クリスマスまで後10日と迫りました。
MySQL Casual Advent Calendar 2016 の15日目です。
ご挨拶
はじめまして。
eshimizuです。
新卒入社の会社でMySQLを触り始め、4年目になる今に至るまでMySQL以外を扱って来ませんでした。MySQL以外何も知らない雑魚です。やさしくしてください。
去年くらいからMySQLのコードを覗きはじめたので、そのあたりの話をゆるく書いていこうと思います。
※MySQL中級者以上の人にとっては、当たり前だったり悪手だったりするかもしれないので、悪手だった場合は「やさしく」良い手法を教えてください。
コードを読みたいのに読めない葛藤
MySQLを使っている人であれば、一度くらいは見てみたいなと思ったことはあると思います。
私もそれについては薄々感じていたのですが、具体的にどうすればよいのか分からず、挫折挫折のオンパレードで全然読むことは出来ませんでした。
- コードの入手場所がすぐに見つからず挫折(なんとなく見ようと思ったとき)
- コードを展開してその量に圧倒されて挫折(初めての挫折から数ヶ月)
- 自分のコードリーディングのセンスのなさに挫折(2度目の挫折から数週間)
これが覚えている挫折リストです。
他にも何度かチャレンジしたことがあったような気がしますが、幾度と無く読もうと思ってはあきらめてを繰り返してました。
このあたりは、個々のレベルに応じてだと思いますが、私の場合はソースコードがある場所が分からずというレベルからスタートしていたので、多くのエンジニアさんにとってはこのあたりは障害にはならないと思います。
でも、同じような悩みを持つエンジニアも必ずいると信じて、そこからのやり方を本記事では記載していきます。
コードの入手
まずはダウンロードページに行って、MySQL Community Serverを押下します。
※gitから取ってもいいと思いますが、当時の私はgitにあることを知りませんでした。
すると、以下のような画面があると思うので、Select PlatformのプルダウンをデフォルトのMicrosoft WindowsからSource Codeにします。(赤枠で囲った部分です)
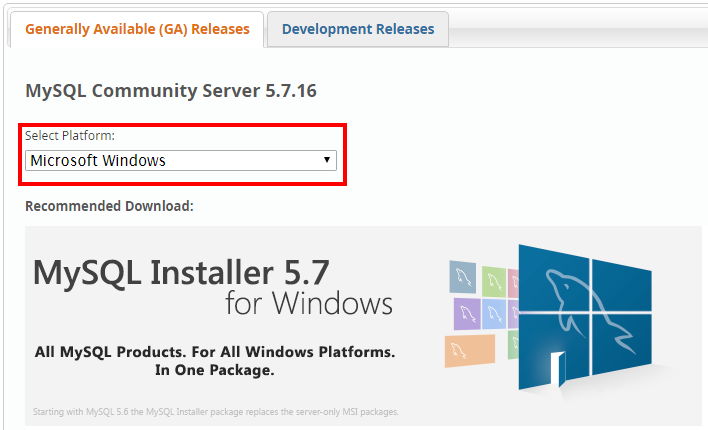
その後は、各環境に合わせたパッケージがあるので、好きなものをダウンロードしてください。
私はGeneric Linux (Architecture Independent), Compressed TAR Archiveを選択しますが、windows向けだとzipもあるので手元のPCでお手軽に見るのであればそちらでも良いと思います。
ちなみに、私のノートPCでは展開時にはこうなって結構時間掛かります。
tarの方については、会社の検証環境に展開します。
$ tar -xvf mysql-5.7.16.tar.gz
展開すると、mysql-5.7.16というディレクトリが出来ていて、その中にMySQLの全てが詰まっています。
どこから読むか
私が詰まったところとして、コードが大量にあってどう読んでいいか分からなかったという問題があります。人間は持ってる能力以上のことはできないので、私にとっては大問題でした。
ディレクトリにはそれらしい意味ありげな名前がついているので、そこから読んでみようと思っても中には大量のコード、ファイルがあって雑魚には読めません。
なので、私はgrepを利用して自分の知っている単語を引っ掛けるという方法で徐々にスタートしていきました。
初めてのgrepではBarracudaを引いたので、それを例にやって見ます。
Barracudaを引こうと思ったのは、イッテQでバラクーダトルネードのカレンダー特集をやっていたのを見て思いついたからです。
初grepの時にはBarracudaがどこら辺に入っているかのあたりを付けられなかったので、mysql-5.7.16ディレクトリ直下でgrepしていました。
今の私はstorageエンジンという言葉を知っていて、さらにBarracudaはinnodbに関わるものであるということも知っているので以下のコマンドでgrepします。少しは賢くなってますね。
$ cd mysql-5.7.16
$ $ grep -r "Barracuda" storage/innobase/
storage/innobase/fsp/fsp0fsp.cc: /* Barracuda row formats COMPRESSED and DYNAMIC use a feature called
storage/innobase/handler/ha_innodb.cc:static const char* innodb_file_format_default = "Barracuda";
storage/innobase/handler/ha_innodb.cc: file_format=Barracuda unless there is a target tablespace. */
storage/innobase/include/dict0dict.ic: /* Barracuda row formats COMPRESSED and DYNAMIC both use
storage/innobase/include/dict0dict.ic: /* Barracuda row formats COMPRESSED and DYNAMIC build on
storage/innobase/include/dict0mem.h:Barracuda row formats store the whole blob or text field off-page atomically.
storage/innobase/include/dict0mem.h: 3072 for Barracuda table */
storage/innobase/include/dict0mem.h:Barracuda row formats COMPRESSED and DYNAMIC, the length could
storage/innobase/include/fsp0types.h:to the two Barracuda row formats COMPRESSED and DYNAMIC. */
storage/innobase/include/univ.i: /** Barracuda File Format: Introduced in InnoDB plugin for 5.1:
storage/innobase/row/row0row.cc: clustered index record. In the Barracuda format, also
storage/innobase/row/row0row.cc: /* In the Barracuda format
storage/innobase/trx/trx0sys.cc: "Barracuda",
こんな感じにヒットしたので、いくつか見ていきます。
// ファイルフォーマットのデフォルトはBarracudaのようです
storage/innobase/handler/ha_innodb.cc:static const char* innodb_file_format_default = "Barracuda";
// ファイルフォーマットは未来の分まで予約済み
$ less storage/innobase/trx/trx0sys.cc
<SNIP>
/** List of animal names representing file format. */
static const char* file_format_name_map[] = {
"Antelope",
"Barracuda",
"Cheetah",
"Dragon",
"Elk",
"Fox",
"Gazelle",
"Hornet",
"Impala",
"Jaguar",
"Kangaroo",
"Leopard",
"Moose",
"Nautilus",
"Ocelot",
"Porpoise",
"Quail",
"Rabbit",
"Shark",
"Tiger",
"Urchin",
"Viper",
"Whale",
"Xenops",
"Yak",
"Zebra"
};
<SNIP>
MySQLを作った人たちは、いったいいくつまで実現すると考えていたのでしょうか。かなり大量に予約してあるみたいです。
この中ではDragonだけなぜか空想の生き物です。
どうせなら伝説のラスボス的ポジションとして、最終形態最強のファイルフォーマットDragonみたいな位置づけにして欲しかったです。
この並びだとオレが生きている内にDragonには出会えてしまいそうで、あまり夢が無いですね。
もっと簡単に読む
ソースコードを配置して、grepするなりディレクトリ名から当たりを付けて読んでいくなりということは、ここまでくれば出来るようになったと思います。
この記事を書こうと思ったときにはここがゴールでしたが、もう少し書いてみようという気持ちになったので、自分がコードを読むときに大いにお世話になっているツールを紹介して終わりにしたいと思います。
opengrok
http://opengrok.github.io/OpenGrok/
これは、ソースコードを読むための検索エンジンみたいなやつらしいです。
無論、かつてソースコードを読むのに何度も挫折した男がいきなりこんなツールを使い始められるわけは無く、会社の先輩がコードリーディング用にセットアップしてくれた環境があったので、そこにどんどん読みたいものをぶち込ませてもらってます。
これは全文検索だったりパラメータで引っ掛けられるので、エラーメッセージの文言や番号入れてみたり、気になるパラメータとか入れてみるとその周辺にたどり着けるようになります。
これが使えるようになってから、コードを読むためのハードルがすごく低くなったので助かりました。
先日もLabのGroup Replication(12/12に5.7GAに入って来ましたね)を使おうとしたらなぜかうまくいかず、少しソースコードを探して修正したらうまくいったという場面にも出くわしました。
全てopengrokが教えてくれたことです。感謝。
来年の目標
今年はコードの読み方を記事にしたので、来年はプルリクを出す話を記事にできたら良いなと考えています。
そのためには、コードをもっと読んで改善出来る発見する能力が求められるので、これから1年間かけて少しずつコードを読んでいく機会を増やしていきます。
コーディングが尋常じゃなく下手糞なので、人様に見せても恥ずかしくないコードを書く練習もしていきます。
まとめ
今回は、私がソースコードを読もうと思ってから実現するまでに挫折したポイントを乗り越えられるように記事を投稿しました。
やることは単純2STEP(より深く読んで行きたい人は3STEP)
- まずは、コードを準備
- 気になる単語をgrep
3. 対象のコードを好きなように見る - もっと読んでみたいと思ったらopengrokの準備
コードを読みたい・見てみたい気持ちはあるのに、読み方が分からない、そもそもどうしたら良いかわからない。
そんな人に対して、ハゲたサンタさんからの素敵なクリスマスプレゼントになってくれることを祈ります。
明日はyebiharaさんです。