(サブタイトル)
Pandas の出自、来歴、皆さん知っていますか? 〜みんなが知らない財務モデリングとの関係性〜
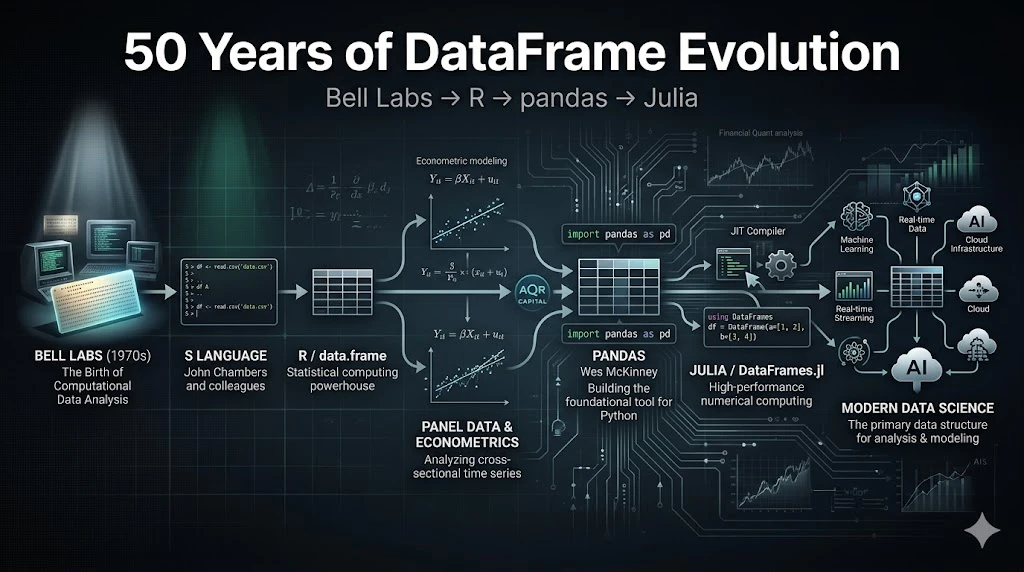
この記事について(3 分でわかる全体像)
想定読者
本記事は、以下のような皆様を想定して書きました。
-
pandas を日常的に使うデータサイエンティスト・BI エンジニア・機械学習エンジニア:
自分の道具のルーツを知りたい方
-
R や Julia を使う統計学者・計量経済学者・科学計算研究者:
3言語の系譜を一望してみたい方
-
金融業界のエンジニア・クオンツ・FP&A 担当者:
Python・R・Julia のどれを業務に取り入れるか迷っている方 -
言語設計に関心のあるソフトウェアエンジニア:
データ分析言語の進化の本流を、ひとつの物語として理解したい方
-
これからデータ分析を学ぶ学生・新人エンジニア:
「自分が今いる時代がどんな歴史的位置にあるのか」を掴みたい方
なお、本記事は 簿記・会計・コーポレートファイナンスの知識を一切前提としていません。財務モデリングの概念は、プログラマーの言葉で噛み砕いて解説します。

読むと得られるもの
本記事を通読することで、以下が得られます。
-
pandas の出自に関する正確な事実:
2008 年 4 月 6 日に AQR Capital で誕生した、その背景と動機
-
R の
data.frameと Julia のDataFrames.jlとの系譜関係:
1976 年 Bell Labs から 2026 年まで続く 50 年の旅
-
Scheme から R が受け継いだ lexical scoping:
なぜ R は「予測可能」な言語なのか、コード例で理解
-
金融業界の言語哲学の対比:
AQR(Python 実用主義) vs Jane Street(OCaml 厳密主義) vs Tsuru Capital(Haskell 厳密主義)
-
F# と「Python のエルゴノミクス + 関数型の厳密性」の探求の現在地:F# は過去の言語か?Mojo・Roc・Gleam・Scala 3 はどこまで来たか?
-
LLM 時代に関数型・宣言型の価値はどう変化するか:Google の AI 生成コード 25%、2026 年 ACM FSE 論文、Wes McKinney の最新発言
-
財務モデリングの概念的イメージ(プログラマー向け):
3表連動モデルを「計算 DAG」として理解
-
企業が実際に公開している財務系コードの GitHub URL 一覧:
Goldman Sachs gs-quant、JPMorgan python-training、JuliaFinance、QuantLib.jl、hledger、r-ledger 等
記事の全体イメージ
本記事は、以下の構造で展開します。
第 1 章: 1976 年、Bell Labs ── すべての始まり
└── S 言語、`data frame` 概念、R の誕生、Scheme と lexical scoping
第 2 章: 2008 年、AQR Capital ── Python へのパス
└── Wes McKinney、pandas 誕生、「panel data」の由来、AQR の決断
第 3 章: 2012 年、JuliaStats ── 3 つ目の系譜
└── Julia 言語、DataFrames.jl、julia-dev での歴史的な対話
第 4 章: 3 つの DataFrame は何が同じで、何が違うのか
└── 共通する DNA、3 言語のコード比較
第 5 章: そして、財務モデリングとの関係性
└── 財務モデリングとは何か(プログラマー向け概念解説)
└── 3 言語の財務系公開コード GitHub URL 一覧
└── 大企業の Python 採用事例(JPMorgan、Bank of America、Citigroup)
└── 関数型クオンツの世界(Jane Street、Tsuru Capital、Standard Chartered)
└── Python・Julia の使いやすさと関数型の厳密性を両立する言語の現在
└── AI/LLM 時代の関数型・宣言型プログラミングの価値
終章: 2026 年の今、3 つの DataFrame に支払うべき敬意
└── 3 世代の継承者、`pd.DataFrame()` の背後にある 50 年

読了の目安は、ゆっくり読んで 25〜35 分。電車での通勤・通学時間が、1976 年から 2026 年までの 50 年を旅する時間に変わるはずです。
はじめに
import pandas as pdこの 1 行の背後には、50 年にわたる技術と言語設計の歴史があります。
Bell Labs の S 言語、R の
data.frame、計量経済学のpanel data、クオンツヘッジファンド AQR Capital、そして Julia のDataFrames.jl。pandas は単なる Python ライブラリではありません。
それは、
- 統計学
- 金融工学
- 財務モデリング
- プログラミング言語設計
- データ分析文化
が交差する場所から生まれた、「DataFrame」という概念の継承者です。
本記事では、
import pandas as pdの背後にある、1976 年から 2026 年までの 50 年を辿ります。
import pandas as pd
このコードを、皆さんは何度書いたでしょうか。
データサイエンティスト、BI エンジニア、機械学習エンジニア、データアナリスト ── pandas は、皆様の日々の仕事において、最も身近な道具の 1 つです。
2026 年現在、pandas の月間ダウンロード数は 4,000 万件 を超え、Netflix、JPMorgan Chase、NASA をはじめとする世界中の組織で使われています。
ところが、その ルーツ を語れる方は、意外と少ないのではないでしょうか。
- pandas は、いつ、どこで、誰が、なぜ作ったのか
- pandas という名前は、何に由来しているのか
- R の
data.frameや Julia のDataFrames.jlと、どんな関係にあるのか
本記事では、pandas の出自と、そのルーツが 財務モデリング という意外な領域にあったこと、そして R と Julia を含めた 3 つの DataFrame の 50 年の系譜 を辿ります。
本記事の射程
本記事で辿る系譜は、以下の通りです。
timeline
title DataFrame 概念の 50 年の系譜
section 第一世代:R の系譜 (1976-2000)
1976 : S 言語の誕生
: Bell Labs, John Chambers
1992 : data frame 概念の正式確立
: Chambers & Hastie 白本
1992 : R 言語の開発開始
: Auckland 大学
2000 : R 1.0.0 リリース
section 第二世代:pandas の系譜 (2008-2009)
2008 : pandas 開発開始
: AQR Capital, Wes McKinney
2009 : pandas オープンソース化
section 第三世代:Julia の系譜 (2012-2021)
2012 : Julia 言語と DataFrames.jl 誕生
2021 : DataFrames.jl 1.0 リリース
section 現在 (2026)
2026 : pandas 月間 4,000 万ダウンロード
: LLM 時代

3 つの DataFrame ── R の data.frame、Python の pandas、Julia の DataFrames.jl ── は、それぞれ独立に作られたものではありません。1 本の系譜でつながっています。
そして、その系譜の 2 つの結節点が、財務分析(財務モデリング)の現場 にあった ── これが、本記事を貫くテーマです。

第 1 章: 1976 年、Bell Labs ── すべての始まり
John Chambers と S 言語
データ分析言語の系譜は、1976 年に始まります。
舞台は、米国ニュージャージー州の Bell Labs(現 Nokia Bell Labs)。当時、AT&T Corp. の傘下にあったこの研究所で、統計学者 John Chambers と同僚たちは、ある問題に直面していました。
「統計分析のアルゴリズムは Fortran のサブルーチンとして実装されているが、それを使うためには、毎回 Fortran のメインプログラムを書き、ジョブ制御言語(JCL)で投入し、結果を待たなければならない。これは、データ分析の仕事として煩雑すぎる」
そこで彼らは、Fortran のサブルーチンを簡潔な構文でラップする言語 を作ることにしました。これが S 言語 です。
「S」という 1 文字の名前は、AT&T Bell Labs の伝統(C 言語、AWK、Yacc など、簡潔な名前を好む文化)を反映しています。
data frame 概念の誕生
S 言語は、1988 年に C 言語で完全に書き直され、現代的な姿を取り始めます(Version 3)。
そして、決定的な瞬間が訪れます。
1992 年、John Chambers と Trevor Hastie の共著 Statistical Models in S(通称「白本」)が出版され、その 第 3 章 で、ある概念が正式に確立されました。
A data frame represents a set of n values for p observable variables, the classical form of scientific data.
(データフレームは、p 個の観測変数について n 個の値を表現する、科学データの古典的な形式である)
これが、現代のすべての DataFrame の出発点 です。
R の data.frame、Python の pandas.DataFrame、Julia の DataFrame ── すべてはこの 1992 年の白本に遡ります。
S 言語は AT&T の社内言語にとどまらなかった
ここで、ひとつ気になる疑問があります。
「S 言語は AT&T Bell Labs の内部言語だったのなら、外部の人はどうやって使ったのか?」
実は、S 言語は 早い段階から Bell Labs の外に出ていました。
- 1980 年:S の最初のバージョンが Bell Labs の 外部に配布 され始める
- 1981 年:ソースコードが入手可能になり、学術界に無償で広く配布 される
- 1984 年:AT&T Software Sales が S のソースコードを商用ライセンスとして販売開始(教育・商用目的)
- 1984 年:Becker & Chambers 著 S: An Interactive Environment for Data Analysis and Graphics(通称「ブラウンブック」)出版
- 1988 年:Doug Martin(ワシントン大学統計学教授)が Bell Labs 在籍経験を活かして Statistical Sciences, Inc.(StatSci) をシアトルで設立、商用版 S-PLUS をリリース
- 1993 年:Bell Labs が StatSci に S の 独占商用ライセンス を付与
- ピーク時の S-PLUS ユーザー数:北米だけで 25,000〜30,000 人
つまり、1980 年代後半以降、S 言語は:
- 学術界:統計学者・計量経済学者の間で広く普及(無償の学術版)
- 製薬会社:臨床試験の統計解析で標準ツールに
- 金融機関:クオンツ・リスク管理部門で利用
- 計量経済学者:マクロ経済モデルの構築で使用
という形で、AT&T の外でも 業界標準的なツール になっていました。
S から R へ ── そして、ある若き研究者の発見
1992 年、地球の反対側で、もう 1 つの動きがありました。
ニュージーランドの Auckland 大学(オークランド大学)で、統計学者 Ross Ihaka が、ある面白い経験をします。
Ihaka 自身が後に「Past and Future History」で語ったところによれば ──
私はある日、同僚の Alan Zaslavsky に、lexical scope を使って「自分専用の変数(own variables)」を作る方法を見せようとした。Scheme のコピーが手元になかったので、S で試してみた。しかし、S と Scheme のスコープルールが違うため、私の説明は失敗した。それが「S に有用な追加機能があるかもしれない」と思った瞬間だった。
そう、Ihaka は Scheme 言語(MIT で開発された Lisp 系の関数型言語)を既に知っていて、Scheme と S の スコープルール(変数の有効範囲のルール)の違い に気づいたのです。
その後、Ihaka は同じ Auckland 大学の Robert Gentleman と意気投合し、Macintosh の教育ラボで使える、より良い統計計算環境を作ろうという発想に至ります。商用の S-PLUS は高価で、教育用途には適していませんでした。
そのプロジェクトの名前は、R。
「R」は、開発者 2 人(Ross と Robert)の頭文字であり、同時に 「S の前の文字」 という遊び心も込められています。
Scheme から受け継いだ「lexical scoping」とは何か
ここで、ちょっとだけ技術的な話に踏み込みます。Ihaka と Gentleman が R に持ち込んだ最も重要な概念が、lexical scoping(レキシカル・スコーピング、字句的スコープ) です。
スコープ(scope) とは、「ある変数が、どの範囲で参照可能か」を決めるルールです。プログラミング言語ごとに、このルールが少しずつ違います。
S 言語(古い設計)では、関数の中で参照される変数は、「グローバル」か「ローカル」の二択 でした。関数の中で見つからない変数があると、グローバル変数を探しに行く ── というシンプルなルールです。
しかし、Scheme(R の参考にした言語)は lexical scoping という、より柔軟な仕組みを採用していました。Lexical scoping では、「関数が定義された場所の環境」が、関数と一緒に保存される のです。
具体例で説明します。次のような R のコードを考えてみます:
make_counter <- function() {
total <- 0
function() {
total <<- total + 1
total
}
}
counter <- make_counter()
counter() # → 1
counter() # → 2
counter() # → 3
ここで make_counter は、「内側の関数を返す」関数 です。total という変数は make_counter の中で定義されています。
S 言語であれば:内側の関数が呼ばれたとき、total を探しに行ってもグローバルにはないので、エラーになるか、不可解な動きをします。
R(lexical scoping)であれば:内側の関数は、「自分が定義された時点の環境(total が存在する make_counter の内部)」を覚えている ので、total を正しく参照できます。何度呼んでも、その「定義時の環境」にある total をインクリメントし続けます。
これが、function closure(関数クロージャ) という概念です。Scheme から受け継いだこの設計により、R は:
- 予測可能 ── 「この変数はどこから来たのか?」が、関数の 書かれた場所 から決定的に決まる(動的スコープのように、呼ばれ方によって変わらない)
- モジュラー ── 関数同士が思わぬ干渉を起こさない
-
状態を持てる ── 上記の
counterのように、関数自身が「自分の状態」を保持できる
Ihaka と Gentleman は、この性質を 統計計算で大いに活用 しました。例えば最尤推定(Maximum Likelihood Estimation)では、対数尤度関数を最適化する際に、観測データを「埋め込んだ」関数を作る必要があります。lexical scoping があれば、これがエレガントに書けます。
実際、R の最適化関数(optim()、nlm()、optimize() など)は、この lexical scoping を前提に設計 されています。
(なお、R が Scheme から受け継いだ性質はもう 1 つあります:すべてのオブジェクトをメモリ上に保持する 設計です。これは、関数が自分の定義時環境を覚えている以上、ディスクに保存しておくことができないためです。R が「メモリを多く使う」と言われる理由は、この lexical scoping の代償でもあります)
R 1.0.0 リリース
そのプロジェクトのスタートから 8 年。
2000 年 2 月 29 日(うるう日)、ついに R 1.0.0 がリリースされます。
S 言語の発祥(1976 年)から、24 年。data frame 概念の確立(1992 年)から、8 年。データ分析言語の本格的な民主化が、この日に始まりました。
そして、興味深い事実があります。R Development Core Team には、John Chambers 自身も参加 しているのです。S の生みの親が、その後継者である R の開発に直接関与する ── これは、ソフトウェアの歴史でも稀有な、美しい継承関係です。
John Chambers、85 歳、今もスタンフォードに
ここで、1 つだけ伝えたい事実があります。
S 言語と R 言語の生みの親である John Chambers(1941 年トロント生まれ)は、現在 85 歳。
それでも、彼は スタンフォード大学統計学科の Adjunct Professor、そして Stanford Data Science の Senior Advisor として、今も現役で活動しています。
1998 年、ACM(Association for Computing Machinery、計算機学会)は、彼に ACM Software System Award を授与しました。受賞理由は:
S 言語は、人がデータを分析・可視化・操作する方法を永久に変えた。
データ分析言語の歴史を、皆様が import pandas as pd と書く時、その遥か上流には、85 歳の John Chambers が今も歩み続ける姿があります。
[画像挿入位置候補 B:John Chambers の Bell Labs 時代と、S 言語誕生の図]
第 2 章: 2008 年、AQR Capital ── Python へのパス
場面が変わって、コネチカット州グリニッジ
舞台は、1976 年の Bell Labs から、32 年後の 2008 年、米国コネチカット州グリニッジに移ります。
ここに、AQR Capital Management という、世界有数のクオンツ・ヘッジファンドがあります。
「AQR」は Applied Quantitative Research(応用定量的研究)の略。文字通り、数学と統計を駆使して投資判断を行う、米国金融業界の最前線です。
(AQR は本連載第 1 回で言及した Jane Street Capital や Tsuru Capital と同じ「クオンツ・ヘッジファンド」の世界です。
ただし、言語選択の哲学は対照的 です。Jane Street は OCaml で 3,000 万行のシステムを、Tsuru Capital は Haskell でマーケットメイキングを書いています
── つまり 関数型言語 + 強い型システムで「正しさ」を担保する 流派です。
一方、AQR は Python・C++・Java を主軸とする、より 実用主義(pragmatic)的なスタック を採用しています。
本記事執筆時点で公開されている AQR の Quant Research Engineer 求人を見ても、Python・NumPy・pandas が必須スキルとして筆頭に挙げられています。「金融業界の最前線」には複数の言語哲学が共存している ── これは興味深い事実です)
その AQR の front office quant research team(フロントオフィス・クオンツ研究チーム)に、2007 年 8 月、1 人の若者が新人として加わりました。
若き Wes McKinney
Wes McKinney。
オハイオ州 Akron 出身。数学とテクノロジーに早くから才能を見せ、ティーンエイジャーの頃から数学コンテストに参加し、ウェブサイトを構築していたという経歴の持ち主です。
2007 年、MIT で理論数学の BS(Bachelor of Science)を取得して卒業。在学中に Sarkovskii の定理(力学系の順序に関する定理)に関するプロジェクトを完成させた、純粋数学のバックグラウンドを持つ人物です。
そんな彼が、グリニッジの AQR に入社した時、何を感じたか ──
彼自身が後に振り返って語っています:
AQR に入って、基本的なデータ分析と統計の仕事が、いかに退屈な作業に満ちているか、衝撃を受けた。優秀で献身的な人々が、効率的に働けていない。Microsoft Excel での驚くほど多くの手作業に時間を費やしていた。
純粋数学を学んできた若者の目には、世界トップクラスのクオンツ・ヘッジファンドですら、データ分析のツールの未熟さ が映ったのです。
📘 補足コラム:2026 年の Excel は、もはや 2008 年の Excel ではない(公平のために)
ここで、Excel の名誉のために 一つ、本記事執筆者として補足させてください。
上記の Wes McKinney の証言は、2008 年当時の Excel に対するものです。2026 年現在の Excel は、もはやその姿ではありません。Microsoft が過去 10 年余りで Excel に追加してきた機能は、驚くほど強力です。
| 機能 | 内容 | 影響 |
|---|---|---|
| Power Query(2013 年〜) | Excel ネイティブの ETL(抽出・変換・読み込み)エンジン。複数データソースの接続、データクリーニング、結合をすべて GUI で実行可能 | VBA で書いていた前処理スクリプトを、ボタンクリックで置き換え可能に |
| Power Pivot + DAX(2010 年〜、2016 年から標準搭載) | データモデリング専用エンジン。数億行のデータを高速処理、複数テーブル間のリレーション設定、DAX(Data Analysis Expressions)による計算カラム・KPI 定義 | Excel が単なるシートから「軽量データウェアハウス」へ進化 |
| 動的配列関数(2020 年〜) |
XLOOKUP、FILTER、SORT、UNIQUE、SEQUENCE など、配列を自然に扱える新世代関数群 |
VLOOKUP 時代のセル参照地獄から解放 |
| Python in Excel(2023 年〜) | Excel セル内で Python コードを直接実行(=PY(...))。Anaconda 経由で pandas、NumPy、matplotlib、scikit-learn が利用可能
|
Excel と Python の世界が公式に統合 |
| Microsoft Copilot in Excel(2023 年〜、2024 年機能拡張) | AI による複数列にわたる複雑な数式の自動生成、カスタムチャート・ピボットテーブル作成、テキストデータの要約、ステップバイステップの指導 | AI 時代の Excel |
つまり、2026 年の実務では、Excel と Python は対立する道具ではなく、補完し合うパートナー になっています。財務モデリングや FP&A の世界では、以下のようなハイブリッド戦略が広く採用されています:
- Power Query で大量データを ETL し、Excel に取り込む
- Power Pivot で数億行のデータをモデル化し、DAX で集計指標を定義
- Python in Excel で機械学習や高度な統計分析を Excel 内で実行
- 完成した財務モデルを Excel で経営層にプレゼンテーション
Wes McKinney 自身も、2026 年 2 月の Rill Data Podcast で、Excel が依然として財務・会計の世界で主役であり続けることを認め、pandas と Excel の共存を肯定的に語っています。
「Excel か Python か」ではなく、「Excel も Python も」 ── これが 2026 年の正しい認識です。
ですから、本記事執筆者は、Excel を毎日使われている読者の皆様への敬意 を込めて、この補足コラムを置きました。Excel は決して「過去の道具」ではなく、世界最強の表計算ソフトとして、今も進化を続けている現役の主役 です。
2008 年 4 月 6 日 ── pandas の誕生
そして、運命の日が訪れます。
2008 年 4 月 6 日。
Wes McKinney が、後に世界中のデータ分析を変えることになるプロジェクトの開発を始めた、その具体的な日付です。彼自身が公式ブログで明記しています:
I started building pandas on April 6, 2008, as part of a skunkworks effort to reproduce some econometric research in Python.
(私は 2008 年 4 月 6 日に pandas の構築を始めた。Python で計量経済学的研究を再現するための、社内非公式プロジェクトの一環として)
「skunkworks effort」── これは、米国軍需産業 Lockheed Martin の伝説的な特命プロジェクト部門 Skunk Works に由来する言葉で、「上司の正式な承認なしに、有志が独自に進めるプロジェクト」 を意味します。
つまり、pandas は AQR 社内の公式プロジェクトではなく、Wes McKinney 個人の試行錯誤 から始まりました。
なぜ「pandas」という名前なのか
ここで、皆様にお訊ねしたい問いがあります。
pandas という名前は、何に由来していると思いますか?
「panda(パンダ)」の複数形? それとも「Python data analysis」の頭文字?
正解は、「panel data」(パネルデータ) という、計量経済学の専門用語です。
📘 補足コラム:計量経済学とは何か(プログラマー向け 90 秒入門)
「計量経済学」と聞いても、ピンと来ない方もいらっしゃるかもしれません。簡潔に紹介します。
計量経済学(Econometrics) とは、経済現象を、統計学・確率論・数学を使って定量的に分析する学問 です。1930 年に設立された Econometric Society(計量経済学会)を起源とし、現在は経済学・金融学・政策分析の中核を担う領域になっています。
プログラマーの言葉に翻訳すれば:
| 計量経済学の世界 | プログラマーの世界 |
|---|---|
| 観測データから経済モデルを推定 | 訓練データから機械学習モデルを学習 |
| 回帰分析(OLS、GLS、IV 推定) | 線形回帰、ロジスティック回帰 |
| 時系列分析(ARIMA、VAR、GARCH) | 時系列予測、状態空間モデル |
| パネルデータ分析(固定効果、ランダム効果) | マルチレベル / 階層ベイズモデル |
| 因果推論(差分の差分法、操作変数法、回帰不連続) | 因果推論機械学習(CausalML、DoWhy) |
| マクロ経済モデル(DSGE、VAR) | システムダイナミクス、エージェントベースシミュレーション |
つまり計量経済学は、データサイエンス・機械学習・統計学が分化する以前の、「経済データから何かを推定する」ためのデータ科学 とも言えます。
Nobel 経済学賞の多くは、計量経済学の発展に関する研究に与えられてきました(2003 年 Granger 因果性、2021 年自然実験と因果推論など)。
そして、計量経済学が扱う代表的なデータ形式の一つが、panel data(パネルデータ) ── つまり、pandas の名前の由来そのものです。

パネルデータとは、複数の対象(企業、国、個人など)について、複数の時点で観測したデータ のことです。例えば:
| 企業 | 2024 年売上 | 2025 年売上 | 2026 年売上 |
|---|---|---|---|
| エタール精密機械工業 | 1,200 億円 | 1,350 億円 | 1,480 億円 |
| エタール重工 | 8,000 億円 | 8,200 億円 | 8,500 億円 |
| エタール化学 | 3,500 億円 | 3,400 億円 | 3,600 億円 |
このような 「複数企業 × 複数時点」 の表形式データを、計量経済学では panel data と呼びます。
そして、AQR Capital のような クオンツ・ヘッジファンドが日々扱うデータは、まさに panel data そのもの ── 何千銘柄の株価、何百カ国のマクロ経済指標、それらを何十年分も、というデータです。
pandas は、panel data を Python で効率的に扱うためのライブラリ として設計され、その名前を採用しました(「Python data analysis library」のダブルミーニングでもあります)。
つまり、pandas は 計量経済学・金融データ分析のために生まれた道具 だったのです。

R の data.frame をモデルに
Wes McKinney が pandas を設計する際に参考にしたのは、ほかでもない R の data.frame でした。
AQR のクオンツ研究者の多くは、R を使ってデータ分析をしていました。Wes McKinney 自身も R を学び、R の data.frame の表現力に感銘を受けます。
R にはこんなに便利な道具があるのに、Python には同等のものがない。だったら、自分が作ろう。
彼の動機は、シンプルでした。
そして、1976 年に Bell Labs で John Chambers が始めた系譜は、ここで R から Python へとブリッジ されたのです。
2009 年、AQR のオープンソース化決断
Wes McKinney が個人的に始めた pandas は、AQR 社内で徐々に使われるようになります。
そして、2009 年。
AQR Capital は、社内ツールである pandas を BSD ライセンスでオープンソース化することを許可しました。
これは、ヘッジファンド業界では極めて稀有な決断です。
一般的に、ヘッジファンドの社内ツールは競争優位の源泉として厳しく秘匿されます。AQR がこの決断をした背景には、Wes McKinney の情熱と、AQR 経営陣の先見性がありました。
2010 年、AQR を離れて
pandas のオープンソース化から 1 年後、Wes McKinney は AQR を退社します(2010 年 7 月)。
退社後、彼は Duke 大学の統計学博士課程に進学(2010 年)、しかし 1 年後にはオープンソース活動に専念するため leave of absence を取り、結局博士課程は中断しました。
2012 年、O'Reilly Media から Python for Data Analysis を出版。これは現在まで世界中のデータサイエンティストの定番教科書となり、複数版が出版されています。
2013 年、pandas プロジェクトは完全にコミュニティ所有 となり、Wes McKinney は「BDFL(Benevolent Dictator for Life、慈悲深き終身独裁者)」という名誉的な役割に退きます。
その後の彼の歩みは、本記事の終章で触れます。

2008 年 4 月 6 日のドラマ ── AQR の若き Wes McKinney と Excel スプレッドシート → pandas DataFrame への変革
第 3 章: 2012 年、JuliaStats ── 3 つ目の系譜
Julia 言語の誕生
時代はさらに進みます。
2012 年、MIT(マサチューセッツ工科大学)。
Jeff Bezanson、Stefan Karpinski、Viral B. Shah、Alan Edelman の 4 人が、新しいプログラミング言語 Julia を発表しました。
Julia の設計思想は野心的でした:
Python のように書きやすく、R のように統計分析に強く、C のように高速で、Ruby のように動的、Lisp のようにマクロを持ち、Matlab のように数値計算に強い ── これらすべてを 1 つの言語で実現する。
「The 2 language problem(2 言語問題)」を解決するための言語です。
データサイエンティストが、プロトタイプを Python や R で書き、実運用のために C++ で書き直す ── この非効率を、Julia は最初から高速に書ける単一言語で解決しようとしたのです。

DataFrames.jl の開発開始
Julia の開発が始まると、ほぼ同時に、DataFrames.jl の開発も始まります。
なぜ「ほぼ同時」かというと、データを表形式で扱うことは、データ分析の最も基本的な前提だから です。
R に data.frame があり、Python に pandas がある。だったら Julia にも、それに相当する道具が必要だ ── 自然な発想でした。
初期実装者は Harlan Harris(統計学者・データサイエンティスト)。
彼は、julia-dev メーリングリストで、Julia エコシステムの設計について熱心に議論していました。
julia-dev での歴史的な対話
ここで、興味深い歴史的記録があります。
julia-dev メーリングリスト(現在は Google Groups でアーカイブされている)に、こんなやり取りが残されています(スレッドのアーカイブ:Subsetting: Is Julia making the same mistake R made 20 years ago?):
- Harlan Harris:「Julia の DataFrames は、R の data.frame と Python の pandas のどちらの設計思想を取るべきか」
- Wes McKinney(pandas 作者本人が登場!):「pandas の設計の意図はこうである」
- Harlan Harris:「Thanks, Wes! ご説明ありがとうございます」
つまり、pandas の生みの親である Wes McKinney 本人が、Julia 版 DataFrames の設計に意見を寄せていた のです。これは、3 つの DataFrame が独立に発展したのではなく、直接的な対話の中で進化してきた ことを示す貴重な記録です。
2021 年、DataFrames.jl 1.0 リリース
DataFrames.jl は、Julia 1.0 リリース(2018 年 8 月)から 3 年後 の 2021 年に 1.0 リリース を迎えます。
これは、「機能が成熟するまで 1.0 を出さない」という JuliaStats の慎重な方針の表れです。同じ DataFrames.jl は、開発開始から数えると 9 年もの歳月 をかけて、ようやく 1.0 に到達しました。
現在のメインメンテナーは:
- Bogumił Kamiński 教授(ワルシャワ経済大学/Warsaw School of Economics, SGH 校)
- Milan Bouchet-Valat
- Peter Deffebach ほか
特に Bogumił Kamiński 教授は、 Julia for Data Analysis の著者でもあり、現在の DataFrames.jl の技術的方向性をリードしています。
2023 年、ついに DataFrames.jl は Journal of Statistical Software という統計学界のトップ学術誌に論文として正式発表されました。
「学術 → 産業 → 学術」── データ分析の系譜が、再び学術界に帰ってきた瞬間です。

第 4 章: 3 つの DataFrame は何が同じで、何が違うのか
ここまで、3 つの DataFrame の 出自 を辿ってきました。
では、3 つは現代において、何が同じで、何が違うのでしょうか。
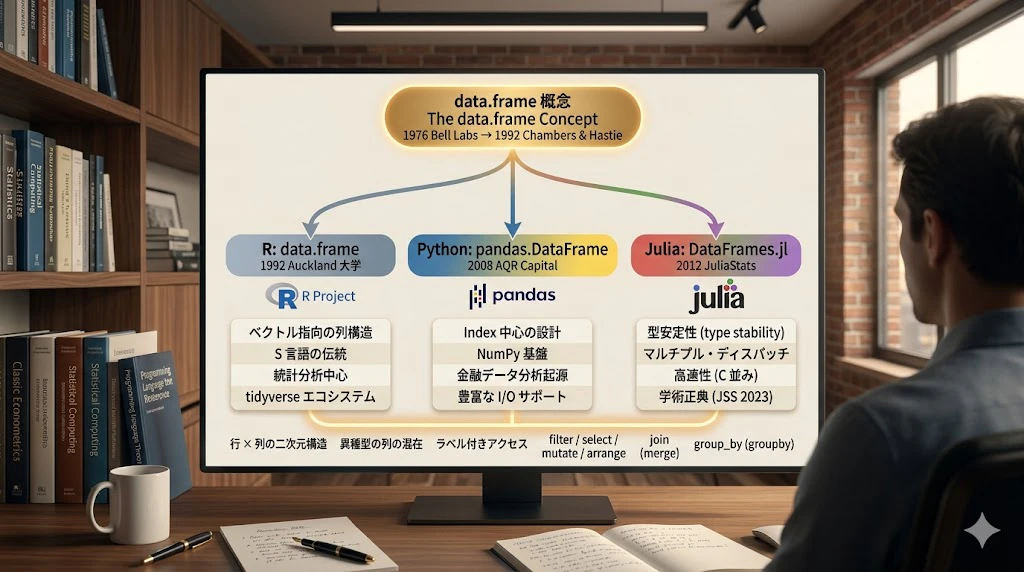
共通する DNA
3 つの DataFrame には、共通する DNA があります。それは、1992 年の Chambers & Hastie 白本が定義した、たった 1 つの概念です:
データを表形式で構造化し、列名と型を持って扱う
このたった 1 つの概念が、R、Python、Julia という 3 つの全く異なる言語環境で、それぞれの特性に合わせて実装されてきたのです。

設計思想の違い
3 つの言語は、それぞれ 得意領域 が異なります。
| 項目 | R data.frame
|
Python pandas | Julia DataFrames.jl |
|---|---|---|---|
| 誕生年 | 1976 年(S 言語)→ 1992 年(概念確立) | 2008 年 | 2012 年 |
| 誕生場所 | Bell Labs(米国・統計学研究) | AQR Capital(米国・クオンツ金融) | MIT / JuliaStats(米国・学術 + 産業) |
| 直接の動機 | 統計学者がデータ分析を手軽に行えるように | 金融データを Python で効率的に扱えるように | R と pandas の良さを Julia で実現 |
| 名前の由来 | 「データを表形式で扱う」概念から | 「Panel Data」(計量経済学用語)から | R の data.frame をそのまま継承 |
| 強みの領域 | 統計学、医学、社会科学 | データサイエンス全般、機械学習、金融 | 数値計算、最適化、科学計算 |
| 言語特性 | インタープリタ、対話的 | インタープリタ、エコシステム巨大 | コンパイル、高速、型システム |
| 欠損値の扱い | NA |
NaN / None / pd.NA
|
missing |
| 破壊的変更の表現 |
<- で代入、関数は基本非破壊 |
inplace=True 引数 |
関数名の末尾に !
|
同じ操作のコード比較
「百聞は一見にしかず」ですので、同じ操作を 3 言語で書いてみましょう。
お題:データフレームの中から、region ごとに value の平均を計算する。
R(dplyr パッケージ使用)
library(dplyr)
df %>%
group_by(region) %>%
summarize(mean_value = mean(value))
Python(pandas)
import pandas as pd
df.groupby("region")["value"].mean()
Julia(DataFrames.jl)
using DataFrames, Statistics
combine(groupby(df, :region), :value => mean)
3 言語とも、同じ思想・異なる構文・共通する DNA で記述できることが分かります。
そして、データ分析を生業とするエンジニアであれば、この 3 言語のいずれかで書ける能力 が、2026 年の世界で極めて価値ある武器になります。
第 5 章: そして、財務モデリングとの関係性
2 つの結節点が、財務分析の現場にあった
ここで、本記事のタイトルにある 「みんなが知らない財務モデリングとの関係性」 に戻りましょう。
3 つの DataFrame の系譜を振り返ると、2 つの結節点が、財務分析の現場 にあったことが見えてきます。
-
1992 年の「panel data」概念:計量経済学(金融・経済データ分析の学問)の専門用語が、pandas の名前の由来になった
- 2008 年の AQR Capital:クオンツ・ヘッジファンドの社内ツールとして、pandas は誕生した
つまり、Python の DataFrame 系譜は、最初から最後まで、金融データ分析が動機 でした。

財務モデリングとは何か ── プログラマー向け 5 分概念ツアー
ここで、「財務モデリング」 という用語について、簿記も会計もコーポレートファイナンスもご存知ない方のために、プログラマーの言葉で 説明します。
一行で言えば
財務モデリングは、「企業を 1 つの巨大な Excel スプレッドシート」または「1 つの Python スクリプト」としてシミュレートすること です。
入力:過去の実績データ、仮定(成長率、価格、コスト、金利など)
出力:未来 3〜10 年間の利益、現金残高、企業価値
プログラマー向けのアナロジー
財務モデリングを、プログラマーが日常的に扱う概念に翻訳すると、以下のようになります。
| 財務モデリングの世界 | プログラマーの世界 |
|---|---|
| 企業 | 1 つの巨大な関数 f(過去, 仮定) → 未来
|
| 売上予測 | 入力に対する出力の予測モデル |
| 損益計算書(P/L、Income Statement) | 「期間内の収支」を出力する関数 |
| 貸借対照表(B/S、Balance Sheet) | 「ある瞬間の資産・負債のスナップショット」(状態) |
| キャッシュフロー計算書(C/F、Cash Flow) | 「現金の流入と流出」のログ |
| 3 表連動 | 3 つの関数が 互いに参照し合う相互依存ネットワーク |
| シナリオ分析 | パラメータを変えて関数を何度も呼ぶ(楽観・基本・悲観の 3 通り) |
| 感応度分析 | 偏微分:「金利が 1% 上がると、企業価値はいくら下がるか?」 |
| WACC(資本コスト) | 割引率。未来の現金を「今の価値」に変換する係数 |
| NPV(正味現在価値) | 将来現金フローを WACC で割り引いて合計したスカラー値 |
| バリュエーション(企業価値評価) | NPV を計算して、企業を 1 つの数字(価格)に縮約する |

3 表連動モデル ── データ構造としての企業
財務モデリングの中核となる 「3 表連動モデル(3-Statement Financial Model)」 は、以下の 3 つの DataFrame が相互に参照し合う構造です:
損益計算書(P/L) 貸借対照表(B/S) キャッシュフロー計算書(C/F)
───────────────── ───────────────── ──────────────────────
売上 10,000 現金 3,000 営業 CF +2,500
原価 -6,000 ─→ 売掛金 1,500 投資 CF -1,000
減価償却 -500 固定資産 8,000 ←─ 財務 CF -500
───────── ───────── ─────────
営業利益 3,500 資産合計 12,500 現金増減 +1,000
利息 -200 負債 5,000 ←─ 期末現金 3,000
税金 -1,000 資本 7,500
───────── ───────── ↑ 期末現金が B/S の現金と一致
当期純利益 2,300 (これが「3 表連動」)
│
└────────────────────→ 利益剰余金として B/S 資本に加算
ここに 3 つの矢印 が走っています:
1. P/L の「当期純利益」→ B/S の「利益剰余金」(資本セクション)
2. C/F の「期末現金」→ B/S の「現金」
3. B/S の「固定資産」← C/F の「投資 CF」(資産購入)
つまり、1 つの数字を変えると、3 つの表すべてが連動して更新される ── これが「3 表連動」の核心です。
Excel で書けば、これは 数千個のセル間の依存関係グラフ になります。Python で書けば、3 つの DataFrame が相互参照する 計算 DAG(Directed Acyclic Graph) になります。

このような財務モデルを誰が日々書いているのか
財務モデリングを業務として行っているのは、以下の専門職です:
- 投資銀行のアナリスト:M&A の対象企業を評価
- アセットマネージャー・ヘッジファンドのクオンツ:投資対象の現在価値を計算
- 事業会社の FP&A(Financial Planning & Analysis)部門:来期予算の策定、設備投資判断
- 経営コンサルタント:クライアント企業の戦略代替案の財務インパクト評価
- スタートアップの CFO:バーンレート(現金消費速度)管理、次の資金調達計画
- 規制当局の検査官:銀行の自己資本比率、保険会社の支払い能力評価
これらの専門職が、日々、Excel や Python や R や Julia で、「来期の売上はいくらか」「次の事業投資の回収期間はどれくらいか」「リスク調整後の利益率はどうか」 を計算しています。

そして、その計算の 最も基本的なデータ構造 が、DataFrame です ── R の data.frame、Python の pandas、Julia の DataFrames.jl。
つまり、本記事で 50 年の系譜を辿ってきた 3 つの DataFrame は、現代の世界の財務モデリングのほぼすべてを下支えしている のです。

3 言語で、財務モデリングの何が解かれているか ── 公開コードで見る現場
ここからが、本記事の 最後の見どころ です。
「3 つの DataFrame が財務モデリングの下支え」と書きましたが、具体的に、どの企業が、どの言語で、どんな財務問題を解いているのか? ── 実際の公開コードを URL で紹介します。
Python 公開コード:Goldman Sachs の gs-quant
データサイエンティスト・BI エンジニアの皆様がもっとも親しみやすいのは、おそらく Goldman Sachs(ゴールドマン・サックス) が GitHub で公開しているクオンツ・ファイナンス・ライブラリ gs-quant でしょう。

🔗 公開リポジトリ: https://github.com/goldmansachs/gs-quant
🔗 Goldman Sachs 公式紹介ページ: https://developer.gs.com/discover/open-source
gs-quant は、Goldman Sachs が長年社内で使ってきた Python のクオンツ・ファイナンス・ツールキット を、外部公開したものです。何ができるのか:
- デリバティブ(オプション、スワップ、先物)のプライシング
- リスク分析(感応度、ストレステスト)
- シナリオ分析(金利が 1% 上がったら、ポートフォリオはどう変わるか)
- 市場データへのアクセス
- バックテスト(過去データで戦略を検証)
これらすべての処理で、pandas DataFrame が基本データ構造として使われている ことを、皆様は実際のコードで確認できます。

Python 公開コード:JPMorgan Chase の Open Source プロジェクト群
JPMorgan Chase は、複数の Python ライブラリを公開しています。
🔗 JPMorgan Open Source 一覧: https://jpmorganchase.github.io/
特に注目すべきもの:
-
python-training: https://github.com/jpmorganchase/python-training- 「JPMorgan のビジネスアナリストとトレーダー向けの Python 教材」 をそのまま公開しているリポジトリ
- pandas、NumPy、可視化を使った、実際の金融データ分析の基礎が学べる
-
PyFusion: JPMorgan の Fusion プラットフォーム API への Python SDK
-
DataQuery SDK: https://github.com/jpmorganchase/dataquery-sdk- JPMorgan の金融データへのアクセス用 SDK
- JPMorgan の金融データへのアクセス用 SDK
-
swblocks-decisiontree: 意思決定ツリーを高性能に評価するライブラリ(取引ルールの判定などに使う)
第 5 章の冒頭で紹介した「Athena の 3,500 万行 Python コード」は社内システムですが、JPMorgan の Python 文化 がこれらの公開コードから垣間見えます。
Python 公開コード:業界標準 QuantLib(C++ コア + Python バインディング)
🔗 公式サイト: https://www.quantlib.org/
QuantLib は、銀行・ヘッジファンド・フィンテック・学術界で 業界標準 として使われている、オープンソースのクオンツ・ファイナンス・ライブラリです。
コアは C++ ですが、Python バインディング(QuantLib-Python) が完備されており、pandas との統合も容易です。
機能:
- 債券・スワップ・オプション・エキゾチック・クレジット商品の プライシングエンジン
- イールドカーブ構築(国債金利曲線の作成、補間)
- 確率モデル(Hull–White、SABR、CIR など)
- Monte Carlo シミュレーション
業界標準として、本記事執筆者が言及した 金融機関のほぼすべてが QuantLib を直接または派生形で使用 しています。

Python 公開コード:汎用キュレーション awesome-quant
🔗 キュレーションリスト: https://github.com/wilsonfreitas/awesome-quant
「クオンツ・ファイナンスのための、信じられないほど素晴らしいライブラリ・パッケージ・リソースのキュレーションリスト」。Python・R・Julia・C++ の全言語で、財務モデリングの公開ライブラリが整理されています。
Julia 公開コード:JuliaFinance と QuantLib.jl
Julia 言語のクオンツ・ファイナンス公開コードも、複数あります。
🔗 JuliaFinance organization: https://github.com/JuliaFinance
- 21 個のリポジトリ
-
BusinessDays.jl(営業日計算、金融契約の決済日計算に必須)、その他
🔗 JuliaQuant organization: https://github.com/JuliaQuant
- 22 個のリポジトリ
-
Ito.jl、MarketTechnicals.jlなど
🔗 QuantLib.jl(QuantLib の純粋 Julia ポート): https://github.com/pazzo83/QuantLib.jl
- 同リポジトリには、債券の NPV(正味現在価値)計算のサンプルコード が示されており、皆様は実際に動かして「Julia で財務モデリングを書くとはこういうことか」を体感できます
# QuantLib.jl による債券 NPV 計算の一部(README より)
using QuantLib
using Dates
settlement_date = Date(2008, 9, 18)
set_eval_date!(settings, settlement_date - Dates.Day(3))
# イールドカーブ構築のための短期金利・債券データ
depo_rates = [0.0096, 0.0145, 0.0194]
depo_tens = [Dates.Month(3), Dates.Month(6), Dates.Month(12)]
# (...続く)
Haskell 公開コード:hledger ── 関数型言語で書かれた複式簿記
最後に、皆様にとって 最も知的に刺激的かもしれない例 を紹介します。
🔗 hledger 公開リポジトリ: https://github.com/simonmichael/hledger
🔗 hledger 公式サイト: https://hledger.org/
hledger は、Haskell で書かれた、複式簿記(double-entry bookkeeping)のためのプレーンテキスト会計ツール です。Simon Michael 氏が主導し、140 名以上の貢献者がいて、2007 年から継続的にメンテナンスされています。
何ができるのか:
- 取引を シンプルなテキストファイル で記述する
-
貸借対照表(
hledger bs)、損益計算書(hledger is)、キャッシュフロー(hledger cf) を CLI で出力 - 複数通貨対応、暗号通貨対応、時間追跡もできる
- 関数型言語の特性(不変性、強い型システム)で、会計データの整合性が言語レベルで保証 される
これは、本記事で言及した Standard Chartered Bank の Haskell 製金融モデリング言語「Mu」と思想的に最も近い、公開されたコード例 です(Mu は社内非公開ですが、hledger は GPL ライセンスで完全公開)。
簿記を一切知らないプログラマーの皆様にとっても、hledger のテキスト形式 + 関数型コードは、「会計を、関数型言語で表現するとこうなる」 という稀有な学習素材です。

R 公開コード:r-ledger と tidyverse
🔗 r-ledger 公開リポジトリ: https://github.com/trevorld/r-ledger
r-ledger は、hledger 等のプレーンテキスト会計ファイルを R の data.frame として読み込む R パッケージです。
tidyverse(dplyr、ggplot2、tidyr)と組み合わせて、会計データの分析・可視化を R で行うことができます。
そのほか、R には統計学・計量経済学・金融分野での歴史的優位があり、quantmod(金融時系列の取得・分析)、tidyquant(tidyverse 流のクオンツ分析)、Rmetrics(教育用の金融数学パッケージ)、SmithWilsonYieldCurve(スミス・ウィルソン法によるイールドカーブ構築) など、財務モデリング系のパッケージが豊富にあります。

まとめ:同じ問題を、3 つの DNA で
ここまで紹介してきた公開コードは、すべて 「企業の財務をモデル化する」 という同じ問題に取り組んでいます。
| 言語 | 公開コード例 | 強みの源泉 |
|---|---|---|
| Python | gs-quant、QuantLib-Python、JPMC python-training | エコシステムの巨大さ、pandas との一体性、金融業界の標準 |
| Julia | QuantLib.jl、JuliaFinance、JuliaQuant | Monte Carlo・最適化の高速性、数値計算の表現力 |
| R | r-ledger、quantmod、tidyquant、Rmetrics | 統計学・計量経済学との一体性、ggplot2 の可視化力 |
| Haskell | hledger | 型システムによる会計データの整合性保証(Standard Chartered Mu 系の思想) |
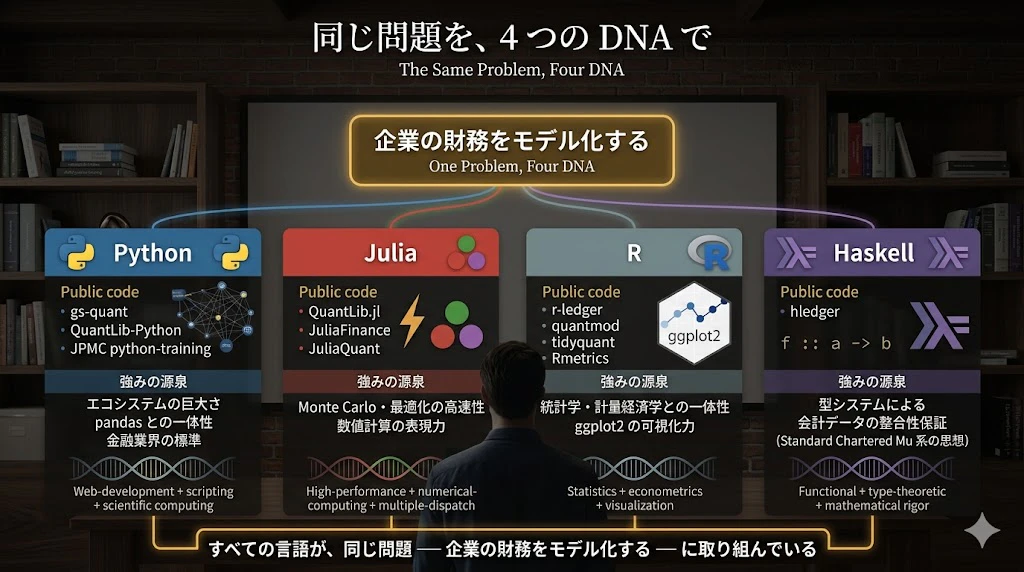
そして、これらすべての公開コードは、1976 年 Bell Labs の John Chambers が始めた「データを表形式で構造化し、列名と型を持って扱う」という 1 つの DNA から、50 年かけて分岐し、それぞれの言語の文化と特性に合わせて発展してきたものです。
皆様が今夜、これらの GitHub リポジトリをいくつか覗いてみるとしたら ── たぶん、hledger が最も知的な驚きを提供するでしょう(関数型言語で会計が書けるのか!という驚き)。
gs-quant が最も実務的な学びを提供するでしょう(Goldman Sachs が日々使っているコードを覗ける!)。
そして r-ledger は、財務データを R の tidyverse 文化で料理する、洗練された一例を見せてくれるはずです。
大企業の Python 採用事例
pandas が金融業界にもたらしたインパクトは、桁違いです。具体的な数字を見てみましょう。
JPMorgan Chase ── Athena プラットフォーム
JPMorgan Chase の社内基幹プラットフォーム Athena(プライシング・トレーディング・リスク管理・分析を行う)は、約 3,500 万行(35 million lines)の Python コード で構築されています。
- 150,000 以上の Python モジュール
- 500 以上のオープンソースパッケージ
- 1,500 人以上の開発者(2019 年時点)
- CI/CD 環境で 1 週間あたり 10,000 〜 15,000 のプロダクション変更
出典:JPMorgan の Executive Director、Misha Tselman 氏が 2019 年に PyData NYC で行った講演内容に基づく(TechRepublic 報道、2019 年 9 月;Python Bytes Podcast Episode #152)。
Bank of America ── Quartz プラットフォーム
Bank of America の社内基幹プラットフォーム Quartz は、約 1,000 万〜1,700 万行の Python コード で構築されています(2014 年時点で 1,000 万行、2018 年時点で 1,700 万行)。
- 約 5,000 名の Python 開発者(社内全体)
- 1 日あたり約 3,000 commits
- 会社全体のビジネスシステムを単一の Python 基盤に統合する社内プロジェクト
出典:Quartz の最初の採用エンジニア Chris Laffra 氏のメーリングリスト投稿(2014 年、Python.org TriZPUG);元 Bank of America Managing Director の Kirat Singh 氏(後に JPMorgan で Athena プロジェクトを主導)による Finextra Research インタビュー(Finextra Research, 2020);2018 年 PyGotham 講演 Seventeen Million Lines of Python Later: Launching a Startup in an Investment Bank(PyVideo)。
Citigroup ── 全アナリスト・トレーダーへの Python 必修化
Citigroup は、2018 年以降、全アナリスト・トレーダーに Python を必修化 しています(同上 Finextra Research 報道)。
これらの巨大な Python 基盤の、ほぼすべてに pandas が組み込まれています。
2008 年に AQR Capital で 1 人の若者が始めた小さなプロジェクトは、わずか 18 年で、世界の金融業界のインフラそのものになりました。
関数型クオンツの世界
pandas が生まれた AQR Capital と同じ世界 ── クオンツ・ヘッジファンド ── には、別の言語文化もあります。
- Jane Street Capital(ニューヨーク): OCaml で 3,000 万行のトレーディングシステム
- Tsuru Capital(東京・シンガポール): Haskell でマーケットメイキング
- Standard Chartered Bank: Haskell で約 650 万行の価格設定エンジン(Markets 部門の年間営業収益 30 億ドルを支える基盤)
これらの企業は、型安全性と数学的厳密性 を最優先する文化を持っています。Wes McKinney が AQR に在籍していた時代、彼の周辺にもこうした「関数型クオンツ」の流れがありました。
pandas もまた、この 「金融業界の最前線で、数学的厳密性とデータ分析の効率を両立する」 という文化の中から生まれた、と言えるのです。
Python・Julia の使いやすさ と Haskell・OCaml・Idris の厳密性を両立した言語はあるか?
ここまで読まれて、皆様の中にはこんな疑問を持たれた方もいらっしゃるかもしれません。
「Python や Julia は 使いやすい けれど型は緩い。Haskell・OCaml・Idris は 厳密 だけれど学習コストが高い。両方の良さを併せ持つ言語はないのか?」
正直に言えば、完全な答えはまだ存在しません。
しかし、2020 年代後半に複数の有力候補が登場 しており、現在進行形で発展しています。代表的なものを挙げます:
Scala(2004 年〜、JVM)
- オブジェクト指向 + 関数型 を融合させた、最も古参のハイブリッド言語
- 強い静的型システム、型推論
- 金融業界では Twitter、Goldman Sachs、Morgan Stanley などが採用
- 学習曲線がやや急、Java エコシステムの上に立つ
F#(2005 年〜、.NET)
- Microsoft 開発の OCaml 派生言語
- Credit Suisse がクオンツ分析に F# を採用 している、と Risk.net が報じている(Risk.net, 2019)
- 不変性・強い型・優れた構文。「Python のような書きやすさ + 関数型の厳密性」を志向
- ただし、Microsoft エコシステム(.NET)の上に立つため、好みが分かれる
Mojo(2023 年〜)
- Chris Lattner(LLVM・Clang・Swift の作者)が立ち上げた Modular 社が開発
- 「Python のように書け、C++ や CUDA のように速い」 を標榜
- AI・GPU プログラミングに特化した設計
- Python 互換のシンタックス + コンパイル時メタプログラミング + 所有権ベースのメモリ管理
- 2026 年現在もまだ初期段階だが、Q1 2026 にプロダクション版のリリースが予定されている
Roc(2019 年〜)
- Richard Feldman(Elm コミュニティで著名)が立ち上げた純関数型言語
- Haskell の純粋性 + Go の小さなバイナリ + 親しみやすい構文 を目指す
- 「Elm にインスパイアされた、汎用言語」
Gleam(2020 年〜)
- Erlang VM 上の静的型付き関数型言語
- 高並行性 + 型安全性 + 親しみやすい構文
- v1.16.0(2026 年 4 月)、GitHub Star 21,000 超え
これらの言語に共通するテーマは、「Python のエルゴノミクス(人間工学性)と、関数型言語の型安全性を両立する」 です。
ただし、注意点があります:
-
どれもまだ「Python の代替」になっていない: エコシステムの規模(NumPy、pandas、scikit-learn、PyTorch、TensorFlow)が圧倒的に違う
-
専門領域での採用は進む: Mojo は AI、F# はクオンツ金融、Scala はビッグデータ ── という形で、特定分野で確かに使われ始めている
-
「使い分け」が現実的な解: Python で分析、本番系を Rust や Mojo へ ── というハイブリッド戦略が、2026 年の主流
つまり、「1 つの言語が全てを担う」時代は終わり、「複数の言語を、それぞれの強みに応じて使い分ける」時代 に入っているのです。

本連載第 1 回で 9 言語(Python・Julia・Rust・C/C++・Haskell・Idris・Coq・Lean 4 検討中・TypeScript/React)を扱う理由は、まさにここにあります。
AI / LLM 時代に、関数型・宣言型プログラミングの価値はどう変化するか
ここでもう 1 つ、本記事執筆者ご自身が問いを立てるべきテーマがあります。
「LLM や AI エージェントがコードを書く時代に、人間が関数型言語の宣言型スタイルを書きやすくする支援は、もはや不要なのではないか?」
直感的には、こう思えます。AI が代わりにコードを書いてくれるなら、人間が Haskell の難解な型を理解する苦労 や、Idris の依存型に挑む覚悟 など、必要ないのではないか。
しかし、結論から申し上げると、まったく逆 です。AI 時代こそ、関数型・宣言型プログラミングの価値が最大化 します。3 つの根拠を示します。

根拠 0:そもそも宣言型プログラミングとは ── SQL という最も馴染み深い例
ここで、宣言型プログラミング(declarative programming) という用語について、簡単に確認しておきます。
実は、皆様にもっとも馴染み深い宣言型プログラミング言語は ── SQL です。
SELECT customer_id, SUM(amount) AS total
FROM orders
WHERE date >= '2026-01-01'
GROUP BY customer_id
HAVING SUM(amount) > 10000
ORDER BY total DESC;
この SQL 文を書くとき、皆様は 「何が欲しいか(what)」 だけを宣言しています:
- 「2026 年以降の注文から」
- 「顧客 ID ごとに金額を合計して」
- 「合計が 1 万を超えるものだけを」
- 「合計の降順で並べたい」
しかし、「どうやって取得するか(how)」 ── どのインデックスを使うか、ジョインの順序、ハッシュ vs ソートマージ、並列化の有無、メモリ vs ディスク ── これらは 一切書きません。すべて、データベースのクエリオプティマイザが、自動で決定します。
これが 宣言型(declarative)プログラミング の本質です。「何を」だけを書き、「どうやって」は処理系に委ねる。
対照的に、命令型(imperative)プログラミングでは、ループの書き方、データ構造の選択、メモリ確保のタイミング、すべてを人間が指示します。
Haskell・OCaml・Idris の関数型プログラミングは、SQL と同じ思想で、「何を計算するか」を関数の合成として宣言 します。
「副作用なしで」「不変なデータで」「関数の合成として」── これらは、SQL が DB エンジンに最適化を任せられるのと同じ理由で、処理系(コンパイラ・ランタイム)に多くの最適化を委ねられる ことを意味します。
宣言型は、皆様お馴染みの SQL の世界の、より一般化された姿 なのです。
根拠 1:LLM が生成するコードのコンパイルエラーの 94% は「型チェック失敗」
2025 年の学術研究で、LLM が生成するコードのコンパイルエラーの約 94% が、型チェック失敗である ことが報告されています。
これは何を意味するか:
型システムが厳密な言語ほど、AI 生成コードのバグを早期に発見できる ということです。AI は 文法的にもっともらしい コードは書けますが、意味的に正しい コードを書くとは限りません。型システムは、その「文法と意味のギャップ」を、コンパイル時に自動で検出するガードレールです。
実際、TypeScript は 2025 年に 1 年で 100 万人の新規貢献者を獲得 しました。これは Next.js や Angular がデフォルトで TypeScript を採用していることに加えて、AI 支援開発において、型がガードレールとして機能する ことが理由として広く認識された結果です。
根拠 2:Google で新規コードの 25% が AI 生成 ── 形式検証エージェントが必要に
2026 年 3 月の ACM FSE(Foundations of Software Engineering)論文「Agentic Verification of Software Systems」(arXiv:2511.17330)は、衝撃的な事実を明らかにしています:
Today, more than 25% of the new code at Google is generated by AI.
(今日、Google で新規コードの 25% 以上が AI によって生成されている)
そして同論文は、「AI が生成するコードを検証する形式手法エージェント(Coq、Lean 4、Idris、Dafny を活用する自動証明エージェント)が、本格的に必要になっている」 と論じています。
論旨を要約すれば:人間がコード 1 行ずつをレビューする時代は終わり、AI 同士が「全体の正しさ」を機械的に保証する時代に入ろうとしている。だからこそ、形式検証(Coq、Lean 4、Idris)の重要性は 低下するのではなく、むしろ高まる。
これは、本記事執筆者が本連載第1回で論じた 「形式手法による経営判断ロジックの論理的整合性保証」 が、AI 時代に向けて、正しい方向を向いている ことの強力な裏付けです。
根拠 3:Wes McKinney 自身の最新発言
pandas の生みの親、Wes McKinney は、2026 年 2 月の Rill Data Podcast インタビューで、こう語っています(トランスクリプト):
「LLM は pandas のコードを書くのが、本当に、本当にうまい。pandas はもうどこにも消えない」
これは何を示唆しているか。LLM 時代でも、「人間が読みやすいエルゴノミクス + 表現力ある型システム + 宣言的なデータ操作」 という言語特性は、ますます重要になる、ということです。
pandas は宣言的データ操作の典型例(df.groupby(...).agg(...) という宣言的記法)であり、LLM はそういう 宣言的に何を計算するかが明確なコード を書くのが、特に得意です。
結論:AI 時代の言語選択の本質
| 時代 | 人間の主な役割 | 言語に求められる性質 |
|---|---|---|
| 〜 2020 年代前半 | コード 1 行ずつを書く | エルゴノミクス(人間工学)(書きやすさ) |
| 2025 年〜 | AI への指示 + コードのレビュー | 検証可能性、型安全性、宣言性 |
つまり、本記事執筆者の問い「Python・Julia のエルゴノミクス(人間工学)と Haskell・OCaml・Idris の厳密性を両立した言語はあるか?」は、まさに AI 時代の言語設計の最前線を捉えた問い なのです。
そして、その答えは:
- Mojo(Chris Lattner、Python 互換 + C++ 級速度)
- Scala 3(JVM、関数型と OOP の融合)
- F#(.NET、ニッチ化しているが Credit Suisse 採用実績)
- Roc(Elm の Richard Feldman、純関数型 + Go 級バイナリ)
- Gleam(Erlang VM、型安全な BEAM 言語)
── まだ「決定版」は存在しないけれど、複数の候補が現在進行形で発展中、というのが 2026 年 5 月の現状です。

そして、これらすべての候補が 「宣言型・関数型の思想を、より親しみやすい構文で届ける」 という方向を向いていることは、SQL の 50 年の成功が示すように、人類のプログラミングの本流の進化 なのだと、本記事執筆者は考えております。

終章: 2026 年の今、私たちが 3 つの DataFrame に支払うべき敬意
3 世代の継承者
データ分析の DataFrame 系譜には、3 世代の継承者がいます。
第 1 世代:John Chambers(1941 年生まれ、85 歳)
- 1976 年に S 言語を生み出し、1992 年に
data frame概念を確立 - 1998 年 ACM Software System Award 受賞
- 現在もスタンフォード大学で現役
第 2 世代:Wes McKinney(MIT 2007 年卒)
- 2008 年 4 月 6 日、AQR Capital で pandas を始める
- 現在は Voltron Data の CTO・共同創業者として、Apache Arrow と Ibis(統一データフレーム API)の開発をリード
- Python for Data Analysis の著者(複数版)
第 3 世代:Bogumił Kamiński 教授ら
- ワルシャワ経済大学を拠点に、DataFrames.jl の技術的方向性をリード
- 2023 年、Journal of Statistical Software に正式論文として発表
- 「学術 → 産業 → 学術」のサイクルを完成させた
pd.DataFrame() の背後にある 50 年
明日、皆様がエディタを開いて、何気なく import pandas as pd と書いた時 ──
その 1 行の背後には:
- 1976 年、Bell Labs で John Chambers が始めた、データ分析を手軽にしようという思想
- 1992 年、Chambers & Hastie 白本で確立された
data frame概念 - 2008 年 4 月 6 日、AQR Capital で Wes McKinney が始めた skunkworks プロジェクト
- 2009 年、AQR が下したオープンソース化の決断
- 2012 年、Julia コミュニティで Harlan Harris が始めた DataFrames.jl
- 2021 年、Bogumił Kamiński らによる DataFrames.jl 1.0 リリース
── これら 50 年の物語 が、確かに息づいています。
道具を作った人々への敬意
最後に、もし皆様が pandas や R の data.frame や Julia の DataFrames.jl を使うことで、給料を得たり、研究成果を出したり、事業を成功させたりしてきた ── そういう経験があるならば。
その背後には、「自分の道具に満足できなかったから、自分で作った」 という、無数の名もない貢献者(maintainers, contributors, documentation writers, bug reporters)の努力があります。
そして、John Chambers が 85 歳の今もスタンフォードで歩み続けるように、Wes McKinney が 2 つ目・3 つ目のオープンソースプロジェクトに挑戦するように、Bogumił Kamiński 教授がワルシャワで DataFrames.jl を磨き続けるように ── 彼らの仕事はまだ終わっていない、ということを、私たちは時々、思い出してもよいのではないでしょうか。
import pandas as pd ── この 1 行は、皆様の仕事を支える道具であると同時に、50 年の知的旅路の最新章 でもあるのです。

関連情報
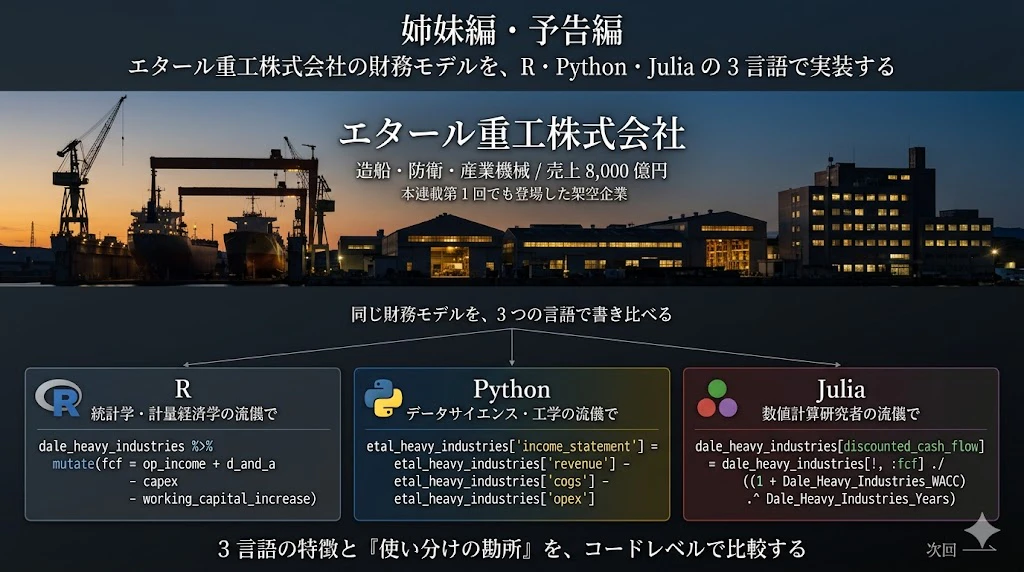
姉妹編の予告 ── 3 言語による財務モデリング実装記事
本記事の 姉妹編 として、本記事執筆者は近日中に以下の記事を公開済みです。
「R・Python・Julia の 3 言語で、エタール重工株式会社の財務モデリングを書いてみる」(仮題、近日公開)
本記事では、3 つの DataFrame の 歴史と系譜 を辿りましたが、姉妹編では、3 つの DataFrame を使って 実際に同じ財務モデルを書き比べる ことに取り組みます。
題材は、エタール重工株式会社(造船・防衛・産業機械を含む総合重工、売上規模 8,000 億円)── 本連載第 1 回でも登場した架空企業です。同社の 3 表連動財務モデル(損益計算書、貸借対照表、キャッシュフロー計算書)を、
-
R(
data.frame+dplyr):統計学者・計量経済学者の流儀で - Python(pandas + NumPy):データサイエンティストの流儀で
- Julia(DataFrames.jl + Statistics.jl):数値計算研究者の流儀で
の 3 通りで実装 し、それぞれの言語の特徴と、財務モデリングという文脈での「使い分けの勘所」を、コードレベルで比較します。
(2026/5/16 追記)
姉妹編(後編)の記事を公開致しました。以下がその記事になります。
本記事で歴史的系譜を理解いただいた皆様には、姉妹編の 実装比較 を、より深く楽しんでいただけるはずです。
本記事執筆者の他の Qiita 記事
本記事執筆者は、データサイエンス・経済安全保障・金融データ分析の交差領域で、複数の記事を Qiita で公開しています。
参考文献・出典
- John Chambers (2008). Software for Data Analysis: Programming with R. Springer.
- John Chambers & Trevor Hastie (1992). Statistical Models in S. Wadsworth & Brooks/Cole.
- Wes McKinney (2022). Python for Data Analysis, 3rd Edition. O'Reilly Media.
- Wes McKinney 公式ブログ: https://wesmckinney.com/about
- DataFrames.jl 公式ドキュメント: https://dataframes.juliadata.org/
- Bogumił Kamiński, Milan Bouchet-Valat ほか (2023). DataFrames.jl: Flexible and Fast Tabular Data in Julia. Journal of Statistical Software.