はじめに
まとめると趣味の出費を可視化して分析してみよう、という話です。
なぜそんなことをしようとしたかは長くなるので省略します。
アプリケーションにはKibana, Elasticsearch, Logstashを使用することにします。
いろいろあって複雑そうに見えますが、これらは、セットで扱うことが多いようです。(ー> ELK Stack)
Kibanaとは
ビジュアライゼーションツール。Elasticsearchのデータを可視化することができる。
Webサーバとして起動する。
Elasticsearchとは
全文検索エンジン・データベース。
Logstashとは
ログ収集ツール。コマンドラインから実行可能。
インストール
公式サイトからダウンロードして展開します。
Elastic · Revealing Insights from Data (Formerly Elasticsearch) | Elastic
今回は以下の環境で試しました。
- Windows7 64bit
- Elasticsearch 6.0.0
- Kibana 6.0.0
- Logstash 6.0.0
ElasticsearchとKibanaの起動と確認
Elasticsearchの起動
> elasticsearch\bin\elasticsearch.bat
デフォルトで9200,9300ポートで起動します。
Kibanaの起動
>kibana\bin\kibana.bat
デフォルトでポート5601で起動します。
確認する
5601ポートでKibanaにアクセスします。
画面が表示できればOKです。
入力データ
入力データはcsvで用意しました。
例えば、「12月12日にSphereのチケットを1,000で購入した」という場合は、以下のようなcsvとしました。
1,2017/12/12,1000,チケット,Sphere
先頭の数値はシーケンス的なユニークのIDです。
Logstashを設定する
次はLogstashの設定を行います。
Logstashは[入力]-[変換]-[出力]といった、ストリーミング的な設定をyamlですることができます。
ここではCSVデータを入力、Elasticsearchに出力にします。
○inputのブロック
指定のディレクトリ内のファイルを対象にします。
sincedb_pathはどこまで読み込んだかを管理するファイルが保存されるパスです。
csvファイルはExcelで作成しているため、Shift-JISとしました。
input {
file {
path => ["H:/01_daily/20171202/data/*"]
sincedb_path => "H:/01_daily/20171202/sincedb"
start_position => "beginning"
codec => plain {
charset => "SJIS"
}
}
}
○filterのブロック
読み込んだcsvを処理します。
columnsでcsvの各カラムに名づけをします。
変換処理として、日付と金額の型変換を行っています。
filter {
csv {
columns => ["id", "date", "value", "category1", "category2"]
convert => {
"value" => "integer"
}
}
date {
match => ["date" , "yyyy/MM/dd"]
}
}
○outputのブロック
elasticsearchに出力します。
indexはいわゆるRDBにおけるテーブル名、document_idはPKとなります。
接続ホストはデフォルトでlocalhost:9200となるため、省略しています。
output {
elasticsearch {
index => "expenses"
document_id => "%{id}"
}
}
まとめると以下のようになります。
ファイル名をwotaku.confとしました。
input {
file {
path => ["H:/01_daily/20171202/data/*"]
sincedb_path => "H:/01_daily/20171202/sincedb"
start_position => "beginning"
codec => plain {
charset => "SJIS"
}
}
}
filter {
csv {
columns => ["id", "date", "value", "category1", "category2"]
convert => {
"value" => "integer"
}
}
date {
match => ["date" , "yyyy/MM/dd"]
}
}
output {
elasticsearch {
index => "expenses"
document_id => "%{id}"
}
}
データを投入する
Logstashを起動してelasticsearchにデータを投入します。
以下のコマンドを実行すると、設定ファイルで設定したディレクトリを監視してデータを投入します。
≫ \bin\logstash.bat -f .\wotaku.conf
ディレクトリのファイルに追記したり、ファイルを作成したら数秒で反映されます。これは便利ですね!
kibanaで可視化する
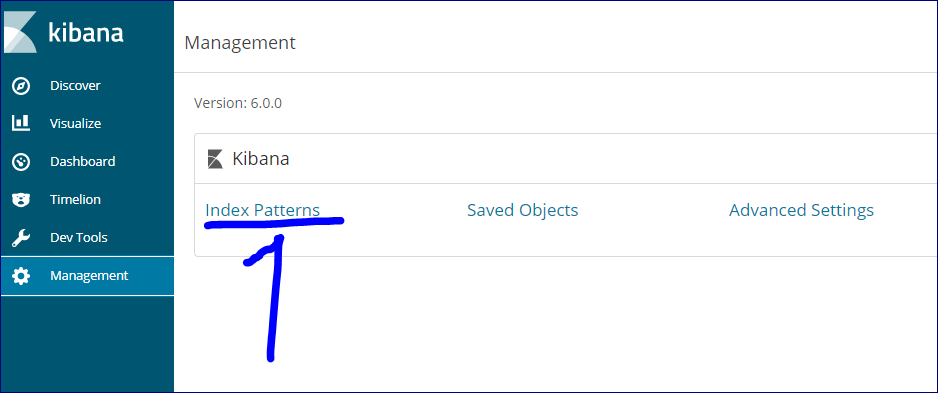
まずはkibanaにindexの設定をします。
http://localhost:5601 から、左側のメニューの「Management」-「Kibana」-「Index Pattern」を選択し、indexを追加します。
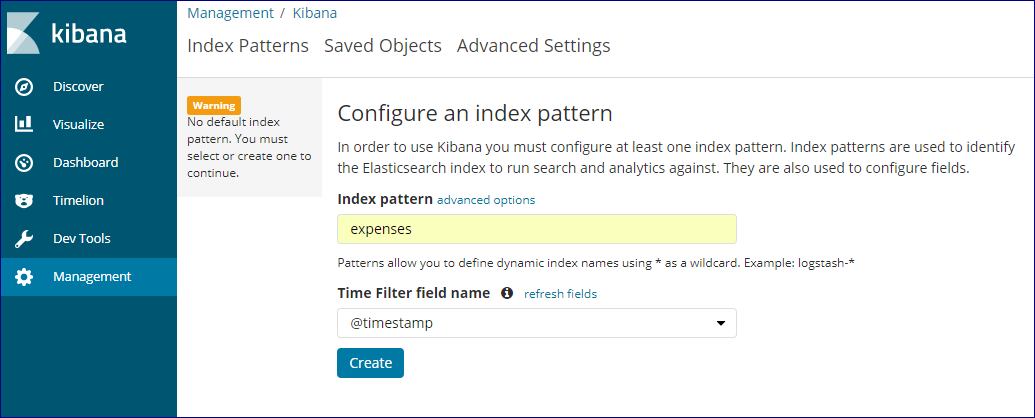
Index patternに設定ファイルで指定した「expenses」を選択して、「Create」します。
「Time Filter field name」はデフォルトの@timestampとします。
これはメタデータの時刻となるフィールドを指定しておきます。デフォルトではデータ投入時刻になります。
今回は明示的に@timestampというフィールドは作成していませんが、データ投入時刻ではなく、csvのdateカラムとなります。
filterでdate変換した場合、その値が@timestampに設定されるためです。
次はパーツを作成します。
左側のメニューから「Visualize」-「+」アイコンを選択します。
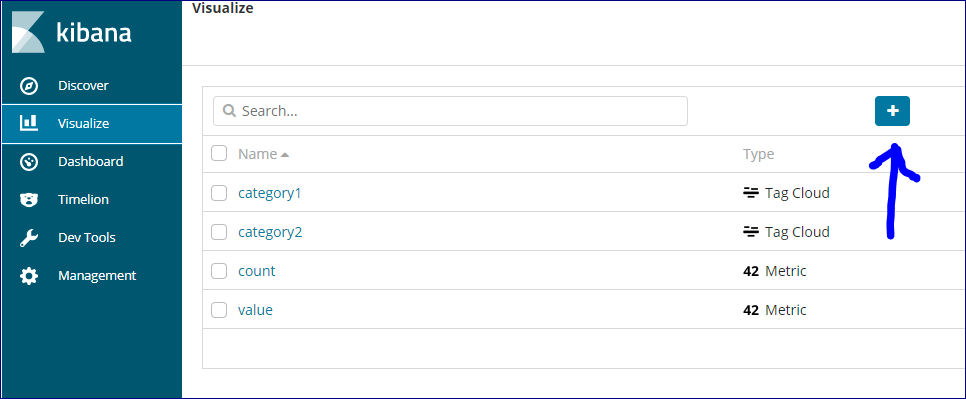
様々なパーツが選択できます。
ここでは、以下の4つのパーツを作成することにします。
- Metric - データ件数
- Metric - 金額合計
- Tag Cloud - カテゴリ1のタグクラウド
- Tag Cloud - カテゴリ1のタグクラウド
この辺はGUIなので、いろいろ試してプレビューしてみるのが良いかと思います。
続いて作成したパーツをまとめて表示するダッシュボードを作成します。
左のメニューから「Dashboard」を選択して同様にAddしていきます。
これもGUIで配置できます。
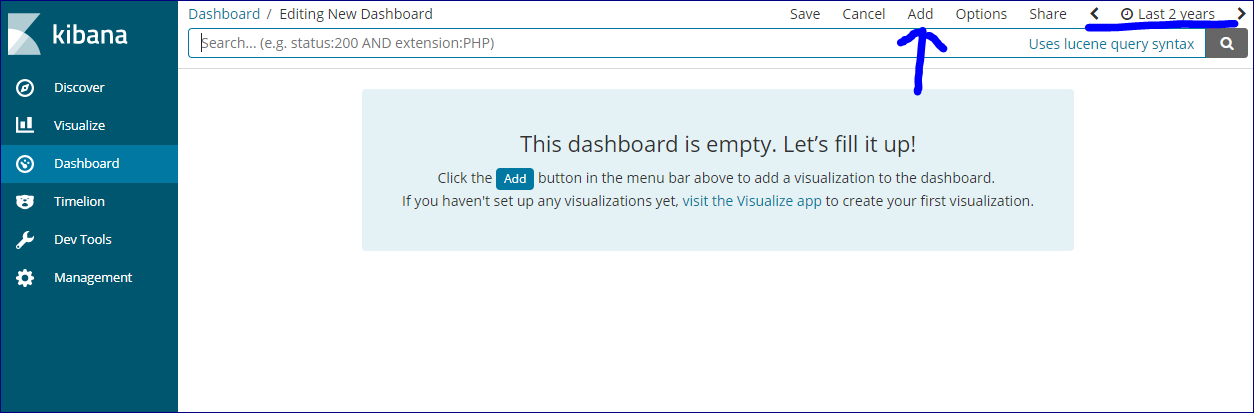
ここで注意するのが画面右上の時間の部分です。
これは対象とする@timestampの範囲を示しています。
これを目的の範囲が含まれるように変更しないと、データが表示されず、データの投入に失敗している?など悩むことになります。
結果
金額は伏せてみました。

ひぇぇ。
今年の出費はどうやらシンデレラガールズに一番使ったようです。
Sphereだと予想してたのですが。
しかし、シンデレラガールズとcategory1の写真集はイメージできませんね。そこで「シンデレラガールズ」の文字をクリックしてみます。

ライブ、グッズ、フィギュアあたり。心当たりありますね。
ゲームが出てきていないので気づいてしまいましたが、google playの出費は入力データに含めるのを忘れました。
写真集はいろいろな人で分散されるので、category2には出てきてないということでしょう。
わりと技術書にもお金を使っていますね。
などなど中々面白いです。
まあでも、頭痛いです。
おわりに
というわけで、ELK Stackを使用してオタクの出費を可視化してみました。
Kibanaのビジュアライゼーションは便利です。
とはいえ、設定のUIの操作感はあまり良くないように思いました。慣れが必要です。
あと、全体としてELK Stack自体の管理ツールがあるとよいですね。
有償verならできるのでしょうか。
Logstashはちょっと難しいです。
今回は入力データを扱いやすいように作ってしまいましたが、実際は好き勝手に作られたフォーマットのデータの加工をすることになると思います。
そのときにかなり大変になることが予想できます。
ウィザードによるスケルトン作成などが欲しいところです。
おわりだよ~