近年の自動運転やロボット制御の分野では
- 現実世界での試行は高コストかつ危険
- AIが安全かつ効率的に学習するには,シミュレーションや仮想環境での学習が不可欠
そこで注目されているのが 世界モデル(World Models) です.
1. 基礎となる「World Models」
世界モデルとは?
- 定義
世界モデルとは,エージェントが環境のダイナミクスを内部で予測できるモデルのことです.
人間が頭の中で「これをしたら,こうなるであろう」と未来の状態を想像するようにAIがデータから学習した「内部シミュレータ」と考えると分かりやすいです. - 注目される理由
1. 現実環境での高コストな試行を減らせる
2. 強化学習のサンプル効率を大幅に改善できる
3. ロボット制御や自動運転など、現実で試行が難しい分野への応用が可能
World Modelsの構成要素
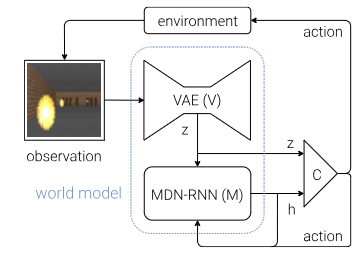
(この画像は World Models論文の図8 から引用)
World Modelsは、主にV(Vision Model),M(Memory Model),C(Controller Model)の3つのコンポーネントで構成されている.
1. V (Vision Model - 視覚モデル)
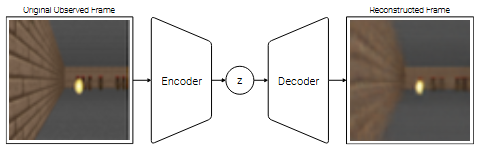
(この画像は World Models論文の図5 から引用)
VモデルにはVariational Autoencoder(VAE) が用いられている.VAEは単に入力された情報(画像)を圧縮するだけでなく,潜在空間を確率分布として学習する.これにより,入力データに多少のノイズや変動があってもそれに左右されにくい,より安定した特徴量Zを抽出するようになる.
また,VAEは潜在空間を滑らかで連続的になるように整理して学習を行う.この「意味のある」構造化された潜在空間は,後述するMモデルが未来の状態を予測する上で非常に扱いやすい情報となる.
2. M (Memory Model - 記憶モデル)
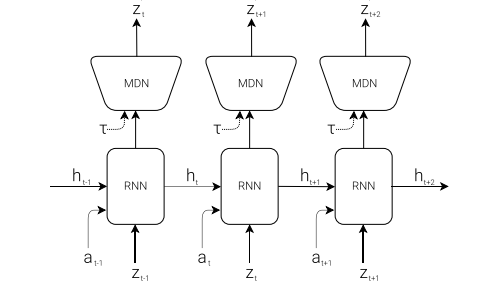
(この画像はWorld Models論文の図6 から引用)
MモデルにはMDN-RNN (Mixture Density Network - Recurrent Neural Network) が用いられる.その役割は,Vモデルが生成した現在の特徴量Zとエージェントが取った行動Aから「次に何が起こるか」を予測することです.これにより,エージェントは環境の動的なダイナミクスを学習し,その予測能力は自身の隠れ状態hに集約されていきます.
MDN-RNNは,RNNによって過去の情報を記憶し(隠れ状態h),MDNによって次の特徴量Z'を単一の値ではなく,複数のガウス分布の混合として確率的に予測します.これにより,未来の不確実性を表現しながら,より柔軟で正確な予測が可能になります.
3. C (Controller Model - 制御モデル)
Cモデル(コントローラー)は,エージェントの意思決定を担います.Vモデルから得られた現在の認識ZとMモデルに蓄えられた記憶(隠れ状態h)を入力として受け取り,期待される累積報酬を最大化するような次にとるべき最適な行動Aを決定します.
この論文では,VとMで構成される世界モデルにエージェントの複雑さの大部分を持たせるため,Cモデルは非常にシンプルな単一層の線形モデルとして実装されている.これにより,行動学習の問題が簡素化され,効率的な訓練が可能となる.
2. Dreamer:世界モデルの革新
そこで登場したのが,本記事の主役である『Dreamer』です.DreamerはWorld Modelsの思想を継承しつつ,行動学習のプロセスを根本から見直し,性能と効率を劇的に向上させた.
Dreamerの核心的なアイデア
Dreamerの核心は,その名の通り「潜在空間の中で夢を見ること(=想像すること)」で行動を学習する点にあります.
学習した世界モデルを単なる未来予測器としてではなく,完全に微分可能なシミュレータとして扱い,その中でActor-Critic法を用いて方策(行動)と価値(評価)を効率的に学習する.
これにより,全てのコンポーネントが勾配法(深層学習で一般的な最適化手法)によってエンドツーエンドで学習可能になり,既存手法のWorld Modelsよりも遥かに効率的で強力なエージェントが実現された.
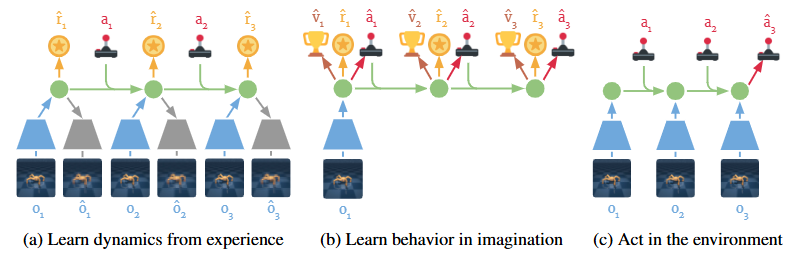
(この画像は Dreamer論文の図3 から引用)
Dreamerの学習プロセスは,大きく分けて以下の3つのパートを並行して実行する.
学習の3つのプロセス
Dreamerは以下の3つのパートを並行して実行します.
-
(a) 世界モデルの学習 (Learning Dynamics)
- 現実世界での経験データから,RSSM (Recurrent State Space Model) と呼ばれる世界モデルを学習します.
- World ModelsではVとMを別々に学習させていましたが,Dreamerではこれらを統合し,画像の圧縮とダイナミクスの予測をEnd-to-Endで学習させることで,より予測に適した表現を獲得します.
-
(b) 想像による行動学習 (Learning Behavior)
- 学習したモデル内で,未来のシミュレーション(想像)を行います.
- この想像上のデータのみを使って Actor-Critic を更新します.ここがDreamerの最も革新的な部分です.
-
(c) 環境との相互作用 (Environment Interaction)
- 学習したActorを使って現実世界で行動し,新たなデータを収集します.
想像による行動学習の詳細
Dreamerの強みである「想像による学習」は,具体的には以下のステップで行われます.
-
想像の開始:
- 過去の経験から得られた潜在状態 $s_t$ をスタート地点とします.
-
行動の予測(Actor):
- 現在の潜在状態 $s_t$ から Actor ネットワークが行動 $a_t$ を予測します.
-
未来の予測(World Model):
- 世界モデルを使い,次の状態 $s_{t+1}$ と報酬 $r_t$ を予測します.
-
想像の連鎖:
- 上記の手順を 15 ステップなど一定期間繰り返し,潜在空間内に完全に想像上の軌跡を生成します.
-
価値の推定(Critic)– $\lambda$-return:
- Criticモデルは各ステップの状態価値 $V(s_t)$ を推定します.
- Dreamer は単純な累積報酬ではなく $\lambda$-return を使用します.
- これは「近い未来の予測報酬」と「遠い未来の価値」をバランス良く混ぜ合わせる方法で,学習の安定化と過度な近視眼性の防止に役立ちます.
-
勾配による更新(Analytic Gradients):
- 計算された価値を最大化できるように,世界モデルの想像プロセスを通して勾配を逆伝播します.
- Actor は「将来の価値を高める行動」を解析的に直接学習でき,従来の強化学習よりきわめて少ないデータで賢い方策を獲得できます.
3. 動作確認
GitHubの以下のリポジトリを参考に動作確認を行いました.
https://github.com/adityabingi/Dreamer/tree/main
実験設定
-
対象タスク:
cartpole-balance(DMC Suite) - 総学習ステップ数: 100,000
- 世界モデルの学習: シーケンス長 50
- 想像(Imagination): ロールアウト長 15
-
学習率: World Model
6e-4,Actor/Critic8e-5
実験結果
学習時・評価時の報酬推移
(上:学習時 / 下:評価時)
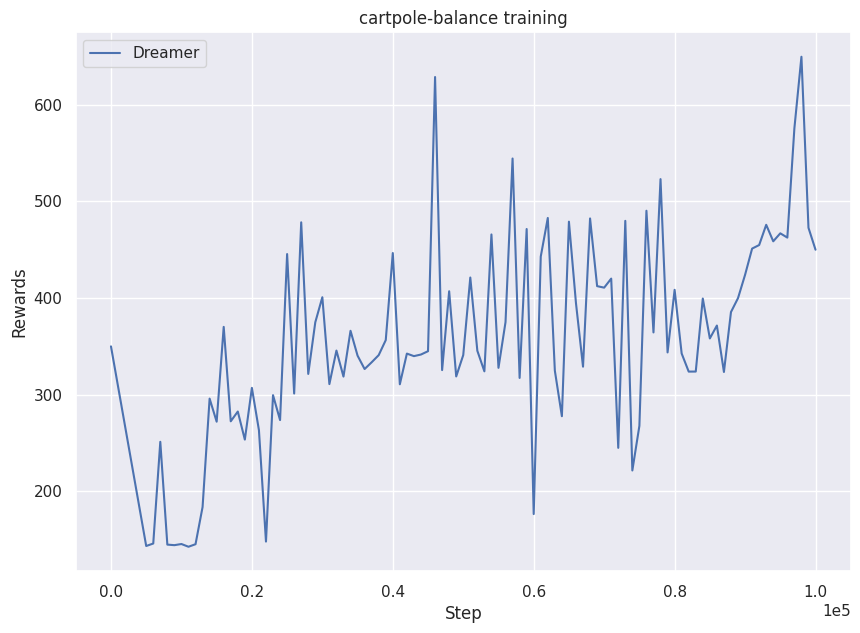
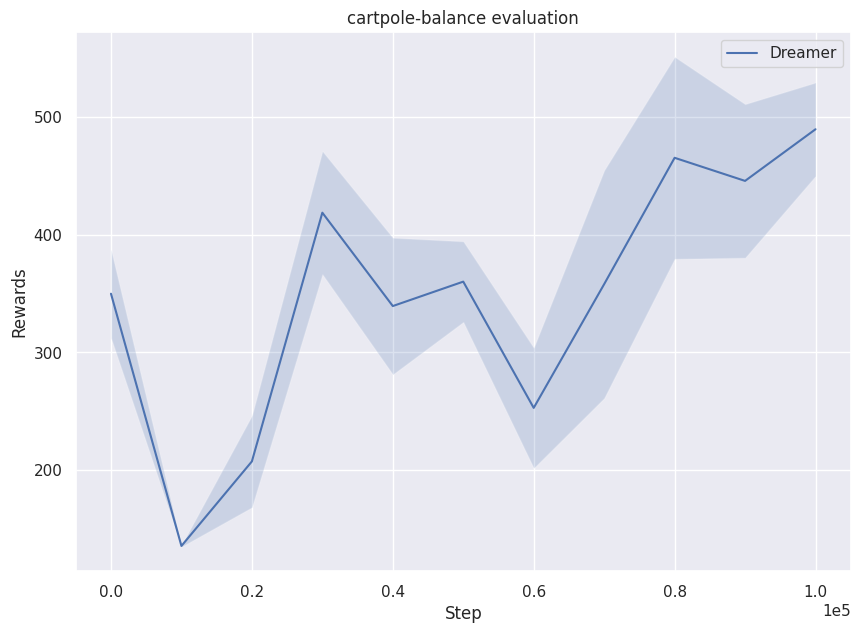
世界モデルによる再構成
以下は,世界モデルが「何を見ているか」の可視化です.

- 上段: 実際の観測画像 (Ground Truth)
- 中段: 世界モデルによる再構成画像 (Reconstruction)
- 下段: 誤差 (Error)
今回の学習ステップ数は少ないですが,9フレーム先程度まではポールの位置や角度を正しく予測できていることが分かります.世界モデルが環境の視覚的特徴とダイナミクスを捉え始めています.
まとめ
World Modelsは「AIが内部にシミュレータを持つ」というパラダイムを提示しました.DreamerはそのモデルをRSSMとして高度化し,潜在空間での「想像」を通じて直接的かつ効率的に行動を最適化することで,複雑なタスクにおいて画期的な成果を上げました.
近年ではDreamer v2,v3とさらに発展しており,Atariのような離散的なゲーム環境でも人間を超えるスコアを記録しています.世界モデルは汎用人工知能(AGI)への重要な一歩と言えるでしょう.
参考文献
World Modelの論文
Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 2.3 (2018).
https://arxiv.org/abs/1803.10122
Dreamerの論文
Hafner, Danijar, et al. "Dream to control: Learning behaviors by latent imagination." arXiv preprint arXiv:1912.01603 (2019).
https://arxiv.org/abs/1912.01603