はじめに
「画像でゴミ分類!」アプリ作成日誌2日目の今日はいよいよモデルを作成していきたいと思います。モデルはVGG16を利用してFine-tuningしたいと思います。それでは早速やっていきましょう。
<記事一覧>
- 「画像でゴミ分類!」アプリ作成日誌day1~データセットの作成~
- 「画像でゴミ分類!」アプリ作成日誌day2~VGG16でFine-tuning~ ←イマココ
- 「画像でゴミ分類!」アプリ作成日誌day3~Djangoでwebアプリ化~
- 「画像でゴミ分類!」アプリ作成日誌day4~Bootstrapでフロントエンドを整える~
- 「画像でゴミ分類!」アプリ作成日誌day5~Bootstrapでフロントエンドを整える2~
- 「画像でゴミ分類!」アプリ作成日誌day6~ディレクトリ構成の修正~
- 「画像でゴミ分類!」アプリ作成日誌day7~サイドバーのスライドメニュー化~
- 「画像でゴミ分類!」アプリ作成日誌day8~herokuデプロイ~
前回までのあらすじ
前回はデータセットの作成ということで様々な写真を撮ってデータセットを作成しました。フォルダ構成は以下のようになっています。
train
├可燃ごみ
│ └画像たち(以下同様)
├資源品
├不燃ごみ
├包装容器プラスチック類
└有害ごみ
val
├可燃ごみ
│ └画像たち(以下同様)
├資源品
├不燃ごみ
├包装容器プラスチック類
└有害ごみ
これをもとにしてモデルを作成していきます。
ライブラリのインポート
必要なライブラリを読み込んでいきます。
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
from glob import glob
また、パラメーターも設定しておきましょう。まずは分類するクラスを指定していきます。それぞれ個々に指定してもよいのですが、誤字るとめんどくさいことになるので、一括で取得するようにします。
# 分類するクラス
classes = glob("train/*")
classes = [c.split("\\", 1)[-1] for c in classes]
nb_classes = len(classes)
trainフォルダと同じディレクトリに実行ファイルを置いておくと、classesは1行目で['train\\不燃ごみ', 'train\\包装容器プラスチック類',,,]のように取得されます。なので、splitで分割するのを内包表記で全要素にすれば['不燃ごみ', '包装容器プラスチック類',,,]のように必要な部分だけを取り出すことができます。(OSによってディレクトリの区切りが/か\\(\はエスケープシーケンスなので2個必要)かが違うのでwindows以外の方は得られたものを見て直してください。
次に画像関連のパラメーターを指定していきます。
# 画像の大きさを設定
img_width, img_height = 150, 150
# 画像フォルダの指定
train_dir = 'train'
val_dir = 'val'
# バッチサイズ
batch_size = 16
データを作成
今回はデータを水増ししたいということでImageDataGeneratorを使っていきます。これによってどのように水増しするかを指定できます。
# 水増し処理
train_datagen = ImageDataGenerator(
rotation_range=90, #±何度まで回転させるか
width_shift_range=0.1, #横方向にどれぐらいの割合まで移動させるか
height_shift_range=0.1, #縦方向にどれぐらいの割合まで移動させるか
rescale=1.0 / 255, #0~1に正規化
zoom_range=0.2, #どれぐらい拡大するか
horizontal_flip=True, #水平方向に反転させるか
vertical_flip=True #鉛直方向に反転させるか
)
val_datagen = ImageDataGenerator(rescale=1.0 / 255)
trainデータに関しては水増しの処理を行い、testデータに対してはスケール化の処理のみ行うことがポイントになります。パラメーターはコメントに書いているとおりですが、もっと詳しいパラメーターの話は以下を参考にして下さい。
上記の処理を実際の画像に適用させたいと思います。flow_from_directoryという関数を使うことでディレクトリから、いい感じにデータを作成してくれます。※この処理をするために、フォルダ構造は仕様に合わせてきちんと作っておく必要があります。
# ジェネレーターを生成
train_generator = train_datagen.flow_from_directory(
train_dir, # ディレクトリへのパス
target_size=(img_width, img_height), #リサイズ後の画像サイズ
color_mode='rgb', #画像のチャンネルの指定
classes=classes, #クラスのリスト(ここで指定するサブディレクトリに画像がある必要がある)
class_mode='categorical', #"categorical","binary","sparse"など
batch_size=batch_size,
shuffle=True)
val_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
モデルの構築
いよいよモデルを作っていきます。なお、構造やパラメーターを含めて以下の記事を参考にしています。
作る構造としては畳み込み層に関してはVGG16を利用し、全結合層は自分で設計します。また、重みについてはlayer15までは学習せず、最後の畳み込み層と全結合層を学習する感じにします。
# VGG16
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
まず、VGG16を読み込んでいきます。パラメーターは以下です。
- include_top:全結合層を含むかどうか
- weights:どの種類の重みを利用するか、現時点では
None(ランダム初期化)か'imagenet'のみ選択できるらしい
次に全結合層を定義します。
# 全結合層
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
top_model.summary()
全結合層は以下のようになります。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_3 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_6 (Dense) (None, 256) 2097408
_________________________________________________________________
dropout_3 (Dropout) (None, 256) 0
_________________________________________________________________
dense_7 (Dense) (None, 5) 1285
=================================================================
Total params: 2,098,693
Trainable params: 2,098,693
Non-trainable params: 0
これで目的のクラス数に分類する出口を作ることができたので、VGG16のほうと結合していきます。
vgg_model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 重みを固定
for layer in vgg_model.layers[:15]:
layer.trainable = False
vgg_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['acc'])
vgg_model.summary()
結合する書き方はFunctional APIの書き方そのままです。
最適化関数に関してはFine-tuningなので、学習率を低めに設定したSGDを用います。
モデルは以下のようになりました。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
sequential_3 (Sequential) (None, 5) 2098693
=================================================================
Total params: 16,813,381
Trainable params: 9,178,117
Non-trainable params: 7,635,264
それでは学習していきましょう。
history = vgg_model.fit(
train_generator, #訓練用のジェネレーター
steps_per_epoch=len(train_generator), #1エポック当たりのバッチ数
epochs=30,
validation_data=val_generator,
validation_steps=len(val_generator))
# acc, val_accのプロット
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("acc")
plt.close()
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("loss")
plt.close()
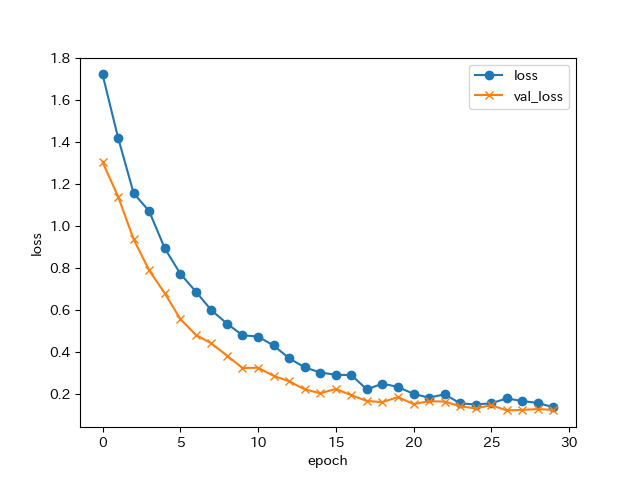
いい感じに学習できたかと思います。
最後にこのモデルを保存して読み込めるようにしてモデル作成は完了です。
# 保存
open("model.json", 'w').write(vgg_model.to_json())
vgg_model.save_weights('param.hdf5')
予測
次に上位のモデルを使って予測していきたいと思います。
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing import image
from keras.models import model_from_json
model = model_from_json(open("model.json").read())
model.load_weights('param.hdf5')
img_width, img_height = 150, 150
classes = ['不燃ごみ', '包装容器プラスチック類', '可燃ごみ', '有害ごみ', '資源品']
classesは、デプロイしたときのことを考えて名前で直接指定しています。
画像はジェネレーターにする必要がないので直接読み込みます。
filename = "val/資源品/IMG_20201108_105804.jpg"
img = image.load_img(filename, target_size=(img_height, img_width))
x = image.img_to_array(img)
x = x / 255.0 #正規化
x = np.expand_dims(x, axis=0)
# 画像の人物を予測
pred = model.predict(x)[0]
# 結果を表示する
result = {c:s for (c, s) in zip(classes, pred*100)}
result = sorted(result.items(), key=lambda x:x[1], reverse=True)
print(result)
結果はこのようになりました。
 |
 |
|---|---|
| '資源品', 99.783165 | '不燃ごみ', 99.97801 |
| '不燃ごみ', 0.1700096 | '資源品', 0.014258962 |
| '包装容器プラスチック類', 0.04342786 | '包装容器プラスチック類', 0.007412854 |
| '可燃ごみ', 0.00205229 | '可燃ごみ', 0.0002818475 |
| '有害ごみ', 0.0013515248 | '有害ごみ', 3.024669e-05 |
多種類のごみを用意できなかった関係上、訓練時のデータセットに似たようなものが含まれていた可能性は多分にありそうですが、きちんと区別できていそうです。
次回はこのモデルをDjangoに組み込んでいきたいと思います。お楽しみに!
<記事一覧>
- 「画像でゴミ分類!」アプリ作成日誌day1~データセットの作成~
- 「画像でゴミ分類!」アプリ作成日誌day2~VGG16でFine-tuning~ ←イマココ
- 「画像でゴミ分類!」アプリ作成日誌day3~Djangoでwebアプリ化~
- 「画像でゴミ分類!」アプリ作成日誌day4~Bootstrapでフロントエンドを整える~
- 「画像でゴミ分類!」アプリ作成日誌day5~Bootstrapでフロントエンドを整える2~
- 「画像でゴミ分類!」アプリ作成日誌day6~ディレクトリ構成の修正~
- 「画像でゴミ分類!」アプリ作成日誌day7~サイドバーのスライドメニュー化~
- 「画像でゴミ分類!」アプリ作成日誌day8~herokuデプロイ~