「実装編」をやっとですがまとめましたw
本連載はEMR開発の実装に特化した内容となっております。
Hadoopの一般的な内容やEMRの基本的なところは以下をご参照下さい。
現状のEMR処理の実装について
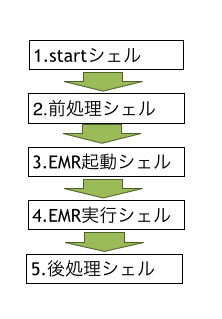
1.startシェル
通常実行、基本的なメンテナンス時のコマンドを受け付けるインターフェースです。
具体的には、バッチ処理全体を制御します。
主に処理対象をマスタDBから取得し、後続の2.を制御します。
2.前処理シェル
最小の処理単位毎にEMR処理を制御するシェルです。
具体的には、1.から渡される処理単位ごとのEMR処理を制御します。
マスタDBから必要なデータを取得、更新し、EMR処理の準備します。
準備が完了すると後続の3.に渡します。
3.EMR起動シェル
EMRの起動を制御します。
具体的には、設定された起動オプションでJobFlowを起動します。
また、無駄にEMRが起動されないよう制御します。
ほとんどの処理で共通化されてます。
4.EMR実行シェル
EMRの実行を制御します。
具体的には、3.で起動されたEMRクラスタに対してJobをadd。
処理状況を監視(polling)。正常終了、異常終了を判別し適切に処理します。
5.後処理シェル
EMRのoutputデータに対して後処理を施して仕上げます。
具体的には、outputデータをDB投入、excel化、文字コード変換等になります。
簡単な処理の場合は4.に入れてしまう場合も多いです。
実装のポイントについて
不具合を想定する。
リカバリやメンテ実行は コマンド一発全自動 できるようにしておく。
大規模データを取り扱うため、リカバリやメンテ実行の際にファイル移動や
DBオペレーション等をしていると面倒だしミスの温床になるので、
自動化しておきましょう。
無駄にEMRが起動されないように。
EMRは1度起動してしまうと1時間分の課金が発生するので注意が必要です。
EMRで完結しない処理を前処理、後処理という形で切り分けておくと、
前処理、後処理で失敗した場合にその部分だけやり直す運用ができるので効率的です。
値チェックを入れる。
Hadoop処理では少々のエラーは突き抜けてしまいます。(ほとんど起きないですが)
集計の用途で別ロジックでの集計(hourly、daily)と比較できる値は処理完了時に
整合性チェックしておくと安心です。
設計はシンプルに、モジュールはコンパクトに
とにかくシンプルに作る
要件を実現するために必要な機能を洗い出し、
できる限りシンプルで疎結合な処理へ分けて実装することが重要です。
上図で示したように、前処理、EMR起動、EMR実行、後処理
と処理毎にモジュールを切り分け、各段階が独立で動かせるようにしてあります。
このようにしておくと、日々変わって行くビジネス要件に柔軟に対応することが出来ます。
より高速な処理のために
inputのファイルサイズを 適切 に設定する。
EMR(Hadoop)は大規模データの並列処理です。
この並列処理がどれだけ有効に機能する(処理速度の高速化)かどうかは、
inputのファイルサイズ、数に大きく左右されると実感しています。
これは、input1ファイルに対して、最低でも1Mapタスクが起動するためです。
以下で、主にinputファイルを調整することで処理を高速化させる方法をまとめました。
- Hadoopの処理効率は、 多数の小容量inputファイル < 少数の大容量inputファイルと言われています。
適切なinputファイルのファイルの容量は一般的に、
HDFSのブロックサイズにより64MB〜128MBとされています が、
これはEMR(Hadoop=ミドルウェア)視点からの適切なファイルサイズであり
肝心のアプリケーションによっては不適切な設定となる場合があります。
- 適切なinput データはどう決めるか
具体的に、inputデータ1行に対しての処理が重いものを、
大量ノードを使って短時間にoutputさせたい処理の場合。
思い切ってファイルサイズを小さくするとうまく行きます。試しにinputデータサイズを128MB->3MBにしたところ、
全く同じcluster構成で 5倍 の早さになったことがありました。
大量ノードで処理する場合はMapタスクを早く回転させる(Mapタスクを増やす)方が早いです。inputファイルサイズの目安を1Mapタスクの処理時間が長くても
10分以内となるようにinputファイルサイズを調整しています。
inputファイルサイズを調整する方法。
より効率的な処理のために アプリケーションに適切なinputファイルサイズ を
調整するには以下の方法があります。
-
S3DistCpでinputファイルサイズを調整
EMR起動時にinputファイルをまとめられる場合はS3DistCpが有用です。
EMRアプリケーションとして起動するため台数効果が効き、相性抜群のツールです。
http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/UsingEMR_s3distcp.html -
CombineFileInputFormatで読み込みファイルの調整
多段MapReduceを使っているためにS3DistCpが使えない場合に有用です。
各MR処理のMapタスク起動直前にファイルをまとめられます。 -
mapred.job.reuse.jvm.num.tasksでタスク効率の調整
Hadoopの設定でお手軽にタスク効率を上げられる設定値です。
JVMの使い回し頻度を設定する値でEMRではデフォルト20に設定されています。
具体的には、inputファイルが小容量に断片化されてしまうのを避けるのが難しいような場合に
「-1」=JVM無限に使い回すに設定するとJVM起動オーバーヘッドが回避できるため高速化します。
http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/TaskConfiguration_H1.0.3.html#TaskJVMSettings_AMI2.3
EMR開発時に参考になる情報(リンク集)
EMRマニュアル
EMR設定関連
AWS全般
-
トレーニング集
-
アーキテクチャ集
S3マニュアル
以上です。
次回「運用編」もよろしくお願いします!
大規模データについてのリンク
「大規模データについていろいろやってみます!(第1回)」
「大規模データについて第2回~EMR(Hadoop)について、なぜEMRなのか〜」
「大規模データについて第3回~EMR開発_基礎編〜」
「大規模データについて第4回~EMR開発_実践編〜」
「大規模データについて第5回~EMR開発_運用編〜」
「大規模データについて第6回~Redshift編〜」