この記事は2019新卒 エンジニア Advent Calendar 2019の4日目の記事です。
エンジニアとして働くなかで知ったService Meshという設計思想が大変興味深かったので、概要を自分の言葉で説明してみるとともに、簡単なService Meshを作成してみることで知ってもらおうという記事です。
Service Meshの概要
Service Meshって?
Service Meshとはネットワーク周りのゴニョゴニョをアプリケーションのレイヤーから別のレイヤーに移してよろしくやりたいね。という設計思想です。そうじゃないかもしれません。正直、新しい分野ですし、istioやlinkerdといったService Meshを謳うプロダクトのこれから次第な感じではあると思います。ですが、今回はこれくらいの定義で行きたいと思います。
ネットワーク周りの処理のゴニョゴニョの例としては以下のようなものがあります。
- リトライ
- ルーティング
- カナリーデプロイ
- ABテスト
- 障害注入
- サーキットブレイカー
- 相互TLS通信
- ロギング
どうやって実現するの?
Service Meshはデータプレーンとコントロールプレーンの2つから構成されます。
データプレーンとは各アプリケーションに1台ずつ用意されるプロキシのことであり、アプリケーションのIn/Outすべての通信をそのプロキシを経由します。
コントロールプレーンは、データプレーンを操作するためにあり、現在反映されている設定を伝えたり、メトリクスを収集したり、証明書を管理したり等の役割があります。
Service Meshでは、プロキシを用いて諸々の処理をハンドリングします。そのため、アプリケーションはService Meshを意識せずに実装することができます。
具体的にどんなService Meshのプロダクトがあるのかは以下のサイトが参考になりそうです。
プロキシは、kubernetes上では基本的にプロキシ用のコンテナ1つ立ち上げて実現されますが、必ずしもコンテナである必要はなく、物理マシン、VM等で実現することもできます。
Service Meshの何が嬉しいの?
なぜわざわざService Meshを使うのでしょうか。リトライ等の処理であれば、アプリケーション側で実現することもできますし、間にプロキシが挟まる分、通信のlatenctyも悪くなりそうです。また、データプレーン、コントロールプレーンのコンポーネントを管理・運用する手間も増えそうです。
そうしたデメリットを上回りうるメリットとして例えば次のようなものがあります。
- 通信を宣言的に管理することかできる
- たとえば、リトライのための手続きを書くのではなく、3回しろ!と書ける
- 通信周りの変更に際してApplicationのソースコードを変えなくていい
- 上記の通信の処理をするにあたって言語やフレームワークに縛れられる必要がない
- Application自体を落とすさずに変更を反映させることができる
これらをまとめるなら、アプリケーションと通信周りの関係を疎にすることができるというのが、Servish Meshの利点です。
Service Meshは、ネットワークの処理がより重要になってくるMicro Serviceと親和性がありますが、必ずしもMicro Serviceの文脈で語られる必要はなく、モノリシックなアプローチに置いても有効な考え方ということは理解しておいた方が良いでしょう。
Service Meshを作ってみる
もう少しService Meshに触れてみるために簡易的なService Meshを作ってみることにします。筆者がRubyしか書けないため、コンポーネントは全てRubyで書いて、docker-composeを使って動かしていきます。
今回の構成
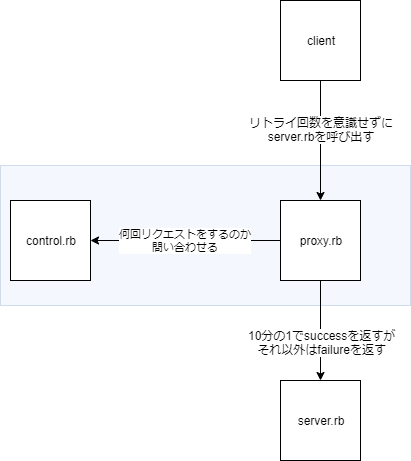
Service Meshを作ってみるために次のような構成を考えてみます。
- success/failureを1:9の割合でbodyに入れてserver.rb
- control.rbから取得した回数だけリトライするproxy.rb
- proxy.rbに対してリトライすべき回数を答えるcontrol.rb
server.rbはアプリケーション側で、proxy.rbとcontrol.rbはService Meshのためのコンポーネントです。通常であれば正しいレスポンスを得るためにリトライする処理は呼び出す側に必要ですが、proxyでその処理を書いていきます。
各ソースコード
require 'webrick'
server = WEBrick::HTTPServer.new({
:Port => 3001
})
server.mount_proc '/' do |req, res|
if rand(10) == 0
puts res.body = "success\n"
else
puts res.body = "failure\n"
end
end
server.start
require 'webrick'
require 'webrick/httpproxy'
require 'uri'
require 'retryable'
require 'net/http'
handler = Proc.new() do |req,res|
retry_count = Net::HTTP.get URI.parse('http://host.docker.internal:3002')
p "retry-setting: #{retry_count}"
Retryable.retryable(tries: retry_count.to_i, sleep: 0) do |retries, exception|
if res.body == "failure\n"
res.body = Net::HTTP.get req.request_uri
raise "error"
else
puts "retry: #{retries}"
end
end
rescue
res.body = "failure\n"
end
s = WEBrick::HTTPProxyServer.new(
:Port => 3000,
:ProxyContentHandler => handler
)
Signal.trap('INT') do
s.shutdown
end
s.start
require 'webrick'
server = WEBrick::HTTPServer.new({
:Port => 3002
})
server.mount_proc '/' do |req, res|
res.body = ENV["RETRY"] || 10
end
server.start
FROM ruby:2.5
RUN apt-get update
WORKDIR /home/ruby
version: '2'
services:
proxy:
build:
context: .
dockerfile: Dockerfile
volumes:
- ./:/home/ruby
- bundle_install:/usr/local/bundle
ports:
- "3000:3000"
depends_on:
- server
command:
ruby proxy.rb
server:
build:
context: .
dockerfile: Dockerfile
volumes:
- ./:/home/ruby
ports:
- "3001:3001"
command:
ruby server.rb
control:
build:
context: .
dockerfile: Dockerfile
volumes:
- ./:/home/ruby
environment:
- RETRY=10
ports:
- "3002:3002"
command:
ruby control.rb
volumes:
bundle_install:
driver: local
上記のような構成を作成することで
curl host.docker.internal:3001 -x host.docker.internal:3000
上記のようにプロキシを経由してリクエストすることで、本来なら10%の成功率のところをリトライした数だけ高い成功率でレスポンスを受け取れるようになります。

考察
今回は簡便のためリクエストする側がプロキシを指していますが、リバースプロキシの形にしてリクエストする側が意識する必要がない方がより正しい形だと思います。
また、リクエストのたびにコントロールプレーンに現在の設定を確認するリクエストを送っていますが、毎回確認するのもリソースの無駄遣いなのでキャッシュをしておくか、変更があったタイミングでpushしてもらうか等の改良の余地が考えられます。
ここらへんのことをよしなにやってくれるのが、istioのようなプロダクトということですね。
参考
https://servicemesh.io/
https://www.oreilly.com/library/view/istio-up-and/9781492043775/