はじめに
今回は文部科学省のページで公開されている情報Ⅰの教員研修用教材の「質的データの分析」についてみていきたいと思います。
ここでは、MeCabによる形態素解析とWordCloudをRで実装する例が書かれています。
今回はその内容をpythonに置き換えていきたいと思います。
教材
高等学校情報科「情報Ⅰ」教員研修用教材(本編):文部科学省
第4章情報通信ネットワークとデータの活用・巻末 (PDF:10284KB) PDF
環境
- ipython
- Colaboratory - Google Colab
概要
今回は、「情報Ⅰ」教員研修用教材の「第4章情報通信ネットワークとデータの活用・巻末」について、
学習23 質的データの分析
のRの箇所をpythonに書き換えたいと思います。
テキストマイニングについて
1 形態素解析について
pythonのソースコード
MeCabを使えるように前準備します。
(2020/07/24 16:30追記)
mecab-python3の作者様から、古いバージョン(0.7)を使っているという指摘を頂きました。
最新のバージョン(1.0.1)に変更しています。
- mecab-python3 (1.0.1)
- unidic-lite (1.0.6)
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3
!pip install unidic-lite
形態素解析を行います。
import MeCab #MeCabを読み出す
# 形態素解析を行う
tagger = MeCab.Tagger()
parse_str = tagger.parse('隣の客はよく柿食う客だ')
print(parse_str)
pythonによる出力結果
隣 トナリ トナリ 隣り 名詞-普通名詞-一般 0
の ノ ノ の 助詞-格助詞
客 キャク キャク 客 名詞-普通名詞-一般 0
は ワ ハ は 助詞-係助詞
よく ヨク ヨク 良く 副詞 1
柿 カキ カキ 柿 名詞-普通名詞-一般 0
食う クー クウ 食う 動詞-一般 五段-ワア行 連体形-一般 1
客 キャク キャク 客 名詞-普通名詞-一般 0
だ ダ ダ だ 助動詞 助動詞-ダ 終止形-一般
EOS
[参考]Rのソースコード(教材より)
Library(RMeCab)
unlist(RMeCabc(“ 隣の客はよく柿食う客だ ”))
### [参考]Rによる出力結果
> ```console
名詞 助詞 名詞 助詞 形容詞 名詞 動詞 名詞 助動詞
" 隣 " " の " " 客 " " は " " 良く " " 柿 " " 食う " " 客 " " だ ”
2 形態素の出現頻度
pythonのソースコード
from collections import Counter
import urllib.request
import zipfile
import os.path,glob
import re
# 「杜子春」をx に読み込む
url = 'https://www.aozora.gr.jp/cards/000879/files/43015_ruby_17393.zip'
# zipファイル保存名
file_path = 'temp.zip'
with urllib.request.urlopen(url) as dl_file:
with open(file_path, 'wb') as out_file:
out_file.write(dl_file.read())
with zipfile.ZipFile(file_path) as zf:
listfiles = zf.namelist()
zf.extractall()
os.remove(file_path)
# shift_jisで読み込み
with open(listfiles[0], 'rb') as f:
text = f.read().decode('shift_jis')
# ルビ、注釈などの除去
text = re.split(r'\-{5,}', text)[2]
text = re.split(r'底本:', text)[0]
text = re.sub(r'《.+?》', '', text)
text = re.sub(r'[#.+?]', '', text)
text = text.strip()
tagger = MeCab.Tagger()
# 初期化しないとエラーになる
tagger.parse("")
node = tagger.parseToNode(text)
word_list_raw = []
result_dict_raw = {}
while node:
#詳細情報を取得
word_feature = node.feature.split(",")
#単語を取得(原則、基本形)
word = node.surface
#品詞を取得
word_class = word_feature[0]
fine_word_class = word_feature[1]
if (word not in ['', ' ','\r', '\u3000']):
#wordリスト
word_list_raw.append(word)
result_dict_raw[word] = [word_class, fine_word_class]
#次の単語に進める
node = node.next
freq_counterlist_raw = Counter(word_list_raw)
dict_freq_raw = dict(freq_counterlist_raw)
print('length =' ,len(dict_freq_raw))
print('Term','Info1','Info2','Freq')
for item in list(dict_freq_raw.keys())[:6]:
print(item, result_dict_raw[item][0], result_dict_raw[item][1], dict_freq_raw[item])
pythonによる出力結果
length = 1157
Term Info1 Info2 Freq
一 名詞 数詞 34
或 連体詞 * 2
春 名詞 普通名詞 3
の 助詞 格助詞 334
日暮 名詞 普通名詞 1
です 助動詞 * 47
コメント
pythonのMecabモジュール等を使ったため、RのRMeCabFreq()をうまく再現できませんでしたが、
概ねやりたいことは実現できたかと思います。
なお,Aozora 関数は RMeCab の作者である徳島大学の石田基広先生が提供している。
というのが、Rにはあるので解析するだけの目的であるならば、Rのほうが向いている気がします。
[参考]Rのソースコード(教材より)
library(dplyr)
source(“http://rmecab.jp/R/Aozora.R”)
x<-Aozora(“https://www.aozora.gr.jp/cards/000879/files/43015_ruby_17393.zip”)
glove<-RMeCabFreq(x)
> ```R
glove %>% head()
[参考]Rによる出力結果
file = ./NORUBY/toshishun2.txt
length = 1150
> ```console
# Term Info1 Info2 Freq
# 1 あの フィラー * 1
# 2 いいえ 感動詞 * 1
# 3 おお 感動詞 * 2
# 4 こら 感動詞 * 3
# 5 さあ 感動詞 * 1
# 6 はあ 感動詞 * 1
3 形態素解析(大分類の中から名詞と動詞を選択し,細分類から数,非自立,接尾にあたる用語を除外)
pythonのソースコード
extra_result_list = []
for k, v in dict_freq_raw.items():
if (result_dict_raw[k][0] in ['名詞', '動詞']) and (result_dict_raw[k][1] not in ['数', '非自立', '接尾']):
extra_result_list.append([k, result_dict_raw[k][0], result_dict_raw[k][1], v])
print('Term','Info1','Info2','Freq')
for item in extra_result_list[:6]:
print(item[0],item[1],item[2],item[3])
pythonによる出力結果
Term Info1 Info2 Freq
一 名詞 数詞 34
春 名詞 普通名詞 3
日暮 名詞 普通名詞 1
唐 名詞 固有名詞 1
都 名詞 普通名詞 6
洛陽 名詞 固有名詞 9
[参考]Rのソースコード(教材より)
Subset 関数を使うと,選びたい品詞,除外したい品詞を指定することができる。以下では,大分類の中から名詞と動詞を選択し,細分類から数,非自立,接尾にあたる用語を除外している。
glove2 <- subset(glove,Info1 %in%c(" 名詞 "," 動詞 "))
glove3 <- subset(glove2,!Info2 %in%c(" 数 "," 非自立 "," 接尾 "))
glove3 %>% head()
### [参考]Rによる出力結果
> ```console
# Term Info1 Info2 Freq
# 149 あく 動詞 自立 1
# 150 ある 動詞 自立 18
# 151 いう 動詞 自立 3
# 152 いえる 動詞 自立 1
# 153 いる 動詞 自立 11
# 154 かいつまむ 動詞 自立 1
4 形態素解析(単語の出現頻度順にソート)
pythonのソースコード
語の出現頻度順にソートする際は,以下のようにする。
extra_result_sorted_list = sorted(extra_result_list, key=lambda x:x[3], reverse=True)
print('Term','Info1','Info2','Freq')
for item in extra_result_sorted_list[:6]:
print(item[0], item[1], item[2], item[3])
pythonによる出力結果
Term Info1 Info2 Freq
杜 名詞 固有名詞 66
子春 名詞 固有名詞 66
し 動詞 非自立可能 50
い 動詞 非自立可能 44
いる 動詞 非自立可能 42
一 名詞 数詞 34
コメント
出現回数が違っているのが気になりますが、概ねやりたいことはできたように思います。
Rのソースコード(教材より)
glove4 <- glove3[order(glove3$Freq,decreasing=T),]
glove4 %>% head()
### Rによる出力結果
> ```console
# Term Info1 Info2 Freq
# 741 春 名詞 一般 69
# 831 杜 名詞 一般 67
# 163 する 動詞 自立 61
# 179 なる 動詞 自立 31
# 244 見る 動詞 自立 25
# 929 老人 名詞 一般 22
5 WordCloud作成
pythonのソースコード
wordcloudと日本語フォントを読み込めるようにします。
!pip install wordcloud
!apt-get -y install fonts-ipafont-gothic
matplotlibで日本語フォントを使用するには、下記lsコマンドでキャッシュの位置を確認後、rmコマンドで削除を行います。
!ls -ll /root/.cache/matplotlib/
!rm /root/.cache/matplotlib/fontlist-v310.json
ランタイムの再起動を行ったあと、wordcloudを作成します。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import numpy as np
import pandas as pd
wordcloud_list = []
plot_list = []
# 抽出リスト
for item in extra_result_sorted_list:
if item[3] >= 9:
wordcloud_list.append(item[0])
plot_list.append(item)
# リストを文字列に変換
word_chain = ' '.join(wordcloud_list)
f_path = '/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf'
jp_font = {'fontname':'IPAGothic'}
nplist = np.array(plot_list)
nplist = np.flipud(nplist)
x_params = list(nplist[:,0])
y_params = list(nplist[:,3])
y_params = [float(s) for s in y_params]
x = np.arange(len(x_params))
width = 0.8
fig, ax = plt.subplots()
rect = ax.barh(x, y_params, width, align="center")
ax.set_yticks(x)
ax.set_yticklabels(x_params, **jp_font)
plt.savefig('img1.png')
plt.show()
# regexp = r"[\w']+"にしないと入れないと、春などの一文字の単語が表示できない。
# デフォルトはr"\w[\w']+"
wc = WordCloud(width=800, height=600, background_color="white", relative_scaling = 0, regexp = r"[\w']+", font_path=f_path)
wc_g = wc.generate(word_chain)
plt.figure(figsize=(12,10))
plt.imshow(wc_g)
plt.axis('off') #メモリの非表示
plt.savefig('img2.png')
plt.show()
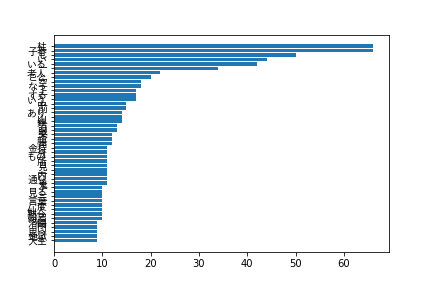
pythonによる出力結果

コメント
グラフを適当に出力させたので、もっと見やすくする必要はありそうです。
WordCloudは、引数のregexpを指定しないと、一文字の文字がWordCloudに表示されないので注意する必要があります。デフォルト値では、英単語でアルファベット2文字以上のものをWordCloudに取り込むようになっていますが、日本語は一文字で意味を持つものがたくさんあるため、一文字の単語もWordCloudに表示できるようにする必要があります。
あと辞書の差からか教材のほうでは杜子春から春として単語を切り出していますが、今回のpythonのコードでは杜子春から子春として単語を切り出している点の違いなどがありそうです。
[参考]Rのソースコード(教材より)
さらに,R で出現頻度のグラフと出現頻に応じた文字の大きさで単語を表示するワードクラウドを作成することによって,テキストデータの可視化を行ってみよう。グラフを描くためには ggplot2,ワードクラウドを作成するためには wordcloud というパッケージのインストールが事前に必要である。
library(ggplot2)
glove4 %>%
filter(Freq >=9) %>%
mutate(Term=reorder(Term,Freq)) %>%
ggplot(aes(Term,Freq))+
geom_col()+
theme_gray(base_family="IPAMincho")+
coord_flip()library(ggplot2)
library(wordcloud)
wordcloud(glove4$Term,glove4$Freq,min.freq=4,color=brewer.pal(8,"Dark2"),family="IPAMincho")
### [参考]Rによる出力結果
> 
# ソースコード
https://gist.github.com/ereyester/5f1a93311f434b08f1e57fda4fb5398f