OOMKillerの殺意
顧客EC2のTomcatがアクセスの無い早朝にもかかわらずOOMKillerに突然殺されてしまったので、調査した顛末をたぶん同じような問題に直面されている方もおられるかと思いますので備忘録として記載します。
Javaヒープのチューニングにも多少役立つかと思います。
(この記事はJava8が対象となります。)
OOMKillerとはOut of Memory時に、サーバ全体を守るためにメモリーを消費しているプロセスを停止するLinuxの標準機能です。
そのOOMKillerになんとTomcatが突然殺害されてしまいました。
問答無用の辻斬り状態です。
早朝ですのでアクセスログには何も記録されておらず、catalina.outには
OpenJDK 64-Bit Server VM warning: Setting LargePageSizeInBytes has no effect on this OS. Large page size is 2048K.
OpenJDK 64-Bit Server VM warning: Failed to reserve large pages memory req_addr: 0x00000006c0000000 bytes: 4294967296 (errno = 12)
というログが記録された直後にOOMKillerが走っていました。
えっLarge Page Memory~???
bytes: 4294967296だと~???
状況が呑み込めないまま、とりあえずfreeコマンドでメモリーを見てみます。
再起動後なので当然空きメモリーには余裕があります。
しか-し、驚愕の事実その1が判明しました。
なんとswap totalが0じゃあーりませんか。
これはAWSのデフォルト設定だそうです。
エラスティックサーバなのでswapなんてまだるっこしいことやってねーで物理メモリー使いや~ってことなのでしょうが、顧客はエラスティックな契約になっていなかったのでOOMKillerさんが発狂して辻斬りに及んだようです。
辻斬りの真相を明かすためJavaの環境変数を確認する
辻斬りの原因の一つはこれでわかったわけですが、まだ肝心の何故Out of Memoryになったのかが解決できていません。
とりあえずTOPコマンドでメモリー使用率降順にソートして動作中のプロセスをチェックします。
その結果、Java以外でウィルスチェッカーのエージェントやらログ収集ツールのエージェントやらで1.6GBのメモリー消費がありました。
ここでついでにJavaのPIDをメモしておきましょう。
(errno = 12)ということでメモリーアロケーションに失敗したことだけは確かなようなので、何か初期設定に問題があるのではと考えました。
まずは環境変数の設定確認です。
setenv.shを開いて確認します。
-XX:NewSize=1024m ・・・・・・・New領域の最小サイズ
-XX:MaxNewSize=1024m ・・・・・・・New領域の最大サイズ
-Xms4096 ・・・・・・・・・・・・・Javaヒープ全体の最小サイズ
-Xmx4096 ・・・・・・・・・・・・・Javaヒープ全体の最大サイズ
-XX:SurvivorRatio=12 ・・・・・・・New領域内の配分比 Survivor領域1に対しEdenは12
-XX:TargetSurvivorRatio=90 ・・・Surviver領域が90%に達したらマイナーGC
-XX:MaxTenuringThreshold=15 ・・・Survivor領域における移動の回数
-XX:LargePageSizeInBytes=256m ・・ラージページを使用するための領域確保
-XX:MetaspaceSize=384m ・・・・・メタスペースサイズ
-XX:MaxMetaspaceSize=384m ・・・メタスペース最大値
ミドルウエアの納入業者が設定し直したようでJavaヒープがTomcatのデフォルト設定値から大きく増やされているようです。
確かにLargePageの設定はありますが、256MBです。
更にjmapでもJavaヒープを確認します。
# jmap -heap [PID]
[PID]にJavaのプロセス番号を入力することでJava Heapの詳細が確認できます。
jmap -heapで見るとsetenvで定義されていないデフォルトの設定も確認できるので全体像がわかります。setenvで未定義だった
-XX:CompressedclassspaceSize=1024m・・・圧縮されたClass領域のデフォルト値
というのが見つかりました。
Javaヒープ全体のサイズは-Xms -Xmxで設定しますので、4GBであることがわかります。
そのうち新しいオブジェクトを格納するNEW領域が-XX:NewSizeで1GBで設定されています。
そのNew領域はEdenとSurvivorに分かれます。
-XX:TargetSurvivorRaioというのがありますが、これがSurvivor領域1に対してのEden領域を決定する倍数となります。
つまり1GBのNEW領域中でSurvivorが1、Edenが12という比率になっていることがわかります。
Old領域は上記の場合、Javaヒープ全体が4GBに設定されていてNew領域が1GBなので、残りの3GBがOld領域ということになります。
Javaヒープに関しておさらい
さてここでJavaヒープについて少しおさらいしておきましょう。
JavaヒープはNew領域とOld領域からなります。
New領域は更にEden領域とSurvivor領域にわかれています。
Survivor領域は更にSurvivor0とSurvivor1からなります。
新規に発生したオブジェクトはまずEdenに入ります。
Edenがいっぱいになったらマイナー・ガベージコレクション(以下GC)が起動して篩いにかけて生きているものをSurvivor0に移します。
またEdenがいっぱいになったらマイナー・GCが起動して今度はSurvivor1に生き残ったオブジェクトを移動します。この時点でSurvivor0は空になります。
このように生き残ったオブジェクトをSurvivor0と1で繰り返し篩いにかけながら-XX:MaxTenuringThreshold で定義された回数移動を繰り返します。
従ってSurvivor領域は2つあっても常にどちらかが空なので1つの空間として見ることができます。そして-XX:MaxTenuringThreshold 回数のGCに耐え抜いて生き残った勇者?が老兵としてOld領域に晴れて移動するのです。
最終的にOld領域が満杯になったらフル・GCがかかってメモリーを奇麗にします。
実はJVMのメモリー領域はJavaヒープだけではありません。
大きくJavaヒープとネイティブヒープに分けることができます。
ネイティブヒープはMetaSpace、ConpressedClassSpace、C Heap、Thread Stackからなります。
ちょっとわかりにくいので箇条書きでまとめてみます。
- Javaヒープ
- New領域・・・新しいオブジェクトを入れる領域
- Eden・・・新規のオブジェクトを入れる領域
- Survivor・・・GCで生き残ったオブジェクトを入れる領域(Survivor0,Survivor1)
- Old領域・・・生き残っている古いオブジェクトを入れる領域(Tenured)
- ネイティブヒープ
- MetaSpace・・・クラスやメソッドなど静的オブジェクトを管理する領域
- ConpressedClassSpace・・・MetaSpace同様静的オブジェクトを格納する領域でデフォルト1GBの容量がとられている。
- C Heap・・・JVM自身のリソースを格納する領域
- Thread Stack・・・静的スレッドを格納する領域
これらのメモリーアロケーションをマップにしたものが下図となります。
ついでに上記環境変数のパラメータを当てはめてみました。
ConpressedClassSpaceはデフォルトで1GB確保するらしいので、そうするとほかの部分を合わせてネイティブヒープだけで2GB近く消費しているのではないかと思われます。
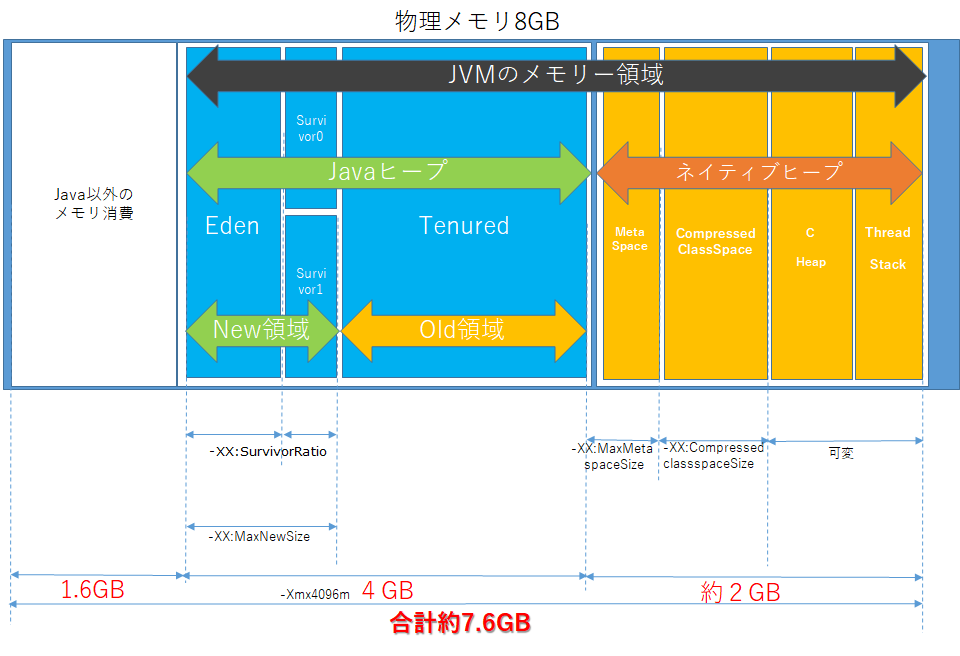
なんだ初期設定の段階でメモリー満杯じゃん。
フルGCが起動する段階ではほぼメモリーがいっぱいの状態になるので、フルGCが勝つか、OOMEが勝つか巌流島の決闘状態になっていたものと思われます。
たぶんフルGCのタイミングでOld領域に積もり積もった老兵が反乱を起こしてOut of Memory Errorが発生したものと思われます。
jstatで確認する
リアルタイムで実際のJavaヒープを確認する方法として手っ取り早いのがjstatです。
色々オプションがあるので全部を理解するのはなかなか難しいのですが、我々初心者にわかりやすいのは以下の二つです。
# jstat -gc -t [PID] 1000
# jstat -gcutil -t [PID] 1000
-tは先頭にタイムスタンプが付き、1000ミリ秒ごとに対象PIDの情報を出力するという意味になります。
-gc は各項目の使用量がKB単位で出力されます。
-gcutilは各項目の使用量が%単位で表示されます。
それぞれの出力項目は以下の通りです。
jstat -gc の項目一覧
CCSU以前の値は全てKB
| 項目名 | 項目内容 |
|---|---|
| S0C | Survivor0の設定値 |
| S1C | Survivor1の設定値 |
| S0U | Survivor0の実使用量 |
| S1U | Survivor1の実使用量 |
| EC | Edenの設定値 |
| EU | Edenの実使用量 |
| OC | Old領域の設定値 |
| OU | Oldの実使用量 |
| MC | メタスペースの設定値 |
| MU | メタスペースの実使用量 |
| CCSC | 圧縮されたClass領域の設定値 |
| CCSU | 圧縮されたClass領域の実使用量 |
| YGC | Young世代のガベージコレクションイベント数 |
| YGCT | Young世代のガベージコレクション累積時間 |
| FGC | フルガベージコレクションのイベント数 |
| FGCT | フルガベージコレクションの累積時間 |
| GCT | ガベージコレクションの総累積時間 |
jstat -gcutil の項目一覧
CCS以前の単位は%
| 項目名 | 項目内容 |
|---|---|
| S0 | Survivor0の実使用率 |
| S1 | Survivor1の実使用率 |
| E | Edenの実使用率 |
| O | Oldの実使用率 |
| M | メタスペースの実使用率 |
| CCS | 圧縮されたClass領域の実使用率 |
| YGC | Young世代のガベージコレクションイベント数 |
| YGCT | Young世代のガベージコレクション累積時間 |
| FGC | フルガベージコレクションのイベント数 |
| FGCT | フルガベージコレクションの累積時間 |
| GCT | ガベージコレクションの総累積時間 |
jstatで監視していると、本当にEdenが100%になったところでマイナーGCが実行され、Surviver領域が書き換わる瞬間を見ることができます。
ここでEdenがしっかり0になって、1マイナーGCあたりのタイムが0.1秒以下とかで処理されていればNew領域に関しては全く問題無いと思います。(違ってたらご指摘を・・)
一方で今の時代、NEWで1GBならOldでその3倍も領域をとる必要があるのか甚だ疑問に感じます。
いつまでたってもフルGCが実行されずゾンビみたいなのがどんどん溜まって最後はOOMKillerに殺されてしまうなんてことはナンセンスな話です。これだけNew領域が大きいのであれば、Oldも同じくらいで良いのではないでしょうか。
結論
適当な設定は死を招きます。
気を付けましょう。
想像以上にストックしていただいた方が多かったので、少し結論の補足をいたします。
まずコメント欄にも書いた通り直接の障害の元と考えられるのは、納入業者が過去に納入した32GB Memoryの設定をそのまま8GB Memory
のサーバに適用したことと考えられます。
その結果java ヒープ、ネイティブヒープ、その他のメモリー使用合算値が物理メモリーと同等に膨れ上がって、フルGCのタイミングで溢れてしまったというのが事の顛末と考えられます。
例えば今回のように8GBレベルで運用する場合、目安として以下くらいで設定して様子を見て小まめにチューニングするといったことが推奨されます。
-XX:NewSize=700m
-XX:MaxNewSize=700m
-Xms2048m
-Xmx2048m
-XX:MetaspaceSize=300m
-XX:MaxMetaspaceSize=300m
-XX:SurvivorRatio=6
-XX:TargetSurvivorRatio=9
-XX:MaxTenuringThreshold=15
(上記は飽くまでも目安です。必ず独自にチューニングを行ってください。動作するアプリやサーバの環境によって条件が全く異なりますので、各々の環境に合った設定を行う必要があります。上記設定丸写しで何か問題があってもenoshimanは一切責任は持てませんのでそこはご了承くださいね。)
今回のようにあからさまに設定がおかしい場合は割と直ぐにわかりますが、現実にはアプリ側起因でメモリーリークがあったり物理メモリーそのものが足りなかったり様々な要因が考えられますので、一定期間ヒープダンプをとってみて異常な数字が無いか確認してみたり、コメントでご指摘があったようにVisualVMを使用して可視化したりといったことも有効です。
慣れるとjstatでも割と手に取るように変化がわかります。
各領域の実使用量の推移やGCの時間を見て、減りが悪かったりGCに時間がかかったりムラがあったりした場合は何か問題がある可能性があります。ちゃんと動いているGCを見ているとなんだかスカッとしますよ。(ちょっと変な趣味に走りそうですが・・・)