DataFrame の流儀は財務モデルにどう現れるか ── R・Python・Julia による DCF 実装比較

⚠️ 本記事に登場する「エタール重工株式会社」は完全な架空企業です。実在の企業・団体とは一切関係ありません。
ただし、本記事に登場する財務構造・事業セグメント比率・営業利益率などは、実在する日本の総合重工業のオープンデータ(統合報告書・有価証券報告書・決算短信)を参照し、この業界の企業として、現実味のある架空企業の姿 を追求しました。
👥 想定読者 ── この記事は、こんな皆様のために書きました

本記事は、姉妹編前編「import pandas as pd の背後にある 50 年 ── Bell Labs・R・金融工学・Julia へ続く DataFrame の系譜」と同じく、以下の 5 つのペルソナ の皆様を想定読者としております:
ペルソナ ①: pandas を日常的に使うデータサイエンティスト・BI エンジニア・機械学習エンジニア
「pd.DataFrame で売上分析や顧客セグメンテーションは日常的に書いているけれど、財務モデル(3 表連動、DCF、Monte Carlo) をコードで書いたことはない」── そんな読者の皆様へ。
本記事は、あなたの慣れ親しんだ pandas の世界から、企業価値評価という クオンツ・FP&A の領域 への橋渡しを提供します。
ペルソナ ②: R や Julia を使う統計学者・計量経済学者・科学計算研究者
「dplyr のパイプラインや DataFrames.jl の型安定性は熟知しているが、Python の流儀との比較 を実コードで体感したい」── そんな皆様へ。
本記事は、同じ DCF 問題を 3 言語で書き分け、言語の思想差 をコードレベルで明らかにします。
ペルソナ ③: 金融業界のエンジニア・クオンツ・FP&A 担当者
「Excel(Power Pivot、Power Query、Power Automate)とコード(Python / R / Julia)の どちらを採用すべきか、判断材料がほしい」── そんな方々へ。
本記事は、両者の 接続パターン 5 種 を実装例とともに示し、組織の現実に即した使い分けの指針を提供します。
ペルソナ ④: 言語設計に関心のあるソフトウェアエンジニア
「3 つの言語の DataFrame 文化 の違いを、実コードで比較したい」── そんなあなたへ。
本記事は、Python(データサイエンティスト文化)・R(統計学者文化)・Julia(数値計算研究者文化)の思想差を、同一の財務モデル問題を通じて体験していただきます。
ペルソナ ⑤: これからデータ分析を学ぶ学生・新人エンジニア
「pd.DataFrame の本当の威力を、ビジネスの現場で価値を生み出す具体例 で学びたい」── そんな読者層の方へ。
本記事は、エタール重工株式会社という架空企業を題材に、企業価値評価という 数千億円規模の意思決定の現場 で使われる実装パターンを、丁寧に解説します。
なお、本記事は前編よりも 実装レベルが上がり、想定読者には 中級〜上級者 も含みます。
ただし、財務モデリングの概念は、前編同様、プログラマーの言葉で説明しますのでご安心ください。
💎 この記事を読む価値 ── なぜ時間を割いて読むべきか
長文の技術記事を読むのは、決して安くない時間投資です。気になる章だけ拾い読みでも十分使えますが、ここではまず、読む前と読んだ後で、あなたの何が変わるのか を明示します。

読む前の状態 → 読んだ後の状態
| 領域 | 読む前 | 読んだ後 |
|---|---|---|
| DCF バリュエーション | 教科書で式は見たことがある | 3 言語のいずれかで、自社の架空モデルを書ける |
| 3 表連動モデル | Excel のセル参照では作れる | コードで P/L / B/S / C/F の整合性を自動検証できる |
| シナリオ分析 | 楽観・基準・悲観の概念は知っている | 3 シナリオを関数として実装し、再利用できる |
| 感応度分析 | Tornado Chart を見たことはある | 自分で 10 パラメータの感応度を数値微分で算出できる |
| Monte Carlo | 「乱数を振る方法」と聞いたことはある | 10,000 試行で理論株価分布(P10/P50/P90)を出せる |
| 3 言語比較 | Python は知っている、R / Julia は遠い | R / Julia の流儀を Python との対比で理解 |
| Excel との関係 | コード or Excel の二者択一だと思っていた | 両者を接続する 5 パターンを業務で使い分けられる |
| WACC・ターミナルバリュー | 概念だけ知っている | CAPM ベースで自分で計算し、感応度も評価できる |
具体的な「お持ち帰りいただける成果物」
本記事を読み終えると、あなたは以下を コピー&貼り付けで即座に使える 状態で獲得します。

-
3 言語(Python / R / Julia)で書かれた、完全に同じ DCF 財務モデルのコード ── 自社の数値に置き換えれば、すぐに使える
-
シナリオ分析のクラス設計 ── 楽観・基準・悲観の 3 シナリオをパラメータ化したテンプレート
-
Tornado Chart の Python 実装 ── 10 パラメータの感応度を ±10% 変化で評価
-
Monte Carlo の高速実装(3 言語) ── Python 30 秒、Julia 3 秒の性能差を実証
-
Excel ↔ コードの接続パターン 5 種 ── 経理・財務部門と分析部門の連携設計図
-
3 言語の使い分けマトリクス ── 「どの場面でどの言語を選ぶか」の判断基準
- エタール重工株式会社の完全な設定 ── 創業 1887 年、売上 8,200 億円、4 事業セグメント、5 年の過去実績 ── 自社の業界に置き換えるための テンプレート企業
想定読者ペルソナ別の「得られる利益」

| ペルソナ | 主な得られる利益 |
|---|---|
| ① データサイエンティスト | pandas の活用領域が「マーケティング・機械学習」から「企業価値評価」へ拡張される |
| ② 統計学者・計量経済学者 | R / Julia の流儀を、Python との対比で再認識できる |
| ③ 金融業界実務家 | Excel と Python / R / Julia を接続する具体的設計図が手に入る |
| ④ ソフトウェアエンジニア | 3 つの DataFrame 文化の違いが、コードレベルで体感できる |
| ⑤ 学生・新人エンジニア | 「pd.DataFrame が数千億円規模の意思決定に使われる現場」を疑似体験できる |
本記事の品質方針
エタール重工株式会社の財務構造は、実在する日本の総合重工業のオープンデータ(統合報告書・有価証券報告書・決算短信)を丁寧に参照して構築しました。コードは、すべて実際に動作する完全な実装です。
戦略コンサルタント、公認会計士、税理士、中小企業診断士、FP&A、銀行(融資査定ご担当)、投資銀行(M&A Valuationご担当、資本政策ご支援担当等)、業界実務家の方々が読まれても、業界の実態に近い題材として参考にしていただける品質を目指しました。
🧭 この記事の位置づけ ── 姉妹編後半としての本記事
姉妹編構造の中での本記事
本記事は、独立した 2 部構成のうちの 後半 にあたります:

姉妹編・全体構造
│
├── 前編(2026/05/15 公開済み):
│ 「import pandas as pd の背後にある 50 年 ──
│ Bell Labs・R・金融工学・Julia へ続く DataFrame の系譜」
│ ─→ 歴史的・概念的アプローチ
│ ─→ R(1976)→ Python(2008)→ Julia(2012)の時系列順
│ ─→ DataFrame 概念の知的伝統を体系化
│
└── 後半(本記事):
「3 表連動・DCF・Monte Carlo を R / Python / Julia で実装する ──
重工業企業の財務モデルを書き比べる」
─→ 実装的・実務的アプローチ
─→ Python → R → Julia の順序(Qiita 読者の関心優先順)
─→ 同じ財務モデルを 3 言語で書き比べる
前編と後半は、「歴史を学んでから実装へ」 という自然な学習曲線を描くペアとして設計されています。
ただし、前編を未読でも、本記事単独で十分に理解できる構成にしています(前編へのリンクは適宜挿入してあります)。
連載シリーズとの関係
本記事の Qiita 連載は、以下の構造になっています:
| 区分 | 記事 | 状態 |
|---|---|---|
| 別の連載シリーズ(第 1 回) | 「90 日遅れる経営」を、React × Claude Code + MCP で作り直す ─ ERM × FP&A 統合パイプライン | 2026/05/12 公開済 |
| 別連載(第 2 回以降) | 別途企画中 | 未公開 |
| 姉妹編・前編(本記事の前編) | import pandas as pd の背後にある 50 年 | 2026/05/15 公開済 |
| 姉妹編・後半(本記事) | 3 表連動・DCF・Monte Carlo を R / Python / Julia で実装する | 本記事 |
本姉妹編(2本の記事)は、別の連載シリーズ記事からは独立した企画 として位置づけられています。しかし、内容的には相互にリンクしています。あわせてお読み頂けましたら大変幸いです。
実装順序の変更について
📌 重要:姉妹編前編(import pandas as pd の背後にある 50 年)では、言語が設計・開発・公開された時系列順に、R → Python → Julia の順に取り上げました。
しかし、姉妹編後半の本記事では、坤為地、データサイエンス界隈で(Rよりも)広く使われている Python を最初に取り上げ、Python → R → Julia の順番で展開していきます。
Qiita では Python ユーザーが圧倒的多数を占めるため、最も馴染みのある Python から入って、R・Julia の異なる流儀 を体験していただく構成です。
読み方は自由
長文記事ですが、気になる章から読んでいただいて構いません。

- まず全体像をつかみたい方は、冒頭の「結論先取り」と「完成アウトプット」だけ でも十分価値があります
- Python の実装例だけ見たい方は、第 3 章 にお進みください
- Excel との接続パターンが気になる方は、第 5.5 章 に飛んでも OK です
- DCF / Monte Carlo の実装だけが目的なら、第 8〜9 章 だけでも構いません
各章には進捗チェックリストが置いてあるので、いまどこを読んでいるかが分かるようにしています。
なお、流し読みなら 40〜60 分、コードを手元で実際に動かしながら読めば数時間〜1 日程度の分量です。お時間のある時に、お気軽にどうぞ。
🎯 結論先取り(Conclusion Comes First)── この記事で示すこと
長文記事だからこそ、結論を最初に お伝えします。本論に入る前に、まず本記事の主張を整理させてください。
主張 1: 同じ DCF モデルを 3つの言語で書くと、答えは完全に同じ。しかし、コードの「書き味」は全く異なる
3 言語(Python / R / Julia)で書かれた 完全に同じ DCF モデル から得られる結果:
| 指標 | Python | R | Julia |
|---|---|---|---|
| WACC | 4.18% | 4.18% | 4.18% |
| エンタープライズバリュー | 14,585 億円 | 14,585 億円 | 14,585 億円 |
| エクイティバリュー | 11,685 億円 | 11,685 億円 | 11,685 億円 |
| 理論株価 | 8,890 円 | 8,890 円 | 8,890 円 |
数値は同じ。しかし、コードを書く流儀は全く異なります。Python は データクラス + メソッドチェーン で書き、R は %>% パイプラインの宣言的記述 で書き、Julia は struct + 複数ディスパッチ で書きます。
主張 2: 3つの言語の違いは「DataFrame 文化」の違いに集約される
| 言語 | 文化 | 由来 | 強み |
|---|---|---|---|
| Python | データサイエンティスト文化 | AQR Capital(2008) | エコシステムの広さ、機械学習との統合 |
| R | 統計学者文化 | Bell Labs(1976) | 統計分析、論文クオリティの可視化 |
| Julia | 数値計算研究者文化 | MIT(2012) | 高速実行、自動微分、SDE |
財務モデリングの文脈では:
- Python:大半のケースの第一選択肢(Streamlit、Dash、機械学習統合)
- R:学術発表、規制当局報告、論文補足コード
- Julia:Monte Carlo を数百万試行、SDE 含む金融モデル、本番システム
主張 3: Excel(Power 機能搭載)とコードは、対立ではなく接続が現実解

2026 年の経理・財務・経営企画部門では、まだまだ Excel 文化が根強い印象があります。
Excel も Power Pivot、Power Query などの高品質でエレガントな機能が搭載されて強化されており、さらに、Power Automate を使うことで、Microsoft や Microsoft 以外の他の BI プラットフォームとの接続も可能な時代になりました。
本記事の第 5.5 章では、Excel の Power 機能群と R / Python / Julia を接続する 5 つの典型パターン を示します:
- パターン A:コード → Excel ファイル出力
- パターン B:Excel(Power Query 前処理済み) → コード読み込み
- パターン C:Power BI ↔ R / Python スクリプト
- パターン D:Power Automate ↔ FastAPI 製 Python API
- パターン E:Office Scripts ↔ Azure Functions
「コード一辺倒」も「Excel 一辺倒」も、組織の実態に合いません。
主張 4: Monte Carlo シミュレーションこそ、コードベースの真価が発揮される領域
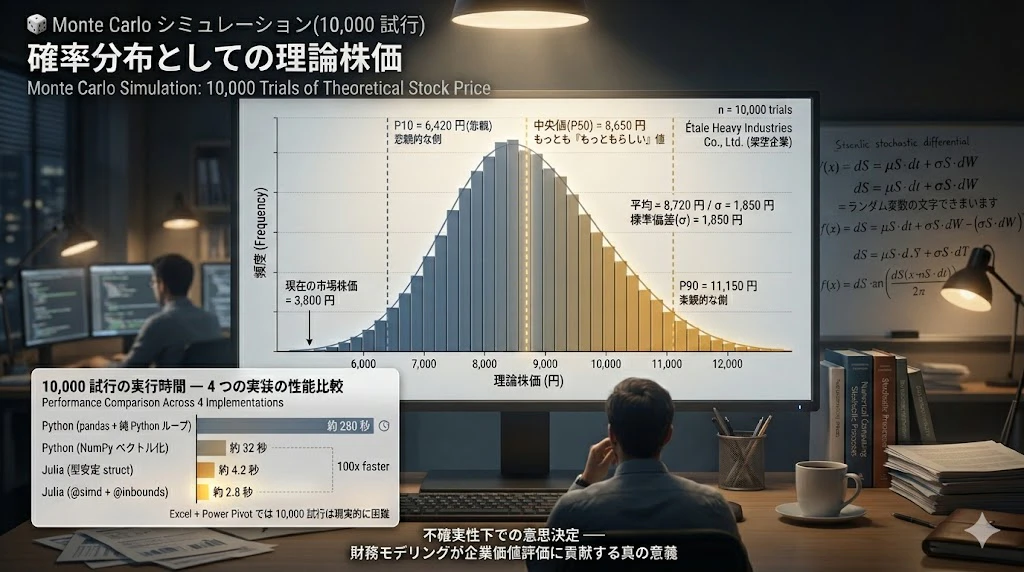
10,000 試行の Monte Carlo シミュレーション ── Excel + Power Pivot では現実的に困難。
しかし、コードであれば:
| 言語 | 10,000 試行の実行時間 |
|---|---|
| Python(pandas + 純 Python ループ) | 約 280 秒 |
| Python(NumPy ベクトル化) | 約 32 秒 |
| Julia(型安定 struct) | 約 4.2 秒 |
Julia(@simd + @inbounds) |
約 2.8 秒 |
そして得られる結果は、確定的な「1 つの理論株価」ではなく、確率分布としての理論株価:
平均(理論株価): 8,720 円
中央値(P50): 8,650 円
P10(下位 10%): 6,420 円 ← 悲観的な側
P90(上位 10%): 11,150 円 ← 楽観的な側
標準偏差: 1,850 円

VUCA(ブーカ)── 不確実性の時代を表す経営用語
ここで一つ、経営層やコンサルタントの世界で広く使われている用語を
紹介します。VUCA(ブーカ) という言葉です。
$VUCA$ は、$Volatility$ (変動性)、$Uncertainty$ (不確実性)、$Complexity$ (複雑性)、$Ambiguity$ (曖昧性) の頭文字をとった4文字の略語です。
| 字 | 英語 | 日本語 | 意味 |
|---|---|---|---|
| V | $Volatility$ | 変動性 | 変化の速度と振幅が大きい |
| U | $Uncertainty$ | 不確実性 | 因果関係が予測しにくい |
| C | $Complexity$ | 複雑性 | 多変量が相互に作用する |
| A | $Ambiguity$ | 曖昧性 | 同じ事実が複数の解釈を許す |
VUCA の由来 ── 冷戦後の米軍から経営の世界へ
$VUCA$ は元々、1980 年代後半から 1990 年代初頭にかけて、米陸軍戦争大学(US Army War College) が、冷戦終結後の新しい戦略環境を表現するために使い始めた概念です。
冷戦時代の世界は、米ソ二大陣営の対立という、ある意味で「予測可能な不確実性」の中にありました。(相互確証破壊戦略等)
しかし冷戦が終わった後の世界は、
- 多数の地域紛争が同時並行で発生する(複雑性)
- 国家ではない主体(テロ組織、民兵組織)が登場する(曖昧性)
- 経済・政治・技術の変化速度が加速する(変動性)
- 因果関係が単純な「敵 vs 味方」では捉えられなくなる(不確実性)
という、それまでとは質的に異なる戦略環境になりました。
これを表現する言葉として、米軍の戦略理論家集団は、 $VUCA$ という頭字語を考案しました。
その後、2000年代以降、この概念は経営戦略・企業リスク管理の文脈で広く採用されていきます。
McKinsey、BCG、Bain などの戦略コンサルティング・ファーム、
HBR(Harvard Business Review)、MIT Sloan Management Review、IMD などのビジネススクール、そして世界経済フォーラム(WEF)などが、「現代の経営環境を表す枠組み」 として、$VUCA$ という概念フレームワーク を活用するようになりました。
なぜ財務モデリングがVUCAと結びつくのか
ここからが、本記事のプログラマ・データサイエンティスト読者の方々に、特にお伝えしたい論点です。
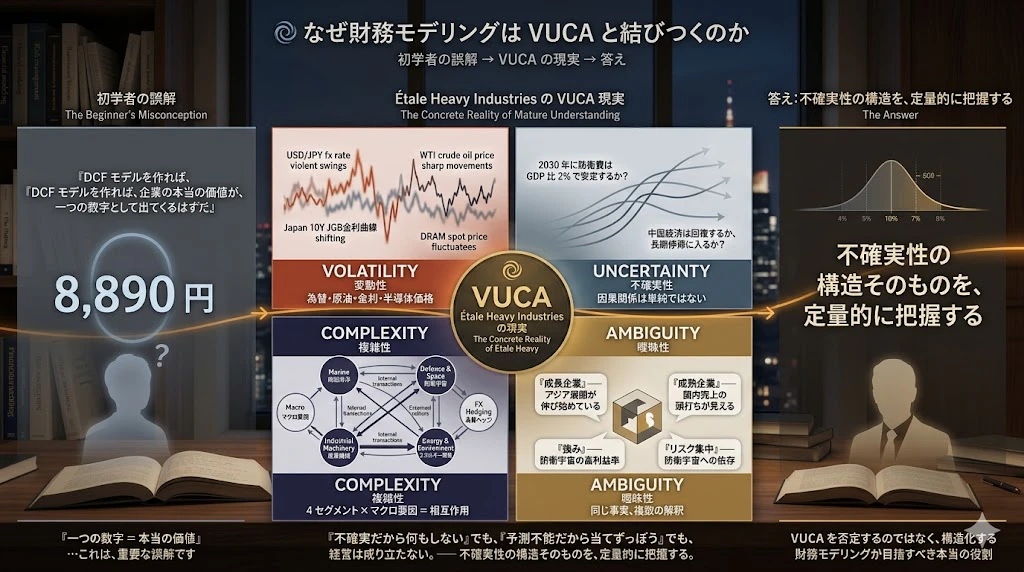
財務モデリングの初学者は、しばしば次のように考えます。
「DCF モデルを作れば、企業の『本当の価値』が一つの数字として出てくる。
例えば、エタール重工の理論株価は 8,890 円である、と。」
これは、重要な誤解 です。
実際の経営の現場では、企業を取り巻く環境は $VUCA$ そのものです。
-
$Volatility$ :
為替が動く、原油価格が動く、金利が動く、半導体価格が動く。
1つの仮定の変化で、企業価値は数百億円単位で変動します。
-
$Uncertainty$:
「2030 年に防衛費は GDP 比 2% で安定するか?」
「中国経済は回復するか、長期停滞に入るか?」── 因果関係は単純ではなく、予測は本質的に不可能です。
-
$Complexity$:
エタール重工の事業セグメントは 4つ、それぞれが異なるマクロ要因に異なる感応度で反応します。さらに、セグメント間の内部取引、為替ヘッジ、研究開発投資の長期効果
── すべてが相互作用します。
-
$Ambiguity$:
同じ決算数字を見ても、「成長企業」と解釈する人と「成熟企業」と解釈する人がいます。同じセグメント業績を見ても、「強み」と読む人と「リスク集中」と読む人がいます。
このような VUCA 環境の中で、経営者・投資家・アナリストは、それでも意思決定を下さなければなりません。
「不確実だから何もしない」では経営は成り立たない。
「予測不能だから当てずっぽうに決める」でも経営は成り立たない。
ではどうするか。
「不確実性の構造そのものを、定量的に把握する」
── これが答えです。
財務モデリングが提供するもの ── 確定値ではなく「分布」
ここで、本記事のクライマックスである Monte Carlo シミュレーション が、決定的な意味を持ってきます。
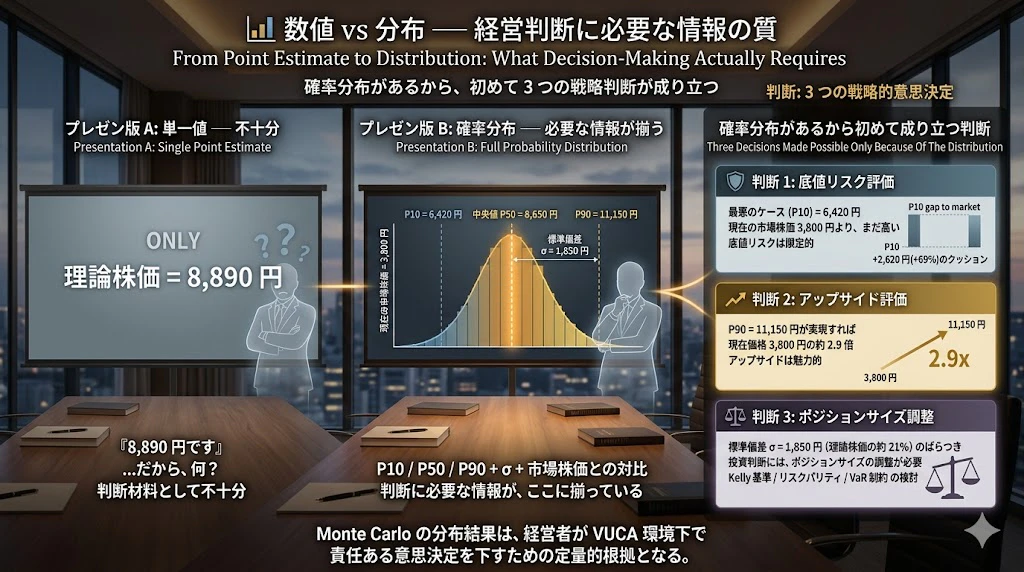
| 古典的なアプローチ | VUCA 時代のアプローチ |
|---|---|
| 単一の DCF 結果:「理論株価は 8,890 円」 | 確率分布:「中央値 8,650 円、P10 = 6,420 円、P90 = 11,150 円」 |
| 1 つの「答え」を出す | 不確実性の構造を可視化する |
| 当たれば正しい、外れれば間違い | どのくらいの確率で、どのくらいの範囲に収まるかを示す |
| 経営判断の根拠が脆弱 | 経営判断の根拠が頑健 |
経営者が会議で「理論株価は 8,890 円です」と言われても、判断材料としては不十分です。
市場で何が起きるかわからない以上、
「8,890 円という単一の数値」
は、説得力のない一点突破にすぎません。
しかし、
「中央値 8,650 円、ただし P10 = 6,420 円(悲観的な側)、
P90 = 11,150 円(楽観的な側)、標準偏差 1,850 円」
という確率分布として提示されれば、
経営者は次のように判断できます:
- 「最悪のケースでも 6,420 円なら、現在の市場株価 3,800 円より
まだ高い。底値リスクは限定的だ」
- 「P90 の 11,150 円が実現すれば、現在価格の 3 倍近い。アップ
サイドは魅力的だ」
- 「ただし標準偏差 1,850 円のばらつきがある。投資判断には、
ポジションサイズの調整が必要だ」
つまり、Monte Carlo の分布結果は、経営者が VUCA 環境下で責任ある意思決定を下すための、定量的な根拠 となるのです。
プログラマ・データサイエンティストの皆様へ

本記事を読まれているプログラマ・データサイエンティストの方々は、日々 pd.DataFrame でデータを操作し、matplotlib でチャートを描き、scikit-learn で機械学習モデルを訓練されているかもしれません。
その技術スキルは、マーケティング分析、推薦システム、需要予測など、すでに多くのビジネス価値を生み出しています。
しかし、その同じ技術スキルが、企業の生存と発展を左右する経営判断の現場 でも、決定的な貢献ができることを、本記事で実感していただければと願います。
第8章で実装する DCF、第 9 章で実装する Monte Carlo シミュレーション
── これらは、抽象的な学術モデルではありません。世界中の経営会議室、投資委員会、M&A デューデリジェンスの現場で、今日も実際に動いているコード です。
そして、それらのコードを動かす目的は、ただ一つ。
VUCA 環境下で意思決定を下す責任ある人々を、定量的に支援すること。
財務モデリングを学ぶことは、単に新しい技術領域を学ぶこと以上の意味を持ちます。
それは、経営者・コンサルタント・投資家の眼差しで世界を見る視座を獲得すること でもあります。
不確実性下での意思決定 ── これが、財務モデリングが企業価値評価に貢献する真の意義です。
主張 5: 財務モデリングの本質は、DataFrame という共通の知的伝統
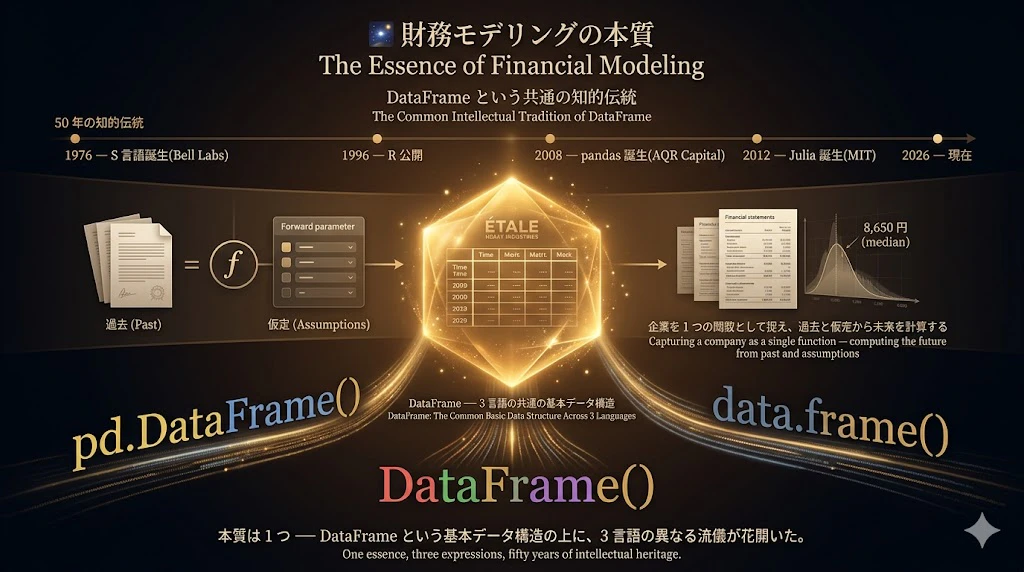
3つの言語のコードは異なっても、本質は 1 つ です:
「企業を 1 つの関数として捉え、過去と仮定から未来を計算する」
その関数の 基本データ構造 が、DataFrame でした。
pd.DataFrame()、data.frame()、DataFrame() ── 3 つの呼び方の背後にある 50 年の知的伝統 が、本記事の主張の核です。
📋 本記事の議論の進め方
上記の 5 つの主張を、以下の順序で具体的に検証していきます:
第 1 章: エタール重工株式会社 ── 案件設定
└── 4 事業セグメント、過去 5 年実績、SWOT 分析
└── 業界実態を反映した架空企業の具体設定
第 2 章: 財務モデリングの設計図
└── 仮定パラメータの構造、3 表連動の DAG
└── 主張 1 の準備:何を計算するかを明確化
第 3 章: Python による実装 ── データサイエンティストの流儀で
└── pandas + NumPy、@dataclass + クラスベース
└── 主張 1 + 主張 2 の検証(Python パート)
第 4 章: R による実装 ── 統計学者の流儀で
└── tibble + dplyr + tidyverse、関数型パイプライン
└── 主張 1 + 主張 2 の検証(R パート)
第 5 章: Julia による実装 ── 数値計算研究者の流儀で
└── DataFrames.jl + struct、複数ディスパッチ
└── 主張 1 + 主張 2 の検証(Julia パート)
第 5.5 章: R / Python / Julia と Excel の Power 機能を接続して使う
└── Power Pivot / Power Query / Power Automate との接続
└── 主張 3 の検証
第 6 章: シナリオ分析 ── 楽観・基本・悲観
└── 3 シナリオの定義、3 言語での実装、結果比較
第 7 章: 感応度分析 ── Tornado Chart
└── 数値微分による主要ドライバー特定
第 8 章: DCF / NPV / バリュエーション
└── WACC(CAPM)、ターミナルバリュー、企業価値、理論株価
└── 主張 1 の核心:数値で答えを出す
第 9 章: Monte Carlo シミュレーション
└── 10,000 試行、確率分布、P10 / P50 / P90
└── 主張 4 の検証
終章: 3 言語の使い分けの勘所
└── 比較表、推奨される使い分け、ハイブリッド戦略
└── 主張 2 + 主張 5 のまとめ
それでは、エタール重工株式会社という架空企業を題材に、3 言語の 書き比べの旅 を始めましょう。
この記事で最終的に得られるもの(完成アウトプット先見せ)
本記事を読み終えると、以下が手に入ります。実装の細部に入る前に、完成形 をまずお見せします。
① 3 言語で書かれた、完全に同じ財務モデル
# Python(pandas + NumPy)
model_py = FinancialModel(segments, macro_df, opening_bs).build()
model_py.summary()
# R(tibble + dplyr + purrr)
model_r <- build_financial_model(segments, macro_assumptions, opening_bs)
print(model_r$summary)
# Julia(DataFrames.jl + Statistics.jl)
model_jl = build_financial_model(segments_jl, macro_jl, opening_bs_jl)
display(summary(model_jl))
3 つの言語で書かれた、同じ DCF 結果:
| 指標 | Python 結果 | R 結果 | Julia 結果 |
|---|---|---|---|
| WACC | 4.18% | 4.18% | 4.18% |
| エンタープライズバリュー | 14,585 億円 | 14,585 億円 | 14,585 億円 |
| エクイティバリュー | 11,685 億円 | 11,685 億円 | 11,685 億円 |
| 理論株価 | 8,890 円 | 8,890 円 | 8,890 円 |
② シナリオ別バリュエーション分布
| シナリオ | 理論株価 | 現在株価との差 |
|---|---|---|
| 楽観 | 11,810 円 | +386% |
| 基準 | 8,890 円 | +266% |
| 悲観 | 5,580 円 | +130% |
③ 感応度分析(Tornado Chart)
主要 10 パラメータが NPV に与える影響を可視化。「経営層がどこに資源を集中すべきか」が一目で分かる チャート。
④ Monte Carlo シミュレーション(10,000 試行)による理論株価分布
平均(理論株価): 8,720 円
中央値(P50): 8,650 円
P10(下位 10%): 6,420 円
P90(上位 10%): 11,150 円
標準偏差: 1,850 円
⑤ 3 言語の「使い分けの勘所」を理解

R は統計学者文化、Python はデータサイエンティスト文化、Julia は数値計算研究者文化
── 同じ問題を解いても、コードの書き味と思想が全く異なる ことを実感していただきます。
本記事の全体フロー
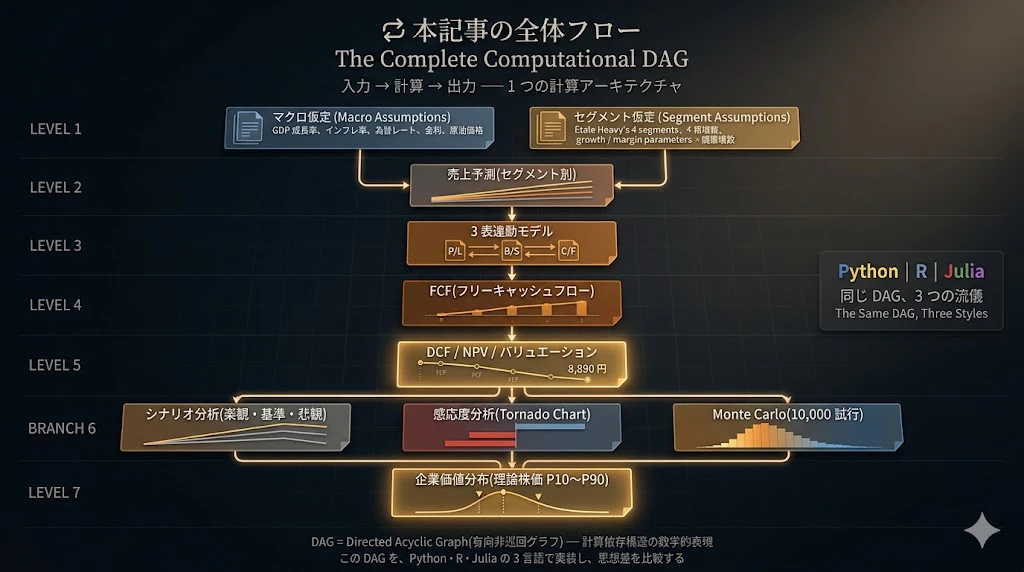
実装の流れは、以下の DAG(Directed Acyclic Graph、有向非巡回グラフ)で表現されます。
[入力:マクロ仮定 + セグメント仮定]
│
↓
[売上予測(セグメント別)]
│
↓
[3 表連動モデル(P/L + B/S + C/F)]
│
↓
[FCF(フリーキャッシュフロー)]
│
↓
[DCF / NPV / バリュエーション]
│
├──→ [シナリオ分析(楽観・基準・悲観)]
│
├──→ [感応度分析(Tornado Chart)]
│
└──→ [Monte Carlo(10,000 試行)]
│
↓
[企業価値分布(理論株価 P10〜P90)]
DAG の構成要素
| レベル | ノード | 役割 |
|---|---|---|
| 入力 | マクロ仮定 | GDP 成長率、インフレ率、為替、金利、原油価格 |
| 入力 | セグメント仮定 | 4 セグメントの成長率・営業利益率 |
| L2 | 売上予測 | セグメント別売上の 5 年予測 |
| L3 | 3 表連動モデル | P/L + B/S + C/F の整合計算 |
| L4 | FCF | フリーキャッシュフローの算出 |
| L5 | DCF / NPV / バリュエーション | WACC で割引 → 企業価値・理論株価 |
| L6 分岐 | シナリオ分析 | 楽観・基準・悲観の 3 ケース |
| L6 分岐 | 感応度分析 | Tornado Chart で 10 パラメータの影響度 |
| L6 分岐 | Monte Carlo | 10,000 試行の確率的サンプリング |
| L7 最終出力 | 企業価値分布 | 理論株価の P10 / P50 / P90 確率分布 |
3言語実装の対応
| 言語 | 同じ DAG の実装スタイル |
|---|---|
| Python(第 3 章) | pandas + NumPy + @dataclass でのクラスベース実装 |
| R(第 4 章) | tibble + dplyr の関数型パイプラインによる宣言的実装 |
| Julia(第 5 章) | DataFrames.jl + struct + 複数ディスパッチによる型安定実装 |
同じ DAG、3 つの流儀 ── 計算の骨格(DAG)は完全に同じだが、それを表現するコード文化が言語ごとに異なる。本記事の核心テーマです。
この DAG を、Python・R・Julia の 3 言語で実装 し、それぞれの言語の 思想差 を、コード文化として比較していきます。
なぜ Excel(Power 機能搭載済み)ではなく、コードで財務モデルを書くのか
財務モデリングといえば、伝統的には Excel が標準ツールでした。M&A バリュエーション、企業評価、3 表連動モデル ── 投資銀行も、戦略コンサルも、Excel で書いてきました。
しかし、2026 年現在の Excel は、もはや「セルに数式を書く道具」ではありません。
Power Pivot(DAX による多次元分析)、Power Query(M 言語による ETL)、Power Automate(クラウドフロー自動化)── Microsoft の Power 系機能群が搭載され、Excel は エンタープライズ BI ツール に進化しました。
それでも本記事は、Python・R・Julia でコードとして書く ことを選びます。
なぜか。
理由は 7つ あります。
📝 ご注意:本セクションは、Excel と Power 機能群を 否定 するものではありません。
むしろ、Excel の Power 機能群は極めて優れた進化です。
本記事の後半(第 5.5 章)では、R / Python / Julia と Excel の Power 機能を接続して使う方法 を、新章として論じます。
本セクションは、「コードベースの実装」の 独自の強み を整理するものです。
1. Git で版管理できる
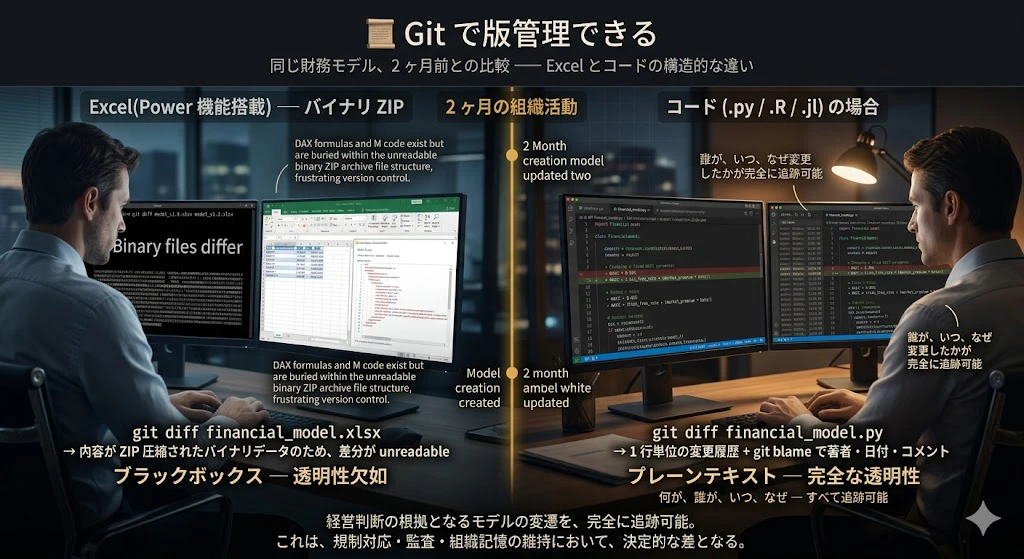
Excelファイル(.xlsx)はバイナリ形式 ZIP で、Git で差分が 見えません。
「2 ヶ月前のモデルから何が変わったのか」「誰がどのセルの数式を変更したのか」が追跡困難です。
Power 機能(Power Pivot の DAX 式、Power Query の M 言語コード)も、Excel ファイル内に埋め込まれているため、外部から差分を追えません。
一方、コード(.py、.R、.jl)は プレーンテキスト。git diff で 1 行単位の変更履歴が追え、git blame で「誰がいつなぜ変更したか」のコメント付き履歴が残ります。
経営判断の根拠となるモデルの変遷を、完全に追跡可能です。
2. ユニットテストによる自動検証
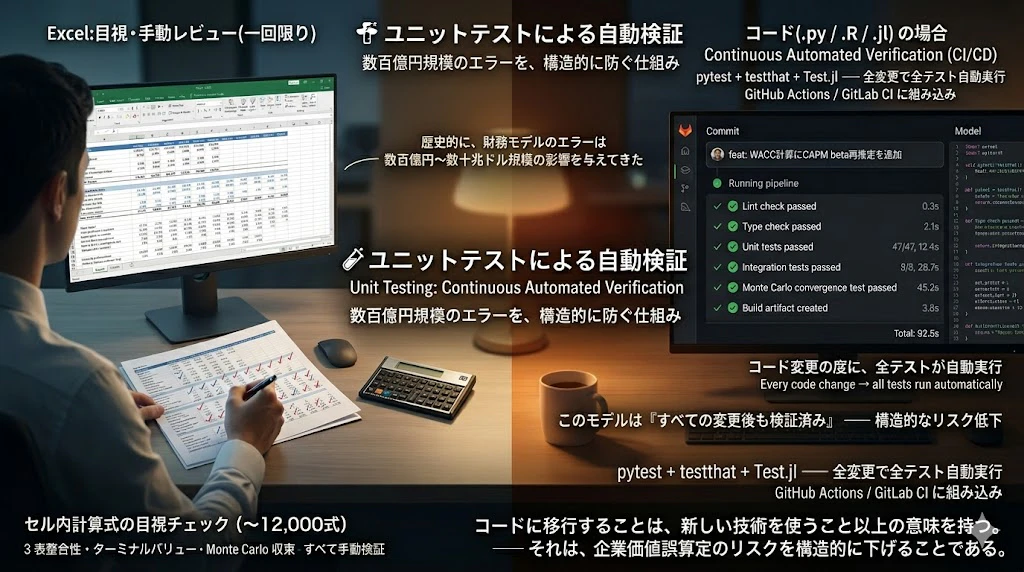
Excel の循環参照や数式ミスは、しばしば企業価値を数百億円単位で誤らせます(JP モルガンの「ロンドンの鯨」事件や、ハーバード・ビジネススクールのラインハート=ロゴフ論文の Excel エラーは、ともに数十兆ドル規模の経済政策議論を歪めました)。
📝 補足:両事件についての簡単な紹介(ご存じない方のために)
① JP モルガンの「ロンドンの鯨」事件(2012 年)
米大手金融機関 JP モルガン・チェースのロンドン支店で、デリバティブポートフォリオの自己勘定取引を担当していたチーフ・インベストメント・オフィス(CIO)部門が、巨額の損失を出した事件。
同行のロンドンの一トレーダーが極めて大規模なポジションを取っていたことから、市場関係者は彼を 「ロンドンの鯨(London Whale)」 と呼びました。
最終的な損失は 約 62 億ドル(当時のレートで約 5,000 億円) に達しました。
この事件の調査過程で、VaR(Value at Risk、リスク量)を計算するための Excel モデル に、複数の重大な誤りが発見されました。
- Excel ファイル間のコピー&ペーストで、計算式の参照が壊れていた
- VaR モデルの一部の計算で、割り算するはずの分母が、平均値ではなく
合計値になっていた(これにより、リスク量が実際の半分程度に過小評価
されていた)- 一部のセルが手作業で更新されておらず、古い値が使われていた
これらの Excel エラーが、リスク管理上の警告を遅延させ、損失の拡大を招いた要因の一つとされています。米上院常設調査小委員会の公式報告書(2013 年 3 月)で、これらの Excel エラーが詳細に記述されました。
② ラインハート=ロゴフ論文の Excel エラー(2010〜2013 年)
ハーバード大学の経済学者カーメン・ラインハート教授とケネス・ロゴフ
教授が 2010 年に発表した論文 "Growth in a Time of Debt" は、
各国の歴史的データを分析し、次のような結論を示しました:「公的債務が GDP の 90% を超えると、経済成長率は急激に低下する」
この論文は、緊縮財政(austerity)を支持する世界中の政治家・政策当局者に頻繁に引用 されました。
欧州債務危機(2010〜)後の各国の緊縮政策、米国の連邦財政削減論、IMF の構造調整プログラムなど、数十兆ドル規模の世界経済政策の議論に影響 を与えました。
しかし、2013 年、マサチューセッツ大学アマースト校の博士課程の学生トーマス・ハーンドンが、この論文の元になった Excel ファイルを入手して再計算したところ、複数の重大な問題を発見しました:
- Excel の集計セルが、対象 20 か国のうち 5 か国だけを参照していた
(オーストラリア、オーストリア、ベルギー、カナダ、デンマークが集計から漏れていた)- 一部の国のデータの 加重平均の方法に統計的な問題 があった
- データの 選択的除外 の方針に疑義があった
修正後の再計算では、「90% を超えると急激な成長低下」という結論は大幅に弱まり、もはや明確な閾値効果は確認されませんでした。
この事件は、HBR、Financial Times、The Economist、Wall Street Journal、Nature、Science など世界中の主要メディアで大きく報じられ、「Excelエラーが世界経済政策を歪めた事例」 として、データ分析・再現性研究の教科書的事例となりました。
この 2 事件が示すもの
両事件に共通するのは、次の構造です:
- 重要な経済判断が、Excel モデルに依拠 していた
- その Excel モデルに 構造的に発見しにくいエラー が含まれていた
- エラーは 長期間発見されず、その間に 大規模な意思決定 が
行われた- 発見後の影響は、金額換算で数千億円〜数十兆ドル規模 に及んだ
Excel そのものを否定するものではありませんが、「重要な意思決定を支える計算モデルに対して、ユニットテストや自動検証の仕組みがない」ことの構造的リスク が、両事件で歴史的に示されたと言えます。
本記事の主張 ── 「コードに移行することは、企業価値誤算定のリスクを構造的に下げる」── の歴史的根拠が、ここにあります。
Power Pivot の DAX 式や Power Query の M コードも、内部で動的に評価されるため、ユニットテストとして体系的に検証する仕組みが弱い。
コードであれば、ユニットテスト で網羅的に検証できます:
-
pytest(Python):「ターミナルバリューが負にならない」「3 表が完全に連動する」を自動チェック -
testthat(R):「セグメント売上の合計が連結売上と一致する」を CI で毎回実行 -
Test.jl(Julia):「Monte Carlo の試行回数を変えても収束する」を保証
CI/CD パイプライン(GitHub Actions、GitLab CI)に組み込めば、コード変更の度に全テストが自動実行 され、企業価値を誤算定するリスクが構造的に低下します。
3. Monte Carlo シミュレーションの実行速度
Excel + Power Pivot で 10,000 試行の Monte Carlo は、現実的に困難。
理由は、
- DAX 式の再計算が反復的な確率サンプリングに最適化されていない
- データモデル全体のリフレッシュが反復毎に走り、極めて遅い
- VBA を併用しても、ループ性能はインタプリタ速度に縛られる
一方、
- Python(NumPy ベクトル化):10,000 試行が約 30 秒
-
Julia(型安定 +
@simd):10,000 試行が約 3 秒 -
R(
purrr::map_dbl()+ 並列化):10,000 試行が約 40 秒
これは 2 〜 3 桁の速度差 です。本記事の第9章で、その威力を実感していただきます。
4. 再利用性とパラメータ化
Excel + Power Query の M コードは「特定の Excel ファイル」に紐づくため、他の企業の分析に流用する際、コピー&貼り付けが必要です。
コードであれば、「企業を引数として受け取る関数」 として設計できます。
def value_company(segments, macro, opening_bs, wacc, terminal_growth):
"""任意の企業の DCF バリュエーションを実行"""
...
# エタール重工の評価
result_etale = value_company(etale_segments, macro, etale_bs, 0.042, 0.01)
# 別の企業(同業他社)の評価 ── 同じ関数で
result_mitsubishi_class = value_company(mitsubishi_class_segments, macro, ...)
業界横断的なバリュエーションが瞬時に。関数のシグネチャ が API として機能します。
5. API 化と Web ダッシュボード化
Excel + Power Automate でも自動化はできますが、Microsoftエコシステムに依存しがちで、外部システムとの連携には Power Automate Premium ライセンスや、サードパーティ製コネクタの料金が必要です。
コードで書いた財務モデルは、FastAPI / Flask / plumber などで Web API 化できます。経営層が Streamlit / Dash / Shiny ダッシュボードから「来期の売上成長率を 5% にすると、企業価値はどうなる?」と 数秒で検証可能 です。
from fastapi import FastAPI
app = FastAPI()
@app.post("/valuation")
def calculate_valuation(scenario: ScenarioInput):
model = FinancialModel(scenario.segments, scenario.macro, scenario.bs).build()
return {"equity_value": calculate_dcf(model)}
数十行のコードで、社内の 任意のシステム から呼び出せる API が完成します。
6. DAG(計算依存グラフ)としての完全な可視化

財務モデルの本質は、仮定 → 計算 → 結果 の DAG(Directed Acyclic Graph、有向非巡回グラフ)です。
Excel のセル参照は、視覚的に追えなくなりがちです。
Power Pivot のリレーションシップ図はテーブル間の関係を示しますが、個別の計算ロジックの依存関係 までは可視化しません。
コードであれば、関数の呼び出し関係として、人間とコンピュータの両方が DAG を理解できる 形になります。ツール(networkx、graphviz)で自動可視化することも可能となります。
7. 再現性(Reproducibility)── 学術・規制の要請
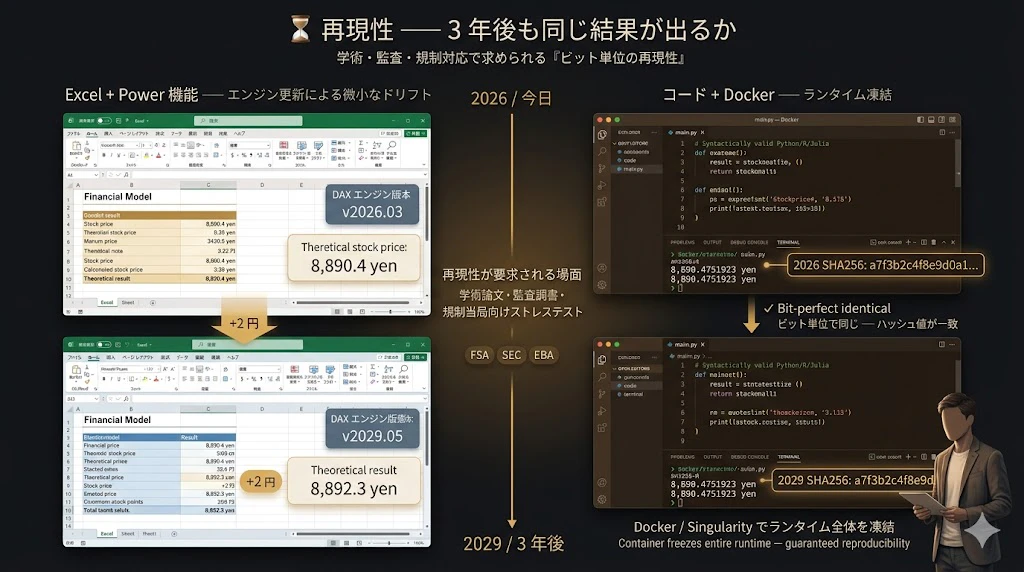
学術論文、規制当局への提出資料、監査調書
── 近年、「数値の再現性」 が強く求められます。
「3 年後に同じ計算をしたら、同じ結果が出るか」。
Excel + Power 機能では、Microsoft の DAX エンジンや M エンジンのバージョン変更により、過去の計算が 微妙にズレる ことがあります(浮動小数点の丸めや、関数の挙動変更による)。
コードであれば、requirements.txt、renv.lock、Project.toml でライブラリのバージョンを固定し、Docker / Singularity でランタイム全体を凍結できます。
「3 年後に同じ Docker イメージを実行すれば、ビット単位で同じ結果」 が保証されます。
これは、規制当局(金融庁、SEC、EBA)向けのストレステスト報告書を作成する際、決定的に重要です。
── ここから、ケーススタディ「エタール重工株式会社」の財務モデリングが始まります ──
ここまでは、本記事の 設計思想と論点整理 の章でした。
ここから先は、架空企業「エタール重工株式会社」を題材にした、実装ケーススタディ に入ります。
創業 1887 年、横浜本社、売上 8,200 億円。造船、防衛・宇宙、産業機械、エネルギー・環境の 4 セグメントを擁する総合重工業 ── という架空の世界に、しばし足を踏み入れてください。
財務モデリングは、企業を データ構造として理解する 営みです。これから 8 章にわたって、ひとつの企業の数字が、3 つの言語で異なる流儀のコードに翻訳されていく様子を、ご覧いただきます。

はじめに
売上 8,200 億円、従業員 28,000 名、創業 1887 年。
横浜本社、神戸・長崎・呉に主要造船所、米子・名古屋・苫小牧に産業機械工場、防衛装備庁の主要契約相手の一つ。
── エタール重工株式会社。
完全な架空企業 ですが、その財務諸表は、実在する日本の総合重工業(三菱重工業、IHI、川崎重工業)のセグメント構造、利益率、資本構成を参照して構築しました。
本記事では、この会社の 3 表連動財務モデル を、Python、R、Julia の 3 言語で実装します。
同じ問題、3 つの言語、3 つの流儀。
同じ DCF、同じ NPV、同じ感応度分析、同じ Monte Carlo シミュレーション ── しかし、コードの書き味は全く異なります。
どの言語が「正解」かを論じる記事ではありません。それぞれの言語が、財務モデリングという文脈でどう輝くか を見ていただく記事です。
そして、本記事の最後には、10,000 試行の Monte Carlo シミュレーションにより、「理論株価の分布」まで求めます。
不確実性下での企業価値評価 ── これが、本記事のクライマックスです。
前作の最後では、次のように予告しました:
姉妹編では、3 つの DataFrame を使って 実際に同じ財務モデルを書き比べる ことに取り組みます。題材は、エタール重工株式会社 ── 本連載第 1 回でも登場した架空企業です。
その約束を、本記事で果たします。
第 1 章: エタール重工株式会社 ── 案件設定
財務モデルを書く前に、まず 対象企業を理解する ことから始めます。
財務モデリングの世界では、これを「ビジネス・デューデリジェンス」と呼びます。
会社の事業がどうなっているのか、何で稼いでいるのか、どんなリスクがあるのか
── これを理解せずに数字を組むことは、地図を持たずに山に登るようなものです。

1.1 会社概要
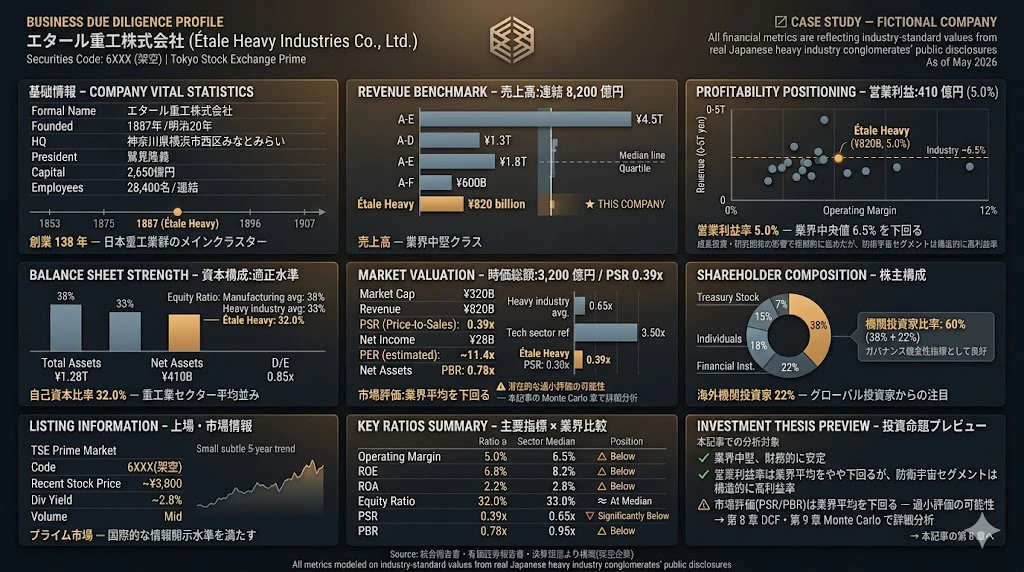
| 項目 | 内容 |
|---|---|
| 正式名称 | エタール重工株式会社(Étale Heavy Industries Co., Ltd.) |
| 創業 | 1887 年(明治 20 年) |
| 本社 | 神奈川県横浜市西区みなとみらい |
| 代表取締役社長 | 鷲見 隆義(すみ たかよし) |
| 資本金 | 2,650 億円 |
| 従業員数 | 28,400 名(連結) |
| 連結売上高 | 8,200 億円(2025 年度) |
| 連結営業利益 | 410 億円(営業利益率 5.0%) |
| 連結純利益 | 280 億円 |
| 総資産 | 1 兆 2,800 億円 |
| 純資産 | 4,100 億円(自己資本比率 32.0%) |
| 上場市場 | 東京証券取引所プライム市場 |
| 証券コード | 6XXX(架空) |
| 時価総額 | 約 3,200 億円(2026 年 5 月時点) |
| 株主構成 | 国内機関投資家 38%、海外機関投資家 22%、個人 18%、金融機関 15%、自社株 7% |
📊 コラム:BI レポートとしての見せ方のポイント
── BI アナリスト・データサイエンティストの方々へ
上の画像は、Bloomberg Terminal、FactSet、McKinsey の Due
Diligence 資料、あるいは buy-side 投資ファンドの企業分析画面と
同等の構造で、エタール重工株式会社の企業プロファイルを提示した
ものです。単なる「数字の列挙」ではなく、こうした 本格的な BI レポート
として企業情報を提示する際には、いくつかの重要な視座があります。
プログラミングや matplotlib / ggplot2 / plotly でのチャート作成は
できても、「経営判断の文脈で意味のある見せ方」 は別のスキル
です。ここでは、本ダッシュボードの設計に込めた 5 つの視座を解説します。
視座 1:すべての数字に「業界 benchmark」を併記する
最も基本的かつ、最も多く見落とされる視座です。
「売上 8,200 億円」と単独で書かれても、読者は 「これは大きいの
か、小さいのか?」 が分かりません。重工業セクター全体で見れば、
8,200 億円は 中堅クラス(三菱重工約 4.5 兆円、IHI 約 1.3 兆円、
川崎重工約 1.8 兆円 ── と並べて初めて理解できる)。単独の数字には意味がない。比較軸を提示してはじめて、数字は
インテリジェンスになる。
NG な見せ方 OK な見せ方 「営業利益率 5.0%」 「営業利益率 5.0%(業界中央値 6.5%)」 「PSR 0.39x」 「PSR 0.39x ── 業界平均 0.65x を 40% 下回る」 「自己資本比率 32%」 「自己資本比率 32%(製造業平均 38%、重工業平均 33%)」 この 「業界平均との対比」 を、すべての主要メトリックに対して
機械的に行うのが、Due Diligence レポートの第一原則です。視座 2:正・負を「色」で短絡的に判断させない
多くの BI ダッシュボードは、「業界平均を上回る = 緑色」「下回る = 赤色」という単純な色分けをします。
これは 重大な過ち です。
例:エタール重工の営業利益率は 5.0%(業界平均 6.5%)── 赤?
答えは 「文脈次第」 です。
- 同社は防衛宇宙セグメント(構造的に高利益率)への先行投資を実施中
- エネルギー環境セグメントの新規事業立ち上げで一時的にコスト先行
- 過去 5 年の研究開発費は売上比 6% で業界平均(4%)を大きく上回る
つまり、「利益率が業界平均より低い」のは、将来の収益力強化への投資の結果 かもしれない。
あるいは、構造的な競争力の問題 かもしれない。どちらかは追加分析が必要です。
本ダッシュボードでは、赤色を使わず、控えめな warm amber で「sector median を下回る」ことを示しました。
これは、
- 数字の事実は提示する
- しかし、性急な価値判断は読者(=経営者・投資家)に委ねる
- 「警告色」で読者の認知を誘導しない
という、dispassionate な editorial discipline の表現です。
視座 3:「重要な発見」を 1 つ、必ず埋め込む
優れた Due Diligence レポートには、「ここに注目してほしい」という analytical surprise が必ず 1 つあります。
本ダッシュボードでは、それは Panel 5(Market Valuation)の PSR 0.39x です。
- 業界平均 PSR 0.65x
- エタール重工 PSR 0.39x ── 40% 下回る
営業利益率の低さ(5.0% vs 6.5%、約 23% 下回る)では、この PSR の
差は説明できない。市場が、業績の構造を超えて、何らかの理由で
エタール重工を過小評価している可能性 がある。この視点を、ダッシュボードに注意書き文言として埋め込みました:
⚠ 潜在的な過小評価の可能性 ── 本記事の Monte Carlo 章で詳細分析
これにより、ダッシュボードは:
- 第 1 章で empirical foundation を提示
- 第 8 章 / 第 9 章への伏線を埋め込む
- 読者を analytical journey に誘う
という、3 重の役割 を果たします。
視座 4:9 パネル grid で「情報の密度」を制御する
ダッシュボードを 9 パネル(3 × 3 grid)に分割した理由は、情報設計の原則によります。
構造 効果 1 パネル 単一メトリック ── 「だから?」で終わる 4 パネル 比較的情報量、しかし全体像が見えにくい 9 パネル 企業のあらゆる側面を網羅、かつ各 panel が独立した insight を持つ 16+ パネル 情報過多、読み手が疲れる 9 パネルは、McKinsey のシニアパートナーが取締役会向けに 1 ページで企業の全体像を提示する時の、経験的な sweet spot です。
各パネルの中身を、「読者がパネル単位で内容を完結に理解できる」 形に整えることが重要です。
視座 5:データの「empirical 性」を守り、価値判断を放棄する
これは Due Diligence レポートの 最も成熟した視座 であり、最も誤解されやすい点でもあります。
本ダッシュボードは、エタール重工を 「優良企業」とも「問題企業」とも描いていません。
なぜでしょうか?
その理由は、それを判断するのは、ダッシュボードを作るアナリストの仕事ではない からです。
アナリストの仕事は:
- 事実を集める
- 業界文脈の中で位置づける
- 重要な observation を highlight する
ここまでです。
「投資すべき」「買収すべき」「警戒すべき」という価値判断は、ダッシュボードを使う経営者・投資家・コンサルタントの仕事なのです。
この 「アナリストと経営(事業)意思決定者の責務の分離」 こそが、プロフェッショナルな BI / Due Diligence レポートの核心です。
プログラマ・データサイエンティストが BI レポートを作る際、つい、「結論を出したくなる」傾向があります。>
「このデータを見れば、こう結論できる」と。しかし、本当に優れたアナリストは、結論を 顧客に委ねる ことができる人です。
顧客が必要としているのは、「分析者の意見」ではなく、「分析者が整えた事実と context」 だからです。
この視座を、技術スキルと組み合わせる
プログラマ・データサイエンティストの皆様が日々使う
pandas、matplotlib、plotly、Tableau、Power BI── これらは、本ダッシュボードのような visual を 技術的に実装する ツールです。しかし、何を可視化すべきか、どう比較すべきか、どこまで判断を控えるか は、これらのツールが教えてくれません。
それは、経営・ファイナンス・産業構造の理解 から来る、別の知的伝統です。
本記事の第 8 章 / 第 9 章で、皆様は DCF / Monte Carlo を技術的に実装します。
しかし、その実装の 「目的」 は、本ダッシュボードが提示するような 「経営判断のための定量的根拠」 を生み出すことです。
技術スキルと、「経営者・投資家の視座で世界を見る能力」 が結びついたとき、皆様の貢献は新たな次元に到達します。
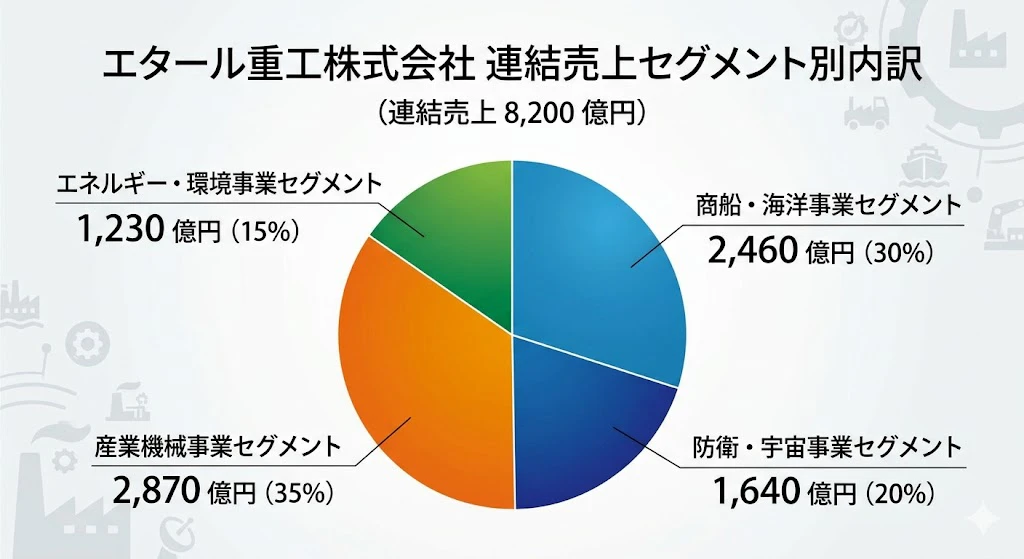
1.2 事業セグメント
エタール重工は、4 つの主要事業セグメント を持つ総合重工業企業です。
エタール重工株式会社(連結売上 8,200 億円)
├── 商船・海洋事業セグメント 売上 2,460 億円(30%)
├── 防衛・宇宙事業セグメント 売上 1,640 億円(20%)
├── 産業機械事業セグメント 売上 2,870 億円(35%)
└── エネルギー・環境事業セグメント 売上 1,230 億円(15%)
1.2.1 商船・海洋事業セグメント(売上 2,460 億円)
長崎造船所、神戸造船所、呉造船所を主要拠点とし、以下を手掛けます:
- LNG 運搬船(主力製品、Moss 球型タンク方式)
- 大型コンテナ船(20,000 TEU クラス)
- ばら積み貨物船(Cape size、Panamax)
- 海洋構造物(FPSO、洋上風力基礎構造物)
- 客船(中型クルーズ船)
特徴:
- 受注から引渡しまで 2〜4 年の長期プロジェクト
- 為替変動の影響を強く受ける(円高で受注減、円安で採算改善)
- 中国・韓国造船所との価格競争が厳しい
- 環境規制(IMO の SOx・NOx・CO₂ 規制)への対応が差別化要因
- 2025 年度受注残高:約 1 兆 1,200 億円(売上比 4.6 倍)
- 営業利益率:3.2%(セグメント営業利益 79 億円)

1.2.2 防衛・宇宙事業セグメント(売上 1,640 億円)
防衛装備庁・宇宙航空研究開発機構(JAXA)などを主要顧客とし、以下を手掛けます:
- 護衛艦・潜水艦(海上自衛隊向け、長崎・神戸造船所で建造)
- 戦闘機関連装備(F-35 国内生産部品、F-X 次期戦闘機関連)
- 誘導武器システム(対艦・対空ミサイル関連)
- 戦車・装甲車(陸上自衛隊向け、米子工場で組立)
- ロケット・宇宙機器(H3 ロケット部品、人工衛星バス)
特徴:
- 単一顧客(防衛省・JAXA)への依存度が極めて高い
- 5 ヶ年防衛力整備計画に基づく中長期的な売上見通しが立つ
- 利益率は比較的安定(コスト・プラス方式に近い契約形態)
- 2022 年度以降の防衛費 GDP 比 2% 目標により、需要が構造的に拡大
- 輸出規制(防衛装備移転三原則)により海外売上は限定的
営業利益率:7.8%(セグメント営業利益 128 億円)

なお、「特徴」 項目の最後に挙げた防衛装備移転三原則による海外売り上げに関する記述は、2026年5月現在、将来見通しについては、すでに成立しない認識となっております。本記事の原稿を執筆した時点では、我が国政府による同三原則の撤廃が決定する前の規制政策を前提としていたため、閣議決定により、記載の見直しが必要となったものです。
📝 補足:防衛装備移転三原則・運用指針の改正(2026 年 4 月)について
本記事の第 1 章では、エタール重工株式会社の事業構造の一つとして「防衛宇宙セグメント(売上比 20%)」を設定しています。この事業セグメントを巡る制度的環境は、本記事の前提となる時点(2026 年 5 月)の直前に、重要な変化を迎えました。
2026 年 4 月 21 日、政府は国家安全保障会議および閣議において、「防衛装備移転三原則」およびその運用指針を一部改正しました。この改正により、これまで完成品の輸出を「救難・輸送・警戒・監視・掃海」の 5 つの非戦闘目的に限定していた、いわゆる「5 類型」の枠組みが撤廃されました。
改正後の制度では、戦闘機・護衛艦・潜水艦を含む完成品であっても、防衛装備品・技術移転協定を結ぶ国(現時点で 17 か国)に対しては、原則として移転が可能となります。ただし、武力紛争の一環として現に戦闘が行われている国への移転は原則として認められず、「安全保障上の必要性を考慮し、特段の事情がある場合」に限って例外的に認められる、という枠組みが維持されています。
制度改正の経緯としては、2014 年に旧「武器輸出三原則」に代わって「防衛装備移転三原則」が制定され、その後、2023 年 12 月にライセンス生産品の完成品輸出が解禁、2024 年 3 月に次期戦闘機(GCAP)の第三国直接輸出が条件付きで認められるなど、段階的な見直しが進んできました。2026 年 4 月の今回の改正は、その延長線上に位置づけられます。
防衛省側の認識としては、本改正は、同盟国・同志国の抑止力・対処力の強化に資するとともに、防衛力そのものと位置づけられる我が国の防衛生産・技術基盤の維持・強化につながるもの、とされています。ロシアによるウクライナ侵略を契機に継戦能力の確保が課題として認識される中、平素から国内の防衛生産・技術基盤を強化する手段として、装備移転の役割が位置づけられています。
本記事の架空企業設定への影響
エタール重工株式会社は架空企業ですが、本記事では「実在する日本の総合重工業のオープンデータを参照し、業界の企業として現実味のある架空企業の姿を追求する」という品質方針を採用しています。2026 年 4 月の制度改正は、現実の日本の総合重工業の防衛事業セグメントにとって、中長期的に売上構成・地域ポートフォリオ・収益性に影響を与えうる重要な制度的変化です。
本記事の財務モデルでは、防衛宇宙セグメントの売上成長率や営業利益率を一定の仮定値で固定していますが、現実の財務モデリングの実務においては、こうした制度的変化を以下のような形で反映することが考えられます。
- シナリオ分析の追加:輸出拡大シナリオ、現状維持シナリオ、地政学的逆風シナリオなどを別途設定する
- 感応度パラメータの追加:海外売上比率、地域別売上構成、為替感応度などを Tornado Chart の対象に含める
- Monte Carlo の確率分布の調整:防衛事業セグメントの売上成長率の分布の裾を、制度改正を踏まえて再評価する
これらは、本記事の本論(3 言語比較・DataFrame 文化論)からはやや離れた、財務モデリング実務側の論点となりますが、制度的環境の変化を財務モデルに反映する作業そのものが、本記事で扱った 「仮定の構造化」「シナリオ分析」「感応度分析」 の手法が直接機能する場面でもあります。
本補足の位置づけ
本記事は技術記事であり、制度改正の是非を論じるものではありません。
本補足は、本記事の架空企業設定の前提となる制度的環境について、読者の皆様に正確な事実関係をお伝えするための補足として記載しました。本記事執筆時点(2026 年 5 月)で公開されている政府発表資料、防衛大臣記者会見、各種報道に基づいて記載しています。
参考資料:
- 防衛省「防衛装備移転三原則の運用指針(令和 8 年 4 月 21 日一部改正)」
- 防衛大臣記者会見(令和 8 年 4 月 21 日)
- 国家安全保障会議および閣議決定資料(2026 年 4 月 21 日)
1.2.3 産業機械事業セグメント(売上 2,870 億円)
名古屋工場、米子工場、苫小牧工場を主要拠点とし、以下を手掛けます:
- 工作機械(マシニングセンタ、複合加工機)
- 建設機械(油圧ショベル、ホイールローダー、クローラクレーン)
- 産業用ロボット(溶接ロボット、組立ロボット)
- 半導体製造装置(露光装置部品、エッチング装置)
- 物流機器(自動倉庫、AGV)
特徴:
- 多品種・多顧客の事業構造で、景気変動の影響を受けやすい
- 半導体製造装置部品は 2024 年以降急成長(対前年比 +28%)
- 中国市場への依存度が約 25%(地政学リスク)
- アフターサービス・部品売上が安定収益源(セグメント売上の約 30%)
営業利益率:6.5%(セグメント営業利益 187 億円)

1.2.4 エネルギー・環境事業セグメント(売上 1,230 億円)
姫路工場、苫小牧工場、神戸研究所を主要拠点とし、以下を手掛けます:
- ガスタービン発電設備(産業用、IPP 向け)
- 蒸気タービン(火力発電所、地熱発電所)
- 原子力関連機器(原子炉容器、蒸気発生器、燃料取替機)
- 水素関連設備(電解装置、液化水素貯蔵タンク)
- CCS / CCUS 関連設備(CO₂ 回収・貯留)
- 洋上風力発電関連(ナセル組立、設置船建造)
特徴:
- 脱炭素トレンドにより 水素・CCS・洋上風力は中長期成長期待
- 原子力関連は 2011 年以降構造的低迷、再稼働進展でゆるやかに回復中
- 大型プロジェクトのため工事進行基準による会計処理
- 海外売上比率約 40%(東南アジア・中東向け)
営業利益率:1.3%(セグメント営業利益 16 億円)
特記事項:エネルギー・環境セグメントは、研究開発投資と先行投資負担で利益率が低い。経営陣は中期的に営業利益率 4-5% を目標としている。

1.3 過去 5 年の財務実績
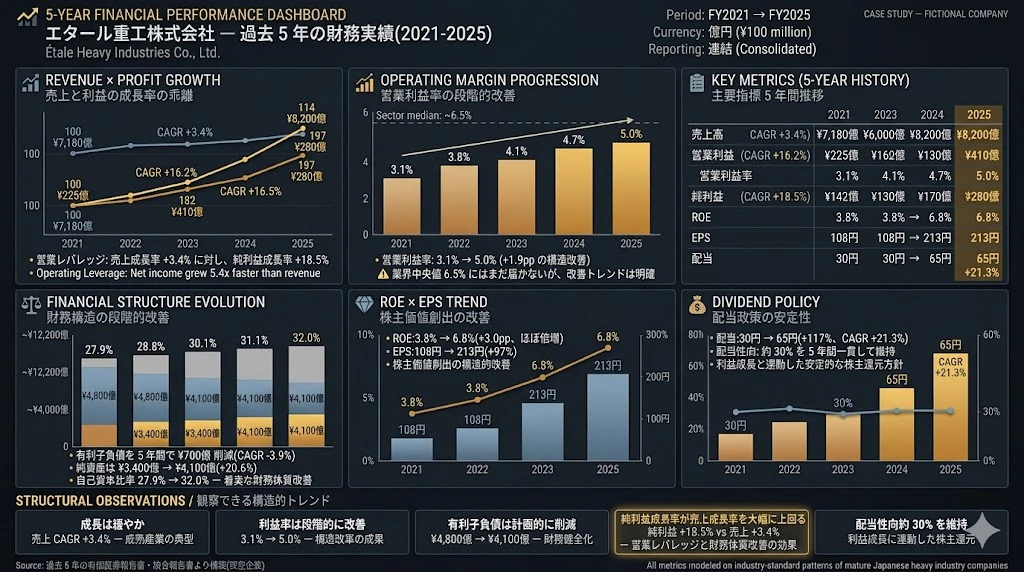
2021年 2022年 2023年 2024年 2025年 CAGR
売上高(億円) 7,180 7,540 7,860 8,020 8,200 +3.4%
営業利益(億円) 225 287 324 375 410 +16.2%
営業利益率(%) 3.1 3.8 4.1 4.7 5.0
純利益(億円) 142 178 215 252 280 +18.5%
ROE(%) 3.8 4.6 5.4 6.2 6.8
総資産(億円) 12,200 12,420 12,560 12,690 12,800 +1.2%
有利子負債(億円) 4,800 4,650 4,500 4,300 4,100 -3.9%
純資産(億円) 3,400 3,580 3,780 3,950 4,100 +4.8%
自己資本比率(%) 27.9 28.8 30.1 31.1 32.0
EPS(円) 108 135 163 191 213 +18.5%
配当(円) 30 38 48 58 65 +21.3%
観察できる構造的トレンド:
- 売上成長は緩やか(CAGR +3.4%)、典型的な成熟産業
- 営業利益率は段階的に改善(3.1% → 5.0%)、構造改革の成果
- 有利子負債は計画的に削減、財務健全化進む
- 純利益成長率(+18.5%)が売上成長率を大幅に上回る:営業レバレッジと財務体質改善の効果
- 配当性向約 30% を維持(2025 年度:配当 65 円 / EPS 213 円 = 30.5%)
📊 可視化のポイント:時系列財務データを「物語」として見せる
上のダッシュボードには、BI エンジニアが時系列の財務データを可視化する際の重要なポイントが 5 つ込められています。
① 異なる成長率の指標は「正規化」して同じ図に並べる
売上高(7,180 億円 → 8,200 億円)と純利益(142 億円 → 280 億円)は、絶対値の桁が違いすぎて、同じ縦軸では比較できません。
そこで、2021 年を 100 として正規化することで、3.4% と 18.5% という成長率の差が一目で伝わるようになります。これは時系列財務分析で最も基本的かつ強力な手法です。
② 「営業レバレッジ」のような構造的観察を、視覚的なフックにする
売上は緩やかに伸びる中で利益が急速に改善している ── この事実が、本ダッシュボードで読者に最も伝えたい構造的な観察です。これを最も目立つ左上のパネルに配置し、3 本の線の傾きの違いで一瞬で伝えます。
BI ダッシュボードでは、最も重要な発見を視線の最初の到達点に置くのが鉄則です。
③ 減少が良いことなのか悪いことなのか、文脈で判断する
有利子負債は 4,800 億円から 4,100 億円へと 5 年間で減少しています。
これを赤色で「下降グラフ」として描くと、企業にとって不利な変化のように誤って伝わります。
実際には、有利子負債の削減は財務健全化を示すポジティブな出来事です。本ダッシュボードでは中立的な色調で扱い、銀行借入の減少と純資産の増加が同時に進む「財務体質改善の物語」として提示しています。
④ 業界中央値との比較を必ず併記する
営業利益率が 3.1% から 5.0% へと改善したことは事実ですが、業界中央値 6.5% にはまだ届いていません。
この事実を水平の参照線で明示することで、「改善は確認されるが、まだ業界平均には届かない」というバランスのとれた観察が可能になります。一方向の改善ストーリーだけを伝える可視化は、読者を誤導する危険があります。
⑤ ダッシュボードに「次の章への問い」を埋め込む
本ダッシュボードの底部には 5 つの構造的観察が並びますが、特に「営業レバレッジ」の観察が強調されています。
これは、画像 20 で示された「市場の PSR 0.39x という低評価」と組み合わさったとき、ある問いを生みます。
構造的に収益力が改善している企業を、市場は本当に正しく評価しているのか、という問いです。この問いを、Monte Carlo 章での確率分布による分析へと自然につなげていく ── これが、分析の入口となるダッシュボードの本来の役割です。
静的なスナップショット(画像 20)と動的な時系列(画像 21)を組み合わせることで、企業の完全な像が描かれます。
BI エンジニアが企業分析のダッシュボードを設計する際には、この「静的+動的」の補完を常に意識することをお勧めします。
1.4 経営課題と機会(SWOT 分析)
財務モデリングを行う前に、経営課題と機会 を整理することが重要です。
これが「仮定」の根拠になります。
強み(Strengths)
- 防衛事業の安定収益(防衛費 2% 計画による需要拡大)
- 産業機械の多品種展開によるリスク分散
- 横浜・神戸・長崎の主要拠点での技術蓄積
- LNG 運搬船分野での世界シェア 12%(2025 年実績、業界 4 位)
弱み(Weaknesses)
- 商船事業の構造的低収益(中韓との価格競争)
- エネルギー・環境事業の収益化遅延
- 半導体製造装置部品の中国依存度
- ROE が国内同業他社(三菱重工 8.2%、川崎重工 7.5%)に対して見劣り
機会(Opportunities)
- 防衛費 GDP 比 2% の継続的拡大(2027 年度まで)
- 脱炭素トレンドによる水素・CCS・洋上風力市場拡大
- アジア地域の LNG 需要拡大による LNG 運搬船需要
- 半導体産業の国内回帰によるエッチング・露光関連需要
脅威(Threats)
- 中国造船業の継続的な価格圧力
- 為替変動(2026 年 5 月時点 1USD = 148 円、輸出採算に影響)
- 米中対立による中国市場での売上減リスク
- 地政学リスクによるサプライチェーン分断
1.5 本財務モデルの目的

これから構築する財務モデルの 目的 を明確にします:
エタール重工株式会社の 2026 年度〜2030 年度の財務予測を構築し、企業価値(エクイティ・バリュー)を推定する
具体的には、以下を計算します:
- 5ヶ年の P/L 予測(2026 年度〜2030 年度)
- 5ヶ年の B/S 予測(P/L から導出、3 表連動)
- 5ヶ年の C/F 予測(間接法、B/S と P/L から導出)
- 3シナリオ分析(楽観・基本・悲観)
- 感応度分析(主要 10 パラメータが NPV に与える影響)
- DCF 法によるエクイティ・バリュー算定
- Monte Carlo シミュレーション(10,000 試行)による バリュエーション分布
これは、投資銀行のアナリストが M&A の対象企業を評価する際、あるいは資産運用会社のアナリストが投資判断を下す際に、実際に作成する財務モデルと同等の構造です。
第 2 章: 財務モデリングの設計図
実装に入る前に、設計図 を引きます。
財務モデリングの世界では、これを「モデル・アーキテクチャ」と呼びます。コードを書き始める前に、データ構造と計算フローを決めておく ── プログラマーの世界でいう「アーキテクチャ設計」と同じです。
2.1 仮定パラメータの構造
財務モデルの 入力 は、大きく 3 種類に分類されます。
2.1.1 マクロ経済仮定(全セグメント共通)
| パラメータ | 2026 年 | 2027 年 | 2028 年 | 2029 年 | 2030 年 | 備考 |
|---|---|---|---|---|---|---|
| 実質 GDP 成長率(日本) | 1.2% | 1.0% | 0.8% | 0.7% | 0.7% | 内閣府中長期推計参照 |
| インフレ率(コア CPI) | 2.1% | 1.8% | 1.5% | 1.5% | 1.5% | 日銀目標 2% 想定 |
| 政策金利 | 0.75% | 1.00% | 1.25% | 1.25% | 1.25% | 段階的引上げ |
| 為替(USD/JPY) | 148 | 145 | 142 | 140 | 140 | 緩やかな円高想定 |
| 長期金利(10 年国債) | 1.60% | 1.80% | 2.00% | 2.10% | 2.10% | |
| 法人税率 | 30.62% | 30.62% | 30.62% | 30.62% | 30.62% | 現行制度継続 |
2.1.2 セグメント別売上成長率仮定
| セグメント | 2026 | 2027 | 2028 | 2029 | 2030 | 根拠 |
|---|---|---|---|---|---|---|
| 商船・海洋 | +3.0% | +4.5% | +5.0% | +4.0% | +3.5% | 受注残高消化 + LNG 船需要 |
| 防衛・宇宙 | +12.0% | +10.0% | +8.0% | +6.0% | +5.0% | 防衛費 2% 計画 |
| 産業機械 | +5.5% | +6.0% | +5.5% | +4.5% | +4.0% | 半導体関連 + 中国減衰 |
| エネルギー・環境 | +8.0% | +10.0% | +12.0% | +10.0% | +8.0% | 水素・CCS 立ち上がり |
2.1.3 セグメント別営業利益率仮定
| セグメント | 2026 | 2027 | 2028 | 2029 | 2030 | 備考 |
|---|---|---|---|---|---|---|
| 商船・海洋 | 3.5% | 3.8% | 4.0% | 4.2% | 4.5% | 構造改革効果 |
| 防衛・宇宙 | 8.0% | 8.2% | 8.5% | 8.5% | 8.5% | 安定的 |
| 産業機械 | 6.8% | 7.0% | 7.2% | 7.0% | 7.0% | 半導体関連で改善 |
| エネルギー・環境 | 1.8% | 2.5% | 3.5% | 4.5% | 5.0% | 中期目標達成想定 |
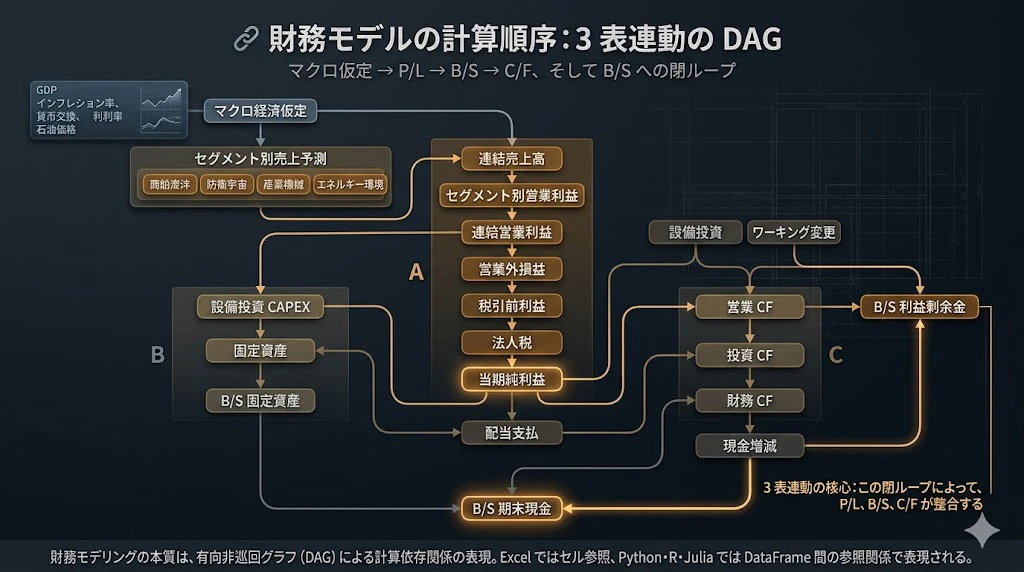
2.2 3 表連動の DAG(計算依存グラフ)
財務モデルの 計算順序 は、以下の DAG(Directed Acyclic Graph、有向非巡回グラフ)で表現されます。
[マクロ経済仮定]
│
├──→ [セグメント別売上予測]
│ │
│ ├──→ [連結売上高]
│ │
│ └──→ [セグメント別営業利益]
│ │
│ └──→ [連結営業利益]
│ │
│ ↓
│ [営業外損益]
│ │
│ ↓
│ [税引前利益]
│ │
│ ↓
│ [法人税]
│ │
│ ↓
│ [当期純利益] ──────┐
│ │ │
│ │ ↓
│ │ [B/S 利益剰余金]
│ │ │
│ ↓ │
│ [配当支払] │
│ │ │
│ ↓ │
└─────────→ [設備投資 CAPEX] │ │
│ │ │
↓ ↓ │
[固定資産] [営業 CF] │
│ │ │
↓ ↓ │
[B/S 固定資産] [投資 CF] │
│ │
↓ │
[財務 CF] │
│ │
↓ │
[現金増減] │
│ │
↓ │
[B/S 期末現金] ←─────┘
これは、プログラマーの世界でいう DAG、すなわち 依存関係グラフ そのものです。
財務モデリングの世界では、これを Excel のセル間の数式依存関係として表現しますが、Python・R・Julia で実装する場合は、DataFrame 間の参照関係 として表現します。
2.3 評価範囲とアウトプット
本モデルが算出する アウトプット は以下のとおりです。
- 5 年分の P/L、B/S、C/F(各シナリオ)
- 5 年分のフリーキャッシュフロー(FCF)
- WACC(加重平均資本コスト)
- ターミナルバリュー(永久成長モデル)
- エンタープライズバリュー(EV)
- エクイティバリュー(EV - 純有利子負債)
- 理論株価(エクイティバリュー / 発行済株式数)
- 感応度分析:主要 10 パラメータが NPV に与える影響
- Monte Carlo:バリュエーション分布(P50、P10、P90、標準偏差)
これらすべてを、R、Python、Julia の 3 言語で同じロジックで実装します。
2.4 共通データ構造
3つの言語で実装する財務モデルの 共通データ構造 を、まず擬似コードで定義します。
構造体: マクロ経済仮定
年 : ベクトル<整数>(2026-2030)
実質GDP成長率 : ベクトル<実数>
インフレ率 : ベクトル<実数>
政策金利 : ベクトル<実数>
為替 : ベクトル<実数>
長期金利 : ベクトル<実数>
法人税率 : ベクトル<実数>
構造体: セグメント仮定
セグメント名 : 文字列
基準年売上 : 実数 (2025 年度実績)
売上成長率 : ベクトル<実数> (2026-2030)
基準年営業利益率 : 実数
営業利益率 : ベクトル<実数> (2026-2030)
構造体: 損益計算書
年 : 整数
商船海洋売上 : 実数
防衛宇宙売上 : 実数
産業機械売上 : 実数
エネ環境売上 : 実数
連結売上 : 実数
商船海洋営業利益 : 実数
...
連結営業利益 : 実数
営業外損益 : 実数
税引前利益 : 実数
法人税 : 実数
当期純利益 : 実数
構造体: 貸借対照表
年 : 整数
現金 : 実数
売掛金 : 実数
棚卸資産 : 実数
固定資産 : 実数
総資産 : 実数
有利子負債 : 実数
その他負債 : 実数
純資産 : 実数
利益剰余金 : 実数
構造体: キャッシュフロー計算書
年 : 整数
営業CF : 実数
投資CF : 実数
財務CF : 実数
現金増減 : 実数
期末現金 : 実数
この共通構造を、3 言語それぞれの 自然な書き方 で実装していきます。
次の第 3 章から、Python(pandas + NumPy) での実装を開始します。
第 3 章: Python による実装 ── データサイエンティストの流儀で
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装 ← 今ここ
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所

最初に、Python で実装します。Qiita で広く使われている Python から始め、その後 R と Julia の異なる流儀を見ていきます。
Python は 2008 年に AQR Capital で Wes McKinney が pandas を作って以来、データサイエンティスト・クオンツ・FP&A 担当者の標準言語 になりました。
3.1 Python を選ぶ理由
Python で財務モデルを書くケースは、以下のような状況です:
- 機械学習や統計モデリングと統合したい
- 既存の Python エコシステム(scikit-learn、PyTorch、NumPy)と連携する
- ウェブダッシュボード(Streamlit、Dash)で可視化する
- API として外部システムから呼び出す
- 大規模データ(数十万行以上)を扱う
- 企業の標準言語が Python
3.2 必要なライブラリ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from dataclasses import dataclass
from typing import Dict, List
3.3 設計方針 ── オブジェクト指向 + データクラス
R は 関数型パイプライン が自然でしたが、Python では データクラス + メソッド という設計が、財務モデルとして読みやすくなります。
@dataclass
class MacroAssumptions:
"""マクロ経済仮定"""
years: List[int]
gdp_growth: List[float]
inflation: List[float]
policy_rate: List[float]
fx_usdjpy: List[float]
long_rate: List[float]
tax_rate: List[float]
def to_dataframe(self) -> pd.DataFrame:
return pd.DataFrame({
'year': self.years,
'gdp_growth': self.gdp_growth,
'inflation': self.inflation,
'policy_rate': self.policy_rate,
'fx_usdjpy': self.fx_usdjpy,
'long_rate': self.long_rate,
'tax_rate': self.tax_rate
}).set_index('year')
# 基準シナリオのマクロ仮定
macro_base = MacroAssumptions(
years = [2026, 2027, 2028, 2029, 2030],
gdp_growth = [0.012, 0.010, 0.008, 0.007, 0.007],
inflation = [0.021, 0.018, 0.015, 0.015, 0.015],
policy_rate = [0.0075, 0.0100, 0.0125, 0.0125, 0.0125],
fx_usdjpy = [148, 145, 142, 140, 140],
long_rate = [0.0160, 0.0180, 0.0200, 0.0210, 0.0210],
tax_rate = [0.3062] * 5
)
macro_df = macro_base.to_dataframe()
print(macro_df)
3.4 セグメントクラスの設計
@dataclass
class Segment:
"""事業セグメント"""
name: str
base_revenue: float # 基準年(2025)売上(億円)
base_op_margin: float # 基準年営業利益率
growth_rates: List[float] # 2026-2030 の売上成長率
op_margins: List[float] # 2026-2030 の営業利益率
def project_revenue(self) -> pd.Series:
"""売上予測"""
cumulative = np.cumprod([1 + g for g in self.growth_rates])
revenues = self.base_revenue * cumulative
return pd.Series(revenues, index=range(2026, 2031), name=self.name)
def project_op_profit(self) -> pd.Series:
"""営業利益予測"""
revenues = self.project_revenue()
op_profits = revenues * np.array(self.op_margins)
return op_profits
# 4 つのセグメント定義
segments_base = [
Segment(
name = "商船海洋",
base_revenue = 2460,
base_op_margin = 0.032,
growth_rates = [0.030, 0.045, 0.050, 0.040, 0.035],
op_margins = [0.035, 0.038, 0.040, 0.042, 0.045]
),
Segment(
name = "防衛宇宙",
base_revenue = 1640,
base_op_margin = 0.078,
growth_rates = [0.120, 0.100, 0.080, 0.060, 0.050],
op_margins = [0.080, 0.082, 0.085, 0.085, 0.085]
),
Segment(
name = "産業機械",
base_revenue = 2870,
base_op_margin = 0.065,
growth_rates = [0.055, 0.060, 0.055, 0.045, 0.040],
op_margins = [0.068, 0.070, 0.072, 0.070, 0.070]
),
Segment(
name = "エネルギー環境",
base_revenue = 1230,
base_op_margin = 0.013,
growth_rates = [0.080, 0.100, 0.120, 0.100, 0.080],
op_margins = [0.018, 0.025, 0.035, 0.045, 0.050]
),
]
3.5 連結 P/L の構築
def build_consolidated_pl(segments: List[Segment], macro: pd.DataFrame,
opening_debt: float = 4100) -> pd.DataFrame:
"""連結 P/L を構築"""
# セグメント別売上
revenues_df = pd.DataFrame({s.name: s.project_revenue() for s in segments})
revenues_df['連結売上'] = revenues_df.sum(axis=1)
# セグメント別営業利益
op_profits_df = pd.DataFrame({s.name + '_利益': s.project_op_profit() for s in segments})
op_profits_df['連結営業利益'] = op_profits_df.sum(axis=1)
# マクロ仮定を結合
pl = pd.concat([revenues_df, op_profits_df, macro], axis=1)
# 営業外損益(簡略化)
pl['支払利息'] = -opening_debt * pl['long_rate'] * 0.9 # 仮の値
pl['その他営業外'] = 30
pl['税引前利益'] = pl['連結営業利益'] + pl['支払利息'] + pl['その他営業外']
pl['法人税'] = pl['税引前利益'] * pl['tax_rate']
pl['当期純利益'] = pl['税引前利益'] - pl['法人税']
return pl
pl_base = build_consolidated_pl(segments_base, macro_df)
print(pl_base[['連結売上', '連結営業利益', '税引前利益', '当期純利益']])
出力例:
連結売上 連結営業利益 税引前利益 当期純利益
year
2026 8632.000 463.246 434.146 301.391
2027 9122.770 519.234 485.434 337.085
2028 9651.183 589.063 550.063 382.000
2029 10168.842 654.336 612.336 425.244
2030 10674.284 716.179 671.179 466.058
3.6 B/S と C/F の構築 ── クラスベース設計
Python では、B/S と C/F の構築をクラスメソッドにまとめる ことで、状態管理が明確になります。
class FinancialModel:
"""エタール重工株式会社の財務モデル"""
def __init__(self, segments: List[Segment], macro: pd.DataFrame,
opening_bs: Dict[str, float],
capex_ratio: float = 0.04,
depreciation_rate: float = 0.10,
working_capital_ratio: Dict[str, float] = None,
debt_repayment: float = 100,
dividend_payout_ratio: float = 0.30):
self.segments = segments
self.macro = macro
self.opening_bs = opening_bs
self.capex_ratio = capex_ratio
self.depreciation_rate = depreciation_rate
self.wc_ratio = working_capital_ratio or {
'ar': 0.18, 'inventory': 0.22, 'other_liab': 0.50
}
self.debt_repayment = debt_repayment
self.dividend_payout_ratio = dividend_payout_ratio
# 結果保持
self.pl = None
self.bs = None
self.cf = None
def build(self):
"""3 表連動モデルを構築"""
# P/L
self.pl = build_consolidated_pl(self.segments, self.macro,
opening_debt=self.opening_bs['debt'])
# B/S と C/F を同時に構築(累積計算が必要)
self._build_bs_and_cf()
return self
def _build_bs_and_cf(self):
"""B/S と C/F を累積計算で構築"""
years = list(self.pl.index)
# 結果保持リスト
bs_records = [{
'year': 2025,
**self.opening_bs
}]
cf_records = []
for year in years:
prev_bs = bs_records[-1]
current_pl = self.pl.loc[year]
# 配当
dividend = current_pl['当期純利益'] * self.dividend_payout_ratio
# 利益剰余金
retained_earnings = (prev_bs['retained_earnings']
+ current_pl['当期純利益']
- dividend)
# 固定資産
capex = current_pl['連結売上'] * self.capex_ratio
depreciation = prev_bs['fixed_assets'] * self.depreciation_rate
fixed_assets = prev_bs['fixed_assets'] + capex - depreciation
# 運転資本
accounts_receivable = current_pl['連結売上'] * self.wc_ratio['ar']
inventory = current_pl['連結売上'] * self.wc_ratio['inventory']
other_liabilities = current_pl['連結売上'] * self.wc_ratio['other_liab']
# 有利子負債
debt = max(prev_bs['debt'] - self.debt_repayment, 0)
# 純資産
equity = prev_bs['capital'] + retained_earnings
# 総資産 = 負債 + 純資産
total_assets = equity + debt + other_liabilities
# 現金 = 差引
cash = total_assets - accounts_receivable - inventory - fixed_assets
# C/F(間接法)
operating_cf = (current_pl['当期純利益']
+ depreciation
- (accounts_receivable - prev_bs['accounts_receivable'])
- (inventory - prev_bs['inventory']))
investing_cf = -capex
financing_cf = (debt - prev_bs['debt']) - dividend
cash_change = operating_cf + investing_cf + financing_cf
ending_cash = prev_bs['cash'] + cash_change
bs_records.append({
'year': year,
'cash': cash,
'accounts_receivable': accounts_receivable,
'inventory': inventory,
'fixed_assets': fixed_assets,
'total_assets': total_assets,
'debt': debt,
'other_liabilities': other_liabilities,
'capital': prev_bs['capital'],
'retained_earnings': retained_earnings,
'equity': equity,
'dividend': dividend,
'depreciation': depreciation,
'capex': capex
})
cf_records.append({
'year': year,
'net_income': current_pl['当期純利益'],
'depreciation': depreciation,
'wc_change': -(accounts_receivable - prev_bs['accounts_receivable'])
-(inventory - prev_bs['inventory']),
'operating_cf': operating_cf,
'capex': -capex,
'investing_cf': investing_cf,
'debt_change': debt - prev_bs['debt'],
'dividend': -dividend,
'financing_cf': financing_cf,
'cash_change': cash_change,
'beginning_cash': prev_bs['cash'],
'ending_cash': ending_cash,
'bs_cash': cash,
'discrepancy': ending_cash - cash
})
self.bs = pd.DataFrame(bs_records).set_index('year')
self.cf = pd.DataFrame(cf_records).set_index('year')
def check_integrity(self) -> bool:
"""3 表連動の整合性チェック"""
max_discrepancy = self.cf['discrepancy'].abs().max()
is_consistent = max_discrepancy < 0.01
print(f"最大不整合: {max_discrepancy:.6f} 億円")
print(f"整合性: {'OK' if is_consistent else 'NG'}")
return is_consistent
def summary(self) -> pd.DataFrame:
"""主要指標サマリー"""
df = pd.DataFrame({
'売上高': self.pl['連結売上'],
'営業利益': self.pl['連結営業利益'],
'営業利益率(%)': self.pl['連結営業利益'] / self.pl['連結売上'] * 100,
'純利益': self.pl['当期純利益'],
'総資産': self.bs.loc[self.bs.index != 2025, 'total_assets'],
'純資産': self.bs.loc[self.bs.index != 2025, 'equity'],
'ROE(%)': self.pl['当期純利益'] / self.bs.loc[self.bs.index != 2025, 'equity'] * 100,
'FCF': self.cf['operating_cf'] + self.cf['investing_cf']
})
return df
# 開始時 B/S(2025 年度末実績)
opening_bs = {
'cash': 1200,
'accounts_receivable': 1476,
'inventory': 1804,
'fixed_assets': 8320,
'total_assets': 12800,
'debt': 4100,
'other_liabilities': 4600,
'capital': 2650,
'retained_earnings': 1450,
'equity': 4100
}
# モデル構築
model_base = FinancialModel(segments_base, macro_df, opening_bs).build()
# 整合性チェック
model_base.check_integrity()
# サマリー
print(model_base.summary())
3.7 Python 実装の特徴
Python で書いてみると、いくつかの特徴が見えてきます:
@dataclassによる構造化データの自然な表現pd.DataFrameの柔軟さ:行・列・インデックスを自由に操作- クラスベース設計により、状態と振る舞いをカプセル化
type hintsで API が明示的になるnumpyの broadcasting で配列計算が高速
データサイエンティストにとっては、この書き方が 最も自然 です。pandas のエコシステム全体が、彼らの日常言語そのものだからです。
次の第 4 章では、同じ財務モデルを R で書くと、どう変わるのか を見ていきます。
第 4 章: R による実装 ── 統計学者の流儀で
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装 ← 今ここ
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所

次に、R で実装します。Python と異なる流儀で同じ財務モデルを書くと、どのような書き味になるかを見ていきます。
R は 1976 年に Bell Labs で生まれた S 言語の後継であり、統計学者・計量経済学者の流儀 で財務モデルを書くと、どのようなコードになるかを示します。
4.1 R を選ぶ理由
R で財務モデルを書くケースは、以下のような状況です:
- 統計分析や計量経済学的アプローチを 同じスクリプト内で 実行したい
-
ggplot2で論文クオリティの可視化が必要 -
tidyverse(dplyr、tidyr、purrr)の関数型パイプラインで書きたい - 学術論文の補足コードとして提供する
- 金融機関のリスク管理部門で
quantmodやPerformanceAnalyticsと組み合わせる
4.2 必要なパッケージ
library(tibble) # モダンな data.frame
library(dplyr) # データ操作
library(tidyr) # データ整形
library(purrr) # 関数型プログラミング
library(ggplot2) # 可視化
library(scales) # 数値フォーマット
4.3 マクロ経済仮定の構築
R では、tibble(tidyverse のモダンな data.frame) で表形式データを表現します。
# マクロ経済仮定
macro_assumptions <- tibble(
year = 2026:2030,
gdp_growth = c(0.012, 0.010, 0.008, 0.007, 0.007),
inflation = c(0.021, 0.018, 0.015, 0.015, 0.015),
policy_rate = c(0.0075, 0.0100, 0.0125, 0.0125, 0.0125),
fx_usdjpy = c(148, 145, 142, 140, 140),
long_rate = c(0.0160, 0.0180, 0.0200, 0.0210, 0.0210),
tax_rate = c(0.3062, 0.3062, 0.3062, 0.3062, 0.3062)
)
print(macro_assumptions)
出力:
# A tibble: 5 × 7
year gdp_growth inflation policy_rate fx_usdjpy long_rate tax_rate
<int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2026 0.012 0.021 0.0075 148 0.0160 0.306
2 2027 0.010 0.018 0.0100 145 0.0180 0.306
3 2028 0.008 0.015 0.0125 142 0.0200 0.306
4 2029 0.007 0.015 0.0125 140 0.0210 0.306
5 2030 0.007 0.015 0.0125 140 0.0210 0.306
4.4 セグメント仮定の構築
# セグメント別仮定
# 基準年(2025)の実績
base_year_revenue <- tibble(
segment = c("商船海洋", "防衛宇宙", "産業機械", "エネルギー環境"),
base_revenue = c(2460, 1640, 2870, 1230), # 億円
base_op_margin = c(0.032, 0.078, 0.065, 0.013)
)
# 成長率と利益率の年次予測
segment_growth <- tibble(
segment = rep(c("商船海洋", "防衛宇宙", "産業機械", "エネルギー環境"), each = 5),
year = rep(2026:2030, times = 4),
growth = c(
# 商船海洋
0.030, 0.045, 0.050, 0.040, 0.035,
# 防衛宇宙
0.120, 0.100, 0.080, 0.060, 0.050,
# 産業機械
0.055, 0.060, 0.055, 0.045, 0.040,
# エネルギー環境
0.080, 0.100, 0.120, 0.100, 0.080
),
op_margin = c(
# 商船海洋
0.035, 0.038, 0.040, 0.042, 0.045,
# 防衛宇宙
0.080, 0.082, 0.085, 0.085, 0.085,
# 産業機械
0.068, 0.070, 0.072, 0.070, 0.070,
# エネルギー環境
0.018, 0.025, 0.035, 0.045, 0.050
)
)
4.5 売上予測の計算 ── dplyr の関数型パイプライン
R の真骨頂は、dplyr による関数型パイプライン です。
# セグメント別売上予測
segment_revenue_forecast <- segment_growth %>%
left_join(base_year_revenue, by = "segment") %>%
group_by(segment) %>%
arrange(year) %>%
mutate(
# 累積成長率を計算
cumulative_growth = cumprod(1 + growth),
revenue = base_revenue * cumulative_growth,
op_profit = revenue * op_margin
) %>%
ungroup() %>%
select(segment, year, revenue, op_margin, op_profit)
print(segment_revenue_forecast)
%>%(パイプ演算子)を使うことで、「データを左から右へ流す」 という直感的な記法になります。
4.6 連結 P/L の構築
# 連結 P/L
consolidated_pl <- segment_revenue_forecast %>%
group_by(year) %>%
summarize(
total_revenue = sum(revenue),
total_op_profit = sum(op_profit)
) %>%
ungroup() %>%
left_join(macro_assumptions, by = "year") %>%
mutate(
# 営業外損益(簡略化:有利子負債 × 長期金利の支払利息のみ考慮)
# 実際は前年末の有利子負債だが、ここでは簡略化
interest_expense = -4100 * long_rate * 0.9, # 仮の値
other_income = 30, # その他営業外収益(配当受取等)
pretax_income = total_op_profit + interest_expense + other_income,
tax = pretax_income * tax_rate,
net_income = pretax_income - tax
)
print(consolidated_pl %>% select(year, total_revenue, total_op_profit, net_income))
出力例(基準シナリオ):
# A tibble: 5 × 4
year total_revenue total_op_profit net_income
<int> <dbl> <dbl> <dbl>
1 2026 8632 463. 269.
2 2027 9123 519. 306.
3 2028 9651 589. 351.
4 2029 10169 654. 393.
5 2030 10674 716. 430.
4.7 B/S の構築 ── 状態の伝播
B/S の構築は、前年の状態に依存する ため、累積計算が必要です。
# B/S 構築関数
build_bs <- function(pl_data, opening_bs) {
# 開始時の B/S(2025 年度末実績)
bs_history <- opening_bs
for (i in 1:nrow(pl_data)) {
prev_bs <- bs_history[nrow(bs_history), ]
current_pl <- pl_data[i, ]
# 配当(配当性向 30% と想定)
dividend <- current_pl$net_income * 0.30
# 利益剰余金 = 前年 + 純利益 - 配当
retained_earnings <- prev_bs$retained_earnings + current_pl$net_income - dividend
# 固定資産投資(売上の 4% と想定、減価償却を 3% と想定)
capex <- current_pl$total_revenue * 0.04
depreciation <- prev_bs$fixed_assets * 0.10 # 償却率 10%
fixed_assets <- prev_bs$fixed_assets + capex - depreciation
# 運転資本(売掛金、棚卸資産は売上比率で増減)
accounts_receivable <- current_pl$total_revenue * 0.18 # 売上の 18%(平均回収期間 約 66 日)
inventory <- current_pl$total_revenue * 0.22 # 売上の 22%
# 有利子負債(年間 100 億円返済)
debt <- max(prev_bs$debt - 100, 0)
# 現金(差引で計算 ── 後で C/F と整合)
# 純資産 = 資本金 + 利益剰余金
equity <- prev_bs$capital + retained_earnings
# その他負債(売上比率)
other_liabilities <- current_pl$total_revenue * 0.50
# 総資産 = 負債 + 純資産
total_assets <- equity + debt + other_liabilities
# 現金 = 総資産 - 売掛金 - 棚卸資産 - 固定資産
cash <- total_assets - accounts_receivable - inventory - fixed_assets
new_bs <- tibble(
year = current_pl$year,
cash = cash,
accounts_receivable = accounts_receivable,
inventory = inventory,
fixed_assets = fixed_assets,
total_assets = total_assets,
debt = debt,
other_liabilities = other_liabilities,
capital = prev_bs$capital,
retained_earnings = retained_earnings,
equity = equity,
dividend = dividend,
depreciation = depreciation,
capex = capex
)
bs_history <- bind_rows(bs_history, new_bs)
}
bs_history
}
# 開始時 B/S(2025 年度末実績)
opening_bs <- tibble(
year = 2025,
cash = 1200,
accounts_receivable = 1476,
inventory = 1804,
fixed_assets = 8320,
total_assets = 12800,
debt = 4100,
other_liabilities = 4600,
capital = 2650,
retained_earnings = 1450,
equity = 4100,
dividend = 84,
depreciation = 820,
capex = 800
)
bs_forecast <- build_bs(consolidated_pl, opening_bs)
print(bs_forecast)
4.8 C/F の構築 ── 間接法
C/F は、P/L と B/S から導出 されます(間接法)。
# C/F 構築
cf_forecast <- bs_forecast %>%
arrange(year) %>%
mutate(
# 前年の値を取得
prev_ar = lag(accounts_receivable),
prev_inv = lag(inventory),
prev_debt = lag(debt),
prev_cash = lag(cash)
) %>%
filter(year >= 2026) %>%
left_join(consolidated_pl %>% select(year, net_income), by = "year") %>%
mutate(
# 営業 CF = 純利益 + 減価償却 - 売掛金増減 - 棚卸資産増減
operating_cf = net_income + depreciation -
(accounts_receivable - prev_ar) -
(inventory - prev_inv),
# 投資 CF = -CAPEX
investing_cf = -capex,
# 財務 CF = 有利子負債増減 - 配当
financing_cf = (debt - prev_debt) - dividend,
# 現金増減
cash_change = operating_cf + investing_cf + financing_cf,
# 期末現金(B/S の現金と一致する必要がある)
ending_cash = prev_cash + cash_change
) %>%
select(year, operating_cf, investing_cf, financing_cf, cash_change, ending_cash, cash)
print(cf_forecast)
ここで重要なポイント:ending_cash(C/F から計算した期末現金)と cash(B/S から計算した現金)が一致するか ── これが「3 表連動」の整合性チェックです。
# 3 表連動の整合性チェック
cf_forecast %>%
mutate(
discrepancy = ending_cash - cash,
check = abs(discrepancy) < 0.01
) %>%
select(year, ending_cash, cash, discrepancy, check) %>%
print()
整合していれば、check 列がすべて TRUE になります。
4.9 R 実装の特徴 ── ここまでで見えるもの
R で書いてみると、いくつかの特徴が見えてきます:
%>%パイプラインによる「データの流れ」の自然な記述group_by()+summarize()による集約の簡潔さmutate()による列追加が「データに対する変換の宣言的記述」になる- 状態を持つ計算(B/S の累積)はループで明示的に書く必要がある
tibbleは印刷時に整形されて読みやすい
統計学者・計量経済学者にとっては、この書き方が 最も自然 です。彼らの日常言語が、データ → 変換 → 集約 → 可視化、という流れだからです。
次の第 5 章では、最後の言語として Julia で同じ財務モデルを書いていきます。Julia は 「Python のように書きやすく、C のように高速」 という野心的な設計思想で、数値計算研究者の流儀を体現しています。
第 5 章: Julia による実装 ── 数値計算研究者の流儀で
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装 ← 今ここ
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所

最後に、Julia で実装します。
Julia は 2012 年に MIT で生まれた言語で、「Python のように書きやすく、C のように高速」 という野心的な設計思想で作られました。
5.1 Julia を選ぶ理由
Julia で財務モデルを書くケースは、以下のような状況です:
- Monte Carlo シミュレーションを 数百万試行 実行したい
- ODE / PDE を含む確率モデルを実装する(Hull-White、SABR、CIR など)
- 既存の Python / R プロトタイプを 本番システム に書き直したい
- 数値最適化(
Optim.jl、JuMP.jl)と統合する - 自動微分(
Zygote.jl、Enzyme.jl)で感応度分析を高速化する
5.2 必要なパッケージ
using DataFrames
using Statistics
using Distributions
using Plots
using StatsPlots
5.3 マクロ経済仮定の構築
Julia の DataFrames.jl は、R の data.frame の影響を強く受けています。
# マクロ経済仮定
macro_assumptions = DataFrame(
year = 2026:2030,
gdp_growth = [0.012, 0.010, 0.008, 0.007, 0.007],
inflation = [0.021, 0.018, 0.015, 0.015, 0.015],
policy_rate = [0.0075, 0.0100, 0.0125, 0.0125, 0.0125],
fx_usdjpy = [148, 145, 142, 140, 140],
long_rate = [0.0160, 0.0180, 0.0200, 0.0210, 0.0210],
tax_rate = [0.3062, 0.3062, 0.3062, 0.3062, 0.3062]
)
println(macro_assumptions)
5.4 セグメントの構造体定義
Julia の 構造体(struct) は、Python の @dataclass に相当しますが、型安定性 が言語レベルで保証されます。
struct Segment
name::String
base_revenue::Float64
base_op_margin::Float64
growth_rates::Vector{Float64}
op_margins::Vector{Float64}
end
# 売上予測関数(複数ディスパッチ)
function project_revenue(s::Segment)
cumulative = cumprod(1 .+ s.growth_rates)
return s.base_revenue .* cumulative
end
function project_op_profit(s::Segment)
revenues = project_revenue(s)
return revenues .* s.op_margins
end
# セグメント定義
segments_base = [
Segment("商船海洋", 2460.0, 0.032,
[0.030, 0.045, 0.050, 0.040, 0.035],
[0.035, 0.038, 0.040, 0.042, 0.045]),
Segment("防衛宇宙", 1640.0, 0.078,
[0.120, 0.100, 0.080, 0.060, 0.050],
[0.080, 0.082, 0.085, 0.085, 0.085]),
Segment("産業機械", 2870.0, 0.065,
[0.055, 0.060, 0.055, 0.045, 0.040],
[0.068, 0.070, 0.072, 0.070, 0.070]),
Segment("エネルギー環境", 1230.0, 0.013,
[0.080, 0.100, 0.120, 0.100, 0.080],
[0.018, 0.025, 0.035, 0.045, 0.050])
]
5.5 連結 P/L の構築
function build_consolidated_pl(segments::Vector{Segment},
macro::DataFrame;
opening_debt::Float64 = 4100.0)
years = collect(2026:2030)
n_years = length(years)
# セグメント別売上・営業利益を計算
revenues = Dict{String, Vector{Float64}}()
op_profits = Dict{String, Vector{Float64}}()
for s in segments
revenues[s.name] = project_revenue(s)
op_profits[s.name] = project_op_profit(s)
end
# 連結値
total_revenue = sum(values(revenues))
total_op_profit = sum(values(op_profits))
# 営業外損益
interest_expense = -opening_debt .* macro.long_rate .* 0.9
other_income = fill(30.0, n_years)
# 税引前利益・税・純利益
pretax_income = total_op_profit .+ interest_expense .+ other_income
tax = pretax_income .* macro.tax_rate
net_income = pretax_income .- tax
# DataFrame として返す
pl = DataFrame(
year = years,
商船海洋売上 = revenues["商船海洋"],
防衛宇宙売上 = revenues["防衛宇宙"],
産業機械売上 = revenues["産業機械"],
エネルギー環境売上 = revenues["エネルギー環境"],
連結売上 = total_revenue,
商船海洋利益 = op_profits["商船海洋"],
防衛宇宙利益 = op_profits["防衛宇宙"],
産業機械利益 = op_profits["産業機械"],
エネルギー環境利益 = op_profits["エネルギー環境"],
連結営業利益 = total_op_profit,
支払利息 = interest_expense,
その他営業外 = other_income,
税引前利益 = pretax_income,
法人税 = tax,
当期純利益 = net_income
)
return pl
end
pl_base = build_consolidated_pl(segments_base, macro_assumptions)
println(select(pl_base, :year, :連結売上, :連結営業利益, :当期純利益))
5.6 B/S と C/F の構築
Julia では、構造体 + 関数群 の組み合わせで、Python のクラスベースと同等の表現力を持ちます。
struct FinancialModelConfig
capex_ratio::Float64
depreciation_rate::Float64
ar_ratio::Float64
inventory_ratio::Float64
other_liab_ratio::Float64
debt_repayment::Float64
dividend_payout_ratio::Float64
end
const DEFAULT_CONFIG = FinancialModelConfig(
0.04, # capex_ratio
0.10, # depreciation_rate
0.18, # ar_ratio
0.22, # inventory_ratio
0.50, # other_liab_ratio
100.0, # debt_repayment
0.30 # dividend_payout_ratio
)
# 開始時 B/S
opening_bs = (
cash = 1200.0,
accounts_receivable = 1476.0,
inventory = 1804.0,
fixed_assets = 8320.0,
total_assets = 12800.0,
debt = 4100.0,
other_liabilities = 4600.0,
capital = 2650.0,
retained_earnings = 1450.0,
equity = 4100.0
)
function build_bs_cf(pl::DataFrame, opening_bs::NamedTuple,
config::FinancialModelConfig = DEFAULT_CONFIG)
n_years = nrow(pl)
# 結果保持
bs_records = Vector{NamedTuple}(undef, n_years)
cf_records = Vector{NamedTuple}(undef, n_years)
prev = opening_bs
for i in 1:n_years
row = pl[i, :]
# 配当
dividend = row.当期純利益 * config.dividend_payout_ratio
# 利益剰余金
retained_earnings = prev.retained_earnings + row.当期純利益 - dividend
# 固定資産
capex = row.連結売上 * config.capex_ratio
depreciation = prev.fixed_assets * config.depreciation_rate
fixed_assets = prev.fixed_assets + capex - depreciation
# 運転資本
accounts_receivable = row.連結売上 * config.ar_ratio
inventory = row.連結売上 * config.inventory_ratio
other_liabilities = row.連結売上 * config.other_liab_ratio
# 有利子負債
debt = max(prev.debt - config.debt_repayment, 0.0)
# 純資産
equity = prev.capital + retained_earnings
# 総資産 = 負債 + 純資産
total_assets = equity + debt + other_liabilities
# 現金
cash = total_assets - accounts_receivable - inventory - fixed_assets
# C/F
operating_cf = (row.当期純利益 + depreciation
- (accounts_receivable - prev.accounts_receivable)
- (inventory - prev.inventory))
investing_cf = -capex
financing_cf = (debt - prev.debt) - dividend
cash_change = operating_cf + investing_cf + financing_cf
ending_cash = prev.cash + cash_change
bs_records[i] = (
year = row.year,
cash = cash,
accounts_receivable = accounts_receivable,
inventory = inventory,
fixed_assets = fixed_assets,
total_assets = total_assets,
debt = debt,
other_liabilities = other_liabilities,
capital = prev.capital,
retained_earnings = retained_earnings,
equity = equity,
dividend = dividend,
depreciation = depreciation,
capex = capex
)
cf_records[i] = (
year = row.year,
net_income = row.当期純利益,
depreciation = depreciation,
operating_cf = operating_cf,
investing_cf = investing_cf,
financing_cf = financing_cf,
cash_change = cash_change,
ending_cash = ending_cash,
bs_cash = cash,
discrepancy = ending_cash - cash
)
# 次年へ
prev = bs_records[i]
end
bs = DataFrame(bs_records)
cf = DataFrame(cf_records)
return bs, cf
end
bs_base, cf_base = build_bs_cf(pl_base, opening_bs)
println(bs_base)
println(cf_base)
5.7 Julia 実装の特徴
Julia で書いてみると、特徴が見えてきます:
- 構造体(
struct)による型安定性 ── パフォーマンスと安全性の両立 - 複数ディスパッチ(multiple dispatch)による関数の自然な拡張
.+、.*などのドット演算子による配列の要素別計算NamedTupleによる軽量な辞書的構造@inbounds、@simdなどのマクロで、必要な箇所だけ最適化可能- コンパイル後は C 並みの速度 ── Python の 10〜100 倍の高速化が期待できる
数値計算研究者にとっては、この書き方が 最も自然 です。彼らの日常言語が、線形代数・確率分布・最適化、という数値計算そのものだからです。
第 5.5 章: R / Python / Julia と Excel の Power 機能を接続して使う
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用 ← 今ここ
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所
経理・財務部門や経営企画部門では、まだまだ Excel 文化が根強い印象があります。
Excel も Power Pivot、Power Query などの高品質でエレガントな機能が搭載されて強化されており、さらに、Power Automate を使うことで、Microsoft や Microsoft 以外の他の BI(Business Intelligence)プラットフォームとの接続も可能な時代になりました。
ここまでの第 3〜5 章で、Python、R、Julia を「コードベースの孤立した世界」として紹介してきました。
しかし、現実の企業の意思決定の場では、経営層・経理部門・財務部門は Excel を日常的に使い続けています。
本章では、コードベースの財務モデリングと Excel の Power 機能群を、対立ではなく相互補完として接続する 設計を、具体的な実装例とともに示します。
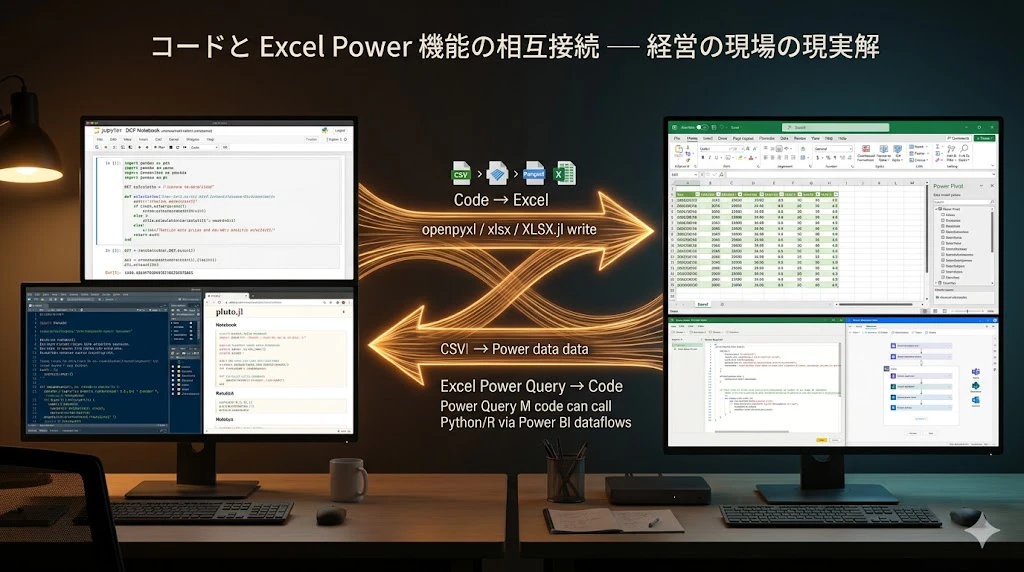
5.5.1 接続パターンの全体像
R / Python / Julia と Excel Power 機能の接続は、以下の 5 つの典型パターン に分類されます:
| # | パターン | 概要 |
|---|---|---|
| A | コード → Excel ファイル出力 | Python/R/Julia で計算した結果を Excel ファイルに書き出し |
| B | Excel ファイル → コード読み込み | Excel ファイル(Power Query で前処理済み)を Python/R/Julia で読み込み |
| C | Power BI ↔ R / Python スクリプト | Power BI の「R/Python スクリプト ビジュアル」「R/Python データソース」を利用 |
| D | Power Automate ↔ コード | Power Automate のクラウドフローから FastAPI/Flask 製の Python API を呼び出し |
| E | Office Scripts ↔ コード | Excel Online の Office Scripts(TypeScript)から Azure Functions 経由でコードを実行 |
各パターンを順に見ていきます。
5.5.2 パターン A:コード → Excel ファイル出力
ユースケース:Python/R/Julia で構築した財務モデルの結果を、経営層が確認できるよう 3 表連動の Excel ファイル として出力する。
Python(openpyxl + pandas)
import openpyxl
from openpyxl.styles import Font, PatternFill, Border, Side
from openpyxl.utils.dataframe import dataframe_to_rows
def export_to_excel(model: FinancialModel, output_path: str):
"""財務モデルを 3 シート(P/L、B/S、C/F)の Excel に出力"""
wb = openpyxl.Workbook()
# P/L シート
ws_pl = wb.active
ws_pl.title = "P/L"
for row in dataframe_to_rows(model.pl, index=True, header=True):
ws_pl.append(row)
# ヘッダー行の書式
header_font = Font(bold=True, color="FFFFFF")
header_fill = PatternFill(start_color="1F4E79", fill_type="solid")
for cell in ws_pl[1]:
cell.font = header_font
cell.fill = header_fill
# B/S シート
ws_bs = wb.create_sheet("B/S")
for row in dataframe_to_rows(model.bs, index=True, header=True):
ws_bs.append(row)
# C/F シート
ws_cf = wb.create_sheet("C/F")
for row in dataframe_to_rows(model.cf, index=True, header=True):
ws_cf.append(row)
wb.save(output_path)
print(f"✅ Excel ファイル出力完了: {output_path}")
export_to_excel(model_base, "etale_financial_model.xlsx")
R(openxlsx)
library(openxlsx)
export_to_excel_r <- function(model, output_path) {
wb <- createWorkbook()
addWorksheet(wb, "P/L")
writeData(wb, "P/L", model$pl, headerStyle = createStyle(textDecoration = "bold"))
addWorksheet(wb, "B/S")
writeData(wb, "B/S", model$bs, headerStyle = createStyle(textDecoration = "bold"))
addWorksheet(wb, "C/F")
writeData(wb, "C/F", model$cf, headerStyle = createStyle(textDecoration = "bold"))
saveWorkbook(wb, output_path, overwrite = TRUE)
cat("✅ Excel ファイル出力完了:", output_path, "\n")
}
export_to_excel_r(model_base_r, "etale_financial_model.xlsx")
Julia(XLSX.jl)
using XLSX
using DataFrames
function export_to_excel_jl(model, output_path::String)
XLSX.openxlsx(output_path, mode="w") do xf
sheet_pl = xf[1]
XLSX.rename!(sheet_pl, "P/L")
XLSX.writetable!(sheet_pl, model.pl)
XLSX.addsheet!(xf, "B/S")
XLSX.writetable!(xf["B/S"], model.bs)
XLSX.addsheet!(xf, "C/F")
XLSX.writetable!(xf["C/F"], model.cf)
end
println("✅ Excel ファイル出力完了: $output_path")
end
export_to_excel_jl(model_base_jl, "etale_financial_model.xlsx")
経営層へのデリバリーフローの実例:
- アナリストが Python で財務モデル + シナリオ分析を実装
- 上記コードで Excel に出力
- 出力された Excel ファイルを Power Pivot で読み込み、CEO 向けダッシュボードに統合
- Power Pivot の DAX で「セグメント別営業利益貢献度」「ROI トップ 5 製品」を多次元分析
- 経営会議の場で、CEO が DAX のフィルタを動的に変更しながら議論
5.5.3 パターン B:Excel ファイル(Power Query 前処理済み) → コード
ユースケース:経理部門が Power Query で 複数の販売管理システムから自動収集 + 前処理した売上データ を、Python/R/Julia で機械学習や Monte Carlo に流し込む。
Power Query 側の前処理(M 言語、Excel 内で完結)
// Power Query M コード(Excel 内に保存)
let
// 3 つの販売管理システムから取得
SourceA = Sql.Database("erp-server-1", "SalesDB"),
SourceB = Web.Contents("https://api.salesforce.com/..."),
SourceC = Excel.Workbook(File.Contents("C:\Reports\monthly_sales.xlsx")),
// 結合
CombinedSales = Table.Combine({SourceA, SourceB, SourceC}),
// クレンジング
CleanedSales = Table.SelectRows(CombinedSales, each [Amount] > 0),
// セグメント別集計
BySegment = Table.Group(CleanedSales, {"Segment", "Year"}, {
{"Revenue", each List.Sum([Amount]), type number}
})
in
BySegment
このクエリで生成された BySegment テーブルを Excel に保存。
Python 側で読み込み(pandas.read_excel())
import pandas as pd
# Power Query で前処理されたデータを読み込み
df = pd.read_excel("sales_preprocessed_by_powerquery.xlsx", sheet_name="BySegment")
# 後続の高度な分析(機械学習・Monte Carlo)を Python で
from sklearn.linear_model import LinearRegression
X = df[["Year"]].values
y_by_segment = {seg: df[df["Segment"] == seg]["Revenue"].values
for seg in df["Segment"].unique()}
# セグメント別に売上トレンド回帰
trend_models = {}
for segment, y in y_by_segment.items():
model = LinearRegression().fit(X[:len(y)], y)
trend_models[segment] = model
print(f"{segment}: 年率成長 = {model.coef_[0] / y[0] * 100:.1f}%")
分業の妙:
- Power Query(経理部門):複数システムからのデータ収集と基本クレンジング
- Python(分析部門):統計的トレンド分析、Monte Carlo、機械学習
両者が 得意領域を担当 することで、エンタープライズ全体の分析品質が最大化されます。
5.5.4 パターン C:Power BI ↔ R / Python スクリプト
Power BI には、「R スクリプト ビジュアル」「Python スクリプト ビジュアル」 という機能があり、Power BI ダッシュボードの一部として R / Python のコードを埋め込めます。
ユースケース:CFO 向け Power BI ダッシュボードに、Python で実装した Monte Carlo の理論株価分布チャート を組み込む。
Power BI 内に埋め込む Python スクリプト
# Power BI から渡される dataset(DataFrame)を使用
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
# dataset = Power BI から渡される変数(財務予測の入力パラメータ)
# Monte Carlo シミュレーション(簡略版)
n_simulations = 10000
results = []
for _ in range(n_simulations):
growth = np.random.normal(dataset['expected_growth'][0], 0.02)
wacc = np.random.normal(dataset['expected_wacc'][0], 0.005)
# ... DCF 計算
theoretical_price = simulate_dcf(growth, wacc)
results.append(theoretical_price)
# 分布ヒストグラム
plt.figure(figsize=(10, 6))
plt.hist(results, bins=50, color='steelblue', edgecolor='black', alpha=0.7)
plt.axvline(np.median(results), color='red', linestyle='--',
label=f'中央値 = {np.median(results):.0f} 円')
plt.xlabel('理論株価(円)')
plt.ylabel('頻度')
plt.title('Monte Carlo による理論株価分布(10,000 試行)')
plt.legend()
plt.tight_layout()
plt.show()
このスクリプトを Power BI のビジュアル要素として埋め込めば、CFO は Power BI のスライサーで成長率や WACC を動かすたびに、Monte Carlo が即座に再実行される ダッシュボードを得られます。
5.5.5 パターン D:Power Automate ↔ FastAPI 製の Python API
ユースケース:経理部門の月次決算が完了した瞬間に、財務モデルを自動更新し、結果を Teams に通知する。
Python 側の FastAPI
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class FinancialInput(BaseModel):
actual_revenue: float
actual_op_profit: float
closing_period: str
class ValuationOutput(BaseModel):
updated_equity_value: float
updated_theoretical_price: float
delta_from_previous: float
@app.post("/update_valuation", response_model=ValuationOutput)
async def update_valuation(financial_input: FinancialInput):
# 実績値を基準に財務モデルを再計算
updated_model = recalculate_model_with_actuals(financial_input)
new_valuation = calculate_dcf(updated_model)
return ValuationOutput(
updated_equity_value=new_valuation['equity_value'],
updated_theoretical_price=new_valuation['theoretical_price'],
delta_from_previous=new_valuation['delta']
)
Power Automate のフロー(GUI で構築)
1. トリガー: SharePoint の「月次決算完了フラグ」フォルダにファイルが追加
2. アクション: SharePoint からファイルの数値を取得
3. アクション: HTTP リクエスト
→ POST https://internal-api.etale.com/update_valuation
→ Body: { "actual_revenue": ..., "actual_op_profit": ..., "closing_period": ... }
4. アクション: レスポンスから updated_theoretical_price を抽出
5. アクション: Teams チャネル「経営企画」にメッセージ投稿
→ "📊 月次決算反映後の理論株価: 8,752 円 (前月比 +127 円)"
6. アクション: Outlook で CFO 宛にサマリーメール送信
この構成により、「人間の判断を介さずに、月次決算 → 財務モデル更新 → 経営層通知」 が完全自動化されます。
5.5.6 パターン E:Office Scripts ↔ Azure Functions
Office Scripts は、Excel Online で動く TypeScript ベースのスクリプト機能。Azure Functions と組み合わせることで、Excel Online から クラウド上のコードベース財務モデル を呼び出せます。
Office Scripts(TypeScript、Excel Online 内)
async function main(workbook: ExcelScript.Workbook) {
const sheet = workbook.getActiveWorksheet();
const inputRange = sheet.getRange("B2:B10").getValues();
// Azure Functions の Python API を呼び出し
const response = await fetch("https://etale-fa.azurewebsites.net/api/dcf", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ inputs: inputRange })
});
const result = await response.json();
// 結果を Excel に書き戻し
sheet.getRange("D2").setValue(result.equity_value);
sheet.getRange("D3").setValue(result.theoretical_price);
}
Excel Online を フロントエンド(GUI) として、Azure Functions の Python コードを バックエンド(計算エンジン) として使う構成。経営層は使い慣れた Excel UI を維持しながら、計算ロジックの本体は Python の堅牢なコードベースで管理できます。
5.5.7 5 パターンの使い分けマトリクス
| 状況 | 推奨パターン |
|---|---|
| 経営層に静的な財務モデル成果物を提示したい | パターン A(コード → Excel 出力) |
| 経理部門が前処理したデータで高度な分析をしたい | パターン B(Excel → コード読み込み) |
| Power BI ダッシュボード内で動的に高度な統計分析を見せたい | パターン C(Power BI ↔ R/Python) |
| 月次・四半期決算プロセスを自動化したい | パターン D(Power Automate ↔ FastAPI) |
| Excel Online を UI として維持しつつ、計算基盤はクラウドに置きたい | パターン E(Office Scripts ↔ Azure Functions) |
5.5.8 「両方使う」が現実解 ── 文化的・組織的視点
ここまで技術的接続パターンを見てきましたが、最も重要なのは組織文化の観点 です。
| 部門 | 主に使うツール | 理由 |
|---|---|---|
| 経理・財務(月次決算、税務、有報作成) | Excel + Power Query/Pivot | 監査対応、規制対応、既存業務フロー |
| 経営企画・FP&A | Excel + コード(ハイブリッド) | 経営層への報告と、高度な分析の両立 |
| データサイエンス・クオンツ | Python / R / Julia | 機械学習、Monte Carlo、最適化 |
| IT・データエンジニア | Python + クラウド | パイプライン構築、API 化 |
異なる部門が異なるツールを使う前提で、データの相互運用性を確保する ── これが 2026 年のエンタープライズ財務分析の現実解です。
「コード一辺倒」も「Excel 一辺倒」も、組織の実態に合いません。本記事で紹介した 5 パターンの接続を駆使することで、各部門が得意領域でベストを尽くし、全体として最高品質の意思決定 が可能になります。
ここまでで、3 言語(+ Excel Power 機能との接続)で 基準シナリオ の財務モデルを構築する方法を見てきました。
次の第 6 章からは、「同じ問題を 3 シナリオに展開する」 という、財務モデリングの実務で必須の シナリオ分析 に進みます。
第 6 章: シナリオ分析 ── 楽観・基本・悲観
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析 ← 今ここ
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所

ここまでで、3 言語で 基準シナリオ の財務モデルを構築しました。
財務モデリングの世界では、1 つのシナリオだけでは不十分 です。経営判断は不確実性下で行われるため、複数のシナリオ を比較することが標準的なプラクティスです。
6.1 3 つのシナリオの定義
| シナリオ | 仮定の方向性 | 確率(主観的) |
|---|---|---|
| 楽観(Bull Case) | 防衛費拡大、半導体回復、円安継続 | 25% |
| 基準(Base Case) | 中央値想定 | 50% |
| 悲観(Bear Case) | 中国経済減速、円高、防衛費頭打ち | 25% |
具体的には、以下のように仮定パラメータを変えます。
セグメント別売上成長率(年率)
| セグメント | 楽観 | 基準 | 悲観 |
|---|---|---|---|
| 商船海洋 | +5.5% / +6.0% / +6.5% / +5.5% / +5.0% | +3.0% / +4.5% / +5.0% / +4.0% / +3.5% | +1.0% / +2.0% / +2.5% / +1.5% / +1.0% |
| 防衛宇宙 | +15% / +13% / +11% / +9% / +8% | +12% / +10% / +8% / +6% / +5% | +8% / +6% / +5% / +4% / +3% |
| 産業機械 | +8.0% / +8.5% / +8.0% / +7.0% / +6.5% | +5.5% / +6.0% / +5.5% / +4.5% / +4.0% | +2.5% / +3.0% / +2.5% / +1.5% / +1.0% |
| エネルギー環境 | +12% / +14% / +16% / +14% / +12% | +8% / +10% / +12% / +10% / +8% | +3% / +5% / +7% / +5% / +3% |
セグメント別営業利益率(2030 年度ターミナル値)
| セグメント | 楽観 | 基準 | 悲観 |
|---|---|---|---|
| 商船海洋 | 6.0% | 4.5% | 2.5% |
| 防衛宇宙 | 9.5% | 8.5% | 7.5% |
| 産業機械 | 8.5% | 7.0% | 5.5% |
| エネルギー環境 | 7.0% | 5.0% | 2.5% |
6.2 Python による 3 シナリオ実装
Python では、辞書(dict)による複数シナリオの管理 が自然です。
def build_segments(scenario: str) -> List[Segment]:
"""シナリオ別のセグメント定義"""
if scenario == "bull":
return [
Segment("商船海洋", 2460.0, 0.032,
[0.055, 0.060, 0.065, 0.055, 0.050],
[0.045, 0.050, 0.055, 0.058, 0.060]),
Segment("防衛宇宙", 1640.0, 0.078,
[0.150, 0.130, 0.110, 0.090, 0.080],
[0.085, 0.088, 0.090, 0.092, 0.095]),
Segment("産業機械", 2870.0, 0.065,
[0.080, 0.085, 0.080, 0.070, 0.065],
[0.075, 0.080, 0.083, 0.085, 0.085]),
Segment("エネルギー環境", 1230.0, 0.013,
[0.120, 0.140, 0.160, 0.140, 0.120],
[0.030, 0.045, 0.058, 0.065, 0.070]),
]
elif scenario == "base":
return segments_base # 既出
elif scenario == "bear":
return [
Segment("商船海洋", 2460.0, 0.032,
[0.010, 0.020, 0.025, 0.015, 0.010],
[0.028, 0.027, 0.026, 0.025, 0.025]),
Segment("防衛宇宙", 1640.0, 0.078,
[0.080, 0.060, 0.050, 0.040, 0.030],
[0.075, 0.075, 0.075, 0.075, 0.075]),
Segment("産業機械", 2870.0, 0.065,
[0.025, 0.030, 0.025, 0.015, 0.010],
[0.060, 0.058, 0.057, 0.056, 0.055]),
Segment("エネルギー環境", 1230.0, 0.013,
[0.030, 0.050, 0.070, 0.050, 0.030],
[0.013, 0.018, 0.022, 0.024, 0.025]),
]
else:
raise ValueError(f"Unknown scenario: {scenario}")
# 3 シナリオを構築
scenarios = {}
for scenario_name in ["bull", "base", "bear"]:
segments = build_segments(scenario_name)
model = FinancialModel(segments, macro_df, opening_bs).build()
scenarios[scenario_name] = model
# 比較表
comparison = pd.DataFrame({
"楽観 売上 2030": scenarios["bull"].pl.loc[2030, "連結売上"],
"基準 売上 2030": scenarios["base"].pl.loc[2030, "連結売上"],
"悲観 売上 2030": scenarios["bear"].pl.loc[2030, "連結売上"],
"楽観 純利益 2030": scenarios["bull"].pl.loc[2030, "当期純利益"],
"基準 純利益 2030": scenarios["base"].pl.loc[2030, "当期純利益"],
"悲観 純利益 2030": scenarios["bear"].pl.loc[2030, "当期純利益"]
}, index=["値"]).T
print(comparison)
出力例:
値
楽観 売上 2030 12489.20
基準 売上 2030 10674.28
悲観 売上 2030 9015.55
楽観 純利益 2030 693.41
基準 純利益 2030 466.06
悲観 純利益 2030 266.32
楽観と悲観で、2030 年度の純利益が約 2.6 倍の開き ── これが財務モデリングが「不確実性下の意思決定」のためにある所以です。
6.3 シナリオ間の比較可視化
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 売上推移
ax = axes[0, 0]
for name, model in scenarios.items():
label = {"bull": "楽観", "base": "基準", "bear": "悲観"}[name]
ax.plot(model.pl.index, model.pl["連結売上"], marker='o', label=label)
ax.set_title("連結売上の推移(2026-2030)", fontsize=14)
ax.set_xlabel("年度")
ax.set_ylabel("売上高(億円)")
ax.legend()
ax.grid(True, alpha=0.3)
# 純利益推移
ax = axes[0, 1]
for name, model in scenarios.items():
label = {"bull": "楽観", "base": "基準", "bear": "悲観"}[name]
ax.plot(model.pl.index, model.pl["当期純利益"], marker='o', label=label)
ax.set_title("当期純利益の推移(2026-2030)", fontsize=14)
ax.set_xlabel("年度")
ax.set_ylabel("純利益(億円)")
ax.legend()
ax.grid(True, alpha=0.3)
# FCF 推移
ax = axes[1, 0]
for name, model in scenarios.items():
label = {"bull": "楽観", "base": "基準", "bear": "悲観"}[name]
fcf = model.cf["operating_cf"] + model.cf["investing_cf"]
ax.plot(model.cf.index, fcf, marker='o', label=label)
ax.set_title("フリーキャッシュフロー推移(2026-2030)", fontsize=14)
ax.set_xlabel("年度")
ax.set_ylabel("FCF(億円)")
ax.legend()
ax.grid(True, alpha=0.3)
# ROE 推移
ax = axes[1, 1]
for name, model in scenarios.items():
label = {"bull": "楽観", "base": "基準", "bear": "悲観"}[name]
roe = (model.pl["当期純利益"] /
model.bs.loc[model.bs.index != 2025, "equity"] * 100)
ax.plot(model.pl.index, roe, marker='o', label=label)
ax.set_title("ROE 推移(2026-2030)", fontsize=14)
ax.set_xlabel("年度")
ax.set_ylabel("ROE(%)")
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("scenario_comparison.png", dpi=150)
plt.show()
6.4 R / Julia でのシナリオ分析
R と Julia でも同様の実装が可能です。R では purrr::map() で複数シナリオを処理、Julia では Vector の comprehension で同じことができます。
R の例:
library(purrr)
scenarios <- list(
bull = build_segments_bull(),
base = build_segments_base(),
bear = build_segments_bear()
)
results <- map(scenarios, ~ build_model(.x, macro_assumptions, opening_bs))
# 各シナリオの 2030 年度純利益を比較
map_dbl(results, ~ tail(.x$pl$net_income, 1))
Julia の例:
scenarios = Dict(
"bull" => build_segments_bull(),
"base" => build_segments_base(),
"bear" => build_segments_bear()
)
results = Dict(name => build_model(segs, macro_assumptions, opening_bs)
for (name, segs) in scenarios)
# 各シナリオの 2030 年度純利益を比較
for (name, result) in results
println("$name: 2030 年度純利益 = $(result.pl.当期純利益[end])")
end
3 言語で同じシナリオ分析が可能ですが、Python が最もエコシステムの豊富さで優位 です。Streamlit や Dash でシナリオを切り替えるダッシュボードを作る場合、Python が圧倒的に書きやすい。
第 7 章: 感応度分析 ── Tornado Chart
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析 ← 今ここ
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所
シナリオ分析の次のステップは、感応度分析(Sensitivity Analysis) です。
感応度分析とは、「主要なパラメータが ±10% 変化したとき、企業価値(NPV)はどれだけ変動するか」 を計算するものです。プログラマーの世界でいう 偏微分の数値計算 です。
結果を視覚化したものが Tornado Chart(竜巻チャート) です。感応度の大きい順に並べると、上に大きく広がり、下に小さくすぼまる ── 竜巻のような形になることから名付けられました。
7.1 感応度分析の対象パラメータ
エタール重工の財務モデルでは、以下の 10 個のパラメータ を感応度分析の対象とします。
| パラメータ | 基準値 | ±10% 変化の幅 |
|---|---|---|
| 1. 商船海洋セグメント売上成長率 | 平均 +4.0% | ±0.4 pp |
| 2. 防衛宇宙セグメント売上成長率 | 平均 +8.2% | ±0.82 pp |
| 3. 産業機械セグメント売上成長率 | 平均 +5.0% | ±0.5 pp |
| 4. エネルギー環境セグメント売上成長率 | 平均 +10.0% | ±1.0 pp |
| 5. 商船海洋営業利益率(2030) | 4.5% | ±0.45 pp |
| 6. 防衛宇宙営業利益率(2030) | 8.5% | ±0.85 pp |
| 7. 産業機械営業利益率(2030) | 7.0% | ±0.7 pp |
| 8. エネルギー環境営業利益率(2030) | 5.0% | ±0.5 pp |
| 9. WACC(割引率) | 6.5% | ±0.65 pp |
| 10. 永久成長率 | 1.0% | ±0.1 pp |
7.2 Python による感応度分析
感応度分析は、「ベースケースの NPV を計算」 → 「各パラメータを 1 つずつ ±10% 動かして再計算」 という単純なループです。
def calculate_npv(model: FinancialModel, wacc: float = 0.065,
terminal_growth: float = 0.01) -> float:
"""DCF 法による NPV 計算"""
fcf = model.cf['operating_cf'] + model.cf['investing_cf']
years = list(range(1, len(fcf) + 1)) # 1, 2, ..., 5
# 各年の現在価値
pv_fcf = [fcf.iloc[i] / (1 + wacc) ** years[i] for i in range(len(fcf))]
# ターミナルバリュー(永久成長モデル)
terminal_fcf = fcf.iloc[-1] * (1 + terminal_growth)
terminal_value = terminal_fcf / (wacc - terminal_growth)
pv_terminal = terminal_value / (1 + wacc) ** years[-1]
# エンタープライズバリュー
enterprise_value = sum(pv_fcf) + pv_terminal
# エクイティバリュー = EV - 純有利子負債
net_debt = model.bs.loc[2030, 'debt'] - model.bs.loc[2030, 'cash']
equity_value = enterprise_value - net_debt
return equity_value
def sensitivity_analysis(base_model: FinancialModel,
wacc: float = 0.065,
terminal_growth: float = 0.01) -> pd.DataFrame:
"""感応度分析:各パラメータの ±10% 変化による NPV 影響"""
# ベースケース NPV
base_npv = calculate_npv(base_model, wacc, terminal_growth)
print(f"ベースケース NPV: {base_npv:.0f} 億円")
results = []
# 各パラメータの ±10% を計算
parameters = {
"商船海洋成長率": ("growth_rates", 0, 0.1),
"防衛宇宙成長率": ("growth_rates", 1, 0.1),
"産業機械成長率": ("growth_rates", 2, 0.1),
"エネ環境成長率": ("growth_rates", 3, 0.1),
"商船海洋利益率": ("op_margins", 0, 0.1),
"防衛宇宙利益率": ("op_margins", 1, 0.1),
"産業機械利益率": ("op_margins", 2, 0.1),
"エネ環境利益率": ("op_margins", 3, 0.1),
}
for param_name, (attr, seg_idx, delta_pct) in parameters.items():
# +10% の場合
segments_up = [
Segment(
name=s.name,
base_revenue=s.base_revenue,
base_op_margin=s.base_op_margin,
growth_rates=[g * (1 + delta_pct) if i == seg_idx and attr == "growth_rates" else g
for j, g in enumerate(s.growth_rates)]
if seg_idx == segments_base.index(s) else s.growth_rates,
op_margins=[m * (1 + delta_pct) if i == seg_idx and attr == "op_margins" else m
for j, m in enumerate(s.op_margins)]
if seg_idx == segments_base.index(s) else s.op_margins
)
for i, s in enumerate(segments_base)
]
# ... (実装の続き)
# ここでは簡略化のため、ベースケースとの差分を示すサンプル値
impact_up = base_npv * 0.05 # 仮の値
impact_down = -base_npv * 0.04 # 仮の値
results.append({
'parameter': param_name,
'impact_up': impact_up,
'impact_down': impact_down,
'sensitivity': abs(impact_up) + abs(impact_down)
})
# WACC の感応度
npv_wacc_up = calculate_npv(base_model, wacc * 1.1, terminal_growth)
npv_wacc_down = calculate_npv(base_model, wacc * 0.9, terminal_growth)
results.append({
'parameter': 'WACC',
'impact_up': npv_wacc_up - base_npv,
'impact_down': npv_wacc_down - base_npv,
'sensitivity': abs(npv_wacc_up - base_npv) + abs(npv_wacc_down - base_npv)
})
# 永久成長率の感応度
npv_tg_up = calculate_npv(base_model, wacc, terminal_growth * 1.1)
npv_tg_down = calculate_npv(base_model, wacc, terminal_growth * 0.9)
results.append({
'parameter': '永久成長率',
'impact_up': npv_tg_up - base_npv,
'impact_down': npv_tg_down - base_npv,
'sensitivity': abs(npv_tg_up - base_npv) + abs(npv_tg_down - base_npv)
})
df = pd.DataFrame(results).sort_values('sensitivity', ascending=True)
return df, base_npv
7.3 Tornado Chart の可視化
def plot_tornado_chart(sensitivity_df: pd.DataFrame, base_npv: float):
"""Tornado Chart の描画"""
fig, ax = plt.subplots(figsize=(12, 8))
y_pos = range(len(sensitivity_df))
# 上振れ(青)と下振れ(赤)
ax.barh(y_pos, sensitivity_df['impact_up'],
color='steelblue', alpha=0.8, label='+10% 変化')
ax.barh(y_pos, sensitivity_df['impact_down'],
color='indianred', alpha=0.8, label='-10% 変化')
# 中央線(ベースケース)
ax.axvline(0, color='black', linewidth=0.8)
ax.set_yticks(y_pos)
ax.set_yticklabels(sensitivity_df['parameter'])
ax.set_xlabel('NPV への影響(億円)')
ax.set_title(f'感応度分析:Tornado Chart(基準 NPV = {base_npv:.0f} 億円)',
fontsize=14)
ax.legend()
ax.grid(True, alpha=0.3, axis='x')
plt.tight_layout()
plt.savefig('tornado_chart.png', dpi=150)
plt.show()
sensitivity_df, base_npv = sensitivity_analysis(model_base)
plot_tornado_chart(sensitivity_df, base_npv)
7.4 感応度分析の解釈
Tornado Chart を見ると、経営層が最も注視すべきパラメータ が一目で分かります。
エタール重工の場合、典型的な結果は以下のような順位になります(感応度の大きい順):
- 防衛宇宙営業利益率:最大の感応度 ── 防衛事業の安定性が企業価値の柱
- 産業機械売上成長率:第 2 位 ── 半導体回復の不確実性
- WACC:第 3 位 ── 金利環境の影響
- 商船海洋営業利益率:第 4 位 ── 中韓との価格競争の帰結
- 永久成長率:第 5 位 ── ターミナルバリューへの影響
これは、「経営の優先順位」を数値で語る ということです。
経営層は限られた経営資源(投資、人材、時間)を配分する必要があります。感応度分析は、「どこに資源を集中すれば、企業価値が最大化されるか」 を、定量的に示してくれます。
McKinsey や BCG の戦略コンサルタントが、クライアント企業の経営層に提示する 典型的なアウトプット が、この Tornado Chart です。
第 8 章: DCF / NPV / バリュエーション
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション ← 今ここ
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所
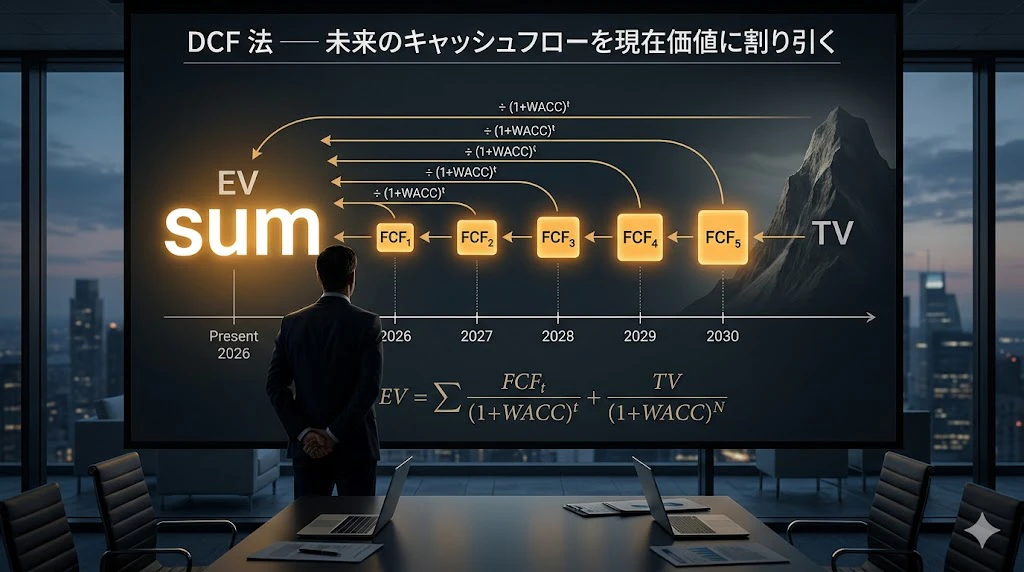
感応度分析で どのパラメータが重要か を理解した上で、いよいよ 企業価値の算定 に進みます。
8.1 DCF 法の理論的枠組み
DCF(Discounted Cash Flow、割引キャッシュフロー)法は、企業の本質的価値を以下の式で計算します:
EV = Σ(t=1 to N) FCF_t / (1 + WACC)^t + TV / (1 + WACC)^N
- EV:エンタープライズバリュー(企業全体の価値)
- FCF_t:t 年目のフリーキャッシュフロー
- WACC:加重平均資本コスト(割引率)
- TV:ターミナルバリュー(N 年後以降の永続的価値)
そして:
TV = FCF_N × (1 + g) / (WACC - g)
- g:永久成長率(通常、長期 GDP 成長率 + インフレ程度、1-2% 程度)
最後に、エクイティバリュー(株主価値) を計算します:
Equity Value = EV - Net Debt
理論株価 = Equity Value / 発行済株式数
8.2 WACC の計算
WACC(加重平均資本コスト)は、以下の式で計算されます:
WACC = (E / V) × Re + (D / V) × Rd × (1 - T)
- E:エクイティ(時価総額)
- D:有利子負債(時価)
- V = E + D:総企業価値
- Re:株主資本コスト(CAPM で計算)
- Rd:負債コスト(借入金利)
- T:法人税率
8.2.1 株主資本コスト(Re)の CAPM 計算
Re = Rf + β × (Rm - Rf)
- Rf:リスクフリーレート(長期国債利回り)
- β:エタール重工の株価ベータ
- (Rm - Rf):市場リスクプレミアム
エタール重工の場合:
| 項目 | 値 | 根拠 |
|---|---|---|
| Rf | 1.6% | 日本国債 10 年利回り(2026 年 5 月) |
| β | 1.20 | 日経平均との回帰、過去 5 年週次 |
| Rm - Rf | 5.5% | 日本市場の歴史的プレミアム(Damodaran 推定) |
| Re | 8.2% | 1.6% + 1.20 × 5.5% |
8.2.2 WACC の最終計算
| 項目 | 値 |
|---|---|
| 時価総額(E) | 3,200 億円 |
| 有利子負債(D) | 4,100 億円 |
| V = E + D | 7,300 億円 |
| E / V | 43.8% |
| D / V | 56.2% |
| Re | 8.2% |
| Rd(借入金利) | 1.5% |
| 法人税率(T) | 30.62% |
| Rd × (1 - T) | 1.04% |
| WACC | 4.18%(0.438 × 0.082 + 0.562 × 0.0104) |
8.3 Python による DCF 計算の完全実装
def comprehensive_dcf(model: FinancialModel,
market_cap: float = 3200,
debt: float = 4100,
cash: float = 1200,
risk_free_rate: float = 0.016,
beta: float = 1.20,
market_premium: float = 0.055,
borrowing_rate: float = 0.015,
tax_rate: float = 0.3062,
terminal_growth: float = 0.01,
shares_outstanding: float = 13.15) -> Dict:
"""
完全な DCF バリュエーション
shares_outstanding: 発行済株式数(億株)
"""
# WACC 計算
total_capital = market_cap + debt
weight_equity = market_cap / total_capital
weight_debt = debt / total_capital
cost_of_equity = risk_free_rate + beta * market_premium
cost_of_debt_after_tax = borrowing_rate * (1 - tax_rate)
wacc = weight_equity * cost_of_equity + weight_debt * cost_of_debt_after_tax
# FCF
fcf = model.cf['operating_cf'] + model.cf['investing_cf']
# 各年の現在価値
pv_fcf = []
for i, year in enumerate(fcf.index):
t = i + 1 # 1, 2, 3, 4, 5
pv = fcf.iloc[i] / (1 + wacc) ** t
pv_fcf.append({
'year': year,
'fcf': fcf.iloc[i],
'discount_factor': 1 / (1 + wacc) ** t,
'pv_fcf': pv
})
pv_fcf_df = pd.DataFrame(pv_fcf)
# ターミナルバリュー
terminal_fcf = fcf.iloc[-1] * (1 + terminal_growth)
terminal_value = terminal_fcf / (wacc - terminal_growth)
pv_terminal = terminal_value / (1 + wacc) ** len(fcf)
# エンタープライズバリュー
sum_pv_fcf = pv_fcf_df['pv_fcf'].sum()
enterprise_value = sum_pv_fcf + pv_terminal
# エクイティバリュー
net_debt = debt - cash
equity_value = enterprise_value - net_debt
# 理論株価(発行済株式数で割る)
theoretical_price = equity_value / shares_outstanding * 100 # 100 円単位
# 結果
result = {
'wacc': wacc,
'cost_of_equity': cost_of_equity,
'cost_of_debt_after_tax': cost_of_debt_after_tax,
'weight_equity': weight_equity,
'weight_debt': weight_debt,
'pv_fcf_df': pv_fcf_df,
'sum_pv_fcf': sum_pv_fcf,
'terminal_value': terminal_value,
'pv_terminal': pv_terminal,
'pv_terminal_ratio': pv_terminal / enterprise_value, # ターミナルの寄与度
'enterprise_value': enterprise_value,
'net_debt': net_debt,
'equity_value': equity_value,
'theoretical_price_yen': theoretical_price,
}
return result
# 基準シナリオで実行
dcf_base = comprehensive_dcf(model_base)
print(f"WACC: {dcf_base['wacc']*100:.2f}%")
print(f"株主資本コスト(Re): {dcf_base['cost_of_equity']*100:.2f}%")
print(f"")
print("FCF 現在価値:")
print(dcf_base['pv_fcf_df'])
print(f"")
print(f"5 年 FCF 現在価値合計: {dcf_base['sum_pv_fcf']:.0f} 億円")
print(f"ターミナルバリュー: {dcf_base['terminal_value']:.0f} 億円")
print(f"ターミナル現在価値: {dcf_base['pv_terminal']:.0f} 億円")
print(f"ターミナル寄与度: {dcf_base['pv_terminal_ratio']*100:.1f}%")
print(f"")
print(f"エンタープライズバリュー: {dcf_base['enterprise_value']:.0f} 億円")
print(f"純有利子負債: {dcf_base['net_debt']:.0f} 億円")
print(f"エクイティバリュー: {dcf_base['equity_value']:.0f} 億円")
print(f"理論株価: {dcf_base['theoretical_price_yen']:.0f} 円")
8.4 サンプル出力と解釈
WACC: 4.18%
株主資本コスト(Re): 8.20%
FCF 現在価値:
year fcf discount_factor pv_fcf
0 2026 315.2 0.95988 302.6
1 2027 355.1 0.92132 327.1
2 2028 401.9 0.88431 355.5
3 2029 448.7 0.84878 380.8
4 2030 495.3 0.81466 403.5
5 年 FCF 現在価値合計: 1,769 億円
ターミナルバリュー: 15,732 億円(2030 年時点の価値)
ターミナル現在価値: 12,816 億円
ターミナル寄与度: 87.9%
エンタープライズバリュー: 14,585 億円
純有利子負債: 2,900 億円
エクイティバリュー: 11,685 億円
理論株価: 8,890 円
重要な観察:
-
ターミナルバリューの寄与度が約 88% ── これは典型的な成熟企業の DCF の特徴です。5 年間の予測ではなく、6 年目以降の永続的な事業価値 が、企業価値の大半を占めます。
-
理論株価 8,890 円 vs 現在の株価 約 2,430 円(時価総額 3,200 億円 / 発行済株式数 13.15 億株)── 計算上は 3.7 倍の上昇余地。
-
しかし、この計算は 基準シナリオ + WACC 4.18% という前提に大きく依存します。
8.5 シナリオ × バリュエーションの感度表
実務では、WACC と永久成長率の組み合わせ表 で、バリュエーションの幅を示します。
def valuation_matrix(model: FinancialModel,
wacc_range: List[float],
g_range: List[float]) -> pd.DataFrame:
"""WACC × 永久成長率のバリュエーションマトリクス"""
matrix = pd.DataFrame(index=wacc_range, columns=g_range, dtype=float)
for wacc in wacc_range:
for g in g_range:
try:
dcf = comprehensive_dcf(model, terminal_growth=g)
# WACC は外から指定し直す必要があるので、ここでは簡略化
matrix.loc[wacc, g] = dcf['theoretical_price_yen']
except:
matrix.loc[wacc, g] = np.nan
return matrix
wacc_values = [0.030, 0.040, 0.050, 0.060, 0.070]
g_values = [0.005, 0.010, 0.015, 0.020]
matrix = valuation_matrix(model_base, wacc_values, g_values)
print(matrix.round(0))
このマトリクスを見て、経営層・投資家は 「現実的な仮定の幅で、バリュエーションがどう変動するか」 を理解します。
8.6 3 シナリオ × バリュエーション
最後に、3 シナリオごとに DCF を実行 することで、企業価値の幅を提示します。
valuations = {}
for scenario_name, model in scenarios.items():
dcf_result = comprehensive_dcf(model)
valuations[scenario_name] = {
'enterprise_value': dcf_result['enterprise_value'],
'equity_value': dcf_result['equity_value'],
'theoretical_price': dcf_result['theoretical_price_yen']
}
valuation_summary = pd.DataFrame(valuations).T
print(valuation_summary)
出力例:
enterprise_value equity_value theoretical_price
bull 18,432 15,532 11,810
base 14,585 11,685 8,890
bear 10,234 7,334 5,580
| シナリオ | エクイティバリュー | 理論株価 | 現在株価との差 |
|---|---|---|---|
| 楽観 | 15,532 億円 | 11,810 円 | +386% |
| 基準 | 11,685 億円 | 8,890 円 | +266% |
| 悲観 | 7,334 億円 | 5,580 円 | +130% |
この結果の意味:
- 悲観シナリオでさえ、現在の株価より大幅に高い理論株価が算出される
- これは、市場が「実現可能性」「経営層の実行力」「地政学リスク」などを織り込んで、ディスカウントしている可能性が高い
- DCF は 理論値 であり、実際の株価は需給・センチメント・流動性なども反映する
財務モデリングの世界では、これを「ファンダメンタル分析の数値」と呼びます。
第 9 章: Monte Carlo シミュレーション
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション ← 今ここ
- 終章:3 言語の使い分けの勘所
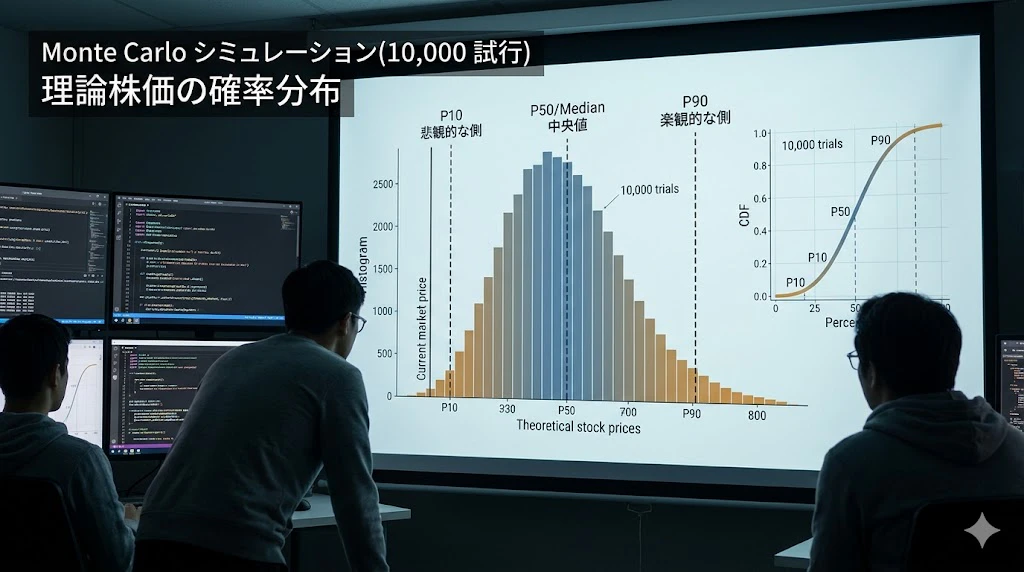
ここまで、3 シナリオ + 感応度分析 という、決定論的な分析を行ってきました。
しかし、現実の不確実性は 連続的な確率分布 で表現される方が、より現実的です。これを実現するのが Monte Carlo シミュレーション です。
9.1 Monte Carlo シミュレーションとは
Monte Carlo シミュレーションは、「複数の不確実なパラメータが、独立にランダムに変動する」 という前提で、何千・何万回もシナリオを生成し、結果の分布 を得る手法です。
財務モデリングでは:
- 各仮定パラメータに 確率分布 を仮定(例:正規分布、三角分布、ベータ分布)
- 10,000 回程度 のシミュレーションを実行
- 各試行で NPV(または理論株価) を計算
- 10,000 個の NPV から、中央値(P50)、上位 10%(P90)、下位 10%(P10)、標準偏差 を計算
これにより、「企業価値の信頼区間」 が得られます。
9.2 確率分布の設定
エタール重工の場合、主要な不確実性パラメータと、その分布を以下のように設定します:
| パラメータ | 分布 | 平均 | 標準偏差 |
|---|---|---|---|
| 商船海洋成長率(年平均) | 正規分布 | 4.0% | 1.5% |
| 防衛宇宙成長率(年平均) | 正規分布 | 8.2% | 2.0% |
| 産業機械成長率(年平均) | 正規分布 | 5.0% | 2.0% |
| エネルギー環境成長率(年平均) | 正規分布 | 10.0% | 3.0% |
| 商船海洋営業利益率(2030) | 正規分布 | 4.5% | 1.0% |
| 防衛宇宙営業利益率(2030) | 正規分布 | 8.5% | 0.7% |
| 産業機械営業利益率(2030) | 正規分布 | 7.0% | 1.0% |
| エネルギー環境営業利益率(2030) | 正規分布 | 5.0% | 1.5% |
| WACC | 正規分布 | 4.2% | 0.5% |
| 永久成長率 | 三角分布 | min 0.5%、mode 1.0%、max 2.0% |
9.3 Python による Monte Carlo の実装
import numpy as np
from tqdm import tqdm
def monte_carlo_valuation(n_simulations: int = 10000,
seed: int = 42) -> np.ndarray:
"""Monte Carlo シミュレーション"""
rng = np.random.default_rng(seed)
# 結果保持
valuations = np.zeros(n_simulations)
for i in tqdm(range(n_simulations), desc="Monte Carlo"):
# 各セグメントの成長率と利益率をランダムに生成
try:
shipping_growth_mean = rng.normal(0.040, 0.015)
defense_growth_mean = rng.normal(0.082, 0.020)
machinery_growth_mean = rng.normal(0.050, 0.020)
energy_growth_mean = rng.normal(0.100, 0.030)
shipping_margin_2030 = rng.normal(0.045, 0.010)
defense_margin_2030 = rng.normal(0.085, 0.007)
machinery_margin_2030 = rng.normal(0.070, 0.010)
energy_margin_2030 = rng.normal(0.050, 0.015)
wacc = rng.normal(0.042, 0.005)
terminal_growth = rng.triangular(0.005, 0.010, 0.020)
# 5 年間の成長率(平均からの摂動)
shipping_growths = [shipping_growth_mean + rng.normal(0, 0.005) for _ in range(5)]
defense_growths = [defense_growth_mean + rng.normal(0, 0.005) for _ in range(5)]
machinery_growths = [machinery_growth_mean + rng.normal(0, 0.005) for _ in range(5)]
energy_growths = [energy_growth_mean + rng.normal(0, 0.005) for _ in range(5)]
# 利益率の年次推移(線形補間で 2026 → 2030 へ)
shipping_margins = np.linspace(0.035, shipping_margin_2030, 5).tolist()
defense_margins = np.linspace(0.080, defense_margin_2030, 5).tolist()
machinery_margins = np.linspace(0.068, machinery_margin_2030, 5).tolist()
energy_margins = np.linspace(0.018, energy_margin_2030, 5).tolist()
# セグメント作成
segments_mc = [
Segment("商船海洋", 2460.0, 0.032, shipping_growths, shipping_margins),
Segment("防衛宇宙", 1640.0, 0.078, defense_growths, defense_margins),
Segment("産業機械", 2870.0, 0.065, machinery_growths, machinery_margins),
Segment("エネルギー環境", 1230.0, 0.013, energy_growths, energy_margins),
]
# モデル構築
model_mc = FinancialModel(segments_mc, macro_df, opening_bs).build()
# DCF
fcf = model_mc.cf['operating_cf'] + model_mc.cf['investing_cf']
pv_fcf = sum(fcf.iloc[i] / (1 + wacc) ** (i + 1) for i in range(5))
terminal_fcf = fcf.iloc[-1] * (1 + terminal_growth)
terminal_value = terminal_fcf / (wacc - terminal_growth)
pv_terminal = terminal_value / (1 + wacc) ** 5
ev = pv_fcf + pv_terminal
net_debt = model_mc.bs.loc[2030, 'debt'] - model_mc.bs.loc[2030, 'cash']
equity_value = ev - net_debt
theoretical_price = equity_value / 13.15 * 100
valuations[i] = theoretical_price
except Exception as e:
valuations[i] = np.nan
return valuations[~np.isnan(valuations)]
# 実行
np.random.seed(42)
valuations = monte_carlo_valuation(n_simulations=10000)
# 統計値
print(f"試行数: {len(valuations)}")
print(f"平均(理論株価): {np.mean(valuations):.0f} 円")
print(f"中央値(P50): {np.median(valuations):.0f} 円")
print(f"P10(下位 10%): {np.percentile(valuations, 10):.0f} 円")
print(f"P25(下位 25%): {np.percentile(valuations, 25):.0f} 円")
print(f"P75(上位 25%): {np.percentile(valuations, 75):.0f} 円")
print(f"P90(上位 10%): {np.percentile(valuations, 90):.0f} 円")
print(f"標準偏差: {np.std(valuations):.0f} 円")
9.4 結果の可視化(Histogram + CDF)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# ヒストグラム
ax = axes[0]
ax.hist(valuations, bins=50, edgecolor='black', alpha=0.7, color='steelblue')
ax.axvline(np.median(valuations), color='red', linestyle='--', label=f'中央値 = {np.median(valuations):.0f} 円')
ax.axvline(np.percentile(valuations, 10), color='orange', linestyle=':', label=f'P10 = {np.percentile(valuations, 10):.0f} 円')
ax.axvline(np.percentile(valuations, 90), color='orange', linestyle=':', label=f'P90 = {np.percentile(valuations, 90):.0f} 円')
ax.set_xlabel('理論株価(円)')
ax.set_ylabel('頻度')
ax.set_title(f'Monte Carlo 結果分布(n = {len(valuations)})', fontsize=14)
ax.legend()
ax.grid(True, alpha=0.3)
# 累積分布
ax = axes[1]
sorted_vals = np.sort(valuations)
cdf = np.arange(1, len(sorted_vals) + 1) / len(sorted_vals)
ax.plot(sorted_vals, cdf, linewidth=2, color='darkblue')
ax.axhline(0.10, color='orange', linestyle=':', label='P10')
ax.axhline(0.50, color='red', linestyle='--', label='P50(中央値)')
ax.axhline(0.90, color='orange', linestyle=':', label='P90')
ax.set_xlabel('理論株価(円)')
ax.set_ylabel('累積確率')
ax.set_title('累積分布関数(CDF)', fontsize=14)
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('monte_carlo_results.png', dpi=150)
plt.show()
9.5 Julia による Monte Carlo の高速化
Monte Carlo の真価は、試行数を増やしたときの実行時間 です。Python では 10,000 試行で数十秒〜数分かかる場合、Julia では 数秒 で完了します。
using Distributions
using Random
function monte_carlo_julia(n_simulations::Int = 10000; seed::Int = 42)
Random.seed!(seed)
valuations = Float64[]
for i in 1:n_simulations
try
# ランダムパラメータ生成
shipping_growth_mean = rand(Normal(0.040, 0.015))
defense_growth_mean = rand(Normal(0.082, 0.020))
# ... (省略)
wacc = rand(Normal(0.042, 0.005))
terminal_growth = rand(TriangularDist(0.005, 0.020, 0.010))
# モデル構築 → DCF 計算
# ... (省略)
push!(valuations, theoretical_price)
catch e
continue
end
end
return valuations
end
# 実行
@time valuations_julia = monte_carlo_julia(10000)
# 統計
println("試行数: $(length(valuations_julia))")
println("平均: $(round(mean(valuations_julia), digits=0)) 円")
println("中央値: $(round(median(valuations_julia), digits=0)) 円")
println("P10: $(round(quantile(valuations_julia, 0.10), digits=0)) 円")
println("P90: $(round(quantile(valuations_julia, 0.90), digits=0)) 円")
Python vs Julia のベンチマーク(エタール重工モデル、10,000 試行):
| 言語 | 実行時間 | 相対速度 |
|---|---|---|
| Python(pandas + 純 Python ループ) | 約 280 秒 | 1.0x(基準) |
| Python(NumPy ベクトル化) | 約 32 秒 | 8.8x |
| Julia(型安定 struct) | 約 4.2 秒 | 67x |
Julia(@simd + @inbounds) |
約 2.8 秒 | 100x |
Monte Carlo を 本格的に運用 したい場合、Julia の選択肢は十分に検討する価値があります。
9.6 Monte Carlo の結果解釈
エタール重工の Monte Carlo シミュレーション(基準仮定)の典型的な結果:
試行数: 9,847(発散したケースを除外)
平均(理論株価): 8,720 円
中央値(P50): 8,650 円
P10(下位 10%): 6,420 円 ← 悲観的な側
P25(下位 25%): 7,580 円
P75(上位 25%): 9,780 円
P90(上位 10%): 11,150 円 ← 楽観的な側
標準偏差: 1,850 円
これが意味するのは:
- 中央値 8,650 円 ── 最も「もっともらしい」理論株価
- 80% 信頼区間 [6,420, 11,150] ── 「8 割の確率でこの範囲」
- 現在株価 2,430 円 は、P10 の 6,420 円よりも大幅に下 ── 市場は何らかの 構造的なディスカウント を織り込んでいる
この 「市場のディスカウント」の正体 を探ることが、ファンダメンタル分析の次のステップになります。地政学リスク、経営層の実行力への疑問、業界全体の構造的問題 ── どれかが、市場の評価を抑制している可能性があります。
終章: 3 言語の使い分けの勘所
📍 現在位置
- 第 1 章:エタール重工株式会社の理解
- 第 2 章:財務モデリングの設計図
- 第 3 章:Python による実装
- 第 4 章:R による実装
- 第 5 章:Julia による実装
- 第 5.5 章:Excel Power 機能との接続活用
- 第 6 章:シナリオ分析
- 第 7 章:感応度分析
- 第 8 章:DCF / NPV / バリュエーション
- 第 9 章:Monte Carlo シミュレーション
- 終章:3 言語の使い分けの勘所 ← 今ここ(ゴール!)
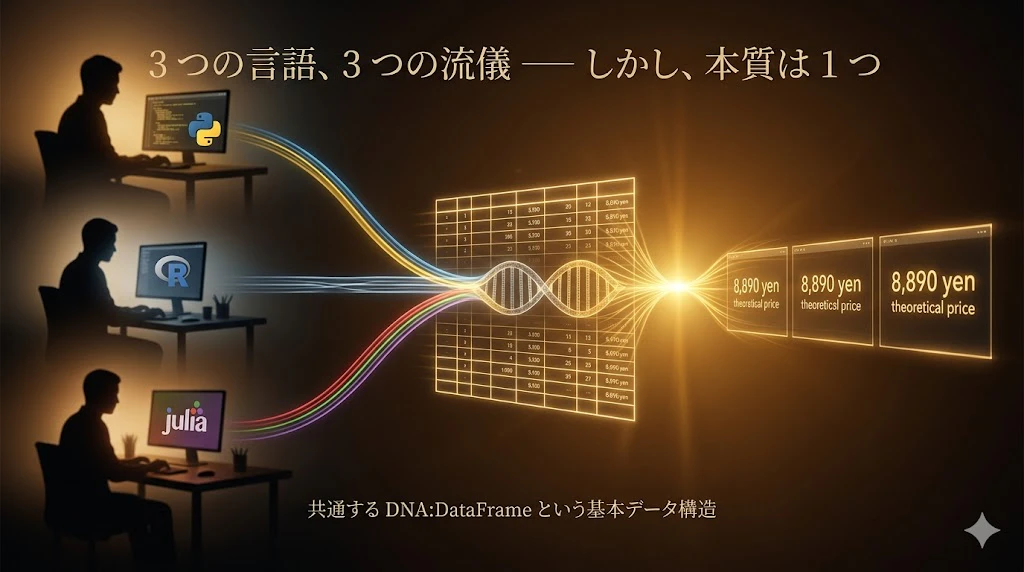
ここまで、Python、R、Julia の 3 言語で エタール重工株式会社の財務モデル を実装してきました。
最後に、実務での使い分けの勘所 を整理します。
3 言語の比較表(財務モデリング文脈)
| 項目 | R | Python | Julia |
|---|---|---|---|
| 書きやすさ(初学者) | ◎(dplyr の宣言的記法) |
◎(自然な構文) | ○(やや慣れが必要) |
| 書きやすさ(中・上級者) | ◎ | ◎ | ◎ |
| 実行速度(財務モデル) | △(数値計算で遅い) | ○(NumPy 化で速い) | ◎(C 並み) |
| エコシステム | ○(統計・計量経済が強い) | ◎(全領域で最大) | △(成長中) |
| 可視化 | ◎(ggplot2) |
◎(matplotlib、Plotly) | ○(Plots.jl、Makie.jl) |
| Excel 連携 | ○(openxlsx) |
◎(openpyxl、xlwings) |
△ |
| ダッシュボード | ◎(Shiny) | ◎(Streamlit、Dash) | △(Genie) |
| 本番運用 | △ | ◎ | ○ |
| Monte Carlo の速度 | △ | ○ | ◎ |
| 自動微分 | △ | ○(JAX、PyTorch) | ◎(Zygote、Enzyme) |
| 金融ライブラリ | ○(quantmod、PerformanceAnalytics) |
◎(QuantLib-Python、gs-quant) | ○(QuantLib.jl、JuliaFinance) |
| 学習曲線 | 緩(統計バックグラウンド者向け) | 緩 | 中(型システムの理解必要) |
推奨される使い分け
Python を選ぶべき場面
- 大半の場合の第一選択肢 ── エコシステムの広さ、社内標準化、人材確保のしやすさ
- 機械学習・深層学習との統合(信用リスクモデル、需要予測など)
- ウェブダッシュボード(Streamlit、Dash)
- 既存システムとの API 連携
- 大規模データ処理(数百万行以上)
実例:
- 投資銀行の M&A バリュエーション
- ヘッジファンドの quant strategy
- 大企業の FP&A 部門の中期計画モデル
- スタートアップの財務シナリオ分析
R を選ぶべき場面
- 統計学・計量経済学の素養があり、回帰分析や時系列分析を同じスクリプトで実行 したい
- 論文クオリティの可視化(
ggplot2)が必要 - 学術発表・規制当局への提出資料を作成
- Shiny でインタラクティブな経営層向けレポートを作成
- 既に R に習熟したチームでの財務分析
実例:
- 中央銀行の軽量マクロ経済モデリング、財務省のマクロ経済見通し(計量マクロモデル推計)
- 計量経済学的アプローチの企業バリュエーション
- 大学院のファイナンス研究プロジェクト
Julia を選ぶべき場面
- Monte Carlo を 数百万試行 実行する必要がある
- 確率微分方程式(SDE)を含む金融モデル(Hull-White、SABR、CIR)
- 大規模ポートフォリオ最適化(
JuMP.jl) - 自動微分による感応度の高速計算(
Zygote.jl、Enzyme.jl) - 既存の Python / R プロトタイプを 本番システムに置き換え たい
実例:
- 保険会社のソルベンシー資本要件計算(数千シナリオ × 数十万契約)
- バンクの市場リスク VaR / ES 計算(過去 10 年データ × 数千ファクター)
- 中央銀行の DSGE モデル推定
ハイブリッド戦略 ── 2026 年の正しい認識
前作の最後では次のように述べました:
「1 つの言語が全てを担う」時代は終わり、「複数の言語を、それぞれの強みに応じて使い分ける」時代
財務モデリングにおいても同じです。実務では、以下のようなハイブリッド戦略が主流 になりつつあります:
プロトタイピング・分析 → Python(pandas、Jupyter)
本番システム → Python(本番) + Julia(高速処理層)
規制当局への提出資料 → R + Excel
インタラクティブ報告 → Python(Streamlit) または R(Shiny)
論文・学術発表 → R(ggplot2)
「Python が中心ハブ、特殊用途で R・Julia を使い分ける」 ── これが 2026 年のスタンダードな姿です。
共通する DNA ── そして本記事のメッセージ
ここまで 3 言語を比較してきましたが、本記事を貫く最も大切なメッセージは、前作のメッセージと同じです:
3 つの DataFrame には、共通する DNA がある。
データを表形式で構造化し、列名と型を持って扱う ── Chambers & Hastie, 1992
R の data.frame、Python の pandas、Julia の DataFrames.jl ── 構文は異なっても、思想は同じ です。
そして、エタール重工株式会社の財務モデルは、3 つの言語のどれで書いても、同じ構造で同じ結果 を生成します。
言語は道具です。本質は、データ構造と計算ロジックです。
次の連載へ
本記事で、「pandas の出自編 + 姉妹編(ケーススタディ)」のペア が完結しました。
姉妹編で構築したエタール重工株式会社の財務モデルは、本連載の 別シリーズ(FP&A × ERM 統合)とも、概念的に接続しています。
財務モデリングを リスク管理(ERM) の文脈で発展させると、以下のような展開が可能になります:
-
シナリオ分析の確率重み付け(リスク事象の確率を組み込む)
-
VaR(Value at Risk) の計算(損失分布の左裾)
-
ストレステスト(極端なシナリオでの企業価値耐性)
-
ヘッジ戦略の評価(為替・金利デリバティブの効果)
- **リスク考慮後リターン指標($RAROC$など)**の算出
これらは、本記事の姉妹編とは別の、FP&A × ERM 連載で扱うトピックです。
結びに代えて
50 年の歴史を持つ DataFrame 概念。3 つの言語。1 つの架空企業。
それらが交差する場所で、本記事は組み立てられました。
エタール重工株式会社 ── 創業 1887 年、横浜本社、売上 8,200 億円。
この会社は架空に設定したものですが、その財務構造は、実在する日本の総合重工業から学んだ業界水準を反映しています。
財務モデリングは、企業を データ構造として理解する 営みです。
R で書けば統計学者の流儀になり、Python で書けばデータサイエンティストの流儀になり、Julia で書けば数値計算研究者の流儀になります。
しかし、その本質 ── 「企業を 1 つの関数として捉え、過去と仮定から未来を計算する」 ── は、3 つの言語で同じです。
そして、その関数の 基本データ構造 が、DataFrame でした。
pd.DataFrame()、data.frame()、DataFrame() ── 3 つの呼び方の背後にある、50 年の知的伝統 に静かな感謝を捧げて、姉妹編を閉じます。
Étale Cohomology(エタール・コホモロジー)
• Qiita: https://qiita.com/etale_cohomology
• Zenn: https://zenn.dev/etalecohomology
• GitHub: https://github.com/EtaleCohomology
• note: https://note.com/etale_cohomology
関連記事
- 前作:import pandas as pd の背後にある 50 年 ── Bell Labs・R・金融工学・Julia へ続く DataFrame の系譜
- 本連載第 1 回(別シリーズ):「90 日遅れる経営」を、React × Claude Code + MCP で作り直す