C#のDictionary<TKey,TValue>は、キーと値のペアを高速に管理するコレクションです。この記事では、.NET Runtimeの実装コードを元に、Dictionaryの内部構造と動作原理を解説します。
基本構造
Dictionaryはハッシュテーブルとして実装されています。主要なフィールドは以下の通りです。
private int[]? _buckets; // ハッシュバケット配列
private Entry[]? _entries; // エントリの実体配列
private int _count; // 要素数
private int _freeList; // 削除された要素のリスト
private int _freeCount; // 削除された要素の数
private IEqualityComparer<TKey>? _comparer; // キーの比較器
Entry構造体は、実際のデータを保持します。
private struct Entry
{
public uint hashCode; // キーのハッシュコード
public int next; // 次のエントリのインデックス(チェーン)
public TKey key; // キー
public TValue value; // 値
}
データ構造の詳細
Dictionaryは、エントリチェーンの先頭を指す_buckets配列と、実際のデータそのものを格納する_entries配列の、2つの配列を使った巧妙な設計になっています。
_bucketsと_entriesの関係
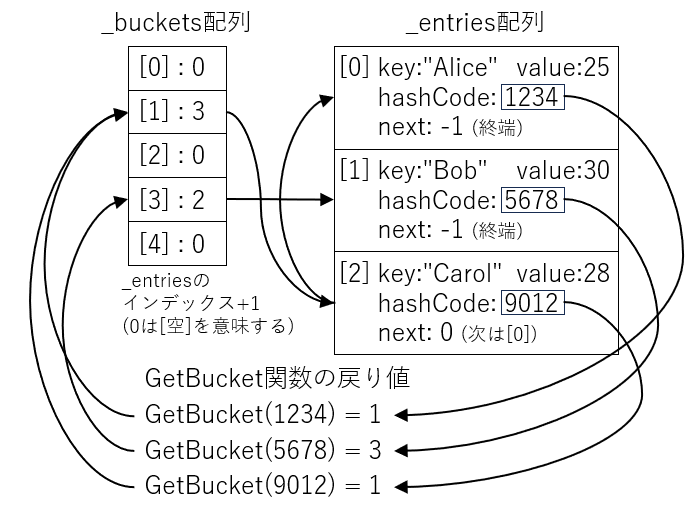
なぜ2層構造なのか?
- _buckets: ハッシュ値からエントリーチェーンの開始位置を高速に特定
- _entries: 実際のデータを格納し、チェーンを形成
この設計により、圧縮されたハッシュ値による高速な検索と、チェーンの線形探索による絞り込みという、メモリ効率とパフォーマンスのバランスが取れた実装となっています。
バケットのインデックスが「1始まり」の理由
実装を見ると、バケットの値は常にindex + 1で格納されています。
bucket = index + 1; // Value in _buckets is 1-based
これは0を「空」の状態として扱うためです。
0 → バケットが空(まだ要素が割り当てられていない)
1 → _entries[0]を指す
2 → _entries[1]を指す
...
この工夫により、初期化時に配列を0で埋めるだけで「すべて空」の状態を表現できます。
バケットのチェーン構造
複数のキーが一つのバケットにマップされた場合、連結リストで管理されます。
_buckets[1] = 3 (最後に追加された要素を指す)
↓
_entries[2]: key: "Carol" next: 0
↓
_entries[0]: key: "Alice" next: -1 (終端)
検索時は、このチェーンを先頭から順に辿って、hashCodeとkeyの両方が一致するエントリを探します。
削除されたエントリの管理
要素を削除すると、そのスロットは再利用可能な状態になります。
private const int StartOfFreeList = -3;
// 削除時
entry.next = StartOfFreeList - _freeList; // -3, -4, -5, ...
_freeList = i; // 削除したインデックスを記録
_freeCount++;
nextフィールドが負の値(-2以下)の場合、そのエントリは削除済みを意味します。
next >= -1 → 使用中(-1は終端、0以上はチェーン)
next < -1 → 削除済み(フリーリストの一部)
新しい要素を追加する際は、まずフリーリストから空きスロットを再利用し、なければ配列の末尾に追加します。
if (_freeCount > 0)
{
index = _freeList; // 削除済みスロットを再利用
_freeList = StartOfFreeList - entries[_freeList].next;
_freeCount--;
}
else
{
index = _count; // 新しいスロットを使用
_count++;
}
この仕組みにより、削除と追加を繰り返してもメモリの断片化を最小限に抑えられます。
要素の追加処理
要素を追加するAddメソッドは、内部的にTryInsertを呼び出します。
public void Add(TKey key, TValue value)
{
bool modified = TryInsert(key, value, InsertionBehavior.ThrowOnExisting);
}
TryInsertの動作は以下の手順で進みます。
ハッシュコードの計算
uint hashCode = (uint)((typeof(TKey).IsValueType && comparer == null)
? key.GetHashCode()
: comparer!.GetHashCode(key));
キーが値型で比較器がない場合はGetHashCodeを直接呼び出し、それ以外は比較器経由で取得します。
バケットの特定
ref int bucket = ref GetBucket(hashCode);
int i = bucket - 1; // バケットの値は1始まり
GetBucketメソッドは、ハッシュコードから、_buckets配列の対応するインデックスを返します。
private ref int GetBucket(uint hashCode)
{
int[] buckets = _buckets!;
#if TARGET_64BIT
return ref buckets[HashHelpers.FastMod(hashCode, (uint)buckets.Length, _fastModMultiplier)];
#else
return ref buckets[(uint)hashCode % buckets.Length];
#endif
}
64ビット環境では、高速な剰余計算(FastMod)が使用されます。
衝突のチェック
同じバケットに既に要素がある場合、チェーンを辿って既存のキーと比較します。
while ((uint)i < (uint)entries.Length)
{
if (entries[i].hashCode == hashCode &&
EqualityComparer<TKey>.Default.Equals(entries[i].key, key))
{
// 既存のキーが見つかった場合の処理
if (behavior == InsertionBehavior.ThrowOnExisting)
{
ThrowHelper.ThrowAddingDuplicateWithKeyArgumentException(key);
}
return false;
}
i = entries[i].next; // 次のエントリへ
collisionCount++;
}
新しいエントリの追加
空きスロットを見つけて、新しいエントリを追加します。
ref Entry entry = ref entries![index];
entry.hashCode = hashCode;
entry.next = bucket - 1; // チェーンに接続
entry.key = key;
entry.value = value;
bucket = index + 1; // バケットを更新
_version++;
検索アルゴリズム
FindValueメソッドは、キーから値への参照を返します。
internal ref TValue FindValue(TKey key)
{
if (_buckets != null)
{
uint hashCode = (uint)EqualityComparer<TKey>.Default.GetHashCode(key);
int i = GetBucket(hashCode);
Entry[]? entries = _entries;
uint collisionCount = 0;
i--; // 1始まりを0始まりに変換
do
{
if ((uint)i >= (uint)entries.Length)
{
goto ReturnNotFound;
}
entry = ref entries[i];
if (entry.hashCode == hashCode &&
EqualityComparer<TKey>.Default.Equals(entry.key, key))
{
goto ReturnFound;
}
i = entry.next;
collisionCount++;
} while (collisionCount <= (uint)entries.Length);
goto ConcurrentOperation; // 無限ループ検出
}
goto ReturnNotFound;
}
- ハッシュコードを計算し、対応するバケットを特定
- チェーンを辿りながらキーを比較
- 一致するエントリが見つかれば値を返す
このアルゴリズムの特徴:
- O(1)の平均計算量: ハッシュが適切に分散していれば、ほぼ一定時間で検索できる
-
チェーンの追跡: 衝突がある場合、
nextフィールドを辿る -
無限ループ検出:
collisionCountで並行更新による異常を検出
リサイズ処理
要素数が増えると、配列を拡張して再ハッシュします。この処理は非常に重要で、Dictionaryのパフォーマンスに大きく影響します。
リサイズのトリガー
リサイズはTryInsert内で、新しい要素を追加しようとしたときに発生します。
int count = _count;
if (count == entries.Length)
{
Resize(); // 配列が満杯になったらリサイズ
bucket = ref GetBucket(hashCode);
}
つまり、_entries配列に空きスロットがなくなった時点でリサイズが実行されます。
新しいサイズの決定
private void Resize() => Resize(HashHelpers.ExpandPrime(_count), false);
HashHelpers.ExpandPrimeは、現在のサイズより大きい素数を返します。
旧サイズ → 新サイズ(素数)
3 → 7
7 → 17
17 → 37
37 → 79
79 → 163
163 → 331
...
素数を使う理由は、ハッシュコードの剰余計算(hashCode % size)でより均等な分散が得られるためです。
リサイズの詳細な手順
private void Resize(int newSize, bool forceNewHashCodes)
{
Debug.Assert(_entries != null, "_entries should be non-null");
Debug.Assert(newSize >= _entries.Length);
// ステップ1: 新しいentries配列を作成してデータをコピー
Entry[] entries = new Entry[newSize];
int count = _count;
Array.Copy(_entries, entries, count); // 既存データをコピー
// ステップ2: 必要に応じてハッシュコードを再計算
if (!typeof(TKey).IsValueType && forceNewHashCodes)
{
Debug.Assert(_comparer is NonRandomizedStringEqualityComparer);
IEqualityComparer<TKey> comparer = _comparer =
(IEqualityComparer<TKey>)((NonRandomizedStringEqualityComparer)_comparer)
.GetRandomizedEqualityComparer();
// 文字列キーの場合、ランダム化されたハッシュを再計算
for (int i = 0; i < count; i++)
{
if (entries[i].next >= -1)
{
entries[i].hashCode = (uint)comparer.GetHashCode(entries[i].key);
}
}
}
// ステップ3: 新しいbuckets配列を作成
_buckets = new int[newSize]; // すべて0で初期化される
#if TARGET_64BIT
_fastModMultiplier = HashHelpers.GetFastModMultiplier((uint)newSize);
#endif
// ステップ4: すべてのエントリを新しいバケットに再配置(再ハッシュ)
for (int i = 0; i < count; i++)
{
if (entries[i].next >= -1) // 使用中のエントリのみ処理
{
ref int bucket = ref GetBucket(entries[i].hashCode);
entries[i].next = bucket - 1; // 新しいチェーンに接続
bucket = i + 1;
}
}
_entries = entries;
}
配列サイズの変化
_backets配列と_entries配列の両方が、新しいサイズに拡張されます。例えば、現在のサイズが7で満杯の場合、リサイズ後は両方とも17になります。
リサイズ前:
_buckets.Length = 7
_entries.Length = 7
_count = 7 (満杯)
↓ Resize(17, false)
リサイズ後:
_buckets.Length = 17 (新規作成)
_entries.Length = 17 (古いデータをコピー + 拡張)
_count = 7 (変わらず)
再ハッシュの必要性
バケットサイズが変わると、同じハッシュコードでも異なるバケットにマッピングされます。
例: ハッシュコード = 25
旧サイズ 7の場合:
25 % 7 = 4 → _buckets[4]
新サイズ 17の場合:
25 % 17 = 8 → _buckets[8]
このため、すべてのエントリを新しいバケット配列に再配置する必要があります。
forceNewHashCodesパラメータ
このフラグがtrueの場合、ハッシュコード自体を再計算します。これはハッシュの衝突が多発した場合の対策です。
// 衝突が多すぎる場合、ランダム化されたハッシュに切り替え
if (!typeof(TKey).IsValueType &&
collisionCount > HashHelpers.HashCollisionThreshold &&
comparer is NonRandomizedStringEqualityComparer)
{
Resize(entries.Length, true); // forceNewHashCodes = true
}
通常、文字列キーの場合は非ランダム化された比較器(NonRandomizedStringEqualityComparer)が使われます。これはパフォーマンスのための最適化ですが、偶然多くのキーが同じバケットに集中してしまうことがあります。
衝突が閾値(HashCollisionThreshold)を超えた場合、ランダム化されたハッシュ関数に切り替えることで、キーをより均等に分散させ、パフォーマンス劣化を回避します。
リサイズのコスト
リサイズはO(n) の操作です:
-
Array.Copy: O(n) - 既存データのコピー - 再ハッシュループ: O(n) - すべてのエントリを再配置
ただし、リサイズは指数的な間隔で発生するため(3→7→17→37...)、償却計算量はO(1) になります。つまり、n個の要素を追加する全体のコストはO(n)です。
GetHashCodeの重要性
Dictionaryの性能は、キーのハッシュコードの品質に大きく依存します。
良いハッシュ関数の条件
- 決定性: 同じオブジェクトは常に同じハッシュコードを返す
- 均等分散: 異なるオブジェクトは、なるべく異なるハッシュコードを持つ
- 高速: 計算コストが低い
悪い実装例
public class BadKey
{
public int Id { get; set; }
public string Name { get; set; }
// ❌ 常に同じ値を返す
public override int GetHashCode() => 0;
}
このようなキーを使うと、すべての要素が同じバケットに格納され、検索がO(n) に劣化します。
良い実装例
public class GoodKey
{
public int Id { get; set; }
public string Name { get; set; }
// ✅ 複数のフィールドを組み合わせる
public override int GetHashCode()
{
return HashCode.Combine(Id, Name);
}
public override bool Equals(object? obj)
{
return obj is GoodKey other &&
Id == other.Id &&
Name == other.Name;
}
}
HashCode.Combineを使うと、複数の値から品質の高いハッシュコードを生成できます。
Equalsとの整合性
重要な原則: Equalsで等しいオブジェクトは、同じハッシュコードを返さなければなりません。
// ✅ 正しい実装
if (a.Equals(b))
{
Debug.Assert(a.GetHashCode() == b.GetHashCode());
}
逆は必須ではありません(異なるオブジェクトが同じハッシュコードを持つことは許容されます)。
まとめ
Dictionary<TKey,TValue>の主要なポイント:
-
ハッシュテーブル構造:
_buckets配列と_entries配列の2層構造 - O(1)の検索: 適切なハッシュ関数により高速アクセスを実現
- 動的リサイズ: 要素数の増加に応じて自動的に拡張
- GetHashCodeの品質: パフォーマンスに直結する重要な要素
カスタムクラスをDictionaryのキーとして使う場合は、必ずGetHashCodeとEqualsを適切に実装しましょう。これにより、Dictionaryの真の性能を引き出すことができます。