皆様メリークリスマス!ふぁむたろうです。 記事遅れてしまいすみませんでした
自分はここ1年くらいのコンペでは脳死で wandb(Weights & Bias) を使って実験管理をしていたのですが、1年の節目ということで他のツール(サービス)も見てみようと思い記事にしました。
(余談ですが wandb の読み方は「Weights & Bias」でも「ワンディービー」でも「ダブリューアンドビー」でも良いっぽいです)
特に業務上で使う場合 pricing 等も気をつけなきゃいけないため、この記事ではそこらへんにも触れていければと思います。
とはいえ昨今の実験管理ツールはたくさんあるので、今回は以下の5つに絞って比較してみます。
(pytorch lightning に標準装備されているもの)
pricing等は2021年12月4日時点の情報であることに注意
結論
そんなに大差ないので目的に応じて好きなもの使いましょう。
0. ここでいう実験管理とは
実験管理という言葉がいろんな意味を持つと思うので、この記事では以下のような意味で使います。
ですので 実験で使用したコードの管理 とか デプロイ周りの管理 とかは今回触れないのでご注意ください。
「実験で設定したパラメータ(ハイパラ)」と「結果(各種指標)」を一箇所にまとめて比較できるようにすること
- パラメータ(ハイパラ)
- lr とか
- あとは当時のお気持ちとか
- 結果(各種指標)
- Loss(train, valid) とか Accuracy とか
- あとついでに計算リソースの使用具合とかも見れればハッピー
1. Q. 実験管理って必要?csvやlogに吐き出せば良くない?
A. なくても実験はできるけどあるととても便利
自分も最初は下記で対応できるだろうしいらんやろって思ってました。
- 結果をコンソールに吐き出す
- コンソール上で cat とか叩く
- csv を後で jupyter notebook とかで見る(pandas とか matplotlib で)
- 神から賜りし表計算ソフトウエア Excel にて集計する
ただKaggleや長期PJ等で何十回何百回も実験してると下記のような気持ちを持ってしまいました。
- 毎回図にするの手間
上司とかPMにちょっとアレとアレを比較した図を作ってよとか言われたときのめんどくさという気持ち- 1実験の図ならスクリプトで学習スクリプトの後に一緒に作成できると思いますが、比較した図が欲しいシーンが多いのかなと思います
- 特定の実験同士を比較した図を作るの手間
- 各実験の各epochでの loss や metrics の挙動
- 3つ以上の実験パラメータと結果を比較するの手間
そのような経緯で Tensorboard とかを触り始めたところ、思っていたより便利で今でも使えるときは使うようになりました。
2. 各ツール(サービス)の紹介
大まかに分けると SaaS か否かであり、業務等でクラウドが許されていない場合 Offline mode にするか TensorBoard か MLflow を使いましょう。
-
TensorBoard
- 一番触っている人が多いのではないかと思います
- 大体 TensorFlow や PyTorch をインストールするときに一緒にインストールすることが多いのかなと思います
- 気軽にローカルや適当なサーバーで Tensorboard を開けば図とかが見れるイメージです
- どちらかというと結果を送るというより指定した場所に自分で置く感じです
-
MLflow
- OSS ということで個人や業務でもあまり気を使わずに使えるのがポイント
- ローカルに置いて見ても良いし、S3等に置いて見ることも可能
- またサーバーを立ててそこに REST API 形式で送ることも可能
- また
An open source platform for the machine learning lifecycleと謳っているだけあって、mlflow で管理できる対象が多い- Tracking: コードや設定、結果の管理
- Projects: 実験の再現周りの管理
- Models: Deploy 周りの管理
- Registry: 上記含めた全体の管理
- 各種 API を揃えていて Python 以外でも利用できる
- Python API
- R API
- Java APU
- REST API
- ただし全体の機能がリッチ(複雑)なため Tracking 以外は導入ハードルが高そう
-
Neptune.ai(neptune)
- SaaS(結果をクラウドにあげるイメージ)
- 各種 API が揃っている
- Python API
- R API
- neptune.ai は頻繁に実験管理ツールの比較Blogを書いていて、UI とかも気を使ってそう
-
Weights & Biases(wandb)
- SaaS
- 個人的には一番手軽で見た目が好み
- 主に Python のみが対象
-
Comet
- SaaS
- wandb よりももう少し UI をシンプルにした印象
- 主に Python のみが対象
3. 使ってみた
3.1 環境
- CUDA 11.1
- Python 3.7.10
各種ライブラリ
torch==1.8.1+cu111
torchvision==0.9.1+cu111
lightning-bolts==0.4.0
pytorch-lightning==1.5.4
torchmetrics==0.6.0
# 使いたいものだけ pip install する。TensorBoard は上記を install すると入っているので不要
mlflow==1.22.0
neptune-client==0.13.3
wandb==0.12.7
comet-ml==3.23.0
3.2 事前準備
neptune、wandb、cometについては事前にユーザー登録が必要です。
(いずれもGoogleやGitHubアカウントがあれば数クリックでできます)
3.2.1 Neptune.ai
Neptune.aiの場合Webページ上でログインして右上のタブから Get Your API token をクリックしてトークンを取得します。
次に下記のようにして環境変数に入れておきます。
export NEPTUNE_API_TOKEN=<YOUR API TOKEN>
呼び出すときは os.environ["NEPTUNE_API_TOKEN"] のようにして呼び出します。くれぐれもコードに直接API tokenを記載しないようにしましょう。
また Neptune.ai の場合予めプロジェクトを作っておく必要があるので、Web上でログインして create project からプロジェクトを作っておきます。
3.2.2 Weights & Biases(wandb)
wandb の場合 pip install wandb の後にコンソール上で wandb login で必要情報を入力してログインしても良いですし、Web上でログインして Settings → API keys から API key をコピーして wandb login <API key> を入力してもログインできます。
また python スクリプト内でログインしたい場合 wandb.login(key=api_key) のようにしてログインすることもできます。
3.2.1 Comet
Neptune.ai と同様に、Webページ上でログインして Settings → API key から API key をコピーして下記のように環境変数に入れておきます。
export COMET_API_TOKEN=<YOUR API TOKEN>
呼び出すときも同様に os.environ["COMET_API_TOKEN"] で呼び出します。
- comet
3.3 使用コード
今回は下記の pytorch-lightning コードを base として作成しました。
コードは少し長いので折りたたみタブ内に入れました。
コードでやりたいこととしては下記のようなことです。
- データ: CIFAR10
- モデル: ResNet18
- 変えたい設定(ハイパーパラメータ)
- learning rate(lr)
- batch size(bs)
main.py
"""
https://pytorch-lightning.readthedocs.io/en/stable/notebooks/lightning_examples/cifar10-baseline.html
"""
import os
import argparse
import comet_ml
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from pytorch_lightning import LightningModule, Trainer, seed_everything
from pytorch_lightning.callbacks import LearningRateMonitor
from pytorch_lightning.loggers import (CometLogger, MLFlowLogger,
NeptuneLogger, TensorBoardLogger,
WandbLogger)
from torch.optim.lr_scheduler import OneCycleLR
from torchmetrics.functional import accuracy
from pl_bolts.datamodules import CIFAR10DataModule
from pl_bolts.transforms.dataset_normalizations import cifar10_normalization
def create_model():
model = torchvision.models.resnet18(pretrained=False, num_classes=10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
model.maxpool = nn.Identity()
return model
class LitResnet(LightningModule):
def __init__(self, params):
super().__init__()
self.save_hyperparameters(params)
self.model = create_model()
def forward(self, x):
out = self.model(x)
return F.log_softmax(out, dim=1)
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
acc = accuracy(preds, y)
self.log(f"valid_loss", loss, prog_bar=True)
self.log(f"valid_acc", acc, prog_bar=True)
def configure_optimizers(self):
optimizer = torch.optim.SGD(
self.parameters(),
lr=self.hparams.lr,
momentum=0.9,
weight_decay=5e-4,
)
steps_per_epoch = 45000 // self.hparams.bs
scheduler_dict = {
"scheduler": OneCycleLR(
optimizer,
0.1,
epochs=self.trainer.max_epochs,
steps_per_epoch=steps_per_epoch,
),
"interval": "step",
}
return {"optimizer": optimizer, "lr_scheduler": scheduler_dict}
def make_parse():
parser = argparse.ArgumentParser()
arg = parser.add_argument
arg("--exp", default="exp0", type=str)
arg("--lr", default=0.05, type=float)
arg("--bs", default=256, type=int)
return parser.parse_args()
def main():
args = make_parse()
seed_everything(1222)
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
cifar10_normalization(),
])
test_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
cifar10_normalization(),
])
cifar10_dm = CIFAR10DataModule(
data_dir=".",
batch_size=args.bs,
num_workers=int(os.cpu_count() / 2),
train_transforms=train_transforms,
test_transforms=test_transforms,
val_transforms=test_transforms,
)
model = LitResnet(args)
# model.datamodule = cifar10_dm
project_name = "kaggle-advent-calendar2021"
logger = [
TensorBoardLogger("tensorboard_logs/", name=args.exp),
MLFlowLogger(
experiment_name=project_name,
run_name=args.exp,
save_dir='./mlruns'
),
NeptuneLogger(
api_key=os.environ["NEPTUNE_API_TOKEN"],
project=f"yukkyo/{project_name}",
tags=["training", "sample"], # optional
),
WandbLogger(
name=args.exp,
save_dir=None,
offline=False,
project=project_name,
group="sample"
),
CometLogger(
api_key=os.environ["COMET_API_TOKEN"],
save_dir="comet_logs", # Optional
project_name=project_name,
experiment_name=args.exp
)
]
trainer = Trainer(
max_epochs=30,
gpus=1,
logger=logger,
callbacks=[LearningRateMonitor(logging_interval="step")],
)
trainer.fit(model, cifar10_dm)
if __name__ == '__main__':
main()
上記のコードに対して下記のように設定を変えて実験したとします。
$ python main.py --exp exp0 --lr 0.05 --bs 256
$ python main.py --exp exp1 --lr 0.01 --bs 256
$ python main.py --exp exp2 --lr 0.05 --bs 512
$ python main.py --exp exp3 --lr 0.01 --bs 512
またここでは紹介していませんが、neptune等は画像ファイルを送ったりもできるので、間違えたファイル等をまとめたい場合使えるかもしれません。
class LitModel(LightningModule):
def training_step(self, batch, batch_idx):
# log metrics
acc = ...
self.log("train/loss", loss)
def any_lightning_module_function_or_hook(self):
# log images
img = ...
self.logger.experiment["train/misclassified_images"].log(File.as_image(img))
3.4 学習結果の確認
3.4.1 TensorBoard
予め以下のようなコマンドを実行しておきます。
$ tensorboard --logdir tensorboard_logs --port 8857 --bind_all
- 以前よりもUIが洗練されてる気がします
- ローカル(サーバー)で動かしている分、サーバーからのレスポンスが速い環境であればサクサク動いて快適です
- 一方各図は縦にしか並べなさそう?でした
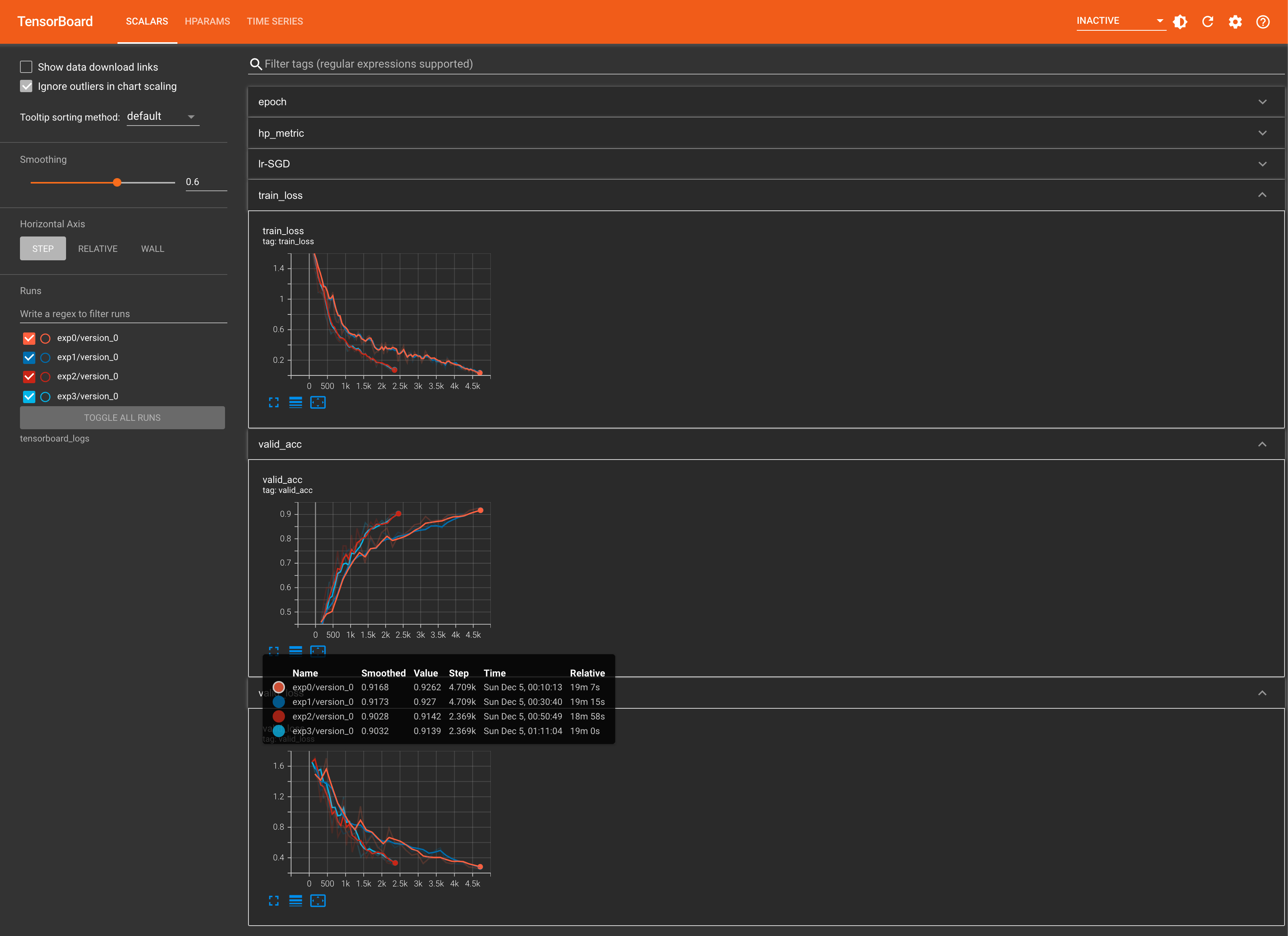
- また設定したハイパラは別タブで見ることができました
- しかし正しく使えていなかったのか、この画面で評価指標を見ることができませんでした…
- 通常のログとは別に
hp_metricのような属性で保存しないといけない…?
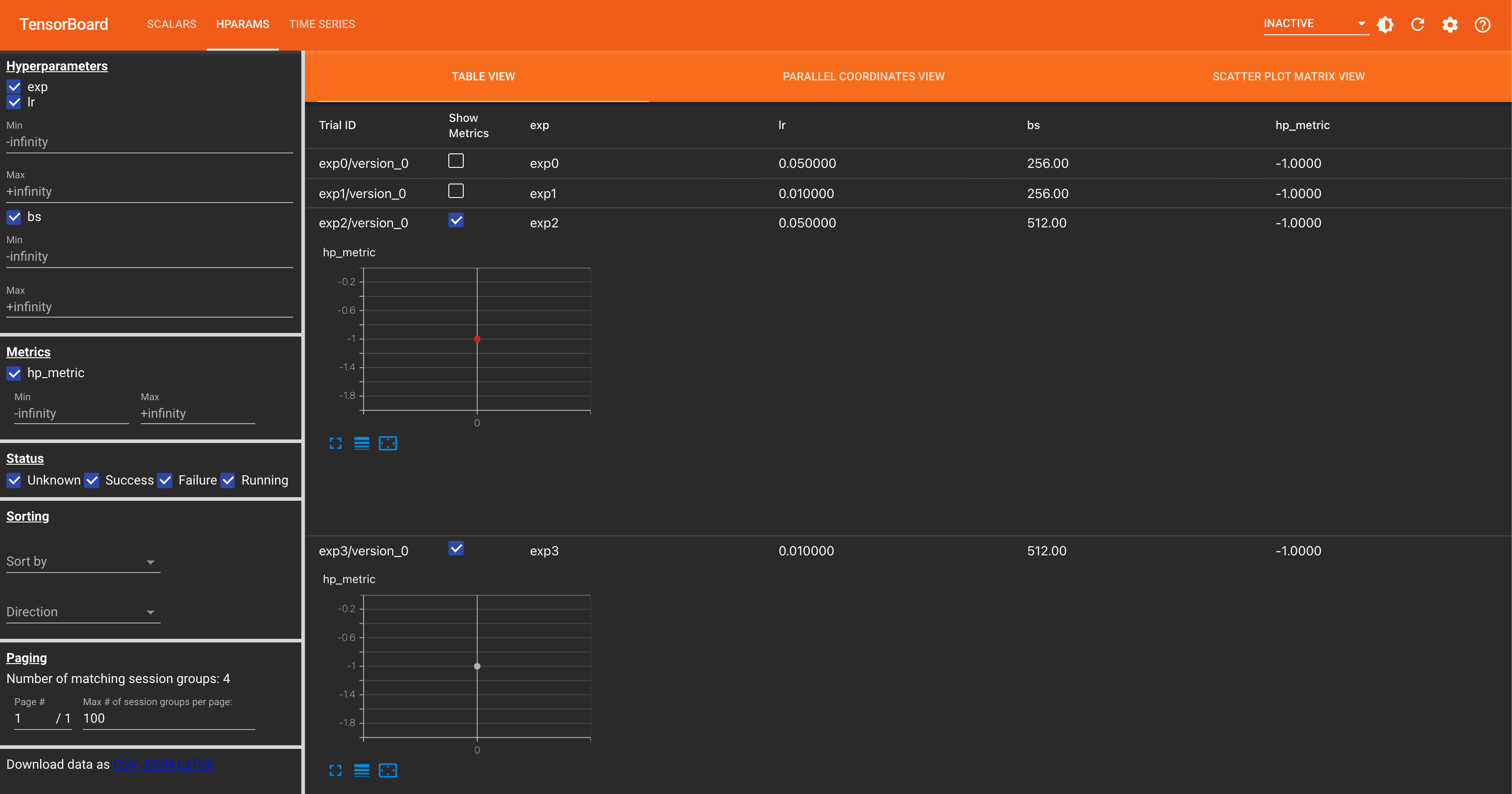
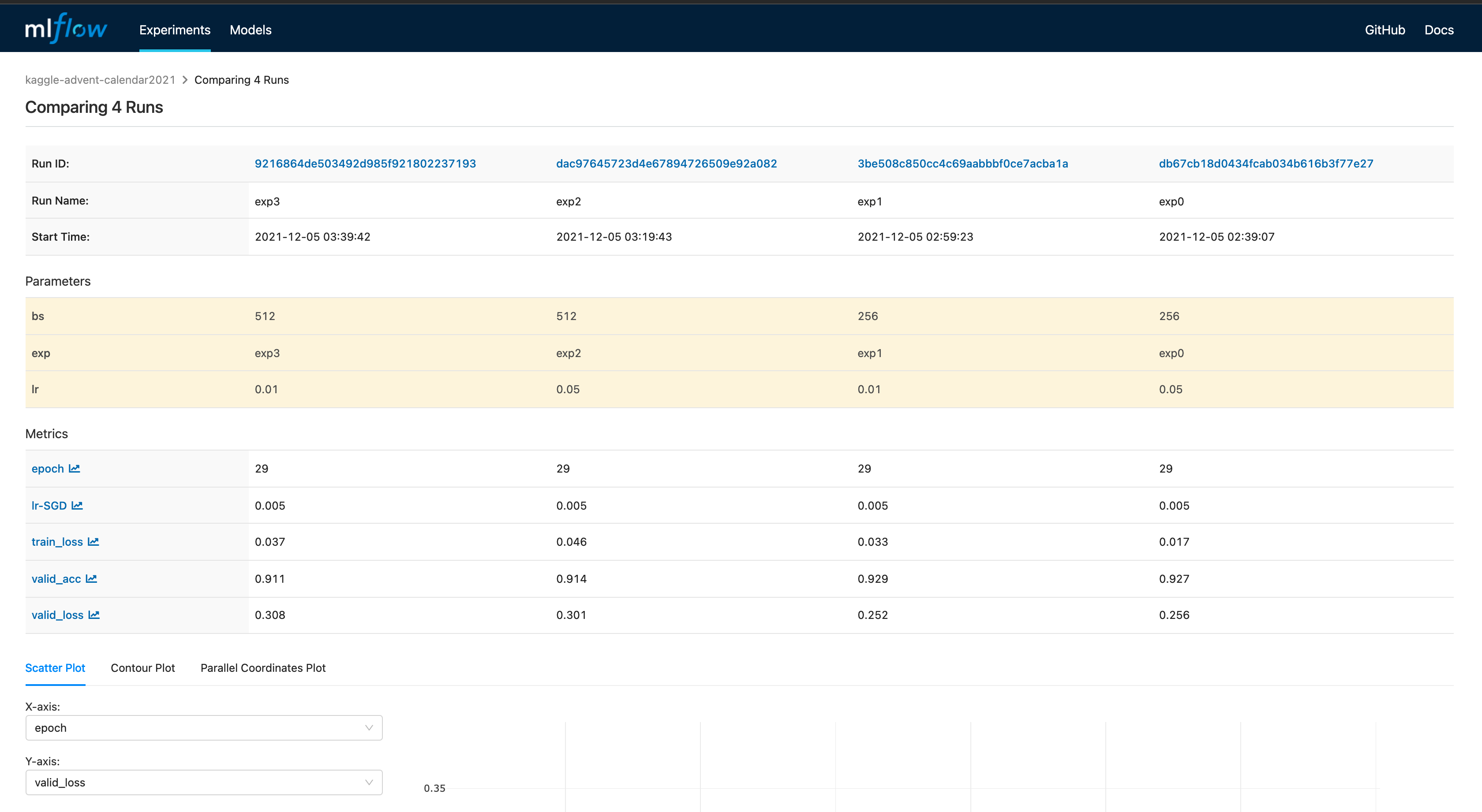
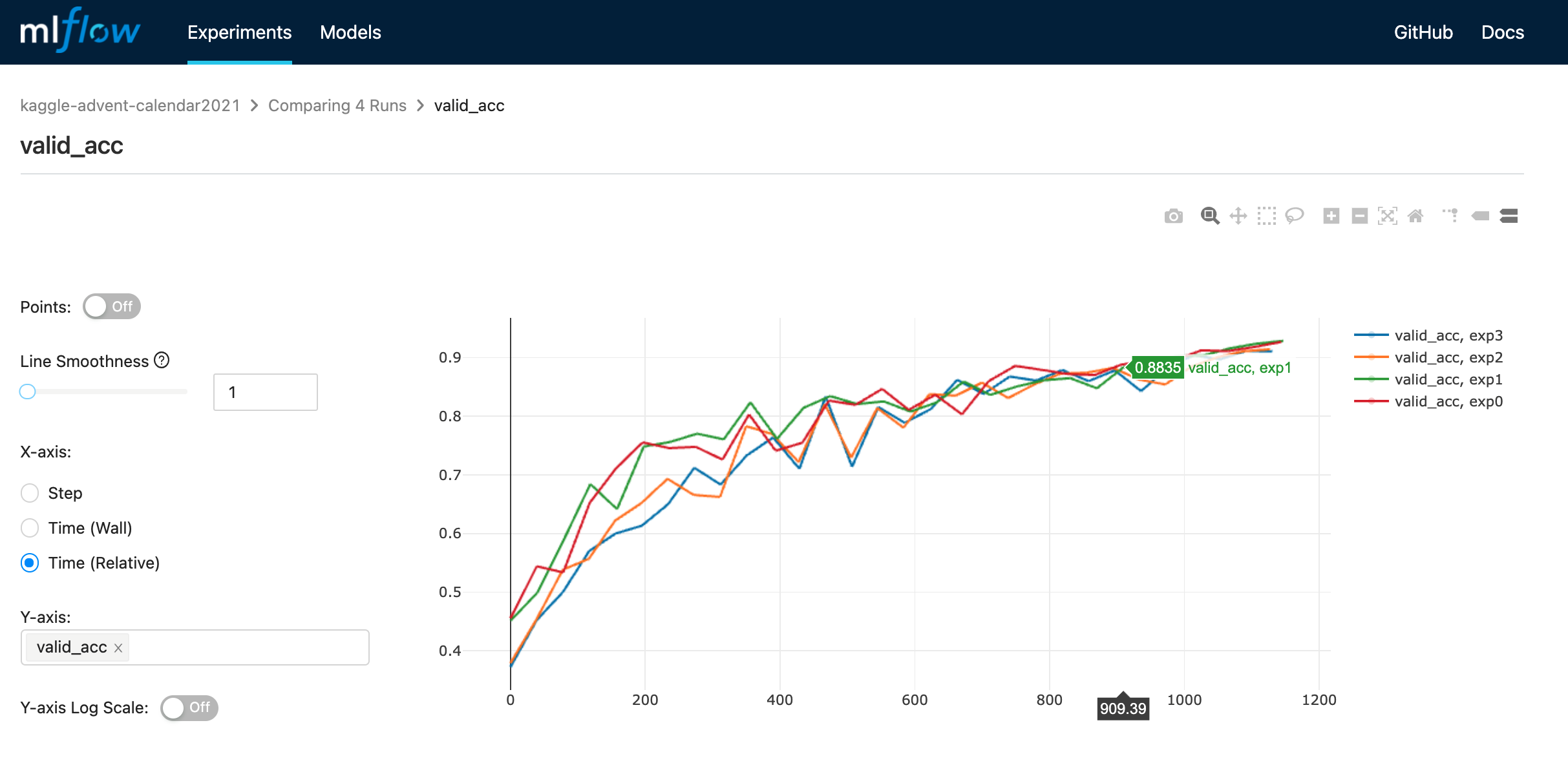
3.4.2 MLFlow
今回はローカルに置いたファイルを見れれば良いので、mlruns ディレクトリがある場所で下記コマンドを実行します。
$ mlflow server -h 0.0.0.0 -p 8857
- mlflow の場合は先に設定ハイパラ一覧が見れるようです
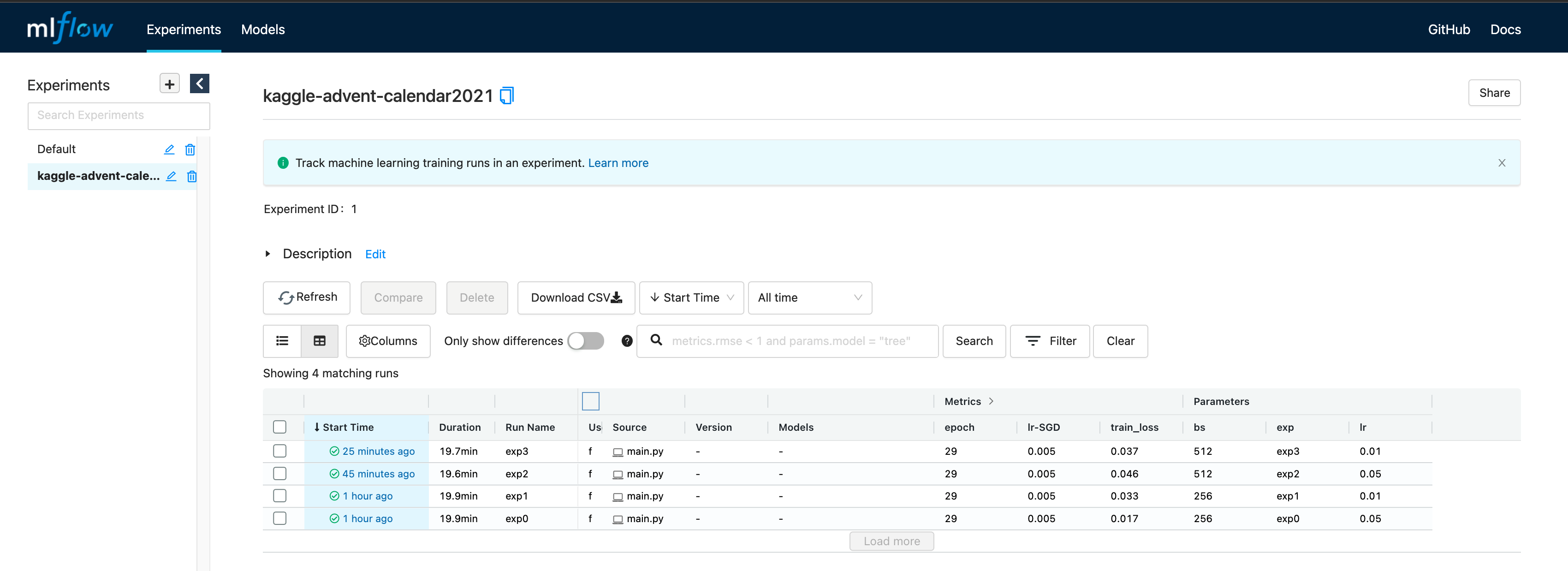
- この画面から比較したい実験を選択して同画面内の
Compareを押し、さらに見たい metrics を押すと比較した図が見れるようです- この画面下部では最終 epoch の結果しかプロットされませんでした…
- 複数 metrics を同時には見れなさそう?でした
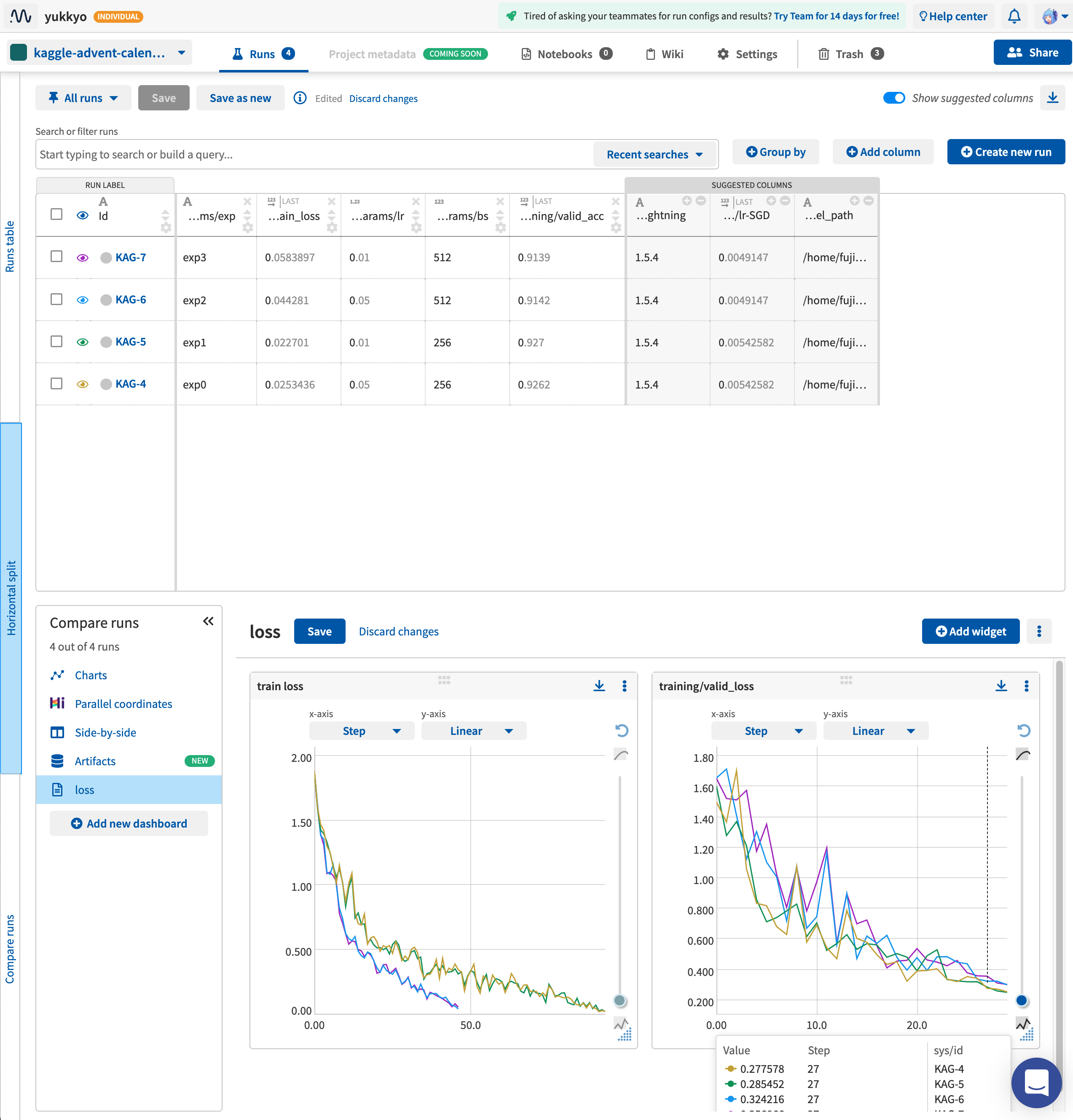
3.4.3 Neptune.ai
- Neptuneの場合自分で必要なチャートやカラムをどんどん足していく感じでした
- これらは検索で出せるのは地味に便利でした
-
SUGGESTED COLUMNSがあるのは SaaS っぽいなと思いました
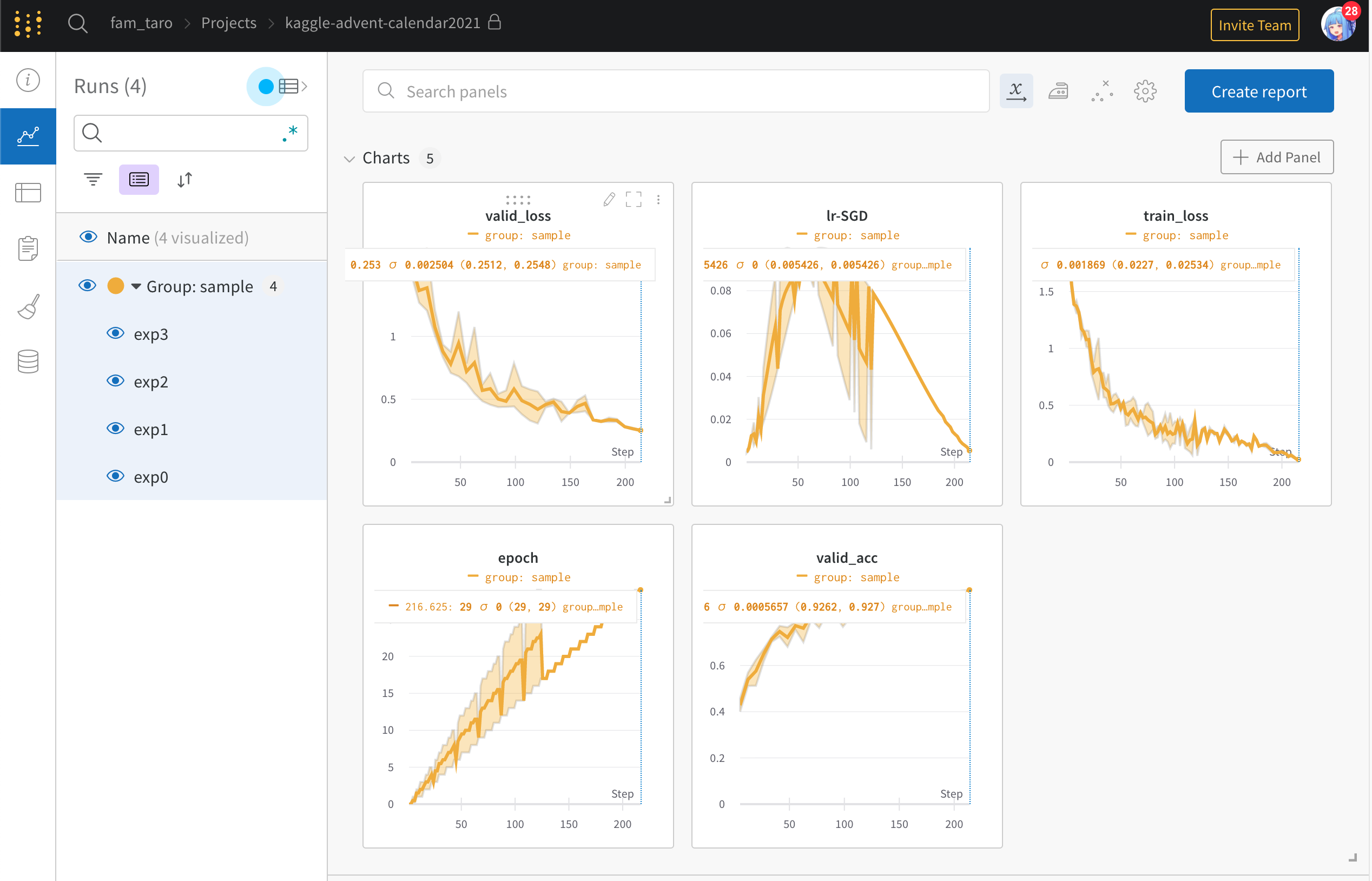
3.4.5 Weights & Biases(wandb)
- 今回wandbのgrouping機能も使ってみたところ、開くとまずはじめにgroup単位での結果を見ることができて地味に便利だなと思いました
- 特に複数foldで cross-validation したときに実験ごとの比較が楽になりそうでした
- 次にグループ内での結果は以下のように見比べることができました
- 地味にリソース(GPU等)のモニタリングもできているのは便利だなと思いました
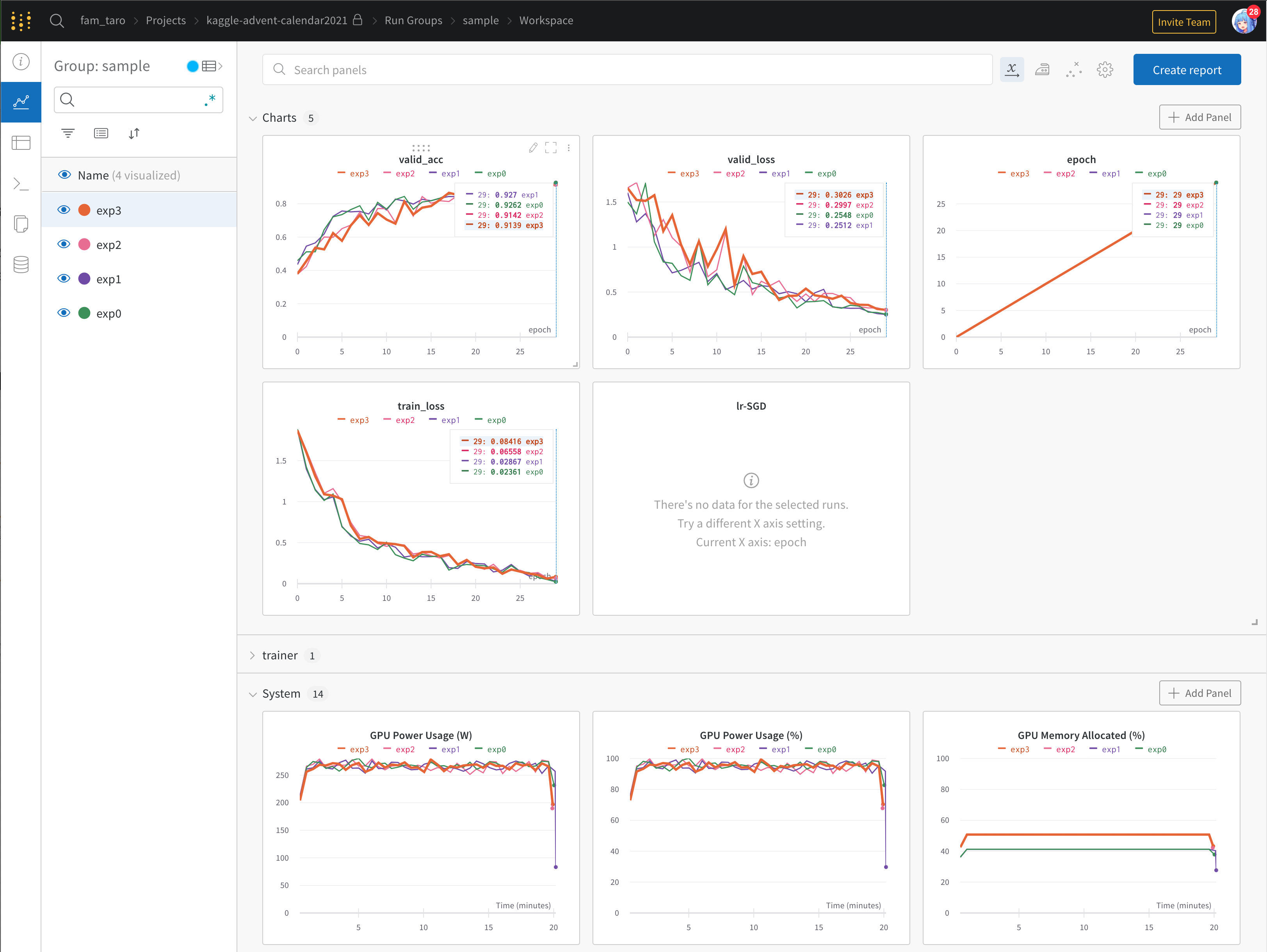
- 一方設定したハイパラと評価指標を見ようとした場合、別タブを開く必要があります
- かつ表示される
valid_acc等は last epoch の値のみ表示されるようです
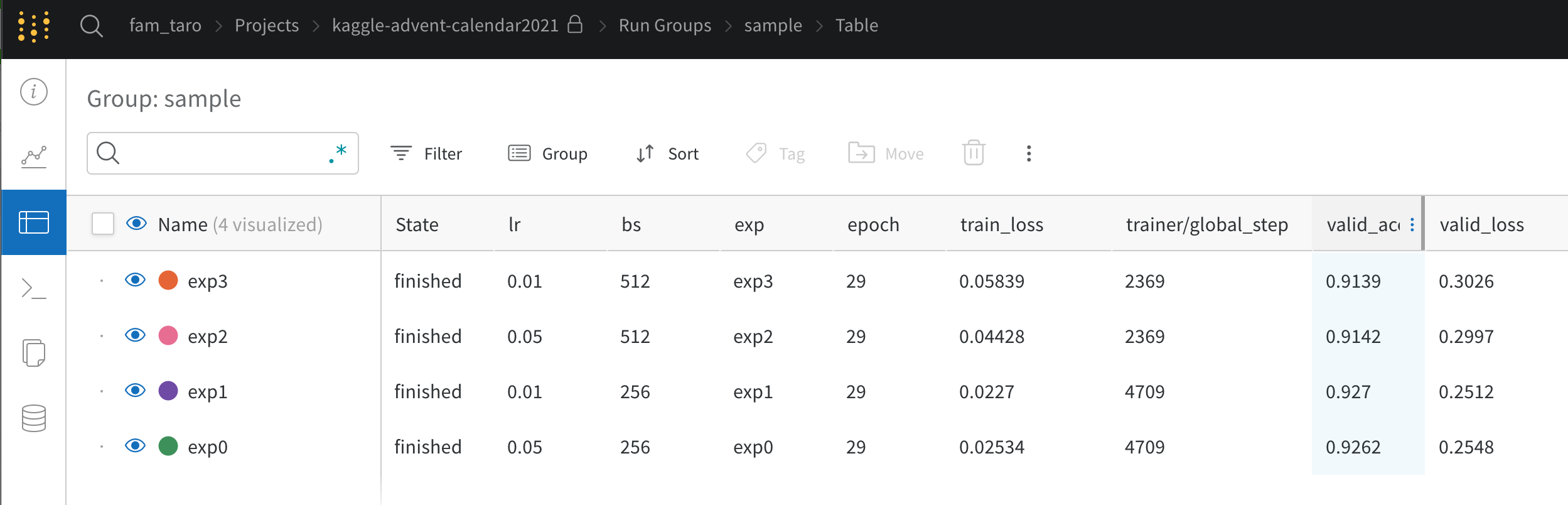
- その代わり右上あたりのボタンを押すと図とテーブルを同時に見れるようです
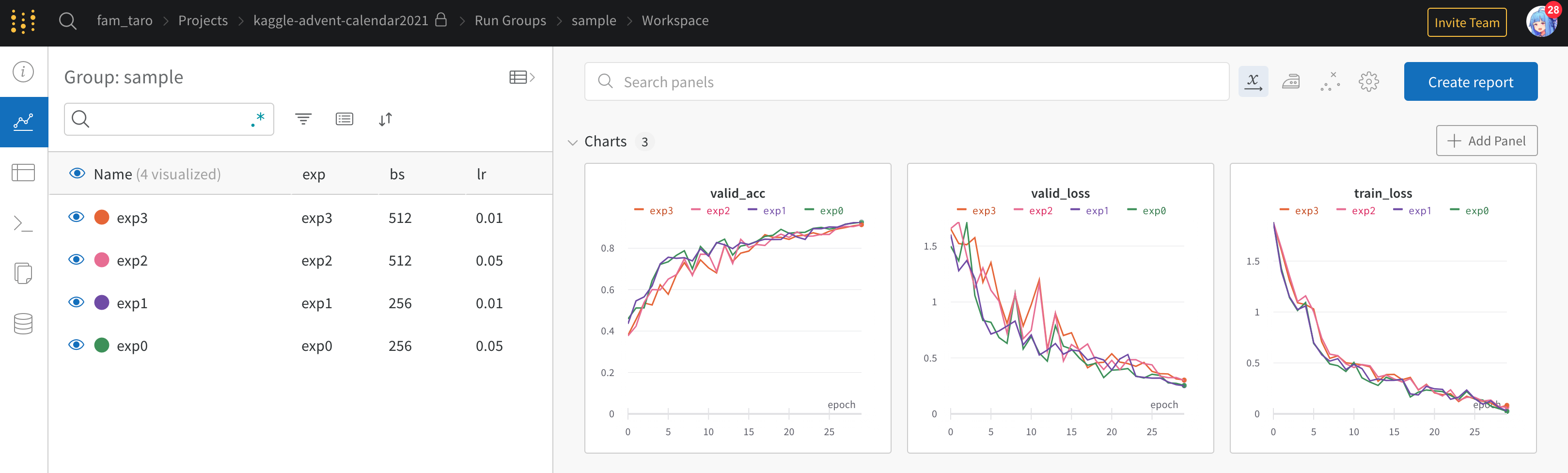
3.4.6 Comet
- Cometも大体 wandb と同じような画面を見ることができます
- カーソルを図のように合わせたときに1実験分のスコアしか見れないのは地味にストレスでしたが…
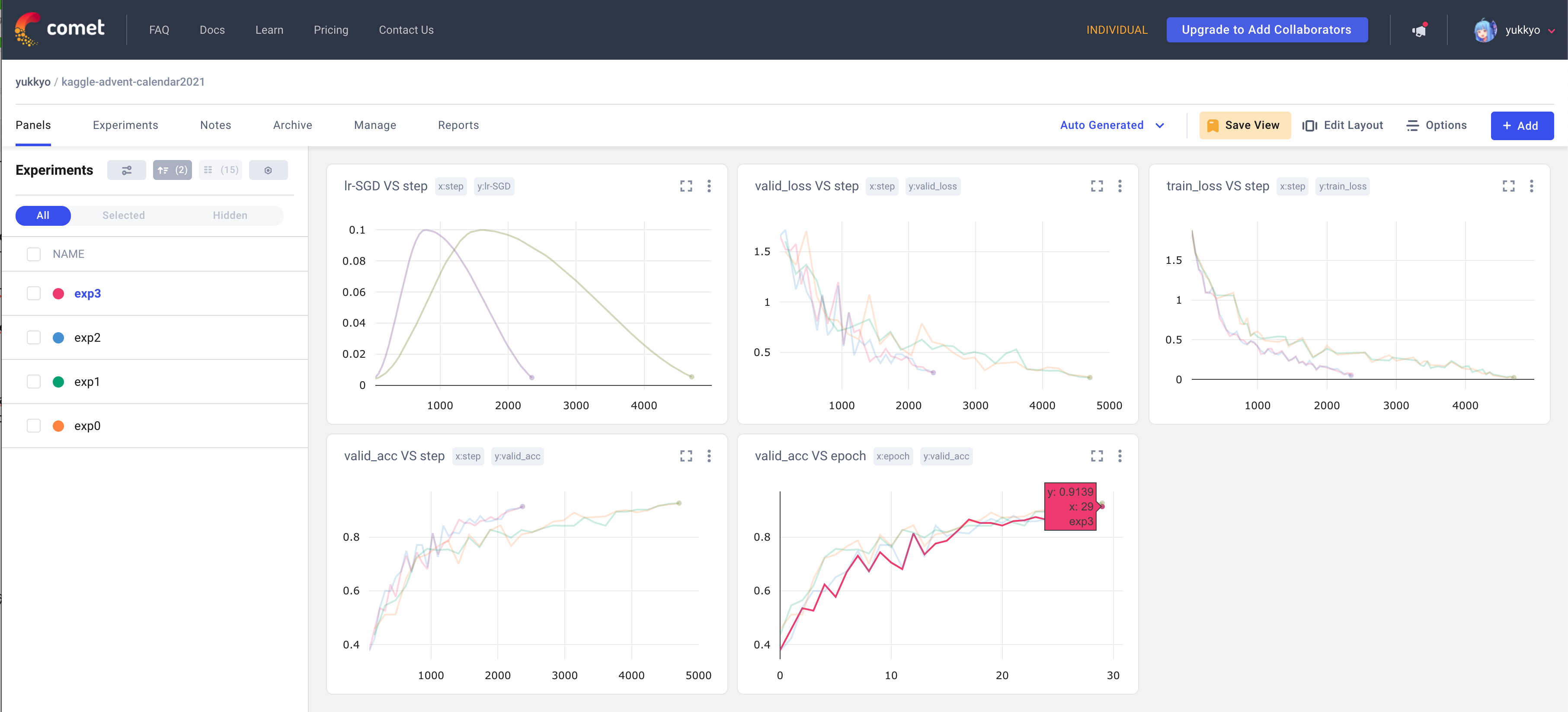
- また設定したハイパラも wandb と同様に別タブで見ることができます
- ただしこちらは wandb と違って図を同時に見ることはできなさそうです
- もし知ってる方いらしたら教えて下さい
- ただしこちらは wandb と違って図を同時に見ることはできなさそうです
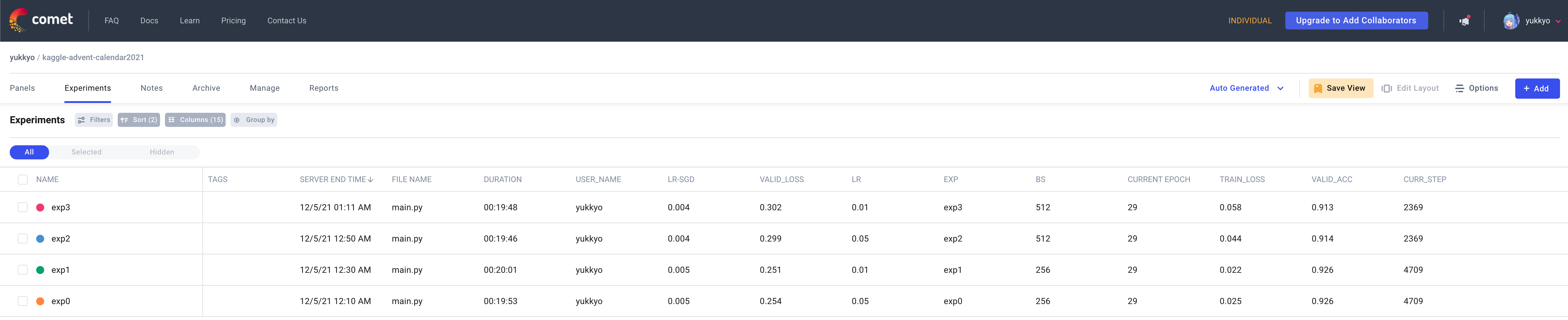
- その代わり表示するカラムについてはこちらのほうが僅かに整理しやすそうだなと思いました

3.5 Pricing
- 以下2つはFreeですので触れません
- TensorBoard
- MLFlow
- 以下3つについてなるべく一覧できるよう整理しました
| サービス (プラン) |
Pricing (month) |
対象 | 商用利用 | team members |
Storage | monitoring hours (month) |
その他 |
|---|---|---|---|---|---|---|---|
| Neptune.ai (Individual) |
Free | per user | 可 | 1 | 100GB | 200 | |
| Neptune.ai (Team) |
$49 | per team | 可 | Unlimited | 100GB | 200 | ・Email and chat support |
| Neptune.ai (Scale) |
$499 | per team | 可 | Unlimited | Custom | Custom | ・Service accounts for CI workflows ・Single Sign-on ・Onboarding support ・品質保証 |
| Wandb (Personal) |
Free | per user | 不可 | 1 | 100GB | Unlimited | |
| Wandb (Standard) |
$35 | per user ※1 |
可 | Unlimited | 100GB | 250 | ・Email and chat support |
| Wandb (Advanced) |
応相談 | teams ※3 |
可 | Unlimited | Custom | Unlimited | ・手厚いサポート ・専用サポートチャンネル ・Single sign on ・Service account for CI work flows |
| Comet (Community) |
Free | per user | 可 ※2 |
1 | 100GB | Unlimited | ・Hyperparameter Search ・Community Slack Support |
| Comet (Teams) |
$179 ※4 |
per user | 可 | 5 | 250GB | Unlimited | ・Hyperparameter Search ・Community Slack and Email Support |
| Comet (Teams Pro) |
$249 | per user | 可 | 5 | 500GB | Unlimited | ・Hyperparameter Search ・専用Slackチャンネル ・Model Management ・API Account |
| Comet (Enterprise) |
応相談 | teams ※3 |
可 | Unlimited | 1TB | Unlimited | ・Hyperparameter Search ・Flexible Deployment - On-premises, VPC or Cloud ・手厚いMLOpsサポート ・Phone, email and dedicated Slack channel |
- ※1: ただし所属は 1 Teamまで
- ※2: commercial use について言及されていないのでおそらく可
- ※3: いわゆる法人単位での契約
- ※4:
Comet Teams is available for free for Academics and Early stage startups.
色々書いてあるので個人的に気になるポイントをピックアップしました。
- 個人でのプライベート(業務外)利用の場合、どのサービスも無料で利用できる
- ただし Neptune.ai(Individual) の場合
monitoring hoursが 200 hours までであることに注意- コンペとかで無限に計算する人は注意しましょう
- ただし Neptune.ai(Individual) の場合
- 個人での業務(商用)利用の場合、Tensorboard、MLflow、Neptune.ai(Individual)なら無料で利用できる
- ただし上記と同様に monitoring hours に注意
- チーム単位で利用したい場合、商用に問わず SaaS(Neptune、Wandb、Comet)は有料になる
- Comet は研究目的の場合相談可
- Cometはチームメンバー数が最大5人であり、かつ料金の上がり方がすごいので注意
- この場合 MLFlow サーバーを自分たちで立てたほうが良さそう
- ストレージについてはSaaSのサービスに課金しても 100GB 程度なので、そもそも重たいもの(学習済み重みや画像等)はSaaS先に保存しない方針が良さそう
4. まとめ
- 個人でプライベート利用する場合
- wandb か Comet
- あまり計算回さない(< 200 hours)なら Neptune.ai もあり
- 個人で商用利用する場合
- 無料で使いたいなら Neptune.ai か Comet、MLFlow
- MLFlow はUI等の使い方や自分でサーバーを管理する手間が発生するが、気にならないならあり
- 機能としては Neptune.ai が整理されているが、monitoring hours に注意(200 hours)
- チームで利用する
- 無料で利用したいなら MLFlow
- 有料でも良いなら Neptune.ai か wandb
- monitoring hours が気にならないならチーム単位で Neptune.ai(Team)で良い
- 気になる場合、Neptune.ai(Scale)かWandb(Advanced)でそれぞれ相談したほうが良い
- 商用利用したいけど神様からクラウドを禁止されてる場合
- MLFlow
Must ではないですし今回比較してない項目もあるので自分で触ってみて好きなもの使ってください
5. その他:Kaggle Notebook でも実験管理したい場合
Kaggle Notebook で学習して結果をまとめたい場合、SaaSの Neptune、wandb、Cometあたりが良いと思います。
上記 Notebook 内のように kaggle_secrets を使うことで API key を公開せずに使うことができます。
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("api_key")
wandb.login(key=secret_value_0)
最後に
今回は めんどくさかったのもあって pytorch lightning に組み込まれているもののみで比較しましたが
他にもこんなツールやサービス良かったよってのがあれば教えて下さい!
追記:その他のサービス(ClearML)について(2021/12/05)
- 他のツールとしては ClearML もあるらしいです
- ローカルで立てて(self hosted)使っても良いし、クラウド(SaaS)としても使えるようです
- Choose the best MLOps plan for your team| ClearML Pricing
- 上記確認したところ少なくとも self hosted で使う場合は無料っぽいです
- パット見では「TensorBoard Log の出力とか weight の保存を自動でキャッチしてくれてよしなにしてくれる TensorBoardよりイケてるUI」
- ローカルで立てて(self hosted)使っても良いし、クラウド(SaaS)としても使えるようです