
方法はこちらの方のQiitaを参考にさせていただきました。
おそらくこれでドキドキクイズもクリア出来たのではないでしょうか…!o(`ω´ )o
(非常に余談ですが、このクイズが伏線になっていることに気づいた時は驚きました…。
連載再開が楽しみですね。)
動作環境
・MacBook Air (Retina, 13-inch, 2020)
・Big Sur 11.4
・Python 3.8.7
・jupyter lab 3.0.16
・Anacondaは使用していません
形態素解析を実行する前の私
・曲の感想多そう
・形容詞多そう
*1. twarcでツイートを取得〜保存
ツイートを取得〜保存まではターミナルで行いました。
※ jupyter labの場合
!twarc2 search --start-time 2022-07-18 --end-time 2022-07-24 '"BE:FIRST"' results_day.jsonl
で、jupyter labでも取得可能です。保存先は.ipynbを保存しているディレクトリです。
(1)ツイートを検索(7日間<今回は6日間>、Academic APIにアクセスできる場合は、
--archiveオプションを使用してツイートの完全なアーカイブを検索できます。)
ターミナルにて、
% twarc2 search --start-time 2022-07-18 --end-time 2022-07-24 '"BE:FIRST"' results_day.jsonl
1%|▏ | Processed an hour/6 days [01:06<1:17:05, 5099 tweets total ]
※ --start-time:開始日
※ --end-time:終了日
(2)100%になれば検索・保存終了です
(2022年07月18日〜2022年07月24までを検索した結果、
収集終了に2時間以上かかりました。お時間にお気をつけください( ; _ ; )/~~~)。
ターミナルで実行した場合、jsonlはホームフォルダに保存されます(csvも同様)。
100%|█████████| Processed 6 days/6 days [2:02:13<00:00, 363923 tweets total ]
(3)ツイートを収集し終えたらjsonlからcsvに変換します。
% twarc2 csv results_day.jsonl results_day.csv
100%|██████████████| Processed 1.59G/1.59G of input file [05:51<00:00, 4.86MB/s]
*2. 分析開始(実行場所:jupyter lab)
twarcインストール時に各種APIキーを入力しているのですが、
一応python-dotenvとurllib3を使用して各種キーをベタ書きしないようにしています。
(1)任意の場所に保存したcsvのPATHをコピーします
(2)("/hogehoge/results_day.csv")にPATHを貼り付けます
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 一応.envファイルからキーを取得
http = urllib3.PoolManager()
env_file = find_dotenv()
load_dotenv(env_file)
# 一応Twitterの認証
api_key = os.environ["API_KEY"]
api_secret_key = os.environ["API_SECRET_KEY"]
access_token = os.environ["ACCESS_TOKEN"]
access_token_secret = os.environ["ACCESS_TOKEN_SECRET"]
# KEY = os.environ.get("KEY")
# tweepyの認証
# auth = tweepy.OAuthHandler(api_key, api_secret_key)
# auth.set_access_token(access_token, access_token_secret)
# api = tweepy.API(auth)
pd.set_option("display.unicode.east_asian_width", True)
tweet_df = pd.read_csv("/Users/watashi/Documents/twarc/results_day.csv", parse_dates=["created_at"], low_memory=False)
tweet_df["count"] = 1
tweet_trend_df = tweet_df.set_index("created_at")
fig, ax = plt.subplots()
tweet_trend_df["count"].resample("D").sum().plot(title="BE:FIRSTツイート分析");
# グラフが見切れないようにする
plt.tight_layout()
# 高画質保存、同じセルに入れないと保存画像が真っ白になる
plt.savefig("befirst_matplotlib.png", dpi=300)
(3)どどん!※ 2022年7月24日取得

2022年7月22日が66,000〜件と飛び抜けています。
2022年7月22日の20時にジョナスブルーとのコラボ曲(オリジナル:Why Don't We)の
リリックビデオがアップされたためツイートが大幅に伸びているのではないかと予想します。
「BE:FIRST」というキーワードが6日間トータルで363,923件ツイートされたことが
分かったので、次はどのような言葉と一緒にツイートされているか形態素解析していきます。
☆1. jupyter labでMeCabのインストール
インストールされている方は飛ばしてください。
(1)ターミナルにてMeCabインストール(Homebrewを使用しています)
% brew install mecab
やっぱりWarningが出ました
Warning: A newer Command Line Tools release is available.
Update them from Software Update in System Preferences or run:
softwareupdate --all --install --force
If that doesn't show you any updates, run:
sudo rm -rf /Library/Developer/CommandLineTools
sudo xcode-select --install
Alternatively, manually download them from:
https://developer.apple.com/download/all/.
You should download the Command Line Tools for Xcode 13.2.1.
こちらの方々を参考にさせていただきました。
(2)MeCab用のIPAの辞書をインストールします
% brew install mecab-ipadic
(3)MeCab操作用のpythonライブラリをインストールします
% pip3 install mecab-python3
DEPRECATION: Configuring installation scheme with distutils config files is deprecated and will no longer work in the near future. If you are using a Homebrew or Linuxbrew Python, please see discussion at https://github.com/Homebrew/homebrew-core/issues/76621
Collecting mecab-python3
Downloading mecab_python3-1.0.5-cp39-cp39-macosx_10_15_x86_64.whl (282 kB)
|████████████████████████████████| 282 kB 10.7 MB/s
Installing collected packages: mecab-python3
DEPRECATION: Configuring installation scheme with distutils config files is deprecated and will no longer work in the near future. If you are using a Homebrew or Linuxbrew Python, please see discussion at https://github.com/Homebrew/homebrew-core/issues/76621
Successfully installed mecab-python3-1.0.5
(4)ターミナルで動作確認(大好きな赤毛連盟から引用しました)
% python3
>>> import MeCab
>>> m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/ipadic")
>>> print(m.parse("概して、事件の外見が奇怪に見えれば見えるほど、その本質は単純なものだ。平凡な顔ほど見わけがつきにくいように、ありふれた特徴のない犯罪ほど、本当はやっかいなんだよ。"))
概して 副詞,一般,*,*,*,*,概して,ガイシテ,ガイシテ
、 記号,読点,*,*,*,*,、,、,、
事件 名詞,一般,*,*,*,*,事件,ジケン,ジケン
の 助詞,連体化,*,*,*,*,の,ノ,ノ
外見 名詞,一般,*,*,*,*,外見,ガイケン,ガイケン
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
奇怪 名詞,形容動詞語幹,*,*,*,*,奇怪,キカイ,キカイ
に 助詞,副詞化,*,*,*,*,に,ニ,ニ
見えれ 動詞,自立,*,*,一段,仮定形,見える,ミエレ,ミエレ
ば 助詞,接続助詞,*,*,*,*,ば,バ,バ
見える 動詞,自立,*,*,一段,基本形,見える,ミエル,ミエル
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
、 記号,読点,*,*,*,*,、,、,、
その 連体詞,*,*,*,*,*,その,ソノ,ソノ
本質 名詞,一般,*,*,*,*,本質,ホンシツ,ホンシツ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
単純 名詞,形容動詞語幹,*,*,*,*,単純,タンジュン,タンジュン
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
もの 名詞,非自立,一般,*,*,*,もの,モノ,モノ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
。 記号,句点,*,*,*,*,。,。,。
平凡 名詞,形容動詞語幹,*,*,*,*,平凡,ヘイボン,ヘイボン
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
顔 名詞,一般,*,*,*,*,顔,カオ,カオ
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
見 動詞,自立,*,*,一段,連用形,見る,ミ,ミ
わけ 名詞,一般,*,*,*,*,わけ,ワケ,ワケ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
つき 動詞,自立,*,*,五段・カ行イ音便,連用形,つく,ツキ,ツキ
にくい 形容詞,非自立,*,*,形容詞・アウオ段,基本形,にくい,ニクイ,ニクイ
よう 名詞,非自立,助動詞語幹,*,*,*,よう,ヨウ,ヨー
に 助詞,副詞化,*,*,*,*,に,ニ,ニ
、 記号,読点,*,*,*,*,、,、,、
ありふれ 動詞,自立,*,*,一段,連用形,ありふれる,アリフレ,アリフレ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
特徴 名詞,一般,*,*,*,*,特徴,トクチョウ,トクチョー
の 助詞,格助詞,一般,*,*,*,の,ノ,ノ
ない 形容詞,自立,*,*,形容詞・アウオ段,基本形,ない,ナイ,ナイ
犯罪 名詞,一般,*,*,*,*,犯罪,ハンザイ,ハンザイ
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
、 記号,読点,*,*,*,*,、,、,、
本当は 副詞,一般,*,*,*,*,本当は,ホントウハ,ホントーワ
やっかい 名詞,形容動詞語幹,*,*,*,*,やっかい,ヤッカイ,ヤッカイ
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
ん 名詞,非自立,一般,*,*,*,ん,ン,ン
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
よ 助詞,終助詞,*,*,*,*,よ,ヨ,ヨ
。 記号,句点,*,*,*,*,。,。,。
EOS
(5)動作確認が終了したらjupyter labを開き、下記コマンドを実行します
pip install mecab-python3
(6)jupyter labでも動作確認を行います
import MeCab
m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/ipadic")
print(m.parse("概して、事件の外見が奇怪に見えれば見えるほど、その本質は単純なものだ。平凡な顔ほど見わけがつきにくいように、ありふれた特徴のない犯罪ほど、本当はやっかいなんだよ。"))
# 実行結果
概して 副詞,一般,*,*,*,*,概して,ガイシテ,ガイシテ
、 記号,読点,*,*,*,*,、,、,、
事件 名詞,一般,*,*,*,*,事件,ジケン,ジケン
の 助詞,連体化,*,*,*,*,の,ノ,ノ
外見 名詞,一般,*,*,*,*,外見,ガイケン,ガイケン
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
奇怪 名詞,形容動詞語幹,*,*,*,*,奇怪,キカイ,キカイ
に 助詞,副詞化,*,*,*,*,に,ニ,ニ
見えれ 動詞,自立,*,*,一段,仮定形,見える,ミエレ,ミエレ
ば 助詞,接続助詞,*,*,*,*,ば,バ,バ
見える 動詞,自立,*,*,一段,基本形,見える,ミエル,ミエル
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
、 記号,読点,*,*,*,*,、,、,、
その 連体詞,*,*,*,*,*,その,ソノ,ソノ
本質 名詞,一般,*,*,*,*,本質,ホンシツ,ホンシツ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
単純 名詞,形容動詞語幹,*,*,*,*,単純,タンジュン,タンジュン
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
もの 名詞,非自立,一般,*,*,*,もの,モノ,モノ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
。 記号,句点,*,*,*,*,。,。,。
平凡 名詞,形容動詞語幹,*,*,*,*,平凡,ヘイボン,ヘイボン
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
顔 名詞,一般,*,*,*,*,顔,カオ,カオ
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
見 動詞,自立,*,*,一段,連用形,見る,ミ,ミ
わけ 名詞,一般,*,*,*,*,わけ,ワケ,ワケ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
つき 動詞,自立,*,*,五段・カ行イ音便,連用形,つく,ツキ,ツキ
にくい 形容詞,非自立,*,*,形容詞・アウオ段,基本形,にくい,ニクイ,ニクイ
よう 名詞,非自立,助動詞語幹,*,*,*,よう,ヨウ,ヨー
に 助詞,副詞化,*,*,*,*,に,ニ,ニ
、 記号,読点,*,*,*,*,、,、,、
ありふれ 動詞,自立,*,*,一段,連用形,ありふれる,アリフレ,アリフレ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
特徴 名詞,一般,*,*,*,*,特徴,トクチョウ,トクチョー
の 助詞,格助詞,一般,*,*,*,の,ノ,ノ
ない 形容詞,自立,*,*,形容詞・アウオ段,基本形,ない,ナイ,ナイ
犯罪 名詞,一般,*,*,*,*,犯罪,ハンザイ,ハンザイ
ほど 助詞,副助詞,*,*,*,*,ほど,ホド,ホド
、 記号,読点,*,*,*,*,、,、,、
本当は 副詞,一般,*,*,*,*,本当は,ホントウハ,ホントーワ
やっかい 名詞,形容動詞語幹,*,*,*,*,やっかい,ヤッカイ,ヤッカイ
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
ん 名詞,非自立,一般,*,*,*,ん,ン,ン
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
よ 助詞,終助詞,*,*,*,*,よ,ヨ,ヨ
。 記号,句点,*,*,*,*,。,。,。
EOS
jupyter labでもMeCabが使えるようになりました!!
☆2. twarcで取得したツイートを形態素解析する
実装方法をそのまま使用させていただきました。
(1)twarcで取得したツイートをMeCabで形態素解析し、単語ごとにカウント
(2)カウントした結果をMatplotlibで可視化
Twitter APIを申請する際に参考にさせていただいたHPは全て参考欄に記載しております。
(1)ライブラリのインポート〜Twitterの認証まで
import os
import urllib3
import json
from requests_oauthlib import OAuth1Session
from dotenv import find_dotenv, load_dotenv
import pandas as pd
import numpy as np
import MeCab
import collections
# 一応.envファイルからキーを取得
http = urllib3.PoolManager()
env_file = find_dotenv()
load_dotenv(env_file)
# 一応Twitterの認証
api_key = os.environ["API_KEY"]
api_secret_key = os.environ["API_SECRET_KEY"]
access_token = os.environ["ACCESS_TOKEN"]
access_token_secret = os.environ["ACCESS_TOKEN_SECRET"]
# KEY = os.environ.get("KEY")
# tweepyの認証
# auth = tweepy.OAuthHandler(api_key, api_secret_key)
# auth.set_access_token(access_token, access_token_secret)
# api = tweepy.API(auth)
(2)MeCabで形態素解析、開始!
# twarcで保存したcsvファイルの読み込み
df = pd.read_csv("results_day.csv", encoding="utf-8", parse_dates=["created_at"], low_memory=False)
# df = pd.DataFrame(twarcData)
# NEologd辞書を読み込む
path = "-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd"
m = MeCab.Tagger(path)
# m = MeCab.Tagger ("-Ochasen")
# 形態素解析
words = []
for text in df["text"]:
node = m.parseToNode(text)
temp_words = []
while node:
word = node.surface
# 同じ単語は1回のみカウント
if word not in temp_words:
temp_words.append(word)
node = node.next
words += temp_words
# 単語の登場回数順に並び替え
c = collections.Counter(words)
(3)結果を綺麗なseabornで可視化
import seaborn
import matplotlib.pyplot as plt
import japanize_matplotlib
# グラフ描画
seaborn.set(font="IPAGothic") # フォント
seaborn.set(context="poster") # フォントサイズ
fig = plt.subplots(figsize=(20, 20)) # グラフのスケール
# 上位30項目
seaborn.countplot(y=words,order=[i[0] for i in c.most_common(30)])
plt.tight_layout()
plt.savefig("befirst30.png", dpi=300)
(5)どどん!※ 2022/07/24取得

参考にさせていただいた投稿にもある通り、
BEFIRSTとURLっぽいのと曲名、記号と見事に「てにをは」くらいしか分かりません。
一番多い語句が空白なのも謎だ、、(機械依存文字の可能性もあるでしょうか)
新語・固有表現に強い「mecab-ipadic-NEologd」辞書を使用したのですが
「BE:FIRST」がまだ登録されていないので「BE」「:」「FIRST」で分かれてしまっています。
なので今度は記号や助詞、感嘆符、空白等を除外し取得期間を増やして
「名詞」と、感情を知りたいので「形容詞」、
":"も総計に入れたいため「記号」(":"以外は除外ワードに設定)に絞り、
改めてツイートを取得していきます("1"は除外しておりません)。
★3. 期間指定、除外ワードを含めて再取得開始
(1)ライブラリのインポート〜Twitterの認証まで
import tweepy
import os
import urllib3
import json
from requests_oauthlib import OAuth1Session
from dotenv import find_dotenv, load_dotenv
import pandas as pd
import csv
import MeCab
import collections
# 一応.envファイルからキーを取得
http = urllib3.PoolManager()
env_file = find_dotenv()
load_dotenv(env_file)
# 一応Twitterの認証
api_key = os.environ["API_KEY"]
api_secret_key = os.environ["API_SECRET_KEY"]
access_token = os.environ["ACCESS_TOKEN"]
access_token_secret = os.environ["ACCESS_TOKEN_SECRET"]
# KEY = os.environ.get("KEY")
# tweepyの認証
# auth = tweepy.OAuthHandler(api_key, api_secret_key)
# auth.set_access_token(access_token, access_token_secret)
# api = tweepy.API(auth)
(2)除外ワードの追加
df = pd.read_csv("results_day.csv", encoding="utf-8", parse_dates=["created_at"], low_memory=False)
# df = pd.DataFrame(twarcData)
path = "-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd"
m = MeCab.Tagger(path)
# m = MeCab.Tagger ("-Ochasen")
# 除外ワードの設定
exclude_keyword = [
"http",
"nhttps",
"https",
"co",
"://",
"RT",
"s",
"t",
"jy",
"|",
"。",
"、",
"!",
"!",
"?",
"*",
"ー",
"://",
"/",
"_",
"-",
".",
";",
"&",
",",
"'",
"(",
")",
"「",
"」",
"【",
"】",
"#",
"@",
" ",
"ん",
"て",
"に",
"を",
"は",
"の",
"が",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
"0",
"01",
"02",
"03",
"04",
"05",
"06",
"07",
"08",
"09",
"2022",
]
# 取得する品詞
include_hinshi = ["名詞", "形容詞", "記号"]
# 形態素解析
words = []
for text in df["text"]:
node = m.parseToNode(text)
temp_words = []
while node:
hinshi = node.feature.split(",")[0]
word = node.surface
if hinshi in include_hinshi and word not in exclude_keyword and word not in temp_words:
# if word not in exclude_keyword and word not in temp_words:
temp_words.append(word)
node = node.next
words += temp_words
c = collections.Counter(words)
print(c.most_common(30))
# [('FIRST', 341506), (':', 341385), ('BE', 280039), ('BEFIRST', 254583), ('ByeGoodBye', 146193), ('Gifted', 126996), ('Good-Bye', 120892), ('Bye', 107262), ('Me', 100349), ('Wake', 100289), ('Up', 100204), ('Don', 86407), ('1', 85140), ('BEFIRSTofficial', 81705), ('️', 72202), ('feat', 62944), ('DontWakeMeUp', 58104), ('Blue', 57703), ('JonasBluexBEFIRST', 44384), ('ビーワン', 31691), ('Game', 29980), ('💕', 29310), ('Scream', 29303), ('最高', 28235), ('Jonas', 27464), ('al', 24641), ('Betray', 24511), ('❤', 24141), ('ジョナス・ブルー', 23329), ('✨', 22881)]
(3)seabornで可視化
import seaborn
import matplotlib.pyplot as plt
import japanize_matplotlib
# グラフ描画
seaborn.set(font="IPAexGothic")
seaborn.set(context="poster")
fig = plt.subplots(figsize=(20, 20))
# 上位30項目
seaborn.countplot(y=words,order=[i[0] for i in c.most_common(30)])
plt.tight_layout()
plt.savefig("befirst30_twarc.png", dpi=300)
(4)どどん!上位30項目 ※ 7月24日取得(集計期間:7月18日〜7月24日)
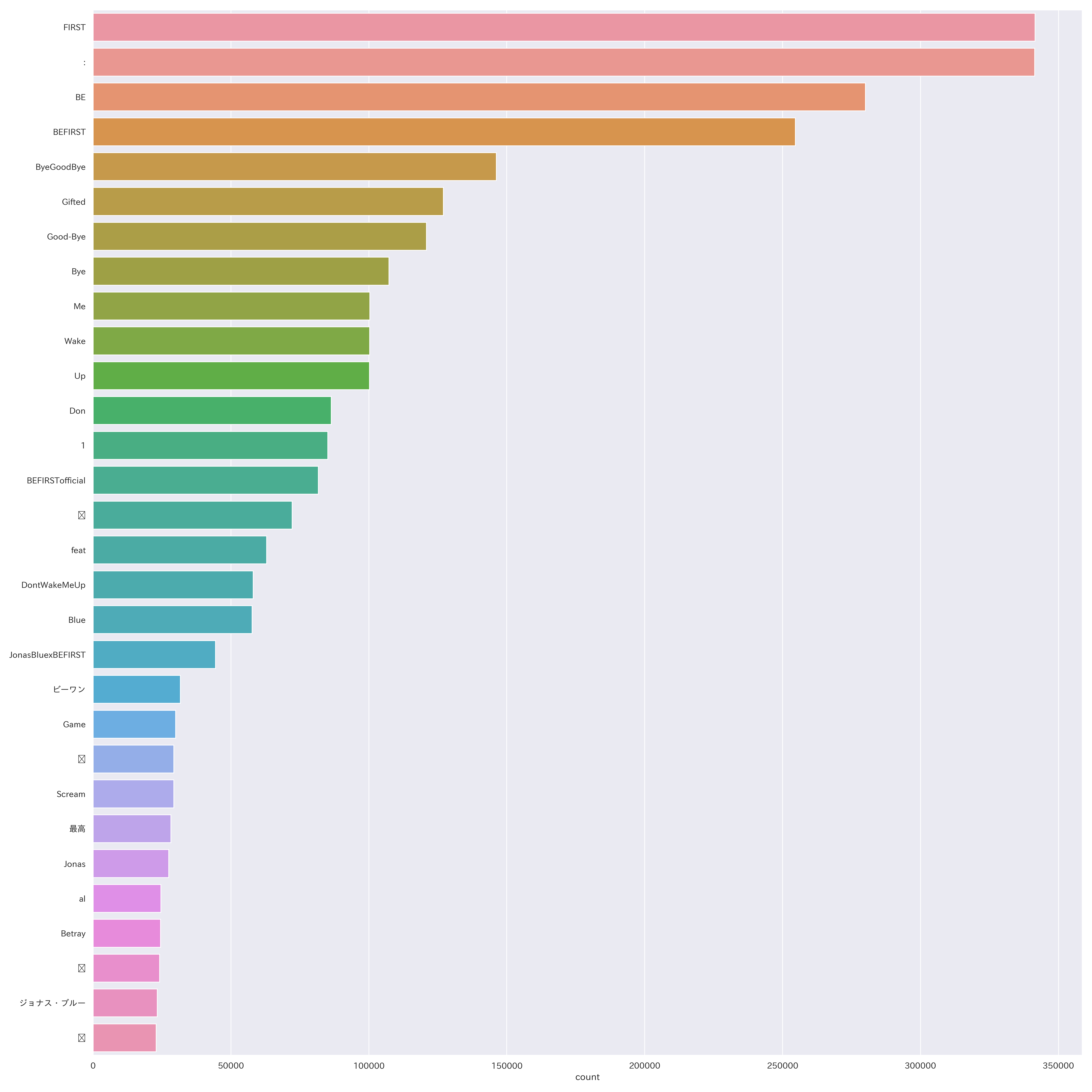
※ 絵文字化け:「(不明)」72,202件、「💕」29,310件、「❤」24,141件、「✨」22,881件
ほとんどがリリックビデオや曲名についての単語です。
30項目中、単語としての感情が「最高」(28,235件)の一単語だけなのも興味深いですね
(タグの一部も入っていると思われます。タグに使われている言葉が上位に入っています)。
(5)上位50項目
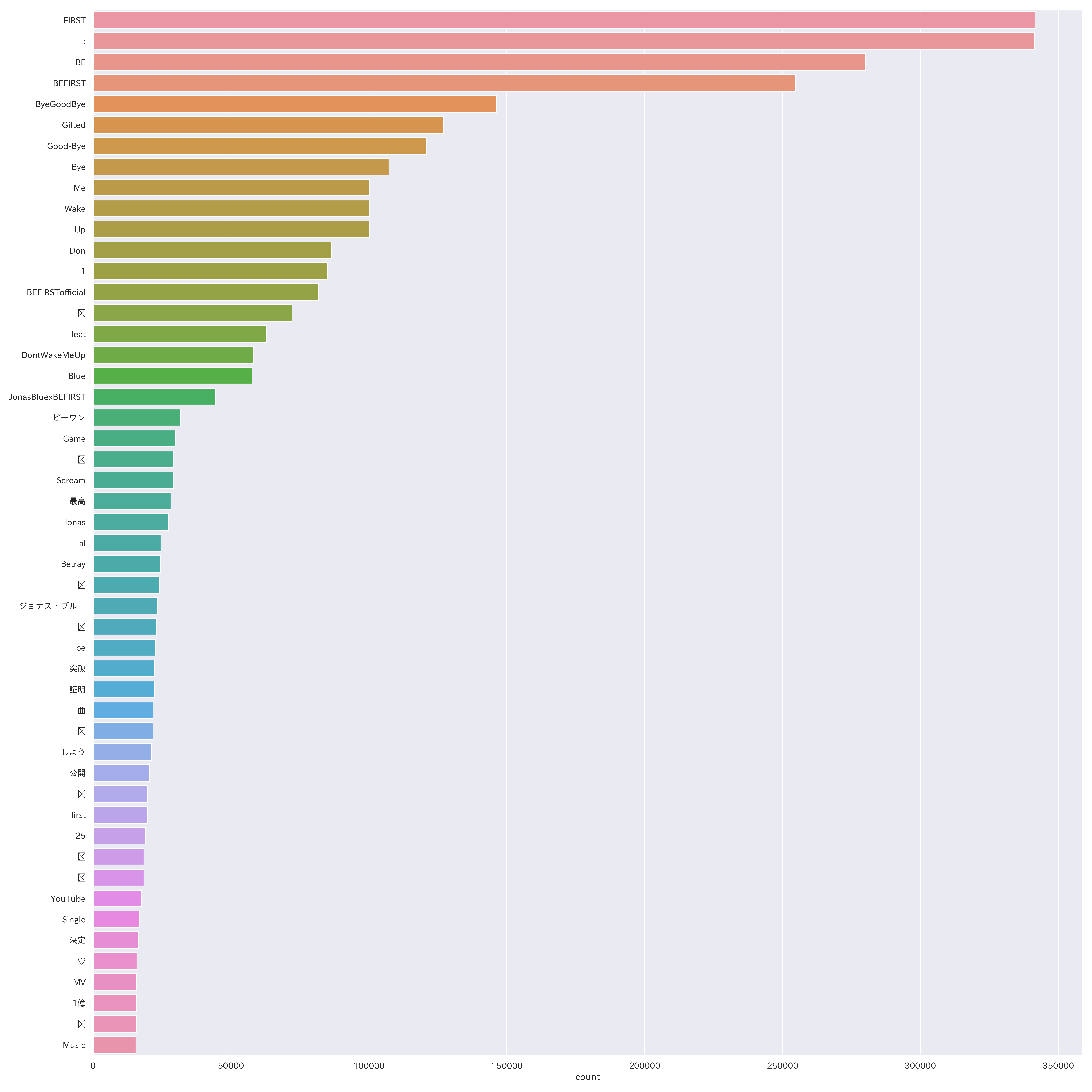
※ 絵文字化け:「(不明)」72,202件、「💕」29,310件、「❤」24,141件、「✨」22,881件、
「🎧」21,762件、「🔥」19,694件、「📣」18,495件、「💗」18,462件、「😊」15,740件
「Don't Wake Me Up」(459,709件、"Me"、"Wake"、"Up"、"Don"、"nDon"、
"DontWakeMeUp"の合算計)、
「Bye-Good-Bye」(389,186件、"Bye-Good-Bye"、"Bye"、"nBye"、"Good-Bye"の合算計)、
「Betrayal Game」(89,791件、"BetrayalGame"と"Betray"、"al"、"Game"の合算計)や
「Scream」(29,303件)などの曲名が上位を占めています。
(6)上位80項目
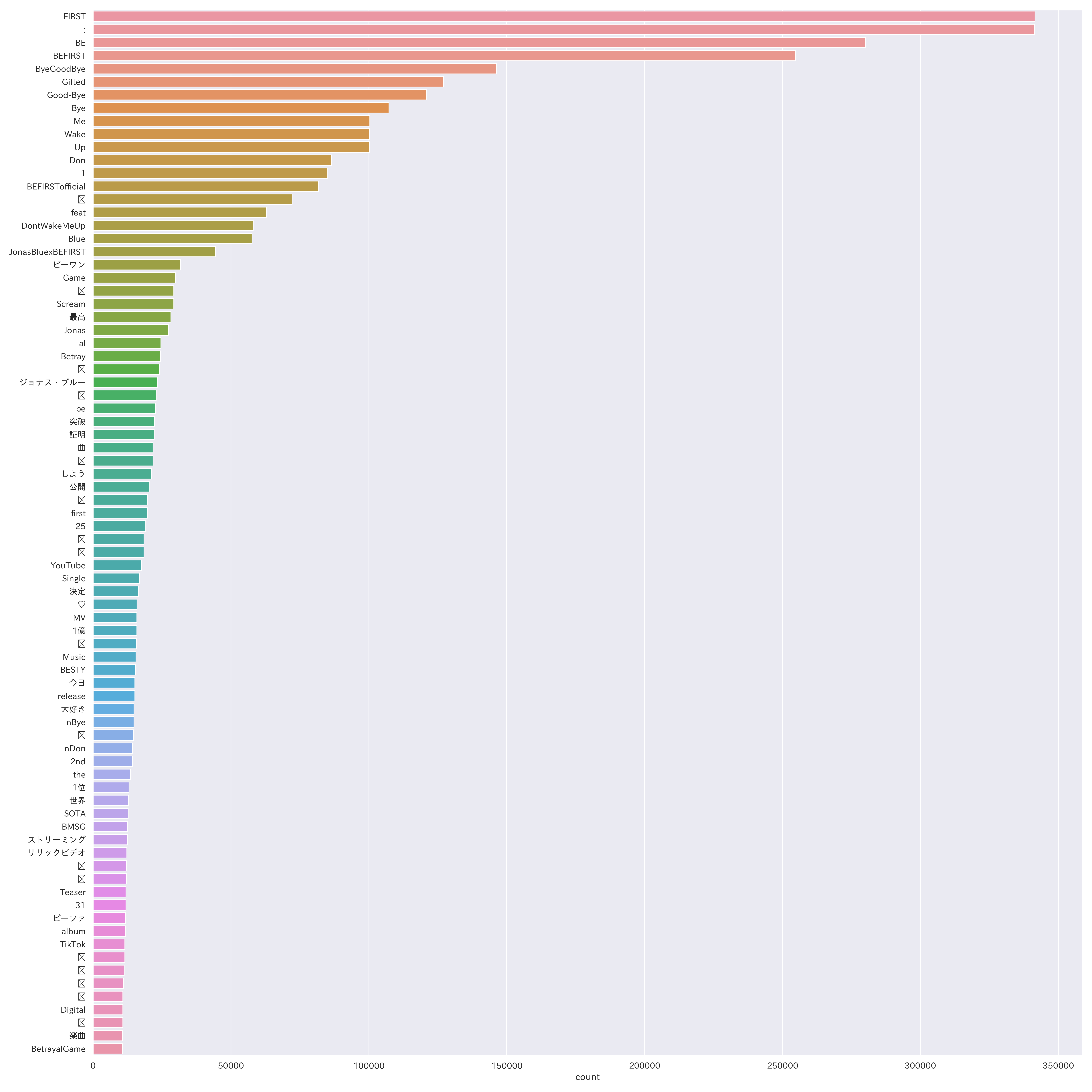
※ 絵文字化け:「(不明)」72,202件、「💕」29,310件、「❤」24,141件、
「✨」22,881件、「🎧」21,762件、「🔥」19,694件、「📣」18,495件、「💗」18,462件、
「😊」15,740件、「🙏」14,779件、「☺」12,219件、「😆」 12,126件、
「(不明)」11,567件、「🔗」11,288件、「🎶」11,061件、「🥰」10,838件、「🙌」10,814件
推測していた形容詞「大好き」(14,884件)が上位80項目で入ってきました。
およそ30万件中「楽しみ」のツイートが9,835件なのも興味深いですね。
ダルツォネに「敵の姿を勝手に想像するな」と言われそうです(※敵ではありません)。
まだ曲名やタグの文章と思われる単語がほとんどを占めています。
(7)上位100項目
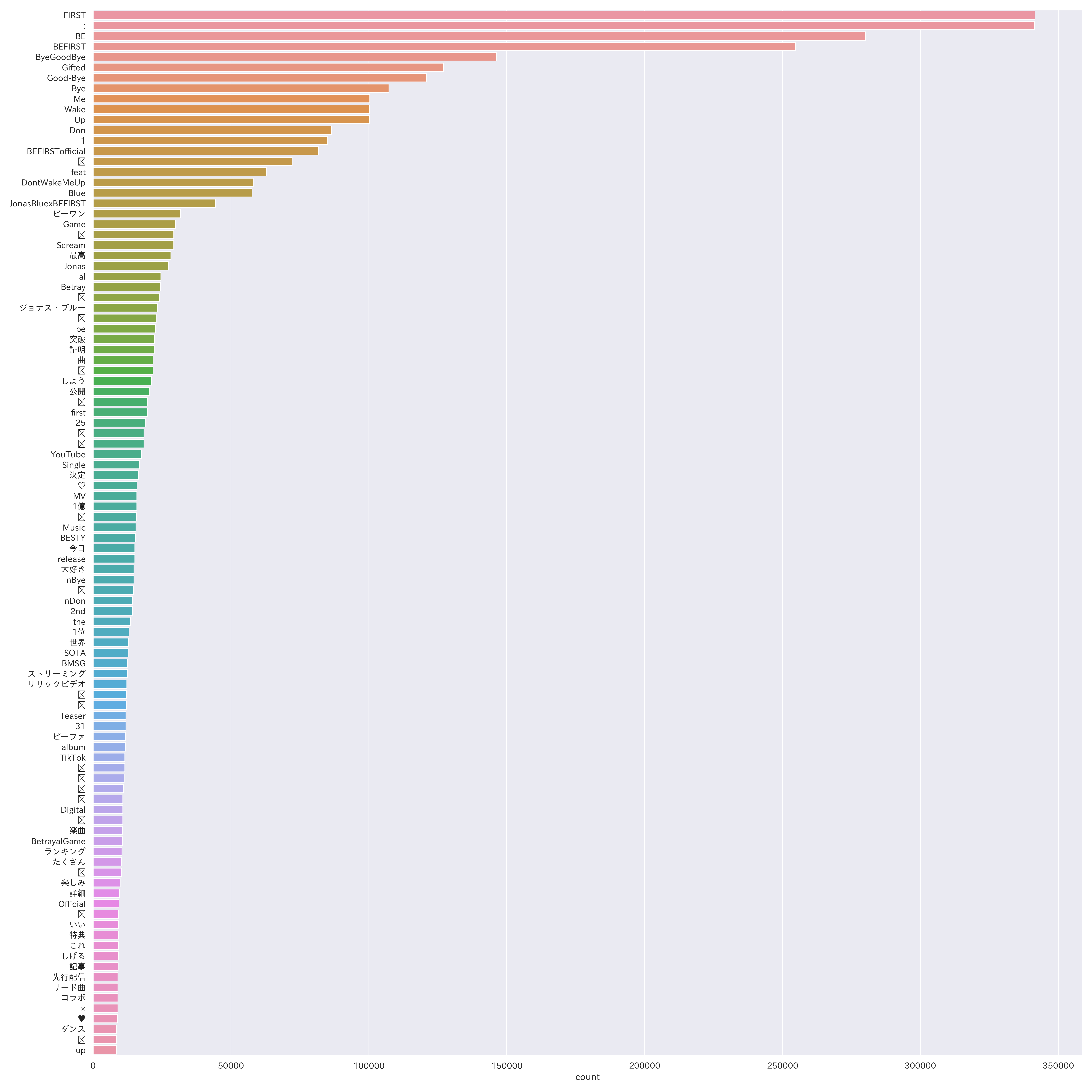
※ 絵文字化け:「(不明)」72,202件、「💕」29,310件、「❤」24,141件、
「✨」22,881件、「🎧」21,762件、「🔥」19,694件、「📣」18,495件、
「💗」18,462件、「😊」15,740件、 「🙏」14,779件、「☺」12,219件、
「😆」 12,126件、「(不明)」11,567件、「🔗」11,288件、「🎶」11,061件、
「🥰」10,838件、「🙌」10,814件、「👏」10,261件、「🎉」9,297件、「🐧」8,496件
「いい」(9,272件)は、おそらく歌詞にある「傷ついても君が"いい"」だと思われます。
(8)感情の単語(抜粋)
「好き」5,736件、「可愛い」3,284件、「かわいい」759件、
「かっこいい」1,040件、「カッコイイ」409件、「面白い」179件、「エモい」96件
かなりの数の形容詞が上位に入ってくると予想していたので驚きです…。
ザッと取得した30万件の単語を見ましたが、
10万件以降はほとんどが1件の単語で、文字の羅列(おそらくID)ばかりでした。
改善点
・ツイートを全文取得出来ていないためにURLに関する文字が多数あり除外ワードが大量発生
・ツイート取得時にRT、引用RT、リプを除外していないためこちらも大量発生
・個人の判断で除外ワードを設定しているため、ほぼ「私の」分析結果になってしまったこと
-> 客観的ではなく、かなり主観的な分析結果になってしまったような気がします。
また、"nDon"や"nBye"など、独断で曲名の一部と認識出来るワードも総計に入れています。
曲名にも入っている"-"はURLとの合算の可能性もあるため除外設定していました。
・絵文字率が高かったため、import emojiで絵文字を除外すべきだったかも
∟ 記号をあえて入れているためにたまに虚無(機械依存文字?)が存在してしまっている
-> 100項目に関しては20/100が絵文字と、あまり当てにならない分析結果になってしまった。
虚無が上位に入っていたので、どんな絵文字・記号だったのか気になって夜も眠れない。
・タグ #BEFIRSTで取得するとまた結果が変わるかもしれませんね。
・取得中、ファンがものすごい勢いで回っていたのでMacに無理させてしまったかなぁと…
こればかりは致し方ないのですが、、
分析をしてみての感想・考察(あくまでも個人的見解)
twarcで取得したツイートをMatplotlibでグラフ化するのに大変時間がかかってしまいました。
tweepyで練習を重ね、やっとtwarcで取得したツイートをグラフ化させることが出来ました。
その結果かなりギリギリになってしまいました。
本題から脱線してしまいますが
推測になりますが(自分の考えです)、「好き」「可愛い」「かっこいい」は前提で
(好きじゃないとわざわざツイートしない、例外もあると思いますが)ツイートするから、
文字としての感情は上位に浮上しにくいのではないかと。
「感情」を他の方と共有したいから「好き」は前提としてアカウントを作成、動かし、
また、情報収集のためにメインのアカウントとは別に作成している方々が多数だと考えます。
何かの「専用」アカウントを所持している時点で「好き」だから、
言葉に出して「好き」「かっこいい」等は言わないのかもしれない。
「かっこいい」という単語一つ取ってもいろんな言い方があるので、
「かっこいい」に集中せずバラけてしまっている可能性もありますね。
また、プロフィールやツイート内容から「何が好き」か把握することも出来るため、
同じ人・物が好きな方やFFさんであればツイートに主語を入れなくてもある程度は通じます。
自分自身がツイートするまでに、他のどなたかがツイートに目を通すまでに、
ありとあらゆる「前提」をたくさん通ってきているんですね。
今回分析したアーティストに関係なく「ツイートする」ボタンを押すまでに
たくさんの段階を踏んでツイートしなければなりません。
無意識に行っていますが、ルーティーン化されてしまっているようにも思います。
ツイートするまでの行動も人それぞれですよね。
「好き」だからツイートする
「興味がある」からツイートする
「意見がある」からツイートする
「報告したい」からツイートする
「感情を共有したい」からツイートする
「嫌い」だからツイートする
「どうでもいい」けどツイートする
「とりあえず」ツイートする
etc…
いろんな前提がありますね。
ツイートに「好き」と呟けば、同じ界隈であれば推しが「好き」と判断できますが、
単純に「好き」と呟かれたツイートを取得するだけでは、
主語がないため「何」が「好き」なのか判断は出来ません。
飼っているワンちゃん猫ちゃんが「好き」なのか?今食べている何かが「好き」なのか?
はたまた「好き(だけど嫌い)」が省略されているのか?前後のツイートと関連があるのか?
プロフィールに何が「好き」かの記載はあるのか?twarcではプロフィールも取得出来るので、
そこからも拾えたらいろいろと分析が広がりそうです。
まだまだ勉強が足らずそこまでたどり着けておりませんが…。
…と考えると「BE:FIRST」が好きなファンの方が「BE:FIRST」と呟くのか?
推しの名前だけで通じるから入れないのでは。。という考えに辿り着いてしまい、
この分析は…となっております…。
応援したいから、たくさんの方の目に触れてほしいから
アーティスト名をツイートしている可能性もあります。
「BE:FIRST」が「好き」という前提でツイートするのなら「BE:FIRST」を入れないかも。。
タグの #BEFIRST や"ビーファ"、メンバーの名前等の投稿が多いかもしれませんね。
ですが、こうやって身も知らない人にツイートを取得、分析される可能性があるので
公開アカウントで呟く際は注意が必要であることの再認識が出来ました。
ツイートを削除しても、もしその瞬間に取得されていたらずっと残ります。
ツイートデータがTwitterの「商品」だということを身を以て知りました。
また、新しいライブラリを使用することが出来て非常に楽しかったです。
AWS LambdaからTwitterにツイートしたり、時間指定してみたり、
はたまたLambdaにPIL入らん!!!!と頭を抱えたり、
形態素解析…!となりましたが、毎日かなり楽しかったです。
次は感情分析も出来たらなぁと思います。
大変長く、疎い記事をここまでお読みいただき本当にありがとうございました。
おまけ:twarcで取得出来るパラメータ
| パラメータ |
|---|
| id |
| conversation_id |
| referenced_tweets.replied_to.id |
| referenced_tweets.retweeted.id |
| referenced_tweets.quoted.id |
| author_id |
| in_reply_to_user_id |
| retweeted_user_id |
| quoted_user_id |
| created_at |
| text |
| lang |
| source |
| public_metrics.like_count |
| public_metrics.quote_count |
| public_metrics.reply_count |
| public_metrics.retweet_count |
| reply_settings |
| possibly_sensitive |
| withheld.scope |
| withheld.copyright |
| withheld.country_codes |
| entities.annotations |
| entities.cashtags |
| entities.hashtags |
| entities.mentions |
| entities.urls |
| context_annotations |
| attachments.media |
| attachments.media_keys |
| attachments.poll.duration_minutes |
| attachments.poll.end_datetime |
| attachments.poll.id |
| attachments.poll.options |
| attachments.poll.voting_status |
| attachments.poll_ids |
| author.id |
| author.created_at |
| author.username |
| author.name |
| author.description |
| author.entities.description.cashtags |
| author.entities.description.hashtags |
| author.entities.description.mentions |
| author.entities.description.urls |
| author.entities.url.urls |
| author.location |
| author.pinned_tweet_id |
| author.profile_image_url |
| author.protected |
| author.public_metrics.followers_count |
| author.public_metrics.following_count |
| author.public_metrics.listed_count |
| author.public_metrics.tweet_count |
| author.url |
| author.verified |
| author.withheld.scope |
| author.withheld.copyright |
| author.withheld.country_codes |
| geo.coordinates.coordinates |
| geo.coordinates.type |
| geo.country |
| geo.country_code |
| geo.full_name |
| geo.geo.bbox |
| geo.geo.type |
| geo.id |
| geo.name |
| geo.place_id |
| geo.place_type |
| __twarc.retrieved_at |
| __twarc.url |
| __twarc.version |
参考
・Twitter API取得〜.envファイル作成まで(VS Codeで作成しました)
・MeCab、形態素解析、可視化(matplotlib)