目標
- AWSサービスを効率的に使って、自然言語処理に関するサービスを構築する。
- 可能な限りローコストを目指す(特にアクセスしていない時の料金を減らす)。
- もちろん高可用性構成。
- マルチテナント構成を取る
- BERTを使って類似文章検索を行う。
- 転置インデックスを使用した全文検索を行いたい(単語での検索など)。ElasticSearchは値段高いのでパス。
前提
今回は、構成の考察。検証済みの部分もあり、未検証部分もあり。
実際の製品がこの構成を取っている事を示すものでは無いです(まだ検証段階です)。
その為、この構成を取った事によって何か問題が発生するかもしれない事はご了承下さい。
技術要件整理
データ
学習済み基本モデル
最近流行りの転移学習向けに、公開されている学習済みデータを使用する。サイズ的には1~数GBを想定。
ファインチューニング用コーパスデータ
転移学習でのファインチューニングをする為の言語データ。具体的には検索対象の全文章。サイズはテナントによるが、大きくて100MB程度。
最終文章ベクトルモデル
ファインチューニング後の学習モデル。これを使用して類似語、類似文章検索を行う。学習した後にpickleでシリアライズしておき、使用時にデシリアライズする。サイズ的には大きくて1GB程度を想定。
処理
最終文章ベクトルモデル作成
処理要素
- 学習済み基本モデルの読み込み
- 最終学習モデルの生成
- 最終学習モデルオブジェクトのpickleシリアライズファイル作成
特性
- 処理時間が長い(量やマシンパワーによるが1時間レベル)
- 扱うファイルがGBオーダー
- 瞬時の反映は要らないが、毎週、毎日、任意のタイミングでの処理をしたい。
類似文章検索
処理要素
- pickleシリアライズファイル読み込み
- 類似文章検索
- スコアリング処理
- 返信データ作成処理
特性
- ユーザーが入力&返答を待つ処理なので遅くて数秒
- pickleシリアライズファイルのメモリ展開に耐えられるメモリが必要
全文検索
処理要素
- 形態素解析ライブラリが必要(大きいサイズの言語データが必要)
- 転置インデックス作成処理(文書の登録更新時)
- 転置インデックスを読み込む
- スコアリング
- 結果返信
特性
- 形態素解析処理が必要
- 低レイテンシーが必要
技術ポイント
AWS Lambda
サーバーレス構成での鉄板サービス。以下の制限がある。
参考:AWS Lambda のクォータ
- 長くて15分の処理
- 一時ファイルは500MBまで
- メモリは最大で3GB(こちらの記事によると、10GBに拡張されたらしい)
- アップするzipファイルは依存ライブラリも含めて50 MBまで。展開後はレイヤー含めて250 MBまで
AWS LambdaLayer
Lambdaを使用する際、単純にやるとライブラリもまとめてソースをzipしてアップする。
多くのLambdaで共通ソースを使う場合、それを最大5つの層に分けて管理する事が出来る。
拙記事 LambdaLayer用zipをCodeBuildでお手軽に作ってみる。 で検証していたりします。
AWS Lambda Container Support
Lambdaを使用する際、コンテナイメージを丸ごと指定できるというもの。
拙記事 LambdaでDockerコンテナイメージ使えるってマジですか?(Python3でやってみる) で検証していたりします。
AWS EFS
EC2での使用が基本だが、LambdaやECSでも使える。テナント毎の情報保持して、各サービスでの高速ファイルアクセスに使用。
Amazon EFS を Lambda に使用する
Lambdaでの一時ファイル上限は500MB。大きいファイルは扱えない。またS3からダウンロードしてくるなどの事が必要になってしまう問題があった。機械学習のような大きいファイルを良く扱う処理をLambdaでやるには必須。
Amazon Elastic Container Service が Amazon EFS ファイルシステムをサポート開始
冗長化をする上で、永続層の共有化は必須。これが使えるようになったの2020年4月と最近なのね。
EFSにセットアップしたPythonライブラリをLambdaにimportする方法
拙記事 Lambda+EFSで自然言語処理ライブラリ(GiNZA)使ってみる で検証していたりします。
AWS SageMaker
機械学習プラットフォーム。機械学習エンジニア御用達ツールのJupyterNotebookの様に使える。
Amazon SageMaker ホスティングサービス
SageMakerで作成したモデルなどを使用した機械学習APIサービスとして提供する事が可能。
AWS ECS
AWS構成で高可用性を求める時、コンテナ技術が使われる。AutoScalingなどを効率よく使用できるサービス。
AWS Fargate
AWS ECS をベース(?)として、コンテナを起動して処理している間のみ料金がかかるサービス。
ある程度の時間がかかるが、一定のタイミングのみ行うような処理に向いている。
AWS Batch
Fargeteと似ている感じだが、AWS Batch 資料及び QA 公開によると、以下の使い分けがあるらしい。説明ページのユースケース画像では、BigDataレベルの巨大な処理で使う事を想定しているらしい。今回は使わないと思うが、知識としては知っておいてよいかも。
AWS Batch では内部的に Amazon ECSを使用しつつ、キューイングされた計算処理を順次実行していくようなバッチコンピューティング環境に特化しております。そのため、このようなバッチ処理であれば AWS Batch をご利用いただき、それ以外のインタラクティブな処理を含む汎用的なワークロードではECS及びECSの機能の一部であるFargateをご利用いただければと思います。
Django
Python用フレームワーク(フロントにも使えるけど)。
EC2やコンテナ上で常駐型で展開するのが基本だと思うが、AWS LambdaでAPI開発するときのパターン集 によると、Lambdaにも組み込む事が可能らしい。
が、LambdaとDjangoの相性ってどうなの??によるとあまり推奨され無さそう。
形態素解析
転置インデックスをする上でほぼ必須。各種ライブラリがあるが、言語データ部分のサイズが大きい。
GiNZA
形態素解析を始めとして各種自然言語処理が出来るpythonライブラリ。spaCyの機能をラップしてる(はず)なのでその機能は使える。
形態素解析エンジンにSudachiを使用したりもしている。
BERT
最近流行っている言語処理技術。これをベースにして各種ライブラリや技術が派生している。
Sentense-BERT
BERTを基本(?)にした文章ベクトルライブラリ。日本語対応された方が後述記事でその紹介をしている。
【日本語モデル付き】2020年に自然言語処理をする人にお勧めしたい文ベクトルモデル
考察
まず、アプリケーション部分の構成を考察し、それからビルドやモニタリング構成を考える。
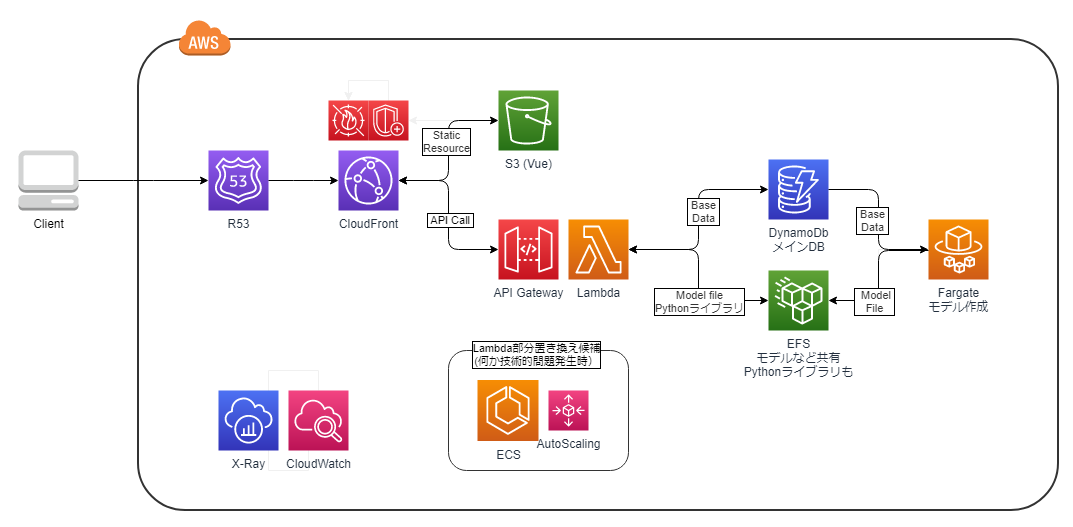
CDN
CloudFrontを使用する。そこからweb静的リソースやAPIコールのオリジンへアクセスを分ける
フロントサイド
サーバーサイドレンダリングなどもあるが、今の時点ではVue.jsをビルドしたものを静的webリソースとして使用する。
サーバーサイド(API)
選択肢としては以下の構成が考えられる。
- APIGateway+Lambda
- ECSでAutoScaling(Djangoでサービス化)
- 自然言語処理部分だけSageMakerホスティングサービス
この部分が今回の記事のメイン。ネットの情報である程度の判断は出来るが、実際に検証してみないとその技術が使えると判断できない。
使用したいと思うライブラリが普通のPythonライブラリに比べて容量が大きい事は解っていた(辞書データがある)。いくつかの技術検証の元、APIGateway+Lambdaを使用する方向。
LambdaLayer
拙記事LambdaLayer用zipをCodeBuildでお手軽に作ってみる。 で検証。記事ではnumpyを使っているが、本来使ってみたかったのは自然言語処理ライブラリのGiNZA。しかし、記事の手法でzip化してみたらLambdaクオータに引っかかる事が判明。もちろんアプリの共通ロジックには使える事は解った。しかし、LambdaをAPIとして使えるという判断にはならない。
Lambdaコンテナイメージ
拙記事LambdaでDockerコンテナイメージ使えるってマジですか?(Python3でやってみる) で検証。GiNZAの依存ライブラリ、Sudachiでsymlnkを使用している事から、コンテナ内とはいえLambdaで使えない事が判明。別の自然言語処理ライブラリを使うという選択肢もあれど、今後機能拡張の際にライブラリが縛られるのは避けたい。一度採用したライブラリが今後VerupなどでLambdaで使えないような事になったら大変なので採用は避けたい。
この時点までは、一旦Djangoでサービス起動できるコンテナを作成する方向で考えていた。
Lambda+EFS
拙記事Lambda+EFSで自然言語処理ライブラリ(GiNZA)使ってみる で検証。
元々EFSはモデルデータなどの共有で使用予定だった。しかし、EFSをLambdaで使う事で大きなライブラリも普通に使える事を確認。
この検証を根拠に、Lambda+APIGatewayで対応する方向を考える事にした。
サーバーサイド(バッチ処理)
主に自然言語処理のベクトル計算に使用する想定。ECSのFargeteで構成。
APIと共通部分は出てくると思うので、その共有化も課題。
共通ストレージ
テナント毎の文書ベクトルファイルはAPI処理で素早くアクセスする必要がある。また、永続化してAutoScalingなどの複数API処理コンテナから共有される必要がある。ここはEFSの出番。
図にまとめてみる
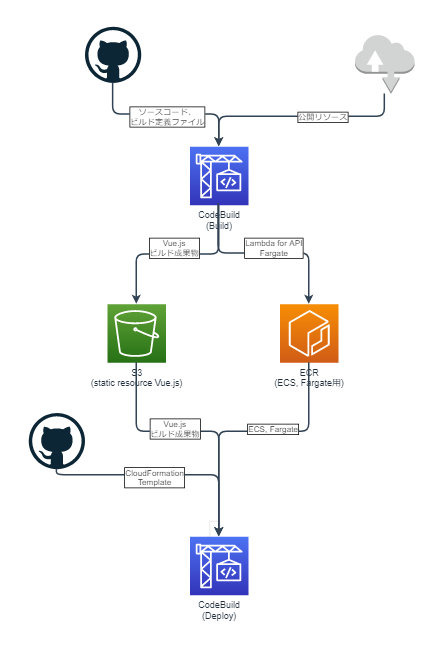
CI/CDフェーズ
ビルド
モジュールとしての生成物はweb用(Vue)の静的リソース、ECS、Fargate用のコンテナイメージとなる。(Lambda使う場合にはLambda用コンテナイメージ)。これらをCodeBuildで行う。
デプロイ
CodeBuildを使って、githubで管理しているCloudFormationを展開。その際に使うコンテナイメージやS3リソースをビルドフェーズで生成する。イメージ図書いてみた(一方通行のフロー図は縦書きにしたいのは何でだろう)。
今後課題や残検証まとめ
- 今後の構成変更可能性を踏まえ、LambdaでもDjangoでも流用可能(プラットフォーム切り替えが可能な)様なソース構成
- API部分とFargete部分で共通処理は単一ソース管理
- モニタリング構成の検証
- DBのマルチテナント構成の検証
- ECSでのEFSのマウントの検証
- SageMakerのホスティングサービスの使い方検証(特に値段)
まとめ
全体設計を何もしないまま部分から作り始めるのも、全体設計を最初から細かく時間をかけるのもリスクがあると感じた。
前者は、いざ各部分をつなげようとすると繋がらなかったりする問題。後者は実際に実装を進めて行くと、解消できない問題に出会うかもしれない問題。もちろんこれは既存の上手く行っているシステムがあればそのリスクを回避できるので前例は探しておいた方が良い。
今回の考察でも、一旦Lambdaを使うのを諦めたのだが、最近提供された機能によりサーバーレスが実現できる見込みが立った。しかし実装を進めていくと別の問題で諦めなくてはならなくなるかもしれない。モジュールなどの機能群やレイヤーで分け、それの入れ替えを容易に出来るようにしておくのが一番重要な気がする。
それらを踏まえてまとめると、AWSに限らないと思うが、システム構成を考える時には以下の点が重要と思う(当たり前と言えば当たり前だが)
- 扱うデータのサイズ、更新頻度、要求レイテンシーレベルを明確にしておく
- ラフな全体図を描いた上で、主要ポイントは単体で技術テストをする(出来るっぽい、と思った事でも出来ない場合対応)
- 無駄なやり直しを防ぐ意味でも、各技術(主にAWS)のユースケースや制限を出来る限り事前調査
- 検証や実際に運用してみての問題が出てきた時の為に各モジュールは疎結合を意識する
- そして実際に構成の実装を進めつつ、問題点の洗い出し及び改善(場合によってはその部分設計しなおし)
その他
アドベントカレンダー用という事で、公開日の1ヵ月前ぐらいから書き始めていたが、2020年12月15日に下記記事が投稿された。
自分が今回の考察で漠然と感じていた事をより具体的に適切な図を使って説得力のある内容をふんだんに盛り込んだような記事。レベルの違いに衝撃を受ける。でも、自分のこの記事も状況に応じて技術を変える具体例の一つとして見てもらえると有り難い。
参考にさせて頂いたサイト
AWSオフィシャル
AWS Lambda のクォータ
AWS SageMaker
皆さんの良記事
AWS LambdaでAPI開発するときのパターン集
LambdaとDjangoの相性ってどうなの??
AWS Lambda Layersでライブラリを共通化
[アップデート]Lambdaのメモリ上限が10G、vCPUの上限が6に拡張されました!! #reinvent
EFSにセットアップしたPythonライブラリをLambdaにimportする方法
【日本語モデル付き】2020年に自然言語処理をする人にお勧めしたい文ベクトルモデル