はじめに
最近痛風発症したファービー(@furbydayonn)です。
ロキソニンとレバミピドのお世話になる毎日です。
私が所属しているノベルワークスでは主にkintone、Garoon関連の拡張サービスをいくつか公開していますが、これらのドキュメントをDocusaurusに移行すべく、あれやこれやと試してきました。
今回は、Docusaurusで構築したドキュメントサイトをデータソースにして、巷でよく聞く(もはや時代遅れ感もありますが)RAGってやつを構築することで、RAG用にデータ整備することもなくチャットボット?AIアシスタント?的なものが作れるじゃん?と思い、試してみることにしました。
目指す構成
今回はまず手軽にRAGというものを体験したい為、ローカルからCLIで呼び出し動作確認するところまでをゴールにします。
ホスティングされているデータを参照しにいくのではなく、ローカルにあるmdファイルを直接参照させます。
実際に今回の構成で運用するとなった場合は、Github等のリモートリポジトリからクローンしてくるのがよいのかなと思います。
以下のような流れで、ドキュメントサイトをデータソースにして質問に回答させます。
Markdown → チャンク化 → 埋め込み生成 → 類似検索 → Claudeで生成回答
技術構成
| 項目 | 使用技術 |
|---|---|
| 言語 | TypeScript(Node.js) |
| 埋め込み生成 | Cohere Embed Multilingual v3(Amazon Bedrock経由) |
| LLM | Claude 3.5 Haiku(Amazon Bedrock経由) |
| ドキュメント形式 | Docusaurus(Markdown) |
| 類似検索 | 独自実装(by GPT-4o) |
| ストレージ | ローカルJSONファイル |
外部のベクトルDBを使わずにローカルに配置します。
Cohere, Claudeの呼び出しにはAmazon Bedrockを使用します。
ディレクトリ構成
docusaurus-project/
├── docs/ # Docusaurus用に作成したmd群
├── rag/
│ ├── ingest.ts # ベクトル生成(埋め込み処理)
│ └── query.ts # 類似検索&Claude応答
├── vectorstore.json # チャンクと埋め込みを保存。ingest.ts によって生成される
├── .env # AWS_PROFILE や AWS_REGION を記載
実装
コードはChatGPT(4o)によって生成されたものをほぼそのまま使っています。
ingest.ts(ドキュメントをベクトル化)
ドキュメントのテキストを分割し、Cohereでベクトル化します。
この処理はドキュメント更新時に都度実行することになります。
-
docs/フォルダ内のMarkdownファイルをすべて取得(fast-glob) -
remark-parse+strip-markdownでHTMLを除去しプレーンテキスト化 - 文単位で500文字程度にチャンク分割
- Bedrock経由でCohereモデルに渡してベクトルを生成
- 結果を
vectorstore.jsonに{ content, source, embedding }の形式で保存
実際に運用する場合にはドキュメントサイト(Docusaurus)のCI/CDに組み込むことで、ドキュメント更新時に自動でベクトルデータを更新することもできそうです。
ingest.ts
// by GPT-4o
import fs from 'fs';
import path from 'path';
import glob from 'fast-glob';
import dotenv from 'dotenv';
import { unified } from 'unified';
import remarkParse from 'remark-parse';
import remarkStringify from 'remark-stringify';
import strip from 'strip-markdown';
import {
BedrockRuntimeClient,
InvokeModelCommand
} from '@aws-sdk/client-bedrock-runtime';
import { fromIni } from '@aws-sdk/credential-provider-ini';
dotenv.config();
const bedrockClient = new BedrockRuntimeClient({
region: process.env.AWS_REGION,
credentials: fromIni({ profile: process.env.AWS_PROFILE || 'default' })
});
const docsPath = path.join(__dirname, '../docs');
const files = glob.sync(`${docsPath}/**/*.md`);
console.log(`Found ${files.length} markdown files.`);
// ユーティリティ: Markdown → プレーンテキスト
async function extractText(markdown: string): Promise<string> {
const file = await unified()
.use(remarkParse)
.use(strip)
.use(remarkStringify)
.process(markdown);
return String(file);
}
// テキストをチャンクに分割(シンプル版)
function chunkText(text: string, maxTokens = 500): string[] {
const sentences = text.split(/(?<=[。!?\n])/);
const chunks: string[] = [];
let chunk = '';
for (const sentence of sentences) {
if ((chunk + sentence).length > maxTokens) {
chunks.push(chunk);
chunk = sentence;
} else {
chunk += sentence;
}
}
if (chunk) chunks.push(chunk);
return chunks;
}
// 各チャンクにEmbeddingをつけて保存用オブジェクトに
async function embedChunks(chunks: string[], source: string) {
const embedded = [];
for (const chunk of chunks) {
const command = new InvokeModelCommand({
modelId: 'cohere.embed-multilingual-v3',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
texts: [chunk],
input_type: 'search_document'
})
});
const response = await bedrockClient.send(command);
const body = await response.body.transformToString();
const parsed = JSON.parse(body);
const embedding = parsed.embeddings[0];
embedded.push({
content: chunk,
source,
embedding,
});
}
return embedded;
}
(async () => {
const vectorData: any[] = [];
for (const filePath of files) {
const raw = fs.readFileSync(filePath, 'utf-8');
const text = await extractText(raw);
const chunks = chunkText(text);
const embeddedChunks = await embedChunks(chunks, filePath);
vectorData.push(...embeddedChunks);
}
fs.writeFileSync('vectorstore.json', JSON.stringify(vectorData, null, 2));
console.log('✅ Embeddings saved to vectorstore.json');
})();
query.ts(質問→検索→生成)
CLI経由で質問を受け取り、最も関連性の高いチャンクをClaudeに渡して回答を生成します。
- ユーザーから質問を受け取り(
readline-sync) - 質問文をCohereで埋め込みベクトル化
-
vectorstore.json内の各チャンクとcos類似度を計算し、Top-3を抽出 - 選ばれたチャンクと質問を組み合わせてClaude用プロンプトを作成
- Claudeにリクエストを送信し、ストリーム形式で回答を受信&表示
query.ts
// by GPT-4o
import fs from 'fs';
import dotenv from 'dotenv';
import readline from 'readline-sync';
import {
BedrockRuntimeClient,
InvokeModelCommand
} from '@aws-sdk/client-bedrock-runtime';
dotenv.config();
// Load vector store
const vectorData = JSON.parse(fs.readFileSync('vectorstore.json', 'utf-8'));
// Cosine similarity
function cosineSimilarity(a: number[], b: number[]): number {
const dot = a.reduce((sum, val, i) => sum + val * b[i], 0);
const magA = Math.sqrt(a.reduce((sum, val) => sum + val * val, 0));
const magB = Math.sqrt(b.reduce((sum, val) => sum + val * val, 0));
return dot / (magA * magB);
}
// Top-k similarity search
function topKSimilarChunks(queryVec: number[], k: number = 3) {
const scored = vectorData.map((item: any) => ({
...item,
score: cosineSimilarity(queryVec, item.embedding)
}));
return scored.sort((a, b) => b.score - a.score).slice(0, k);
}
// Prompt user
const question = readline.question('質問を入力してください: ');
(async () => {
// Embed the query using Cohere Embed via Bedrock
const bedrockClient = new BedrockRuntimeClient({ region: process.env.AWS_REGION });
const embedCommand = new InvokeModelCommand({
modelId: 'cohere.embed-multilingual-v3',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
texts: [question],
input_type: 'search_query'
})
});
const embedResponse = await bedrockClient.send(embedCommand);
const embedBody = await embedResponse.body.transformToString();
const embedParsed = JSON.parse(embedBody);
const queryVec = embedParsed.embeddings[0];
// Find relevant chunks
const topChunks = topKSimilarChunks(queryVec, 3);
const context = topChunks.map(c => c.content).join('\n---\n');
// Create prompt for Claude
const prompt = `
Human: You are a helpful assistant. Use the context below to answer the user's question.
Context:
${context}
Question: ${question}
Assistant:
`;
// Call Claude via Bedrock
const command = new InvokeModelCommand({
modelId: 'us.anthropic.claude-3-5-haiku-20241022-v1:0',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
anthropic_version: 'bedrock-2023-05-31',
max_tokens: 1024,
temperature: 0.3,
messages: [
{
role: 'user',
content: `You are a helpful assistant. Use the context below to answer the user's question.
Context:
${context}
Question: ${question}`
}
]
})
});
const res = await bedrockClient.send(command);
const raw = await res.body.transformToString();
const parsed = JSON.parse(raw);
console.log('\n---\nClaudeの回答');
parsed.content.forEach((c: any) => {
console.log("------------------------------------");
console.log(c.text);
console.log("------------------------------------");
});
})();
動かしてみる
ベクトルデータ生成
まずはingest.tsを実行してベクトルデータを生成します。
今回対象となるmdファイルは134個、ファイルの総サイズは0.3MBほどです。
npx tsx rag/ingest.ts
約1分半ほどでvectorstore.jsonが生成されました。
ファイルサイズは約6MBでした。
問いかける
次にquery.tsを実行して質問に回答させます。
npx tsx rag/query.ts
ノベルワークスで提供しているChobiit for kintoneという製品について聞いてみます。

chobiitはサイボウズ社が提供しているkintoneのデータをAPIで取得して、kintoneアカウントを持ってない人にも公開できるサービスです。
kintoneにはIPアドレス制限をかけることができ、制限かかっててもchobiitは使えるの?という質問です。
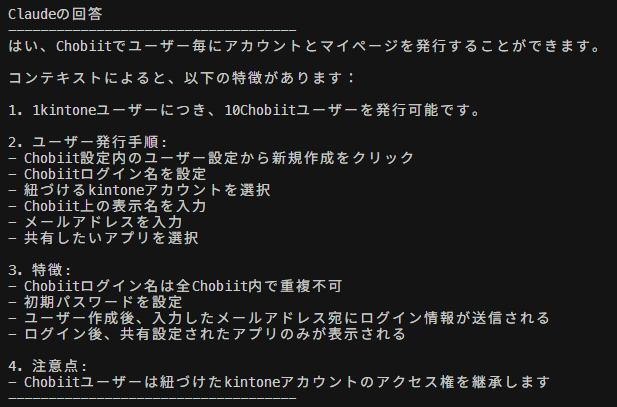
8秒ほどで回答が返ってきました。
若干不自然な部分はありますが、間違ったことは言ってないですね。
「コンテキストによると」という言い回しも気になりますが、この辺りはプロンプト次第でなんとかなるんでしょうか。
まったく同じことをもう一回聞いてみます。

微妙に言い回しが違うだけで、ほぼ同じ内容ですね。
3. 特徴の箇条書きの最後と、4. 注意点の内容が入れ替わってます。
確かにこの文言だけを見れば、注意点なのか特徴なのか微妙なところ。。
使ってみて
今回はお手軽RAG体験が目的だったので精度はそこまで高く感じませんでしたが、
Docusaurusをデータソースとしてあれこれできそうということが体感できました。
RAGの精度をあげるためにもよりよいドキュメント作りが必要になってくるので、良い循環が生まれそうです。
(AIにとって良いドキュメントが、人間にとっても良いドキュメントなのかはわかりませんが🤔)
今後は、UIとの統合やベクトルDBの利用なども検討していきたいと思います。