はじめに
前回の記事で、TensorFlow 2.xで可変長データを入出力に取るモデル (RNN) をCTC (Connectionist Temporal Classification) Lossを使って学習する方法を書きました。
[TensorFlow 2] RNNをCTC Lossを使って学習してみる - Qiita
しかし、一つ積み残していたものがありました。KerasでCTC Lossをうまく扱う方法です。
前回の記事で試してはみたものの、怪しげなハックだらけになった上に処理が遅いという、目も当てられない結果になってしまいました。
今回、その解決策が見つかったのでメモしておきます。
ここに書いた方法は、CTC Lossのみならず、特殊な損失関数を定義して学習したい場合に応用できるのではないかと思います。
検証環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
損失関数の定義方法は compile() だけではない
前回の敗因は、つまるところKerasの Model.compile() で無理やりCTC Lossを定義しようとしてドツボにはまった、ということに尽きると思います。
しかし、実は Model.compile() 以外にも損失関数や評価尺度(正解率など)を追加する方法が存在していました。
Train and evaluate with Keras | TensorFlow Core
The overwhelming majority of losses and metrics can be computed from y_true and y_pred, where y_pred is an output of your model. But not all of them. For instance, a regularization loss may only require the activation of a layer (there are no targets in this case), and this activation may not be a model output.
In such cases, you can call self.add_loss(loss_value) from inside the call method of a custom layer. Here's a simple example that adds activity regularization (note that activity regularization is built-in in all Keras layers -- this layer is just for the sake of providing a concrete example):
(略)
You can do the same for logging metric values:
(略)
独自レイヤーを定義して add_loss() を使用すれば、(y_true, y_pred) のプロトタイプにこだわらずに損失関数を定義できるとのことです!
いやはや、ちゃんとチュートリアルは読まないとダメですね…orz
損失関数を定義する add_loss() と、評価尺度を定義する add_metric() のAPIの説明は、以下のページに書いてあります。
tf.keras.layers.Layer | TensorFlow Core v2.1.0
チュートリアルのサンプルコードからも分かるように、**損失関数や評価尺度は Tensor であり、これらを Tensor の演算で組み立てます。**サンプルコードに含まれている x1 は、レイヤーからの出力を表す Tensor であり、損失関数を表現するために使用することができます。
inputs = keras.Input(shape=(784,), name='digits')
x1 = layers.Dense(64, activation='relu', name='dense_1')(inputs)
x2 = layers.Dense(64, activation='relu', name='dense_2')(x1)
outputs = layers.Dense(10, name='predictions')(x2)
model = keras.Model(inputs=inputs, outputs=outputs)
model.add_loss(tf.reduce_sum(x1) * 0.1)
model.add_metric(keras.backend.std(x1),
name='std_of_activation',
aggregation='mean')
今回の場合、特徴量系列・ラベル系列の長さ情報、さらにはラベル系列そのものも、CTC Loss計算に必要な情報ですから、Tensor として持っていなければなりません。つまり、これらもモデルへの入力として(yではなく、xとして)与える必要があるわけですね。つまり、複数の入力を持つモデルを作ることになります。
うまく動いたサンプルコード
大元のソースコードは
GitHub - igormq/ctc_tensorflow_example: CTC + Tensorflow Example for ASR
です。
# Compatibility imports
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import time
import tensorflow as tf
import scipy.io.wavfile as wav
import numpy as np
from six.moves import xrange as range
try:
from python_speech_features import mfcc
except ImportError:
print("Failed to import python_speech_features.\n Try pip install python_speech_features.")
raise ImportError
from utils import maybe_download as maybe_download
from utils import sparse_tuple_from as sparse_tuple_from
# Constants
SPACE_TOKEN = '<space>'
SPACE_INDEX = 0
FIRST_INDEX = ord('a') - 1 # 0 is reserved to space
FEAT_MASK_VALUE = 1e+10
# Some configs
num_features = 13
num_units = 50 # Number of units in the LSTM cell
# Accounting the 0th indice + space + blank label = 28 characters
num_classes = ord('z') - ord('a') + 1 + 1 + 1
# Hyper-parameters
num_epochs = 400
num_layers = 1
batch_size = 2
initial_learning_rate = 0.005
momentum = 0.9
# Loading the data
audio_filename = maybe_download('LDC93S1.wav', 93638)
target_filename = maybe_download('LDC93S1.txt', 62)
fs, audio = wav.read(audio_filename)
# create a dataset composed of data with variable lengths
inputs = mfcc(audio, samplerate=fs)
inputs = (inputs - np.mean(inputs))/np.std(inputs)
inputs_short = mfcc(audio[fs*8//10:fs*20//10], samplerate=fs)
inputs_short = (inputs_short - np.mean(inputs_short))/np.std(inputs_short)
# Transform in 3D array
train_inputs = tf.ragged.constant([inputs, inputs_short], dtype=np.float32)
train_seq_len = tf.cast(train_inputs.row_lengths(), tf.int32)
train_inputs = train_inputs.to_tensor(default_value=FEAT_MASK_VALUE)
# Reading targets
with open(target_filename, 'r') as f:
#Only the last line is necessary
line = f.readlines()[-1]
# Get only the words between [a-z] and replace period for none
original = ' '.join(line.strip().lower().split(' ')[2:]).replace('.', '')
targets = original.replace(' ', ' ')
targets = targets.split(' ')
# Adding blank label
targets = np.hstack([SPACE_TOKEN if x == '' else list(x) for x in targets])
# Transform char into index
targets = np.asarray([SPACE_INDEX if x == SPACE_TOKEN else ord(x) - FIRST_INDEX
for x in targets])
# Creating sparse representation to feed the placeholder
train_targets = tf.ragged.constant([targets, targets[13:32]], dtype=np.int32)
train_targets_len = tf.cast(train_targets.row_lengths(), tf.int32)
train_targets = train_targets.to_sparse()
# We don't have a validation dataset :(
val_inputs, val_targets, val_seq_len, val_targets_len = train_inputs, train_targets, \
train_seq_len, train_targets_len
# THE MAIN CODE!
# add loss and metrics with a custom layer
class CTCLossLayer(tf.keras.layers.Layer):
def call(self, inputs):
labels = inputs[0]
logits = inputs[1]
label_len = inputs[2]
logit_len = inputs[3]
logits_trans = tf.transpose(logits, (1, 0, 2))
label_len = tf.reshape(label_len, (-1,))
logit_len = tf.reshape(logit_len, (-1,))
loss = tf.reduce_mean(tf.nn.ctc_loss(labels, logits_trans, label_len, logit_len, blank_index=-1))
# define loss here instead of compile()
self.add_loss(loss)
# decode
decoded, _ = tf.nn.ctc_greedy_decoder(logits_trans, logit_len)
# Inaccuracy: label error rate
ler = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32),
labels))
self.add_metric(ler, name="ler", aggregation="mean")
return logits # Pass-through layer.
# Defining the cell
# Can be:
# tf.nn.rnn_cell.RNNCell
# tf.nn.rnn_cell.GRUCell
cells = []
for _ in range(num_layers):
cell = tf.keras.layers.LSTMCell(num_units) # Or LSTMCell(num_units)
cells.append(cell)
stack = tf.keras.layers.StackedRNNCells(cells)
input_feature = tf.keras.layers.Input((None, num_features), name="input_feature")
input_label = tf.keras.layers.Input((None,), dtype=tf.int32, sparse=True, name="input_label")
input_feature_len = tf.keras.layers.Input((1,), dtype=tf.int32, name="input_feature_len")
input_label_len = tf.keras.layers.Input((1,), dtype=tf.int32, name="input_label_len")
layer_masking = tf.keras.layers.Masking(FEAT_MASK_VALUE)(input_feature)
layer_rnn = tf.keras.layers.RNN(stack, return_sequences=True)(layer_masking)
layer_output = tf.keras.layers.Dense(
num_classes,
kernel_initializer=tf.keras.initializers.TruncatedNormal(0.0, 0.1),
bias_initializer="zeros",
name="logit")(layer_rnn)
layer_loss = CTCLossLayer()([input_label, layer_output, input_label_len, input_feature_len])
# create models for training and prediction (sharing weights)
model_train = tf.keras.models.Model(
inputs=[input_feature, input_label, input_feature_len, input_label_len],
outputs=layer_loss)
model_predict = tf.keras.models.Model(inputs=input_feature, outputs=layer_output)
optimizer = tf.keras.optimizers.SGD(initial_learning_rate, momentum)
# adding no loss: we have already defined with a custom layer
model_train.compile(optimizer=optimizer)
# training: y is dummy!
model_train.fit(x=[train_inputs, train_targets, train_seq_len, train_targets_len], y=None,
validation_data=([val_inputs, val_targets, val_seq_len, val_targets_len], None),
epochs=num_epochs)
# Decoding
print('Original:')
print(original)
print(original[13:32])
print('Decoded:')
decoded, _ = tf.nn.ctc_greedy_decoder(tf.transpose(model_predict.predict(train_inputs), (1, 0, 2)), train_seq_len)
d = tf.sparse.to_dense(decoded[0], default_value=-1).numpy()
str_decoded = [''.join([chr(x + FIRST_INDEX) for x in np.asarray(row) if x != -1]) for row in d]
for s in str_decoded:
# Replacing blank label to none
s = s.replace(chr(ord('z') + 1), '')
# Replacing space label to space
s = s.replace(chr(ord('a') - 1), ' ')
print(s)
実行結果は以下のようになります。
Train on 2 samples, validate on 2 samples
Epoch 1/400
2/2 [==============================] - 2s 991ms/sample - loss: 546.3565 - ler: 1.0668 - val_loss: 464.2611 - val_ler: 0.8801
Epoch 2/400
2/2 [==============================] - 0s 136ms/sample - loss: 464.2611 - ler: 0.8801 - val_loss: 179.9780 - val_ler: 1.0000
(略)
Epoch 400/400
2/2 [==============================] - 0s 135ms/sample - loss: 1.6670 - ler: 0.0000e+00 - val_loss: 1.6565 - val_ler: 0.0000e+00
Original:
she had your dark suit in greasy wash water all year
dark suit in greasy
Decoded:
she had your dark suit in greasy wash water all year
dark suit in greasy
処理時間も誤り率の値も問題なさそうで、ようやくまともに動いたようです…!
(処理時間はサンプル数で割った値なので実際の時間は表示の値の2倍になりますが、2サンプルで300ms以下なら前回と同等といえるでしょう)
解説
Loss, Metricsの追加
最初にご説明したように、Layer.add_loss() を使うことによって、モデルに関係する Tensor を自由に使って損失関数を定義することができます。上のコードでは CTCLossLayer というレイヤーを定義して、call() の中ではTensorFlow 2.x版(前回記事参照)の学習ループとほぼ同様の処理を書いています。最後に、入力された logits をそのまま出力するようにしています。
ここで call() には、self を除いて4つの引数を持たせています。この4つの情報があれば、CTC Lossおよびデコードを行うことができます。モデル構築時には、以下のようにレイヤーへの入力も4つ必要となります。
layer_loss = CTCLossLayer()(input_label, layer_output, input_label_len, input_feature_len)
入力レイヤー
先ほどの引数で与えている情報は Tensor になっていなければいけません。layer_output は普通のKerasモデルと変わらないのですが、input_label, input_label_len, input_feature_len については、入力レイヤーを追加して対応しています。
input_feature = tf.keras.layers.Input((None, num_features), name="input_feature")
input_label = tf.keras.layers.Input((None,), dtype=tf.int32, sparse=True, name="input_label")
input_feature_len = tf.keras.layers.Input((1,), dtype=tf.int32, name="input_feature_len")
input_label_len = tf.keras.layers.Input((1,), dtype=tf.int32, name="input_label_len")
ご覧のように、適切な形状と dtype を指定して Input レイヤーを作っています。特徴量以外のレイヤーの dtype は int32 としておけばよいです。
tf.nn.ctc_loss の引数の指定を考えると、本当は input_feature_len と input_label_len の形状を () とでもしたいところなのですが、後段でエラーになってうまく動かせませんでした。そのため、形状は (1,) と書いておき、CTCLossLayer の中で reshape を行って使っています。
もう一つしれっと追加しているのが、input_label 作成時の sparse=True です。これを指定しておくと、input_label に対応する Tensor が SparseTensor になります。
tf.keras.Input | TensorFlow Core v2.1.0
この sparse=True は、デコード結果の誤り率の計算時に、正解ラベルを SparseTensor で渡さなければならないための処置です(CTC Lossの計算で使う tf.nn.ctc_loss も SparseTensor を受けることができます)。Model.fit() などで与えるデータも SparseTensor で作っておきます。
tf.nn.ctc_loss | TensorFlow Core v2.1.0
tf.edit_distance | TensorFlow Core v2.1.0
同様に RaggedTensor の入力を想定する場合には ragged=True というのもあるようです。
モデルの作り方
以下のように、学習用と予測(推論)用のモデルを別個に作成しています。
model_train = tf.keras.models.Model(
inputs=[input_feature, input_label, input_feature_len, input_label_len],
outputs=layer_loss)
model_predict = tf.keras.models.Model(inputs=input_feature, outputs=layer_output)
学習時には4つの入力が必要でしたが、予測(デコード)時にはLogits(つまり Dense の出力)だけがあればよいので、入力としては特徴量があれば十分です。そのため、予測用のモデルは入力が1つだけで動くようにしています。もちろんLossは計算できませんが、デコード用途だけなら不要ですので、出力としては CTCLossLayer を通す前の layer_output を指定しておきます。
図で描くと、つまりこういうことになります。
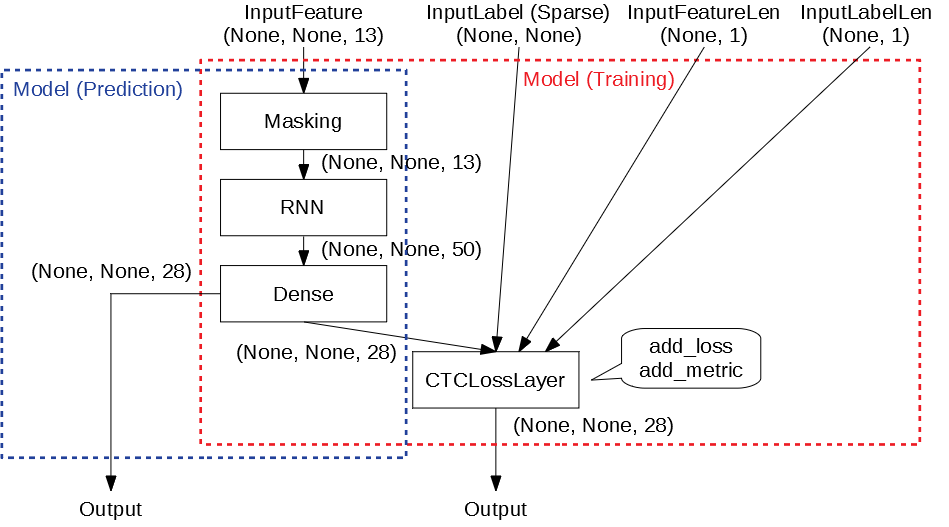
重みが入っているレイヤーは共有するように作成していますので、学習用モデルで学習を行った後、そのまま予測用モデルで推論することができます。
モデルのコンパイル
CTC Lossは独自レイヤーで定義してしまったので、compile() では損失関数を定義する必要がありません。その場合、loss 引数を単に指定しなければよいです。
model_train.compile(optimizer=optimizer)
学習の実行
損失関数の計算に使用するための正解ラベルや長さ情報は、入力レイヤーに流す情報ですから Model.fit() の引数の x 側に指定する必要があります。y には指定するものがなくなりましたので、None を書いておきます。
validation_data も同様に、タプルの2番目に None を書いておきます。
model_train.fit(x=[train_inputs, train_targets, train_seq_len, train_targets_len], y=None,
validation_data=([val_inputs, val_targets, val_seq_len, val_targets_len], None),
epochs=num_epochs)
正直これが公式が想定する使い方なのかどうか分かりませんが、compile() で loss を指定しない場合には y=None にしても問題なく動いています(loss を指定しているときは、損失関数の y_true 引数に渡すラベルが必要なので、当然 y に何かデータを与えないとエラーになります)。
デコード結果の出力
前述の通り、推論時には model_predict の方を使います。predict() の引数には特徴量系列のみを与えればOKです。
decoded, _ = tf.nn.ctc_greedy_decoder(tf.transpose(model_predict.predict(train_inputs), (1, 0, 2)), train_seq_len)
その他気になること
-
Maskingとinput_feature_lenは働きが似ているので、なんだか冗長な気がします…。
まとめ
ちゃんとチュートリアルを読めばKerasでもCTC Lossを使って学習を実行できました。意外とKerasも小回りが利くのですね。どうもすみませんでした。