
【本記事の方針についての注意書き】
本記事は、専門書を開く前段階で全体像を直感的に掴むことを目的としています。
そのため、数学的な厳密性よりも、イメージのつかみやすさを優先しています。本文中の表現や説明には、厳密な定義・命題の前提条件・適用範囲を意図的に省略・簡略化している箇所があります。
本記事を読み終えた後で専門書に進む際に注意していただきたい厳密性とのギャップについては、末尾のAppendixにまとめてありますので、あわせてお読みください。
この記事のゴール ― 一本の道でつなげる
本論に入る前に、この記事がどこからどこまでを一本の道でつないでいるかをお見せします。
測度論
↓(長さ・面積・確率を統一的に測る道具)
ルベーグ積分
↓(ギザギザな関数も積分できる枠組み)
ブラウン運動
↓(連続だが至るところ微分不可能なランダムパス)
伊藤積分
↓(dW で積分するための新しい積分)
伊藤の補題
↓(確率版の連鎖律、2次の項が残る)
ブラックショールズ方程式
↓(オプション価格を決める偏微分方程式)
Heston / Diffusion Models / 強化学習 / 物理 / 生物
専門書ではこの一本の道が、章をまたいで断片的に出てくるので「結局なんのためにこれを学んでいるんだっけ?」と迷子になりがちです。
本記事ではこの矢印を逆向きに辿れるように、各ステップで「なぜそれが必要なのか」をしつこく書きます。
はじめに: この記事の想定読者と読むメリット
想定読者
この記事は、以下のような方を想定しています。
- 高校理系の数学(数III、確率、簡単な微積分)を一度学んだことはあるが、もうほとんど忘れてしまったレベル
- 大学の解析学・微分方程式・偏微分方程式は未学習
- データサイエンスや機械学習の現場で働いており、金融工学や強化学習、生物統計、物理シミュレーションなど、確率微分方程式(SDE, Stochastic differential equation)が出てくる文献に出会って戸惑っている
- ブラックショールズ方程式や「伊藤の補題」という単語は聞いたことがあるが、何をやっているのか正直よくわからない
- いきなり専門書を開くと、「測度空間」「σ加法族」「ルベーグ可測」など、初手から心が折れる定義が並んでいて挫折した
この記事を読むメリット
この記事は定義の羅列をしません。専門書1冊目を読み始める前に、
- 測度論が「なぜ」必要なのか、それぞれのパーツが何のために存在するのかの地図を頭に描けるようになる
- ふつうの微分とどう違って、確率微分は何が"確率的"なのかが直感的にわかる
- 高校で習った積分と、ルベーグ積分・スティルチェス積分・伊藤積分の違いと使い分けがわかる
- 伊藤の補題が「結局何を言っているのか」がわかる
- ブラックショールズ方程式と、それ以外の社会科学・自然科学の確率微分モデルの全体像がわかる
- ここから何をどの順で勉強すればいいか、学習ロードマップが手に入る
- Pythonでどう実装するか、ライブラリ別の使い分けまで一気に俯瞰できる
専門書を読む前の「地図」になることを目的としています。厳密さよりも、気持ち・イメージ・つながりを優先します。
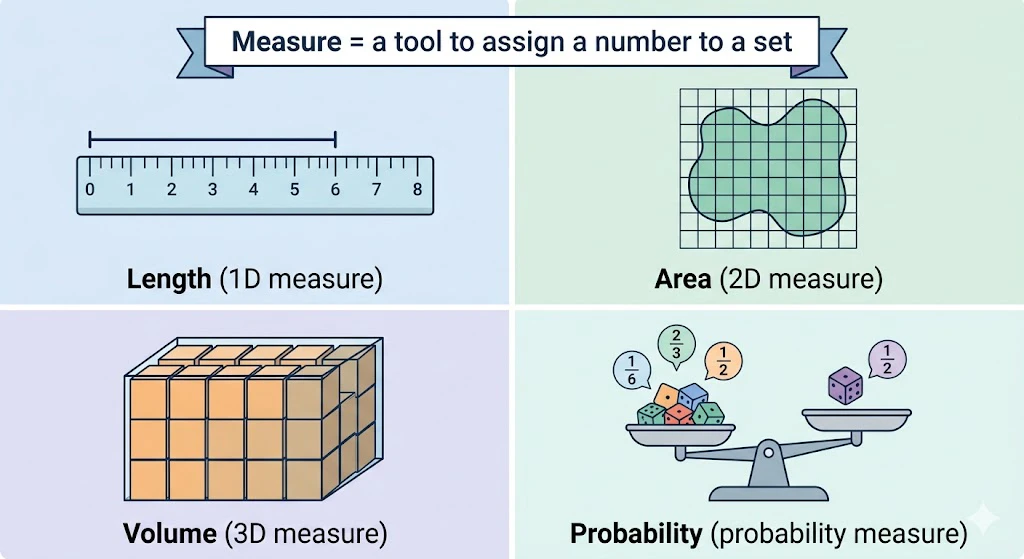
1. そもそも「測度論(そくどろん)」って何? ― 長さ・面積・確率を統一的に扱う道具
1-1. 専門書を開くと最初に出てくるアレ
金融工学や確率微分方程式の本を開くと、たいてい第1章でこういう記述に出会います。
確率空間 $(\Omega, \mathcal{F}, P)$ を考える。ここで $\Omega$ は標本空間、$\mathcal{F}$ は $\Omega$ の部分集合からなるσ加法族、$P$ は $\mathcal{F}$ 上の確率測度である。
ここで多くの人が本を閉じます。でも、本質を言ってしまえば、これは
「長さ・面積・体積・確率を、ひとつの統一的な道具で扱いたい」
というだけの話です。
1-2. 「測度」のイメージは「ものさし」
「測度(そくど。measure)」とは、文字通り、何かを測るための道具です。
- 線分の「長さ」を測る → 1次元の測度
- 図形の「面積」を測る → 2次元の測度
- 立体の「体積」を測る → 3次元の測度
- 事象の「起こりやすさ(確率)」を測る → 確率測度
つまり、長さも面積も確率も、ぜんぶ"集合に対して数を割り振る関数" だと考えれば同じ仲間です。
これを統一的に扱うのが測度論(そくどろん)です。
1-3. なぜ「集合」と「σ加法族」(シグマかほうぞく、σ-additive family of sets)が出てくるのか
「測る対象」は集合です。
たとえば、
- 「サイコロを振って偶数が出る」という事象 = ${2, 4, 6}$ という集合
- 「区間 $[0, 1]$」という集合
- 「気温が20度から25度の間」という集合
これらに対して「どれくらい起こりやすいか」「どれくらいの大きさか」という数値を対応させる必要があります。
ところが、全ての集合に綺麗に数を割り当てるのは数学的に無理だと20世紀初頭にわかりました(バナッハ=タルスキーのパラドックスなど)。そこで、
「測れる集合だけ集めた家族」= σ加法族(シグマかほうぞく)
を最初に決めておいて、そこに属する集合だけ測りましょう、というルールを作ったのです。
σ加法族は「測れる集合のメンバーシップ・クラブ」だと思ってください。
クラブに入っているメンバー(集合)にだけ、測度というスタンプ(数値)を押します。
1-4. 確率空間 の正体
確立空間 $(\Omega, \mathcal{F}, P)$の正体を見ていきましょう。
これでようやく、冒頭の式を理解できるようになります。
| 記号 | 名前 | イメージ |
|---|---|---|
| $\Omega$ | 標本空間 | 「起こりうる全部のシナリオ」の集合(例:サイコロなら${1,2,3,4,5,6}$) |
| $\mathcal{F}$ | σ加法族 | $\Omega$ の部分集合のうち「確率を割り当てられる集合」のクラブ |
| $P$ | 確率測度 | $\mathcal{F}$ のメンバーに対して、「起こる確率」という数値を割り振る関数 |
つまり「確率空間」 $(\Omega, \mathcal{F}, P)$ とは、
「① 起こりうるシナリオ全部」と「② そのうち確率を割り当てる対象」と「③ 割り当てる確率の値」の3点セット
というだけのことです。
1-5. Pythonで気持ちをつかむ
# 簡単な例:サイコロの確率空間
Omega = {1, 2, 3, 4, 5, 6} # 標本空間
# σ加法族(ここでは Omega の全部分集合 = べき集合)
from itertools import chain, combinations
def powerset(s):
return list(chain.from_iterable(combinations(s, r) for r in range(len(s)+1)))
F = [set(x) for x in powerset(Omega)] # σ加法族の例
# 確率測度 P:各集合 A に対して |A|/6 を返す関数
def P(A):
return len(A) / len(Omega)
# 「偶数が出る」事象
A = {2, 4, 6}
print(f"P(偶数) = {P(A)}") # → 0.5
print(f"P(全事象) = {P(Omega)}") # → 1.0
print(f"P(空事象) = {P(set())}") # → 0.0
このコードで、$(\Omega, \mathcal{F}, P)$ という3点セットの気持ちが少しつかめると思います。
2. なぜ「ふつうの微分」じゃダメ? ― 確率微分のキモチ
2-1. ふつうの微分は「滑らかな世界」を前提にしている
高校で習った微分を思い出しましょう。たとえば $y = x^2$ なら $\frac{dy}{dx} = 2x$ ですね。
ここで暗黙に仮定されているのが、
「関数が滑らか(=連続で、微小に動かしてもジャンプしない)」
ということです。微分の定義はそもそも、
$$
\frac{dy}{dx} = \lim_{\Delta x \to 0} \frac{y(x+\Delta x) - y(x)}{\Delta x}
$$
ですから、「$\Delta x$ を小さくすればするほど $\Delta y$ も小さくなる」ことを期待しています。
2-1-α. ブラウン運動ってそもそも何?
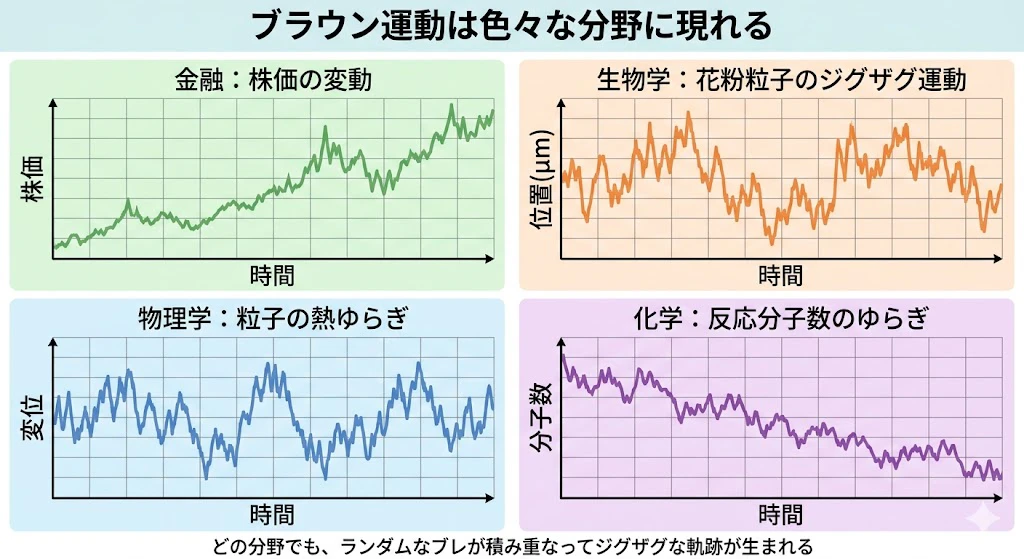
上の4枚は、金融(株価)・生物学(花粉粒子の運動)・物理学(粒子の熱ゆらぎ)・化学(反応分子数のゆらぎ) という、まったく違う分野で観測されるブラウン運動の例です。
縦軸の意味(株価、位置、変位、分子数) も 時間スケール もバラバラなのに、どれも同じように"ジグザグと不規則に揺れ続ける軌跡" を描きます。
これがブラウン運動 が、「分野を超えた共通言語」 になっている理由です。
ここから先で「ブラウン運動」という言葉が何度も出てきます。
そこで、そもそもブラウン運動とは何なのかを、想定読者の方が頭の中にちゃんとイメージを持てるよう、ここで、ゆっくりと説明します。
① 「花粉のジグザグ運動」 ― 名前の由来
1827年、イギリスの植物学者ロバート・ブラウン(Robert Brown)が、顕微鏡で水に浮かべた花粉の微粒子を観察していたとき、粒子が止まることなく、不規則にジグザグと動き回っているのを発見しました。
これが、「ブラウン運動」 の名前の由来です。
ブラウン自身は「なぜそんな動き方をするのか」を説明できませんでしたが、約80年後の1905年、若き日のアインシュタインが「水の分子が四方八方からランダムに花粉粒子にぶつかっているせいだ」と数学的に解明しました(これは相対性理論と並ぶ、彼の1905年の代表的論文のひとつです)。
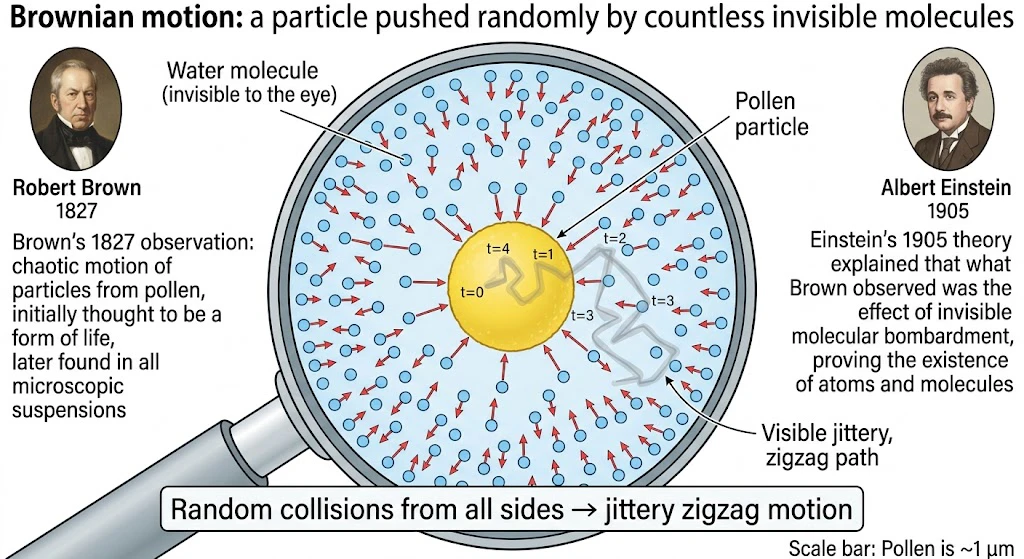
② ブラウン運動の本質:「無数の小さなランダムなショックの積み重ね」
このエピソードからわかる、ブラウン運動の本質は、
「目に見えないくらい小さなランダムな力が、ものすごく高い頻度で、四方八方から加わり続けたときに生まれる動き」
です。一発一発のショックはどっちに向くか分からない、ほぼ無視できるくらい小さなものです。
それでも、それがものすごく短い時間にたくさん積み重なると、粒子は不規則だけれども確かに動いていく――これが、「ブラウン運動」 と呼ばれる動きです。
実はこの考え方は、株価や金利、人口、化学反応、神経細胞の電位など、まったく違う分野の現象にも当てはまります。
たとえば株価は、
- 世界中の何百万人もの投資家が、同時に、ごく小さな売買判断を下している
- 1件1件はほぼ無視できる小さな影響だが、それが膨大に積み重なる
- 結果として、株価は不規則にジグザグと動いていく
という構造をしていて、本質的には花粉のブラウン運動と同じです。
ここから、「株価をブラウン運動でモデル化する」というアイデアが生まれたのです。
(最初に提案したのは、1900年のフランスの数学者ルイ・バシュリエです。
アインシュタインより5年早かったのですが、当時は誰も注目しませんでした)。
③ 数学的なブラウン運動 $W_t$ の3つの性質
物理現象から数学的なモデルに昇格させると、ブラウン運動 $W_t$(時刻 $t$ におけるブラウン運動の値)は次の3つの性質を持つものとして定義されます。いまは丸暗記する必要はありませんが、雰囲気だけ掴んでください。
-
出発点はゼロ:
$W_0 = 0$。時刻ゼロでは、まだどこにも動いていません。
-
増分は正規分布(=ガウス分布、釣鐘型の分布)に従う:
時刻 $s$ から時刻 $t$ の間に $W_t$ がどれだけ動いたか(=増分 $W_t - W_s$)は、平均0、分散 $t-s$ の正規分布に従います。
時間が経つほど、動きうる幅が広がっていきます。
-
過去と未来は独立:
いま $W_t$ がどこにいるかが分かっても、次にどっちに動くかは過去の動きとは無関係です。
「これまで上に動いてきたから、そろそろ下に戻るだろう」といった予測は一切立ちません。
この3番目の性質 が、ブラウン運動のランダムさの核心です。
日常感覚だと、「これだけ上がったんだから、そろそろ下がるはず」と思いがちですが、数学的なブラウン運動ではそれは完全に間違いです。
次の動きは過去とは独立に、毎回まったくのランダムです。
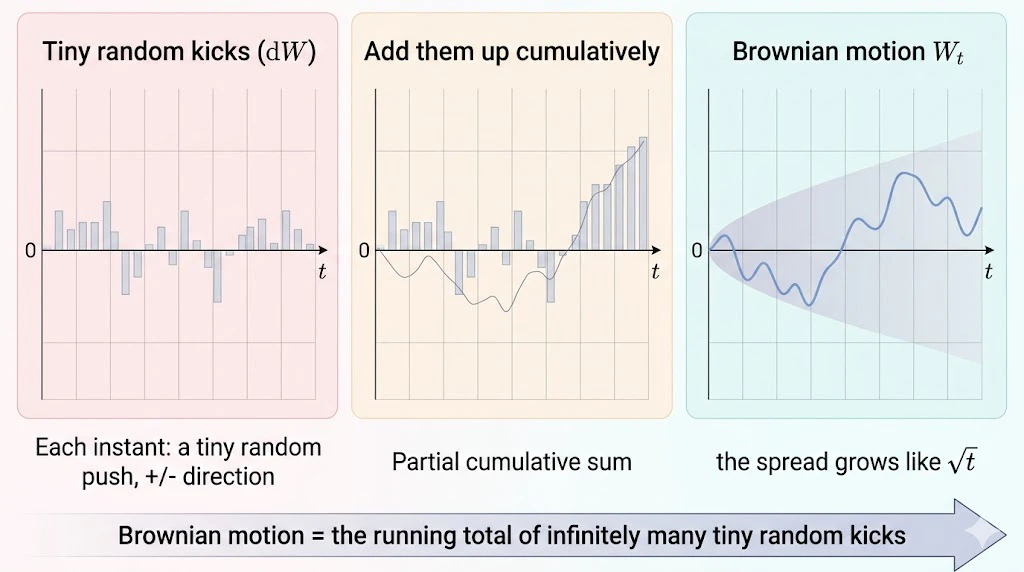
④ 「ノイズの累積」というイメージで眺める
もうひとつ便利なイメージは、
「平均0のランダムな数(ノイズ)を、無限に短い間隔で、無限に小さい刻みで、足し続けたものの軌跡」
です。実際、本記事のあとに出てくるPythonコードでブラウン運動を描くときも、
# 平均0、分散dtの正規乱数を発生させて、累積和を取る
dW = np.sqrt(dt) * np.random.randn(N) # 各時刻のランダムなブレ
W = np.cumsum(dW) # それを順に足し合わせていく
という、まさにこの「ランダムなブレを足していくと軌跡になる」というシンプルな仕組みで実装します。
⑤ なぜブラウン運動が現代数学・データサイエンスの中心にいるのか
ここがいちばん大事なポイントです。ブラウン運動は、
- 本質的には「ランダムなものをたくさん足し合わせた極限」なので、ありとあらゆる場面に自然に現れる(中心極限定理という大定理が、これを保証してくれます)
- 株価、金利、為替、人口、感染者数、化学反応、ニューロンの発火、機械学習の学習過程、画像生成AIの内部――ランダムな揺らぎが少しずつ積み重なる現象は、すべてブラウン運動を出発点にモデル化できる
そのため、本記事で扱う確率微分方程式(SDE)の主役であり、金融工学から物理学、生物学、生成AIまで、現代のあらゆる場面で「ランダムな時系列」を表現する共通言語になっているのです。
それでは、このブラウン運動が「ふつうの曲線とどう違うか」を、次の節で確かめていきましょう。
2-2. ところが、現実の時系列はギザギザ
株価のチャートを思い出してください。
秒単位、ミリ秒単位で見ても、ギザギザしていてどこを取っても滑らかではありません。
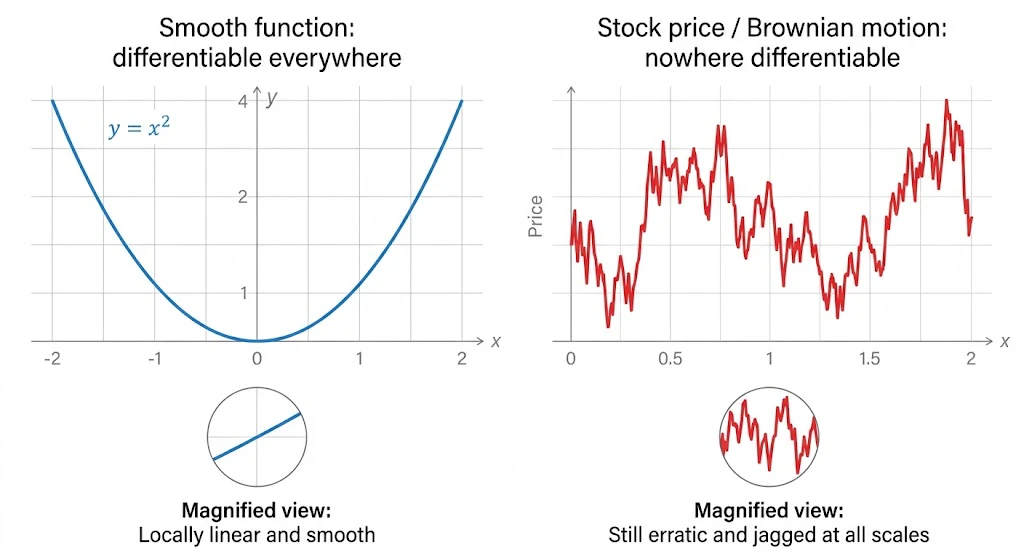
しかも、どんなに拡大してもギザギザは消えません。これがブラウン運動の重要な性質で、
「至るところで連続だが、至るところで微分不可能」
という、高校数学の感覚からすると、ちょっと ”ぎょっとする性質” を持っています。
2-3. 確率微分方程式(SDE)のキモチ
そこで、こんな書き方をします。
$$
dX_t = \mu(X_t, t), dt + \sigma(X_t, t), dW_t
$$
これが確率微分方程式(Stochastic Differential Equation, SDE)の基本形です。
読み方は、
| 部分 | 名前 | イメージ |
|---|---|---|
| $dX_t$ | 微小変化 | 次の瞬間に $X$ がどれだけ動くか |
| $\mu(X_t, t), dt$ | ドリフト項 | 「平均的に」どちらに動くか(決定論的なトレンド) |
| $\sigma(X_t, t), dW_t$ | 拡散項 | 「ランダムに」 どれだけ揺さぶられるか |
| $dW_t$ | ブラウン運動の微小増分 | 平均0、分散$dt$の正規乱数のようなもの |
要するに、
「次の瞬間の変化 = 平均的なトレンド + ランダムなブレ」
をひと続きの式で書いたものが SDE です。
2-3-α. なぜこれが「滑らかな世界」と決定的に違うのか
ここがこの記事でいちばん大事なポイントなので、少し時間をかけて説明します。
まず、ランダム項を取り除くとどうなるか
仮にいったん、$\sigma(X_t, t), dW_t$ の項を全部消してしまうとどうなるでしょう?
残るのは、
$$
dX_t = \mu(X_t, t), dt
$$
ですが、これは実は、高校で習った微分方程式そのものです。
たとえば $\mu = 1$ なら $\frac{dX}{dt} = 1$、つまり $X_t = t + \text{定数}$ という、ただ一直線に進むだけの軌跡になります。
$\mu$ を別の関数にすればもう少し複雑な曲線になりますが、いずれにせよ、
-
初期値 $X_0$ を決めれば、その後の軌跡は完全に1本に決まる(同じ初期値で何度実験しても、まったく同じ曲線がなぞられる)
-
その軌跡はどの点でも滑らかにつながっている(途中で急にギザギザになったりしない)
-
未来の値は、過去の値から原理的には計算できる
これが決定論的(deterministic) な世界の姿です。物理で習う「振り子の運動」や「ボールの放物運動」など、教科書の例題はすべてこちら側にいます。
ところが、ランダム項 $\sigma, dW_t$ が加わると、世界が3つの意味で変わります
第1の変化: 軌跡が1本に決まらない
ランダム項が入った瞬間 、同じ初期値 $X_0$ から出発しても、毎回ちがう軌跡を描きます。
それぞれの軌跡は、「ありえた未来のひとつ」を表しているにすぎません。
同じ初期値の株から100通りの未来をシミュレーションすれば、100通りの全く違う株価チャートが出てきます。
つまり、$X_t$ という記号が指しているのは、もはや「ある時刻 $t$ における1つの数値」ではなく、「ある時刻 $t$ に とりうる 値の 分布(=確率変数) 」です。
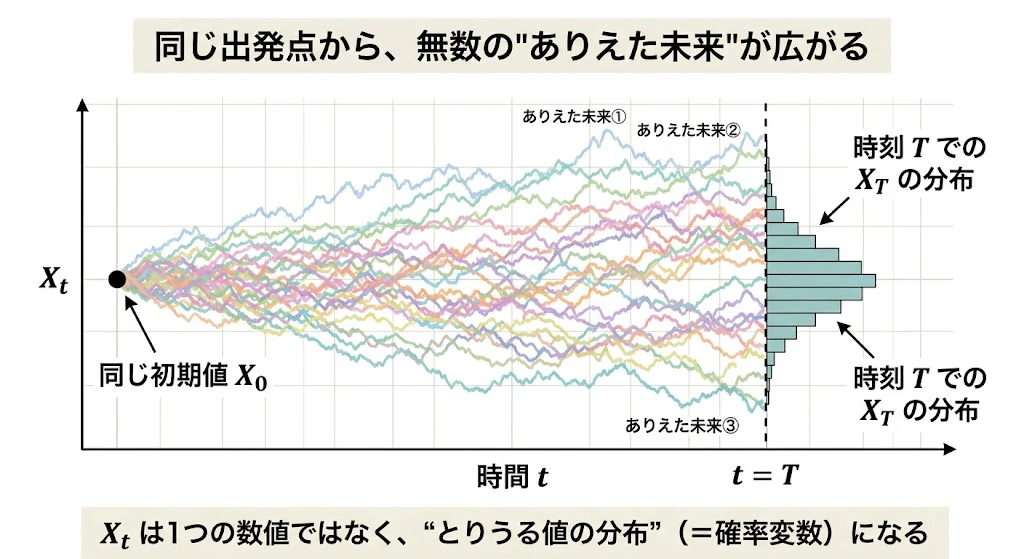
同じ初期値 $X_0$ から出発しても、ランダム項が入った瞬間に未来は1本に決まらず、無数の"ありえた軌跡"が扇状に広がります。
右側の縦向きヒストグラムは、ある特定の時刻 $T$ における値 $X_T$ の分布を表しています。
これが「$X_t$ は、1つの数値ではなく確率変数である 」という言葉の意味です。
第2の変化: 軌跡が"どこを取っても"滑らかでなくなる
決定論的な世界の軌跡は、グラフを拡大すれば拡大するほど、まっすぐな直線に見えてきます(=滑らか、微分可能)。ところがランダム項のせいで、
どんなに拡大しても、軌跡は同じくらいギザギザに見え続ける
という性質が出てきます。
専門的な言い方をすると、この性質は確率1で(=ほぼ間違いなく)成り立つことが数学的に証明されています。
具体的には、
- ブラウン運動 $W_t$ の軌跡は、確率1で、どの時刻においても微分不可能(=接線が定義できない)
- それでも連続ではある(=点と点はつながっている、ジャンプはしない)
という不思議な性質 を持ちます。
「至るところでつながっているのに、至るところで尖っている」
――高校数学の感覚からすると、こんな関数が存在することすら信じがたいですが、これがブラウン運動です。
「接線が定義できない」って、具体的にどういうこと?
ここがピンと来づらいと思うので、もう少しかみくだきます。
高校で習った滑らかな関数 $y = f(x)$、たとえば $y = x^2$ を思い浮かべてください。
曲線上のある1点を選んで、その点で接線を引いてみてください。
鉛筆を当てれば、ピタッと1本の傾きが決まるはずです。接線の傾きが「微分係数」、つまり「その点での変化の速さ」でした。
ところが、ブラウン運動の軌跡上のある1点を選んで、同じことをやろうとすると、どうなるでしょうか?
その点のすぐ右側を見ると、上にも下にも、いろんな方向にギザギザ動いている。
そのギザギザを「もっと小さい範囲で見れば直線に近づくはず」と思って範囲を狭めても、何度狭めても同じくらいギザギザのまま。
だから「この方向に進んでいる」と決められる1本の傾きが、いつまで経っても見つからない。
接線を引こうとすると、点 $P$ から考えうる傾きが無数にあって、どれを採用すべきかが永遠に決まらない。
これが、「接線が定義できない=微分不可能」の具体的な意味 です。
滑らかな関数なら1本の接線がスッと引けるのに、ブラウン運動では同じ点から無限の傾きの候補が放射状に伸びていて、どれにも絞れない――そんなイメージです(次に出てくる画像の下半分が、まさにこの対比を描いたものです)。
つまり、ブラウン運動の軌跡は「線としては確かにつながっているのに、各点で進む方向を1つに決められない 」という、普通の関数では絶対に起こらない奇妙な振る舞いをしているわけです。

上半分は、ブラウン運動をいくら拡大していっても、同じくらいギザギザが現れ続けることを示しています(=フラクタル的な性質)。
下半分は、滑らかな関数なら1本の接線が定義できるのに、ブラウン運動では同じ点から無数の傾きが考えられて接線が決まらないことを示しています。
それでも線そのものはつながっており(連続)、ジャンプはしません。「連続なのに微分不可能」という、高校数学の感覚にはない不思議な世界を、上下2段で視覚化したものです。
このため、高校で習った微分の定義
$$
\frac{dX}{dt} = \lim_{\Delta t \to 0} \frac{X_{t+\Delta t} - X_t}{\Delta t}
$$
は、ブラウン運動に対してはそもそも極限が存在しないので、まったく使えません。
だから、
ふつうの微分積分の道具一式を捨てて、確率微分積分という新しい道具一式を最初から作る必要がある
わけです。
本記事の冒頭の**「一本の道」** が、まさにこの新しい道具一式(測度論 → ルベーグ積分 → 伊藤積分 → 伊藤の補題) を組み立てるための道筋 になっています。
第3の変化: 「予測する」の意味が変わる
決定論的な世界では、「未来を予測する」とは「将来の正確な値 を計算する」ことでした。
確率的な世界では、それは原理的に不可能です。
代わりに、「未来を予測する」の意味が、
-
将来の値の期待値(平均的にどこにいるか)を計算する
-
将来の値が特定の範囲に入る確率を計算する
- 将来のリスク(=値のバラつき方)を計算する
といった、確率分布についての言明に置き換わります。
ブラックショールズ方程式が、「デリバティブ・オプション商品の時価」を計算するときに本当にやっているのも、まさにこの「将来の株価の分布 について、ある関数の期待値 を計算する」という作業です。
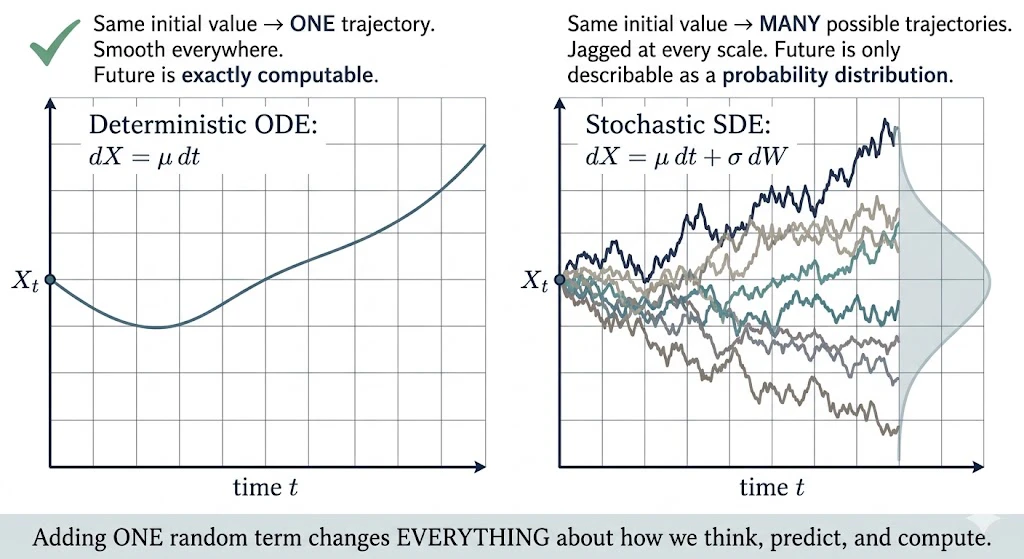
まとめると
ランダム項 $\sigma(X_t, t), dW_t$ を加えるという、見た目には小さな変更は、実は
| 決定論的時系列 $dX = \mu, dt$ | 確率微分方程式 $dX = \mu, dt + \sigma, dW$ | |
|---|---|---|
| 軌跡の本数 | 初期値から1本に確定 | 同じ初期値から無数の可能性 |
| 滑らかさ | 微分可能(接線が引ける) | 確率1で至るところ微分不可能 |
| 連続性 | 連続 | 連続(ジャンプはしない) |
| 「未来」の意味 | 値そのもの | 値の確率分布 |
| 必要な数学 | ふつうの微積分 | 測度論・ルベーグ積分・伊藤積分 |
という、世界観そのものが入れ替わるくらいの大変更を引き起こしているのです。
2-4. Pythonでブラウン運動を描いてみる
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
T = 1.0 # 終端時刻
N = 1000 # 時間刻みの数
dt = T / N
t = np.linspace(0, T, N+1)
# ブラウン運動 W_t をオイラー的に生成
# dW_t ~ N(0, dt) なので、標準正規 × sqrt(dt)
dW = np.sqrt(dt) * np.random.randn(N)
W = np.concatenate([[0], np.cumsum(dW)])
plt.plot(t, W)
plt.title("Sample path of Brownian motion W_t")
plt.xlabel("t"); plt.ylabel("W_t")
plt.grid(True)
plt.show()
このパスは「至るところで連続だが、至るところで微分不可能」というやつです。普通の微分はそもそも定義できないので、新しい積分・微分の枠組みが必要になります。それが伊藤積分であり、その背後を支えるのがルベーグ積分であり、測度論です。
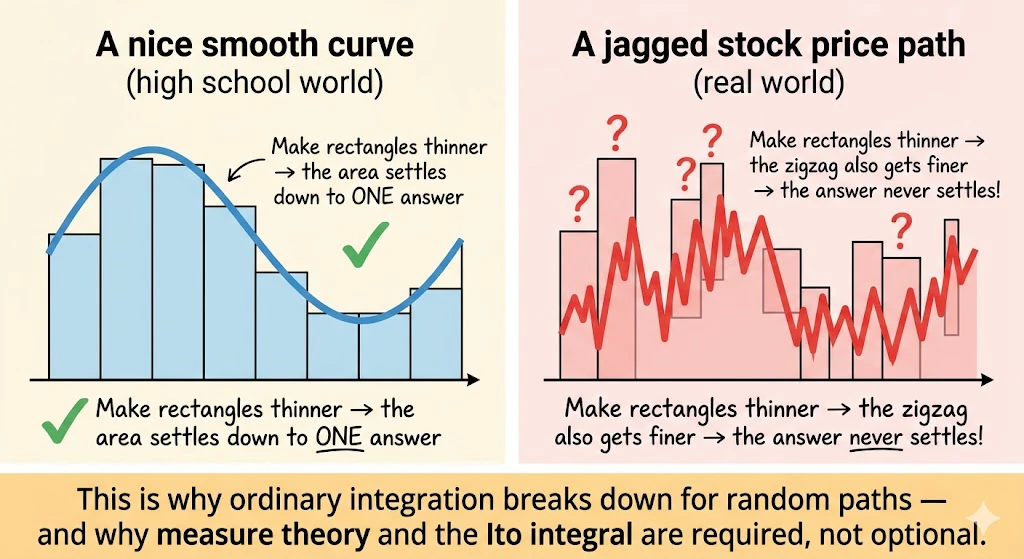
3. ルベーグ積分 ― 高校の積分と何が違う?「縦切り」と「横切り」
3-1. 高校で習った積分は「縦切り」

同じ関数 $y=f(x)$ の下の面積を求めるのに、短冊の向きが90度違うだけ――それが「縦切り」と「横切り」の本質的な違いです。
左(緑)は $x$ 軸を縦に分割して縦長の短冊を積み上げる高校式(リーマン積分)。
右(オレンジ)は $y$ 軸を横に分割して横長の短冊を積み上げるルベーグ式。結果として得られる面積は同じですが、関数がギザギザすぎると左のやり方が破綻する ので、右のやり方が必要 になります(次の節で説明します)。
$\int_a^b f(x), dx$ を高校では「リーマン積分」として習います。これは、
- $x$ 軸を細かく分割する
- 各短冊の高さ $f(x_i)$ × 幅 $\Delta x$ を足し合わせる
- 短冊を細くしていく極限を取る
という方法です。$x$ 軸を縦方向に切るので「縦切り」 と呼ばれます。
3-2. ルベーグ積分は「横切り」
ルベーグ積分は逆に、$y$ 軸(関数値)の方を切ります。
- 関数の値 $y$ を細かく分割する
- 「$f(x)$ がだいたい $y_i$ になる $x$ の集合」の測度(=横幅の合計) を測る
- $y_i \times (\text{その測度})$ を足し合わせる

3-3. なぜ「横切り」が必要なのか
「縦切りで困らないじゃん」と思うかもしれません。
確かに、$f(x) = x^2$ のような綺麗な関数なら縦切りで十分です。
ところが、
- 関数がギザギザすぎて、$x$ を少し動かすと値が激しく変動する
- 関数の値が取りうるのは0か1だけだが、その境界が複雑な集合(例:有理数の集合)
のようなケースでは、縦切りだと短冊の高さが定まらないことがあります。
一方、横切りなら「値が $y_i$ になる $x$ の集合の"大きさ"を測れさえすればOK 」になります。
だから測度論が必要になるわけ です。
つまり、「集合の大きさ=測度」を測る道具があれば、ルベーグ積分はできるという結論が得られます。。

横切りで考えると、「ある $y_i$ レベルで関数を横にスライスしたときに浮かび上がる $x$ の集合」は、バラバラに散らばった何個もの区間の集まりになることがあります(オレンジ色の部分)。
これが縦切りでは扱えなかった部分ですが――「この散らばった集まりの幅の合計」さえ測れる道具(=測度)があれば、ルベーグ積分は動き出します。
測度論は、この"金色のものさし"を、どんなにギザギザでバラバラな集合に対しても矛盾なく定義するための数学的な土台なのです。
「区間の長さに総和で十分じゃない?」という素朴な疑問への答え
ここで、想定読者の方の頭にはごく自然な疑問が浮かんでいるはずです。
「いや、ちょっと待って。
$x$ 軸上の区間の幅を測って足し合わせるだけなら、区間の終わりの値から始まりの値を引いて、それを全部足せばいいんじゃないの?
小学生レベルの算数で済むのに、なんでわざわざ"測度論"なんて大層な数学が必要なの?」
これはとても良い疑問です。
実は、関数 $f(x)$ が穏やかな場合は、本当にその通りです。
たとえば $f(x) = x^2$ のようななめらかな関数なら、ある $y_i$ レベルで横切ったとき浮かび上がる $x$ の集合は、せいぜい1〜2個のきれいな区間になります。引き算と足し算で問題なく測れます。
問題が起きるのは、もっと変なケースです。具体的にどんなケースかを見てみましょう。
① 「区間」と呼べない、もっと変な集合が現れる
たとえばこんな関数を考えてみてください:
「$x$ が有理数のときは $f(x) = 1$、$x$ が無理数のときは $f(x) = 0$」
これをディリクレ関数と呼びます。
横切り(=「$f(x) \geq y$ となる $x$ の集合」を測る)でこの関数を $y = 0.5$ のところで切ると、浮かび上がるのは「$[0, 1]$ 区間内のすべての有理数の集合」になります。
ところがこの集合は、もはや"区間"の形をしていません。
$[0, 1]$ 内の有理数は、無理数の海の中にスカスカに散らばっていて、「始まりと終わり」を持つ普通の区間が1個もないのです。
引き算する対象が、そもそも存在しません。
「小学生レベルの算数」で測ろうにも、引き算する両端の値がそもそも見つからないわけです。
それでも私たちは、この集合の"大きさ"を何らかの形で定義したい。
実は、「ルベーグ測度」 では、「$[0, 1]$ 内の有理数の集合の大きさは 0」と定義されます(有理数は可算個しかなく、無理数の海に比べると無視できるほどスカスカだから)。
この「区間でないものに対しても大きさを矛盾なく定義する」のが、まさに測度論の仕事です。
② 「集合の数」が無限個になっても矛盾なく扱える必要がある
もう一つの問題は、横切りで浮かび上がる集合が、バラバラの区間でも、その個数が無限になることがある、という点です。
たとえば、$x$ 軸上に細かい区間が「最初は幅1cm、次は幅0.5cm、次は0.25cm、…」と無限に並んでいるとします。1個1個の幅を引き算で求めて、全部足し合わせる――ここで、ある重要な問いが生まれます。
「無限個のものを"足し合わせる"って、本当に大丈夫なの? 答えがきちんと1つに定まる保証は?」
実は、小学生の算数の「足し算」は有限個を前提にしています。
無限個の足し算になると、
- 順番を変えたら合計が変わってしまうことがある
- 足しても足しても収束せず、発散してしまうことがある
- そもそも合計が定義できないことがある
といった思わぬ落とし穴が現れます。
測度論 は、「こういう条件を満たす集合なら、無限個に分かれていても合計が矛盾なく定義できますよ」という規則(=σ加法族 と 可算加法性 )を最初にきちんと決めることで、この落とし穴を回避しているのです。
第1章で、「σ加法族」というメンバーシップ・クラブの話 をしたのを覚えていますか?
あれが効いてくるのは、まさにこの場面です。
クラブのメンバー(=測れる集合)に限ってだけ、無限個に分割しても合計が一意に決まる、ということが数学的に保証されるのです。
③ じゃあなぜ確率論で必要なのか
「とはいえ、自分は変な集合は扱わないし、無限個に分かれた集合も扱わないから関係ない」と思われるかもしれません。
ところが、確率論をやり始めると、これらの"変な集合"が普通に出てきてしまうのです。
たとえば、
- 「ブラウン運動が時刻 $t$ までに一度も値0を下回らないようなパスの集合」
- 「ある株価が満期日までにある閾値に1度も触れないようなシナリオの集合」(バリアオプションの価格付けに必要)
こういう集合は、いざ調べてみると、素直な区間の形をしていない、ものすごく複雑な集合になっています。
確率論で期待値や確率を計算するというのは、こうした複雑な集合に対して「測度(=確率)」を割り当てる作業 ですから、素朴な引き算では絶対に届かないのです。
まとめると
| 素朴な「引き算+足し算」で測れるか | 測度論が必要か | |
|---|---|---|
| なめらかな関数の下の面積 | ○ 測れる | 不要 |
| 区間がいくつかバラバラに分かれている集合 | ○ 一応測れる(足し算するだけ) | 不要 |
| ディリクレ関数のように「区間でない集合」 | ✗ 引き算する両端がない | 必要 |
| 区間が無限個に分かれている集合 | △ 合計が一意に決まる保証がない | 必要 |
| ブラウン運動の複雑な事象(金融工学・物理・生物) | ✗ そもそも引き算では届かない | 必要 |
つまり、「ふつうの素直な集合を測るだけ」なら、たしかに測度論は要りません。
だから「測度論を持ち出してくるなんて、大げさだな」という直感は、半分は正しいのです。
しかし、確率論や金融工学で本当に扱いたい集合は、その素直な範囲を遥かに超えて複雑になる。
だからこそ、最初に測度論 という"何にでも対応できる頑丈な定義の枠組み"を用意しておかないと、議論が破綻してしまうわけです。
そして、確率の世界では、
$$
E[X] = \int_\Omega X(\omega), dP(\omega)
$$
のように、期待値そのものが「確率測度 $P$ に関するルベーグ積分」 として定義されます。
確率論をきっちりやるならルベーグ積分は必須なのです。
📖 コラム:「〇〇測度」にはどんなものがある?/そもそも数学者は何のために測度論を作ったのか?
ここまで「測度」「ルベーグ測度」と何度か出てきましたが、皆様の中には、こう思われる方もおられるかもしれません。
「ルベーグ測度以外にも測度ってあるの? あるなら、どんな種類があって、どう使い分けるの?」
「そもそもなぜ数学者は測度論を作ったの? 金融工学で使うために発明したわけじゃないよね?」
このコラムでは、専門書には書いてありますが、初学者向けの解説書には網羅的に記載されていない、測度論の"カタログ一覧表"と"数学者がそれを発見した動機・目的・経緯" を、ごく簡単かつ表面的に俯瞰しておきます。
気軽に読み飛ばしてもOKですが、知っておくと専門書を読むときに迷子になりにくくなります。
① 数学者が発見してきた「〇〇測度」カタログ
「測度」 とは、「集合に大きさを割り振る道具」でした。
実は、目的に応じていろんな〇〇測度 が考案されています。
代表的なものを一覧にしておきます。
| 測度の名前 | 一行で言うと | 主な使い道 |
|---|---|---|
| ルベーグ測度 | 「ふつうの長さ・面積・体積」を、変な集合まで含めて拡張したもの | 解析学の基本、リーマン積分を一般化する標準的な測度 |
| 計数測度 | 集合に含まれる要素の個数そのものを大きさとする測度 | 離散数学、組合せ論、級数の理論 |
| ディラックの測度 | 「ある1点に質量1が全部集中している」と定めた測度(点質量) | 物理(質点)、信号処理(インパルス応答)、確率論の離散分布 |
| 確率測度 | 全体の大きさが必ず1になるよう正規化した測度 | 確率論、統計学、金融工学 |
| ハール測度 | 群(=対称性を持つ空間)の上で、移動しても変わらない大きさを定める測度 | 抽象代数、表現論、調和解析 |
| ハウスドルフ測度 | フラクタル図形のような"穴あき・ギザギザ"な集合に分数次元の大きさを与える測度 | フラクタル幾何、力学系、画像解析 |
| ボレル測度 | 開集合・閉集合といった"標準的な集合"だけに大きさを定めた測度 | ルベーグ測度の前段階、確率論の基礎 |
| ラドン測度 | ボレル測度のうち、有限の範囲では大きさが有限になるもの | 関数解析、偏微分方程式 |
| スペクトル測度 | 行列・作用素の"スペクトル(=固有値の分布)"を測度として表現したもの | 量子力学、関数解析 |
| ガウス測度 | 正規分布を高次元・無限次元に拡張した測度 | 確率論、機械学習、ベイズ統計 |
| ウィーナー測度 | ブラウン運動のパス全体の空間に定義された測度(=「ランダムなパス1本1本に重みをつける」測度) | 確率微分方程式、伊藤積分の土台、金融工学 |
特に最後のウィーナー測度は、本記事の主役である確率微分方程式の根幹を支える測度です。
「ブラウン運動のサンプルパスの集合」という、想像を超えて複雑な対象に対しても、ちゃんと"大きさ(=確率)"を矛盾なく割り振れる、というのが20世紀前半の数学者ウィーナーの偉業でした。
② そもそも数学者は何のために測度論を作ったのか?
結論から言うと、金融工学のためでも、確率論のためでもありませんでした。
測度論 は、19世紀末〜20世紀初頭の純粋数学が直面した、ある根本的な行き詰まりを打開するために生まれたのです。順を追って説明します。
動機その1:リーマン積分が破綻するケースが見つかってしまった
19世紀半ばまで、積分といえばリーマン積分(=高校で習った縦切りの積分)でした。
これで十分やっていけると思われていたのですが、19世紀後半にフーリエ級数(=関数を三角関数の無限和で表す技術)が発展する中で、
「リーマン積分では、極限の操作と積分の操作が交換できないケースが頻発する」
という困った現象が次々と発見されました。
たとえば、「関数の列 $f_n(x)$ が $f(x)$ に収束するとき、$\int f_n$ も $\int f$ に収束してほしい」というごく自然な期待が、リーマン積分の枠組みでは簡単に裏切られてしまうのです。
これは数学者にとって致命的な問題でした。
なぜなら、極限と積分を自由に交換できないと、解析学のほぼあらゆる定理が成り立たなくなるからです。
動機その2:「測れない集合」の存在に気づいた
同じ頃、「集合論」というまったく新しい分野(カントール、1870年代)が登場し、「無限」を厳密に扱う技術が発展しました。すると、
「集合の中には、どんなに頑張っても"大きさ"を矛盾なく定義できないものがある」
ということがわかってきました(ヴィタリ集合の発見、1905年など)。
これは衝撃でした。
「全ての集合に長さを与える」という素朴な願いは、論理的に不可能だったのです。
動機その3:ルベーグの大発明(1902年)
これを解決したのが、フランスの数学者アンリ・ルベーグでした。
彼は博士論文(1902年)で、
「全ての集合は無理でも、"測れる集合"の家族(=σ加法族)を最初にちゃんと決めておけば、極限と積分を自由に交換できる豊かな積分論が作れる」
ということを示しました。
これがルベーグ測度・ルベーグ積分です。
測度論は、純粋数学の内的な必要性から生まれたわけです。
動機は徹頭徹尾、
- リーマン積分の弱点を克服したい
- 「測る」という行為を論理的に矛盾のない形で定式化したい
- 無限を扱う新しい解析学の土台を作りたい
であって、「いずれ金融商品の値段を計算するため」とか、「画像生成AIのため」では、まったくありませんでした。
動機その4:そして確率論に応用された(1933年)
ルベーグ測度が登場してから約30年後の1933年、ソ連の数学者コルモゴロフが、
「確率って、要するに"全体の大きさが1になるように正規化した測度"のことじゃないか」
ということに気づき、確率論を測度論の上に乗せたのです(「確率論の基礎概念」という有名な論文)。
これによって初めて、「事象」「確率変数」「期待値」といった概念が、数学的に矛盾のない形で定義されました。
確率測度・ウィーナー測度・伊藤積分・確率微分方程式・ブラックショールズ方程式は、すべてこの1933年のコルモゴロフの仕事の上に成り立っています。
つまり、こういう物語です。
時系列で並べると、
1854年:リーマン積分(B.リーマン)
↓
1870年代:集合論の登場(カントール)
↓
1900年前後:リーマン積分の限界が次々発覚/測れない集合の発見
↓
1902年:ルベーグ測度・ルベーグ積分(H.ルベーグ)
↓
1923年:ウィーナー測度=ブラウン運動の数学化(N.ウィーナー)
↓
1933年:確率論を測度論で公理化(A.コルモゴロフ)
↓
1944年:伊藤積分(伊藤清)
↓
1973年:ブラックショールズ方程式(F.ブラック、M.ショールズ、R.マートン)
↓
2020年代:拡散モデル(Diffusion Models)でAI画像生成に応用
純粋数学者が「リーマン積分の弱点を直したい」というだけの動機で作った道具が、60〜100年以上のタイムラグを経て、金融市場の値付け、AI画像生成、薬剤設計、神経科学まで、現代社会のほぼあらゆる領域を支える共通言語になっている
―― これが測度論の物語 です。

上の年表は、純粋数学の内的な問題意識から始まった測度論が、約100年以上かけて金融工学やAIの基盤になっていった様子を視覚化したものです。
1902年のルベーグの仕事がターニングポイントで、ここから30年後にコルモゴロフが確率論を測度論で書き直し、さらに40年後に伊藤の補題とブラックショールズ方程式が現れ、そして最近の20年代に拡散モデル(生成AI)として再発見されています。
「実用のために作られた数学ではなく、純粋数学が後から実用に呼ばれた」
――この順序が、現代数学のひとつの典型的なパターンです。
コラムまとめ :
測度論は、「変な集合の大きさを矛盾なく測りたい」という純粋数学者の探究心から生まれた道具です。そして、その豊かさのおかげで、確率・統計・物理・金融・AIといった、もともと考えてもいなかった応用先で「ぴったり当てはまる道具」として再発見され続けています。
だから本記事を学ぶことは、単に金融工学のためではなく、**「現代の応用数学の共通言語を手に入れること」**でもあるのです。
3-3-α. 測度論が「趣味」ではなく「必要」になる瞬間
ここでひとつ強調しておきたいことがあります。
よく「測度論なんて数学者の趣味的なお遊びだろ? 仕事で使うときは、Pythonで小さな時間刻みのループを回して数値計算すれば十分じゃないか」という声を聞きます。
この感覚は半分正しくて、半分は致命的に間違っています。
たしかに、「とにかく動くプログラムを書いて答えの数字さえ出せればいい」という場面では、測度論を知らなくても困りません。
しかし、その先に進もうとした瞬間に、測度論はどうしても必要になります。
その理由を、ここでかみくだいて説明します。
ふつうの積分は「滑らかな曲線」専用の道具
高校で習ったリーマン積分(=縦切りの積分)は、関数のグラフを縦の短冊で切って足し合わせるものでした。
これがうまくいくのは、グラフが滑らかか、せいぜい途中で何回か飛び跳ねる程度の関数だけです。
ところが、株価のように「秒単位でも、ミリ秒単位でも、どこまで拡大してもギザギザが消えない」ような動き(これを本記事ではブラウン運動 と呼んできました)に対しては、
短冊の幅を細かくしていけばいくほど、グラフのギザギザもどんどん細かく見えてきてしまい、短冊の高さが定まらない
という現象が起きます。
これを数学の専門用語では、「有界変動ではない(=パスが上下に動いた距離の合計が、いくら時間を細かく切っても無限大に発散してしまう)」と呼びます。
日常語で言えば、「グラフが上下に揺れすぎていて、どんなに目を凝らしても1本の曲線として扱えない」 ということです。
その結果、$\int f, dW$ という形の積分(=「ブラウン運動の微小増分 $dW$ を重みにして $f$ を足し合わせる」)をリーマン式に定義しようとすると、時間軸をどう切るかによって答えが変わってしまい、ひとつの値に落ち着きません。
リーマン積分の枠組みではそもそも定義できないわけです。
つまり、
リーマン積分では「ギザギザすぎる確率的な動き」を扱えない。
だから金融工学では、ルベーグ積分と、それを裏で支える測度論が"趣味"ではなく"必要"になる。
測度論を知らないと、どこで壁にぶつかるか
具体的には、こんな場面で「ライブラリを呼ぶだけの理解」では足りなくなります。
- ブラックショールズ方程式がなぜあの形をしているのか、自分の言葉で導出できるようになりたいとき
- 「リスクに対して中立な世界での値段付け」(後の章でブラックショールズの導出に出てきます)の論理を、ちゃんと理解したいとき
- 新しいモデル(Heston、SABR、ジャンプを含むモデルなど、第6章で登場します)の論文を読んで、仮定が現実に合っているかを自分で判断できる ようになりたいとき
これらを目指す瞬間に、測度論は飾りではなく、議論を組み立てる土台そのものになります。
逆に言えば、「とりあえずライブラリを呼んで価格の数字さえ出れば満足」なら測度論は要りません。
この記事を読まれているあなたが知りたいのは、おそらく前者の方だと思います。
3-4. 積分にはいろんな種類がある
ここまでで2種類出てきましたが、実は積分にはもっと種類があります。
ごく簡単に整理します。
| 積分の名前 | 何を切る? | 何に対して積分する? | 典型的な利用シーン |
|---|---|---|---|
| リーマン積分 | $x$ 軸(縦切り) | 通常の長さ $dx$ | 高校〜大学初等の解析、物理(運動方程式など) |
| ルベーグ積分 | $y$ 軸(横切り) | 一般の測度 $d\mu$ | 確率論、関数解析、フーリエ解析 |
| スティルチェス積分 | $x$ 軸(縦切り) | 別の関数 $g(x)$ の増分 $dg(x)$ | 確率分布の期待値、累積分布関数 |
| ルベーグ=スティルチェス積分 | $y$ 軸(横切り) | 関数 $g$ が定める測度 $d\mu_g$ | 一般の確率分布、ヘビーテール分布 |
| 伊藤積分(確率積分) | 時間軸 | ブラウン運動の増分 $dW_t$ | 確率微分方程式、金融工学、確率過程 |
| ストラトノヴィッチ積分 | 時間軸 | ブラウン運動の増分 $\circ dW_t$ | 物理学、工学(座標変換に強い) |
3-5. スティルチェス積分のキモチ
スティルチェス積分は、$\int f(x), dg(x)$ と書きます。
「$dx$」の代わりに「$dg(x)$」が来ているのがポイントで、これは
「$g$ がどれだけ増えたかを重みにして $f$ を足し合わせる」
という積分です。
たとえば、$g(x)$ が累積分布関数 CDF だと、$dg(x)$ は確率密度に対応するので、
$$
E[X] = \int x, dF(x)
$$
のように、離散分布でも連続分布でも同じ式で期待値が書けるという強力なメリットがあります。
3-5-α. ルベーグ積分までで解決した問題と、確率微分方程式に至る未解決の問題 ―― 伊藤はそこに何を足したのか?
ここまでで、私たちは「測度論 → ルベーグ積分」という強力な道具一式を手に入れました。
でも、まだ確率微分方程式は解けません。なぜでしょうか?
伊藤清(いとう・きよし)名誉教授が、ルベーグ積分に、何を付け足したことで、確率微分方程式は解けるようになったのでしょうか?
ここを混乱したまま専門書に進む読者がとても多いので、地図の形で整理しておきます。

上の地図は、これから本節で解説する内容の全体像です。
①青のエリア(=ルベーグ積分まででわかっていたこと)→ ②赤のエリア(=ブラウン運動を重みにする積分を作ろうとしたときに立ちはだかった3つの壁)→ ③金色のエリア(=伊藤清が3つの決断でこれらを突破し、確率微分方程式に至った)、という3段階の旅路として、本節を読み進めてください。
いま自分が地図のどこを読んでいるかを意識すると、混乱せずに最後まで辿り着けます。
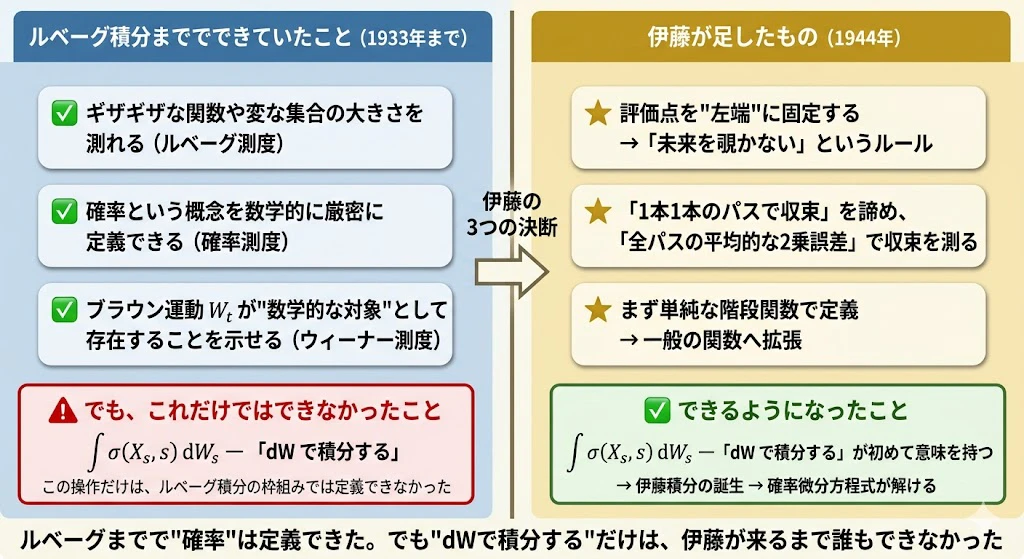
上の図は、本節の結論を1枚で先取りしたものです。
左:ルベーグ積分まででできていたこと(1933年までに数学者たちが整備した、確率を厳密に扱う土台)。
ただし、$\int \sigma, dW_s$ という「$dW$ で積分する」操作だけは、この土台の上では定義できませんでした。右:伊藤が1944年に足した3つのアイデア。
これによって初めて、確率微分方程式という現代の応用数学の主役が誕生しました。詳しい中身は以下で順に解説しますが、「左に何が足りなかったか/右で何が埋まったか」のひと言要約として、まずこの図を頭に入れておいてください。
(1) ルベーグ積分までで"解決した"問題
順番に振り返ってみましょう。19世紀末からルベーグ(1902年)、ウィーナー(1923年)、コルモゴロフ(1933年)まで、約30年かけて以下の問題はすべて解決されました。
| 解決済みの問題 | 解決した道具 |
|---|---|
| ① ギザギザすぎる関数や、変な集合の大きさを矛盾なく測りたい | ルベーグ測度・ルベーグ積分 |
| ② 確率という概念を、数学的に矛盾なく定義したい | コルモゴロフの確率公理(確率測度) |
| ③ 期待値 $E[X]$ を、離散分布でも連続分布でも同じ式で書きたい | 確率測度に関するルベーグ積分 |
| ④ ブラウン運動という"連続だが至るところ微分不可能"なランダム軌跡を、数学的に定義したい | ウィーナー測度(ブラウン運動のパス空間に乗せた測度) |
つまり、「確率」「ブラウン運動」「期待値」までは、1933年の時点ですべて定義済みだったのです。「ブラウン運動 $W_t$ という数学的な対象は確かに存在する」と、誰もが認める段階に達していました。
(2) でも、まだ残っていた問題 ―― 「dW で積分するってどういうこと?」
ここで多くの方が、こう思われるはずです。
「ちょっと待って。
3-3 で、ルベーグ積分は横切りでギザギザな関数も扱えるって言ってましたよね?
ブラウン運動はギザギザだから、ルベーグ積分にすれば積分できるんじゃないの?」
これはとても重要な疑問なので、上記の疑問に、正面から答えさせていただきます。
実は、ルベーグ積分が解決したのは「グラフの縦の動きがギザギザでもOK」という話でした。
ところが、確率微分方程式でやりたいのは、まったく別のことです。
ふつうの足し算で考えてみましょう。
たとえば「身長 × 1人 + 身長 × 1人 + 身長 × 1人 + ...」のように、何かを足し合わせるとき、私たちは普通、「1人」という単位(モノサシ)が、いつも同じ大きさだと思っています。
ふつうの積分も、まさにこの感覚です。
- 高校で習った積分は、「グラフの値 × 短い時間」を全部足し合わせるもの
- このとき、「短い時間」というモノサシは、いつも同じ大きさ(たとえば 0.001秒ずつ)
ルベーグ積分も同じです。モノサシの大きさは一定で、その「モノサシで測られる対象」がギザギザでも大丈夫にした、というのがルベーグの仕事でした。
ここで重要な注意があります。
ふつうの積分 $\int f(x), dx$ では、
- $dx$ は「X軸の幅」(=モノサシの幅)
- $f(x)$ は「Y軸の高さ」
でした。
そのため、皆様の頭の中には、「モノサシ=X軸の幅」というイメージが頭に染み付いているのではないでしょうか?
(私も確率微分方程式を学び始めたとき、そのように固定観念として思い込んでいました)
ところが、伊藤積分 $\int f, dW$ では、
- $dW$ は「X軸の幅」ではなく、「ブラウン運動の Y 軸方向の増分」
なのです。
つまり、$dW$ という「重み」は、X軸の幅ではなく、Y軸方向のランダムな増分です。
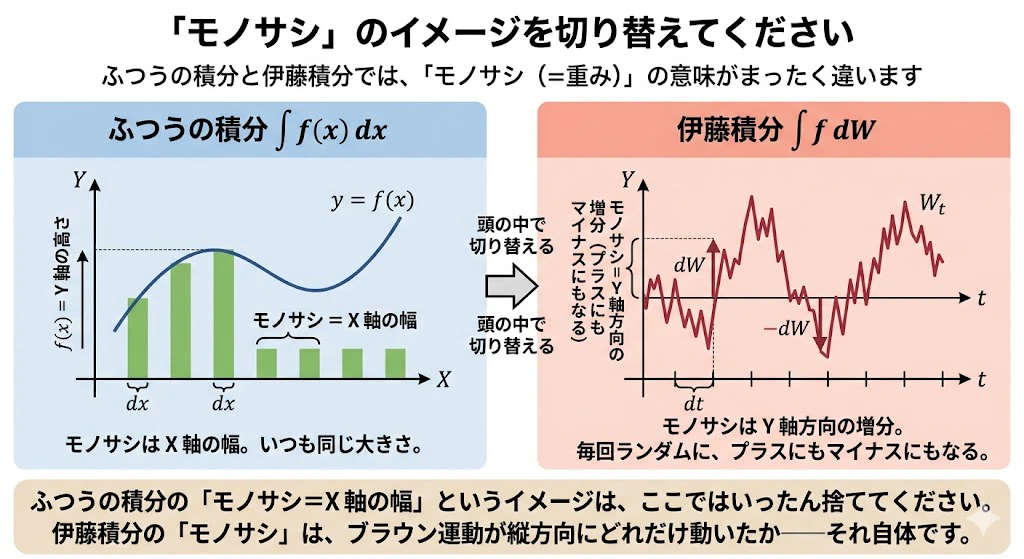
「モノサシ」という言葉を使っていますが、ふつうの積分のときの「X軸の幅」というイメージは、ここではいったん捨ててください。
伊藤積分での「モノサシ=重み」は、ブラウン運動が縦方向にどれだけ動いたかを意味しています。
ここでまた疑問が湧いてくるはずです。
「X軸を $dt$ ずつ進めながら、Y軸方向の増分 $dW$ を毎回掛けて足し合わせる…って、それ、ルベーグ積分でもできるんじゃないの?
ルベーグ積分でも、X軸(時間)を $dt$ ずつ進めながら $f(t)$ を毎回掛けて足し合わせるよね?
$f(t)$ のところに $dW$ を入れたら、それでルベーグ積分で済むのでは?」
これは、本記事のもっとも重要なポイントです。
実は、ルベーグ積分でできるのは、「足し合わせる対象 $f(t)$ が、ある決まった関数」のときだけです。
たとえば、
- $f(t) = t^2$ ―― 時刻 $t$ を入れれば、値が一意に決まる関数
- $f(t) = \sin(t)$ ―― 同じく、時刻を入れれば値が決まる
これらは、時刻 $t$ を決めれば、$f(t)$ の値が1つに確定するので、ルベーグ積分で扱えます。
ところが $dW$ は、そうではないのです。
時刻 $t$ を決めても、$dW(t)$ の値は1つに決まらないのです(確率論的に決まります)。
毎回実験するたびに、$t = 0.001$ のときの $dW$ が、ある時は $+0.03$、別の時は $-0.05$、また別の時は $+0.01$ になります。
$dW$ は「決まった関数」ではなく、「サイコロを振った結果」が時刻ごとに並んでいるだけなのです。
ここがルベーグ積分との決定的な違い
| ルベーグ積分 | 伊藤積分 | |
|---|---|---|
| 足し合わせる対象 | 時刻 $t$ で値が1つに決まる関数 $f(t)$ | 時刻 $t$ で値が1つに決まらないランダムな量 $dW$ |
| 時刻を決めたら | 値が確定する | サイコロを振らないと値が決まらない |
| 同じ計算を何度繰り返しても | 毎回同じ答え | 毎回違う答え |
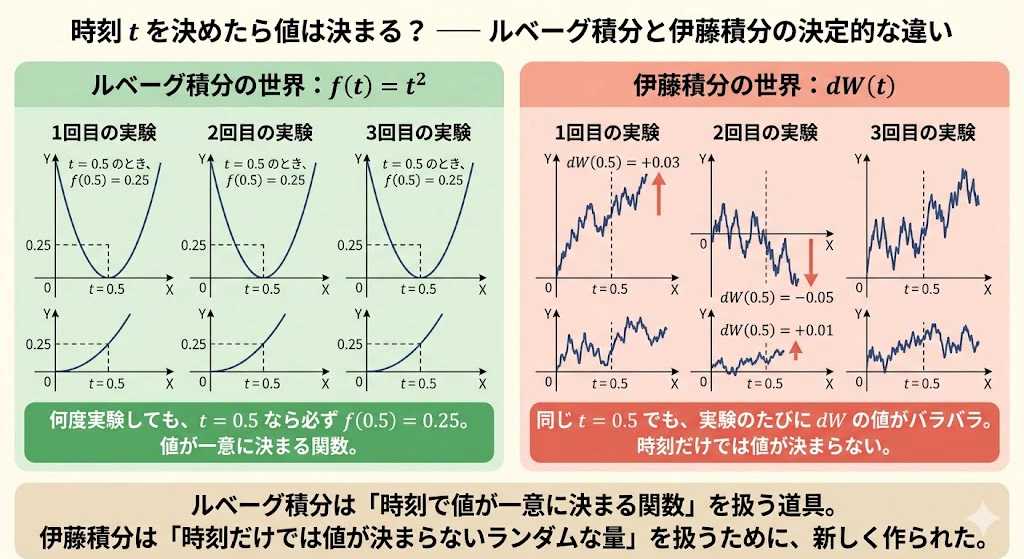
ルベーグ積分は、$f(t)$ の値が時刻に対して一意に決まることを前提にしています。
ところが $dW$ は、時刻だけでは値が決まらない。だからルベーグ積分の枠組みでは、そもそも「何を足し合わせるのか」が定義できないのです。
伊藤積分は、この「時刻だけでは値が決まらないランダムな量」を、ちゃんと足し合わせるために作られた、まったく新しい積分です。
これが、伊藤積分がルベーグ積分の単なる延長ではなく、まったく新しい道具として必要になった理由です。
伊藤積分がとった解決策(アプローチ)
それでは、伊藤積分は、この問題をどう解決したのでしょうか? そのアプローチの全体イメージを簡単に説明します。
伊藤清が見つけた解決策は、ひと言で言えば次の3つの工夫を組み合わせるアプローチでした。
工夫① 「1本ずつ」ではなく「みんなで平均」で考える
ブラウン運動は、実験するたびに違うジグザグの軌跡(=サンプルパス)を描きます。
1本1本のパスを真面目に追いかけようとすると、どれも荒れすぎていてうまく足し算ができません。
そこで伊藤は、1本1本にこだわるのをやめて、「無数のパスを集めてきて平均で考える」 ことにしました。
たとえるならば、「1人ひとりの株式トレーダーの成績を細かく追跡する」のではなく、「市場全体の平均的な振る舞い」を見る、というイメージです。
個々のパスは荒れていても、集団全体の平均で見れば、ちゃんと素直に振る舞ってくれる――この性質を利用します。
💡 専門書での表現:
この「全パスにわたって平均した2乗誤差で収束させる」という考え方は、専門書では「$L^2$ 収束(エル・ツー収束、2乗平均収束)」や「$L^2$ ノルムでのコーシー列の極限」という用語で記述されています。また、ブラウン運動の「動いた距離を2乗して足し合わせると有限値になる(=1乗で足すと無限大に発散するのに、2乗なら大丈夫)」という性質は「二次変分(quadratic variation)」という用語で出てきます。
この二次変分こそが、伊藤積分が「2乗の意味で」収束させる理由の根本です。
📖 コラム:工夫①は、統計力学の発想そのもの
ここで鋭い読者の方は、こう気づかれたかもしれません。
「1本1本を追跡せず、集団の平均で扱う」って、それ、統計力学そのものでは?
その直感は、ど真ん中で正しいです。
実は、ブラウン運動そのものが、もともと統計力学から生まれた概念です。時系列で整理すると、
- 1827年:ロバート・ブラウンが花粉粒子のジグザグ運動を観察
- 1905年:アインシュタインが「水分子が四方八方からランダムにぶつかっているから」と統計力学的に説明
- 同じ1905年:スモルコフスキーも独立に同様の理論を展開
- 1908年:ペランが実験的に検証(後にノーベル賞)
つまり、ブラウン運動は最初から、「無数の分子の集団的な振る舞いを、統計的に扱う」 という統計力学の発想で生まれたのです。
工夫①と統計力学の対応
統計力学 伊藤積分の工夫① 個別 1個の分子の運動は追跡不可能(複雑すぎる) 1本のパスは荒れすぎて扱えない 集団 無数の分子の集団的振る舞いを統計平均で扱う 無数のパスの集団的振る舞いを平均($L^2$)で扱う 基本量 温度・圧力・エントロピー(=集団の平均量) 期待値・分散・二次変分(=集団の平均量) 「個別では扱えない複雑な対象を、集団の統計平均で扱う」――この発想が、両者に共通する根本思想です。
さらに深いつながり:フォッカー=プランク方程式
工夫①と統計力学の関係は、ただの「似ている」ではなく、数学的に同じ構造を持つことが知られています。
具体的には、伊藤の確率微分方程式 $dX_t = \mu, dt + \sigma, dW_t$ に従う粒子があったとき、その確率密度関数 $p(x, t)$ の時間発展(=「時刻 $t$ で粒子がどの位置にいる確率がどれくらいか」が時間とともにどう変わるか)を記述する偏微分方程式は、
\frac{\partial p}{\partial t} = -\frac{\partial}{\partial x}(\mu p) + \frac{1}{2}\frac{\partial^2}{\partial x^2}(\sigma^2 p)という形になります。これをフォッカー=プランク方程式(Fokker-Planck equation) と呼び、統計力学の主役の方程式の1つ です。
つまり、
- 伊藤の確率微分方程式:1本1本の粒子のパスを追跡する視点
- フォッカー=プランク方程式:集団全体の確率分布の時間発展を追跡する視点
という、同じ物理現象の「個別 vs 集団」の2つの見方が、数学的にちゃんと対応しているのです。
ランジュバン方程式との対応
統計力学では、熱浴の中で揺さぶられる粒子の運動を記述する方程式として、
m\ddot{x} = -\gamma \dot{x} + \sqrt{2\gamma k_B T}\, \xi(t)というランジュバン方程式(Langevin equation) が古くから使われています($\xi(t)$ がランダムな熱揺らぎ、$k_B$ がボルツマン定数、$T$ が温度)。
これは見た目こそ違いますが、伊藤の確率微分方程式の特殊な形そのものです。ランジュバン方程式の $\xi(t), dt$ が、伊藤の言葉では $dW_t$(ブラウン運動の微小増分)に対応しています。
物理学者ランジュバンが1908年に直感的に書いた式が、伊藤の理論によって数学的に厳密に意味付けられた、と言ってもよいでしょう。
まとめ
- ブラウン運動そのものが、統計力学の発想から生まれた
- 工夫①の「集団平均で考える」 思想は、統計力学そのもの
- 伊藤の確率微分方程式 ↔ フォッカー=プランク方程式は、同じ物理現象の「個別 vs 集団」の2つの見方
- 物理学者ランジュバンの直感的な式を、数学的に厳密化したのが伊藤の理論
伊藤積分は、純粋に数学的な動機から作られた道具ですが、そのアプローチの根本にある「集団の統計平均で扱う」という発想は、物理学者が約100年かけて磨き上げてきた統計力学の方法論と、本質的に同じものだったわけです。
現代では、物理(統計力学)・金融(伊藤積分)・機械学習(拡散モデル) が、すべてこの共通の言語の上で会話できるようになっています。
着想の由来について(史実の確認):
伊藤清の伊藤積分の着想について、本人の論文・回顧録から確認できる動機は、主に以下の2つです。
① コルモゴロフ(1933年)が公理化した確率論の枠組みの上で、確率過程の理論を厳密に構築したかった
② マルコフ過程の解析的理論(コルモゴロフ前進方程式・後退方程式)を、もっと直接的に「サンプルパスの言葉」で扱いたかった
統計力学のブラウン運動の理論(アインシュタイン1905年、スモルコフスキー、ランジュバン1908年など)は、当時すでに確率論の標準的な対象として認識されていたため、間接的な影響は当然あったと考えられます。
一方、量子力学からの直接的な影響パスは、史実として確認できませんでした。同時代の量子力学(1925〜1930年代の本格的整備)と伊藤積分(1944年)には時期的な重なりがありますが、伊藤本人が量子力学の文献から着想を得たという記録は、現時点では見つけられていません。
(ファインマンの経路積分(1948年)が後にウィーナー測度の言葉で再定式化され、量子力学と確率微分方程式が深く結びつくのは、伊藤積分の登場よりも後の話です)
工夫② 「未来を覗き見しない」ルールを最初に決める
ふつうの積分は、区間の中の「どこで関数の値を読み取るか」を自由に選べました(左端でも、中点でも、右端でも答えは同じ)。
ところが $dW$ 積分では、評価点を変えると答えが変わってしまいます。
そこで伊藤は、「区間の左端の値だけを使う」というルールに固定しました。
これは現実世界の感覚で言えば、「今日の取引判断は、今日までに観測できた情報だけで決める。明日の株価を覗き見してから今日の判断を下す(=インサイダー取引)のは反則」というルールに対応します。
左端だけ使う、という単純なルールを最初に決めることで、答えが1つに定まるようになりました。
💡 専門書での表現
この「未来を覗き見しない」という性質は、専門書では「適合過程(adapted process)」または「フィルトレーション $F_t$ に適合的」という用語で記述されています。
また、「時刻 $t$ までに観測できた情報の全体」という概念は「フィルトレーション(filtration)」と呼ばれ、ふつう ${F_t}_{t \geq 0}$ という記号で書かれます。
専門書を開くと、確率空間が $(\Omega, F, {F_t}, P)$ という4点セットで書かれているのを目にしますが、この ${F_t}$ が「時刻ごとに増えていく情報の量」を表しています。
工夫③ まず「階段」で考えて、その先に進む
いきなり「ジグザグに暴れる関数」を相手にすると、定義そのものが書けません。
そこで伊藤は、まず「階段状の単純な関数」だけで伊藤積分を定義しました(階段状なら、ふつうの足し算で済みます)。
そして、一般のジグザグな関数は、「無数の階段の積み重ね」で近似できるので、その極限として伊藤積分を拡張定義したのです。
「複雑なものを直接扱うのではなく、簡単なもので近似して、その極限を取る」というのは、ルベーグ積分でも使われた数学の王道テクニックです。
💡 専門書での表現:
この「階段状の単純な関数」は、専門書では「単純過程(simple process)」または「初等過程(elementary process)」という用語で記述されています。
そして、「階段関数で定義したものを、極限を取って一般のランダム量に拡張する」という構成は、「稠密な部分集合での定義 → 全体への拡張」という、ルベーグ積分でも使われる標準テクニックです。
この拡張手続きの正当性を保証するのが伊藤の等長性(Itô isometry) という重要定理で、「$L^2$ 空間での距離が、積分の前後で保たれる」ことを述べています。
まとめ
この3つの工夫――
-
1本ずつではなく集団の平均で考える(→ $L^2$ 収束、二次変分)
-
左端の値だけを使う(未来を覗かない)(→ 適合過程、フィルトレーション)
- 階段関数から一般のランダム量へ拡張する(→ 単純過程、伊藤の等長性)
によって、「時刻だけでは値が決まらないランダムな量」でも、ちゃんと足し算が定義できるようになりました。
これが、伊藤積分の正体です。

専門書を開くと、上記の3つが冒頭の何十ページにわたって、定義・定理・証明の形で順番に積み上げられていきます。本記事のここまでの理解があれば、「ああ、これは工夫①の話か」「これは工夫②の話か」と、自分が読んでいる場所が記事のどこに対応するかが見えるようになるはずです。
詳しい中身はこの後の節で順を追って説明していきますが、まずは全体像として、この3つの工夫が伊藤積分の正体だと頭に入れておいてください。
では、この「時刻だけでは値が決まらないランダムな量 $dW$」を使って、確率微分方程式が実際に何をやっているのか、具体例で見てみましょう。
第2章で出てきた確率微分方程式の式を、もう一度書いてみます。
$$
dX_t = \mu(X_t, t), dt + \sigma(X_t, t), dW_t
$$
このうち、右辺のランダムなブレを表す部分:
$$
\sigma(X_t, t), dW_t
$$
を、時間に沿って全部足し合わせる(=積分する)のが、確率微分方程式の右辺の本当の意味です。
株価の例で言うと、確率微分方程式の右辺は、毎日次の掛け算を計算して、それを1年間ぶん全部足し合わせる操作です。
その株のもともとの動きやすさ × 今日のサイコロの目
| 掛け算の左側 | 掛け算の右側 |
|---|---|
| その株のもともとの動きやすさ(標準偏差=ボラティリティ) | 今日のサイコロの目(ブラウン運動が動いた量) |
| その株の体質を表す数値。値動きが激しい株は大きく、穏やかな株は小さい。毎日同じ値 | 市場が今日たまたまどっちにどれくらい動かしてきたか。毎日ランダムに変わる(ある日は +0.04、別の日は -0.07、その次は +0.01...) |
ところがこのモノサシ、よく見ると、毎回サイズがバラバラなのです。
- ある瞬間は「ブラウン運動が +0.03 動いた」
- 次の瞬間は「ブラウン運動が -0.05 動いた」
- その次は「ブラウン運動が +0.01 動いた」
このように、プラスにもマイナスにも、毎回ランダムに大きさが変わるモノサシで、私たちは足し合わせようとしているのです。

ルベーグ積分は、「測られる対象」がギザギザでも大丈夫にした道具でした。
ところが今回ぶつかっているのは、「測られる対象」ではなく、「測るモノサシ」そのものがギザギザに暴れるという、まったく違うタイプの問題です。
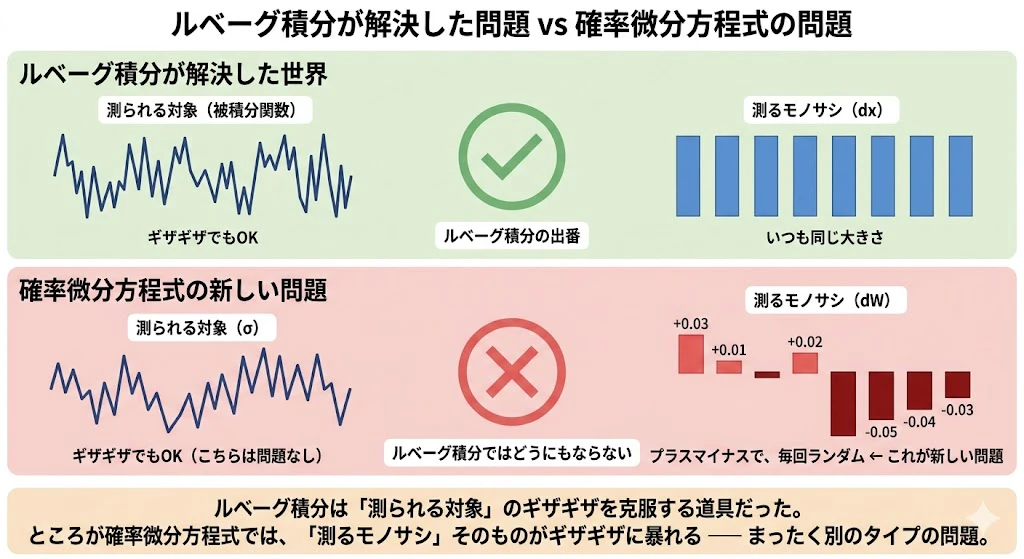
だから、ルベーグ積分ではどうにもなりません。
「ギザギザに暴れるモノサシで、ちゃんと足し算を定義する」――この前人未到の問題を解いたのが、伊藤清の仕事です。
それが伊藤積分です。
では、なぜルベーグ積分の延長では、このギザギザなモノサシを扱えないのか? 具体的な3つの壁を、これから順に見ていきます。
問題①: ブラウン運動の軌跡は"有界変動"でない
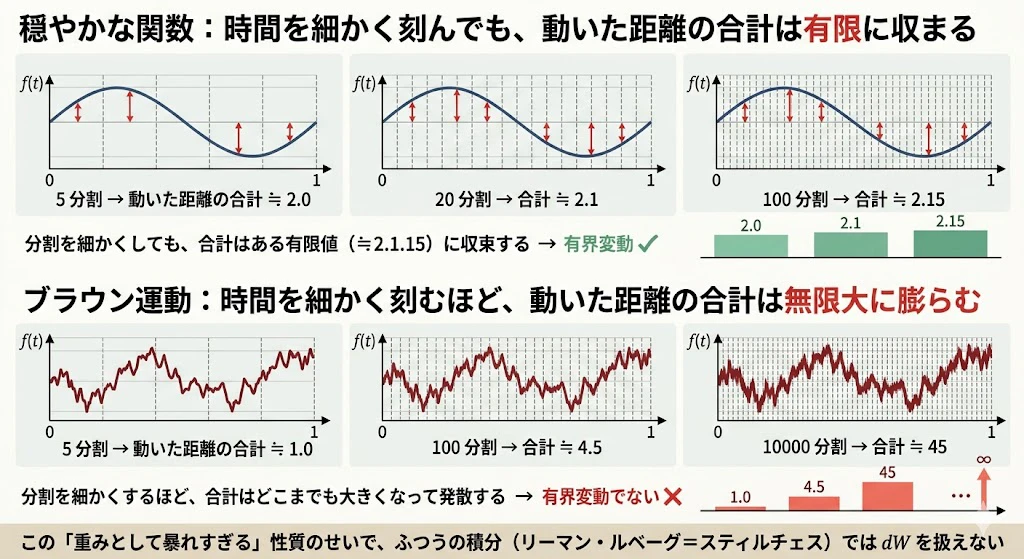
上の段が穏やかな関数(有界変動である関数)、下の段がブラウン運動です。
時間を細かく刻んでいったときに「動いた距離の合計」(=変動の総量)がどうなるかを比べています。
穏やかな関数では、分割を細かくしても合計はある有限の値に落ち着きます(緑のバーグラフ)。
ところがブラウン運動では、分割を細かくするほど合計は際限なく大きくなり、無限大に発散します(赤のバーグラフ)。
$dW_s$ は「重み」として暴れすぎていて、ふつうの積分はこれを扱う想定をしていません
――これが、ルベーグ積分の延長では確率微分方程式が解けない最初の壁 です。
リーマン積分やルベーグ=スティルチェス積分は、「重み(=測る側の関数)」が穏やかに振る舞うことを前提にしています。
具体的には、「有界変動」(=パスが上下に動いた距離の合計が、いくら時間を細かく切っても無限大に発散しない)という条件が必要です。
ところが第3章の3-3-αで見たとおり、ブラウン運動のパスは有界変動ではありません。
秒単位、ミリ秒単位、ナノ秒単位、と時間を細かく切っていくと、動いた距離の合計はどんどん大きくなって発散してしまいます。
つまり、$dW_s$ という「重み」は、ルベーグ=スティルチェス積分が想定する「穏やかな重み」の範囲を完全に逸脱しています。
素朴に積分しようとすると、
-
時間軸の刻み方を変えると、積分の答えが変わってしまう。
-
時間を細かくしていっても、答えがひとつの値に収束しない。
という事態になります。これは積分として致命的です。
問題②: そもそも"パスごとに積分する"ことができない

ふつうの積分(上)は、1本の決まった関数を相手にして、その関数の増分 $\Delta g_i$ を重みに足し合わせます。
ところがブラウン運動(下)は、毎回ちがう無数のパスを同時に持っているため、「どの1本に対して積分すればいいのか」がそもそも決まりません。
「じゃあパスを1本ずつ選んでそれぞれ計算しよう」と考えても、ほぼすべてのパスが問題①の壁にぶつかるので、結局どのパスを選んでもうまくいかない――これが問題②です。
ルベーグ積分も、ルベーグ=スティルチェス積分も、根本的には**「1本の決まった関数」に対して積分を定義する**道具です。
ところがブラウン運動 $W_s$ は、毎回ちがうパスを描くランダムな対象です(2-3-α で見た「軌跡が1本に決まらない」性質)。
どのパスに対して積分すればいいのか、そもそも定まらないわけです。
「1本ずつパスを選んで、そのパスについて積分すればいいのでは?」と思うかもしれません。
ところが、ほとんどすべてのパスが有界変動ではない(=確率1で有界変動でない)ので、どのパスを選んでも問題①にぶつかります。
問題③:時間刻みの"どこの値"で重みを評価するかで答えが変わる

ふつうの積分(上段)では、小区間の中でどこの値を採用しても、刻みを細かくしていけば同じ答えに収束します。これがリーマン積分の素晴らしい性質です。
緑(左端)・オレンジ(中点)・紫(右端)の3トラックが、すべて同じ値
0.785に到達するのを確認してください。ところが、$dW$ で積分する場合(下段)はそうなりません。
まったく同じ計算手順なのに、左端で評価すると 0.42、中点で評価すると 0.55、右端で評価すると 0.68 と、3つとも違う値に収束してしまうのです。3つはどれも数学的に正しい計算結果で、間違いではありません。
それぞれに伊藤積分・ストラトノヴィッチ積分・後方型積分という別々の名前が付いていて、別々の理論として育っています。だから $dW$ 積分には「絶対的な答え」というものが存在せず、「どの流儀で計算しているか」を最初に宣言しないと値が定まらない、という普通の積分とは決定的に違う事情があるのです。
これが一番ややこしいポイントです。普通の積分なら、
$$
\int_0^t f(s), dg(s) \approx \sum_i f(s_i^*) \cdot (g(s_{i+1}) - g(s_i))
$$
のように、小区間 $[s_i, s_{i+1}]$ の中のどこかの点 $s_i^*$ で関数 $f$ を評価して、それを重み $g(s_{i+1}) - g(s_i)$ にかけて足し合わせます。普通の積分では、
「$s_i^*$ を区間内のどこに取っても、時間を細かくしていけば答えは同じ値に収束する」
ことが保証されています。区間内の左端でも、中点でも、右端でも、どこで評価しても結果は同じ。
これがリーマン積分の素晴らしさです。
ところが、$dW$ で積分する場合、これが成り立たないのです。
- 左端 $s_i$ で $f$ を評価して足し合わせると、ある値に収束する
- 中点 $(s_i + s_{i+1})/2$ で評価すると、違う値に収束する
- 右端 $s_{i+1}$ で評価すると、また違う値に収束する
つまり、「どこで評価するか」を最初に決めないと、積分の値そのものが定まらない。これが $dW$ 積分の最大の難しさです。
補足:なぜ「評価点」で答えが変わるのか ―― もう少し丁寧に
ここは初見で理解するのが本当に難しいところなので、3つの角度からかみくだいて説明します。
角度①:そもそも「評価点で答えが変わる」って、何が起きてるの?
まず、想定読者の方の頭にはこんな疑問が浮かんでいるはずです。
「区間 $[s_i, s_{i+1}]$ はものすごく短い時間で、$\Delta s$ をゼロに飛ばす極限を考えているんだから、区間の中のどこで評価しても値はほとんど同じになるはず。なんで違う答えになるの?」
これはとても自然な感覚で、ふつうの関数では本当にその通りです。
$f$ が滑らかなら、区間の左端の値と右端の値は $\Delta s \to 0$ のとき限りなく近づくので、どちらで評価しても結果は同じです。
ところが、$dW$ 積分では話が違います。
理由を一言で言うと、
「$dW$ 自体がとても暴れているせいで、区間内の小さな違いが、足し合わせの段階で打ち消されずに残ってしまう」
からです。これを具体的に見ていきます。
角度②:簡単な例で実際に計算してみる
理論をいくら説明されても腑に落ちないので、実際に $\int_0^T W_s, dW_s$ という具体的な積分を、3つの評価点で計算してみましょう。
被積分関数を $f(s) = W_s$ にした、もっとも素朴な $dW$ 積分です。区間 $[s_i, s_{i+1}]$ で評価点を変えた近似和を、$n$ 個の小区間に分けて考えます。
左端評価(伊藤型):
S^{\text{左}}_n = \sum_{i=0}^{n-1} W_{s_i} \cdot (W_{s_{i+1}} - W_{s_i})
右端評価(後方型):
S^{\text{右}}_n = \sum_{i=0}^{n-1} W_{s_{i+1}} \cdot (W_{s_{i+1}} - W_{s_i})
この2つの差を計算してみます。
S^{\text{右}}_n - S^{\text{左}}_n = \sum_{i=0}^{n-1} (W_{s_{i+1}} - W_{s_i}) \cdot (W_{s_{i+1}} - W_{s_i}) = \sum_{i=0}^{n-1} (W_{s_{i+1}} - W_{s_i})^2
ここで重要なのは、右辺の各項が2乗になっていることです。
第2章 2-3-α の表でも触れたように、ブラウン運動には、
(W_{s_{i+1}} - W_{s_i})^2 \approx s_{i+1} - s_i
という性質(=二次変分の有限性)があります。
ちょっと待った:「二次変分」って何? 「T」って何が突然出てきたの?
ここで2つの単語が突然出てきて立ち止まった方も多いと思います。
整理します。
まず「T」とは何か
これは単純で、いま私たちが積分している区間の長さのことです。本記事で扱っている積分は、
\int_0^T W_s\, dW_s
のように、時刻 $0$ から時刻 $T$ までの区間で考えていました。たとえば $T = 1$(=1秒間積分する)なら、$T$ は単純に $1$ という数値です。$T = 365$(=1年間積分する)なら $365$ です。
そして、この区間 $[0, T]$ を $n$ 個の小区間に等分すると、各小区間の幅 $s_{i+1} - s_i$ は $T/n$ になります。
これを $n$ 個全部足すと、
\sum_{i=0}^{n-1} (s_{i+1} - s_i) = \underbrace{(s_{i+1}-s_i)}_{=T/n} \times n = T
つまり、小区間の幅を全部足したら、当然、区間全体の長さ $T$ になる――これだけのことです。突然魔法のように $T$ が出てきたわけではなく、「全部足したら全体になる」というごく当たり前の話です。
次に「二次変分」とは何か
「二次変分(quadratic variation)」は、確率解析の最深部にある重要概念です。
ひと言で言うと、
「動いた距離を2乗して、それを全部足し合わせたもの」
です。普通の関数の「動いた距離の合計」(=変動)と区別するために、2乗してから足すところがポイントで、「二次(=2乗)」の名前の由来です。
数式で書けば、区間 $[0, T]$ をだんだん細かく刻んでいったときの
\langle W \rangle_T = \lim_{n \to \infty} \sum_{i=0}^{n-1} (W_{s_{i+1}} - W_{s_i})^2
のことを、ブラウン運動 $W$ の 時刻 $T$ までの二次変分 と呼びます。
そもそも、なんで2乗するの?
ここで読者の方は、もっと根本的な疑問を持つはずです。
「動いた距離の合計(=1次変分)はわかる。でも、なんでわざわざ2乗して足すの? 4乗じゃダメ? 絶対値じゃダメ? 数学者の趣味なの?」
これは確率解析を学ぶ多くの人が心の中で、腑に落ちないと疑問を抱えながらも、誰にも聞けずに通り過ぎてしまう 箇所と思われます。
2乗する理由を、順を追って説明します。
理由①:ふつうの「動いた距離の合計」(=1次変分)ではブラウン運動を区別できない
ブラウン運動の最も特徴的な性質は、本記事の問題①で見たとおり、
「動いた距離の合計(=1次変分)がいくらでも無限大になる」
ということでした。これは「ブラウン運動が暴れすぎている」という大事な性質ですが、裏を返すと:
「すべてのブラウン運動が、すべて『動いた距離の合計 = ∞』になってしまう」
ので、距離の合計だけ見ても、ブラウン運動同士を区別できないのです。
「全部 ∞ です」と言われても、その関数の個性が何も見えてきません。これでは情報として使い物になりません。
つまり、1次変分(距離の合計)は、ブラウン運動を測る"ものさし"としては粗すぎるわけです。
理由②:2乗すると「ちょうどよい有限値」が見える
そこで、距離を2乗してから足し合わせるとどうなるか?
「2乗する」というのは、小さい数はさらに小さく、大きい数はそのまま大きくするという操作です($0.1 \to 0.01$、$0.01 \to 0.0001$、$2 \to 4$)。
ブラウン運動の各小区間の動き $\Delta W_i$ は平均的に小さい($\Delta t$ オーダー)ので、これを2乗すると1次変分のときよりも"抑え込まれて"、合計が無限大ではなく有限値 $T$ に収まるようになります。
これがなぜ重要かというと、
- 1次変分: ∞ (ブラウン運動はすべてこれ。区別できない)
- 2次変分: $T$ (ブラウン運動を特徴づける有限値が見える!)
つまり、2乗することで初めて、ブラウン運動の"個性"を有限の数値として取り出せるわけです。「2乗する」というのは、ブラウン運動をちょうどよく見える解像度にするための、絶妙な調整だと思ってください。
理由③:分散・標準偏差で2乗するのと同じ理由
統計学を勉強した方なら、こういう経験があるはずです。
「データのばらつきを測るのに、なぜ偏差を2乗して足すんだ?(=分散の定義) 絶対値じゃダメなの?」
そして、その答えはおそらくこう習ったはずです:
- 絶対値だとプラスとマイナスを単純に消すだけで、扱いが数学的に面倒
- 2乗だと、プラスとマイナスがどちらも自動的に正の量に変換され、数学的に扱いやすい(微分可能、計算がきれい)
- 2乗だと、大きなブレを大きなブレとして強調できる
実は、二次変分も全く同じ理由で2乗を選んでいます。
$dW$ は、平均0でプラスとマイナスの両方の値を取りますが、
- 1乗のまま足すと、プラスとマイナスで打ち消し合って、ほぼ 0 になってしまう(=何の情報も残らない)
- 絶対値で足すと、上で見たとおり ∞ になってしまう(=区別できない)
- 2乗して足すと、プラスもマイナスも正の量に変わり、しかも合計が有限値 $T$ になる(=ちょうどよい情報)
つまり、確率解析における「2乗」は、統計学の分散・標準偏差で2乗するのと、本質的に同じ動機なのです。「ばらつき」「揺さぶり」を測るときは2乗するのが数学全体の作法だと思ってください。
理由④:「2乗の期待値が分散」だから、ブラウン運動と相性が抜群
もう一段深いレベルでは、こういう理由もあります。
ブラウン運動の増分 $\Delta W = W_{t+\Delta t} - W_t$ は、平均0・分散 $\Delta t$ の正規分布に従う、と本記事で何度も言いました。
ここで、
\mathbb{E}[(\Delta W)^2] = \text{Var}(\Delta W) + (\mathbb{E}[\Delta W])^2 = \Delta t + 0 = \Delta t
つまり、$(\Delta W)^2$ の平均値は $\Delta t$ そのものに他なりません。
これは、2乗するからこそ得られる関係です(絶対値や4乗だとこうはなりません)。
この
(\Delta W)^2 \,\approx\, \Delta t
という関係こそが、本記事の伊藤の補題(第4章)の核心部分、つまり、
(dW)^2 = dt
です。
2乗を取ることで、ブラウン運動が"時間"そのものと直接結びつく
――この奇跡的な対応関係が、確率解析全体を成り立たせています。
ここで、もし「4乗」を選んでいたら、$\mathbb{E}[(\Delta W)^4] = 3(\Delta t)^2$ となって、$\Delta t$ ではなく $(\Delta t)^2$ に対応します。
これは確率解析の構造には合いません。2乗だけが、$\Delta t$(=ふつうの時間)にぴったり対応するのです。
まとめると
| 何乗にする? | ブラウン運動に対する合計 | 使い物になる? |
|---|---|---|
| 1乗(プラスマイナスのまま) | 約 0(打ち消し合う) | ✗ 情報が消える |
| 絶対値(1乗の絶対値) | ∞(無限大に発散) | ✗ 区別できない |
| 2乗 | $T$(有限値) | ○ ちょうどよい! |
| 4乗 | 約 0($(\Delta t)^2$ で速くゼロに) | ✗ 情報が消える |
2乗だけが、ブラウン運動を測る上で有限・非ゼロ・時間と対応するという3つの嬉しい性質を同時に満たす唯一の選択肢なのです。
だから二次変分が、確率解析全体のいわば「標準的なものさし」として採用されているわけです。
以上の事情が理解できると、
- なぜ**「伊藤の補題」** に、2次の項が出てくるのか(→ 2乗が時間と等価だから)
- なぜ統計学で、分散(=2乗)が使われるのか(→ 同じ理由)
- なぜ機械学習の損失関数は、2乗誤差がデフォルトなのか(→ これも本質的に同じ)
といった、データサイエンスのあちこちに出てくる「2乗」の意味が、ひとつの統一した原理としてつながって見えてくるはずです。
「2乗」は数学者の好みで選ばれた指数ではなく、ランダムなものを測るときの最も自然な単位なのです。
ブラウン運動の二次変分の驚くべき性質
ここからが驚くべきポイントです。
普通のなめらかな関数(例:$f(t) = t^2$ のような関数)に対して二次変分を計算すると、$n \to \infty$ の極限でゼロになります。
なぜそうなるのか、順を追って見てみましょう。
まず、なめらかな関数 $f$ について、短い時間 $\Delta t$ の間に動いた距離は、中学校で習った「距離 = 速さ × 時間」と同じ感覚で、
\Delta f \approx f'(t) \cdot \Delta t
と書けます($f'(t)$ がその時点の"速度"に対応します)。
これを2乗すると、
(\Delta f)^2 \approx (f'(t))^2 \cdot (\Delta t)^2
になります。
**ここで、$\Delta t$ は、1より小さい数値です。
「1より小さい数値」を2乗すると、2乗する前よりも小さい値になります。(小数点が増えてるからです)
少しかみくだきます。
私たちはいま、$[0, T]$ という区間を $n$ 等分しているので、各小区間の幅は
\Delta t = \frac{T}{n}
です。
たとえば、 $T = 1$ で $n = 1000$ 等分すれば $\Delta t = 0.001$、$n = 1{,}000{,}000$ 等分すれば $\Delta t = 0.000001$ となります。
二次変分は、 $n \to \infty$ の極限を考えるので、$\Delta t$ はどんどん0に近づいていく、ものすごく小さな数(=1よりはるかに小さい小数) を相手にしています。
このとき、
- $\Delta t = 0.001$ なら、$(\Delta t)^2 = 0.000001$
- $\Delta t = 0.000001$ なら、$(\Delta t)^2 = 0.000000000001$
のように、1より小さい数を2乗すると、もとよりもっと小さくなります(小学校の算数の授業で、「$0.5 \times 0.5 = 0.25$」とやったのと同じ話です)。だから、
動いた距離の2乗 $(\Delta f)^2$ は、$\Delta t$ 自体よりも"はるかに小さい量"$(\Delta t)^2$ のオーダーになる
わけです。
ここで「オーダー」というのは、**「だいたいそれくらいの大きさ」**という意味の慣用句だと思ってください(厳密な数学用語にはなっていますが、いまは「大体それくらい」程度の理解で十分です)。
ここで、区間 $[0, T]$ を $n$ 等分しているので、各小区間の幅は $\Delta t = T/n$ です。
これを使って、二次変分(=動いた距離の2乗の合計)を概算してみると、
\sum_{i=0}^{n-1} (\Delta f_i)^2 \approx n \times (\Delta t)^2 = n \times \left(\frac{T}{n}\right)^2 = \frac{T^2}{n}
となります。最後の式は、$n$ を大きくしていくと、分母の $n$ のせいでどんどんゼロに近づきます。つまり、
\lim_{n \to \infty} \sum_{i=0}^{n-1} (\Delta f_i)^2 = 0
これが、「なめらかな関数の二次変分はゼロになる」ということの中身です。
直感的に言えば、なめらかな関数の場合は、
「動いた距離 $\Delta f$ がそもそも $\Delta t$ と同じくらい小さい。それを2乗するともっと小さくなる。それを $n$ 個足しても、$n$ を大きくする勢いに2乗の小ささが勝つので、合計はゼロに吸い込まれていく」
ということです。
ところがブラウン運動の場合、二次変分はゼロでも無限大でもなく、ぴったり $T$ という有限値に収束します。
これがブラウン運動の最も特徴的な性質で、ひと言で書くと、
\langle W \rangle_T = T
です。
読み下すと、「ブラウン運動を時刻 $0$ から $T$ まで観察したときの二次変分は、区間の長さ $T$ にぴったり等しい」 ということになります。
なぜ二次変分が $T$ になるのか
数学的に厳密な証明を追わずに、ブラウン運動が持つ性質から順を追って確かめていきます。
本記事の第2章で、ブラウン運動には次の性質があることを見ました。
短い時間 $\Delta s$ の間にブラウン運動が動く距離は、平均すると0、振れ幅の二乗の平均は $\Delta s$ になる。
「振れ幅の二乗の平均が $\Delta s$」というのは、ブラウン運動の定義そのものです。
少し補足します。
ブラウン運動 $W_s$ は、短い時間 $\Delta s$ の間に上下にランダムに動きます。
動く方向はランダムなので、何度も観測して動いた距離を平均すると0になります。
(プラス方向に動くことも、マイナス方向に動くことも、同じ頻度で起きるため)
ただし、「平均すると0」というのは「ほとんど動かない」という意味ではありません。
実際には毎回それなりに大きく動いていて、ただ方向がプラスとマイナスでバラバラなので、足し合わせると0になっているだけです。
動きの大きさそのものを測りたい場合は、プラスマイナスを打ち消し合わないように、動いた距離を2乗してから平均を取ります。
これが前のセクションで説明した「2乗してばらつきを測る」という考え方です。
そして、この「動いた距離の二乗の平均」が、ちょうど時間の幅 $\Delta s$ に等しくなる――これがブラウン運動の最も基本的な性質です。
式で書けば次のようになります。
(\text{動いた距離 } W_{s_{i+1}} - W_{s_i})^2 \text{ の平均} = s_{i+1} - s_i = \Delta s_i
この性質を使って、二次変分 $\sum_i (W_{s_{i+1}} - W_{s_i})^2$ を計算してみます。
各項は平均すれば $\Delta s_i$ になるので、合計は平均すれば
\sum_{i=0}^{n-1} (\Delta s_i) = T
つまり、小区間の幅をすべて足し合わせたもの、すなわち区間全体の長さ $T$ に等しくなります。
これが、「ブラウン運動の二次変分が $T$ になる」ことの中身です。
直感的に言い直せば、ブラウン運動は「動いた距離を2乗すると、ちょうど経過した時間と同じになる」ように作られている関数です。
だから、距離の2乗を区間全体で足し合わせると、自然に区間の長さ $T$ が出てくるのです。
これが先ほどの近似式
(W_{s_{i+1}} - W_{s_i})^2 \approx s_{i+1} - s_i
の正体です。
「2乗の値は、平均すれば区間の幅と同じ」と言っているわけです。
そして、これを $n$ 個全部足し合わせると、小区間の幅の総和 $= T$ になります。だから、
\sum_i (W_{s_{i+1}} - W_{s_i})^2 \approx \sum_i (s_{i+1} - s_i) = T
となるのです。
ふつうの関数とブラウン運動の対比
ここまでの話を表で整理しておきます。
| ふつうのなめらかな関数 $f$ | ブラウン運動 $W$ | |
|---|---|---|
| 1次変分(動いた距離の合計) | 有限値(=曲線の長さ) | ∞(無限大に発散)※問題①で出てきた性質 |
| 二次変分(動いた距離の2乗の合計) | 0(ゼロ) | $T$(区間の長さ) |
つまり、ブラウン運動は、
- 1次変分(=距離の合計)は無限大に発散する 「動きすぎ」 な関数だけれども
- 2次変分(=距離の2乗の合計)は $T$ という有限値にきれいに収束する
という、ふつうの関数とはまったく違う絶妙な性質を持っているのです。
「動きすぎているけれど、2乗すると有限になる」――これがブラウン運動が「ふつうの積分では扱えないけれど、伊藤積分という新しい積分なら扱える」鍵になっています。
じゃあ、これが何の役に立つの?
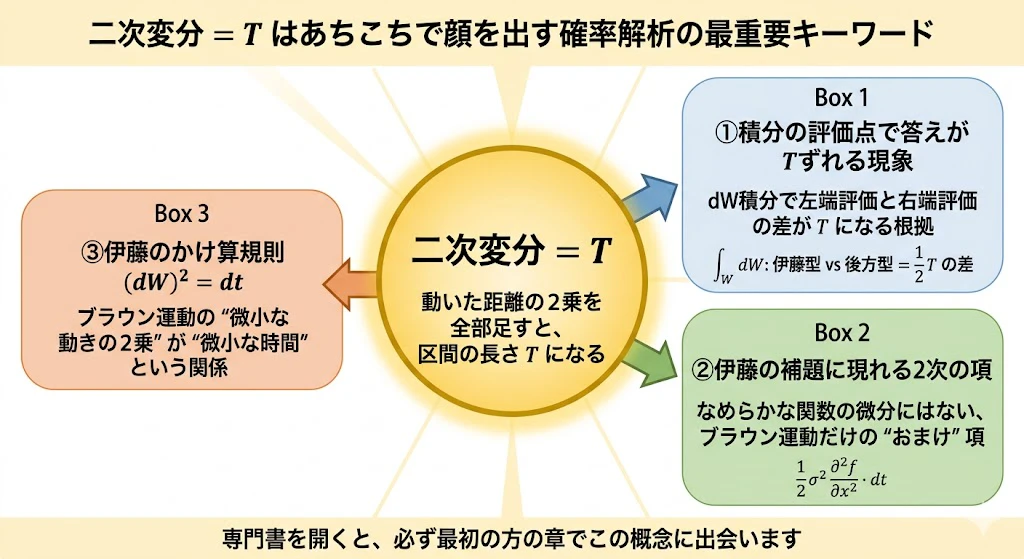
上の図は、ここまで説明してきた「二次変分 = T」というブラウン運動の性質が、確率解析のどこに顔を出すかを1枚にまとめたものです。
中央の円が今回学んだ二次変分の性質、その周りに描かれた3つの箱が、本記事の別の場所で出会う(または既に出会った)3つの場面です。
ここまで読んで、「では、この二次変分という性質は、結局どこで使うのか」と思われるかもしれません。
実は、二次変分が $T$ という消えない有限値になることが、本記事の他の場面でも繰り返し顔を出します。
上の図の3つの箱を、1つずつ簡単に紹介します。
箱①:積分の評価点で答えが $T$ ずれる現象(本節の話)
本節の最大のテーマでした。
$\int W_s, dW_s$ を計算するときに、左端で評価するか右端で評価するかで答えが $\frac{1}{2}T$ だけずれる――その「ずれ」の正体が、まさに二次変分です。
二次変分が $T$ という消えない値を持つから、ずれも $T$ という消えない値として残ります。
箱②:伊藤の補題に現れる2次の項(第4章の話)
本記事の第4章で扱う「伊藤の補題」には、なめらかな関数の合成関数の微分にはない不思議な"おまけ"項が出てきます。
それが $\frac{1}{2}\sigma^2 \frac{\partial^2 f}{\partial x^2}, dt$ という2次の項です。
この項が出てくる理由も、突き詰めればブラウン運動の二次変分が $T$ という有限値を持つことに行き着きます。
箱③:伊藤のかけ算規則 $(dW_t)^2 = dt$(次の第4章で本格的に使う関係式)
ここで「かけ算規則(multiplication rule)」というのは、$dt$ と $dW_t$ という"微小量"どうしを掛け算したときに、それぞれが何になるかを定めたルールのことです。
ふつうの数学では、微小量どうしの掛け算は「もっと小さい微小量」になって無視できます。たとえば $dt \times dt = (dt)^2$ は $dt$ よりずっと小さいので、ふつうは捨ててしまいます。
ところがブラウン運動 $dW_t$ が混じると、$dW_t \times dW_t$ だけは無視できず、なんと $dt$ として残ってしまうのです。
これがまさに、いま学んでいる「二次変分が $T$ になる」という性質の、微小量レベルでの言い換えに他なりません。
次の第4章では、このルールを使って伊藤の補題の核心部分を導出します。
つまり、二次変分 $= T$ という一つの性質を理解しておくことで、本記事の異なる章で出てくる以下の現象が、すべて同じ根から生えていることが見えてきます。
- なぜ伊藤積分とストラトノヴィッチ積分で答えが違うのか
- なぜ伊藤の補題には2次の項が出てくるのか
- なぜ $(dW)^2 = dt$ という関係が成り立つのか
専門書を開くと、二次変分(quadratic variation)という言葉が必ず最初の方の章で大きく扱われていることに気づくはずです。
「動いた距離を2乗して足し合わせる」という、一見地味な操作が、確率解析の中心的なエンジンとして働いていることを覚えておいてください。
まとめると
-
$T$ は、いま積分している区間の長さ(=$\int_0^T$ の $T$)。たとえば 1秒なら $T=1$。
-
二次変分 は、「動いた距離を2乗して全部足したもの」。
- ブラウン運動の二次変分は、ぴったり区間の長さ $T$ に等しい:$\langle W \rangle_T = T$
- だから、本節の数式 $\sum_i (dW_i)^2 \approx T$ は、「動いた距離の2乗を全部足し合わせると、区間の長さになる」 という、ブラウン運動の最も特徴的な性質を述べている
この理解を持ったうえで、もう一度本節冒頭の数式を見直してみてください。
「左端評価と右端評価の差は二次変分そのものだから、$T$ という消えない有限値になる」
――この一文の意味が、立ち上がって見えてくるはずです。
以上を踏まえて、本節冒頭の式に戻ると、
S^{\text{右}}_n - S^{\text{左}}_n \approx \sum_{i=0}^{n-1} (s_{i+1} - s_i) = T
つまり、
左端で評価する場合と右端で評価する場合では、$\Delta s$ をどんなに小さくしても、ぴったり $T$ だけ差が残り続ける
のです。ゼロに収束する誤差ではなく、**最初から最後まで $T$ という"消えない差"**が両者の間に存在します。
実際、伊藤積分の定義に従って $\int_0^T W_s, dW_s$ を計算すると、
| 評価点 | 積分の値 |
|---|---|
| 左端で評価(伊藤積分) | $\frac{1}{2}W_T^2 - \frac{1}{2}T$ |
| 中点で評価(ストラトノヴィッチ積分) | $\frac{1}{2}W_T^2$ |
| 右端で評価(後方型) | $\frac{1}{2}W_T^2 + \frac{1}{2}T$ |
となります。3つの値が、それぞれ $\frac{1}{2}T$ ずつズレているのが分かります。これは数値計算で確認できる、れっきとした事実であって、「ほぼ同じ」とか「誤差の範囲」ではありません。
角度③:直感的なたとえ ―― なぜ消えない差が出るのか
「2乗だから残る」と言われても腑に落ちないと思うので、たとえ話で説明します。
たとえ①:たくさんの小さな"プラスとマイナス"のかけ算
$dW = W_{s_{i+1}} - W_{s_i}$ は、平均0で、プラスにもマイナスにもなる小さなランダム量です。これと左端の $W_{s_i}$ の積を取って足し合わせるのと、右端の $W_{s_{i+1}}$ の積を取って足し合わせるのを比べます。
両者の差は、上の計算で見たとおり $(dW)^2$ の和です。個々の項 $(dW)^2$ は必ず非負なので、プラスマイナスで打ち消し合うことがありません。
ふつうの足し算なら、プラスとマイナスがランダムに現れるとき、$n$ 個足しても合計は $\sqrt{n}$ 倍程度しか大きくならず、平均すれば 0 です。ところが2乗を足し合わせると、全部プラスなので、$n$ 個足したものは $n$ 倍に成長します。これが「消えない差」が生まれる仕組みです。
たとえ②:株式トレーダーの比喩
もっと直感的なイメージで言えば、こんな感じです。
左端評価(伊藤型):「今日の値段がいくらかを見てから、明日上がるか下がるかに賭ける」(=取引時点の情報だけで判断)
右端評価:「明日の値段がいくらかを見てから、明日上がるか下がるかに賭ける」(=未来を知った上で判断するインサイダー取引のような状態)
中点評価(ストラトノヴィッチ型):その中間。
毎区間ごとに見れば、両者の差は「未来を一瞬だけ覗き見できるかどうか」程度のごく小さな違いに見えます。ところが取引を無限回繰り返すと、この小さな"未来覗き見"の優位性が累積して、無視できない差になるわけです。
これが、$dW$ 積分で「評価点」が本質的な意味を持つ理由です。ブラウン運動が暴れすぎていて、未来を一瞬覗くか覗かないかが、長期的には大きな差を生む――そんな世界の話だと思ってください。
角度④:では、なぜ「左端評価」が金融工学の標準なのか?
ここまでで「3つの流派がある」と説明しましたが、実際には金融工学ではほぼ伊藤積分(=左端評価)が使われます。なぜでしょう?
理由は単純で、現実の金融取引では未来の株価を見て今日の取引を決めることはできないからです。
- 今日 $t$ における取引判断は、$t$ 以前の情報だけで決めなければならない(インサイダー取引は違法)
- 区間 $[t, t+\Delta t]$ で「$t$ までに観測した情報」だけを使うということは、区間の左端で評価することに対応する
- だから、現実の取引を数学的にモデル化する場合、左端評価(伊藤積分)が物理的に自然
つまり、伊藤の選択は数学的な便宜ではなく、現実の因果律(未来は過去に影響しない)と整合する選択なのです。
これが「伊藤積分が金融工学の標準である」決定的な理由です。
一方、物理学では、たとえばノイズを連続的に受ける粒子のような系では、ノイズが「区間の前後でなめらかに連続していると見なせる」場合があり、その場合は中点評価(ストラトノヴィッチ型)の方が自然になります。
これがストラトノヴィッチ積分が物理で好まれる理由です。
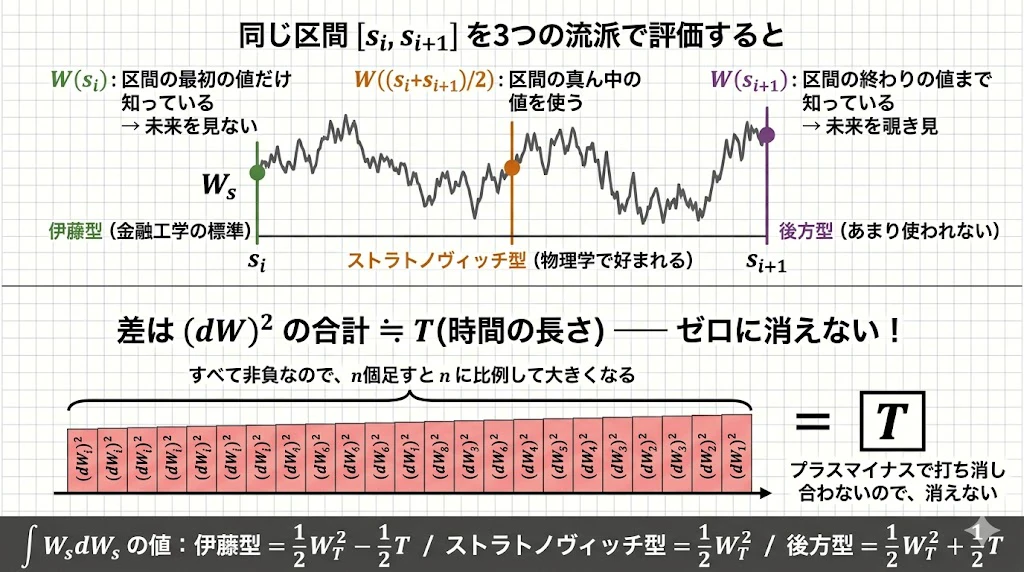
上半分は、ひとつの小さな区間 $[s_i, s_{i+1}]$ の中で、ブラウン運動 $W_s$ がどう暴れているか、そして3つの評価点(左端=緑、中点=オレンジ、右端=紫)でそれぞれ異なる値を取ることを示しています。
下半分が核心です。
左端と右端の差は $(dW)^2$ の和で、これはすべて非負なので、足し合わせても打ち消し合わずに $T$ という消えない量として残ります。だから「無限に細かく刻めばゼロになるはず」という直感が裏切られるのです。
下のバナーに、$\int_0^T W_s, dW_s$ を3流派で計算した結果を並べてあります。
それぞれ $\frac{1}{2}T$ ずつズレているのが見えると思います。
まとめ ―― 結局、何を覚えておけばいいか
- $dW$ 積分では、評価点を左端/中点/右端のどこに取るかで、答えが、 $\frac{1}{2}T$ などの有限量だけズレる
- これは「誤差」ではなく、消えない事実上の差である
- 理由は、差が $(dW)^2$ の和になるから。これはすべて非負で、打ち消し合わない(=ブラウン運動の二次変分が有限値 $T$ になる)
- 現実の因果律(未来を覗かない)と整合するのは左端評価=伊藤積分 で、これが金融工学の標準
- 物理学ではノイズの解釈の違いから中点評価=ストラトノヴィッチ積分が好まれる
この点さえ押さえれば、専門書で「伊藤積分」「ストラトノヴィッチ積分」「適合過程」と出てきたときに、「ああ、評価点を左端に固定する話か」「ああ、中点を取る別の流儀のことか」と、ちゃんと意味のある言葉として理解できるようになります。
(3) 伊藤清の解決策 ―― 1944年の決定打
ここで満を持して登場するのが、伊藤清(1915-2008)です。
京都帝国大学を卒業した若き日の伊藤は、太平洋戦争中の1944年(昭和19年)に、わずか29歳で発表した論文で、この未解決問題を一気に解決しました。
伊藤の解決策は、要点だけ言えば3つの決断から成り立っています。
決断①:左端で評価することにする(=適合過程に限定する)
伊藤は、
「小区間 $[s_i, s_{i+1}]$ の中で関数 $f$ を評価する点は、左端 $s_i$ に固定する」
と決めました。これは単なる便宜上の選択ではなく、深い意味があります。
左端 $s_i$ で評価するということは、「時刻 $s_i$ までの情報だけを使って $f$ を決める」 ということです。$s_i$ 以降の未来の動きを覗き見しません。
これを数学的には「適合過程(adapted process)」と呼びます。
なぜこれが重要かというと、金融工学で例えれば、
「未来の株価を見てから今日の投資判断を下す」のは反則(=インサイダー情報)行為です。
今日の判断は今日までの情報だけで決めなければならない。
という、現実世界の極めて自然な要請に対応するからです。
伊藤の選択は、数学的な制限であると同時に、現実世界の因果律(未来は過去に影響しない)と整合する選択でした。
決断②:「2乗の意味で」収束させる
普通の積分は「絶対値の意味で」収束させますが、伊藤積分は
「平均的に2乗誤差が小さくなる」という意味で収束させる($L^2$ 収束)
と定義します。
これは、「個々のパスごとに収束しなくても、全パスにわたって平均すると2乗誤差がゼロに近づくようにすれば良い」という、緩い基準です。
ブラウン運動の個々のパスは荒れていますが、「2乗の意味で平均化すれば」素直に振る舞ってくれる――伊藤はこの絶妙な"妥協点"を見抜いたのです。
決断③:単純な関数から段階的に拡張する
伊藤はいきなり一般の関数 $\sigma(X_s, s)$ を扱おうとはしませんでした。
代わりに、
- まず単純過程(=時刻ごとに有限個の値しかとらない、階段状の関数)に対して、伊藤積分を有限の足し算で定義する
- 次に、一般の関数を単純過程の極限として近似し、その極限として伊藤積分を定義する
という二段階の戦略を取りました。
これは数学では、「稠密な部分集合での定義 → 全体への拡張」と呼ばれる王道のテクニックで、ルベーグ積分自体もこの戦略で作られています。
(4) 結果:何が手に入ったのか
伊藤のこの3つの決断によって、「$dW$ で積分する」という操作が、初めて数学的に矛盾なく定義されたのです。
それが伊藤積分です。
しかも伊藤は、同じ1944年の論文の中で、この新しい積分を実際に使うための"道具一式" までを、たった1人で全部仕上げてしまいました。
具体的には、
- 伊藤積分が、ふつうの積分と同じように"足し算・引き算・定数倍"などの基本的な計算ルールに従うことを証明した
- 伊藤の補題(=「確率版の合成関数の微分」。普通の微分にはない"おまけ項"がつく公式。本記事第4章のテーマ)を導いた
- 確率微分方程式 $dX_t = \mu, dt + \sigma, dW_t$ という方程式に、ちゃんと"解"が存在し、しかもそれが1つに決まることを証明した(=「解の存在と一意性」と呼ばれます)
つまり伊藤は、
「$dW$ で積分する道具を作る」だけでなく、「その道具を使って確率微分方程式を解く」「解いた結果を変形する」ところまで、ひとつの論文の中で全部やってのけた
ということです。
確率微分方程式の理論は、伊藤の1944年の論文によって、ほぼ完成形のまま世に出されたと言っても過言ではありません。
そして、ここからおよそ30年後の1973年、この伊藤の道具一式を全面的に使って、ブラックショールズとマートンがオプション価格の方程式(=本記事第5章のテーマ)を導き出すことになります。
3-6. なぜ「伊藤積分」が必要なのか
確率微分方程式の右辺の $\sigma(X_t, t), dW_t$ を、いざ積分しようとすると困ります。
$$
\int_0^t \sigma(X_s, s), dW_s = ?
$$
$dW_s$ は普通の意味では微分不可能なので、リーマン積分やリーマン=スティルチェス積分の枠組みではそもそも定義不能です。
そこで伊藤清(いとう・きよし)名誉教授が、
「$W_s$ の増分 $W_{s+\Delta} - W_s$ を、時間刻み $\Delta$ がゼロに近づく極限で2乗平均的に足し合わせる」
という新しい積分(=伊藤積分)を定義しました。これで初めて、確率微分方程式の右辺が数学的に意味を持つようになります。
3-7. Pythonでルベーグ積分っぽい計算を体感
ルベーグ積分そのものをPythonで直接計算するのは難しいですが、「横切り」の気持ちは試せます。
import numpy as np
# ある関数 f(x) を区間 [0, 1] で積分する
def f(x):
return x**2
# 縦切り(リーマン的)
N = 10000
x = np.linspace(0, 1, N)
riemann = np.mean(f(x)) # 短冊の高さの平均
print(f"Riemann-like: {riemann}") # → 約 0.3333
# 横切り(ルベーグ的)
# y を細かく分割し、「f(x) ≈ y となる x の集合の長さ」を測る
M = 10000
y_levels = np.linspace(0, 1, M)
xs = np.random.uniform(0, 1, 1000000) # x をたくさんサンプル
f_vals = f(xs)
lebesgue = 0
dy = 1.0 / M
for y in y_levels:
# f(x) > y となる x の割合(= その集合の測度)
measure = np.mean(f_vals > y)
lebesgue += measure * dy
print(f"Lebesgue-like: {lebesgue}") # → 約 0.3333
両方とも $\int_0^1 x^2, dx = 1/3$ に近い値になります。結果は同じでも、切り方の発想が違うのがポイントです。
4. 伊藤の補題 ― 確率版の「合成関数の微分」
4-1. 高校で習う合成関数の微分
高校で連鎖律をやりましたね。$y = f(g(x))$ なら、
$$
\frac{dy}{dx} = f'(g(x)) \cdot g'(x)
$$
これを微小量で書けば $df = f'(g), dg$ となります。
4-2. ブラウン運動だと事情が変わる
では、$X_t$ がSDEに従うとき、$Y_t = f(X_t, t)$ の微小変化 $dY_t$ はどう書けるでしょうか?
普通の連鎖律を素直に当てはめると、
$$
dY_t = \frac{\partial f}{\partial t} dt + \frac{\partial f}{\partial x} dX_t
$$
としたくなります。ところがこれは間違いです。
なぜか。SDEには $dW_t$ という、平均0・分散$dt$のランダム項が含まれます。テイラー展開を2次までやると、
$$
df \approx \frac{\partial f}{\partial t} dt + \frac{\partial f}{\partial x} dX_t + \frac{1}{2} \frac{\partial^2 f}{\partial x^2} (dX_t)^2
$$
ここで、ふつうの微分なら $(dX_t)^2$ は無視できる微小量(2次以上のオーダー)です。
ところがブラウン運動の場合、$(dW_t)^2 \approx dt$ という関係があり、2次の項がdtのオーダーで残ってしまうのです。これを「伊藤のかけ算の規則」と呼びます。
| 項 | 値 |
|---|---|
| $dt \cdot dt$ | $0$ |
| $dt \cdot dW_t$ | $0$ |
| $dW_t \cdot dW_t$ | $dt$ |
4-3. 伊藤の補題(伊藤公式)
これを反映して、$X_t$ が SDE $dX_t = \mu, dt + \sigma, dW_t$ に従うとき、
$$
\boxed{
dY_t = \left( \frac{\partial f}{\partial t} + \mu \frac{\partial f}{\partial x} + \frac{1}{2} \sigma^2 \frac{\partial^2 f}{\partial x^2} \right) dt + \sigma \frac{\partial f}{\partial x} dW_t
}
$$
最後の項 $\frac{1}{2} \sigma^2 \frac{\partial^2 f}{\partial x^2} dt$ が**普通の連鎖律にはない"おまけ"**で、これが伊藤の補題の心臓部です。
4-4. キモチをひと言で
「ランダムにギザギザ揺れる量を合成関数化すると、揺れの2乗が決定論的なドリフトを生む」
これが伊藤の補題のすべてです。
揺さぶり($\sigma$)が大きいほど、2乗の項が大きく効いて、ふつうの微分では現れないドリフトが余計に出てくるわけです。
4-5. Pythonで伊藤の補題を数値的に確かめる
幾何ブラウン運動 $dS_t = \mu S_t, dt + \sigma S_t, dW_t$ で、$Y_t = \ln S_t$ がどう動くかを伊藤の補題と数値シミュレーションで比較してみます。
伊藤の補題から、$f(x) = \ln x$、$\partial f/\partial x = 1/x$、$\partial^2 f/\partial x^2 = -1/x^2$ なので、
$$
d(\ln S_t) = \left( \mu - \frac{1}{2}\sigma^2 \right) dt + \sigma, dW_t
$$
「単純に $\mu, dt + \sigma, dW_t$ ではない」のがミソです。$-\frac{1}{2}\sigma^2$ が伊藤補正です。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
mu, sigma = 0.1, 0.3
S0 = 100
T, N = 1.0, 10000
dt = T/N
t = np.linspace(0, T, N+1)
# S_t を直接シミュレーション
dW = np.sqrt(dt) * np.random.randn(N)
S = np.empty(N+1); S[0] = S0
for i in range(N):
S[i+1] = S[i] + mu*S[i]*dt + sigma*S[i]*dW[i]
# ln S_t を伊藤の補題で得たSDEで直接シミュレーション
lnS = np.empty(N+1); lnS[0] = np.log(S0)
for i in range(N):
lnS[i+1] = lnS[i] + (mu - 0.5*sigma**2)*dt + sigma*dW[i]
plt.plot(t, np.log(S), label="ln(S_t) from S_t simulation")
plt.plot(t, lnS, '--', label="lnS_t from Ito's lemma SDE")
plt.legend(); plt.xlabel("t"); plt.title("Ito's lemma sanity check")
plt.grid(True); plt.show()
2本のラインがほぼ重なれば、伊藤の補題が正しく機能していることが確認できます。
5. ブラックショールズ方程式は何をやっているのか?
5-1. オプションの値段を決めたい
ブラックショールズ方程式(Black-Scholes equation)は、株価のオプション(=ある期日にある値段で買う/売る権利)を、いま現在いくらで売買すべきかを計算するための方程式です。
仮定はざっくり:
- 株価は幾何ブラウン運動に従う:$dS_t = \mu S_t, dt + \sigma S_t, dW_t$
- 無リスク金利 $r$ で自由にお金を借りたり貸したりできる
- 取引コストや配当はない
5-2. キモはヘッジポートフォリオ
株価とオプションは連動して動きます。そこで、
「株を $\Delta$ 株買って、オプションを1個売る」
というポートフォリオを組むと、$\Delta$ をうまく選べば、ブラウン運動由来のランダム項を完全に打ち消せることが伊藤の補題からわかります。
ランダム項が消えてしまえば、そのポートフォリオは無リスクです。無リスクなら、無リスク金利 $r$ で増えるはずです。この「無リスクなら $r$ で増える」という条件から導かれるのが、
$$
\frac{\partial V}{\partial t} + r S \frac{\partial V}{\partial S} + \frac{1}{2}\sigma^2 S^2 \frac{\partial^2 V}{\partial S^2} - r V = 0
$$
これがブラックショールズ偏微分方程式です。$V(S, t)$ がオプション価格、$S$ が現在の株価、$t$ が時刻。
5-3. つまり何をやっているのか
ひと言でいえば、
「ランダムに動く株価のオプションを、伊藤の補題で2次の項まで考慮しながら、無裁定の原理で価格付けする」
これがブラックショールズの本質です。
5-4. Pythonで解く
ヨーロピアン・コール・オプションには有名な閉形式(解析解)があります。
import numpy as np
from scipy.stats import norm
def black_scholes_call(S, K, T, r, sigma):
"""S: 現在の株価, K: 行使価格, T: 残存期間, r: 無リスク金利, sigma: ボラティリティ"""
d1 = (np.log(S/K) + (r + 0.5*sigma**2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
price = black_scholes_call(S=100, K=100, T=1.0, r=0.05, sigma=0.2)
print(f"Call option price: {price:.4f}") # → 約 10.45
6. ブラックショールズ以外の金融時系列確率微分モデル
ブラックショールズの仮定(ボラティリティ一定など)は現実と乖離があるため、後続の研究で多くの拡張モデルが提案されています。
| モデル名 | 特徴 | 主な用途 |
|---|---|---|
| 幾何ブラウン運動 (GBM) | $dS_t = \mu S_t dt + \sigma S_t dW_t$。ブラックショールズの基本 | 株価の最も単純なモデル |
| Vasicek モデル | 金利が平均回帰する:$dr_t = a(b - r_t)dt + \sigma dW_t$ | 短期金利モデル |
| Cox-Ingersoll-Ross (CIR) モデル | 金利が非負を保つ平均回帰:$dr_t = a(b-r_t)dt + \sigma\sqrt{r_t}, dW_t$ | 金利、ボラティリティモデル |
| Heston モデル | ボラティリティ自体が確率過程:$d v_t = \kappa(\theta - v_t)dt + \xi \sqrt{v_t}, dW_t^v$ | 株価のスマイル(IVの歪み)再現 |
| SABRモデル | 確率ボラティリティの一種、金利デリバティブで主流 | スワップション、キャップ/フロア |
| Merton ジャンプ拡散モデル | GBMにポアソン分布のジャンプを足す | 急変動を伴う株価 |
| Lévy過程モデル | ジャンプ含む一般化過程 | クレジットデリバティブ、極値リスク |
6-1. キモチ:何が違うのか
ざっくり言えば、
- ボラティリティを動かす:Heston、SABR
- 金利を動かす:Vasicek、CIR、HJM
- ジャンプを許す:Merton、Lévy
それぞれ「ブラックショールズで足りないどの仮定を緩めるか」で分類できます。
6-2. なぜHestonモデルが生まれたか ― 「IVスマイル」とは何か
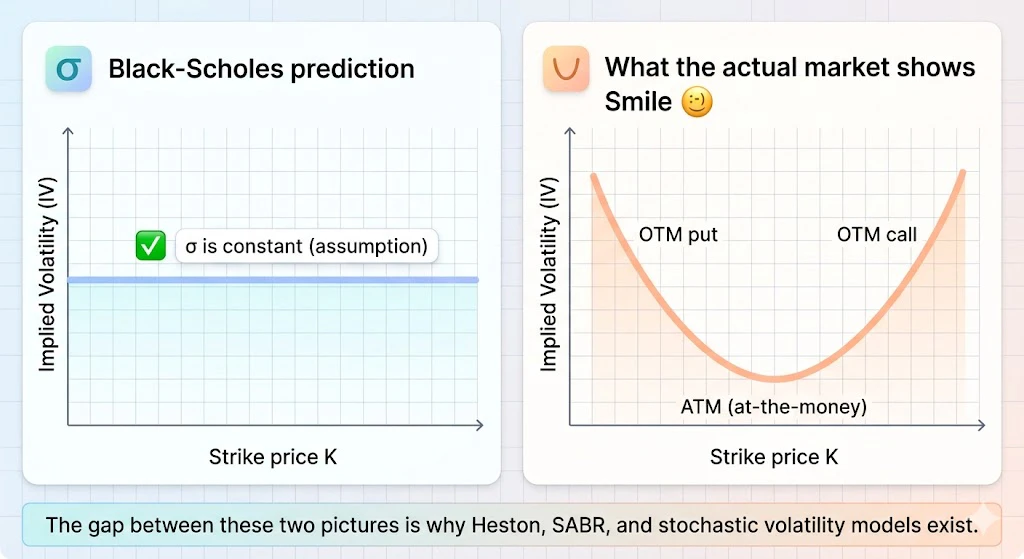
上の表でHestonモデルの用途を「IVスマイル(implied volatility smile)の再現」と書きましたが、IVスマイルって何でしょう? ここは想定読者の方が見落としがちなところなので、丁寧に解説します。
ステップ1:「ボラティリティ」って何だっけ?
ブラックショールズの式に出てきた $\sigma$(シグマ)がボラティリティで、「株価がどれくらい揺さぶられているか」を表す数値です。$\sigma$ が大きいほど株価のブレが大きく、オプションは高くなります(揺れが大きい方が、有利な方向に動く可能性も大きいので、権利の価値が上がる)。
ステップ2:「インプライド(implied)」って何だっけ?
「インプライド」は「含意された」「逆算された」という意味です。
- 普通:$\sigma$ を入力 → ブラックショールズ式 → オプション価格を出力
- インプライド:市場で実際に取引されているオプション価格を入力 → ブラックショールズ式を逆向きに解く → 「この価格が成立するためには $\sigma$ がいくつだったはず?」を出力
この逆算された $\sigma$ をインプライド・ボラティリティ(IV) と呼びます。
ステップ3:ブラックショールズが正しければ、IVは「平ら」になるはず
ブラックショールズは「$\sigma$ は時間と株価によらず一定」という仮定で作られています。だから、同じ株について、行使価格 $K$ が違うオプションを並べてIVを計算したら、全部同じ $\sigma$ になるはずです。グラフにすれば真っ平らな水平線。
ステップ4:ところが現実は「笑った口の形」になる
実際の市場で計算してみると、行使価格 $K$ を横軸、IVを縦軸にプロットすると、真ん中が低く、両端が高い"笑った口の形"になります。これがスマイル(smile) と呼ばれる現象です。
株式市場では片側だけ盛り上がったスキュー(skew) になることが多いですが、いずれにせよ「平らじゃない」のがポイントです。
ステップ5:なぜ平らじゃない? ― 市場が暗黙に言っていること
両端のIVが高いということは、市場参加者が**「真ん中(=現在の株価あたり)からズレた価格になるオプションは、ブラックショールズの予測より割高にお金を払う価値がある」と考えているということです。言い換えれば、「現実の株価は、ブラックショールズが仮定するよりも極端な動き(暴騰・暴落)をしやすい」**と市場は知っているわけです。
ステップ6:だからボラティリティ自体を動かす
ブラックショールズの「$\sigma$ は一定」という仮定では、このスマイルは絶対に再現できません。そこでHestonモデルでは、
$$
dv_t = \kappa(\theta - v_t), dt + \xi \sqrt{v_t}, dW_t^v
$$
のように、分散 $v_t = \sigma_t^2$ そのものをもう一本のSDEで動かします($dW_t^v$ は株価のブラウン運動と相関を持つ別のブラウン運動)。これによって、ボラティリティが時間とともに揺らぐ「確率ボラティリティ」が組み込まれ、市場のIVスマイルを再現できるようになります。
つまり、
Hestonモデルは「ブラックショールズではIVスマイルが説明できない」という現実の市場データへの応答として生まれた
わけです。後続のSABRモデルや、Merton/LévyのジャンプモデルやBates(Heston+ジャンプ)も、すべてこの「現実の市場が示すIVの形を再現したい」という動機の延長線上にあります。
7. 金融以外:社会経済・自然科学での確率微分方程式
確率微分方程式は金融だけのものではありません。
7-1. 社会経済モデル
| 領域 | モデル例 | 内容 |
|---|---|---|
| マクロ経済 | DSGE モデル+確率ショック | GDP、失業率などにブラウン運動的ショックを加える |
| 人口動態 | 確率的Logistic モデル | 人口増加 + ランダム環境変動 |
| マーケティング | Bass拡散モデル+ノイズ | 製品普及の不確実性 |
| 強化学習 | Langevin拡散、SDEとしてのSGD | 最適化アルゴリズムを連続時間で解析 |
7-2. 物理学
物理学はそもそも、ブラウン運動を最初に数学化したアインシュタイン(1905年)の本拠地です。
| 領域 | モデル例 | 内容 |
|---|---|---|
| 統計力学 | Langevin方程式:$m\ddot{x} = -\gamma \dot{x} + \sqrt{2\gamma k_B T}, \xi(t)$ | 熱浴中の粒子運動 |
| 流体力学 | 確率Navier-Stokes | 乱流の確率モデル |
| 量子物理 | 確率Schrödinger方程式 | 連続観測下の量子系 |
7-3. 化学・生物学
| 領域 | モデル例 | 内容 |
|---|---|---|
| 化学反応 | 化学Langevin方程式、Gillespieアルゴリズム | 分子数が少ない反応系の確率的揺らぎ |
| 集団遺伝学 | Wright-Fisher拡散、Fisher-Wright SDE | 遺伝子頻度の確率変動 |
| 神経科学 | Hodgkin-Huxley with noise、FitzHugh-Nagumo SDE | ニューロンの発火 |
| 生態学 | 確率Lotka-Volterra | 捕食被食モデルにランダムノイズ |
| 疫学 | 確率SIRモデル | 感染拡大の不確実性モデリング |
7-4. 工学・データサイエンス
| 領域 | モデル例 | 内容 |
|---|---|---|
| 制御工学 | カルマン-Bucy フィルタ | 連続時間状態空間モデル |
| 生成AI | 拡散モデル (Diffusion Models) | 画像生成、Stable Diffusion等の基礎 |
| 機械学習 | SGD as SDE | 最適化の連続時間解析 |
特に最近、画像生成AI(Stable Diffusionなど)の基盤の一つがSDEとして整理できることは大きなトピックです。次の節で、ここを少し丁寧に追いかけてみます。
7-5. 実は、Diffusion Modelとも話がつながる

「Stable DiffusionやDALL·Eのような画像生成AIは数学的に難しすぎて、自分には縁がない…」と諦めている方も多いと思います。
実はあれ、本記事でここまで積み上げてきた話の延長線上で理解できるのです。
高校数学を忘れた状態からでも、ひとつずつ言葉をかみくだいていけば、ちゃんと意味がわかる場所まで来られます。少しだけ覗いてみましょう。
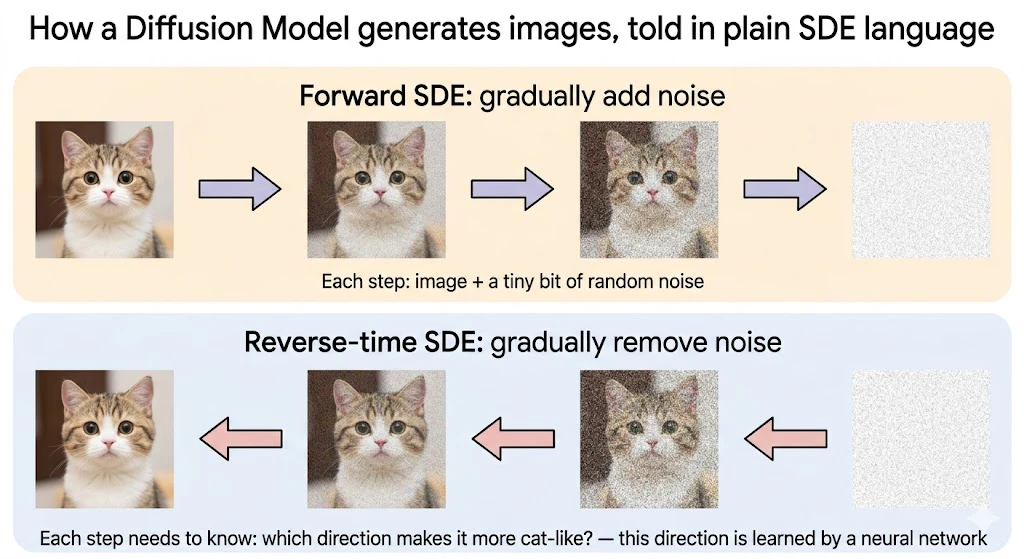
ステップ1:「ノイズを少しずつ足していく」プロセス
きれいな猫の画像を1枚思い浮かべてください。
これに、ほんの少しだけランダムなザラつき(=砂嵐っぽいノイズ)を足すと、ほぼ猫のまま、ちょっとザラついた画像になります。これを何百回も繰り返すと、最終的には**真っ白いノイズ画像(完全な砂嵐)**になります。
これを式で書くと、ちょうど本記事第2章で見た形
$$
dX_t = (\text{ドリフト項}), dt + (\text{拡散項}), dW_t
$$
そっくりです。
画像を「時間に沿ってノイズで壊していく」プロセスは、確率微分方程式(SDE)で書けるわけです。
これを**順方向プロセス(forward process)**と呼びます。
ステップ2:時間を逆向きに辿れたら、ノイズから画像が作れる
ここがDiffusion Modelの天才的アイデアです。
もし、時間を逆向きに走らせるSDEを作れたら、「真っ白なノイズ」から出発して、少しずつノイズを取り除いていけば、最後には「猫の画像」にたどり着けるはず。
「砂嵐 → 猫」という逆プロセスを、SDEで実現してしまおうというわけです。
これを**逆方向プロセス(reverse process)または逆時間SDE(reverse-time SDE)**と呼びます。
普通の物理現象は時間を逆向きに巻き戻せませんが、SDEの場合は、ある条件を満たせば数学的に逆向きを書き下せることが知られています。
ステップ3:何を学習すれば逆向きが作れるか ―「スコア関数」とは
順方向のノイズを足すSDEから、逆方向のノイズを取り除くSDEを作るには、数学的にひとつだけ必要なピースがあります。それは、
「いまノイズだらけの画像を持っているとして、"猫っぽさ"が増す方向はどっちか?」を教えてくれる矢印場
のような関数で、これを**スコア関数(score function)**と呼びます。
記号では $\nabla_x \log p_t(x)$ と書きますが($\nabla$ は「方向を示す矢印」、$\log p$ は「データの分布の山の高さ」をイメージしてください)、いまは記号を覚えなくても大丈夫です。
ノイズだらけのザラついた画像 + スコア関数("猫らしさ"の方向)→ ノイズを少し減らした画像
を繰り返せば、砂嵐から猫に到達できる、と思ってください。
実はこのスコア関数、本記事の第9章のコード例で score(x) という関数名で実装した、あの考え方と同じものです(あちらは1次元の山が2つの分布で、しかも数式で計算できる例でしたが)。
ステップ4:スコア関数は誰が計算する? → ニューラルネットワークが学習する
画像の場合、スコア関数("猫らしさが増す方向")を数式で書き下すことはできません。
じゃあどうするか?
何百万枚もの猫の画像を見せて、「この画像のときはこっちの方向にデータ分布の山がある」というパターンを、ニューラルネットワーク(=大量のデータからパターンを学ぶ機械学習モデル)に丸ごと覚えさせるわけです。
これが Stable Diffusion などの中身です。専門用語抜きで一言でまとめると、以下の一文に要約できます。
Diffusion Modelは、「砂嵐を少しずつ猫に戻していく逆方向のSDE」を、ニューラルネットに"猫らしさの方向矢印"を学ばせることで実現している
このひと言が、本記事のここまでの内容でちゃんと意味のわかる文章として読めたなら、もう数学的な土台は半分以上できています。
ステップ5:歴史的な経緯についての小さな注意
ひとつ豆知識として補足しておくと、Diffusion Modelの研究には大きく2つの流派があります。
-
DDPM系(Ho et al., 2020):
もともとは「画像を1ステップずつ少しだけ変化させる」という、時間を離散的(=連続ではなく、1ステップ、2ステップと飛び飛びに進む)なやり方で式が立てられていました。SDEという連続時間の言葉は最初は使われていませんでした。
-
Score-based系(Song et al., 2021):
最初から「時間を連続的に流れる量として扱うSDE」として定式化し、上で説明した逆時間SDEの理論で画像生成を整理しました。
その後の研究で、これら2つは本質的に同じものの異なる表現方法だったことが明らかになり、現在は「画像生成AIの基盤の一つは、逆時間SDEとして統一的に整理できる」という見方が定着しています。
つまり、本記事で積み上げた「測度論 → ルベーグ積分 → 伊藤積分 → SDE」の道筋は、ブラックショールズだけでなく、最先端の画像生成AIまで一直線につながっているわけです。
ステップ6:高校数学レベルから始める復習ルート
「興味はあるけど自分には無理」と諦めていた方へ。Diffusion Modelの論文を本気で読むには確かに準備が要りますが、本記事の学習ロードマップ(次の第8章)の Step 1 → Step 5 → Step 6 を踏めば、たとえばSong et al. の論文タイトルにある "Score-Based Generative Modeling through Stochastic Differential Equations"(=「確率微分方程式を通じたスコア関数ベースの生成モデリング」)の意味がひとつひとつ自分の言葉に翻訳できるようになります。
つまり、
- 「Score-Based」="猫らしさの方向矢印"を使って、
- 「Generative Modeling」=何もないところから絵を作り出す手法を、
- 「through Stochastic Differential Equations」=確率微分方程式の枠組みで作りました、
と読めるわけです。確率微分方程式は、もはや金融工学だけの道具ではなく、現代の生成AIを理解するための共通言語でもあるのです。
8. 学習ロードマップ:ここから何を、どの順で学ぶか
8-1. レベル別ロードマップ
[Step 0] 高校数学のリハビリ ← この記事の想定読者の出発点
↓
[Step 1] 大学初等の微積分・線形代数・確率統計
↓
[Step 2] 常微分方程式(ODE)の基礎
↓
[Step 3] 偏微分方程式(PDE)の入口
↓
[Step 4] 測度論ベースの確率論
↓
[Step 5] 確率過程・ブラウン運動・マルチンゲール
↓
[Step 6] 伊藤積分・確率微分方程式(SDE)
↓
[Step 7] 金融工学(ブラックショールズ、Heston等)/応用先
8-2. 各ステップでおすすめの書籍
Step 1:大学初等のリハビリ
- 『マセマ大学基礎数学 微分積分キャンパス・ゼミ』(マセマ出版)
- 『プログラミングのための確率統計』平岡和幸・堀玄
- 『線形代数キャンパス・ゼミ』(マセマ出版)
Step 2-3:微分方程式の入口
- 『常微分方程式キャンパス・ゼミ』(マセマ出版)
- 『偏微分方程式キャンパス・ゼミ』(マセマ出版)
- ストロガッツ『非線形ダイナミクスとカオス』(ニュートン・プレス)
Step 4:測度論ベースの確率論
- 『測度・確率・ルベーグ積分』原啓介(講談社) ← 初学者にやさしい
- 『確率論』伊藤清(岩波基礎数学)
- Williams 『Probability with Martingales』 (Cambridge) ← 英語だが定評
Step 5-6:確率過程・SDE
- 『道具としての確率微分方程式』中野張(日本評論社) ← 工学向けで読みやすい
- 『ファイナンスのための確率解析I, II』Shreve(シュプリンガー) ← 金融向けの定番
- Øksendal 『Stochastic Differential Equations』 ← 国際的なバイブル
Step 7:応用
- 『フィナンシャルエンジニアリング』Hull(金融基礎、ブラックショールズ)
- 『Stochastic Calculus for Finance II』Shreve(より深い金融数学)
- 『Bayesian Filtering and Smoothing』Särkkä (カルマン・粒子フィルタ)
- 拡散モデル系:Yang Song et al. "Score-Based Generative Modeling through SDEs" の論文
8-3. 「とにかく雰囲気を一気に掴みたい」人向けの最短ルート
時間がないなら、
- 平岡和幸『プログラミングのための確率統計』
- 中野張『道具としての確率微分方程式』
- Shreve I(離散時間)の前半
の3冊で、ブラックショールズに必要な道具立てを一周できます。

9. 利用シーン別:Python実装ライブラリと実装例
9-1. ライブラリ全体マップ
| 利用シーン | 主なライブラリ | 用途 |
|---|---|---|
| 金融オプション価格 |
QuantLib-Python, py_vollib, scipy
|
ブラックショールズ、Heston、モンテカルロ |
| 一般的なSDE数値解 |
sdeint, torchsde, diffrax (JAX)
|
Euler-丸山、Milstein等 |
| ベイズSDE推定 |
PyMC, Stan (CmdStanPy), numpyro
|
SDEパラメータのベイズ推定 |
| 強化学習・最適化 |
PyTorch, JAX, Optuna
|
Langevin系SGD、ベイズ最適化 |
| 拡散モデル(生成AI) |
diffusers (Hugging Face), torchsde
|
Stable Diffusion等、Score-based SDE |
| 物理シミュレーション |
numpy, scipy, numba
|
Langevin方程式、確率Navier-Stokes |
| 生物・疫学 |
gillespy2, tellurium
|
化学Langevin、Gillespie法 |
| カルマンフィルタ |
filterpy, pykalman
|
状態空間モデル、トラッキング |
9-2. 例1:金融 — Heston モデルのモンテカルロ
import numpy as np
def heston_mc(S0, K, T, r, v0, kappa, theta, xi, rho, n_paths=10000, n_steps=252):
"""Heston モデルでヨーロピアン・コール価格をモンテカルロで評価"""
dt = T / n_steps
S = np.full(n_paths, S0, dtype=float)
v = np.full(n_paths, v0, dtype=float)
for _ in range(n_steps):
z1 = np.random.randn(n_paths)
z2 = np.random.randn(n_paths)
# 相関ブラウン運動
dW_S = np.sqrt(dt) * z1
dW_v = np.sqrt(dt) * (rho*z1 + np.sqrt(1-rho**2)*z2)
# 分散プロセス(CIR)
v = np.maximum(v + kappa*(theta - v)*dt + xi*np.sqrt(np.maximum(v,0))*dW_v, 0)
# 価格プロセス
S = S * np.exp((r - 0.5*v)*dt + np.sqrt(np.maximum(v,0))*dW_S)
payoff = np.maximum(S - K, 0)
return np.exp(-r*T) * payoff.mean()
price = heston_mc(S0=100, K=100, T=1.0, r=0.05,
v0=0.04, kappa=2.0, theta=0.04, xi=0.3, rho=-0.7)
print(f"Heston call price (MC): {price:.4f}")
コード解説:株価 $S$ と分散 $v$ の2本のSDEを同時にオイラー・丸山法で進めます。rho で2つのブラウン運動に相関を入れているのがHestonの特徴。最終時点の $\max(S_T - K, 0)$ の期待値を割引いてオプション価格にしています。
9-3. 例2:強化学習/物理 — Langevin方程式
import numpy as np
import matplotlib.pyplot as plt
# 粒子のポテンシャル U(x) = (x^2 - 1)^2 (ダブルウェル)
def grad_U(x):
return 4 * x * (x**2 - 1)
T_temp = 0.5 # 温度
gamma = 1.0 # 摩擦
dt = 0.001
n_steps = 100000
x = 0.0
trajectory = []
for _ in range(n_steps):
noise = np.sqrt(2 * gamma * T_temp * dt) * np.random.randn()
x = x - grad_U(x) * dt / gamma + noise / gamma
trajectory.append(x)
plt.hist(trajectory, bins=80, density=True)
plt.title("Stationary distribution of overdamped Langevin (double-well)")
plt.xlabel("x"); plt.ylabel("p(x)")
plt.show()
コード解説:摩擦付きで熱揺らぎを受ける粒子の運動。$U(x)=(x^2-1)^2$ なので2つのくぼみがあり、ヒストグラムは2山になります。これはマルコフ連鎖モンテカルロ(MCMC)のLangevin MCの基礎でもあります。
9-4. 例3:生物学/化学 — 化学Langevin(gillespy2を使わずnumpyで実装)
import numpy as np
import matplotlib.pyplot as plt
# Lotka-Volterra(捕食被食)の確率版:x=餌, y=捕食者
a, b, c, d = 1.0, 0.1, 1.5, 0.075
sigma_x, sigma_y = 0.1, 0.1
T, N = 30, 30000
dt = T/N
t = np.linspace(0, T, N+1)
x = np.empty(N+1); y = np.empty(N+1)
x[0], y[0] = 40, 9
for i in range(N):
dW1, dW2 = np.sqrt(dt)*np.random.randn(2)
x[i+1] = x[i] + (a*x[i] - b*x[i]*y[i])*dt + sigma_x*x[i]*dW1
y[i+1] = y[i] + (-c*y[i] + d*x[i]*y[i])*dt + sigma_y*y[i]*dW2
x[i+1] = max(x[i+1], 0); y[i+1] = max(y[i+1], 0)
plt.plot(t, x, label="prey")
plt.plot(t, y, label="predator")
plt.legend(); plt.xlabel("time"); plt.title("Stochastic Lotka-Volterra")
plt.show()
コード解説:通常のLotka-Volterraは綺麗な周期解になりますが、ノイズを加えると周期がよれて、長期的には片方が絶滅する確率も生じます。これは生態モデリングの基本テンプレートです。
9-5. 例4:ML/生成AI — Score-based diffusion の超ミニマル実装
import numpy as np
import matplotlib.pyplot as plt
# 1次元データ:2つの山の混合分布
def sample_data(n):
return np.where(np.random.rand(n) < 0.5,
np.random.randn(n) - 3,
np.random.randn(n) + 3)
# 真のスコア関数:∇log p(x)(混合ガウスの場合、解析的に書ける)
def score(x):
p1 = np.exp(-0.5*(x+3)**2)
p2 = np.exp(-0.5*(x-3)**2)
return ((-(x+3))*p1 + (-(x-3))*p2) / (p1 + p2)
# 逆SDE(Langevin sampling)でノイズ→データを生成
n_samples = 5000
x = np.random.randn(n_samples) * 5 # 初期:広い分布
dt = 0.01
for _ in range(2000):
x = x + score(x) * dt + np.sqrt(2*dt) * np.random.randn(n_samples)
plt.hist(x, bins=80, density=True, alpha=0.6, label="Generated")
plt.hist(sample_data(20000), bins=80, density=True, alpha=0.4, label="True")
plt.legend(); plt.title("Score-based generation via reverse SDE")
plt.show()
コード解説:これがStable Diffusionなどの核アイデアの1次元縮小版です。「対数密度の勾配(=スコア)」さえわかれば、Langevinサンプリングで分布からサンプルできる。実際の画像生成では、このスコアをニューラルネットで学習しています。
9-6. 例5:sdeintで一般のSDEを解く
# pip install sdeint
import numpy as np
import sdeint
import matplotlib.pyplot as plt
# OU過程: dX = -theta * X dt + sigma dW
theta, sigma = 1.0, 0.5
def f(x, t): return -theta * x
def g(x, t): return sigma
x0 = 2.0
tspan = np.linspace(0, 5, 1000)
result = sdeint.itoint(f, g, x0, tspan)
plt.plot(tspan, result)
plt.title("OU process via sdeint (Ito interpretation)")
plt.xlabel("t"); plt.grid(True); plt.show()
コード解説:sdeint.itoint は伊藤型のSDEを数値解する関数。itoSRI2 などより高精度なソルバーもあります。物理寄りならStratonovich型の stratint も使えます。
10. まとめ ― この記事で得たもの
最後に、この記事で散らかした概念を1枚に整理しておきます。
| キーワード | 一言で | 何のために |
|---|---|---|
| 測度 | 集合に数を割り振る関数 | 長さ・面積・確率を統一する |
| σ加法族 | 「測れる集合のクラブ」 | 測度を矛盾なく定義するため |
| 確率空間 | $(\Omega, \mathcal{F}, P)$ の3点セット | 確率論を厳密にやる土台 |
| リーマン積分 | 縦切り | 滑らかな関数 |
| ルベーグ積分 | 横切り | ギザギザな関数、期待値の厳密定義 |
| スティルチェス積分 | 別の関数の増分で重み付け | 一般の分布の期待値 |
| 伊藤積分 | $dW_t$ で積分する確率積分 | SDEを定義する |
| ブラウン運動 | 連続だが微分不可能なランダムパス | あらゆる連続時間ノイズの基準 |
| SDE | ドリフト+拡散の微分方程式 | 株価、粒子、人口…のランダム時系列 |
| 伊藤の補題 | 確率版の連鎖律、2次の項が残る | SDEの変数変換、ブラックショールズ導出 |
| ブラックショールズ | オプション価格の偏微分方程式 | デリバティブの価格付け |
「長さや面積を測る道具をうまく整理したら、確率も測れる。確率が測れるなら期待値も積分で書ける。ふつうの積分はノイズに弱いから伊藤積分を作る。2次の項が思わぬところに出てくる、それが伊藤の補題。それを使って金融も物理も生物もAIも、ぜんぶ同じ言葉で書ける。」
これが、この記事でお伝えしたかった全体像です。
ここからは、上のロードマップに沿って、興味のある応用分野から手を動かしながら学んでいくのが効率的です。Pythonコードを動かして、自分の手でブラウン運動を描いたり、オプション価格を計算したりしてみてください。抽象的だった式が、急に「物理的な意味のある量」に見えてくる瞬間が、確率微分方程式を学ぶ醍醐味です。
それでは、よい確率の旅を!
11. 伊藤清の後 ―― 確率微分方程式は、どう進化してきたか
ここまで、この記事をお読みくださった読者の皆様、有難うございました。
ここで、読者の皆様の中から、次のようなご質問をいただく可能性もあるかもしれません。
「確率微分方程式は、伊藤清の後、さらに改良・発展の積み上げはありますか? あるとした場合、純粋に数学の内部での積上げか、物理学や他の学問からの要請で積み上げられたのですか?」
これは本記事の締めくくりとして、非常に良い問いです。
結論から言うと、
伊藤清の1944年以降、確率微分方程式は約80年にわたって発展を続けており、その推進力は「純粋数学の内的な要請」と「物理・金融・工学・AIからの応用の要請」の両方 です。
しかも、応用からの要請が数学を前進させ、数学の進歩が新しい応用を開くという、双方向のキャッチボールが連続して起きてきました。
主な発展を、時系列でざっと俯瞰してみます。
11-1. 数学内部からの発展
純粋数学者が「伊藤の枠組みをもっと一般化したい・厳密化したい」という動機で進めた発展です。
| 年代 | 発展 | 一行で言うと |
|---|---|---|
| 1950年代〜 | マルチンゲール理論の整備(ドゥーブ、メイエ) | 「公平な賭け」を一般化した確率過程の理論を作り、伊藤積分の土台を強化した |
| 1960年代 | マリアバン解析の前段階(伊藤、ストロック、バラドアン) | 確率過程に対する「微分」のような概念を作る試み |
| 1970年代 | セミマルチンゲール理論(メイエ、デレシェリン) | 伊藤積分を、ジャンプを含むより広いクラスの確率過程に拡張 |
| 1976年 | マリアバン解析(マリアバン) | 確率過程上の「無限次元の微分積分」。後に金融工学のリスク計算にも使われる |
| 1980年代 | 確率流(stochastic flow)の理論(クニタ) | 確率微分方程式の解を、時刻に対して滑らかに動かす理論 |
| 1990年代 | 粗い経路理論(rough path theory)(ライアン、テリー・ライアンズ) | ブラウン運動より荒い「粗い経路」上でも積分を定義する革命的理論 |
| 2010年代 | 正則性構造理論(regularity structures)(マルティン・ヘアラー) | 「ノイズが空間と時間の両方に広がる」場合の確率偏微分方程式を厳密化。フィールズ賞(2014年)受賞 |
特に最後の**ヘアラーの正則性構造理論(2014年フィールズ賞)**は、伊藤の理論を高次元・空間方向にも拡張したもので、確率解析の現代における最大の到達点の1つです。
11-2. 物理学からの要請による発展
物理学者からの「こんな現象を扱える数学が欲しい」という要請が、数学を前に進めたケースです。
| 年代 | 発展 | 要請の出どころ |
|---|---|---|
| 1960年代 | ストラトノヴィッチ積分の体系化 | 物理学者ストラトノヴィッチが、座標変換に強い積分を提案。物理学では伊藤型より自然な場面が多い |
| 1970年代 | 確率偏微分方程式(SPDE)の理論 | 場の量子論、乱流、相転移を扱うため、時間だけでなく空間方向にも広がるノイズを含む方程式が必要に |
| 1980年代 | 無限次元確率解析 | 経路積分の数学的定式化、量子場理論の確率論的扱い |
| 1990年代〜 | KPZ方程式の解析(カルダル、パリージ、チャン) | 物理学者が界面成長を記述する方程式を1986年に提案。これを数学的に厳密に解けるようになったのが、上記のヘアラーの理論(2013年) |
ヘアラーがフィールズ賞を取った直接の動機は、物理学者が30年前に書いた KPZ 方程式を厳密に解くこと でした。これは「物理が数学を引っ張った」典型例です。
11-3. 金融工学からの要請による発展
ブラックショールズ(1973年)以降、金融市場の現実と理論のギャップを埋めるために、数学が呼ばれた発展です。
| 年代 | 発展 | 要請の出どころ |
|---|---|---|
| 1980年代 | マルチンゲール法による価格付け(ハリソン、クレプス、プリスカ) | リスク中立測度・ギルサノフの定理を金融に応用 |
| 1990年代 | 確率ボラティリティモデル(Heston、SABR) | ブラックショールズが説明できないIVスマイルを再現するため |
| 1990年代 | ジャンプ拡散モデル(Merton、Lévy過程) | 株価の急変動(ブラックマンデー等)を扱うため |
| 2000年代 | マリアバン解析の金融応用 | ギリシャ計算(オプションのリスク指標)を高速・高精度に行うため |
| 2000年代 | 後退確率微分方程式(BSDE)(パルドゥー、ペン) | 「将来時点の条件を満たすように現在を決める」という、金融工学特有の問題を扱う |
| 2010年代 | 粗い経路理論の金融応用、ラフボラティリティモデル(ローティング、ジャシアク) | 市場で観測される「ブラウン運動より粗いボラティリティ」を扱うため |
特に後退確率微分方程式(BSDE) は、「満期の条件から逆向きに現在の値段を決める 」というオプション価格付けの本質を捉えた理論で、いまや金融数学の中心的な道具です。
11-4. 機械学習・AIからの要請による発展
直近10年で爆発的に増えているのが、機械学習・AIからの要請です。
| 年代 | 発展 | 要請の出どころ |
|---|---|---|
| 2010年代 | SGDの確率微分方程式としての解析 | ニューラルネットの学習アルゴリズム(SGD)を連続時間SDEとして解析 |
| 2015年〜 | Neural SDE / Neural ODE(チェン、ルードルム) | ニューラルネット自体を確率微分方程式として表現する |
| 2020年〜 | 拡散モデル(Diffusion Models)(ソン、エルモン、ホー) | 画像生成AIの基盤としての逆時間SDE |
| 2022年〜 | スコアベース生成モデルの厳密化 | 高次元での収束保証、サンプリング効率の理論的解析 |
Stable Diffusion や DALL·E が世界を変えた背景には、伊藤の理論から続く確率微分方程式の80年の蓄積があります。
11-5. では、推進力はどちらだったのか?
冒頭の問いに戻ります。
「純粋に数学の内部での積上げか、物理学や他の学問からの要請で積み上げられたのですか?」
答えは、その両方が交互に推進力になってきた、です。
時系列で整理すると、次のような相互作用が見えてきます。
-
1944年:伊藤が純粋数学の内的な動機(コルモゴロフの確率公理の延長)で伊藤積分を発明
-
1950〜70年代:数学内部でマルチンゲール理論・セミマルチンゲール理論として整備
-
1973年:金融工学からの応用(ブラックショールズ)として爆発的に使われ始める
-
1980年代:金融の要請に応えて、数学側がマルチンゲール法・BSDEを発展
-
1986年:物理学が KPZ 方程式を提案 → 数学にとっての新しい課題に
-
2013年:数学が KPZ 問題を解くために正則性構造理論を作り、フィールズ賞へ
- 2020年〜:AIが拡散モデルとして確率微分方程式を再発見、生成AIブームへ
つまり、
「純粋数学が道具を作る → 応用が予想外の場所でそれを使う → 応用の限界を超えるため、また数学が新しい道具を作る」
というキャッチボールが、80年間続いてきたのです。
11-6. これからの確率微分方程式
最後に、現在進行形で起きている発展の方向性を、いくつか挙げておきます。
- 高次元・無限次元:機械学習で扱う「数百万次元のパラメータ空間」の確率過程
- 空間方向に広がるノイズ:気候モデル・流体・量子場理論(SPDE、正則性構造理論)
- 粗い経路・ラフボラティリティ:金融市場の現実をより正確に捉えるための新しい理論
- 平均場ゲーム(Mean Field Games):無数のエージェントが相互作用する経済・群衆動学
- 量子確率論:量子力学と確率論を統合する試み(ホーフェ=クリュンマー、本書のコラムも参照)
確率微分方程式は、伊藤清が1944年に作ったときには想像もできなかった広がりを持つに至り、いまなお現役で進化を続けている数学です。
本記事を読み終えた皆様が、もし論文や教科書でこれらの最新の発展に出会ったとき、「あぁ、これは伊藤の理論の延長線上にあるんだな」と気づける――そんな状態になっていれば、本記事の役目は果たせたのではないかと思います。
📖 コラム:「観測するまで値が決まらない」 ―― 確率微分方程式は量子力学でも使われる?
確率微分方程式の主役 $X_t$ は、本記事で繰り返し説明したとおり、「ある時刻 $t$ における1つの数値」ではなく、「ある時刻 $t$ にとりうる値の確率分布」 でした。
これは、量子力学で「観測するまで状態が1つに決まらない 」と言われている性質と、見た目がよく似ています。
このコラムでは、この直感を出発点に、確率微分方程式と量子力学の関係を整理しておきます。
① 「観測するまで値が決まらない」という直感は、半分正しい
確率微分方程式と量子力学には、確かに似ている部分があります。
| 量子力学 | 確率微分方程式(SDE) | |
|---|---|---|
| 観測前は | 値が1つに決まらない(重ね合わせ状態) | 値が1つに決まらない(無数のサンプルパス) |
| 観測すると | 1つの値に"収束"する(波動関数の収縮) | 1つのサンプルパスが実現する |
| 予測できるのは | 確率分布だけ | 確率分布だけ |
「観測するまで値が1つに決まらない」 という直感は、両方の世界で本当にその通りです。
② ただし、「ランダムさの源」は本質的に違う
ここが大事なところです。
-
確率微分方程式のランダムさ:私たち観測者が、システムの細かい情報を知らないから生まれる「実用上のランダムさ 」。原理的には、もっと細かく観測できれば減らせる。
- 量子力学のランダムさ:自然そのものに組み込まれた「根源的なランダムさ 」。どんなに細かく観測しても、減らせない。
アインシュタインが「神はサイコロを振らない 」と言って量子力学に違和感を表明したのは、まさにこの「自然そのものがサイコロを振っている」という量子力学の主張に対する反発でした。
③ では、量子力学で確率微分方程式は使われるのか?
使われます。しかも、いろんな場面で。
代表的なものを3つ挙げます。
③-1:確率シュレーディンガー方程式(連続観測の量子力学)
普通のシュレーディンガー方程式は、決定論的(=ランダム項なし)です。
ところが、量子系を連続的に観測している状況をモデル化すると、観測のたびに波動関数がランダムに揺さぶられます。これを記述するのが、
$$
d|\psi_t\rangle = (\text{決定論的な項}), dt + (\text{ランダムな項}), dW_t
$$
という形の確率シュレーディンガー方程式で、これはまさに確率微分方程式(SDE)です。
③-2:経路積分とウィーナー測度
量子力学のファインマン経路積分は、「あらゆる可能な経路を足し合わせる」という発想で粒子の運動を記述します。
実は、これを数学的に厳密に定義しようとすると、本記事第3章のコラムに出てきたウィーナー測度(=ブラウン運動のパス空間の上の測度)が登場します。
ファインマンの経路積分と、伊藤の確率微分方程式は、同じウィーナー測度の上に住んでいる兄弟のような関係にあるのです。
③-3:開放量子系(環境とのやり取り)
完全に閉じた量子系は決定論的ですが、現実の量子系は周囲の環境とエネルギーや情報をやり取りしています。
この「環境からのランダムな影響」をモデル化するのに、確率微分方程式が使われます。
これは量子コンピュータの開発などで、量子ビットが時間とともにどう壊れていくか(=デコヒーレンス)を計算するときに、いま現役で使われている数学です。
④ 伊藤清自身は量子力学から着想を得たのか?
着想の由来について(史実の確認) :
伊藤清の伊藤積分の着想について、本人の論文・回顧録から確認できる動機は、主に以下の2つです。
① コルモゴロフ(1933年)が公理化した確率論の枠組みの上で、確率過程の理論を厳密に構築したかった
② マルコフ過程の解析的理論(コルモゴロフ前進方程式・後退方程式)を、もっと直接的に「サンプルパスの言葉」で扱いたかった
統計力学のブラウン運動の理論(アインシュタイン1905年、スモルコフスキー、ランジュバン1908年など)は、当時すでに確率論の標準的な対象として認識されていたため、間接的な影響は当然あったと考えられます。
一方、量子力学からの直接的な影響パスは、史実として確認できませんでした。同時代の量子力学(1925〜1930年代の本格的整備)と伊藤積分(1944年)には時期的な重なりがありますが、伊藤本人が量子力学の文献から着想を得たという記録は、現時点では見つけられていません。
(ファインマンの経路積分(1948年)が後にウィーナー測度の言葉で再定式化され、量子力学と確率微分方程式が深く結びつくのは、伊藤積分の登場よりも後の話です)
⑤ まとめ
「観測するまで値が1つに決まらない」 という直感は、量子力学と確率微分方程式の深い類似を捉えています。
ただし、ランダムさの起源は違います(実用上 vs 根源的)。
それでも数学的な道具立ては共通する部分が多く、量子力学の現代的な定式化のいくつかは、確率微分方程式の言葉で書かれています。
本記事で積み上げた「測度論 → ルベーグ積分 → 伊藤積分 → 確率微分方程式」という道筋は、金融工学やAI画像生成だけでなく、量子力学の最前線にもつながっているということです。
このコラムが、同じ疑問を持たれた他の読者の方の参考になれば幸いです。
Appendix:直感的説明と厳密な数学的議論との橋渡し ― 専門書に進む読者のために
本記事は冒頭でお断りしたとおり、想定読者の方が全体像を素早く掴めるよう、直感的なイメージを優先して執筆しました。その結果、数学的な厳密さの観点からは省略・簡略化した箇所がいくつかあります。
これらは入門段階では大きな問題になりませんが、本記事をきっかけに専門書へ進まれる読者の方が、本記事の説明と専門書の記述との「言い回しの違い」に戸惑わないよう、主な相違点を以下に整理しておきます。
専門書で正確な定式化に出会ったときに、「ああ、あの記事で噛み砕いて書いていたのはこれのことか」と思い出していただけたら幸いです。
A-1. σ加法族の本質と、ルベーグ非可測集合の存在
本文第1章では、σ加法族を「測れる集合のメンバーシップ・クラブ」と説明しました。これはイメージとしては有効ですが、σ加法族の本質は「補集合をとる操作」と「可算個の集合の和をとる操作」について閉じている、という代数的構造にあります。
接頭辞の「σ」は、まさにこの可算個の操作で閉じていることを意味します。この性質があるからこそ、測度論は極限操作(単調収束定理・優収束定理など)と整合的に振る舞い、リーマン積分の欠点を克服できるのです。専門書ではこの可算加法性が冒頭で必ず強調されますので、押さえておいてください。
また、「全ての集合に綺麗に数を割り当てるのは無理」の根拠として本文ではバナッハ=タルスキーのパラドックスに言及しましたが、これは選択公理と3次元体積についての別の文脈の話です。ルベーグ測度に関して「測れない集合」が存在することの直接的な根拠は、ヴィタリ集合(Vitali set)の存在であり、専門書ではこちらが標準的に紹介されます。
A-2.「至るところで微分不可能」は確率1の命題である
本文第2章で「ブラウン運動は至るところで連続だが、至るところで微分不可能」と述べました。これは正確には、
ブラウン運動のサンプルパス $W_t(\omega)$ は、ほとんど確実に(almost surely、確率1で)、すべての時刻 $t$ で微分不可能である
という命題です。確率0の例外的なサンプルパスでは微分可能になる可能性が残ります。確率論では「ほとんど確実に(a.s.)」という限定が至るところに付くのが標準で、本文ではこれを省きました。
A-3.「$(dW_t)^2 = dt$」は形式的記法であり、サンプルパスごとの等式ではない
本文第4章で伊藤のかけ算の規則として「$dW_t \cdot dW_t = dt$」と書きましたが、これは形式的・記号的な略記であり、ある時刻 $t$ における $dW_t$ という値が $dt$ という値に等しい、という意味の等式ではありません。
正確には、ブラウン運動の**二次変分(quadratic variation)**が
$$
\langle W \rangle_t = \lim_{|\Pi|\to 0} \sum_{i} (W_{t_{i+1}} - W_{t_i})^2 = t \quad \text{(確率収束の意味で)}
$$
となる、という事実を、伊藤の補題のテイラー展開で使うときに $(dW_t)^2 \to dt$ と簡略表記しているにすぎません。本来は二次変分という概念を経由して厳密化されるものですので、専門書ではここを丁寧に追ってください。
A-4. ブラックショールズ導出における「自己充足ポートフォリオ」と「リスク中立測度」
本文第5章では、Δヘッジによる「ランダム項の打ち消し」というイメージでブラックショールズ偏微分方程式を導出しました。この説明は直感的にはわかりやすい一方で、厳密な金融数学では以下の二点が補われる必要があります。
第一に、本文の議論では「Δを連続的にリバランスできる」という強い仮定が暗黙に置かれています。厳密には、**自己充足ポートフォリオ(self-financing portfolio)**という、追加投入や引き出しのないポートフォリオ条件を満たす過程として、ヘッジ戦略を定式化する必要があります。
第二に、現代的なブラックショールズの導出はΔヘッジ論法だけでなく、リスク中立測度(同値マルチンゲール測度)への変換を経由するのが標準です。元の確率測度 $P$ から、株価の割引過程がマルチンゲールとなる新しい測度 $Q$ への変換をギルサノフの定理(Girsanov's theorem) によって行い、オプション価格を $Q$ の下での期待値として表現します。本記事ではこの測度変換の枠組みには触れませんでしたが、Shreve II など本格的な金融数学の教科書では中心的なテーマになります。
A-5. 第3章のPythonコードは「ルベーグ積分の定義そのもの」ではない
本文第3章で「ルベーグ積分っぽい計算」として掲載したPythonコードは、実は
$$
\int_0^1 f(x), dx = \int_0^\infty P(f(X) > y), dy \quad (X \text{は }[0,1]\text{ 上の一様分布})
$$
という**層別公式(layer cake representation)**を計算しています。これはルベーグ積分から導かれる結果として正しい等式であり、「横切りの発想」を体感する目的には適していますが、ルベーグ積分の定義そのものを実装したものではありません。
ルベーグ積分の本来の定義は「単関数(有限個の値しかとらない可測関数)の積分を経由して、可測関数の積分を単調極限として定義する」という、より構成的な手続きを踏みます。本文の表現「ルベーグ積分っぽい」はこのギャップを暗に示唆していますが、専門書では定義の手順そのものを追っていただくことをお勧めします。
A-6. 伊藤積分の定義と「適合性」の役割
本文第3章で伊藤積分を「2乗平均的に足し合わせる」と説明しましたが、より正確な定義は次のような構成になります。
- まず、**適合過程(adapted process)**であって階段関数的に表される単純過程に対して、伊藤積分を有限和として直接定義する
- その単純過程の空間で $L^2$ ノルム(2乗ノルム)に関するコーシー列の極限として、より一般の被積分過程に対する伊藤積分を拡張定義する
ここで決定的に重要なのが、被積分過程が適合的であること、すなわち各時刻 $t$ における被積分関数の値が、その時刻までの情報のみに依存し、未来を覗き見していない、という条件です。
実は、本文ではほとんど触れませんでしたが、伊藤積分とストラトノヴィッチ積分の差は、まさにこの「どの時点の値で被積分関数を評価するか」の違いから生じます。伊藤積分は各小区間の左端の値で評価し(未来を覗かない=適合性と整合)、ストラトノヴィッチ積分は中点で評価します。この違いから、伊藤積分はマルチンゲール性を持ち(金融で扱いやすい)、ストラトノヴィッチ積分は通常の連鎖律に従う(物理で扱いやすい)、という応用上の使い分けが生まれます。
本記事では第3章の表でこの2つを並置しただけでしたが、専門書ではこの「離散近似での評価点の取り方の違い」が必ず詳しく説明されますので、定義を追う際にぜひ注目してください。
以上の補足は、本記事の説明が「誤り」であったことの事後修正を目的とするものではなく、入門用の解説文として、意識的に犠牲にした厳密性が、専門書では中心的な役割を果たしている、という点を明示するためのものです。
本記事で全体像を掴んだ上で、これらの厳密化のポイントを意識して専門書を読まれると、定義の一つ一つに「なぜわざわざこんな面倒な書き方をするのか」という納得感が伴って読み進められるはずです。