本記事の方針についての注意書き
本記事は、専門書を開く前段階で全体像を直感的につかむこと を目的としています。
そのため、数学的な厳密性よりも、イメージのつかみやすさを優先しています。
本文中の表現や説明には、厳密な定義・命題の前提条件・適用範囲を意図的に省略・簡略化している箇所があります。
本記事を読み終えた後で、専門書や論文に進む際の参考にしていただけますと幸いです。
※ タイトルの「高校数学レベル」とは、本記事を読むために厳密な測度論や関数解析を前提にしない という意味です。
SDE・コピュラ・点過程といった用語そのものは登場しますが、それぞれを「どんな問題を解く道具なのか」という直感のレベルで説明します。記号や証明を追える必要はありません。

この記事のシリーズ位置
本記事は、Qiita連載「数学高校レベルのDS向け」シリーズの第2弾にあたります。
既発表記事(第1部): 数学高校レベルのDS向けに「測度論 → 伊藤積分 → ブラックショールズ」を全部つなげてみる
第1部では、確率微分方程式(SDE) という、金融工学の主役の1本柱を縦に深く掘り下げました。
本記事(第2部)では、視野を金融工学の全体像にまで広げ、SDE以外にも金融工学を支えている多様な数学理論を、横並びで俯瞰していきます。
第1部を読まれていない方でも、本記事だけで完結して読めるよう配慮しています。
同時に、第1部と組み合わせて読まれると、より立体的にご理解いただけるようにも努めました。
はじめに ― 本記事の想定読者と読むメリット
想定読者

- 高校理系の数学(数III、確率、簡単な微積分)を一度学んだことはあるが、もうほとんど忘れてしまったレベル
- 大学の解析学・微分方程式・偏微分方程式は未学習
- データサイエンスや機械学習の現場で働いており、金融業界の論文や教科書を眺めたときに、確率微分方程式以外にも知らない数学用語が次々と出てきて戸惑ったことがある
- 「金融工学 = ブラックショールズ」というイメージで止まっており、それ以外に何があるのか全体像が見えない
- ロボアドバイザー、リスク管理システム、高頻度取引(HFT)などの個別トピックは聞いたことがあるが、それらがどう体系づけられているのかが、よくわからない!
この記事を読むメリット
本記事は定義の羅列をしません。
金融工学を以下の観点から整理・俯瞰し、金融工学の全体の見取り図(俯瞰図)をお届けします。
- 4つの大領域(値段付け・リスク管理・ポートフォリオ最適化・市場マイクロ構造)に分けて、それぞれの目的と主役の数学を整理する
- 各領域で実際に業界で使われている数学理論の名前と一行説明を、辞書的に俯瞰する
- 各論点ごとに、業界で実際に使われているプログラミング言語(Python、C++、Rなど)の実装コードを、業務イメージとして提示する
- 確率微分方程式(SDE)が、金融工学の全体地図のどこに位置しているのかを、第1部記事との接続とともに明確にする

専門書を読み始める前の「地図」になることを目指します。
厳密さよりも、気持ち・イメージ・つながりを優先します。
『読む前』と『読んだ後』で、読者の皆様はどう変わるか

| 読む前 | 読んだ後 | |
|---|---|---|
| 金融工学のイメージ | 「ブラックショールズが中心の、数学的に難しい何か」 | 「4つの大領域からなる、多様な数学理論の組合せ」 |
| SDE以外の数学理論 | ほとんど名前を知らない | 極値理論・コピュラ・点過程など、主要な道具の名前と用途がわかる |
| 各領域の関係 | バラバラに見える | 「値段付け→リスク管理→最適化→取引」という業務の流れで理解できる |
| 自分の専門との接続 | 金融でどう活きるかイメージできない | 機械学習・統計・最適化の自分のスキルが、どの領域で活きるかがわかる |
| 専門書・論文の読みやすさ | 知らない用語が次々出てきて挫折 | 「これは領域②の極値理論の話だな」と地図上で位置づけられる |
TL;DR(一言要約)
金融工学は、4つの大領域(① デリバティブ値段付け / ② リスク管理 / ③ ポートフォリオ最適化 / ④ 市場マイクロ構造)からなり、それぞれに主役の数学理論がある。
確率微分方程式(SDE)は領域①の中心だが、他の領域では極値理論・コピュラ・凸最適化・点過程など、まったく別の数学が主役を務めている。
本記事は、その全体地図を俯瞰する。
本記事の読み方
本記事はかなり長いため、次のような読み方がおすすめです。
- まず全体像をつかみたい → 第1章 と 第6章(一覧表) だけでも地図になります
- ブラックショールズ周辺・オプション値段付けを知りたい → 第2章
- VaR・コピュラ・金融危機の数学に興味がある → 第3章
- 資産運用・ポートフォリオ理論に興味がある → 第4章
- HFT・アルゴリズム取引・KDB+に興味がある → 第5章
- 「で、結局SDEはどこに位置するの?」を知りたい → 第7章
まずは興味のある章だけ読んでも大丈夫です。各章は独立して読めるように書いています。
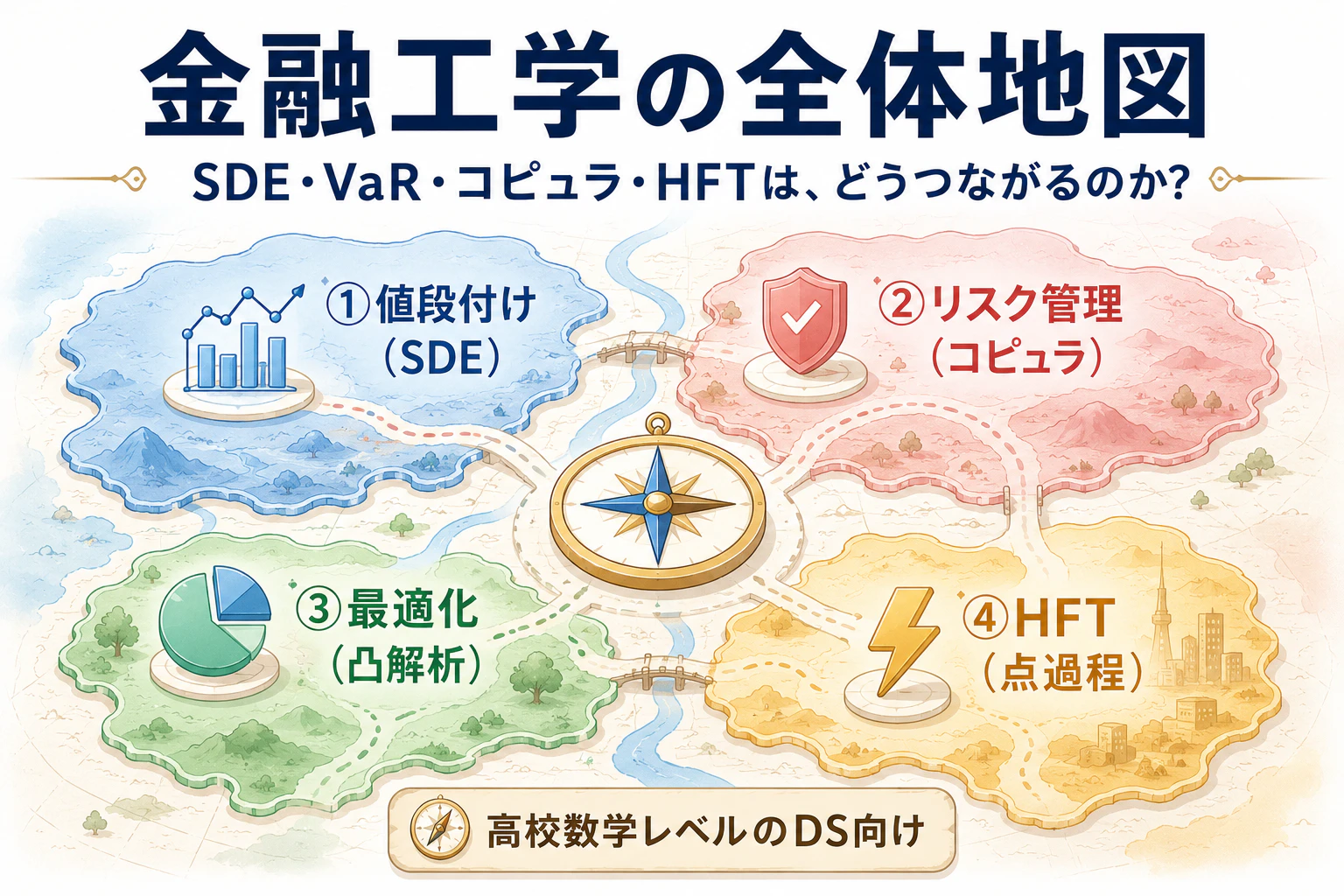
1. そもそも金融工学って何をやっているのか? ―― 4つの大領域
「金融工学」と一言で言われると、なんとなくブラックショールズ方程式やオプション価格の計算を思い浮かべる方が多いかもしれません。
ところが実際の金融工学は、もっと広い領域をカバーしています。
金融機関やヘッジファンドや事業会社が、お金に関わるあらゆる判断を、数学とコンピュータで支える
――これが金融工学の本当の姿です。
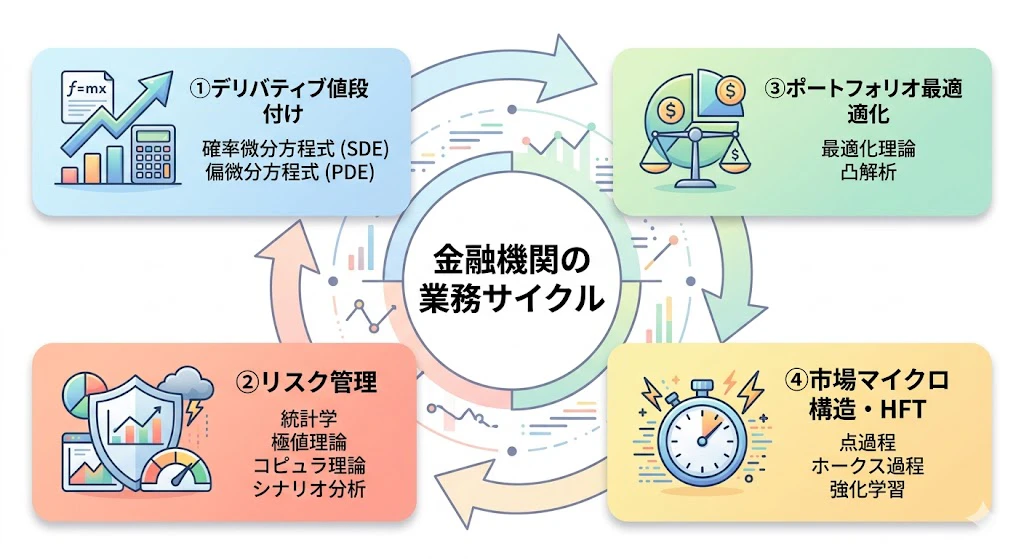
そのために金融工学は、大きく次の4つの領域に分かれています。
1-1. 金融工学の4つの大領域
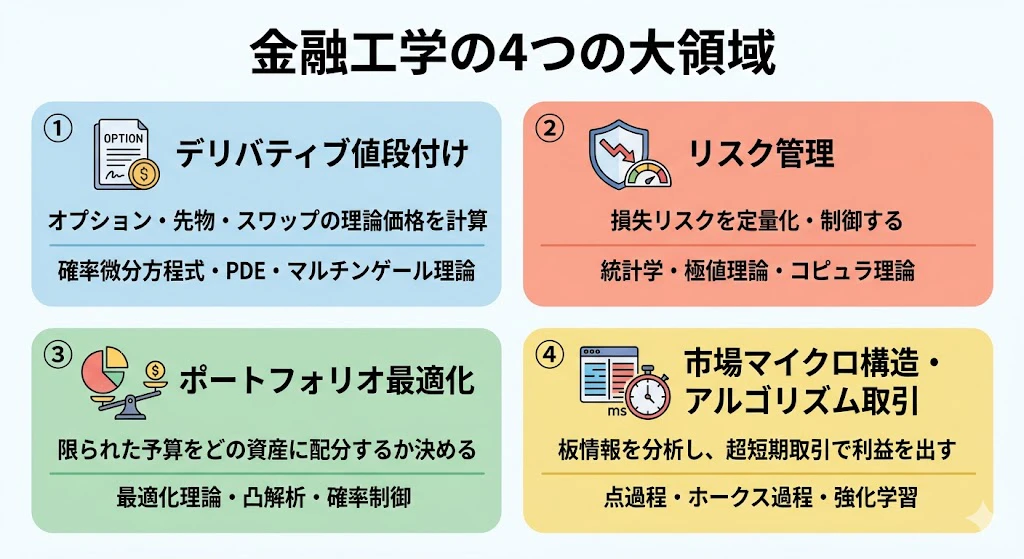
| 領域 | 主な目的 | 主役となる数学 |
|---|---|---|
| ① デリバティブ値段付け | オプション、先物、スワップなど、派生商品の理論価格を計算する | 確率微分方程式、偏微分方程式、マルチンゲール理論 |
| ② リスク管理 | ポートフォリオの損失リスクを定量化・制御する | 統計学、極値理論、コピュラ理論 |
| ③ ポートフォリオ最適化 | 限られた予算をどの資産にどう配分するかを決める | 最適化理論、凸解析、確率制御 |
| ④ 市場マイクロ構造・アルゴリズム取引 | 板情報・約定データを分析し、超短期取引で利益を出す | 点過程、ホークス過程、強化学習 |
この記事では、それぞれの領域について、業務でやっていることをひと言で説明します。
その前に、本記事を貫く視点を先に一言で示すと、次のようになります。
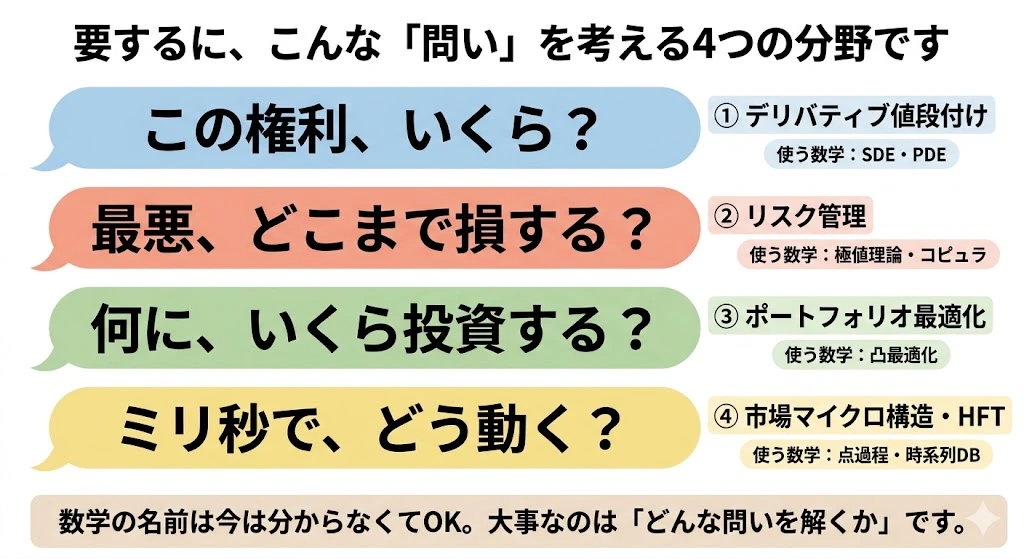
| 領域 | 主に解く問題 | 主役の数学 |
|---|---|---|
| ① デリバティブ値段付け | 将来価格(この権利はいくら?) | SDE・PDE |
| ② リスク管理 | 破綻確率(最悪どこまで損する?) | 極値理論・コピュラ |
| ③ ポートフォリオ最適化 | 配分(何にいくら投資する?) | 凸最適化 |
| ④ 市場マイクロ構造・HFT | 超高速執行(ミリ秒でどう動く?) | 点過程・時系列DB |

4つの領域は、解いている「問題」が違うので、主役の「数学」も違う のです。
この「問題が違えば数学も違う」という構図が、本記事の背骨です。
さらに面白いのは、4つの領域は扱う「時間スケール」もまったく違う ことです。
同じ「金融」という言葉でくくられていても、年単位で動く世界と、ミリ秒で動く世界が同居しているのです。
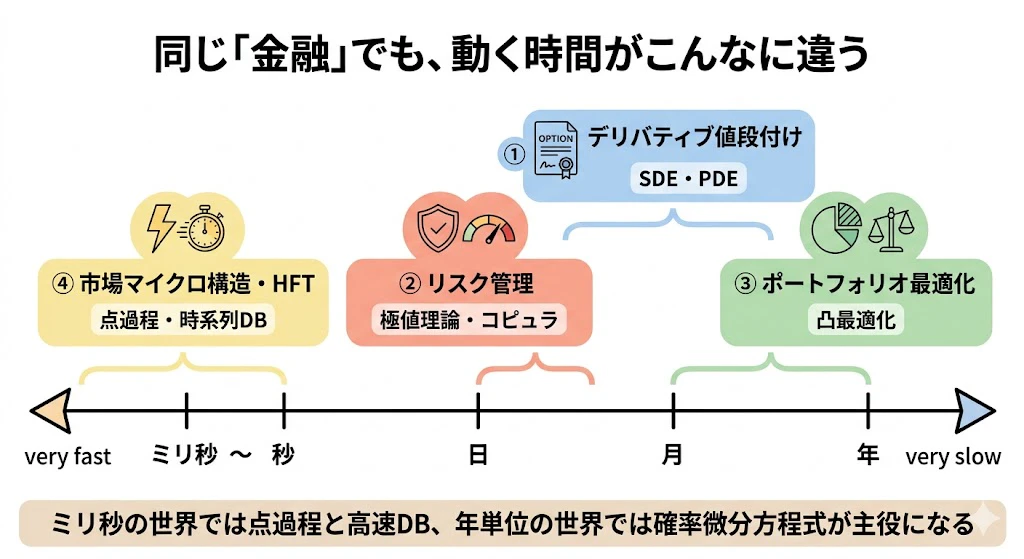
| 領域 | 時間スケール | 主役の数学 |
|---|---|---|
| ① デリバティブ値段付け | 日〜年 | SDE・PDE |
| ② リスク管理 | 日〜月 | 極値理論・コピュラ |
| ③ ポートフォリオ最適化 | 月〜年 | 凸最適化 |
| ④ 市場マイクロ構造・HFT | ミリ秒〜秒 | 点過程・時系列DB |
時間スケールが違えば、必要な数学も、使うコンピュータ技術も変わります。年単位の世界では確率微分方程式が、ミリ秒の世界では点過程と高速データベースが主役になる ―― この対比も、読み進める際の道しるべにしてください。
以下、ひとつずつ見ていきます。
1-2. 領域① デリバティブ値段付け ―― 「この権利、いくらが妥当?」

たとえば、1年後にトヨタ株を 1株 3000円で買える権利を、いま売買するとしたら、いくらが妥当でしょうか?
- 1年後にトヨタ株が 4000円になっていれば、権利を行使すれば 1000円儲かる
- 1年後にトヨタ株が 2500円になっていれば、3000円で買う権利を行使しても損になるので、買い手は権利を放棄します(これを実務では「権利放棄」または「権利消滅」と呼びます)。
ただし、この権利を最初に買ったときに支払ったお金(これをプレミアム と呼びます。
オプションの購入代金です)は戻ってきません。
つまり、この場合は「支払いプレミアム分」が損失となり、買い手にとって損失はプレミアム分に限定されます(損失は「プレミアム分が上限」という、オプション取引の重要な特徴です)。
つまりこの権利は、「1年後の株価次第で価値が変わる」という性質を持っています。これをオプション と呼びます(より正確には、上の例のように「ある期日に、ある値段で買う権利」のオプションをコール・オプション と呼びます。逆に「ある期日に、ある値段で売る権利」のオプションをプット・オプション と呼びます)。
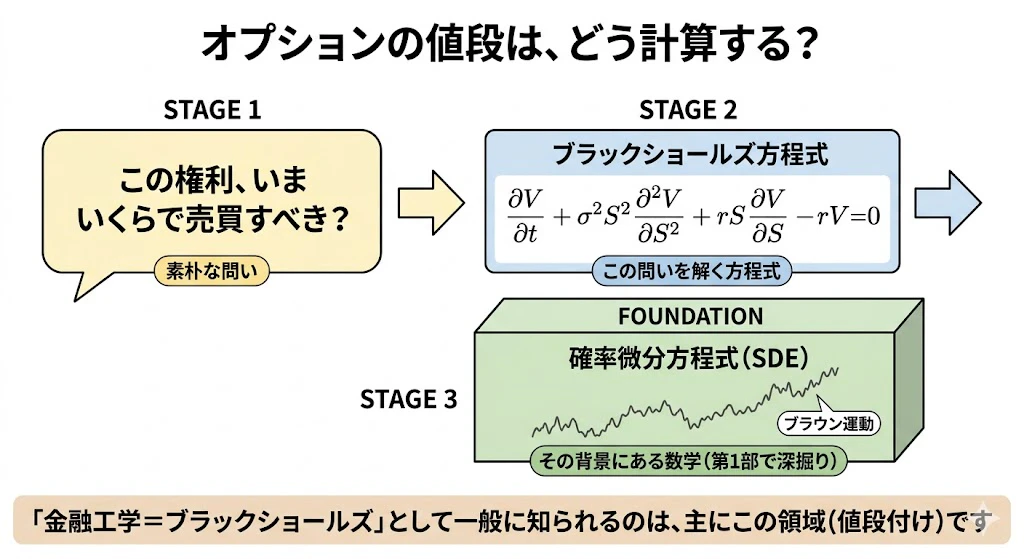
オプションをいま、いくらで売買すべきか? ―― これを計算する数学の中心が、第1部記事で扱ったブラックショールズ方程式であり、その背景にある確率微分方程式(SDE)です。
金融工学が一般に知られているのは、主にこの領域です。
1-3. 領域② リスク管理 ―― 「明日、最悪いくら損するか?」
あなたが運用しているポートフォリオが、明日の取引で 99% の確率で、最大いくら損しそうか?
これに答えるのがリスク管理の領域です。
代表的な道具が、次の3つです。

道具① VaR(Value at Risk、バリュー・アット・リスク)
代表的な指標がVaRで、「99% の確率で、損失は X 円以下に収まる」という形で表現されます。
たとえば、「我が社のポートフォリオの 1日 VaR(99% 信頼水準)は 10億円です」と言えば、これは「99% の確率で、1日の損失は 10億円以下に収まる」という意味です。
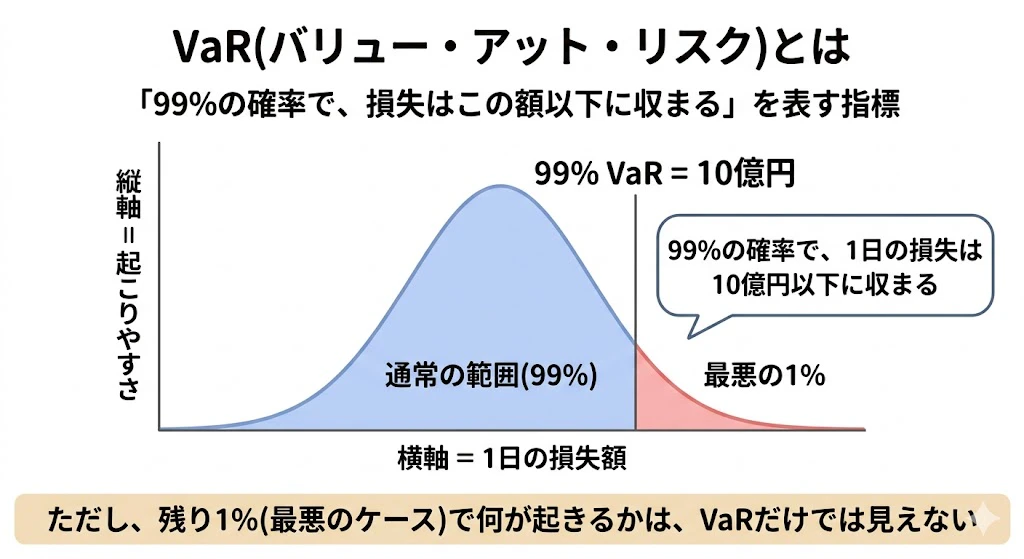
ただし、VaRには本質的な限界があります。
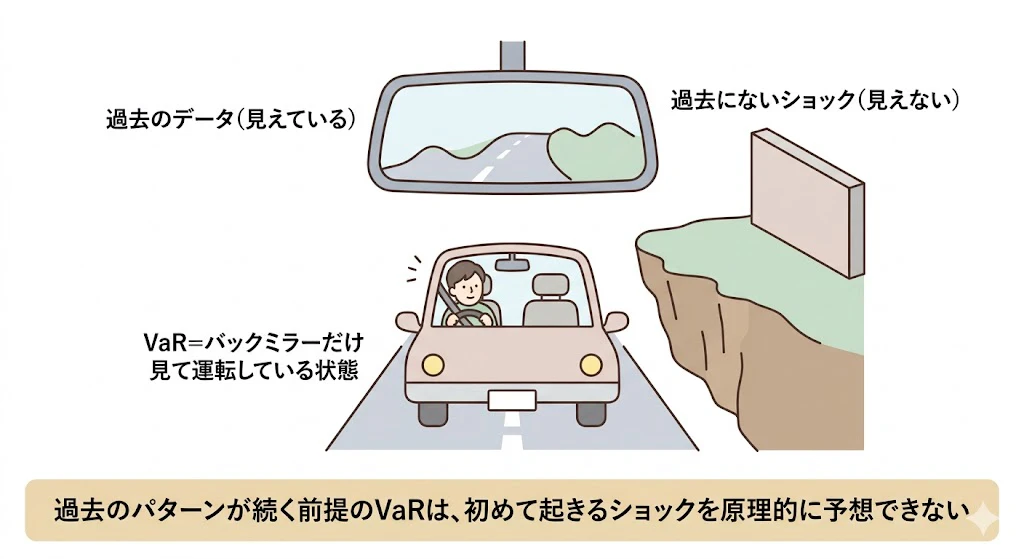
VaRは、過去の市場データのパターンが、将来も同じように続く という前提のもとで、過去のデータから損失分布を推定し、将来の最大損失額を予想する手法です。
つまり、過去に観測されていない種類のショックは、原理的に予想できません。

象徴的だったのが、2008年のサブプライムローン・ショックです。このとき起きたのは、「全米のほとんどの州で、不動産価格が短期間のうちに同時に暴落する」という事象でした。
実は、米連邦準備制度(FRB)の公式見解でも、全国規模での住宅価格の大幅な下落は米国の歴史データにおいて稀であった、と記録されています(Federal Reserve History, "The Great Recession and Its Aftermath")。
過去に類似の事例として、1929年の大恐慌期に全米で住宅価格が約 31% 下落した例がありますが、これは19年かけてゆっくり進行した出来事で、回復にも長期を要しました。一方、2008年の暴落は数年という短期間で20%以上の下落を引き起こす、戦後の経済データには存在しないパターンでした。

加えて、現代の金融機関のVaR計算で使う過去データの期間は、通常 数年から、長くても10年程度です。そのため、80年近く前の大恐慌期のデータは、実務のVaR計算の対象範囲には事実上入っていません。
つまり、実務で使われる範囲の過去データには「全米同時暴落」のパターンが存在しなかったため、過去データを使う VaR では、このリスクイベントを予想することができなかったのです。

道具② ストレステスト(Stress Test)

VaRの限界を補うために、サブプライムショック以降、各国の金融機関で実施が義務付けられるようになったのがストレステストです。
過去に観測されたかどうかにかかわらず、起こりうる極端なシナリオを仮想的に設定し、その下でポートフォリオがどれだけの損失を被るかをシミュレーションします。
サブプライム以降、ストレステストは各国の規制で義務化されました。
- 米国: ドッド・フランク法(2010年制定)に基づき、FRBが大規模銀行に対して一斉ストレステストを毎年実施
- 欧州: EBA(欧州銀行監督機構)が主要銀行に対する一斉ストレステストを定期的に実施
- 国際基準: バーゼル委員会が、各国共通のストレステスト実施に関する諸原則(2009年)を公表
- 日本: 金融庁・日本銀行が、銀行・保険会社に対するストレステストの実施を求めている

道具③ リバース・ストレステスト(Reverse Stress Test)
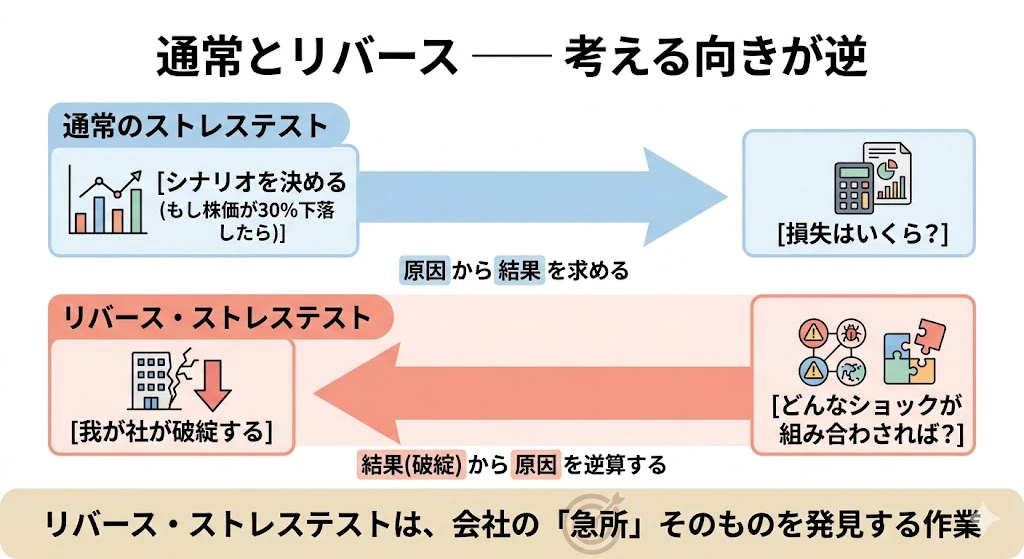
通常のストレステストが「あるシナリオ→損失額」の順なのに対し、リバース・ストレステストは順序を逆にし、「我が社が破綻状態に陥るケース(シナリオ)とは、市場でどんなショックが、どう組み合わさって起きた場合か?」を逆算で導き出します。
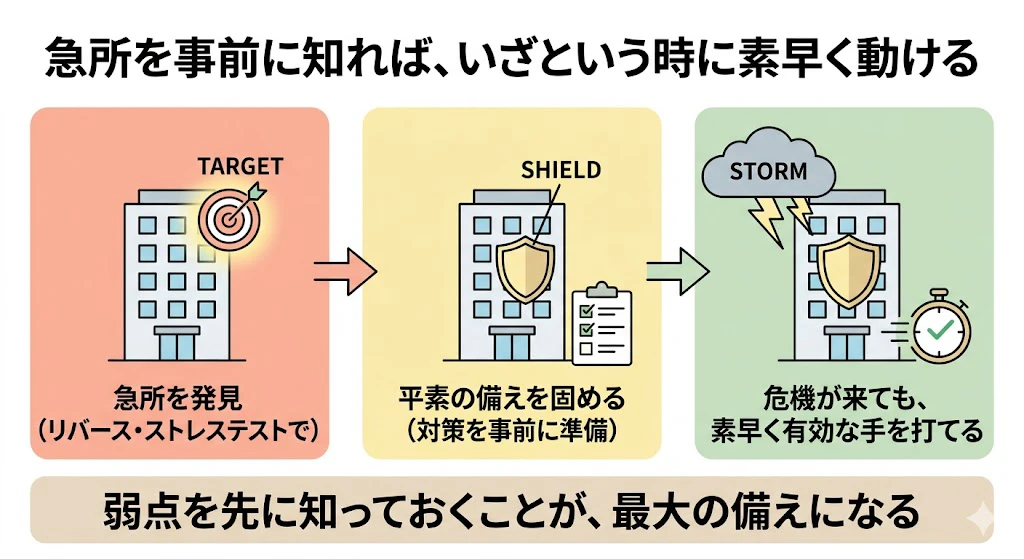
これは、会社の急所そのものを発見する作業です。
発見した自社の経営破綻シナリオを事前に洗い出すことで、そのようなシナリオが将来、発生した場合でも、有効な手立てをスピーディに講じることができるように、「平素の備え」を固めておくことが目的です。
バーゼル委員会・各国規制で実施が求められています。
これらの道具を支える数学は、確率微分方程式ではなく、統計学・極値理論・コピュラ理論・シナリオ分析が中心です。
詳しくは第3章で見ていきます。

1-4. 領域③ ポートフォリオ最適化 ―― 「100万円、どう配分する?」
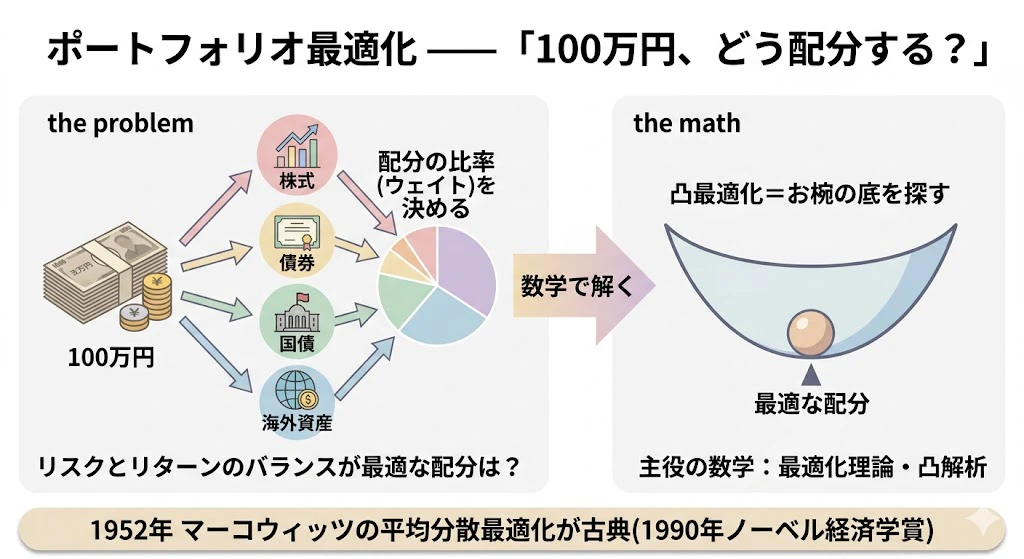
100万円を、どの資産にいくらずつ配分すべきか?
これに答えるのがポートフォリオ最適化の領域です。主役の数学は最適化理論と凸解析です。
1952年にハリー・マーコウィッツが提案した平均分散最適化が古典で、これは凸二次計画問題として書けます。マーコウィッツはこの仕事で 1990年にノーベル経済学賞を受賞しました。
1-5. 領域④ 市場マイクロ構造・アルゴリズム取引 ―― 「ミリ秒の世界」

近年、爆発的に発展しているのが、ミリ秒単位での超短期取引(高頻度取引、HFT)の領域です。
ここで主役になる数学は、点過程(point process)、特にホークス過程(Hawkes process)という、「注文が一度入ると、その後しばらく注文が入りやすくなる」という自己励起性を表現する数学です。
加えて、強化学習などの機械学習も、近年は中心的な道具になっています。
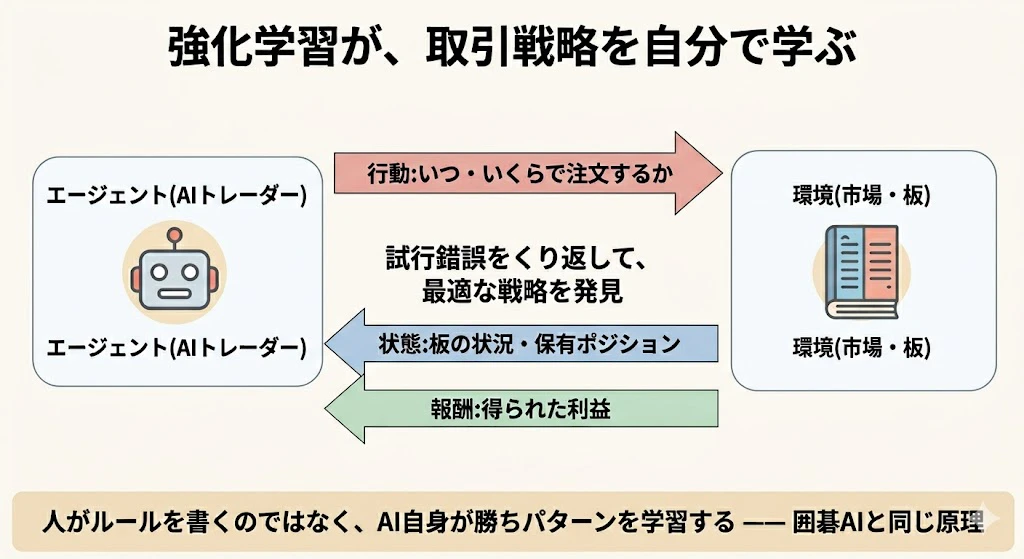
1-6. 4つの領域は、お互いにどう関係しているのか
これら4つの領域は、金融機関の業務の流れとして、次のようにつながっています。
- 領域① で「何がいくらの価値か」を計算し、
- 領域③ で「何にいくら投資するか」を決め、
- 領域④ で「それをどう実行するか」を最適化し、
- 領域② で「全体のリスクをどう管理するか」を監視する
―― という、業務の一連の流れとして、4つの領域がつながっているのです。
1-7. 本記事の進め方
第2章以降では、これら4つの領域をひとつずつ順に深掘りしていきます。
各章では、以下の3点をセットで紹介していきます。
(1) 何を解こうとしている問題なのか?
(2) 主役の数学理論は何か?
(3) 業界で実際に使われているプログラミング言語のコード例は?

それでは、まずは第1部の延長線上にある領域① デリバティブ値段付けから見ていきましょう。
2. 領域① デリバティブ値段付け ―― SDEが主役の世界
それでは、4つの領域を順に深掘りしていきます。
まずは、領域①「デリバティブ値段付け」 から説き起こします。
これは、本記事執筆者が公開済み次の記事で、深堀り解説しています。
ご関心をお寄せ頂いた方は、この記事とセットでお読みいただくと、金融工学に関する理解をさらに深めて頂けると思います。
上記の記事を読まれていない方でも理解できるように、まずはごく簡潔におさらいをします。
その上で、この記事では、上記の記事では触れなかった実務サイドの広がりを見ていきます。
2-1. 過去の関連記事のおさらい(60秒で振り返り)
先ほどご紹介した関連記事では、次の問いに答えるための数学を追いかけました。
「1年後にトヨタ株を 1株 3000円で買える権利(=コール・オプション)を、いま、いくらで売買すべきか?」
この問いに答えるために、株価の動きを確率微分方程式(SDE)でモデル化し、ブラウン運動を伊藤積分で積分し、SDEを解いて株価の確率分布を求め、オプションの期待値を計算し、ブラックショールズ方程式(偏微分方程式)に到達する ―― という流れでした。
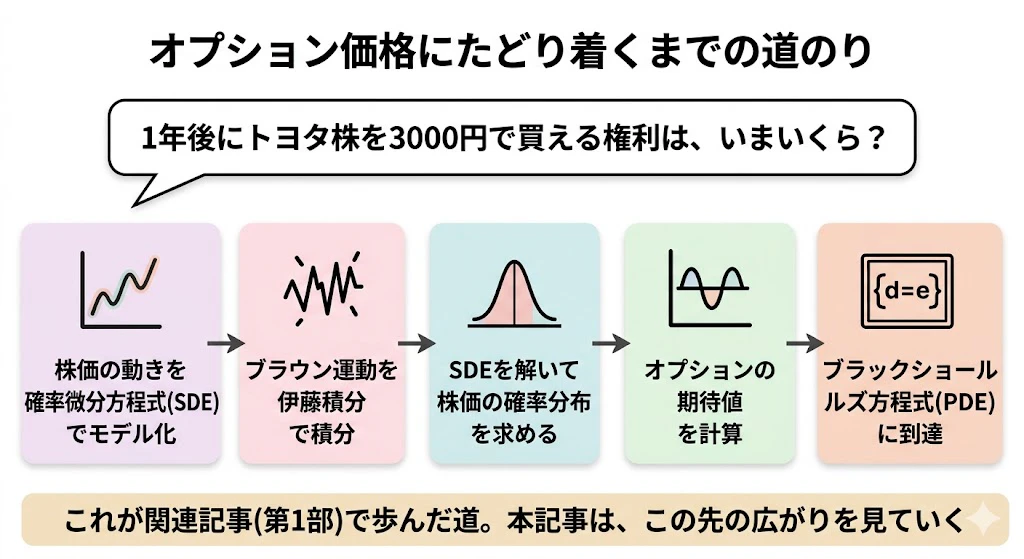
つまり領域① の中心にあるのは、「将来の株価」→「オプションの理論価格」という、確率微分方程式から派生商品の値段を計算する流れです。
2-2. 領域① をもう少し広く眺める
実際のデリバティブ値段付けの現場では、ブラックショールズ方程式だけで済むわけではありません。
実務で扱う商品は、もっと多様で複雑です。

| 商品 | 説明 | 値段付けの難しさ |
|---|---|---|
| 欧州型コール・プット | ある期日にだけ権利行使できる、最もシンプルなオプション | 公式で解析的に計算可能 |
| アメリカン・オプション | 期日までいつでも権利行使できる | 最適停止問題が絡み、解析解はない |
| バリア・オプション | 株価がある水準に到達したら発動・消滅する | 経路依存性があり、計算が複雑 |
| アジアン・オプション | 平均株価で行使価値が決まる | 経路全体の平均が必要で解析解は限定的 |
| 金利デリバティブ | 金利の変動を対象にした派生商品 | 金利の期間構造モデルが必要 |
| クレジット・デリバティブ | 企業の倒産リスクを対象にした派生商品 | 強度過程やコピュラなど別系統の数学が必要 |
ブラックショールズの公式が解析的に使えるのは、欧州型コール・プットのような最も単純なケースに限られます。
実務の大部分の商品では、数値計算に頼らなければなりません。
📖 コラム: 数値計算とは何か
数学の問題を解くアプローチには、大きく2種類あります。
① 解析的に解く(解析解)
紙とペンで答えを「式の形」で書ける場合です。たとえば2次方程式の解の公式のように、誰がやっても同じ式として書けます。② 数値的に解く(数値解)
世の中の多くの問題は解析的には解けません。
たとえば、5次以上の一般の代数方程式は、四則演算と冪根では解けません (アーベル・ルフィニの定理/ガロア理論)。それでもコンピュータを使えば、答えに近づけていくことはできます。これが数値計算です。
金融工学で実務的に解く問題のほとんどは解析的には解けないため、コンピュータで近似計算する数値計算が主役の道具になります。本章のモンテカルロ法・有限差分法・2項ツリー法は、すべてこの数値計算の手法です。
2-3. 実務で使われる3つの数値手法
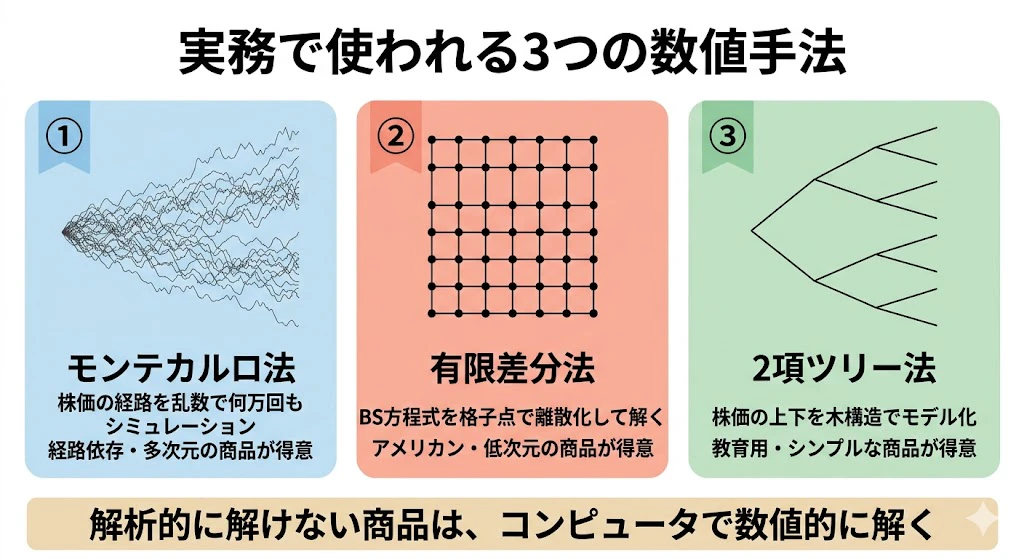
| 手法 | 何をする | 得意な商品 |
|---|---|---|
| ① モンテカルロ法 | 株価の経路を乱数で何万回もシミュレーションし、ペイオフの平均を取る | 経路依存性のある商品、多次元の商品 |
| ② 有限差分法 | ブラックショールズPDEを格子点で離散化して数値的に解く | アメリカン・オプション、低次元の商品 |
| ③ 2項ツリー法 | 株価の上昇・下落を木構造でモデル化 | 教育用、シンプルなアメリカン・オプション |
2-4. 業務イメージ①: モンテカルロ法

モンテカルロ法は、株価の経路をSDEに従ってシミュレーションし、満期時のペイオフを計算し、これを10万回繰り返して平均を取り、リスク中立測度のもとでの期待値として現在価値に割り引く手法です。
SDEさえ書ければどんな複雑な商品でも値段が計算できる、万能な手法です。
import numpy as np
S0 = 3000.0 # 現在の株価
K = 3000.0 # 行使価格
r = 0.01 # 無リスク金利
sigma = 0.20 # ボラティリティ
T = 1.0 # 満期までの期間 (年)
n_paths = 100000 # シミュレーション回数
np.random.seed(42)
Z = np.random.standard_normal(n_paths)
S_T = S0 * np.exp((r - 0.5 * sigma**2) * T + sigma * np.sqrt(T) * Z)
payoff = np.maximum(S_T - K, 0)
call_price = np.exp(-r * T) * np.mean(payoff)
print(f"モンテカルロ法によるコール価格: {call_price:.2f} 円")
業務では、C++やCUDAでの高速化、分散減少法による精度向上、経路依存性への対応、多次元化などの拡張を加えていきます。
業界では計算の中核をC++で書き、Pythonから呼び出す構成が一般的です。
2-5. 業務イメージ②: 有限差分法 ―― PDEを格子で解く

ブラックショールズ方程式は偏微分方程式(PDE)でした。
このPDEを、(株価 S, 時刻 t)の2次元の格子点上で離散化して、満期 T での境界条件(ペイオフ)から時刻を巻き戻すように解いていきます。
-
離散化 ―― 連続的に変化する量を、飛び飛びの点で近似すること。株価や時刻を有限個の格子点に切り分けます。
-
境界条件 ―― 方程式を解くために必要な「端っこでの値」。満期 T に到達した端などで、答えがあらかじめ決まっている条件です。
-
ペイオフ ―― オプションが満期を迎えたときに買い手がもらえる金額。行使価格3000円のコールなら、満期株価4000円でペイオフ1000円、2500円ならペイオフ0円(権利放棄)です。
有限差分法が特に強いのはアメリカン・オプションです。各時刻で「いま行使するか、待つか」を最適に判断する最適停止問題を、満期から時刻を巻き戻すことで自然に扱えます。
少し整理しておきましょう。有限差分法の理解の鍵は、次の3つです。
株価 × 時刻の2次元格子という「舞台」
まず、株価と時刻の組み合わせを、碁盤の目のような格子で表します。これが計算の舞台です。満期の端は、答えが決まっている(境界条件)
格子の右端(満期 T)では、オプションの価値が「ペイオフ」としてあらかじめ決まっています。ここが計算の出発点になります。そこから時刻を巻き戻して、現在の価格を求める
答えが分かっている満期の端から、時刻を1ステップずつ過去にさかのぼり、最終的に「現在の価格」を求めます。
ポイントは、「答えが分かっている満期」から「知りたい現在」へ、時間を逆向きにたどる という発想です。
普通は過去から未来へ計算しそうなものですが、有限差分法では逆。
満期というゴールが先に決まっているからこそ、そこから巻き戻せるのです。
2-6. 業務イメージ③: 2項ツリー法
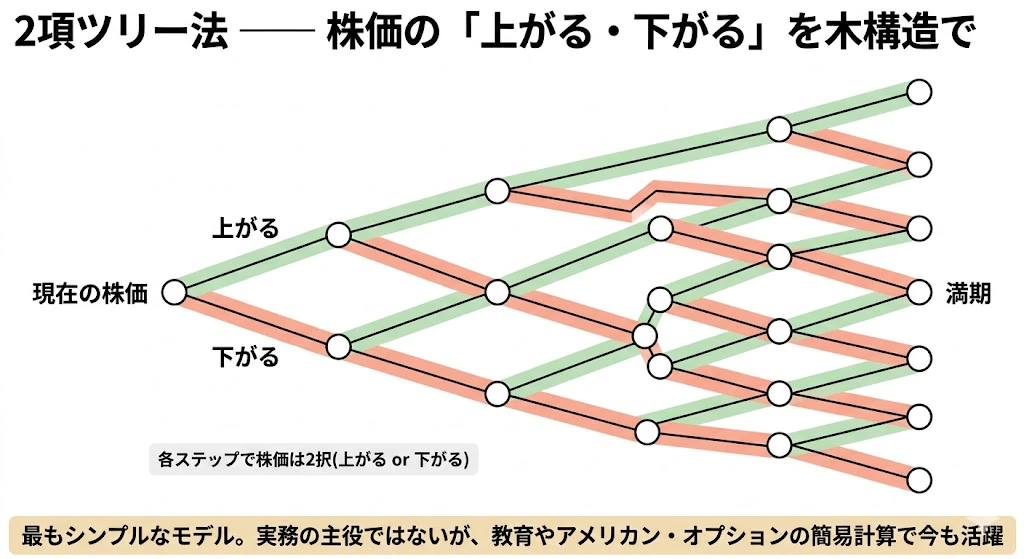
2項ツリー法(Cox-Ross-Rubinsteinモデル)は、株価が各ステップで「上がる」「下がる」の2択を取るとした最もシンプルなモデルです。
実務の主役ではありませんが、教育・プロトタイピング・アメリカン・オプションの簡易計算で、いまも生きています。
2-7. 業務イメージ④: グリークス
実務で重要なのは価格そのものだけではありません。
「株価が1円動いたら価格は何円動くか」「ボラティリティが1%動いたら何円動くか」といった感度(偏微分) が、トレーダーのポジション管理の生命線です。
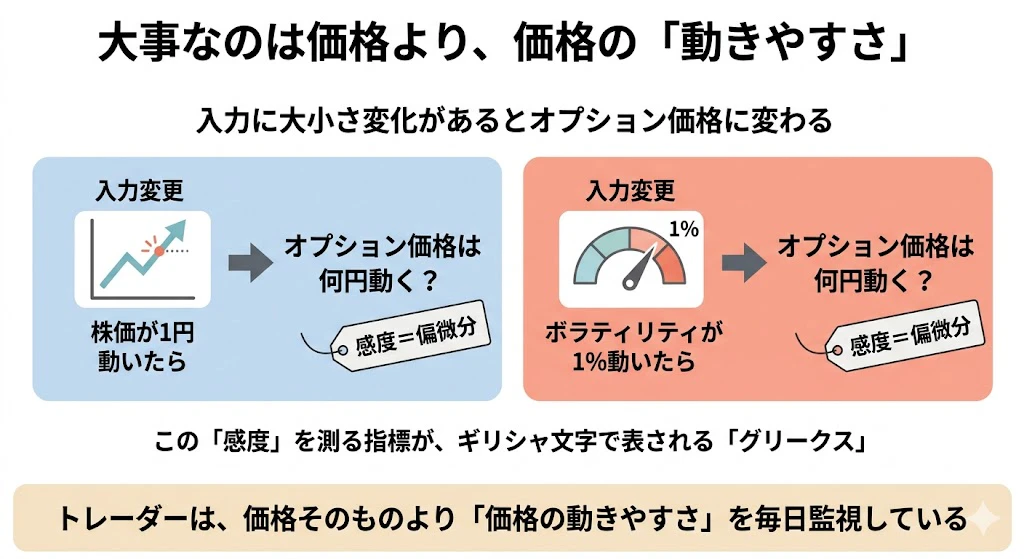
これらはギリシャ文字で表されるため、業界ではグリークス と呼ばれます。

| 記号 | 意味 | 業務での使い方 |
|---|---|---|
| Δ(デルタ) | 株価に対する感度 | ヘッジ比率の計算 |
| Γ(ガンマ) | デルタ自身の感度(2階微分) | デルタヘッジの精度を測る |
| ν(ベガ) | ボラティリティに対する感度 | ボラ変動リスクを把握 |
| Θ(セータ) | 時間に対する感度 | 時間価値の減少を把握 |
| ρ(ロー) | 金利に対する感度 | 金利変動リスクを把握 |
グリークスの計算には、解析計算、モンテカルロでの数値微分、自動微分(AAD)などが使われます。

📖 コラム: 自動微分(AAD)とは何か
グリークスは、価格そのものが「10万本の経路をモンテカルロでシミュレーションして平均を取る」といった大きな計算の塊であるうえ、何百〜何千の市場変数すべてに対する感度を計算する必要があります。
素朴な数値微分(各変数を少し動かして再計算)では、1000変数なら1001回シミュレーションが必要で、計算時間が感度の本数に比例して増えます。
自動微分(AAD)は、これを根本的に変えました。シミュレーションを1回走らせるだけで、すべての市場変数に対する感度を同時に計算できます。数学的には微分の連鎖律を計算グラフ上に逆向きに伝播させる技術で、ディープラーニングの誤差逆伝播法とまったく同じ原理です(PyTorchやTensorFlowの中核技術も自動微分です)。
AADにより、数時間かかっていたグリークス計算が数分で終わるようになり、2010年代に大手投資銀行を中心に広く採用されました。
2-8. 業務イメージ⑤: QuantLib ―― 業界デファクトのOSS
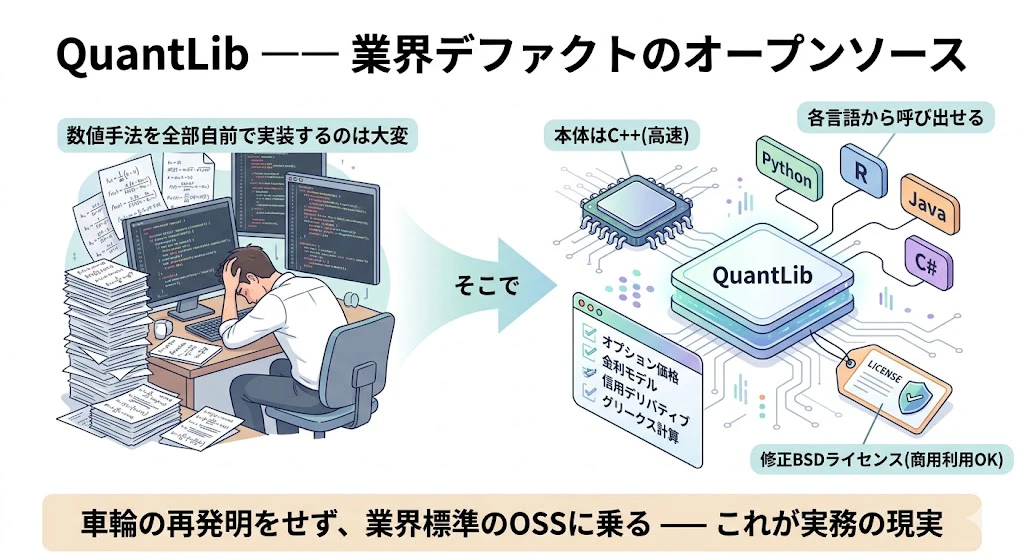
ここまでの数値手法を、全部自前で実装するのは現実的ではありません。
業界で広く使われているOSSがQuantLibです。主言語はC++で、Python・R・Java・C#などから呼び出せます。
各種オプション価格計算、金利モデル、信用デリバティブ、グリークス計算などの機能を持ち、修正BSDライセンス(商用利用可)です。
import QuantLib as ql
today = ql.Date(19, 5, 2026)
ql.Settings.instance().evaluationDate = today
spot, strike = 3000.0, 3000.0
risk_free_rate, dividend_yield, volatility = 0.01, 0.02, 0.20
maturity = ql.Date(19, 5, 2027)
spot_handle = ql.QuoteHandle(ql.SimpleQuote(spot))
rf = ql.YieldTermStructureHandle(ql.FlatForward(today, risk_free_rate, ql.Actual365Fixed()))
div = ql.YieldTermStructureHandle(ql.FlatForward(today, dividend_yield, ql.Actual365Fixed()))
vol = ql.BlackVolTermStructureHandle(ql.BlackConstantVol(today, ql.NullCalendar(), volatility, ql.Actual365Fixed()))
process = ql.BlackScholesMertonProcess(spot_handle, div, rf, vol)
payoff = ql.PlainVanillaPayoff(ql.Option.Call, strike)
exercise = ql.EuropeanExercise(maturity)
option = ql.VanillaOption(payoff, exercise)
option.setPricingEngine(ql.AnalyticEuropeanEngine(process))
print(f"BS価格: {option.NPV():.2f} 円, デルタ: {option.delta():.4f}")
2-9. リスク中立測度 ―― 実務では「いつ使う」概念か

モンテカルロ法のコードに、さらっと「リスク中立測度のもとでの期待値」という言葉が出てきました。
この リスク中立測度 は、金融工学でもっとも抽象的で、もっとも多くの人がつまずく概念です。
しかし実務での使われ方は、実はとてもシンプルです。
ここでは「結局どう使うのか」を最初に言ってしまいます。
ファイナンス実務におけるリスク中立測度とは、「株価の期待リターンを、無リスク金利に置き換えて計算してよい」という便利なルールのことです。
なぜそんな置き換えが許されるのでしょうか?
その理屈を、次のコラムで5ステップに分けて、ゆっくり解説します。
急がず、雰囲気だけつかみとって頂けましたら十分です。
📖 コラム: リスク中立測度とは何か
ステップ1: そもそも「測度」って何?
測度とは「ものの大きさを測る数学的な物差し」のことです。確率論では「事象の起こりやすさを測る物差し」を確率測度と呼びます。コインの表に0.5を与えるのが確率測度の役割です。ステップ2: 「確率測度を変える」とは?
同じ事象でも、使う物差しを変えれば確率の値は変わります。歪んだコイン(本当は表0.6)を、あえて公平(表0.5)とみなす物差しを考える ―― これが確率測度を変えるという操作です。ステップ3: では「リスク中立」とは?
リスク中立的な人とは、不確実性を気にせず期待値だけで判断する人物像です。「100万円もらえる宝くじ(当選確率50%)」と「確実な50万円」を等価とみなします。ステップ3.5: ところで「無リスク金利」とは?
無リスク金利とは「投資家がほぼ100%の確実性で約束されたリターンを受け取れる金融商品の利率」です。日本国債、米国財務省証券、銀行預金などが代表例です。株式投資の期待リターンと無リスク金利の差を、リスクプレミアム(不確実性に耐える代わりにもらえる追加の見返り)と呼びます。ステップ4: 「リスク中立測度」のキモ
現実の株価には無リスク金利より高いリターン(リスクプレミアム)が期待されますが、これを扱うのは難しい。そこで、確率測度をリスク中立な物差しに取り替えると、株価のリターンが無リスク金利と等しくなり、値段付けが劇的に簡単になります。この取り替えた後の仮想の物差しがリスク中立測度です。ステップ5: なぜそれが許されるのか
デリバティブの正しい値段は、リスク中立測度でも現実の確率測度でも同じ値になることが、数学的に証明されます(裁定取引が存在しないという前提のもとで)。だから実務では迷わずリスク中立測度を使います。
コラムが長くなりましたが、実務での結論はとてもシンプルです。
リスク中立測度を使うと、「SDEのドリフト項(株価の期待的な伸び)を、無リスク金利 $r$ に置き換えてシミュレーションし、最後に $exp(-rT)$ で現在価値に割り引く」 という、決まった手続きになります。
第2章の最初に紹介したモンテカルロ法のコードで、
S_0 * np.exp((r - 0.5 *σ^2) * T + ...)
と、ドリフトに金利 $r$ を使っていた のを思い出してください。あれが、まさにリスク中立測度のもとでの計算だったのです。
つまり、理屈は抽象的でも、実際にコードを書くときは「$r$ を使って割り引くだけ」です。
難しい概念が、最後はシンプルな1行の手続きに落ちる ―― ここに金融工学の面白さがあります。
2-10. 領域① でクオンツが日々やっていること
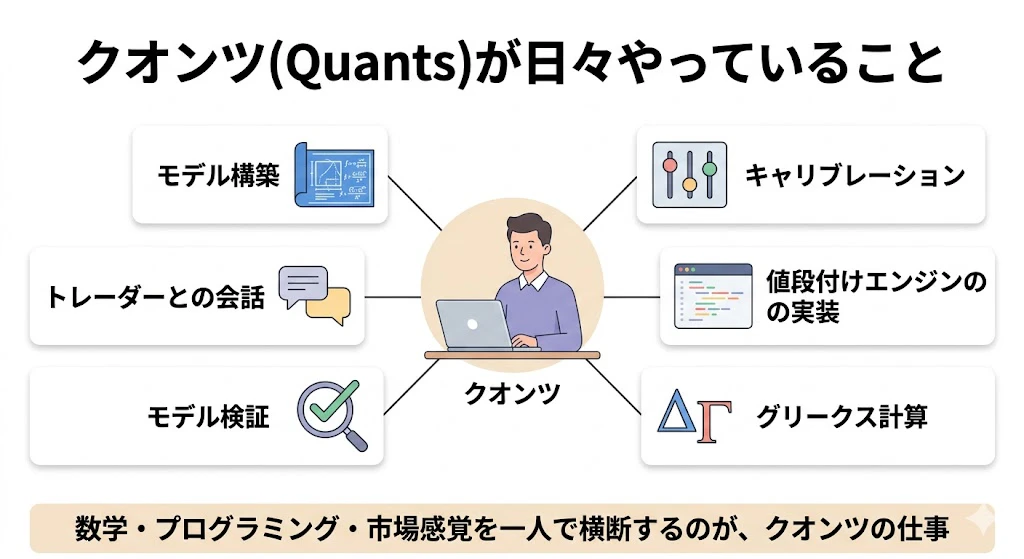
金融機関(投資銀行)やファンドで、クオンツ(Quatns)専門職の人たちが日々取り組んでいる業務は、モデル構築・キャリブレーション・値段付けエンジンの実装・グリークス計算・モデル検証・トレーダーとの会話、などです。
2-10.5. 業界の言語・ツール選択 ―― 誰が何を使っているか
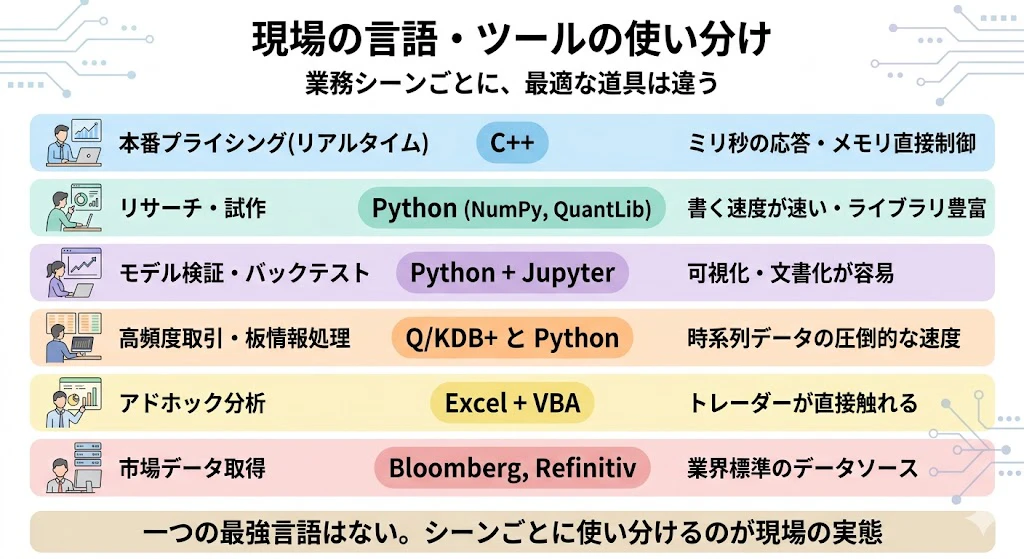
| 業務シーン | 主に使われる言語・ツール | 選ばれる理由 |
|---|---|---|
| 本番プライシング(リアルタイム) | C++ | ミリ秒単位の応答、メモリ・CPU直接制御 |
| リサーチ・プロトタイピング | Python(NumPy, QuantLib) | 書く速度が速い、ライブラリ豊富 |
| モデル検証・バックテスト | Python + Jupyter | 可視化・文書化が容易 |
| 高頻度取引・板情報処理 | Q/KDB+ + Python | 時系列データの圧倒的な処理速度 |
| アドホック分析 | Excel + VBA | トレーダーが直接触れる |
| 市場データ取得 | Bloomberg Terminal/BQuant, Refinitiv | 業界の事実上の標準データソース |
📖 コラム: Q/KDB+ とは何か(HFT界の隠れた支配者)
KDB+は、時系列データに特化した商用の高速データベースです(KX Systems社が開発)。「1秒間に何百万行・何十億行の時系列クエリを処理できる」のが特徴です。東証では1日数十億件の注文・約定データが発生しますが、通常のRDBでは数時間〜数日かかる処理を、KDB+なら秒〜分で処理できます。
Qは、KDB+を操作する専用言語です。配列指向で超簡潔、
{x*x}のような記号的な記述が特徴で、APL系の系譜に連なります。「過去1分間の平均価格」はselect avg price by 1 xbar time.minute from tradeとたった1行で書けます。

Q/KDB+ を学んでみたい人へ
Q/KDB+ は日本語の学習資料がほとんどありませんが、英語の公式・定番リソースは充実しています。学ぶなら、おおむね次の順がおすすめです。
- 無料版をインストールする ―― KX社が個人学習・非商用向けに kdb+ の無料版を配布しています。まずは手元で
q)プロンプトを触るのが一番です(code.kx.com からダウンロードできます)。- 公式チュートリアルを読む ―― 公式ドキュメント code.kx.com の "Learn" セクションに、入門チュートリアルがまとまっています。無料版にコードを貼って動かしながら読めます。
- 定番書『Q for Mortals』 ―― Jeffry A. Borror による、Q/KDB+ 学習の事実上の標準教科書です。オンライン版が無料で公開されており、多くの実務者がここから入っています。
- 『Q-Tips』 ―― 中級者向け。市場マイクロ構造の話題と絡めて実践的なテクニックを学べます。
- KX Academy ―― KX社公式のオンライン学習ポータル。Fundamentals と Advanced のコースに分かれ、PyKX(Python から KDB+ を扱うインターフェース)の入門もあります。
Python から入りたい人は、PyKX(KDB+ を Python から操作できる公式ライブラリ)から触り始めると、馴染みのある環境のまま KDB+ の速度を体験できます。
なお、Q/KDB+ は習得曲線が急で、求人の多くが金融業界に集中しているという特徴があります。「金融に深くコミットする覚悟があるなら強力な差別化武器、そうでなければ ClickHouse や DuckDB など他の時系列・列指向DBから始めるほうが現実的」というのが、業界でよく言われる実態です。
続いて、APLについて簡単に触れます。
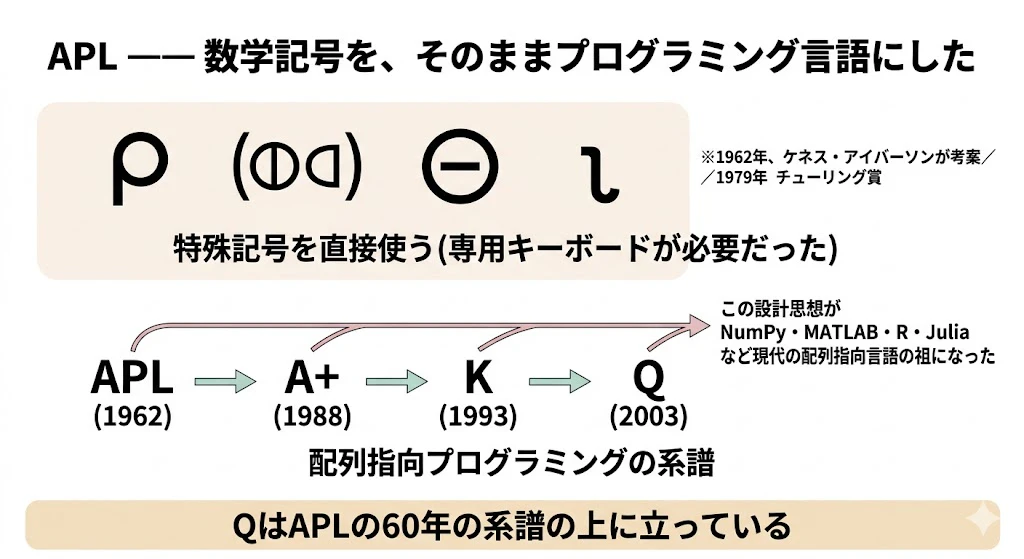
補足: 正確なAPL記号と、その意味
なお、上の画像に描かれた記号は、APLの「雰囲気」を表したイメージです。実際のAPLで使われる記号は、正確には次のものです。画像生成では特殊記号が崩れやすいため、ここで正しい字を確認しておきましょう。
| 画像の雰囲気 | 正確な記号 | 読み方 | 意味 |
|---|---|---|---|
| ρ のような形 | ⍴ |
ロー (rho) | 配列の形を調べる・作り変える(reshape) |
| 丸に三角 | ⌽ |
ファイ (phi) | 配列を左右反転する(reverse) |
| 丸に横線 | ⊖ |
丸の中の線 | 配列を上下反転する |
| つり針のような形 | ⍳ |
イオタ (iota) | 「1からNまでの数列」を作る |
これらは数学やギリシャ文字に由来する記号で、APL専用のキーボードで直接入力していました。一見すると暗号のようですが、一つひとつは「配列に対する操作」を表す、れっきとした演算子です。
APLのコードは、どれくらい短いのか
では、実際のAPLコードがどれほど簡潔か見てみましょう。「1からNまでの整数を全部足す」処理は、こう書きます。
+/⍳N
たった3文字です。
⍳N が「1からNまでの数列を作る」、+/ が「それを全部足し合わせる」という意味です。
同じ処理をPythonで書くと sum(range(1, N+1)) ですから、APLの圧縮率の高さが際立ちます。
もう一つ、「数列の平均値を求める関数」も見てみましょう。
{(+/⍵)÷≢⍵}
わずか9文字です。
{} が関数定義、⍵ が引数、+/⍵ が合計、≢⍵ が要素数、÷ が割り算。
「合計 ÷ 個数 = 平均」が、ほぼ数式そのままの形で書けています。
この「数学の記号を、そのままプログラムにする」という執念が、後の K や Q に受け継がれ、HFTの現場で「1行で巨大な時系列を処理する」文化につながっていきました。
📖 サブコラム: APL ―― 数学記号を直接プログラミング言語にした
APLという名前は "A Programming Language"(=「プログラミング言語のひとつ」)の頭文字に由来します。
1957年、数学者ケネス・E・アイバーソンが数学記号で配列を扱う表記法を考案し、1962年に同名の本を出版。
それを実装した言語の名前が、本のタイトルの頭文字APLになりました。APLは
⍴ ⌽ ⊖ ⍳といった特殊記号を直接使う言語で、専用キーボードが必要でした。配列全体を1操作で扱う設計は、現代のNumPy・MATLAB・R・Q・Juliaなどの配列指向プログラミングの祖です。
アイバーソンは1979年にチューリング賞を受賞しました。
系譜は APL(1962) → A+(1988) → K(1993) → Q(2003) と続き、QはAPLの60年の系譜の上に立っています。
「直近5ティックの移動平均」をPythonとAPLで比べてみます。
# Python (NumPy)
moving_avg = np.array([prices[i:i+N].mean() for i in range(len(prices)-N+1)])
⍝ APL ― たった1行
(N+/prices)÷N
「数列の平均値を計算する関数」はAPLでは {(+/⍵)÷≢⍵} とたった9文字。{} は関数定義、⍵ は引数、+/⍵ は合計、≢⍵ は個数、÷ は割り算です。
同じ平均計算を、APLの直系の子孫Qで書くと avg prices と、特殊記号からASCII文字へと進化しています。
なお、Q/KDB+ と APL は、それぞれ独立した記事として別途詳しく解説する予定です。
本記事では「金融工学の各領域で、こうした言語が実際に使われている」という地図上の位置づけにとどめます。
主要企業・ファンドの言語選好 (公開情報ベース)

- ゴールドマン・サックス: SecDB+Slang(社内言語)から近年Pythonを全社推進
- JPモルガン: Athena(Pythonベース)を全社展開、トレーダーもコードを書く文化
- モルガン・スタンレー: C++の自社ライブラリ、自動微分(AAD)で業界をリード
- Jane Street: 関数型言語OCamlを全面採用(型安全性でバグを抑制)
- シカゴのHFT(Jump Trading等): C++中核、FPGAまで踏み込む
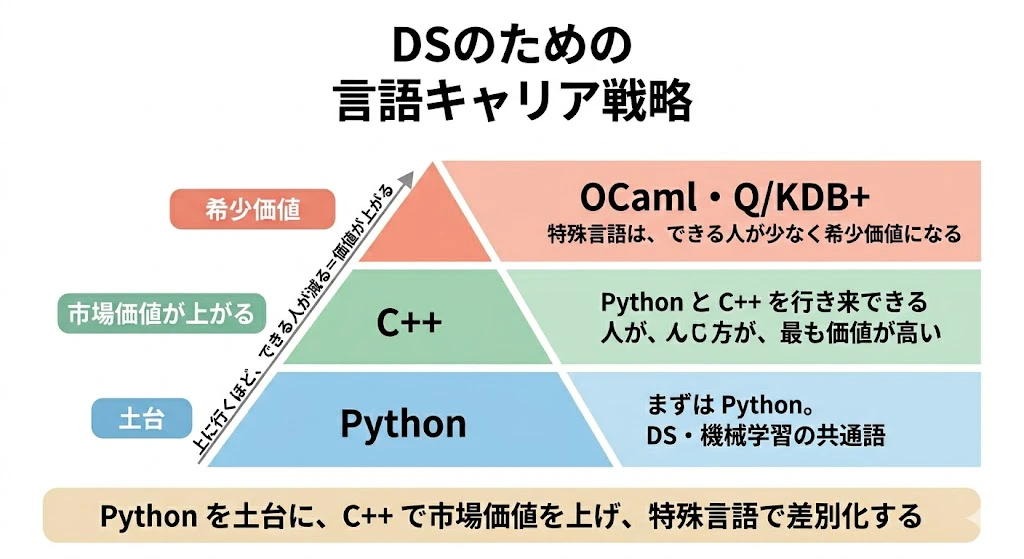
言語選択の背景には、速度の絶対性・レガシーの引きずり・採用しやすさ・バグの起こしにくさ・文化と伝統があります。
学生・若手DSへの示唆として、PythonとC++を行き来できる人が最も価値が高く、OCaml・Q/KDB+などの特殊言語は希少価値になります。
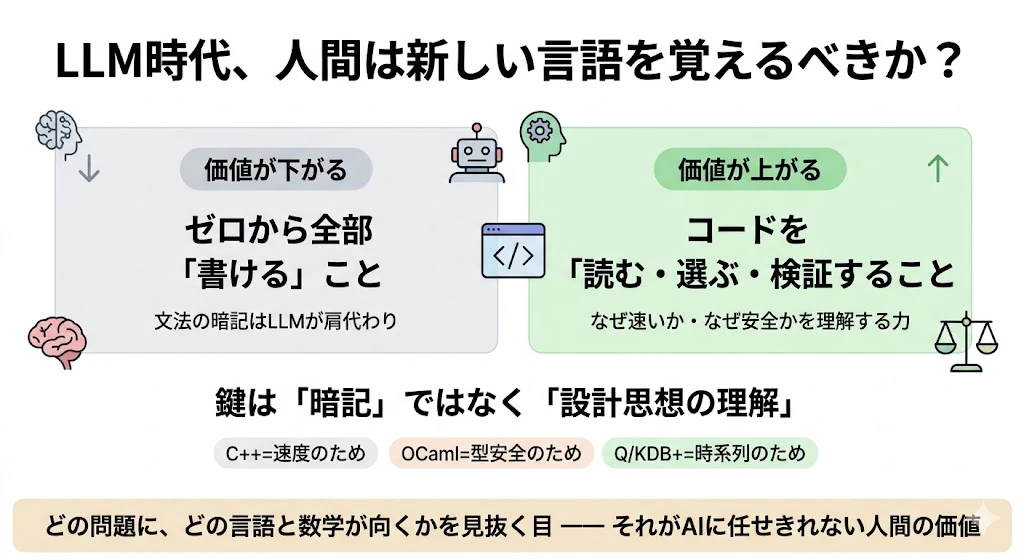
📖 コラム: LLM・AIコーディング時代に、人間は新しい言語を覚えるべきか?
ここまで「Python、C++、OCaml、Q/KDB+ を学ぶと価値が上がる」と書いてきましたが、こう思った方もいるはずです。
「LLMがコードを書いてくれる時代に、わざわざ新しい言語を覚える意味はあるのか?」
これはとても重要な問いです。筆者の考えを述べます。
結論から言うと、「書ける能力」の価値は下がり、「読める・選べる・検証できる能力」の価値は上がる ―― というのが、現時点での見立てです。
LLMは確かに、Q/KDB+ や OCaml のような習得コストの高い言語のコードも、それなりに生成してくれます。文法を暗記する労力は、確実に減りました。この意味で「ゼロから全部書ける」ことの価値は、以前より下がっています。
しかし、金融の本番システムでは、生成されたコードを 読んで理解し、正しいか検証し、性能やリスクを判断する 人間が必要です。特にこの分野では、1つのバグが巨額の損失に直結します。
- C++ なら「なぜここでメモリコピーが起きると遅いのか」を理解していないと、LLMの出力が本番で使えるか判断できません。
- Q/KDB+ なら「なぜこのクエリが列指向で速いのか」を知らないと、生成されたクエリの良し悪しが分かりません。
- OCaml なら「なぜ型システムがこのバグを防ぐのか」を理解していないと、その恩恵を活かせません。
つまり、LLM時代に必要なのは「言語の暗記」ではなく「その言語が何を得意とし、なぜ選ばれるのかという設計思想の理解」 です。
本記事が各言語について、「速度のため」「型安全性のため」「時系列のため」と"理由"を説明してきたのは、まさにこの力が、これからより重要になると考えるからです。
新しい言語をスラスラ書けるようになる必要は、以前ほどはありません。しかし「どの問題に、どの言語(と数学)が向いているか」を見抜く目 ―― それこそが、AIに任せきれない、人間の側に残る価値だと、筆者は考えています。
2-11. 次の章への接続
領域①の主役の数学は、確率微分方程式と偏微分方程式でした。
次の第3章では、まったく別の領域、領域②リスク管理に移ります。
ここでは確率微分方程式は脇役になり、統計学・極値理論・コピュラ理論が主役になります。

3. 領域② リスク管理 ―― 統計学・極値理論・コピュラが主役の世界
本章では領域②リスク管理に移ります。主役の数学がガラッと入れ替わり、統計学・極値理論・コピュラ理論が中心になります。
3-1. 第1章での「3つの道具」のおさらい
| 道具 | 起点 | 答えるもの |
|---|---|---|
| VaR | 過去データ | 「過去のパターンが続けば、99%の確率で損失はX以下」 |
| ストレステスト | 仮想シナリオ | 「このシナリオが起きたら、損失はYになる」 |
| リバース・ストレステスト | 「破綻」という結果 | 「破綻するには、どんな複合的シナリオが必要か」 |
これらの道具の裏側で動いている数学を、統計学・極値理論・コピュラ理論の3つに分けて掘り下げます。
3-2. 数学①: 統計学 ―― VaRの基本を支える

VaRの最もシンプルな計算法(ヒストリカル法)は、過去250営業日の損益データから損失分布を推定し、その99パーセンタイルを99% VaRとするものです。
import numpy as np, pandas as pd
pnl = pd.Series([...]) # 過去250営業日の日次損益
loss = -pnl
var_99 = np.percentile(loss, 99)
print(f"99% VaR: {var_99:,.0f} 円")
業務では分散共分散法、モンテカルロVaR、CVaR(Expected Shortfall)などに拡張します。簡単に言うと、それぞれ次のような手法です。
-
分散共分散法 ―― 損益が「きれいな釣鐘型(正規分布)」に従うと仮定して、平均とばらつき(分散)の数値だけからVaRを一発で計算する方法です。計算が速い反面、現実の「裾の厚さ」を捉えきれないという弱点があります。
-
モンテカルロVaR ―― 第2章で出てきたモンテカルロ法をリスク計算に応用したものです。将来の損益のシナリオを乱数で何万通りもシミュレーションし、その結果の分布からVaRを読み取ります。複雑なポートフォリオにも対応できます。
-
CVaR(Expected Shortfall、期待ショートフォール) ―― VaRが「99%の確率で損失はこれ以下」という"境界線"を示すだけなのに対し、CVaRは「その境界線を超えてしまった最悪の1%のとき、平均でいくら損するか」まで踏み込んで答えます。VaRの「最悪の中身が見えない」という弱点を補う指標で、近年の規制でも重視されています。

ここまでは大学初年度の確率統計の延長ですが、問題は正規分布が現実をうまく表現できないときに始まります。
3-3. 数学②: 極値理論(EVT) ―― 「分布の端っこ」だけを精密にモデル化
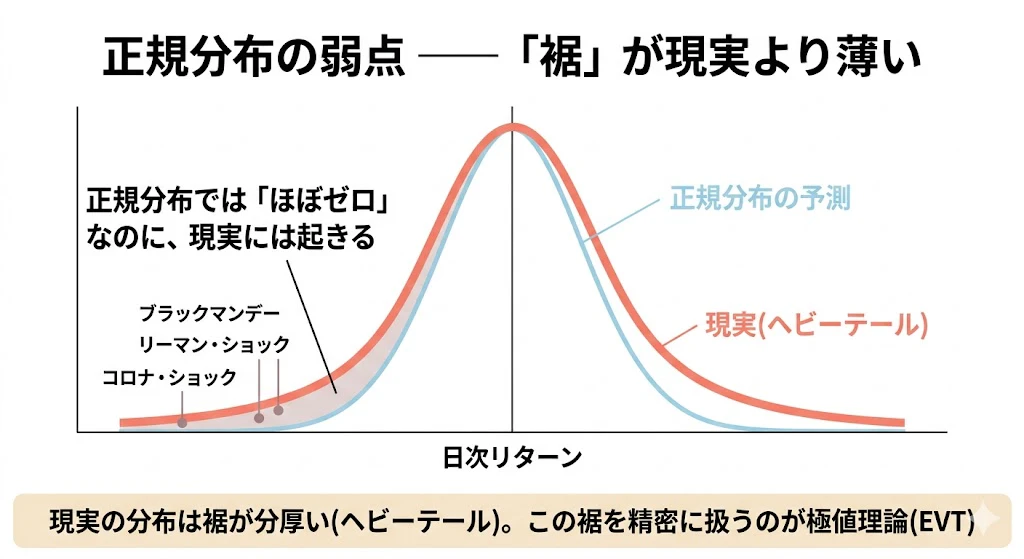
正規分布の最大の弱点は、極端な値が出る確率を過小評価することです。
日経平均を正規分布で近似すると「1日-10%以上の暴落はほぼゼロ」となりますが、現実にはブラックマンデー・リーマン・コロナと複数回起きています。
これは現実の分布の裾(テール)が正規分布より分厚い(ヘビーテール)ことを意味します。
これを扱うのが極値理論(EVT)です。
まず「裾を見る」とは、どういう操作か
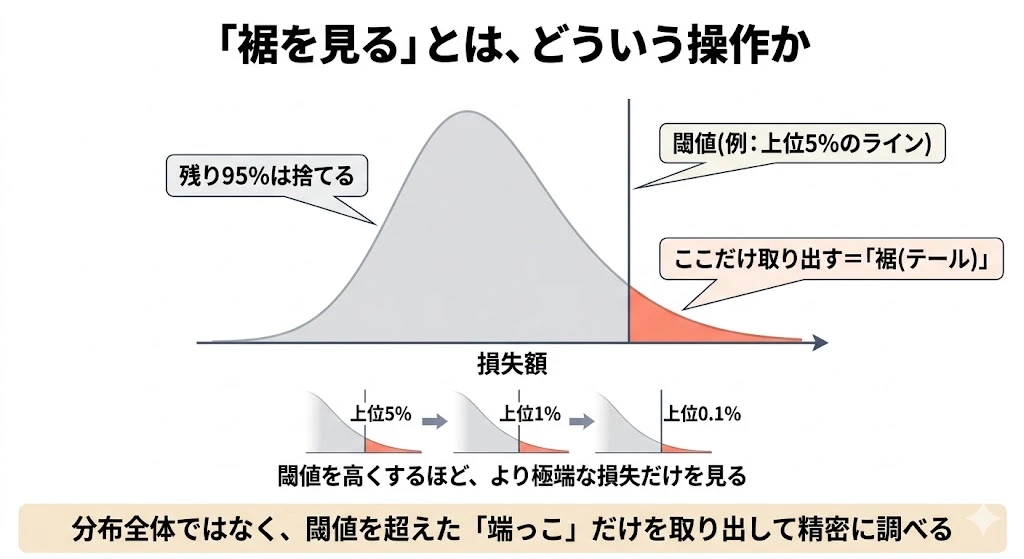
過去1000日分の損失データのうち、損失が大きかった上位5%だけ(ある金額のラインを超えたデータだけ)を取り出します。残りの95%は捨てます。
この「閾値を超えた極端に大きい損失のデータだけ」を集めた集団が「裾」です。
閾値を高くするほど(上位5% → 1% → 0.1%)、より極端な損失だけを見ていることになります。
EVTの中心定理が言っていること
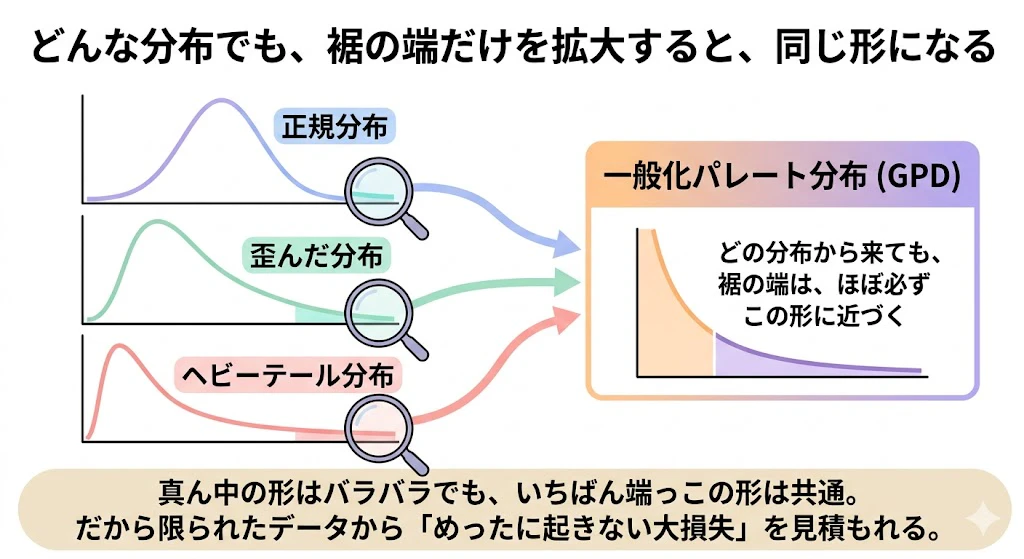
元のデータがどんな分布から来ていようと、閾値を十分に高くして「裾の端」だけを取り出すと、そこに残ったデータは、ほぼ必ず、「一般化パレート分布(GPD)」という、たった2つのパラメータで決まる形 に近づく
-
中心極限定理 : 元がどんな分布でも、たくさん足し合わせると、真ん中が正規分布に近づく
- 極値理論の定理 : 元がどんな分布でも、端っこだけ取り出すと、裾がGPDに近づく(Pickands–Balkema–de Haan の定理)
中心極限定理が「分布の真ん中」を支配する法則なら、極値理論の定理は「分布の端っこ」を支配する法則です。

「一般化パレート分布(GPD)」については、このコラム欄で補足説明をさせていただきます。
🎨 画像生成プロンプト(視覚化①:裾を拡大するとGPDに収束)
📖 コラム: 一般化パレート分布(GPD)とは、どんな分布か
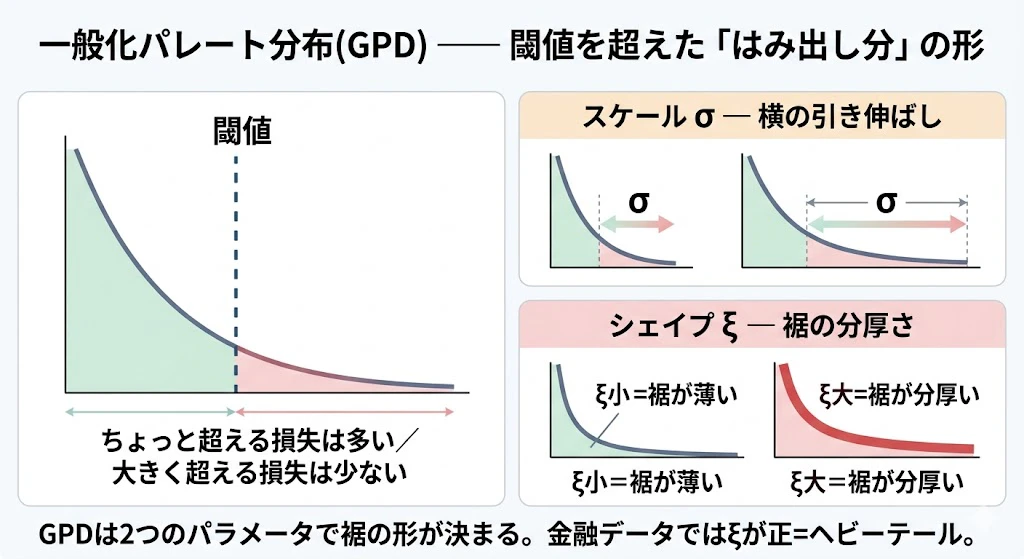
一言で言うと「閾値を超えたはみ出し分の分布」
GPDは、「ある閾値を超えた損失が、その閾値をどれくらい超えるか(はみ出し分の大きさ)」を表す分布です。>
100万円(閾値)をちょっと超えるのはよく起きるが、大きく超えるのはめったに起きない ―― この右肩下がりの減り方の形を表します。
GPDは、たった2つのパラメータで形が決まる
パラメータ 記号 意味(直感) スケール σ はみ出し分の典型的な大きさ。大きいほど損失が全体的に大きく広がる(横の引き伸ばし) シェイプ(形状) ξ 裾の分厚さ。正で大きいほど、桁外れの大損失が出やすい(裾が重い) 特に重要なのがシェイプξです。
ξがゼロに近いと裾は薄め(正規分布に近い)、正で大きいと裾が分厚い(金融危機が起きる世界)。
金融市場のデータにGPDを当てはめるとξはしばしば正になり、これが「現実はヘビーテールだ」ことの数値的裏付けになります。
「パレート」という名前の由来
GPDの「パレート」は、19世紀イタリアの経済学者ヴィルフレド・パレートに由来します。「世の中の富の大部分をごく一部の富裕層が持つ」という偏り(80対20の法則)を発見した人物です。この「ごく一部の極端な値が全体を支配する」偏りの構造が、金融のテールリスクと数学的に同じ形をしているため、パレートの名が冠されています。
※ 次の式は「こういう形で裾の分布を表す」という雰囲気を眺めるだけでOKです。記号の細部を覚える必要はありません。
F(y) = 1 - \left(1 + \frac{\xi y}{\sigma}\right)^{-1/\xi} \quad (\xi \neq 0)
ここで $y$ は閾値を超えた「はみ出し分」、$\sigma$ はスケール(横の引き伸ばし)、$\xi$ はシェイプ(裾の分厚さ)です。細部を覚える必要はありません。大切なのは「閾値を超えたはみ出し分は、$\sigma$ と $\xi$ という2つのつまみだけで形が決まる」という事実です。
なぜこれが嬉しいのか
- データ全体がどんな分布かを当てにいく必要がない
- 閾値を超えた損失データだけを集めて、GPDという決まった形を当てはめるだけでよい
- そのGPDを使えば、まだ起きていないもっと極端な損失(99.9%, 99.95%)も外挿で推定できる
業務イメージのコード(R)
library(POT)
loss <- c(...) # 過去1000日の損失データ
threshold <- quantile(loss, 0.95) # 上位5%のラインを引く
fit <- fitgpd(loss, threshold = threshold) # 裾にGPDを当てはめる
var_995_evt <- qgpd(0.95, loc = threshold,
scale = fit$param["scale"], shape = fit$param["shape"])
print(var_995_evt)
EVTは、オペレーショナル・リスク、巨大自然災害の保険損失、クレジットリスクのテール、規制要求の99.5%/99.9% VaRなどで必須の手法です。
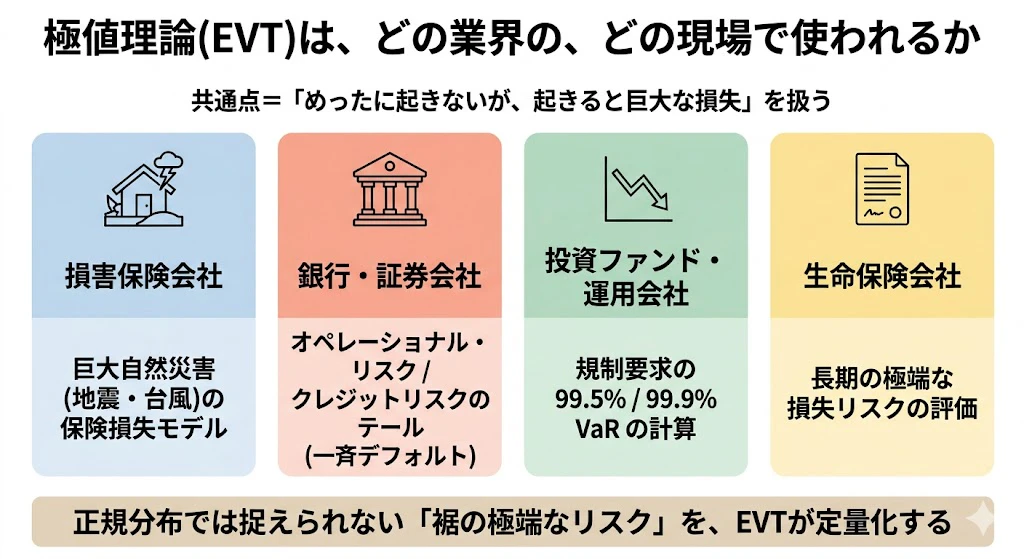
3-4. 数学③: コピュラ理論 ―― 「依存関係」を分布の形と独立に扱う

リスク管理を支える3つ目の数学が、コピュラ理論 です。
統計学(VaRの基本)、極値理論(裾の精密化)に続くこの理論が扱うのは、「複数の資産が、どう連動して動くか」 という問題です。
これまで見てきたVaRやEVTは、どちらかというと「1つの損失分布」を相手にしていました。
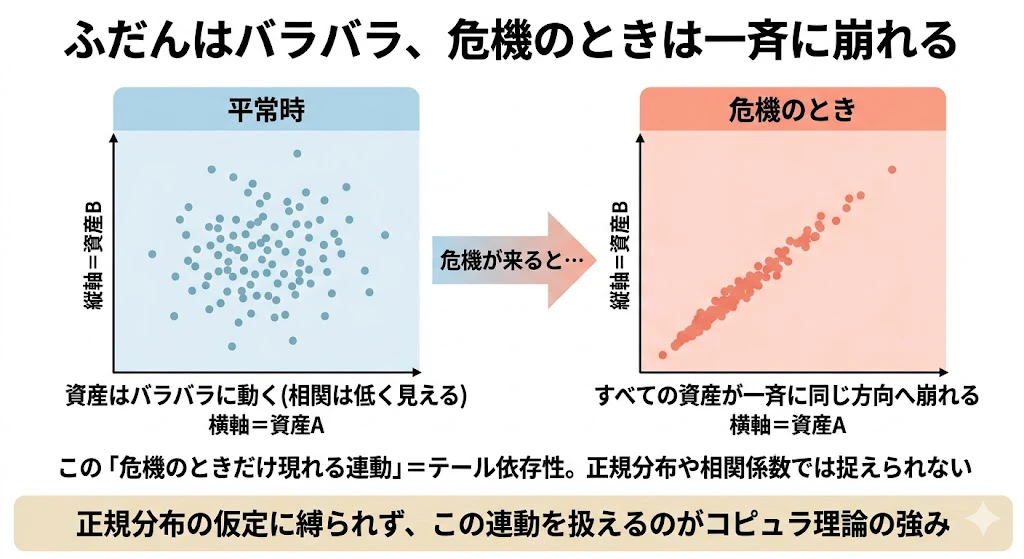
しかし現実のポートフォリオは、何百もの資産が絡み合っています。
そして金融危機でいちばん怖いのは、「ふだんはバラバラに動いていた資産が、危機のときに一斉に同じ方向へ崩れる」 という現象です。
この「資産同士の連動」を、正規分布の仮定に縛られずに扱えるのが、コピュラ理論の強みです。
少し変わった名前なので、まずはこの「コピュラ」という言葉そのものから見ていきましょう。
📖 コラム: 「コピュラ」とは不思議な響きの単語ですが…
コピュラ(copula)は、ラテン語の copula ―― 「結びつけるもの、絆、つなぎ目」に由来します(co-=一緒に + apere=繋ぐ)。英語のcouple(カップル)も同じ語源の双子の単語です。
実は「コピュラ」は1560年代から英語の文法用語でもあります。"The sky is blue." の is のように、主語と補語を結びつける動詞(連結動詞、繋辞)のことです。日本語の「である」「だ」も同じ働きをします。
統計学にこの語が登場したのは1959年。フランスの数学者アブ・スクラーが、複数の確率変数の周辺分布を「結びつけて」同時分布を作る関数に「コピュラ」と名付けました。ラテン語の原義に忠実な命名です。
「2つ以上のものを結びつける」という原義を頭の片隅に置くと、理論の全体像が頭に入りやすくなります。
問題の出発点と古典的アプローチの限界
実際のポートフォリオは数百〜数千の資産から成り、互いに完全には独立していません。
例えば、株式が下落すると社債も下落しやすい等です。
最も素朴な依存関係の指標は相関係数ですが、線形な関係しか測れない、正規分布が暗黙の前提、テール部分の依存を捉えにくい、という限界があります。
特に、「平常時は無相関だが、暴落時には一緒に下落する(テール依存性)」という金融市場の現実を、相関係数は捉えられません。
コピュラの考え方
複数の変数の同時分布は、各変数の周辺分布と、変数間の依存関係(=コピュラ)に分解できる (Sklarの定理, 1959年)
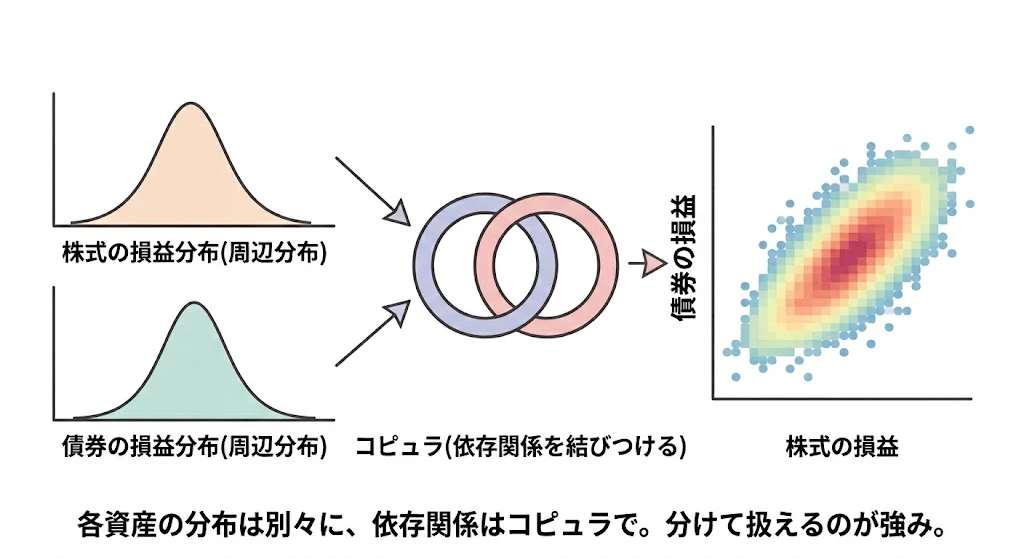
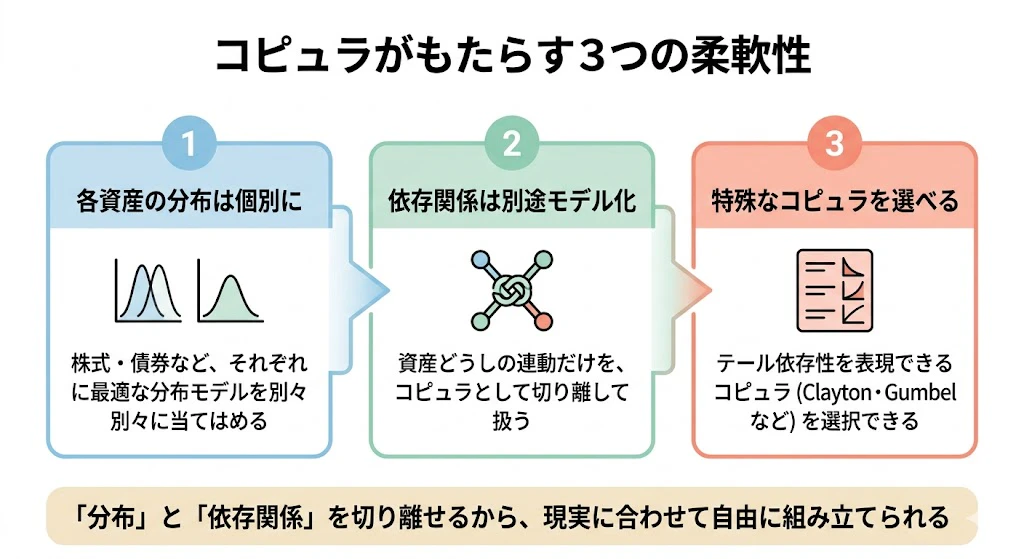
これにより、各資産の損益分布は個別に最適なモデルで表現し、依存関係はコピュラとして別途モデル化し、テール依存性を表現できる特殊なコピュラ(Clayton, Gumbel等)を選べる、という柔軟性が得られます。
| コピュラの種類 | 特徴 | 用途 |
|---|---|---|
| ガウス・コピュラ | 正規分布ベース。テール依存性なし | 入門・初期実務(限界あり) |
| t-コピュラ | t分布ベース。テール依存性あり | 株式ポートフォリオの相関 |
| クレイトン・コピュラ | 下方テール(同時下落)に強い依存性 | 危機時相関 |
| ガンベル・コピュラ | 上方テール(同時上昇)に強い依存性 | バブル相場の同時上昇 |
テール依存性「あり」と「なし」 ―― 使う数学は同じなのか?
ここで、多くの人が抱く疑問に答えておきます。
「テール依存性を表現できるコピュラ(Clayton・Gumbelなど)と、できないコピュラ(ガウス・コピュラ)は、使っている数学が根本的に違うのか?」という問いです。
答えを申し上げると、「枠組み(数学の土台)は同じです。違うのは、その中で選ぶ"関数の形"だけです」 という結論になります。
どういうことか、順を追って説明します。
まず、すべてのコピュラは Sklarの定理という同じ土台 の上に立っています。
「周辺分布と依存関係を分離する」という考え方も、「コピュラ関数で資産を結びつける」という枠組みも、全コピュラで共通です。
ここまでは、どのコピュラも同じ数学です。
違いが生まれるのは、「結びつけるための関数」として、どんな形のものを選ぶか という一点です。
-
ガウス・コピュラ は、正規分布(多変量正規分布)を土台にした関数を使います。正規分布は、中心から離れるほど急速に確率がゼロに近づくため、「両方の資産が同時に大暴落する」という極端な同時現象を、構造的にほぼ起こさない形になっています。これがテール依存性「なし」の正体です。
-
Clayton・Gumbelコピュラ は、アルキメデス・コピュラと呼ばれる別系統の関数を使います。これらは、片方の裾(下落側、または上昇側)で、資産が一斉に連動する確率が消えずに残るように設計された関数です。これがテール依存性「あり」の正体です。
つまり、同じ「コピュラ」という建物の中で、どの"間取り(関数形)"を選ぶかが違うだけ です。
土台(Sklarの定理)は共通でも、選ぶ関数によって「危機時に一斉崩落を表現できるかどうか」が決まる。

2008年の悲劇は、よりによってテール依存性のない「ガウス・コピュラ」を、住宅ローンという"危機時にこそ一斉に崩れる"商品に使ってしまったことに、本質がありました。

歴史的事件: 「ウォール街を壊した式」
コピュラ理論は2008年サブプライムショックの戦犯のひとつとして有名になりました。
住宅ローン担保証券(MBS)・CDOの値段付けにガウス・コピュラが広く使われましたが、ガウス・コピュラにはテール依存性がないため、危機時の同時下落を表現できず、リスクが構造的に過小評価されました。
事件後、Wired誌は2009年に「ウォール街を殺した式」という記事でDavid X. Liの名を広めました。
現代ではt-コピュラやアルキメデス・コピュラへの移行が進んでいます。
数学的に一言でまとめると、2008年に壊れたのは**「正規分布近似が、テール依存と極端な相関を捉えられなかった」** という一点に集約されます。
平常時のデータから推定した相関は低く見えるのに、危機が来ると全資産が一斉に同じ方向へ動く
―― この「テールでだけ現れる依存」を、正規分布ベースのモデル(ガウス・コピュラ)は構造的に表現できなかったのです。
第3章でEVT(極値理論)とコピュラを導入したのは、まさにこの弱点を克服するためでした。
「テールを精密に見るEVT」と「テール依存を表現できるコピュラ」は、2008年の教訓そのものから必然的に要請される道具なのです。
📖 コラム: コピュラは「金融クオンツ専用」のニッチな数学なのか?
ここまで読んで、こう思った方がいるかもしれません。
「複数の事象の連動を扱えるコピュラは、便利そうだ。
でもこれは、投資銀行やファンドのクオンツだけが使う、金融専用のニッチな数学なのだろうか?それとも、総合商社・エネルギー・半導体・建設など他業界のリスク管理や、リスク管理以外のデータ分析でも使えるのだろうか?」
結論から言うと、コピュラは金融専用ではありません。
むしろ、 「複数の変数の連動を、分布の形に縛られず柔軟に扱える」という性質から、分野を問わず使われる汎用的な道具 です。
コピュラの本質は「金融」ではなく「複数の不確実な量が、どう連動して動くか」を扱うことにあります。だから、そういう問題があるところには、どこでもコピュラが現れます。実際の応用例を挙げてみましょう。
水文・防災 ―― 雨量と継続時間、波の高さと高潮など、複数の気象・水文変数の同時分布をモデル化し、洪水・氾濫の予測やダム・防波堤の設計に使われます。「大雨と高潮が同時に起きる確率」はまさにテール依存性の問題です。
保険・再保険 ―― ハリケーンと洪水のように、複数の災害(ペリル)が同時に起きる依存関係をモデル化し、巨大災害保険の保険料算定に使われます。生命保険でも、夫婦など複数人の余命の連動を扱う「連生保険」の価格付けに使われます。
信頼性工学 ―― 電力網や航空機エンジンのような複雑なシステムで、複数の部品が連鎖的に故障する依存関係をモデル化し、故障率の評価や保守計画の最適化に使われます。
エネルギー・環境 ―― 電力需要と気温、複数地域の風力発電量の連動、熱波と干ばつの同時発生など、エネルギー需給や気候リスクの分析に使われます。
機械学習 ―― 変数間の複雑な依存構造を捉える手法として、近年は機械学習の分野でも応用が広がっています。
つまり、総合商社が複数のコモディティ価格の連動リスクを評価する、エネルギー企業が需要と気象の連動を分析する、製造業が複数部品の同時故障リスクを見積もる ―― こうした業務は、いずれもコピュラが活きる典型的な場面です。
データサイエンティストにとってのコピュラの価値は、「相関係数では捉えられない、変数どうしの複雑な(特に危機時の)連動を、定量的に扱える」という一点にあります。
これは金融に限らず、複数の不確実性が絡むあらゆるリスク評価・需要予測・異常検知に応用できる、汎用的な武器 なのです。
金融でとりわけ有名になったのは、2008年の事件のインパクトが大きかったからにすぎません。コピュラ自体は、もっと広く世界で使われている数学です。

3-5. リスク管理 vs デリバティブ値段付け ―― 数学の役割の違い

| 観点 | 領域①: 値段付け | 領域②: リスク管理 |
|---|---|---|
| 問題の性格 | 「正しい値段はいくらか」 | 「最悪どこまで損するか」 |
| 出発点 | 株価のSDE | 損益データの実分布 |
| 主役の数学 | SDE、PDE、マルチンゲール理論 | 統計学、極値理論、コピュラ理論 |
| 計算の目的 | 期待値の計算 | 分位点(テール)の推定 |
| 使う言語(本番) | C++、Python、KDB+ | Python、R、SAS |
領域①は「期待値」を、領域②は「テール(分位点)」を計算する
期待値は分布の真ん中、テールは分布の端っこです。
同じ確率論を使っていても、見ている場所が違うのです。
3-6. 業界の言語・ツール選択
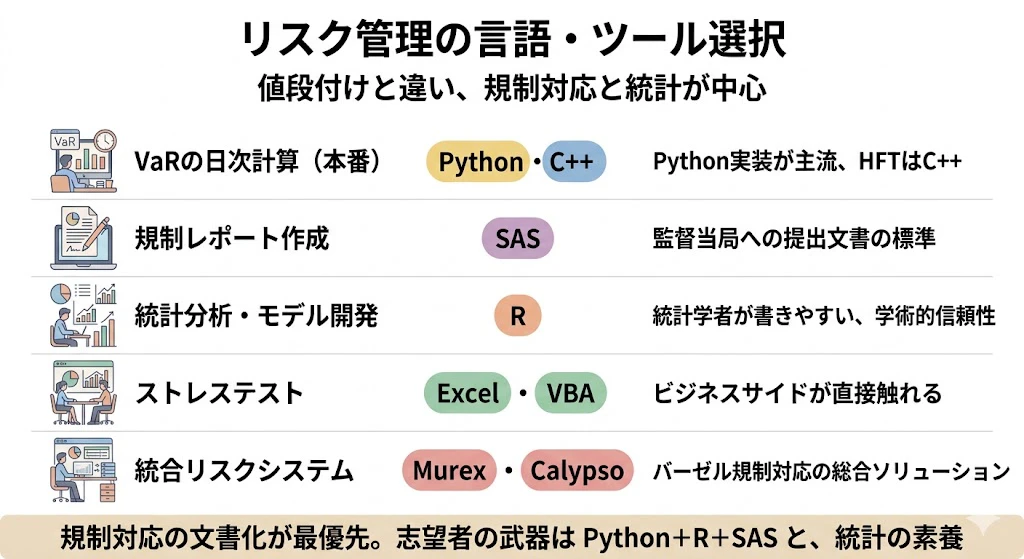
| 業務シーン | 主に使われる言語・ツール | 選ばれる理由 |
|---|---|---|
| VaRの日次計算(本番) | Python(社内ライブラリ)、C++ | Python実装が主流、HFTはC++ |
| 規制レポート作成 | SAS, SAS Risk Management | 監督当局への提出文書の標準 |
| 統計分析・モデル開発 | R(POT, copula, evd) | 統計学者が書きやすい、学術的信頼性 |
| ストレステスト | Excel+VBA, @RISK | ビジネスサイドが直接触れる |
| 統合リスクシステム | Murex, Calypso, Algorithmics | バーゼル規制対応の総合ソリューション |
リスク管理の言語選択は、規制対応の文書化が最優先で、監査ログ・トレーサビリティの高いツール(SAS, Murex)が選ばれやすい点が特徴です。
統計の専門家が多いためRやSASに馴染みがあります。
リスク管理志望者には、Python+R+SASの3点セットと、統計学の素養(ヘビーテール分布、コピュラ、生存分析)、規制を理解する力が武器になります。
補足①: Murex・Calypso・Algorithmics とは何か(金融機関向けの商用システム)
これらは、これまで紹介してきた Python・R・SAS のようなプログラミング言語やライブラリとは性質が異なり、金融機関向けに作られた大規模な商用ソフトウェア(エンタープライズ・パッケージ) です。
個人が趣味で触るものではなく、銀行・証券会社・資産運用会社などが組織として導入する、業務システムそのものです。
- Murex(ミューレックス) ―― フランス・パリ発の企業が開発する、資本市場向けの統合プラットフォーム(主力製品は「MX.3」)。トレーディング・リスク管理・決済・会計までを一つのシステムで扱えるのが特徴で、世界60か国以上、6万人以上が日々利用しています。銀行から商社・エネルギー企業まで幅広く導入されています。
- Calypso(カリプソ) ―― Murex の直接の競合にあたる、同種の統合型プラットフォーム。トレーディングからバックオフィス(決済・処理)まで一気通貫で扱えます。現在は Nasdaq 傘下に入り、規制対応機能を統合した製品群の一部になっています。
- Algorithmics(アルゴリズミクス) ―― リスク管理に特化したシステムとして知られ、特にバーゼル規制対応のリスク計算で広く使われてきました。
これらは金融機関しか使わないのか、料金はいくらか?
基本的に、これらは銀行・証券・資産運用といった金融機関(および商社・エネルギーなど大規模に市場取引を行う事業会社)が導入するものです。一般的なデータサイエンティストが個人で触れる機会は、まずありません。
料金は 完全に非公開 で、定価は存在しません。導入する機能の範囲・利用ユーザー数・取引規模などに応じた個別見積もり(モジュール式の価格設定)が基本です。一般には公表されていませんが、こうしたシステムは導入・カスタマイズ・保守を含めると、年間で数千万円から、大規模行では数億円規模に達することもある と言われる世界です(正確な金額は契約ごとの非公開情報です)。
なぜこれほど高額でも使われるのか。それは、自前で同等のシステムを開発・保守し、かつ各国の規制対応を常に最新に保つコストのほうが、はるかに高くつく からです。「車輪の再発明をせず、規制対応済みの実績あるシステムを買う」という、QuantLib のところで触れたのと同じ判断が、ここでも働いています。
補足②: SASはまだ使われているのか? ―― Pythonに駆逐されないのか?
「Python全盛のいま、SASはもう古いので? かつてMathematicaが存在感を失ったように、いずれ駆逐されるのでは?」 ―― これは、とても自然な疑問です。
結論を先に言うと、SASは確かに勢いを失いつつありますが、「規制が絡む業界」では、いまも生き残っています。 Mathematicaのケースとは、少し事情が異なります。
まず、技術的な人気という点では、SASは明確に後退しています。
開発者アンケートや学習人気のランキング(Kaggle、Stack Overflow、TIOBEなど)では、PythonやRがSASを4倍〜8倍以上引き離しています。
新しくデータ分析を学ぶ人が、わざわざ高価なSASから始めることは、いまやほとんどありません。スタートアップや学術界は、ほぼ完全に無償のPython・Rへ移行しました。
それでも、SASが特定の業界で生き残っているのには、明確な理由があります。
- 規制当局がSASを"標準"として受け入れてきた歴史 ―― 銀行のリスク報告や、製薬の臨床試験データ(FDA・EMA・PMDAなどへの提出)では、長年SASが事実上の標準でした。規制当局自身がSASの出力に慣れているため、「SASで出す」ことが安全な選択になります。
- 検証済み(バリデート済み)であることの価値 ―― 金融や製薬では、「そのコードが正しく動くこと」を証明する責任があります。SASは数十年の実績があり、結果が信頼される"既知の存在"です。Pythonは自由な反面、ライブラリの正しさを自分で証明する負担が残ります。
- 20年分の既存資産 ―― 大手銀行・製薬会社・政府機関には、何十年も積み上げたSASのコード資産があります。動いているものを書き直すリスクとコストは、莫大です。
つまり、SASが残っているのは「技術的に優れているから」というより、「規制対応の文書化と、検証済みであることの信頼性」という、金融・製薬に特有の事情 によるものです。
リスク管理がSASを使い続けるのは、まさにこの理由からです。
ただし、SAS自身も手をこまねいているわけではありません。
近年は、SAS環境の中からPythonやRを呼び出せるように製品を刷新しています(クラウド対応の「SAS Viya」など)。
つまり今後は「SAS か Python か」ではなく、「規制対応の土台はSAS、分析や自動化はPython」という共存 が、当面の現実的な姿になりそうです。
Mathematicaが汎用計算ツールとしての地位をPython(NumPy・SymPy)に明け渡したのに対し、SASは「規制という堀(モート)」に守られて、特定の領域に立てこもって生き残っている ―― そう理解すると、両者の違いが見えてきます。
3-7. 領域② でリスクマネージャーが日々やっていること

日次VaRの計算と報告・リスク限度額の監視・モデル検証・ストレステストの設計と実行・規制対応・新商品のリスク評価・危機対応、などです。
3-8. 次の章への接続
領域②の主役の数学は、統計学・極値理論・コピュラ理論でした。
データ駆動・テール志向・多変量の依存性が特徴です。
次の第4章では領域③ ポートフォリオ最適化に移り、最適化理論・凸解析・確率制御という新しい主役の数学を見ていきます。
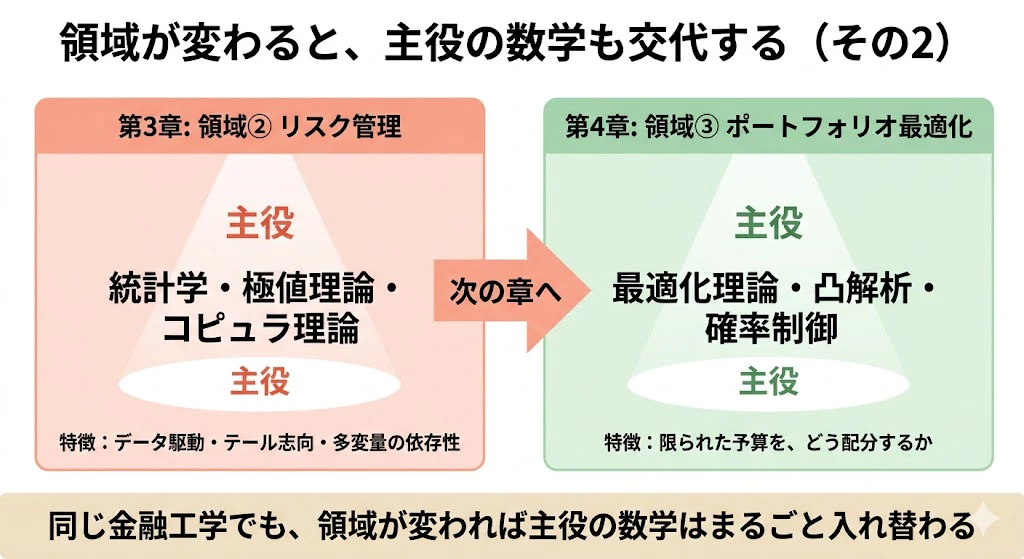
4. 領域③ ポートフォリオ最適化 ―― 最適化理論・凸解析が主役の世界
本章は領域③ポートフォリオ最適化です。主役の数学は、最適化理論・凸解析・確率制御になります。
この領域の数学は、実は、データサイエンティストの皆さまにお手元か、すぐそばにある数学です
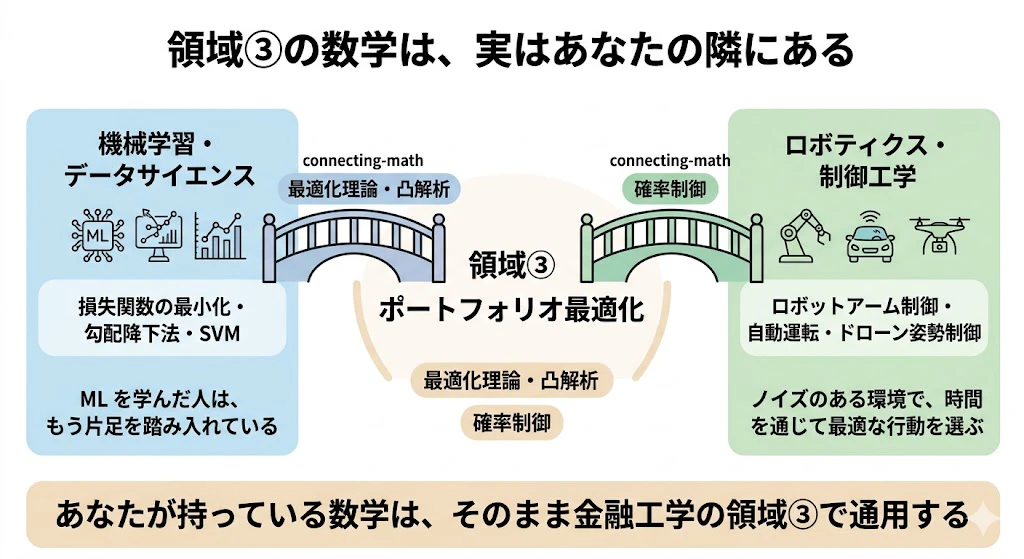
ここで、データサイエンティストの皆様にとって、おそらくは、吉報となるお知らせがあります。
そのお知らせとは、領域③の主役である最適化理論・凸解析は、多くのデータサイエンティストが、すでに知っている数学 である、ということです。
機械学習のモデルを学習させるとき、私たちは「損失関数を最小化する」ことをやっています。
あの勾配降下法も、ロジスティック回帰も、サポートベクターマシンも、本質は「ある関数を最小化する最適化問題」です。
特に、凸最適化は、機械学習の理論的な土台そのものです。
つまり、機械学習を学んだ人は、ポートフォリオ最適化の数学に、すでに片足を踏み入れている のです。
マーコウィッツの平均分散最適化は、いわば「資産という名の特徴量に対する、制約つき最適化問題」だと思えば、すっと頭に入ります。
そしてもう一つ。
領域③のもう一人の主役である確率制御は、ロボティクスや制御工学のエンジニアにとって、おなじみの数学 です。
ロボットアームが、不確実なセンサー情報をもとに、次にどう動くかを最適に決める
―― この「ノイズのある環境で、時間を通じて最適な行動を選び続ける」という問題は、まさに確率制御そのものです。
自動運転の経路計画、ドローンの姿勢制御、強化学習の理論的背景にも、確率制御(特にベルマン方程式やハミルトン・ヤコビ・ベルマン方程式)が顔を出します。
つまり、後で出てくる「動的なポートフォリオ最適化」で、資産配分を時間を通じて最適に調整し続ける という問題は、ロボットが刻々と動きを最適化するのと、数学的には同じ構造をしているのです。
機械学習の最適化を知っている人、ロボティクスの制御を知っている人 ―― あなたの持っている数学は、そのまま金融工学の領域③で通用します。
4-1. この領域が解こうとしている問題
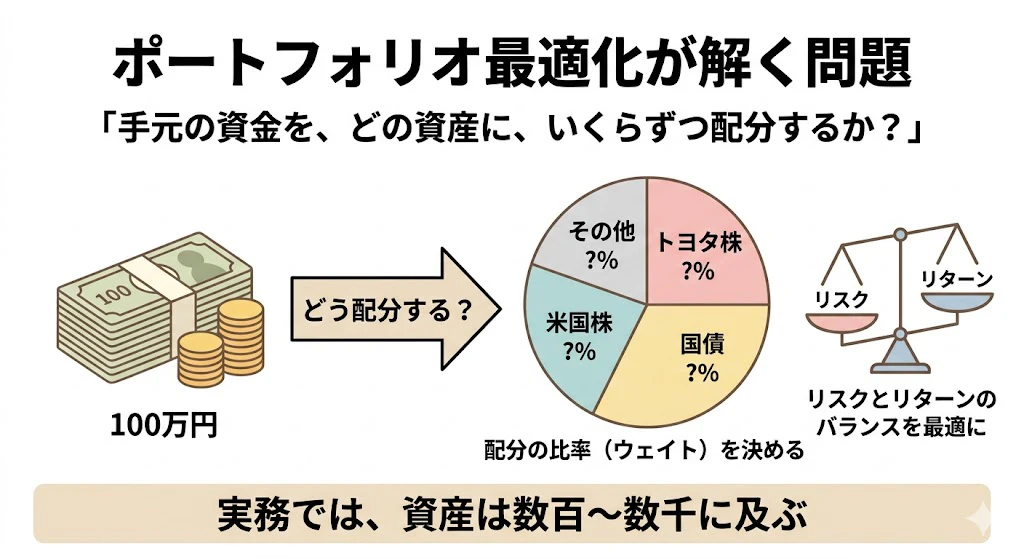
「手元の資金を、どの資産に、いくらずつ配分すれば、いちばん『得』なのか?」
100万円を、トヨタ株に何%、国債に何%、米国株に何%、と配分すれば、リスクとリターンのバランスが最適になるか。この配分の比率(ウェイト)を決めるのがポートフォリオ最適化です。
実務では資産が数百〜数千に及びます。
4-2. マーコウィッツの平均分散最適化 ―― すべての出発点

1952年、ハリー・マーコウィッツは、「リターンの期待値だけでなく、リターンのばらつき(分散)も同時に考えて配分を決めるべきだ」という革命的なアイデアを提示しました。
これを平均分散最適化と呼びます。
最大の貢献は、「卵を1つのカゴに盛るな(分散投資せよ)」という格言を数学的に裏付けたことです。
ポイントは資産同士の相関で、相関の低い資産を組み合わせると、リターンを犠牲にせずにリスクだけを下げられるという、いわばフリーランチが存在することを数式で示しました。
マーコウィッツはこの業績で1990年にノーベル経済学賞を受賞しました。
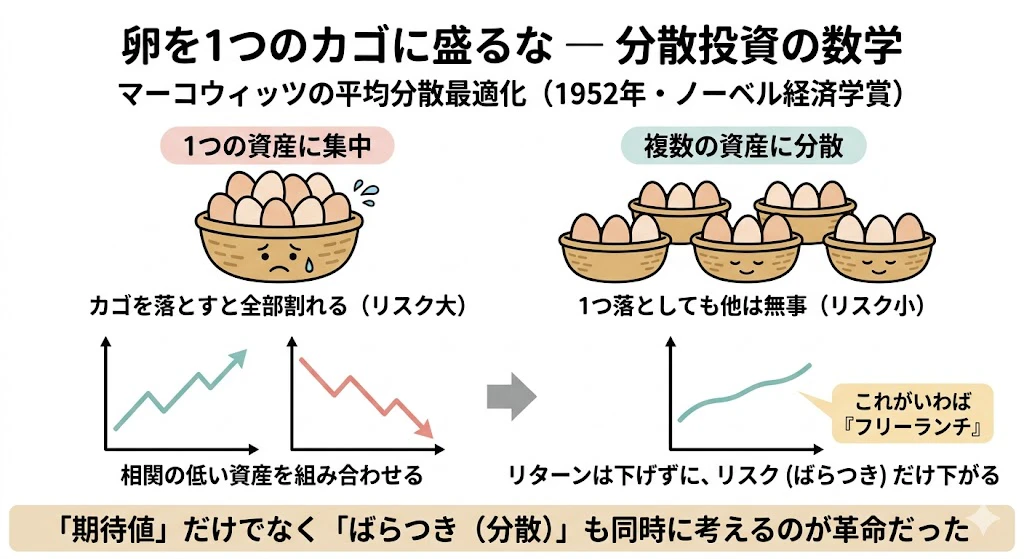
4-3. 数式で見る平均分散最適化(読み飛ばし可)

ポートフォリオのリスクを最小化する問題は、次のように書けます。
※ 次の式は「こういう形で最適化問題を書く」という雰囲気を見るだけでOKです。記号の意味は式の下で説明します。
\min_{w} \; w^T \Sigma w \quad \text{s.t.} \quad w^T \mu = R, \; w^T \mathbf{1} = 1
ここで $w$ は各資産への配分比率(求めたい答え)、$\Sigma$ は分散・共分散行列(リスクと相関の情報)、$\mu$ は各資産の期待リターン、$R$ は投資家が目標とするリターンです。
この問題は凸二次計画問題(convex quadratic programming)という、数学的にとてもきれいな形をしています。

4-4. 「凸最適化」とは何か ―― この領域の心臓部
📖 コラム: 「凸(とつ)」最適化とは何か
凸とは「お椀の形」のこと
凸関数とは、ひとことで言うとお椀(ボウル)のような形をした関数です。
お椀の内側にビー玉を入れて手を離すと、どこから転がしても必ずお椀のいちばん底で止まります。
凸最適化とは、まさにこの「お椀の底を見つける」問題です。
なぜ「お椀の形」だと嬉しいのか
凸でない(デコボコした)関数だと、本当はもっと深い谷(本当の最適解)があるのに、手前の浅いくぼみ(偽物の最適解)にはまって止まることがあります。これを局所最適にはまると言います。
お椀の形ならくぼみは1つしかないので、見つかった底は必ず本当の底(大域最適)であることが数学的に保証されます。
凸であることのご利益
必ず最適解にたどり着ける(局所最適にはまらない)/高速に解ける/解が1つに定まる ―― この3つです。マーコウィッツの平均分散最適化が偉大なのは、ポートフォリオ選択という現実の問題を、この「お椀の形(凸二次計画問題)」に落とし込んだ点にあります。逆に複雑な制約を加えると問題が凸でなくなり、途端に解くのが難しくなる ―― これが実務家が日々向き合う難しさです。
ところで、機械学習を学んだ読者は、ここで「あれ?」と思うかもしれません。
「ディープラーニングの損失関数は、お椀のようなきれいな凸の形ではない。
デコボコの非凸な地形のはずだ。それなのに、なぜ学習がうまくいくのか?」と。
これは非常に良い問いで、ポートフォリオ最適化(凸)とディープラーニング(非凸)の、面白い対比になります。
ポートフォリオ最適化は「お椀=凸」だから確実に底にたどり着けるのに対し、ディープラーニングは「デコボコ=非凸」で、本来なら無数の偽物の底(局所最適)にはまるはず です。
実際、最適化理論の常識からすれば、あの巨大なニューラルネットが学習できること自体、不思議なくらいです。
ではなぜ、ディープラーニングはうまくいくのか。
近年の研究で見えてきたのは、おおむね次のような事情です。
-
超高次元では、そもそも「悪い局所最適」が驚くほど少ない
―― パラメータが何百万・何億とある高次元空間では、「あらゆる方向から見て谷底」という真の局所最適は、めったに存在しません。
多くの停留点(勾配がゼロになる点)は、ある方向には谷でも別の方向には下り坂が続く「鞍点(あんてん、saddle point)」であり、抜け出せるのです。
-
確率的勾配降下法(SGD)の"ノイズ"が、罠から脱出させる
―― ミニバッチごとに勾配がランダムに揺れること(ノイズ)が、かえって浅いくぼみや鞍点から抜け出す助けになります。「いいかげんさ」が、結果的に探索を助けているのです。
-
そもそも地形を"良性"にする工夫を積み重ねている
―― 適切な初期値、バッチ正規化、残差接続(ResNet)、学習率の調整といった、ディープラーニングの数々のテクニックは、見方を変えれば「非凸な地形を、できるだけお椀に近い扱いやすい地形に整える」工夫の集積でもあります。
つまり、ポートフォリオ最適化が「最初からお椀という恵まれた地形を、数学的に保証されて解いている」のに対し、ディープラーニングは「本来デコボコな地形を、高次元の性質・ノイズ・無数の工夫で、なんとか乗りこなしている」と言えます。
同じ「最適化」でも、凸という安全地帯にいるか、非凸という荒野を工夫で進むか
―― この違いが、両者の難しさの本質的な差なのです。
マーコウィッツのポートフォリオ最適化が「お椀(凸)」であることのありがたみは、ディープラーニングの非凸な地形での苦労を知っている人ほど、深く実感できるはずです。

さて。次の「4-5」節に入ります。
ファイナンス業務の議論に話を戻します。
4-5. 業務イメージのコード(Python / CVXPY)
理論が分かったところで、実際にこの最適化問題をコードで解いてみましょう。
ありがたいことに、凸最適化には、数式をほぼそのままの形で書けば自動で解いてくれる便利なライブラリがあります。
その代表が、Pythonの CVXPY です。先ほどの「リスクを最小化する」という数式を、ほとんど数式の見た目のままコードに落とせるのが特徴です。
ここでは、3つの資産(株式・社債・国債)に資金を配分する、最小限の例を見てみましょう。
「目標リターンを達成しつつ、リスク(分散)を最小にする配分」を求めます。
import cvxpy as cp
import numpy as np
mu = np.array([0.10, 0.07, 0.03]) # 株式10%, 社債7%, 国債3%
Sigma = np.array([[0.040, 0.006, 0.000],
[0.006, 0.020, 0.001],
[0.000, 0.001, 0.005]])
w = cp.Variable(3)
target_return = 0.06
problem = cp.Problem(
cp.Minimize(cp.quad_form(w, Sigma)),
[mu @ w == target_return, cp.sum(w) == 1, w >= 0])
problem.solve()
print(f"最適な配分比率: {w.value}")
業務では数百〜数千資産へのスケールアップ、現実的な制約、ロバスト最適化、目的関数の変更(CVaR最小化等)などの拡張を加えます。
4-6. 平均分散最適化の弱点と、その先

ここまでマーコウィッツの平均分散最適化を、いわば「すべての出発点」として紹介してきました。
実際、その発想(リターンとリスクを同時に考える)は、いまも生きています。
しかし、1952年に生まれたこの古典には、実務で利用するに際して、無視できない弱点があることも、その後の研究で明らかになってきました。
「出発点」ではあっても、「終着点」ではないのです。
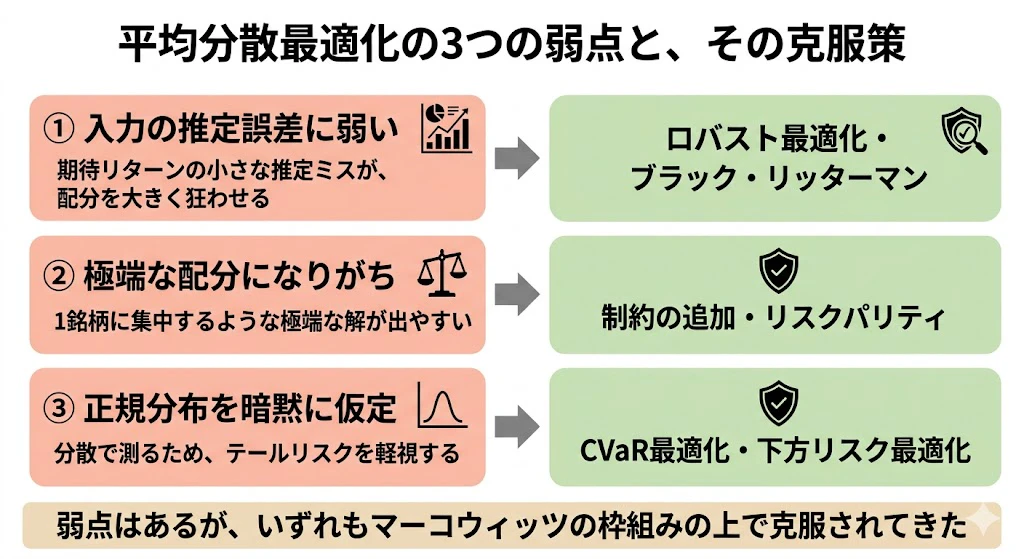
主な弱点は、次の3つです。
| 弱点 | 内容 | 実務での対応 |
|---|---|---|
| 入力の推定誤差に弱い | 期待リターンの小さな推定ミスが配分を大きく狂わせる | ロバスト最適化、ブラック・リッターマン |
| 極端な配分になりがち | 1銘柄集中のような極端な解が出やすい | 制約の追加、リスクパリティ |
| 正規分布を暗黙に仮定 | 分散で測るためテールリスクを軽視 | CVaR最適化、下方リスク最適化 |
発展形として、ブラック・リッターマンモデル(市場均衡と投資家の見通しをベイズ的に統合)、リスクパリティ(各資産がリスクを等しく分担、年金基金で人気)、CVaR最適化(テールリスクを直接最小化)などがあります。
4-7. 動的なポートフォリオ最適化 ―― 確率制御の登場
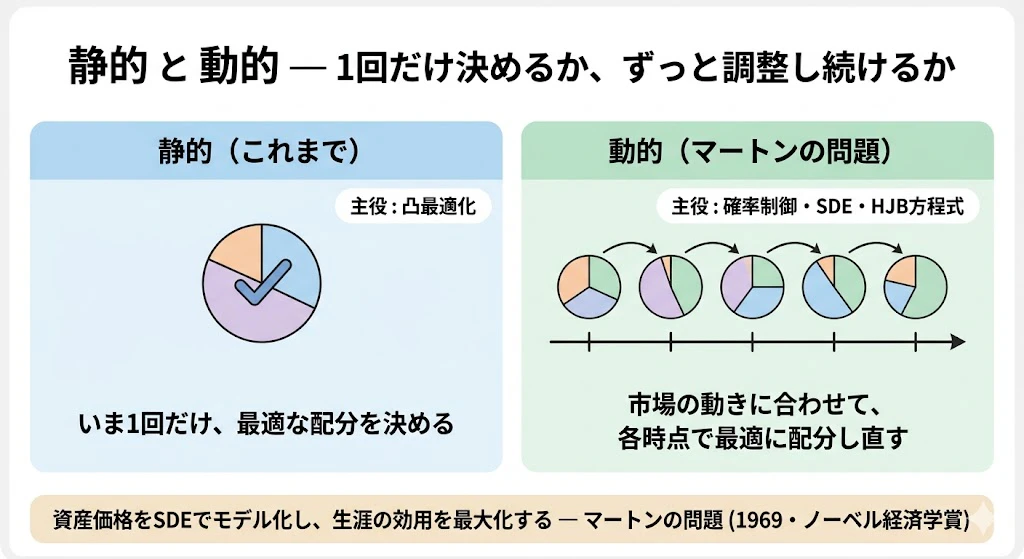
ところで、ここまでは「いま、1回だけ配分を決める」静的な問題でした。
現実には市場が動き、ポートフォリオを継続的にリバランスする必要があります(動的ポートフォリオ最適化)。
ここで第2章のSDEが再登場します。
1969年、ロバート・マートンは「時間を通じて消費と投資をどう最適に配分するか」(マートンの問題)を確率制御で解きました。
資産価格をSDEでモデル化し、生涯の効用を最大化する目標のもとで、各時点の最適投資比率を確率制御で導きます。
このとき登場するのがハミルトン・ヤコビ・ベルマン方程式(HJB方程式)です。マートンは1997年にノーベル経済学賞を受賞しました。
つまりポートフォリオ最適化は、静的に解けば最適化理論・凸解析の世界、動的に解けば確率制御・SDE・PDEの世界(領域①と再会する)、という2つの顔を持っています。

こおで、いま、見逃せないことが起きました。
第2章で「領域①(値段付け) の主役」として登場した確率微分方程式(SDE)が、ここ領域③(ポートフォリオ最適化)の動的な問題を解く場面で、ふたたび姿を現したのです。
別の領域で主役だったはずの数学との、思いがけない再会 です。
この「再会」は、ただの偶然ではありません。実は、本記事全体を貫く大事なことを示しています。
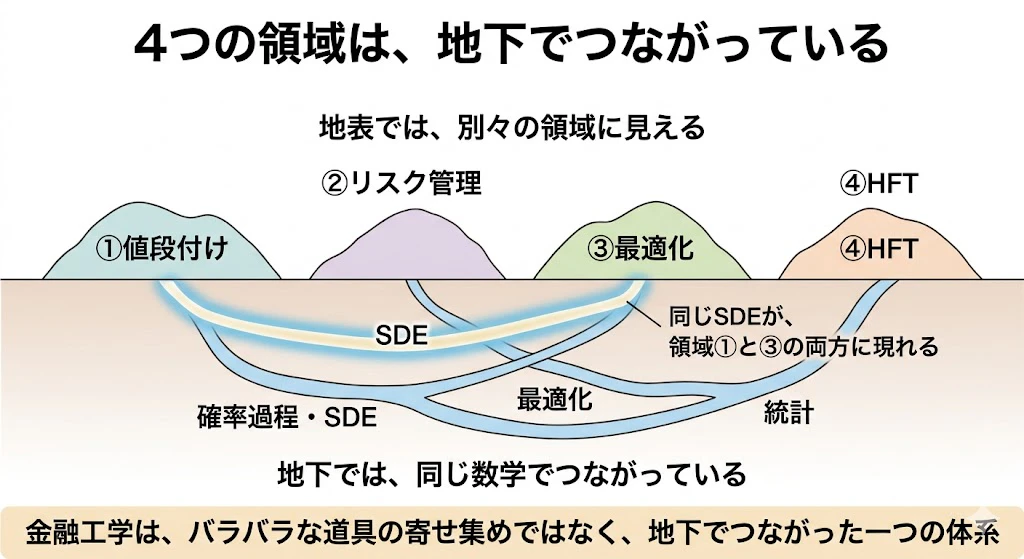
「再会」が意味すること ― 4つの領域は、地下でつながっている
ここで起きた「再会」は、実はこの記事全体を貫く、大事なことを示しています。
本記事では、金融工学を4つの領域(①値段付け、②リスク管理、③最適化、④HFT)に分けて、「領域ごとに主役の数学が違う」と説明してきました。これは事実です。
しかし、4つの各領域は、相互に壁で完全に仕切られているわけではなく、地下では同じ数学でつながっている のです。
その証拠が、いま起きた再会です。
確率微分方程式(SDE)は、領域①(デリバティブ値段付け)の主役でした。
ところが、領域③(ポートフォリオ最適化)を「動的に」解こうとした瞬間、同じSDEが、別の領域の住人として再び姿を現したのです。
これは偶然ではありません。
「将来が不確実な中で、最適な判断を時間を通じて下し続ける」という構造を持つ問題は、それが値段付けであれ、資産配分であれ、根っこで同じ数学(確率過程・確率制御)に行き着くからです。
つまり、4つの領域は、地表では別々の国に見えても、地下水脈でつながった一つの大陸のようなものなのです。
ある領域で学んだ数学が、思いがけず別の領域で顔を出す
―― これこそが、金融工学を「バラバラな道具の寄せ集め」ではなく、「一つの体系」として理解する醍醐味です。
この「つながり」は、最終章(第7章)で、本記事全体の結論として改めて回収します。
いまは「領域は地下でつながっている」という感覚を、頭の片隅に置いておいてください。
4-8. 業界の言語・ツール選択

| 業務シーン | 主に使われる言語・ツール | 選ばれる理由 |
|---|---|---|
| 最適化問題のモデリング | Python(CVXPY, PyPortfolioOpt) | 数式に近い形で書ける |
| 大規模・高速な最適化 | C++, Python+ソルバー | 数千資産のリアルタイム最適化 |
| 商用最適化ソルバー | Gurobi, MOSEK, CPLEX | 大規模問題を高速・確実に解く |
| 統合プラットフォーム | BlackRock Aladdin, Bloomberg PORT | リスク・最適化・執行を統合 |
BlackRockは統合プラットフォームAladdinを外販していることで有名です。
年金基金ではリスクパリティが人気、ヘッジファンドはC++/Pythonの自社開発に商用ソルバーを併用します。
志望者には凸最適化の理論とPython(CVXPY)、商用ソルバーの知識、線形代数が土台になります。
補足: Gurobi・MOSEK・CPLEX は個人でも触れるのか?(商用ソルバーのライセンス事情)
これらは「最適化ソルバー」と呼ばれる、数理最適化問題を高速・確実に解くための専用エンジンです。CVXPY のようなライブラリが「問題を記述する道具」だとすれば、ソルバーは「実際に解く心臓部」にあたります。
結論を言うと、3つとも本来は法人向けの高額な商用ソフトですが、学生・研究者やお試し用には、無料で触れる道がちゃんと用意されています。 Murex や Aladdin のような「金融機関しか触れない世界」とは違い、個人でも入り口に立てるツールです。
- 商用利用(法人) ―― 銀行・運用会社・メーカー・物流など、本格的に使う企業は有償ライセンスを購入します。価格は公開されておらず、利用規模に応じた個別見積もりですが、商用フルライセンスは年額で数十万〜数百万円規模になるのが一般的です。
- アカデミック(学生・研究者) ―― Gurobi と MOSEK は、大学など教育機関に所属する学生・研究者向けに、機能無制限の無料ライセンスを提供しています。CPLEX も、IBM のアカデミック・イニシアティブを通じて無償で利用できます。研究や授業で使う分には、実質的にお金はかかりません。
- 個人・お試し ―― いずれも評価用の試用版があり、また小規模な問題に限れば無料で使える制限版(サイズ制限つきの無料枠など)も用意されています。「まず触ってみる」だけなら、個人でも十分に可能です。
ちなみに、お金をかけたくない場合は、完全に無料・オープンソースのソルバー(CBC、HiGHS、SCIP、ECOS など)も存在します。CVXPY はこうした無料ソルバーも標準でサポートしているため、学習や中小規模の問題なら、一円もかけずに凸最適化を体験できます。 商用ソルバーが本領を発揮するのは、数千〜数万変数の大規模問題や、ミリ秒を争う本番運用の場面です。
まとめると、「入り口は無料で誰でも触れる。本番の大規模・高速処理になって初めて、商用ソルバーの高額ライセンスが効いてくる」という構図です。まずは CVXPY + 無料ソルバーで手を動かしてみるのが、おすすめの第一歩です。
4-9. 領域③ で運用者・クオンツが日々やっていること

最適化モデルの構築・入力データの推定・制約の設計・バックテスト・リバランスの実行・説明責任、などです。
-
最適化モデルの構築 ―― 「何を最大化(または最小化)し、どんな制約を守るか」を数式に落とし込み、CVXPY やソルバーで解ける形のモデルを組み立てます。本記事で見てきた平均分散最適化やその発展形を、実際のコードにする作業です。
-
入力データの推定 ―― モデルに入れる「期待リターン」や「分散・共分散(リスクと相関)」を、過去データなどから見積もります。第4章の弱点で触れたとおり、ここの推定が少しズレるだけで結果が大きく狂うため、実は最も神経を使う工程です。
-
制約の設計 ―― 「1銘柄に30%以上は入れない」「特定の業種に偏らせない」「空売りは禁止」といった、現実の運用ルールや規制を、数式の制約条件として組み込みます。最適化を"現実的な答え"にするための調整です。
-
バックテスト ―― 組んだモデルを過去のデータに当てはめ、「もし過去にこの戦略で運用していたら、どんな成績だったか」を検証します。机上の最適解が、現実でも通用するかを確かめる工程です。
-
リバランスの実行 ―― モデルが出した「最適な配分」に近づくよう、実際に資産を売買します。市場は動き続けるため、定期的に配分を調整し直す(リバランスする)必要があります。
- 説明責任 ―― 「なぜこの配分にしたのか」を、顧客・上司・規制当局に説明します。運用は他人のお金を預かる仕事なので、「数学が最適だと言ったから」では済みません。判断の根拠を、人間の言葉で語れることが求められます。
特に最後の 説明責任 は、見落とされがちですが重要です。どれだけ高度な最適化をしても、その結果を関係者に納得してもらえなければ、現実には実行できないからです。「数学のスキル」と「説明する力」の両方が、この仕事には要ります。
4-10. 次の章への接続

領域③の主役の数学は、最適化理論・凸解析(静的)、確率制御(動的)でした。
中心概念は「お椀の形(凸性)」です。
次の第5章では4領域の最後、領域④ 市場マイクロ構造・HFTに移ります。点過程・ホークス過程・強化学習が主役になります。
ここで、第2章で触れたQ/KDB+が再び主役級の道具として登場します。
5. 領域④ 市場マイクロ構造・高頻度取引(HFT)―― 点過程・強化学習が主役の世界
ついに、本稿で取り上げる「金融工学の4つの領域」で取り上げる最後の領域の解説に入ります。
ここはミリ秒・マイクロ秒の世界で、主役の数学は点過程・ホークス過程・最適執行理論・強化学習になります。
5-1. そもそも「市場マイクロ構造」とは何か
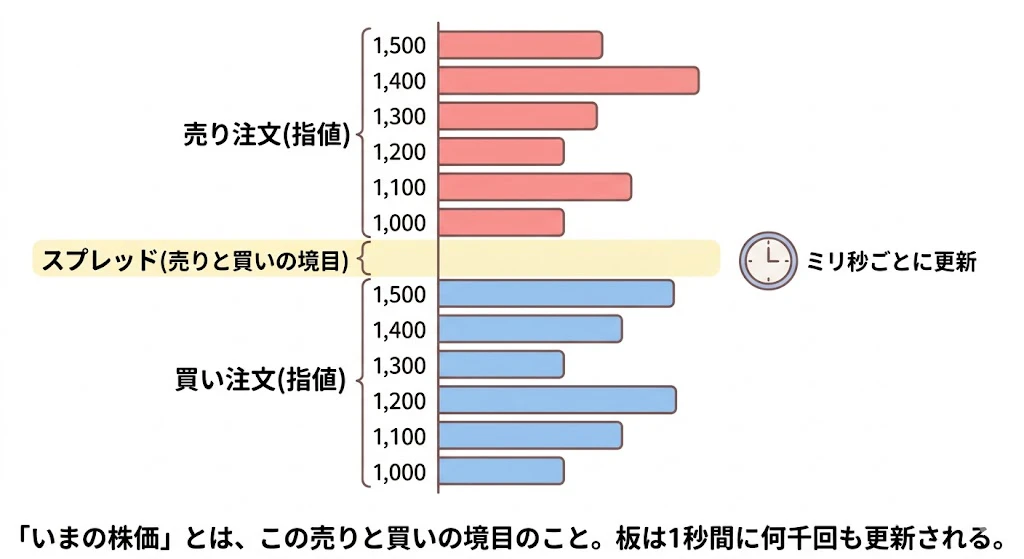
株式や為替の取引は「板(order book)」の上で行われます。
板とは、いまこの瞬間に出ている売り注文と買い注文の一覧表です。
「いまの株価」とは、実はこの板の「売りと買いの境目」あたりの価格にすぎません。
市場マイクロ構造とは、この板の上で注文がどう出され、どう約定し、価格がどう形成されるかを研究する分野です。
具体的には、板は次のような構造をしています。
| 売り注文(価格が高い順) | 株数 |
|---|---|
| 3005円 | 500株 |
| 3004円 | 300株 |
| 3003円 | 800株 |
| ↑ ここから上が「売りたい人」 | |
| ↓ ここから下が「買いたい人」 | |
| 3002円 | 600株 |
| 3001円 | 400株 |
| 3000円 | 900株 |
売りたい人の最安値(3003円)と、買いたい人の最高値(3002円)の差(=1円)をスプレッド と呼びます。
HFTのマーケットメイカーは、このスプレッドを大量・高速に稼ぎます。
5-2. なぜミリ秒が問題になるのか ―― HFTの世界
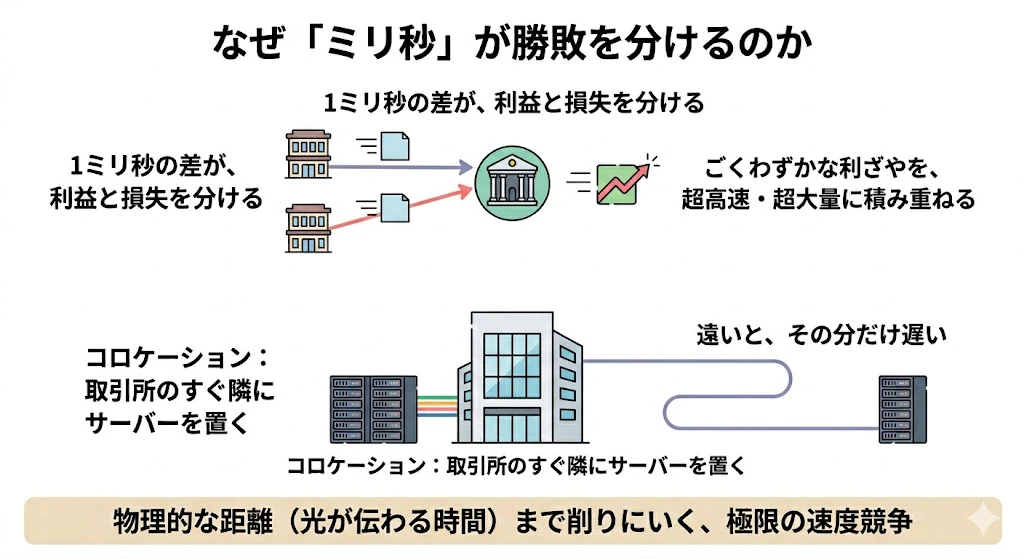
高頻度取引(HFT)とは、コンピュータがミリ秒・マイクロ秒単位で大量の注文を出し入れし、ごくわずかな利ざやを超高速・超大量に積み重ねる取引です。
1ミリ秒の遅れが利益と損失を分けるため、取引所のサーバーに物理的に近い場所にコンピュータを置く(コロケーション)といった極限の速度競争が繰り広げられています。
5-2.5. HFTは、具体的に何で稼いでいるのか
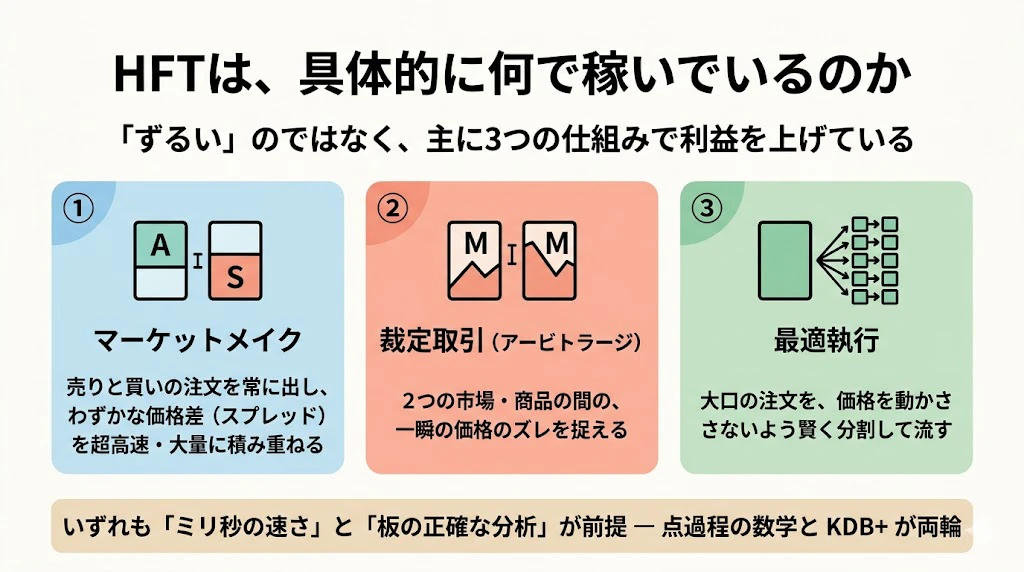
HFTと聞くと「ずるい」「危ない」というイメージを持つ方もいますが、実際の利益の源泉は、主に3つに整理できます。
-
マーケットメイク :売り注文と買い注文の両方を常に出し、わずかな価格差(スプレッド)を、超高速・大量に積み重ねる
-
裁定取引(アービトラージ) :2つの市場間や、関連する2つの商品間の、一瞬の価格のズレを捉える
-
最適執行 :大口の注文を、価格を動かさないように、賢く分割して流す
これらはすべて「ミリ秒単位の速さ」と「板の状態の正確な分析」が前提になります。
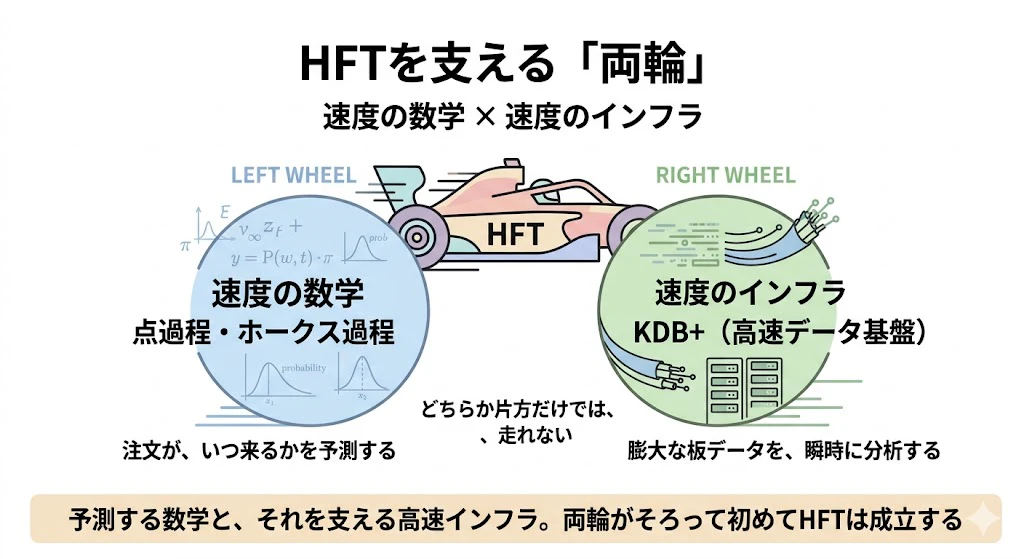
だからこそ、点過程の数学(注文がいつ来るかを予測する)と、KDB+のような高速データ基盤(膨大な板データを瞬時に分析する)が、両輪で必要になるのです。
5-3. 主役の数学① 点過程とホークス過程
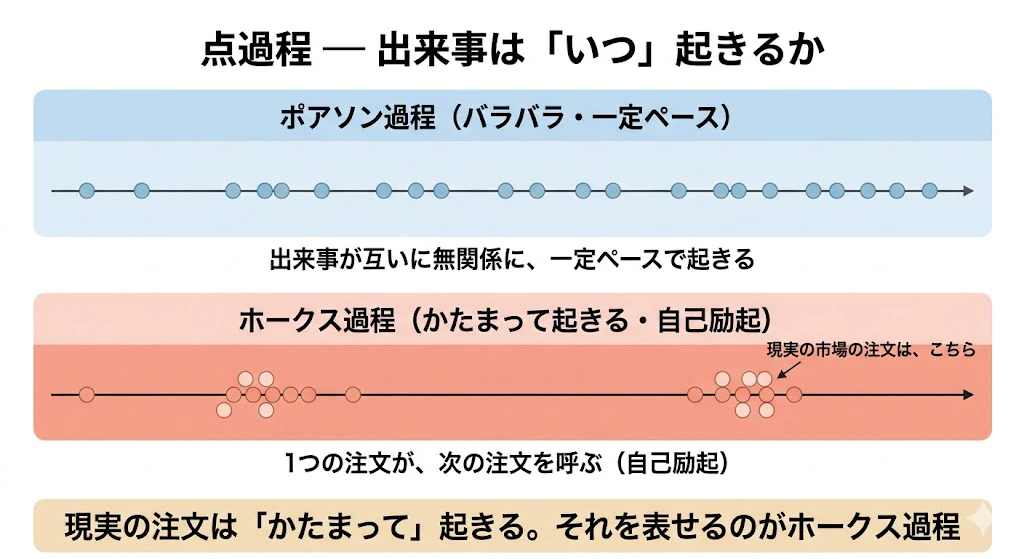
点過程とは、「出来事が時間軸の上でいつ起きるか」を確率的に記述する数学です。
最もシンプルなポアソン過程は「出来事が互いに無関係に一定ペースで起きる」モデルですが、現実の注文にはかたまりがあるため、うまく表せません。
現実の市場では「1つの注文が入ると、それに反応してしばらく次の注文が入りやすくなる」という自己励起(self-exciting)が起きます。
これを表現するのがホークス過程です。
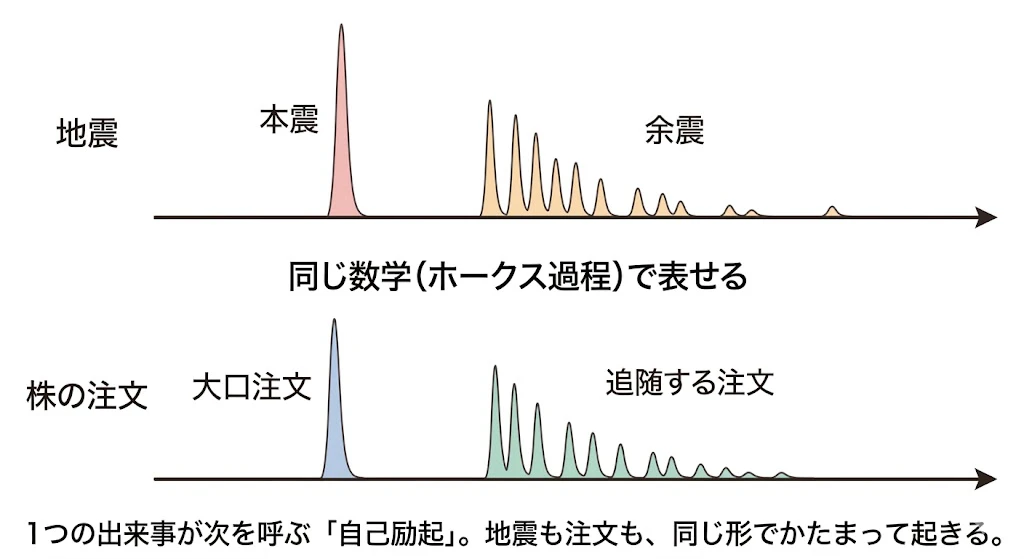
📖 コラム: ホークス過程の「自己励起」を、地震で理解する
ホークス過程は、1971年に統計学者アラン・ホークスが、もともと地震の余震をモデル化するために提案した数学です。大きな地震(本震)が起きると余震が連続し、余震がさらに小さな余震を呼ぶ ―― これが自己励起です。時間とともに余震の頻度はだんだん収まります。
金融市場の注文の流れは、地震とそっくりです。大口注文(本震)が入る→反応した注文(余震)が連続発生→時間が経つと頻度が落ち着く。だから地震のために作られたホークス過程が、そのままHFTの注文流のモデルとして使えるのです。ひとつの数学が、地震という自然現象と金融市場という人工的な現象の、両方のかたまって起きる性質を捉えている美しい例です。
5-4. 主役の数学② 最適執行理論

最適執行の問題は、「10万株を売りたいが、一度に全部売ると価格が暴落する。しかし、少しずつ売ると、その間に価格が動くリスクがある。どのペースで売るのが最適か?」というものです。
急いで売ると、自分の大量売りで価格を押し下げる(マーケットインパクト)結果を招いてしまいます。
他方で、ゆっくりと時間をかけて売ると、市場が勝手に動くリスクを受けてしまいます(タイミングリスク)。
この2つの選択肢のトレードオフを数学的に解きます。
2000年頃のアルメグレン・クリスのモデルが古典です。
近年は強化学習で解くアプローチが発展しています。
5-5. 主役の数学③ 強化学習
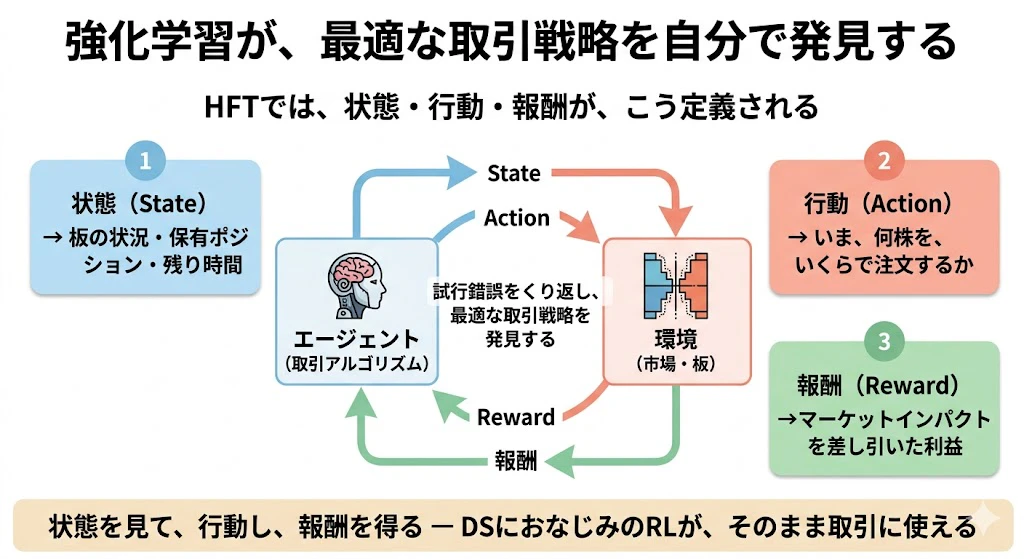
強化学習(RL)は「試行錯誤を通じて報酬が最大になる行動を学習する」機械学習です。
このあたりは、すでに本稿で述べた通り、データサイエンティストの皆様にとっては、馴染みの深い問題解決アルゴリズム理論だと思います。
HFTでは、状態(板の状況、ポジション、残り時間)・行動(いま何株いくらで注文するか)・報酬(マーケットインパクトを差し引いた利益)として、最適な取引戦略を、強化学習アルゴリズムが発見します。
5-6. 業務イメージのコード ―― ホークス過程の推定(Python)
※ 以下のコードは「こういう形で注文流の自己励起をコンピュータに推定させる」という雰囲気だけ掴めばOKです。一行ずつ理解する必要はありません。
from tick.hawkes import HawkesExpKern
import numpy as np
order_times = [np.array([0.1, 0.15, 0.18, 0.4, 0.42, 0.9])]
model = HawkesExpKern(decays=5.0)
model.fit(order_times)
print(f"基礎発生率(baseline): {model.baseline}")
print(f"自己励起の強さ(adjacency): {model.adjacency}")
業務では、ミリ秒精度の膨大な板データ(1日数十億件)を処理し、買い注文と売り注文の相互励起を多次元で扱い、価格予測や執行タイミングの判断に接続します。
この膨大な時系列処理にこそQ/KDB+が活躍します。
5-7. なぜ普通のデータベースでは、HFTに使えないのか

ここで、技術的に面白い問いに踏み込みます。「板データの分析に、なぜPostgreSQLやMySQLのような普通のデータベースが使えないのか?」という問題です。
理由は、HFTが扱うデータの「形」と「量」と「速度」が、Webサービスのデータとまったく違うからです。
ある銘柄の板情報は1秒間に数千〜数万回も更新され、東証(東京証券取引所)全体では1日で数十億件のイベントが発生します。
これを通常のリレーショナルデータベースで処理しようとすると、次の壁にぶつかります。
| 課題 | 通常のRDB(行指向) | HFTが必要とするもの |
|---|---|---|
| データの並び方 | 1行ずつ(行指向) | 列ごとにまとめて(列指向) |
| 「直近100件の平均」 | 全行を走査して集計(遅い) | 時系列順に並んだ列を一気に計算(速い) |
| 1日数十億件の書き込み | ディスクI/Oがボトルネック | メモリ上に保持して高速処理 |
| 時間軸の扱い | 時刻は「ただの列の1つ」 | 時間が主役(時系列ネイティブ) |
ポイントは2つ、「列指向」と「時系列ネイティブ」です。
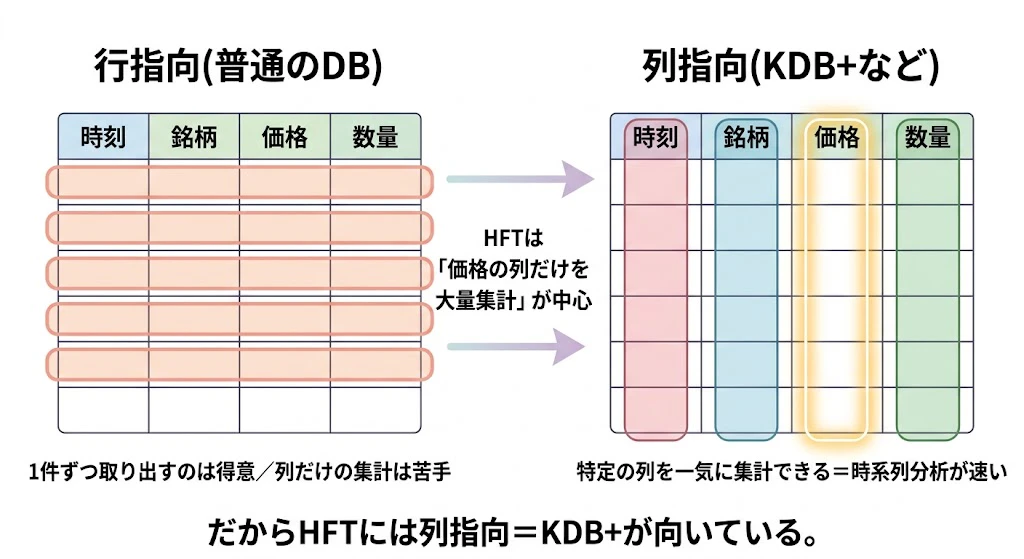
普通のデータベース(行指向)は、「1件の注文」を1行として、横にズラッと属性(時刻・銘柄・価格・数量…)を並べて保存します。
これは「1件の注文の全情報を取り出す」のは得意ですが、「価格の列だけを100万件集計する」のは苦手です。価格を取り出すたびに、要らない他の属性も一緒に読み込んでしまうからです。
一方、列指向データベースは、価格は価格だけ、数量は数量だけ、と列ごとにまとめて保存します。「価格の列だけを一気に集計する」のが圧倒的に速くなります。HFTの分析は、まさにこの「特定の列を時系列順に大量集計する」処理が中心なので、列指向が決定的に有利なのです。
補足: 列指向なら Redshift や NoSQL と同じでは? ―― KDB+ の何が違うのか
「列指向のデータベースなら、Amazon Redshift や ClickHouse もそうだ。NoSQL もある。KDB+ は何が特別なのか?」 ―― これは鋭い疑問です。
ポイントは、「列指向」という storage の形は同じでも、何のために最適化されているか(設計思想)がまったく違う ということです。同じ「列指向」でも、向いている仕事が異なります。
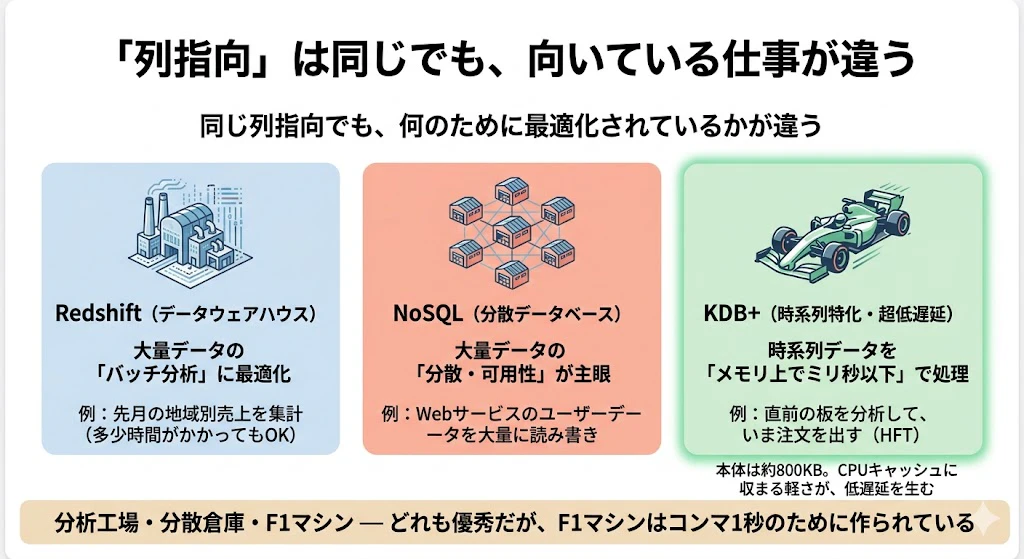
- Amazon Redshift(列指向のデータウェアハウス) ―― ペタバイト級の大量データを、まとめて分析する「バッチ分析」に最適化されています。「先月の地域別売上を集計する」といった、多少時間がかかってもよい大規模分析が得意です。一方で、ミリ秒以下の応答が求められる超低遅延の用途には、設計上向いていません。
- NoSQL(MongoDB・Cassandra など) ―― そもそも目的が違います。NoSQL は「大量のデータを、たくさんのサーバーに分散して、高い可用性で読み書きする」ことに主眼があります(Webサービスのユーザーデータなど)。列指向の分析特化ではなく、分散と柔軟なデータ構造のための仕組みです。
- KDB+(時系列特化・超低遅延) ―― 列指向であることに加えて、「時系列データを、メモリ上で、ミリ秒以下で処理する」ことに極限まで最適化されています。本体が約800KBと極小で、CPUのキャッシュに収まるほど軽量に作られており、これが圧倒的な低遅延を生みます。「直前の数ミリ秒の板を分析して、いま注文を出す」というHFTの用途に、設計思想ごと特化しているのです。
たとえるなら、Redshift は「大型の分析工場」、NoSQL は「分散倉庫」、KDB+ は「F1マシン」です。どれも優れた乗り物ですが、F1マシンは「サーキットでコンマ1秒を削る」ことだけに特化して作られています。HFTという"サーキット"では、汎用の大型車では勝負にならないのです。
なお、「バッチ分析でいいなら Redshift や ClickHouse、リアルタイム性がそこまで要らないなら他の時系列DB(QuestDB、TimescaleDB など)」という選択も十分あり得ます。KDB+ が圧倒的に効くのは、あくまで「ミリ秒以下の低遅延が、利益に直結する」HFTのような領域です。
5-8. ここで Q/KDB+ が再登場する
第2章のコラムで紹介したQ/KDB+は、まさにこの領域④が主戦場です。
KDB+は、上で述べた「列指向」かつ「時系列ネイティブ」を、極限まで突き詰めた商用データベースだからです。
さらに、データをメモリ上に保持し、最適化されたC言語エンジンで動くため、ディスクI/Oのボトルネックも回避します。
規模感を対比すると、その必然性が腹落ちします。
通常のリレーショナルデータベースは、「数万〜数百万行の業務データ」(顧客台帳、注文履歴など)を扱う設計です。
その一方で、HFTは「1日数十億件の時系列イベント」を、ミリ秒単位で連続的に書き込み・分析し続ける必要があります。
桁が3〜4つ違ううえ、求められる速度もまるで違う。この超巨大な時系列を、メモリ上で高速処理するために専用設計されたのがKDB+であり、それを操るために生まれたのが、あの暗号のように簡潔な言語Qなのです。
「変態的に簡潔な言語」が生まれた背景には、「1文字でも短く書いて、巨大な時系列を一気に処理したい」という切実な要求があったわけです。
HFTでは1日数十億件の板データをミリ秒精度で保存・分析する必要があり、通常のDBでは追いつけません。
だからこそ大手がKDB+をHFTの中核に据えています。領域④は「速度の数学(点過程・強化学習)」と「速度のインフラ(Q/KDB+, C++, FPGA)」が両輪で動く世界 です。
なお、KDB+ と、その言語Qの系譜(APL→K→Q)については、本シリーズで独立した記事として詳しく解説する予定です。
5-9. 業界の言語・ツール選択
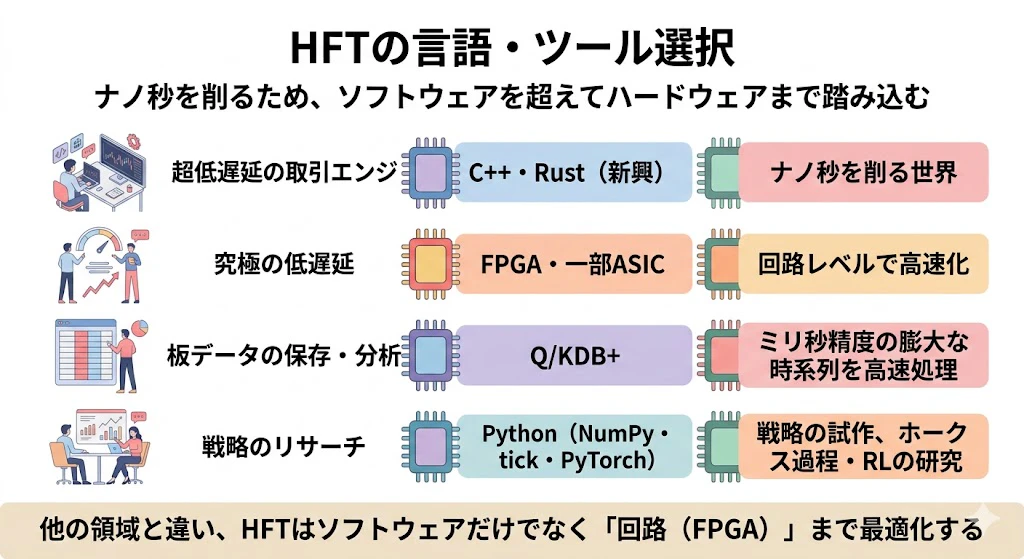
| 業務シーン | 主に使われる言語・ツール | 選ばれる理由 |
|---|---|---|
| 超低遅延の取引エンジン | C++, Rust(新興) | ナノ秒を削る世界 |
| 究極の低遅延 | FPGA, 一部ASIC | 回路レベルで高速化 |
| 板データの保存・分析 | Q/KDB+ | ミリ秒精度の膨大な時系列を高速処理 |
| 戦略のリサーチ | Python(NumPy, tick, PyTorch) | 戦略の試作、ホークス過程・RLの研究 |
補足: FPGA・ASIC とは何か(ソフトウェアの限界の、その先)
表に出てきた FPGA と ASIC は、多くのソフトウェアエンジニアやデータサイエンティストには、なじみの薄い言葉だと思います。これらは「ソフトウェア」ではなく「ハードウェア(電子回路)」の話です。
普段、私たちが書くプログラム(PythonやC++)は、CPUという「何でも屋」の上で動きます。CPUは汎用的で、どんな命令でもこなせますが、その分、一つの処理に「命令を読み込んで、解釈して、実行する」という手間がかかります。この手間が、ナノ秒を争うHFTでは、無視できない遅れになります。
そこで登場するのが、FPGAとASICです。
- FPGA(Field-Programmable Gate Array)
―― ひとことで言うと、「処理内容に合わせて、回路そのものを組み替えられるチップ」です。
ソフトウェアのように「CPUに命令を実行させる」のではなく、やりたい処理を電子回路として直接焼き込みます。回路に直接やらせるので、CPUのような解釈の手間がなく、桁違いに速く・低遅延で動きます。しかも、後から回路を組み替えられる柔軟性もあります。
- ASIC(Application-Specific Integrated Circuit)
―― 「特定の処理だけのために、専用に作り込んだチップ」です。
FPGAが「組み替えられる回路」なのに対し、ASICは用途を固定して焼き付けた、いわば一点特化の専用部品です。> 組み替えはできませんが、その分、究極の速度と効率が得られます(ビットコインのマイニング専用機などが有名な例です)。なぜHFTがここまでするのでしょうか?
理由は単純で、ソフトウェアの最適化(C++やRustでの高速化)には限界があり、その先のナノ秒を削るには、もう回路レベルで戦うしかない からです。
「光が1メートル進むのに約3.3ナノ秒」という物理の世界で勝負しているため、CPUで命令を解釈している暇さえ惜しい、ということです。データサイエンティストがFPGAやASICを直接触ることは、まずありません。しかし、「HFTの世界では、ソフトウェアの限界の先で、ハードウェアそのものを最適化する戦いが繰り広げられている」と知っておくと、この領域の極限性が実感できると思います。

この領域の企業文化は、技術者にとって非常に興味深いものがあります。
-
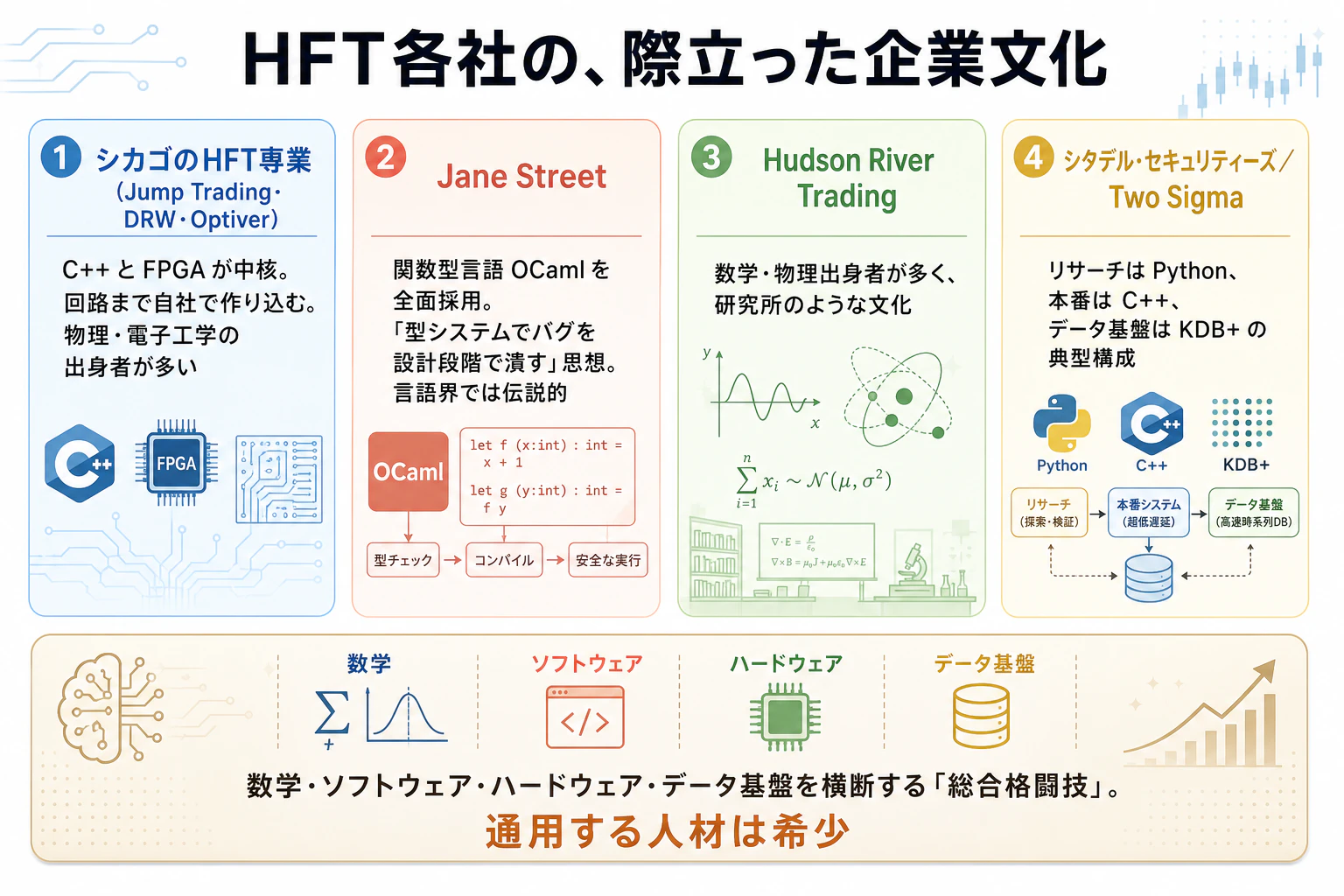
シカゴのHFT専業会社(Jump Trading、DRW、Optiver) :
C++とFPGAが中核。ナノ秒を削るために、ソフトウェアだけでなくハードウェア(回路)まで自社で作り込みます。
物理学・電子工学の出身者が多いのも特徴です。
-
Jane Street :
関数型言語OCamlを全面採用していることで、プログラミング言語界では伝説的な存在です。
「型システムでバグを設計段階で潰す」という思想で、金融の1件のバグが億単位の損失になる世界において、コンパイル時の安全性を重視しています。
-
Hudson River Trading :
数学・物理出身者が多く、研究所のような文化。
-
シタデル・セキュリティーズ、Two Sigma :
C++ + Python + KDB+ の組み合わせ。
リサーチはPython、本番はC++、データ基盤はKDB+、という典型的な構成です。
この領域は、数学(点過程・強化学習)・ソフトウェア(C++・OCaml)・ハードウェア(FPGA)・データ基盤(KDB+)の4つを横断する、いわば総合格闘技の世界です。
だからこそ、ここで通用するエンジニアは希少で、高く評価されます。
5-10. 領域④でクオンツ・エンジニアが日々やっていること
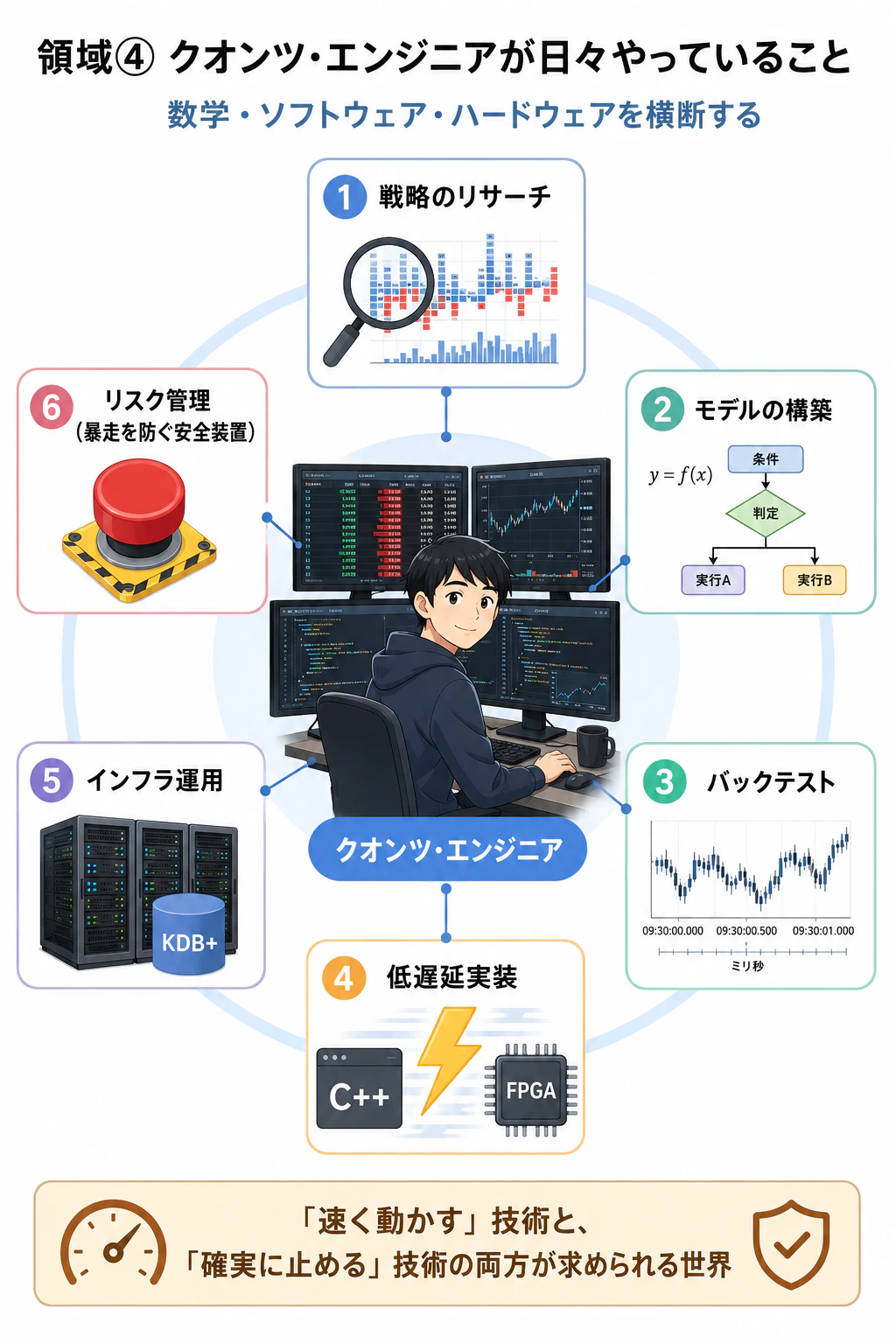
この領域のクオンツ・エンジニアは、日々おおむね次のような業務に取り組んでいます。
数学・ソフトウェア・ハードウェアを横断するため、一人がカバーする範囲は広めです。
-
戦略のリサーチ ―― 「どんな条件のとき、どう注文すれば儲かるか」という取引戦略のアイデアを、膨大な過去の板データを分析しながら探します。点過程やホークス過程、強化学習といった数学を使って、注文の流れのパターンを見つける工程です。
-
モデルの構築 ―― 見つけた戦略を、実際に動く数理モデル(注文のタイミングや量を決めるロジック)に落とし込みます。リサーチでの「思いつき」を、計算可能な形にする作業です。
-
バックテスト ―― 作った戦略を過去の板データに当てはめ、「もし過去にこの戦略で取引していたら、儲かったか」を検証します。ミリ秒単位のデータで、現実に近い形で再現するのがポイントです。
-
低遅延実装 ―― 戦略を、本番で動く超高速なプログラムとして実装します。ここがHFT特有の難所で、C++ や、時にはFPGA(回路)まで使って、ナノ秒単位の遅れを削り込みます。「正しく動く」だけでなく「誰よりも速く動く」ことが求められます。
-
インフラ運用 ―― 取引システムを支える、サーバー・ネットワーク・データ基盤(KDB+ など)を構築し、安定して動かし続けます。コロケーション(取引所の隣にサーバーを置く)の管理も、ここに含まれます。
- リスク管理(暴走を防ぐ安全装置) ―― 自動売買アルゴリズムが、バグや想定外の市場で暴走しないよう、安全装置(一定以上の損失で自動停止する仕組みなど)を組み込みます。HFTは高速なぶん、暴走すると一瞬で巨額の損失を出すため、この「ブレーキ」は極めて重要です。
特に最後の リスク管理(安全装置) は、HFTでは生命線です。実際、過去には自動売買システムの暴走で、わずか数十分のうちに巨額の損失を出し、会社が経営危機に陥った事例もあります。「速く動かす」技術と同じくらい、「危険なときに確実に止める」技術が重視されるのが、この世界の特徴です。
5-11. 4つの領域の旅を終えて
| 領域 | 主役の数学 | 時間スケール |
|---|---|---|
| ① デリバティブ値段付け | SDE、PDE、マルチンゲール理論 | 数日〜数十年 |
| ② リスク管理 | 統計学、極値理論、コピュラ理論 | 1日〜10日 |
| ③ ポートフォリオ最適化 | 最適化理論、凸解析、確率制御 | 数日〜数年 |
| ④ 市場マイクロ構造・HFT | 点過程、ホークス過程、強化学習 | ミリ秒〜マイクロ秒 |
同じ「金融工学」でも、領域が違えば主役の数学も時間スケールも使う言語もまったく違う ―― この多様性こそが金融工学の奥深さです。
5-12. 次の章への接続
これで4つの領域すべてを巡り終えました。
次の第6章では、登場したすべての数学理論を一覧表にまとめます。
そして最後の第7章で、本記事の出発点だった問い ―― 「SDEは全体地図のどこに位置するのか?」 に立ち返ります。
6. 金融工学を支える数学理論の一覧表 ―― 全体地図
本章は、これまで登場した数学を一望できる地図です。
読み物というより辞書・索引として使ってください。
※ この章の表を、全部一気に覚える必要はまったくありません。
今後どこかで知らない数学用語に出会ったとき、「これは金融工学のどの領域の道具なのか」を確認する辞書として、必要なときに戻ってきてください。
6-1. 金融工学の数学 ―― 一覧表
| 数学理論 | 一行で言うと | 主な領域 |
|---|---|---|
| 確率微分方程式(SDE) | ランダムに揺れる量の時間変化を記述 | ① 値段付け |
| 伊藤積分・伊藤の補題 | ブラウン運動を積分する特別な計算法 | ① 値段付け |
| 偏微分方程式(PDE) | 複数の変数で変化する量を記述 | ① 値段付け |
| マルチンゲール理論 | 「公平な賭け」を一般化した理論 | ① 値段付け |
| 測度論 | 「確率」を厳密に定義する数学 | ① 値段付け |
| 最適停止理論 | 「いつ止めるか」を決める数学 | ①④ |
| 統計学・統計推測 | データから分布を推定する | ② リスク管理 |
| 極値理論(EVT) | 分布の「端っこ」だけを扱う | ② リスク管理 |
| コピュラ理論 | 複数変数の依存関係を扱う | ② リスク管理 |
| 最適化理論・凸解析 | 制約下で関数を最小化/最大化 | ③ 最適化 |
| 確率制御理論 | ランダムな系を時間を通じて最適化 | ③④ |
| 点過程・ホークス過程 | 出来事が「いつ起きるか」を記述 | ④ HFT |
| 強化学習 | 試行錯誤で報酬最大の行動を学習 | ③④ |
| 線形代数 | ベクトル・行列の数学 | 全領域 |
| 時系列解析 | 時間変化するデータの分析 | ②③④ |
6-2. 領域ごとの「主役」と「脇役」
| 数学理論 | ①値段付け | ②リスク | ③最適化 | ④HFT |
|---|---|---|---|---|
| 確率微分方程式(SDE) | ◎主役 | ○脇役 | ○脇役(動的) | ○脇役 |
| 偏微分方程式(PDE) | ◎主役 | △ | ○脇役(HJB) | △ |
| マルチンゲール理論 | ◎主役 | △ | △ | △ |
| 統計学 | ○ | ◎主役 | ○ | ◎主役 |
| 極値理論(EVT) | △ | ◎主役 | △ | △ |
| コピュラ理論 | ○(信用) | ◎主役 | ○ | △ |
| 最適化理論・凸解析 | △ | ○ | ◎主役 | ○ |
| 確率制御理論 | ○ | △ | ◎主役(動的) | ○ |
| 点過程・ホークス過程 | △ | △ | △ | ◎主役 |
| 強化学習 | △ | ○ | ○ | ◎主役 |
(◎主役 / ○脇役・準主役 / △あまり使われない)
- SDEは、値段付け(①)では絶対的な主役だが、他の領域では脇役 ― これが本記事を貫くメッセージです
- 統計学は4領域すべてで重要。特に②と④で主役
- 極値理論・コピュラは②に特化した専門道具、点過程・ホークス過程は④だけの専門道具
6-3. 数学の「難易度」と「学ぶ順番」の地図
| 段階 | 数学 | 備考 |
|---|---|---|
| 土台 | 線形代数、微積分、確率・統計の基礎 | すべての出発点 |
| 初級 | 統計学、時系列解析、最適化の基礎 | 領域②③に直結。DSの素養と重なる |
| 中級 | 凸最適化、コピュラ、極値理論 | 領域②③の実務で必要 |
| 中級 | 点過程・ホークス過程 | 領域④に直結 |
| 上級 | 測度論、確率過程論 | SDEを厳密に理解する土台 |
| 上級 | 確率微分方程式、伊藤積分 | 領域①の核心 |
| 上級 | 確率制御、HJB方程式 | 動的最適化(③④) |
| 発展 | 強化学習 | 近年の④の最前線 |
データサイエンティストが既に持っている素養(統計・最適化・機械学習)は、領域②③④に直結する
一方、領域①の核心であるSDEは、測度論という上級の土台を要するため、最も習得に時間がかかります。これは第7章の重要なメッセージにつながります。
6-4. 数学理論と、使われるプログラミング言語の対応
| 数学理論 | 主に使われる言語・ツール |
|---|---|
| SDE・PDE(値段付け) | C++(本番)、Python(リサーチ)、QuantLib |
| モンテカルロ法 | C++、Python、CUDA(GPU並列) |
| 統計学・極値理論 | Python、R(POT, evd)、SAS |
| コピュラ理論 | Python(copulas)、R(copula) |
| 凸最適化 | Python(CVXPY)、Gurobi、MOSEK |
| 点過程・ホークス過程 | Python(tick)、C++ |
| 強化学習 | Python(PyTorch, TensorFlow, JAX) |
| 大規模時系列データ処理 | Q/KDB+、ClickHouse、C++ |
| 超低遅延実行 | C++、Rust、FPGA |
6-5. この地図の使い方
- 知らない数学用語に出会ったとき → 6-1で領域と用途を確認
- 興味のある領域を深めたいとき → 6-2で主役の数学を特定
- 学ぶ順番に迷ったとき → 6-3の学習順序を参考に
- 数学とセットで言語を学びたいとき → 6-4の対応表を参考に

6-6. 次の章への接続
金融工学は、たった1つの数学でできているのではなく、多様な数学理論の集合体である
いよいよ次の最終章で、本記事の出発点だった問い ―― 「SDEは、この全体地図のなかで、どこに位置するのか?」 に立ち返ります。
7. では、確率微分方程式(SDE)は、どこに位置するのか ―― 本記事の結論
7-1. 結論 ―― SDEは「主役の1つ」だが「唯一の主役」ではない

確率微分方程式(SDE)は、金融工学の「値段付け」領域(①)における中心的な主役です。
しかし、金融工学全体を見渡したとき、SDEはその大きな建物を支える「柱の1本」にすぎません。
第6章の主役・脇役マトリクスが示した通り、領域①ではSDEは主役ですが、②は統計学・極値理論・コピュラ、③は最適化理論・凸解析、④は点過程・強化学習が主役で、SDEは脇役です。
「金融工学 = SDE」ではなく、「金融工学 ⊃(値段付け ⊃ SDE)」が正確な姿です。
言い換えると、「金融工学 = ブラックショールズ」という理解は、「機械学習 = 線形回帰」というのと同じくらい限定的 です。
線形回帰は機械学習の出発点であり重要な一角ですが、それだけが機械学習ではありません。
同じように、ブラックショールズ(とその背後のSDE)は金融工学の輝かしい一角ですが、それだけが金融工学ではないのです。
7-2. なぜ、SDEが「金融工学の代名詞」のように見えるのか
- 歴史的なインパクト: ブラックショールズ方程式(1973年)が金融工学を学問として確立させた
- 数学的な美しさと難しさ: 難しくてかっこいいものが象徴として語られやすい
- ノーベル賞: ブラックショールズ・マートンの理論が1997年に受賞
- 教育の順序: 教科書の多くがブラックショールズから始まる
しかし実際の現場はもっと広く多様です。リスク管理では極値理論が、運用では凸最適化が、HFTでは点過程が、それぞれ主役として日々活躍しています。
7-3. データサイエンティストの皆様への、特別なメッセージ

皆様が既に持っているスキル(統計学・最適化・機械学習)は、金融工学の領域②③④に、直接つながっています。
- 統計学・時系列解析 → 領域②(リスク管理)、領域④(HFT)で即戦力
- 最適化・凸最適化 → 領域③(ポートフォリオ最適化)で即戦力
- 機械学習・強化学習 → 領域③④、近年の全領域で武器になる
- コピュラ・極値理論 → 少し学べばリスク管理で強力な専門性に
もう少し具体的に、データサイエンスの日常的なタスクが、金融工学のどこに対応するかを表にすると、次のようになります。
| DSでの典型タスク | 使う手法 | 金融工学での対応する応用 | 領域 |
|---|---|---|---|
| 予測モデル | 回帰・勾配ブースティング | 価格・ボラティリティの予測 | ①④ |
| 異常検知 | Isolation Forest・オートエンコーダ | 不正取引・マネーロンダリング検知 | ② |
| 時系列分析 | ARIMA・状態空間モデル | ボラティリティ・注文流の分析 | ②④ |
| 逐次的意思決定 | 強化学習 | 最適執行・動的ポートフォリオ | ③④ |
| 大規模並列計算 | GPU・分散処理 | モンテカルロ価格付けの高速化 | ① |
| 多変量の依存構造 | コピュラ・相関分析 | ポートフォリオの危機時相関 | ② |
この表を見ると、データサイエンティストの仕事と金融工学が、いかに地続きかが分かります。
皆様は、すでに金融工学の入り口の多くに、片足を踏み入れているのです。
「金融工学に入るには、まず難解なSDEと測度論を制覇しなければならない」というのは誤解です。
SDEは領域①の核心ですが、金融工学への唯一の入り口ではありません。皆様の既存スキルが活きる入り口(②③④)が、ちゃんと用意されています。SDEは「選択肢の1つ」であって「必須の関門」ではないのです。
7-4. 本記事の第1部(既発表記事)との接続
本記事よりも先にQiitaで公開した先行(測度論→伊藤積分→ブラックショールズ)は、領域①の核心であるSDEを縦に深く掘る旅でした。
本記事(第2部)は、その先の「SDE以外の金融工学はどうなっているのか」という、より広い地図を提示するものです。
2つを合わせると、深さ(第1部)と広がり(第2部)の両方の視点が得られ、金融工学という建物の全体像が立体的に見えてきます。
第1部記事: 数学高校レベルのDS向けに「測度論 → 伊藤積分 → ブラックショールズ」を全部つなげてみる
7-5. これから、どこへ向かうか
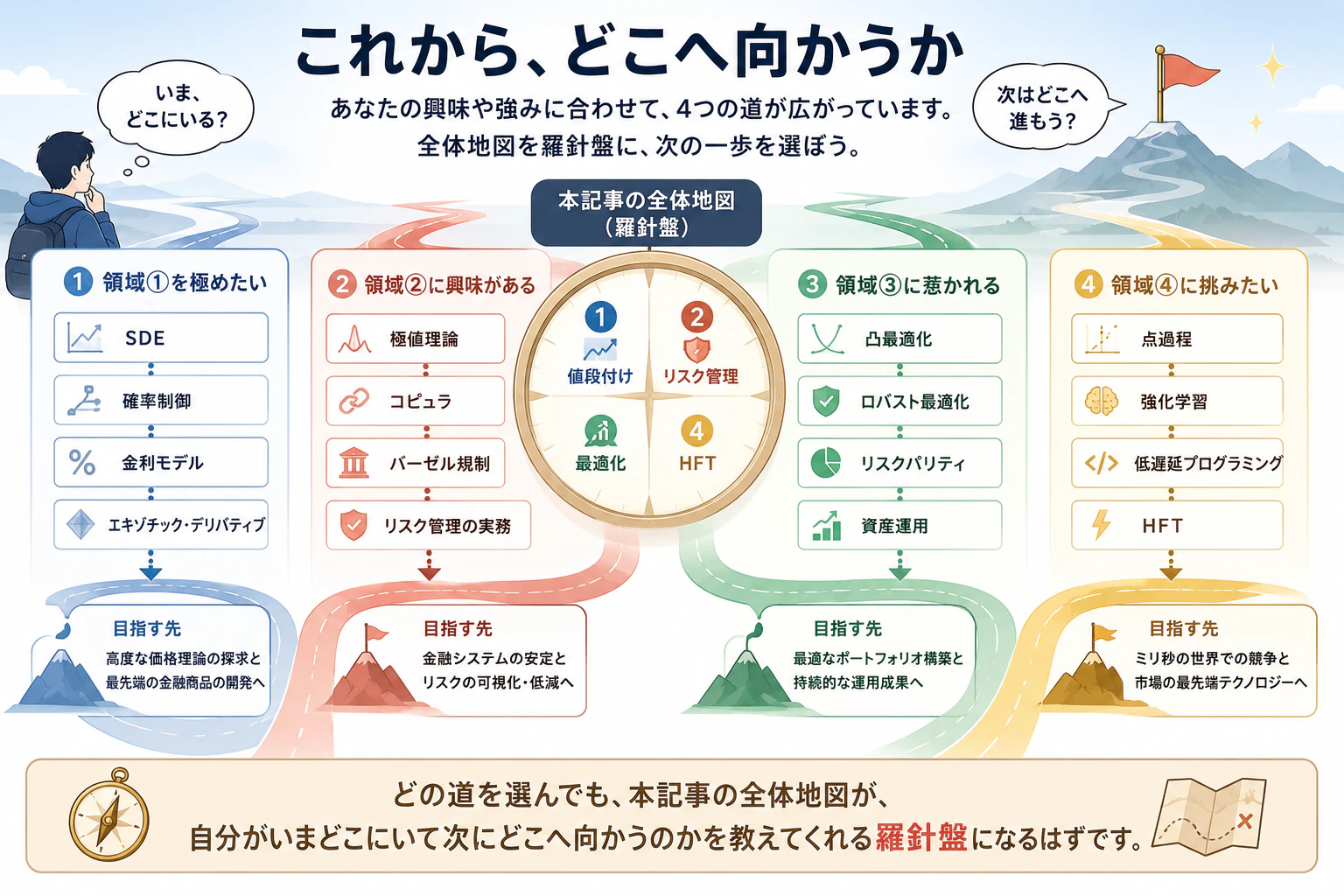
- 領域①を極めたい → SDE、確率制御、金利モデル、エキゾチック・デリバティブへ
- 領域②に興味がある → 極値理論、コピュラ、バーゼル規制、リスク管理の実務へ
- 領域③に惹かれる → 凸最適化、ロバスト最適化、リスクパリティ、資産運用へ
- 領域④に挑みたい → 点過程、強化学習、低遅延プログラミング、HFTへ
どの道を選んでも、本記事の全体地図が、自分がいまどこにいて次にどこへ向かうのかを教えてくれる羅針盤になるはずです。
補足: 「エキゾチック・デリバティブ」と「リスクパリティ」とは
上の図に出てきた2つの言葉を、簡単に補足しておきます。
どちらも本記事で部分的に触れた内容の、その先にあるテーマです。
- エキゾチック・デリバティブ
―― 第2章で見た、バリア・オプションやアジアン・オプションのような「複雑なオプション」を、まとめてこう呼びます。
欧州型コール・プットのような単純(プレーン・バニラ=定番)なオプションに対して、「変わり種」という意味で「エキゾチック(風変わりな)」と名付けられています。経路依存性があったり、複数の条件が組み合わさったりするため、値段付けには高度な数値計算が必要になります。領域①をさらに深めると、この世界に入っていきます。
- リスクパリティ
―― 第4章で少し触れた、ポートフォリオ最適化の発展形の一つです。「パリティ(parity)」は「同等・均等」という意味で、各資産がポートフォリオ全体のリスクを等しく分担するように配分する考え方です。
当てるのが難しい「期待リターンの予測」に頼らず、リスクの分担だけで配分を決めるため、頑健(ロバスト)だとされ、年金基金など長期運用の現場で広く採用されています。領域③を深めると出会う、実務で重要な手法です。
まとめ
本記事のエッセンス

- 金融工学は、大きく4つの領域(①値段付け、②リスク管理、③ポートフォリオ最適化、④市場マイクロ構造・HFT)に分かれている
- それぞれの領域に異なる主役の数学がある。①はSDE・PDE、②は統計学・極値理論・コピュラ、③は最適化理論・凸解析、④は点過程・強化学習
- 確率微分方程式(SDE)は領域①の中心的な主役だが、金融工学全体で見れば柱の1本にすぎない
- DS(データサイエンティスト)が既に持つスキル(統計・最適化・機械学習)は領域②③④に直接つながり、SDEを経由しなくても金融工学に入る道がある
- 各領域は使う数学だけでなく、使うプログラミング言語・ツールも異なる(C++、Python、R、SAS、Q/KDB+、CVXPY、Gurobiなど)
最後に

「金融工学」と一言で言っても、その中身は驚くほど多様です。
確率微分方程式という美しく難解な理論は、確かに金融工学の輝かしい主役の1つです。
けれども、その隣には、極値理論があり、コピュラがあり、凸最適化があり、ホークス過程があり ―― それぞれが、それぞれの現場で、静かに、しかし確かに、主役を務めています。
本記事が、皆様にとって、金融工学という広大な世界を見渡すための一枚の地図になれたなら、これ以上の喜びはありません。最後までお読みいただき、ありがとうございました。
改めて、本記事の到達点を一言で。
金融工学は「ブラックショールズの数式」だけではありません。
値段付け・リスク管理・ポートフォリオ最適化・市場マイクロ構造 という4つの大領域があり、それぞれで主役の数学が違います。
そして、データサイエンティストの皆様が持つ統計・最適化・機械学習のスキルは、その多くに直接つながっています。本記事が、専門書や論文を読む前の「地図」になれば幸いです。
最後に、本記事のテーマを一言で締めくくります。
金融工学とは、1つの数学でできているのではなく、「問題ごとに異なる数学が主役になる、巨大な連合体」である。
この記事は、「数学高校レベルのDS向け」シリーズの第2弾です。
以下の第1弾の記事の続きです。
上記の第1弾の記事と合わせてお読みいただくと、金融工学を縦(深さ)と横(広がり)の両面から理解する上で、お役立ていただけるかもしれません。