はじめに
本記事では、LINEスタンプの画像をWebスクレイピングで収集した後、DCGAN-tensorflowの教師データとして与えるために、画像データをクリーニングする方法についてまとめます。
目次
- はじめに
- WEBスクレイピング
- データのクリーニング
- コマンドラインでのクリーニング
- 学習実行時に発生したエラー
- αチャネルを持たないpngファイルの除外
- 学習の実行
Webスクレイピング
Pythonで簡潔なスクレイピングコードを実装しました。ササッとデータを持ってきたかったので、例外処理などしてません。LINE STORE上の「カワイイ・キュート」カテゴリのスタンプを人気順に並べたものを順にダウンロードしていきます。LINE STOREでは、「カワイイ・キュート」「カッコイイ」などのカテゴリ、さらに「ネコ」「ウサギ」などのキャラクターを指定して絞り込むことができます。
今回は、キャラクターを指定せずにすべて読み込むことにします。
(一通り試し終えたら、"ネコ"に絞り込んで学習も試してみる予定です。)
以下実装したスクリプトになりますが、スクレイピングの際はLINE STOREページのフォーマットに依存します。今後LINE STOREのフォーマットが変更された際、コードは使えなくなるのでご注意ください。(2018/7/5時点)
# かわいいスタンプのランキング上位から順番に保存する
import requests
import os
from bs4 import BeautifulSoup
# htmlのソースから画像リンクを抽出するための関数
def rem(str):
str0 = str.split("(")[1]
return str0.split(";")[0]
# スタンプセットのNo.(指定した番号から始まり、セットごとにフォルダが生成される)
setname = 0
chara = "&character=" + str(10) # 10: ネコ, 11:ウサギ, 12:イヌ, 13:クマ, 14:鳥, 19:パンダ, 20:アザラシ
# キャラクター指定せずにすべてを対象とする場合
chara = ""
# 「カワイイ・キュート」ジャンルのスタンプを昇順に並べ、ページごとにデータを取得する
for page in range(1,11):
ranking_url = 'https://store.line.me/stickershop/showcase/top_creators/ja?taste=1'+ str(chara) + '&page=' + str(page)
ran = requests.get(ranking_url) #requestsを使って、webから取得
soup0 = BeautifulSoup(ran.text, 'lxml') #要素を抽出
stamp_list = soup0.find_all(class_="mdCMN02Li") #ソースの中でスタンプ一覧の箇所を探してリストに格納
for i in stamp_list:
target_url = "https://store.line.me" + i.a.get("href") #スタンプセットに含まれる画像を表示させるページのリンク
#target_url = 'https://store.line.me/stickershop/product/3882252/ja'
r = requests.get(target_url) #requestsを使って、webから取得
setname += 1
new_dir_path = str(setname) #スタンプセットのNo.に対応するフォルダを作成する
os.makedirs(new_dir_path, exist_ok=True) #フォルダが存在しない場合作成する
soup = BeautifulSoup(r.text, 'lxml') #要素を抽出
span_list = soup.findAll("span",{"class":"mdCMN09Image"}) #スタンプセットに含まれる画像の情報をリストに格納
fname = 0 #ダウンロードする画像データの名称
for i in span_list:
fname += 1
imgsrc = rem(i.get("style")) #画像データのURLを取得
req = requests.get(imgsrc)
if r.status_code == 200:
f = open( str(setname) + "/" + str(fname) + ".png", 'wb')
f.write(req.content)
f.close()
print ("finished downloading page: " + str(page) + " , set: ~" + str(setname) )
実行するとフォルダごとで、人気順にスタンプ画像を取得して保存することができます。
【注意】集中してサーバに負荷をかけ過ぎないように、ページ数の範囲指定を大きくしすぎないようにします。
$scrape-line-stamp.py
finished downloading page: 1 , set: ~36
: :
finished downloading page: 8 , set: ~324
finished downloading page: 10 , set: ~360
データのクリーニング
現在画像はフォルダに分けて取得しており、このディレクトリ構成のままではDCGAN-tensorflowの入力として与えることができません。そこで、各画像データをDCGAN-tensorflowの[data]フォルダ内にすべてコピーします。同時に、今回入力として与える教師用の画像・テスト用の画像はすべて固定サイズのものを扱うため、指定したサイズ(259 x 224)の画像のみをコピーします。
import os
from PIL import Image
import shutil
name = 1 #保存画像名
for num in range(1,710): #各画像フォルダ内の画像について
badsize = False
st_list = os.listdir("./"+str(num)+ "/")
for i in st_list:
im = Image.open("./"+str(num)+ "/"+i)
width, height = im.size
if not ( width==259 and height==224 ): #画像サイズが不適切の場合
badsize = True
if badsize:
print("skip: "+ str(num) )
if not badsize:
for i in st_list:
shutil.copyfile("./"+str(num)+ "/"+i, "../AI_st/"+str(name)+ ".png")
name += 1
画像フォルダを格納したディレクトリでスクリプトを実行すると、対象の画像をまとめてコピーすることができます。コンソール出力には画像サイズが不適切で、コピーをスキップした画像フォルダの名称がが表示されます。
$python copy-clean-image.py
skip: 5
skip: 8
: :
skip: 704
この実行例では[AI-st]フォルダ内に、条件を満たした画像データを保存しています。
[参考]コマンドラインでのクリーニング
環境にImagemagickがインストールされていれば、スクリプトを書かなくてもコマンドライン上で特定のサイズの画像を簡単に移動させることができます。以下のコマンドを実行すると、データセットを格納したフォルダの中にbadフォルダを生成し、画像サイズが259x224以外のファイルをすべてbadフォルダ内へ移動します。(Imagemagickのidentifyコマンドを使用)
$mkdir bad
$identify *.png | grep -v 259x224 | awk -F'[[ ]' '{print $1}' | xargs -I {} bash -c "mv {} bad"
上記のコマンドでは、フォルダ内の画像ファイル(.png)の情報を表示した際に「259x224」文字列を含まないファイルを除外します。条件を満たす場合、文字列を"["または"(空白)"で区切ったときの1フィールド目の要素がファイル名となっているので、awkで指定して出力します。下記のように、ダウンロードしたスタンプ画像によってファイル名の後に[1]が付くものが散見されたため、このような条件にしています。
$identify *.png | grep -v 100x100
1.png PNG 259x224 259x224+0+0 8-bit sRGB 12.3KB 0.000u 0:00.009
2.png[1] PNG 259x224 259x224+0+0 8-bit sRGB 256c 27KB 0.000u 0:00.000
学習実行時に発生したエラー
特定のサイズのみを入力として与えてDCGAN-tensorflowの学習を実行してみましたが、途中でエラーが発生してしましました。
Traceback (most recent call last):
File "main.py", line 103, in <module>
tf.app.run()
File "/anaconda3/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 126, in run
_sys.exit(main(argv))
File "main.py", line 86, in main
dcgan.train(FLAGS)
File "/Users/Meta/Document/DCGAN-tensorflow/model.py", line 224, in train
batch_images = np.array(batch).astype(np.float32)
ValueError: could not broadcast input array from shape (64,74,4) into shape (64,74)
エラーの内容は、画像のチャネル数が4から1へブロードキャストできないとのこと。
ValueError: could not broadcast input array from shape (64,74,4) into shape (64,74)
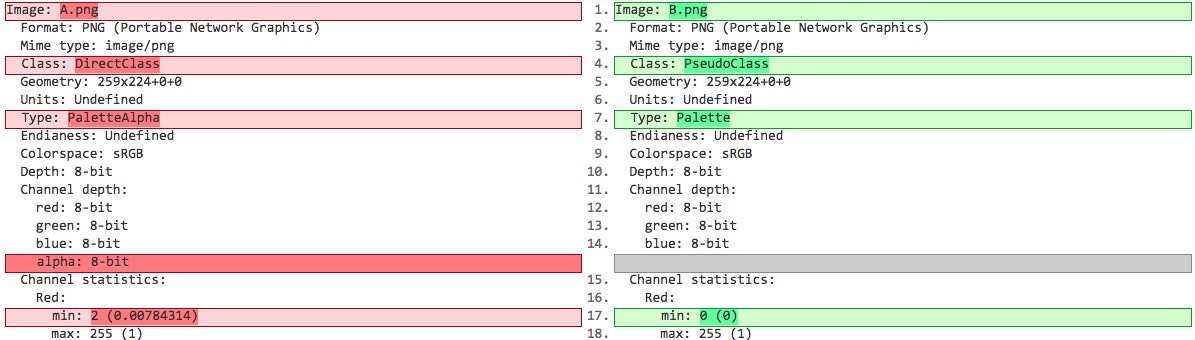
画像データの形式を調べてみると、不透明度を定義する画像のαチャネルを持つデータと持たないデータが混在していることがわかりました。LINEのスタンプでは、背景を透過させたpng形式の画像データが大多数ですが、259x224ピクセルにびっしりと色を詰めた画像の中に、一部αチャネルを持たない画像があり、それが原因でエラーを吐いていました。
$identify *.png
A.png PNG 259x224 259x224+0+0 8-bit sRGB 12.3KB 0.000u 0:00.009
B.png[1] PNG 259x224 259x224+0+0 8-bit sRGB 256c 27KB 0.000u 0:00.000
上記のA.pngとB.pngの2種類のpng形式の詳細を比較してみると、TypeがPalleteAlphaとPalleteとなっており、B.pngではアルファチャネルを持たないことがわかります。
$identify -verbose *.png
比較ツール:https://www.diffchecker.com/
同じpngファイルでも一部形式が異なるものがあるので注意しましょう。異なる形式が混在しているとエラーになるため、αチャネルを持たない画像データを除外します。
[参考]
https://github.com/carpedm20/DCGAN-tensorflow/issues/162
αチャネルを持たないpngファイルの除外
画像のサイズでフィルタリングする時と同じ要領で、エラーの原因となっている画像を除外します。
上記のB.pngのように"256c"形式が混在しているとエラーとなるので、この形式になっているファイルを除外します。
$identify *.png | grep 256c | awk -F'[[ ]' '{ print $1 }' | xargs -I {} bash -c "mv {} bad"
ただ、画像ファイル数が多すぎるとエラーになるので、ご注意ください。
-bash: /opt/local/bin/identify: Argument list too long
参考までに、12,000枚程度保存したフォルダで実行した際はエラーは発生しませんでした。
学習の実行
以上の操作により、データセットのクリーンが完了し、ようやく学習の準備が整いました。あとはDCGAN-tensorflowを実行して待つのみです。
$python main.py --dataset AI-st --input_height=224 --input_fname_pattern="*.png" --train --crop
ただ、私が使えるマシンはMacbookAir(mid2012)しかないので、epoch25で学習データ数20,000枚だと終わりが見えません。途方も無いです。エポック数を減らしたり、学習のハイパパラメータをちょこちょこいじりながら、可能な範囲で少しずつテストを進めています。Part1から、入力画像の種類を大幅に増やして、学習を実施してみたところ生成画像に大きな改善が見られました。
(学習に要した日数は約2日間)
[画像:8000枚, エポック:25]

遠くから見ると割とスタンプ感ある!?
しかし、本格的にDeepLearningするためには、NVIDIAのGeForceシリーズなど高額なGPUは必須みたいですね…。買うのはなかなかハードルが高いのでパブリッククラウドが使えないか検討しています。見通しが立ち上手くいきそうであれば、一度AWSでNVIDIAのGPU搭載のインスタンスを起動して実験してみたいです。
その時は財布と相談……。
次回は、入力画像数などパラメータを変化させて学習を実行して得られる結果の変化を紹介します。
Part3へ続く。
LINEスタンプをDeepLearningで自動生成してみる【Part 3】